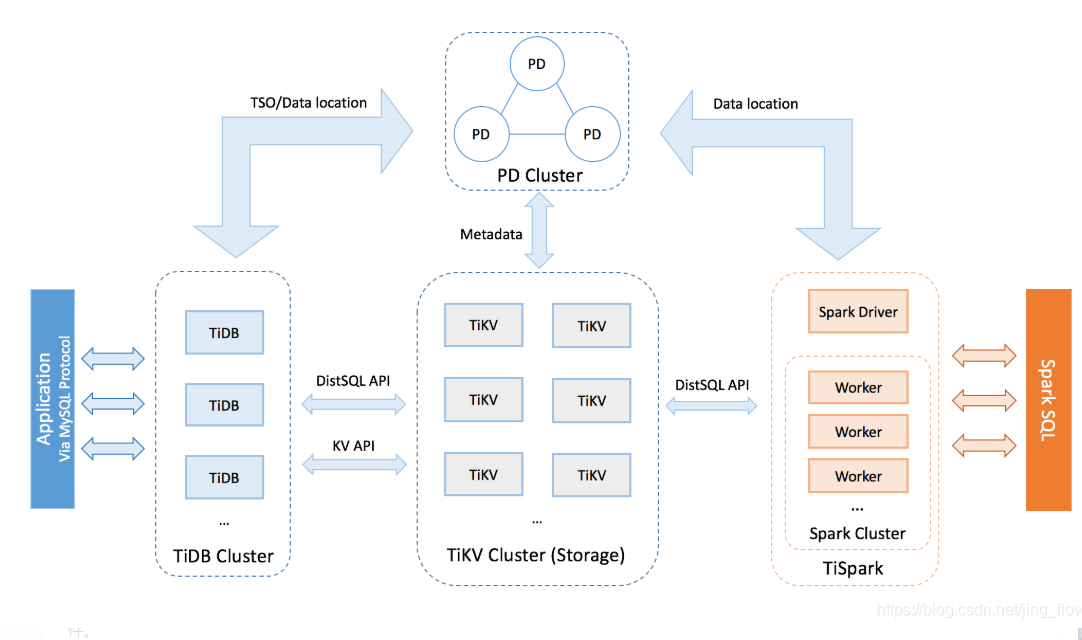
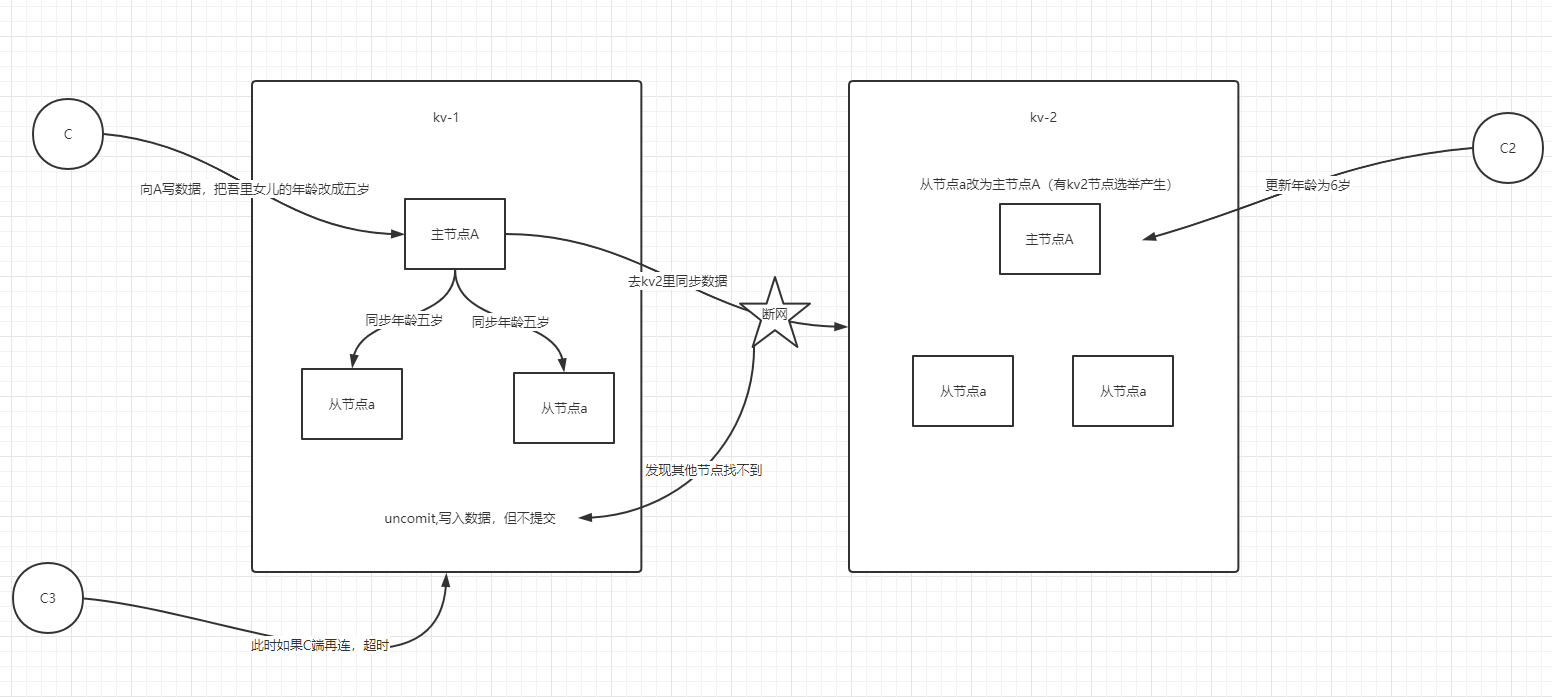
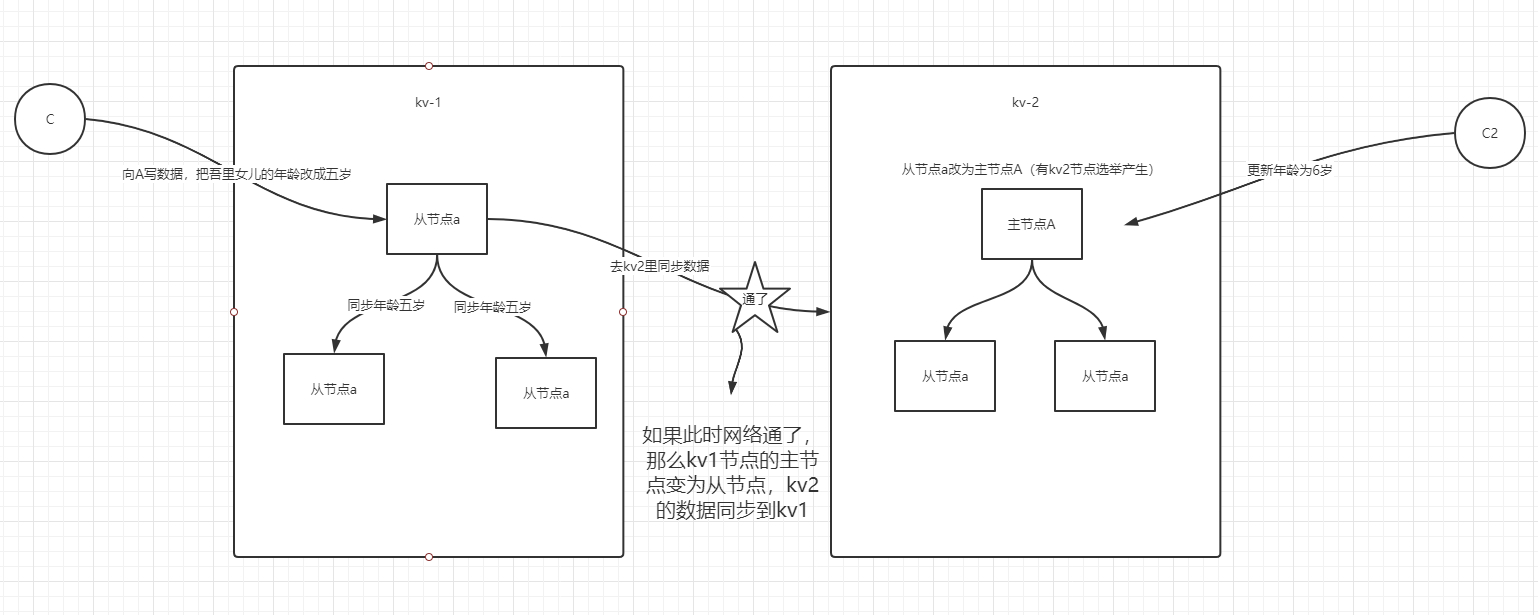
Tidb架构图,如上图
主要分为3部分
1.TiKV-Server
tikv是负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。类似map数据结构(键值对)
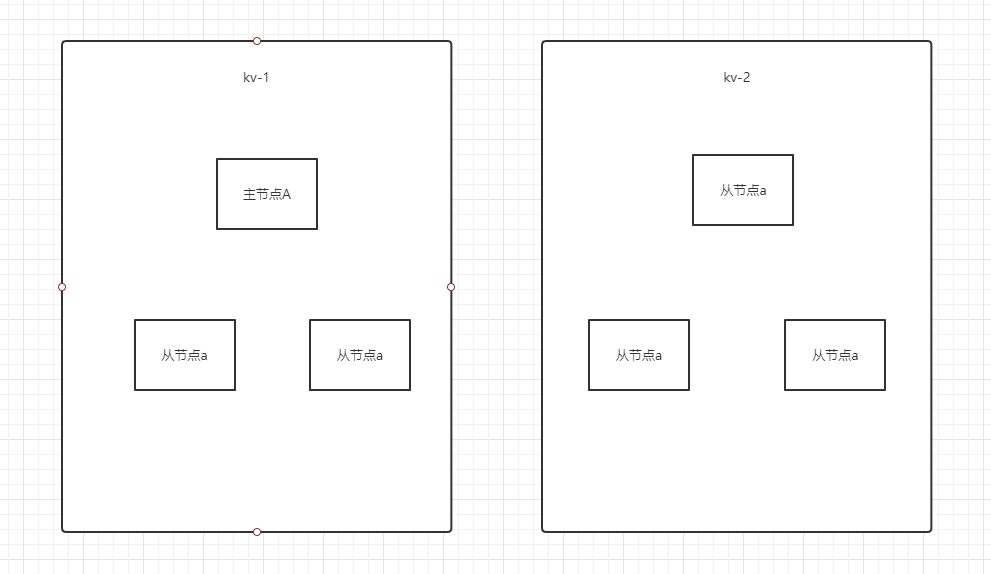
tikv之间是有心跳的,tikv之间的数据都是互相备份的,可以保证数据一致性
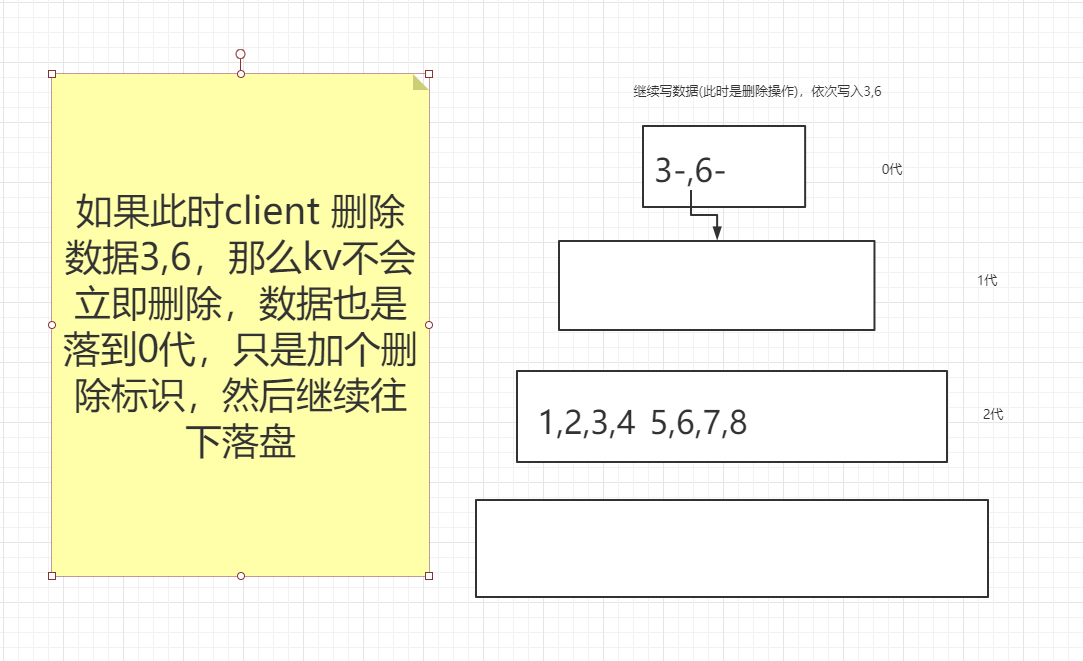
既然tikv是负责存储数据的,为什么读写速度这么快????
数据存储效率还是很高滴,tikv集群内部本身是通过RPC来交互的,,,大家都知道rpc,高性能嘛
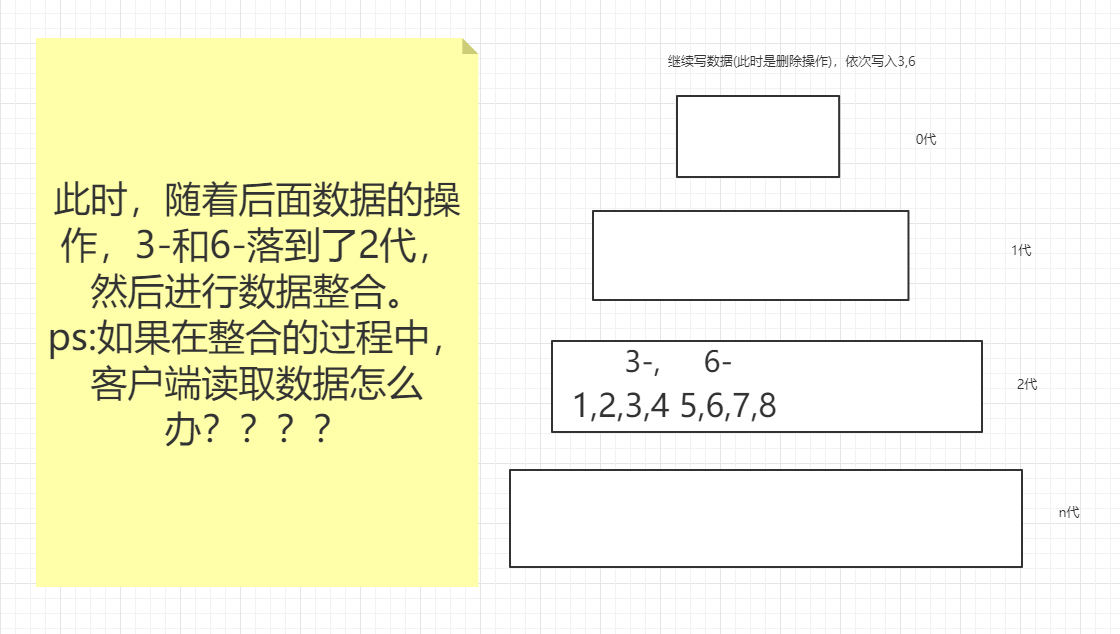
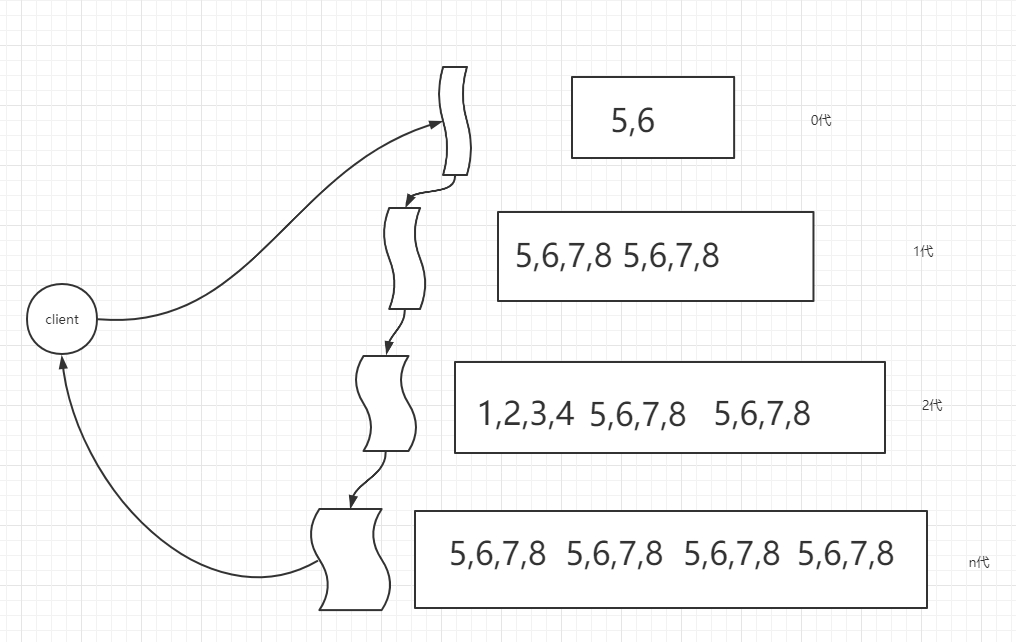
两点 1.IO操作(随机读写问题)即如何去保证顺序读写的,类似于leveldb--通过分代解决写的问题,然后通过布隆过滤器解决读的问题
2.数据一致性的问题(Raft算法)这个是开源算法,tikv节点与备份节点的选举问题
2.PD-Server
1.存储集群的元信息的,比如说某个key在哪个节点上
2.对tikv集群进行调度和负责均衡,包括节点扩容数据自动迁移
3.分配全局唯一rowid
3.Tidb-Server
它是一个mysql的数据引擎,负责解析和处理sql,,然后通过pd去找到数据在kv上面的地址,最后与kv交互拿到数据,再返回结果。
它是个无状态的节点,本身不存储数据,只负责计算,并且可以配置节点个数,无限水平扩展,这个类似于k8s的中的rs
至于服务端连接的话,可以用一下负载组件,比如说HA,nginx,来提供统一的地址
Ti-Spark(tidb对应的一种策略)
这个组件,没太深入研究,它主要是对大数据操作中复杂的sql进行快速计算,快速的实现海量数据的统计,并且他还同时支持OLTP和OLAP 解决数据同步的问题
至于什么是OLTP和OLAP
解释一下
OLTP:它是联机的事务处理----就是说:在尽可能短的时间内返回结果-------对应的就是我们的关系型数据库-----------比如说mysql,oracle,sqlserver
OLAP:它是联机的分析处理----就是说:对历史数据分析,然后产生决策,针对于海量的数据统计快速的给出结果----比如说数据仓库---------hive,tidb
这个很强势。。。
第一个大问题:IO 随机读写问题 ---------损失了一部分读的性能(最终一致性的问题),提高了大量的写的性能
首先需要选择一个map的数据结构的存储方案
RocksDB:他是一个任何持久化的存储引擎(也是基于kv存储的),是谷歌开源的这么一个项目,底层是lsm树,他是树的结合体(树+跳跃表)
如果大家不清楚RocksDB ,,,那么应该听过leveldb ,,,,rocksdb是leveldb的一个升级版本 ,
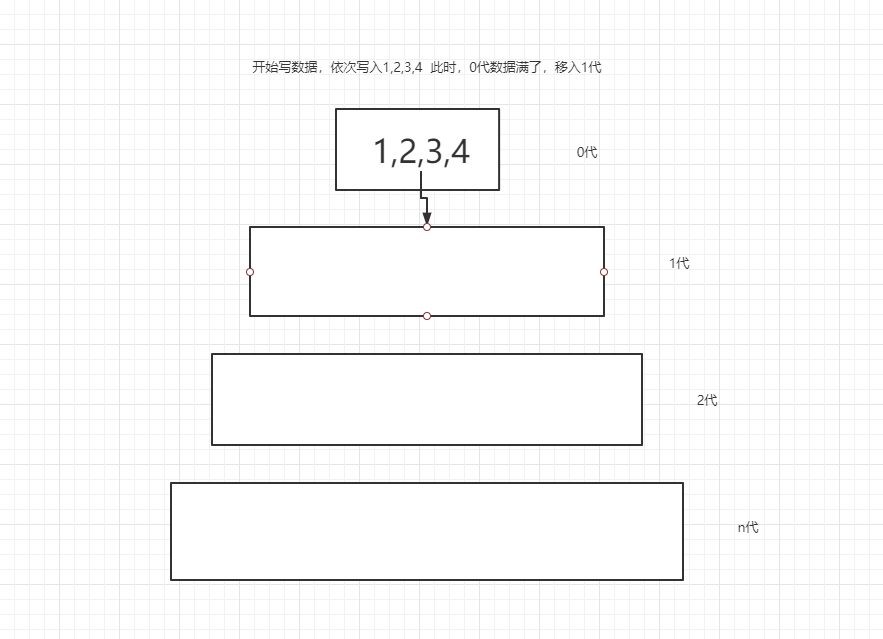
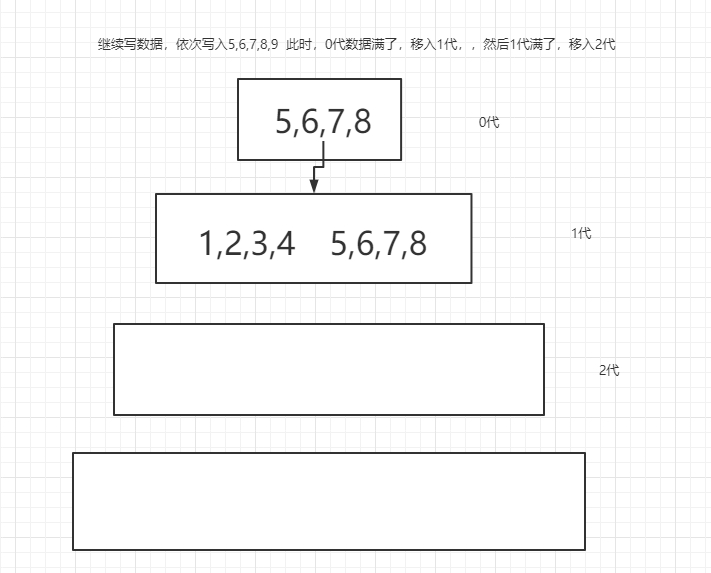
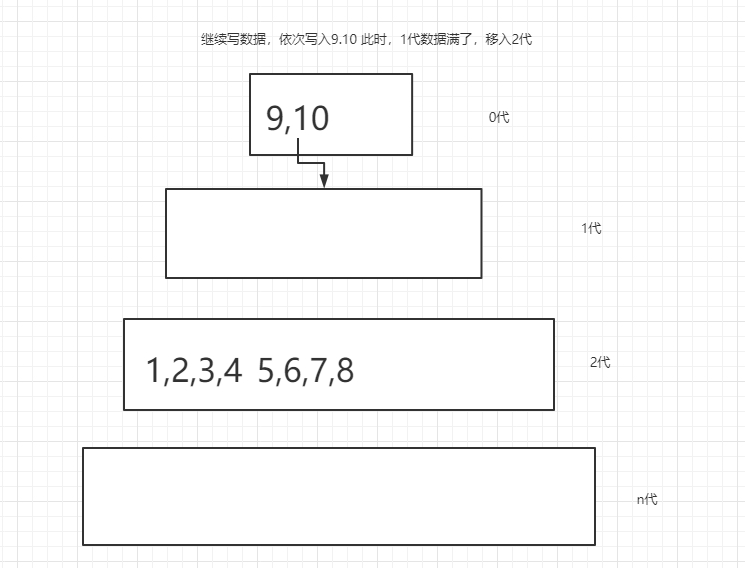
leveldb
他是实现顺序读写的,是通过层级划分
如图