一、什么是配置文件?
-
配置文件示例
[mysql] default-character-set = utf8 [mysqld] port = 3306 basedir = c:mysql-5.7.25-winx64mysql-5.7.25-winx64 daradir = c:mysql-5.7.25-winx64mysql-5.7.25-winx64data max_connections = 200 character-set-server = utf8 default-storage-engine = INNODB explicit_defaults_for_timestamp = true
-
为什么要做配置文件?
所有的代码和配置都变成模块化可配置化,这样就提高了代码的复用性,不用每次都去修改代码内部。
-
场景举例
1、多处地方需要使用同一个参数,这时候最好是配置化,这样改一处就可以了
2、如果是经常变化的变量,我们也可以做这个配置。---> 与参数化要区分开来
-
python中常见的配置文件格式
.ini、.conf、.cfg结尾的文件
-
配置对象
- section
- option
二、ConfigParser模块
掌握一些比较基础的用法:跟file文件一样,要先打开才能进行读取操作
-
实例化ConfigParse对象:cf = configParser.ConfigParser()
-
打开配置文件:cf.read(配置文件名称或者地址)
-
常用方法:
-
- read(filename) 直接读取文件内容
- sections() 得到所有的section,并以列表的形式返回
- options(section) 得到该section的所有option
- items(section) 得到该section的所有键值对
- get(section,option) 得到该section中option的值,返回类型为string
- getint(section,option) 得到该section中option的值,返回为int类型,还有相应的getboolean()和getfloat()
-
练习
import configparser # 实例化ConfigParser对象 conf = configparser.ConfigParser() # 打开配置文件 cf = conf.read("my.conf",encoding = 'utf8') # 根据section和option得到option的值 a = conf.get('mysqld','port') print(a) # 得到所有的section,并以列表的形式返回 b = conf.sections() print(b) # 得到该section的所有option c = conf.options('mysqld') print(c) # 得到该section所有的键值对 d = dict(conf.items("mysql")) print(d)
输出结果为:

-
封装一个读取配置文件的类
import configparser """ 为什么要封装? 封装是为了使用起来更加方便,便于再次修改 封装的需求? 封装成什么样子才能达到我们的目的 封装的原则: 写死的固定数据(变量),可以封装成雷属性 实现某个功能的代码封装成方法 在各个办法中都要用到的数据,抽离出来作为实例属性 """ # 封装前 读取数据(三部曲) # 实例化ConfigParser对象 # conf = configparser.ConfigParser() # 打开配置文件 # conf.read("config.ini",encoding='utf8') # # 根据section和option得到option的值 # conf.get('excel','file_name') class ReadConfig(configparser.ConfigParser): def __init__(self): # 实例化对象 super().__init__() # 加载文件 self.read(r"E:python_api_testAPI_Test_v4_configconfconfig.ini",encoding='utf8') conf = ReadConfig()
-
在其他模块调用封装好的配置文件时:from xxxx.xxxx.config import conf
三、将配置文件集成到单元测试中
1、项目结构
- common:这个目录用来存放的是自己封装的类
- conf:这个目录用来存放配置文件
- librarys:这个目录用来存放已封装好的模块(HTMLtestrunner、ddt)
- logs:这个目录用来存放日志文件
- data:这个目录用来存放excel的测试用例数据
- reposts:这个目录用来存放生成的的测试报告
- testcases:这个目录用来存放所有的测试用例模块
2、各项目层的结构图
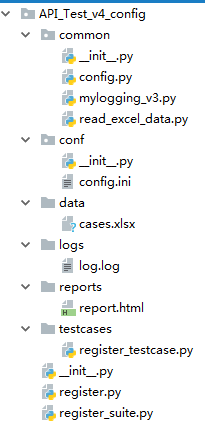
3、各项目层的具体代码
-
common层(包括config.py文件、mylogging_v3.py文件、read_excel_data.py文件)
新建config.py文件
import configparser """ 为什么要封装? 封装是为了使用起来更加方便,便于再次修改 封装的需求? 封装成什么样子才能达到我们的目的 封装的原则: 写死的固定数据(变量),可以封装成雷属性 实现某个功能的代码封装成方法 在各个办法中都要用到的数据,抽离出来作为实例属性 """ # 封装前 读取数据(三部曲) # 实例化ConfigParser对象 # conf = configparser.ConfigParser() # 打开配置文件 # conf.read("config.ini",encoding='utf8') # # 根据section和option得到option的值 # conf.get('excel','file_name') class ReadConfig(configparser.ConfigParser): def __init__(self): # 实例化对象 super().__init__() # 加载文件 self.read(r"E:python_api_testAPI_Test_v4_configconfconfig.ini",encoding='utf8') conf = ReadConfig()
新建mylogging_v3.py文件
import logging from API_Test_v4_config.common.config import conf # 日志收集器的名称 logger_name = conf.get('log','logger_name') # 日志收集器的级别 level = conf.get('log','level').upper() # 输出到控制台的日志级别 sh_level = conf.get('log','sh_level').upper() # 输出到文件的日志级别 fh_level = conf.get('log','fh_level').upper() # 日志保存的文件 log_file_path = conf.get('log','log_file_path') class MyLogging(object): def create_logger(*args,**kwargs): # 创建自己的日志收集器 my_log = logging.getLogger(logger_name) # 设置收集的日志等级,设置为DEBUG等级 my_log.setLevel(level) # 日志输出渠道 # 创建一个日志输出渠道(输出到控制台),并且设置输出的日志等级为INFO以上 l_s = logging.StreamHandler() l_s.setLevel(sh_level) # 创构建一个日志输出渠道(输出到文件),并且设置输出的日志等级为DEBUG以上 l_f = logging.FileHandler(log_file_path,encoding='utf8') l_f.setLevel(fh_level) #将日志输出渠道添加到日志收集器中 my_log.addHandler(l_s) my_log.addHandler(l_f) # 设置日志输出的格式 ft = "%(asctime)s - [%(filename)s -->line:%(lineno)d] - %(levelname)s: %(message)s" ft = logging.Formatter(ft) # 设置控制台和日志文件输出日志的格式 l_s.setFormatter(ft) l_f.setFormatter(ft) return my_log def debug(self,msg): self.my_log.debug(msg) def info(self,msg): self.my_log.info(msg) def warning(self,msg): self.my_log.warning(msg) def error(self,msg): self.my_log.error(msg) def critical(self,msg): self.my_log.critical(msg) #日志输出 m_log = MyLogging() # 创建日志收集器 logger = m_log.create_logger()
新建read_excel_data.py文件
import openpyxl class Case: def __init__(self,arrts): for item in arrts: setattr(self,item[0],item[1]) class ReadExcel(object): def __init__(self,filename,sheetname): """ 定义需要打开的文件及表名 :param filename: 文件名 :param sheetname: 表名 """ self.wb = openpyxl.load_workbook(filename) # 打开工作簿 self.sheet = self.wb[sheetname] # 选定表单 self.filename = filename # 特殊的魔术方法,在对象销毁之后执行的 def __del__(self): # 关闭文件 self.wb.close() def read_data_line(self): #按行读取数据转化为列表 rows_data = list(self.sh.rows) # print(rows_data) # 获取表单的表头信息 titles = [] for title in rows_data[0]: titles.append(title.value) # print(titles) #定义一个空列表用来存储测试用例 cases = [] for case in rows_data[1:]: # print(case) data = [] for cell in case: #获取一条测试用例数据 # print(cell.value) data.append(cell.value) # print(data) #判断该单元格是否为字符串,如果是字符串类型则需要使用eval();如果不是字符串类型则不需要使用eval() if isinstance(cell.value,str): data.append(eval(cell.value)) else: data.append(cell.value) #将该条数据存放至cases中 # print(dict(list(zip(titles,data)))) case_data = dict(list(zip(titles,data))) cases.append(case_data) return cases def read_excel_obj_new(self,list1): """ 按指定的列,读取excel中的数据,以列表的形式返回,列表中每个对象为一条测试用例, Excel中的表头为对象的属性,对应的数据为属性值。 :param list1: list --->要读取的列[1,2,3...] :return: type:list--->[case_obj1,case_obj2.......] """ # 从配置文件中读取的数据类型为string,需要转化为list list1 = eval(list1) # 判断传入的读取数据的列数是否为空,为空的话直接读取excel中所有的数据。 if list1 == []: return self.read_data_line() # 获取表里面的最大行数 max_row = self.sheet.max_row # 定义一个空列表,用来存放测试用例数据 cases = [] # 定义一个空列表,用来存放表头数据 titles = [] # 遍历所有的行数据 for row in range(1,max_row+1): case_data = [] if row != 1: for column in list1: info = self.sheet.cell(row,column).value # print(info) case_data.append(info) case = list(zip(titles,case_data)) # print(case) case_obj = Case(case) cases.append(case_obj) else: for column in list1: title = self.sheet.cell(row,column).value titles.append(title) if None in titles: raise ValueError("表头的数据有显示为空") return cases def write_excel(self,row,column,msg): #写入数据 self.sheet.cell(row=row,column=column,value=msg) self.wb.save(self.filename)
-
conf层(config.ini文件--->配置文件)
新建config.ini文件
# log日志相关配置 [log] # 日志收集器的名称 logger_name = my_log # 日志收集器的级别 level = DEBUG # 输出到控制台的日志级别 sh_level = DEBUG # 输出到文件的日志级别() fh_level = debug # 日志保存的文件 log_file_path = E:python_api_testAPI_Test_v4_configlogslog.log # 读取excel中测试用例数据相关的配置 [excel] # 用例文件名称 file_name = E:python_api_testAPI_Test_v4_configdatacases.xlsx # sheet表单名称 sheet_name = Sheet1 # 读取表单中的列数(每条用例的数据) []空列表便是所有列 read_colums = [1,2,3] # 测试报告相关的配置 [report] report_path = E:python_api_testAPI_Test_v4_config eports eport.html report_name = python接口自动化测试报告 report_tester = 测试
-
data层(cases.xlsx文件--->测试用例数据)
新建cases.xlsx文件

-
testcase层(register_testcase.py文件--->注册函数的测试用例)
新建register_testcase.py文件
import unittest from API_Test_v4_config.register import register from API_Test_v4_config.common.read_excel_data import ReadExcel from ddt import ddt,data from API_Test_v4_config.common.mylogging_v3 import logger from API_Test_v4_config.common.config import conf # 配置文件中读取excel相关数据 file_name = conf.get('excel','file_name') sheet_name = conf.get('excel','sheet_name') read_colums = conf.get('excel','read_colums') # 读取excel中的数据 wb = ReadExcel(file_name,sheet_name) cases = wb.read_excel_obj_new(read_colums) @ddt class RegisterTestCase(unittest.TestCase): def setUp(self): print("准备测试环境,执行测试用例之前会执行此操作") def tearDown(self): print("还原测试环境,执行完测试用例之后会执行此操作") @data(*cases) def test_register(self,case): self.row = case.caseid + 1 res = register(*eval(case.data)) try: self.assertEquals(eval(case.excepted),res) except AssertionError as e: res = "未通过" logger.error(e) raise e else: res = "通过" logger.info("该条测试用例的测试结果为:{}".format(res)) finally: # 调用写入数据的方法,在excel中回写测试用例的执行结果 wb.write_excel(row=self.row,column=4,msg=res) if __name__ == '__main__': unittest.main()
-
最外面层(register.py文件--->需要测试的功能函数、 register_suites.py--->执行测试套件)
新建register.py文件
# 设计用例,对注册功能函数进行单元测试 users = [{'user': 'python18', 'password': '123456'}] def register(username, password1, password2): # 注册功能 for user in users: # 遍历出所有账号,判断账号是否存在 if username == user['user']: # 账号存在 return {"code": 0, "msg": "该账户已存在"} else: if password1 != password2: # 两次密码不一致 return {"code": 0, "msg": "两次密码不一致"} else: # 账号不存在 密码不重复,判断账号密码长度是否在 6-18位之间 if 6 <= len(username) <= 18 and 6 <= len(password1) <= 18: # 注册账号 users.append({'user': username, 'password': password2}) return {"code": 1, "msg": "注册成功"} else: # 账号密码长度不对,注册失败 return {"code": 0, "msg": "账号和密码必须在6-18位之间"}
新建register_suites.py文件
import unittest from HTMLTestRunnerNew import HTMLTestRunner from API_Test_v4_config.testcases import register_testcase from API_Test_v4_config.common.config import conf # 第二步:创建测试套件 suite = unittest.TestSuite() # 第三步:将测试用例加载到测试套件中 loader = unittest.TestLoader() # 通过测试用例类来添加测试用例 # suite.addTest(loader.loadTestsFromTestCase(RegisterTestCase)) # 通过模块来添加测试用例 suite.addTest(loader.loadTestsFromModule(register_testcase)) # 添加测试用例,通过路径加载测试用例目录下的所有模块 # suite.addTest(loader.discover("E:\python_api_test\API_Test_v4_config\testcases")) #第四步:执行测试套件,生成测试报告 # 读取配置文件中report相关的配置信息 report_path = conf.get("report",'report_path') report_name = conf.get('report','report_name') report_tester = conf.get('report','report_tester') with open(report_path,'wb') as f: runner = HTMLTestRunner( stream = f, verbosity = 2, title = 'python_18_report', description = report_name, tester = report_tester ) runner.run(suite)