export是HDFS里的文件导出到RDBMS的工具,不能从hive、hbase导出数据,且HDFS文件只能是文本格式。如果要把hive表数据导出到RDBMS,可以先把hive表通过查询写入到一个临时表,临时用文本格式,然后再从该临时表目录里export数据。
HDFS导出数据到MySQL
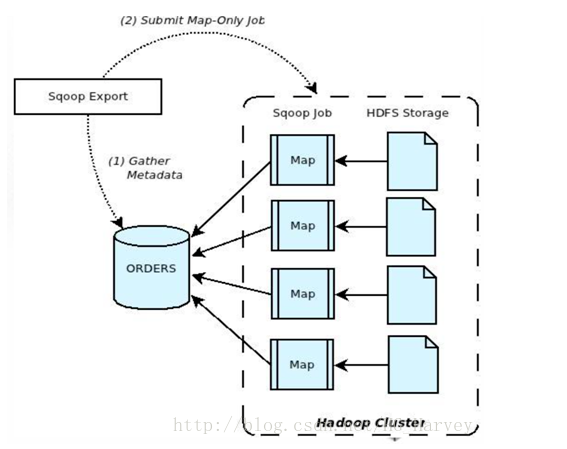
说明:
(1).Sqoop与数据库通信,获取数据库表的元数据信息;
(2).将Hadoop上的文件划分成若干个Split,每个Split由一个Map Task进行数据导出操作;
参数
--columns:指定插入目标数据库的字段,sqoop直接读取hdfs文件并把记录解析成多个字段,此时解析后的记录是没有字段名的 是通过位置和columns列表对应的,数据库插入的sql类似于: insert into _table (c1,c2...) value(v1,v2...) --export-dir:指定HDFS输入文件的目录 --input-fields-terminated-by:字段之间分隔符 --input-lines-terminated-by:行分隔符
sqoop不会在mysql中自动创建表,在mysql中创建表EMP_DEMO
CREATE TABLE EMP_DEMO( EMPNO int(4) PRIMARY KEY, ENAME VARCHAR(10), JOB VARCHAR(9), MGR int(4), HIREDATE DATE, SAL int(7), COMM int(7), DEPTNO int(2), foreign key(deptno) references DEPT(DEPTNO) );
导出数据到mysql
sqoop export --connect jdbc:mysql://localhost:3306/sqoop --username root --password P@ssw0rd --table EMP_DEMO --export-dir /user/hadoop/EMP -m 1
导出指定的列(–columns)
sqoop export --connect jdbc:mysql://localhost:3306/sqoop --username root --password P@ssw0rd --table EMP_DEMO --columns "EMPNO,ENAME,JOB,SAL,COMM" --export-dir /user/hadoop/EMP_COLUMN -m 1
导出数据时设置字段与字段、行与行之间的分隔符
hdfs中/user/hadoop下EMP_SPLIT文件中的数据是我们前面通过mysql导入的,使用了分隔符,所以在导出时也需要指定分隔符,否则导出不成功。EMP_SPLIT文件内容如下
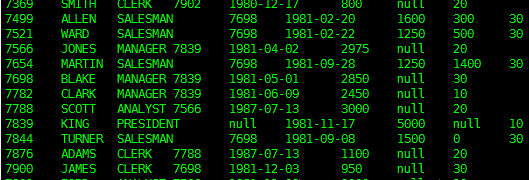
sqoop export --connect jdbc:mysql://localhost:3306/sqoop --username root --password P@ssw0rd --table EMP_DEMO --fields-terminated-by ' '
--lines-terminated-by ' ' --export-dir /user/hadoop/EMP_SPLIT -m 1
Hive 导出数据到 MySQL
实现需求:将hive 表 emp_import 中的数据导出到 Mysql 表 EMP_DEMO
hive 表 emp_import对应hdfs路径:/user/hive/warehouse/db_test.db/emp_import
mysql 中 EMP_DEMO 表结构如下
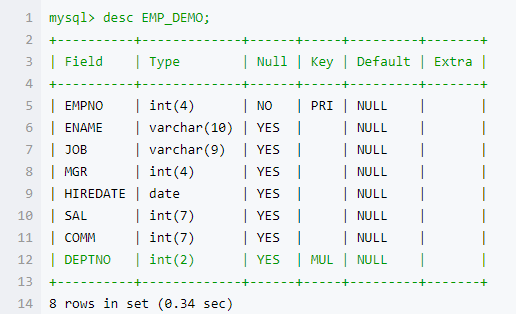
注意:mysql中日期为date类型,hive中对应的字段为字符串类型,其存储格式必须为:yyyy-mm-dd
导出时指定null字段的填充符,如果不指定会报一个异常NumberFormatException
–input-null-string:如果没有这个选项,那么在字符串类型列中,字符串”null”会被转换成空字符串,所以最好写上这个,指定为’N’
–input-null-non-string:如果没有这个选项,那么在非字符串类型的列中,空串和”null”都会被看作是null
sqoop export --connect jdbc:mysql://localhost:3306/sqoop --username root --password P@ssw0rd --table EMP_DEMO --export-dir /user/hive/warehouse/db_test.db/emp_import --input-fields-terminated-by '�01' --input-null-string '\N'
--input-null-non-string '\N' -m 1