HBase是建立在Hadoop文件系统之上的分布式面向列的数据库。它是一个开源项目,是横向扩展的。
HBase是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据。它利用了Hadoop的文件系统(HDFS)提供的容错能力。
它是Hadoop的生态系统,提供对数据的随机实时读/写访问,是Hadoop文件系统的一部分。
人们可以直接或通过HBase的存储HDFS数据。使用HBase在HDFS读取消费/随机访问数据。 HBase在Hadoop的文件系统之上,并提供了读写访问。
HBase 和 HDFS
| HDFS | HBase |
|---|---|
| HDFS是适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库。 |
| HDFS不支持快速单独记录查找。 | HBase提供在较大的表快速查找 |
| 它提供了高延迟批量处理;没有批处理概念。 | 它提供了数十亿条记录低延迟访问单个行记录(随机存取)。 |
| 它提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找。 |
Hbase的特点:
1.面向列:Hbase是面向列的存储和权限控制,并支持独立索引。列式存储,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段时,能大大减少读取的数据量。
2.多版本:Hbase每一个列的存储有多个Version。
3.稀疏性:为空的列不占用存储空间,表可以设计得非常稀疏。
4.扩展性:底层依赖HDFS。
5.高可靠性:WAL机制保证了数据写入时不会因集群异常而导致写入数据丢失,Replication机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且Hbase底层使用HDFS,HDFS本身也有备份。
6.高性能:底层的LSM数据结构和Rowkey有序排列等架构上的独特设计,使得Hbase具有非常高的写入性能。region切分,主键索引和缓存机制使得Hbase在海量数据下具备一定的随机读取性能,该性能真对Rowkey的查询能到达到毫秒级别。
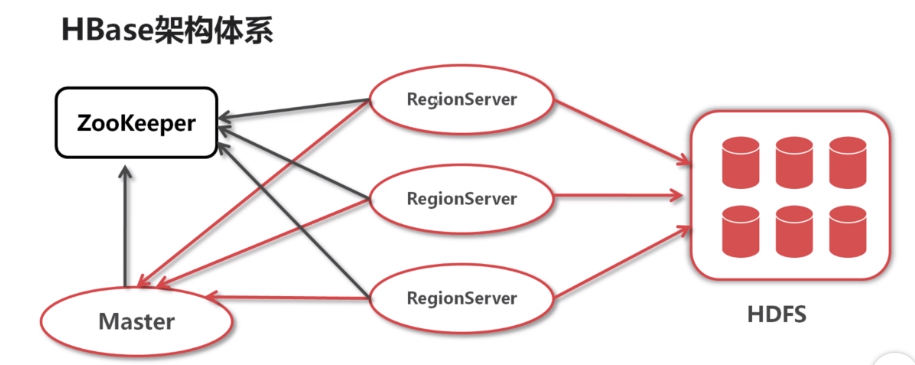
HBas架构体系:
有两个主要进程:RegionServer和Master
两个服务:HDFS和Zookeeper
HBase设计模型:


HBase数据模型


Region管理的数据例子:

