篇写了分布式链路追踪 spring cloud 分布式链路追踪
这样的链路追踪虽然可以解决问题 但日志太过于分散 如果微服务过多 就会变的相当复杂
zipkin就可以帮我们把链路调用的过程全部收集起来
它就像注册中心一样 分为客户端和服务端 想要使用 首先建一个模块 当作他的服务端
首先添加如下依赖
compile 'io.zipkin.java:zipkin-server'
compile 'io.zipkin.java:zipkin-autoconfigure-ui'
在配置文件中配置它的端口号以及项目名
server: port: 9999 spring: application: name: zikpin-server
然后在他的启动类加上@EnableZipkinServer
@EnableZipkinServer @SpringBootApplication public class ZikpinServerProvider { public static void main(String[] args) { SpringApplication.run(ZikpinServerProvider.class,args); } }
它就表示这个是Zipkin的服务端
之后需要在客户端也加入依赖
compile group: 'org.springframework.cloud', name: 'spring-cloud-sleuth-zipkin'
在客户端进行配置
spring: zipkin: base-url: http://localhost:9999 #代表zipkin服务端的地址 sleuth: sampler: percentage: 1.0 #代表提交链路到zipkin的频率 下面细讲
运行localhost:9999

可以看到这个页面 这个就是zipkin的主页面 他就可以非常具体形象的体现出微服务之间的链路及他们的调用 还有耗费的时间、性能等
我们运行一个方法 用微服务调用另一个微服务试一下 如果对这个不会 可以查看我之前的一篇 spring cloud eureka 微服务之间的调用
然后选择时间 进行查询 可以看到
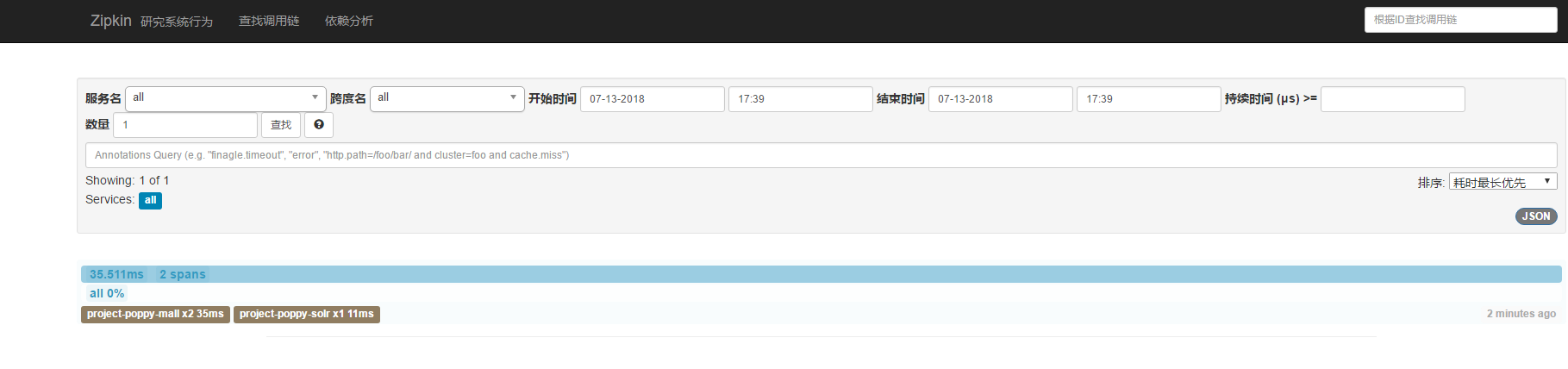 已经看到我们这次请求调用了两个微服务
已经看到我们这次请求调用了两个微服务
我们也可以在右上角 根据id查找调用链 来根据请求的id来查找 需要引入sleuth
具体可以参考我的一篇博客 spring cloud 分布式链路追踪
然后来讲一讲上面的
sleuth:
sampler:
percentage: 1.0
后面的值可以输入0.1-1.0之间 代表百分之多少
它的意思就是 有百分之多少的请求会上传到zipkin 就比如我们百分之五十 那就上传了一次 第二次就不上传 只通过日志的形式显示
为什么要用这个东西呢
我们微服务之间进行调用 本来就有耗费的资源以及限制 因为要调用另外一个微服务 现在还需要上传到zipkin 那就非常影响性能
如果上传到zipkin需要三十秒 那么微服务就什么都不能做 必须等这三十秒之后才能做别的事情 所以如果上传量特别大的话 可以仅上传一些作为采样
也可以把链路信息上传到消息队列中 这样就可以解耦合 对效率不会有影响 然后zipkin再从消息队列进行下载 可以用kafka之类的 这个我以后会另外再写一篇博客细讲
以上就是集成了zipkin的分布式链路跟踪