引言
假如没有len这个内置函数,我们想统计一个字符串或者列表长度,可以使用
s1 = 'jfdsklfjdkslffdsafsajsd' c = 0 for i in s1: c += 1 print(c)
l1 = [1, 2, 34, 55, 66] c = 0 for i in l1: c += 1 print(c)
但是有个问题,我们发现:
# 面向过程过程(流水账)
# 代码重复。
# 可读性差。
引出函数概念:
函数:一个函数封装一个功能。
下面来实现以下:
自己写一个函数,完全与len相同。
'''
def 函数名():
函数体
'''
# 函数的执行
# 函数名() 函数的执行者,调用者
def my_len(): l1 = [1, 2, 34, 55, 66] c = 0 for i in l1: c += 1 print(c) print(my_len())

返回值return
# return 1,函数中遇到return终止函数。
# return 2,返回值 返回给了函数的调用者
# 1, return 返回的是None
# 2, return 单个值 返回单个值
# 3, return 多个值 返回一个由这多个值组成的元组
return 单个值 返回单个值
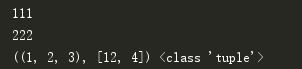
def my_len(): print(111) print(222) return '太白' print(my_len(),type(my_len())) #后面的type里面的也执行了一遍,所以有两个111 222

返回多个值 返回一个由这多个值组成的元组
def my_len(): print(111) print(222) return (1, 2, 3), [12,4] #返回给了my_len():函数的调用者
ret = my_len()
print(ret, type(ret)) #返回多个值
def my_len(): l1 = [1, 2, 34, 55, 66] c = 0 for i in l1: c += 1 return c print(my_len())

补充:
我们还可以这样写:
l1 = [1, 2, 34, 55, 66]
def my_len(): # 形参 和变量一样,自己定义
c = 0
for i in l1:
c += 1
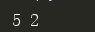
return c,2
ret,ret1= my_len() # 函数的执行者(实参)
print(ret,ret1)
分别赋值的这个概念。
函数的传参
函数分为实参和形参
l1 = [1, 2, 34, 55, 66] def my_len(s): # 形参 和变量一样,自己定义 c = 0 for i in s: c += 1 return c # retrun c所以就是返回最后c的值。 ret= my_len(l1) # 函数的执行者(实参) print(ret)

现在我们已经把my_len做出来和len一样的效果了。
现在测试一下任意字符串。
print(my_len('fdskalfdsjflsdajf;lsa'))

但是这个效率很低,但是我们还是要用自带的len
# 实参角度:
# 位置参数 : 从前至后 一一对应
# 关键字传参: 不用按照顺序,一一对应
# 混合传参: 位置参数一定在前面。
# 实参角度:
#1、 位置参数
def func1(a,b): print(a+b) func1('alex','wusir')

位置参数必须一一对应,否则会报错
练习题:
比较两个数大小,返回打的那个值。
def func1(a,b): # if a > b: # return a # else: # return b return a if a > b else b #和上面的if else一样,可以写成一条
print(func1(100,200))
def func1(a,b):
return a if a > b else b #和上面的if else一样,可以写成一条
print(func1(100,200))

上面的用到了三元运算。我们引申一个三元运算。
三元运算(对if else 优化): 只针对于 if else 二选一的情况。
a = 3 b = 2 # if a > b: # ret = a # else: # ret = b ret = a if a > b else b #和上面的if else一样,可以写成一条 如果a > b,我让ret==a,否则等于b a、b、ret分别是三元 print(ret)
只用两行实现:

2、关键字传参
def func2(age,name): print(name,age) func2(name='alex', age=73)

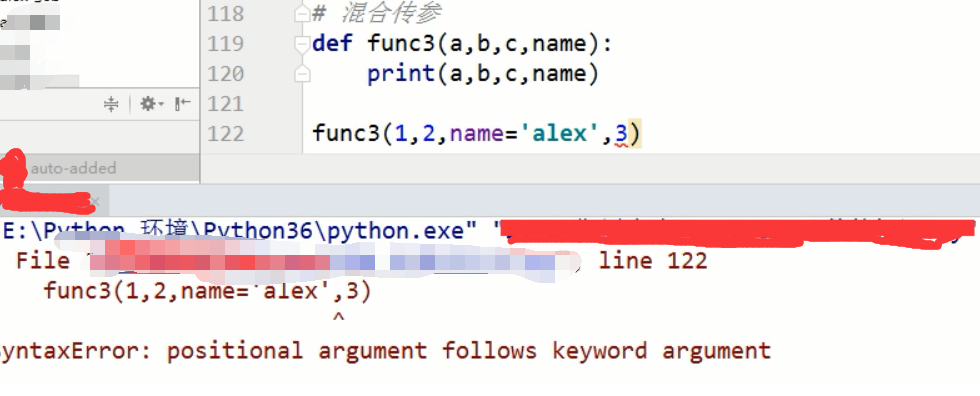
3、混合传参 混合传参: 位置参数一定在前面。
def func3(a,b,c,name): print(a,b,c,name) func3(1,2,3,name='alex')

坑: 混合传参: 位置参数一定在前面。
形参角度
# 位置传参: 按照顺序,一一对应
# 默认传参: 如果不传,则默认使用默认参数,传参则覆盖。 常用的会设置默认参数
# 动态参数,万能参数 *args **kwargs
1、位置参数 需要一一对应,否则报错
def func1(a,b,c): print(a,b,c) func1(1,2,3)

2、默认参数 :
def func2(name,age,sex='男'): print(name,age,sex) func2('alex',73,sex='女')

对于默认参数来说我们来一个练习题:
如果不传,则默认使用默认参数,传参则覆盖。 常用的会设置默认参数
1、班主任要统计同学的人员信息,我们使用函数、文件操作做一个登记表,设置默认性别是男 如果你是经常要输入的,可以设置一个默认。
def wfile(name, age, sex='男'): # 设置默认性别是男
with open('登记表', encoding='utf-8', mode='a') as f1:
f1.write('{}|{}|{}
'.format(name, age, sex)) # 使用write默认只能有一个参数,所以我们要用到格式化输出<br>
while 1:
name = input('姓名(输入Q/q退出):')
if name.upper() == 'Q': break # 增加退出
age = input('年龄:')
if name.startswith('1'): # 增加标识,如果这个是男,我们加一个标识,开头是1的开头的,是男的就不用再输入性别了。
wfile(name, age)
else:
sex = input('性别:')
wfile(name, age, sex)

3、万能参数 *args, **kwargs
* 的魔性用法
* 的魔性用法
# 函数执行时
# *iterable 打散
# **dict 打散
可以扩展多个数字相加,就得预留多个空间。
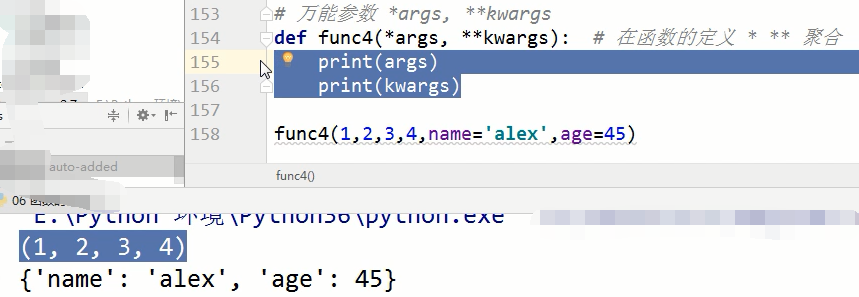
一个* 代理了把所有的位置参数1,2,3,4聚合到了一个元祖里面给了args,**是指的把所有的关键字参数,聚合到了字典里,赋值给了kwargs,前提是在函数的定义的时候。
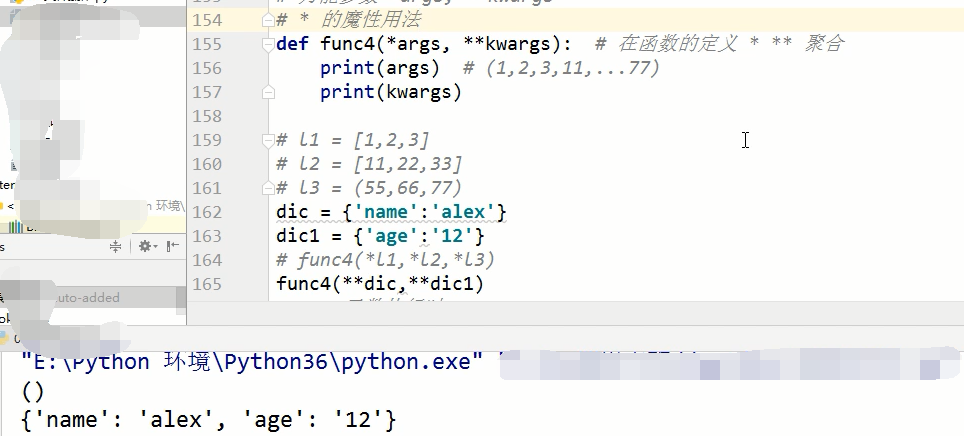
def func4(*args, **kwargs): # 在函数的定义 * ** 聚合
print(args) # (1,2,3,11,...77)
l1 = [1,2,3]
l2 = [11,22,33]
l3 = (55,66,77)
func4(*l1,*l2,*l3) #前面加上*,直接就可以变成(1,2,3,11..77)的元祖格式 *iterable *一颗星代表打撒,**两颗星也是代理打撒,操作的是字典

def func4(*args, **kwargs): # 在函数的定义 * ** 聚合 print(kwargs) dic = {'name':'alex'} dic1 = {'age':'12'} func4(**dic,**dic1)

形参角度:所有参数的顺序 位置参数---->*args----->默认参数---->**kwargs
def func5(a,b,*args,sex='男'): print(a) print(b) print(sex) print(args) # func5(1,2,4,5,6,7,8,9) def func5(a,b,*args,sex='男',**kwargs,): print(a) print(b) print(sex) print(args) func5(1,2,4,5,6,7,8,9,sex='女')
