阅读目录:
- 1.LINQ简述
- 2.LINQ优雅前奏的音符
- 2.1.隐式类型 (由编辑器自动根据表达式推断出对象的最终类型)
- 2.2.对象初始化器 (简化了对象的创建及初始化的过程)
- 2.3.Lambda表达式 (对匿名方法的改进,加入了委托签名的类型推断并很好的与表达式树的结合)
- 2.4.扩展方法 (允许在不修改类型的内部代码的情况下为类型添加独立的行为)
- 2.5.匿名类型 (由对象初始化器推断得出的类型,该类型在编译后自动创建)
- 2.6.表达式目录树(用数据结构表示程序逻辑代码)
- 3.LINQ框架的主要设计模型
- 3.1.链式设计模式(以流水线般的链接方式设计系统逻辑)
- 3.2.链式查询方法(逐步加工查询表达式中的每一个工作点)
- 4.LINQ框架的核心设计原理
- 4.1.托管语言之上的语言(LINQ查询表达式)
- 4.2.托管语言构造的基础(LINQ依附通用接口与查询操作符对应的方法对接)
- 4.3.深入IEnumerable、IEnumerable<T>、Enumerable(LINQ to Object框架的入口)
- 4.4.深入IQueryable、IQueryable<T>、Queryable(LINQ to Provider框架的入口)
- 4.5.LINQ针对不同数据源的查询接口
- 5.动态LINQ查询(动态构建Expression<T>表达式树)
- 6.DLR动态语言运行时(基于CLR之上的动态语言运行时)
1】.LINQ简述
LINQ简称语言集成查询,设计的目的是为了解决在.NET平台上进行统一的数据查询。
微软最初的设计目的是为了解决对象/关系映射的解决方案,通过简单的使用类似T-SQL的语法进行数据实体的查询和操作。不过好的东西最终都能良性的发展演化,变成了如今.NET平台上强大的统一数据源查询接口。
我们可以使用LINQ查询内存中的对象(LINQ to Object)、数据库(LINQ to SQL)、XML文档(LINQ to XML),还有更多的自定义数据源。
使用LINQ查询自定义的数据源需要借助LINQ框架为我们提供的IQueryable、IQueryProvider两个重量级接口。后面的文章将讲解到,这里先了解一下。
在LINQ未出现之前,我们需要掌握很多针对不同数据源查询的接口技术,对于OBJECT集合我们需要进行重复而枯燥的循环迭代。对于数据库我们需要使用诸多T-SQL\PL-SQL之类的数据库查询语言。对于XML我们需要使用XMLDOM编程接口或者XPATH之类的东西,需要我们掌握的东西太多太多,即费力又容易忘。
那么LINQ是如何做到对不同的数据源进行统一的访问呢?它的优雅不是一天两天就修来的,归根到底还得感谢C#的设计师们,是他们让C#能如此完美的演变,最终造就LINQ的优雅。
下面我们来通过观察C#的每一次演化,到底在哪里造就了LINQ的优雅前奏。
2】.LINQ优雅前奏的音符
-
2.1.隐式类型(由编辑器自动根据表达式推断出对象的最终类型)
隐式类型其实是编辑器玩的语法糖而已,但是它在很大程度上方便了我们编码。熟悉JS的朋友对隐式类型不会陌生,但是JS中的隐式类型与这里的C#隐式类型是有很大区别的。尽管在语法上是一样的都是通过var关键字进行定义,但是彼此最终的运行效果是截然不同。
JS是基于动态类型系统设计原理设计的,而C#是基于静态类型系统设计的,两者在设计原理上就不一样,到最后的运行时更不同。
这里顺便推荐一本C#方面比较深入的书籍《深入解析C#》,想深入学习C#的朋友可以看看。这书有两版,第二版是我们熟悉的姚琪琳大哥翻译的很不错。借此谢谢姚哥为我们翻译这么好的一本书。这本书很详细的讲解了C#的发展史,包括很多设计的历史渊源。来自大师的手笔,非常具有学习参考价值,不可多得的好书。
我们通过一个简短的小示例来快速的结束本小节。
 View Code
View Code

1 List<Order> OrderList = new List<Order>() 2 { 3 new Order(){ Count=1}, 4 new Order(){ Count=2}, 5 new Order(){ Count=3} 6 }; 7 foreach (Order order in OrderList) 8 { 9 Console.WriteLine(order.Count); 10 }
这里我定义了一个List<Order>对象并且初始化了几个值,然后通过foreach迭代数据子项。其实这种写法很正常,也很容易理解。但是从C#3起加入了var关键字,编辑器对var关键字进行了自动分析类型的支持,请看下面代码。
View Code
1 var OrderList = new List<Order>() 2 { 3 new Order(){ Count=1}, 4 new Order(){ Count=2}, 5 new Order(){ Count=3} 6 }; 7 foreach (var order in OrderList) 8 { 9 Console.WriteLine(order.Count); 10 }
编辑器可以智能的分析出我们定义是什么类型,换句话说在很多时候我们确实需要编辑器帮我们在编译时确定对象类型。这在LINQ中很常见,在你编写LINQ查询表达式时,你人为的去判断对象要返回的类型是很不现实的,但是由编译器来自动的根据语法规则进行分析就很理想化了。由于LINQ依赖于扩展方法,进行链式查询,所以类型在编写时是无法确定的。后面的文章将详细的讲解到,这里先了解一下。
-
2.2.对象初始化器(简化了对象的创建及初始化的过程)
其实对象初始化器是一个简单的语法改进,目的还是为了方便我们进行对象的构造。(所谓万事俱备只欠东风,这个东风就是LINQ的方案。所以必须得先万事俱备才行。)
那么对象初始化器到底有没有多大的用处?我们还是先来目睹一下它的语法到底如何。
View Code
1 var order = new Order() { Count = 10, OrderId = "123", OrderName = "采购单" };//属性初始化 2 3 var OrderList = new List<Order>() 4 { 5 new Order(){ Count=1, OrderId="1",OrderName="采购单"}, 6 new Order(){ Count=2, OrderId="2",OrderName="采购单"}, 7 new Order(){ Count=3, OrderId="3",OrderName="采购单"} 8 };//集合初始化
注意:对象初始化器只能用在属性、公共字段上。
属性初始化用这种语法编写的效果和直接用(order.Count=10;order.OrderId="123";order.OrderName="采购单";)是相等的。
集合初始化使用大括号的多行语法也很容易理解。类不具体的子对象的数据赋值是相同的。
我想对代码有追求的朋友都会很喜欢这种语法,确实很优美。
-
2.3.Lambda表达式(对匿名方法的改进,加入了委托签名的类型推断并很好的与表达式树的结合)
我想没有朋友对Lambda表达式陌生的,如果你对Lambda表达式陌生的也没关系,这里照看不误。后面再去补习一下就行了。
在LINQ的查询表达式中,到处都是Lambda造就的优雅。通过封装匿名方法来达到强类型的链式查询。
Lambda是函数式编程语言中的特性,将函数很简单的表示起来。不仅在使用时方便,查找定义也很方便。在需要的时候很简单定义就可以使用了,避免了在使用委托前先定义一个方法的繁琐。Lambda表达式与匿名委托在语法上是有区别的,当然这两者都是对匿名函数的封装。但是他们的出现是匿名委托早于Lambda。所以看上去还是Lambda显得优雅。
下面我们来看一个小示例,简单的了解一下Lambda的使用原理,最重要的是它优于匿名委托哪里?
View Code
1 /// <summary> 2 /// 按照指定的逻辑过滤数据 3 /// </summary> 4 public static IEnumerable<T> Filter<T>(IEnumerable<T> ObjectList, Func<T, bool> FilterFunc) 5 { 6 List<T> ResultList = new List<T>(); 7 foreach (var item in ObjectList) 8 { 9 if (FilterFunc(item)) 10 ResultList.Add(item); 11 } 12 return ResultList; 13 }
我们定义一个用来过滤数据的通用方法,这是个泛型方法,在使用时需要指定类型实参。方法有两个参数,第一个是要过滤的数据集合,第二个是要进行过滤的逻辑规则封装。
我们看一下调用的代码:
View Code
1 int[] Number = new int[5] { 1, 2, 3, 4, 5 }; 2 IEnumerable<int> result = Filter<int>(Number, (int item) => { return item > 3; }); 3 4 foreach (var item in result) 5 { 6 Console.WriteLine(item); 7 }
我们这里定义的逻辑规则是,只要大于3的我就把提取出来并且返回。很明显这里的(int item) => { return item > 3; }语法段就是Lambda表达式,它很方便的封装了方法的逻辑。从这点上看Lambda明显要比匿名委托强大很多,最重要的是它还支持泛型的类型推断特性。
那么什么是泛型的类型推断?
其实泛型的类型推断说简单点就是类型实参不需要我们显示的指定,编辑器可以通过分析表达式中的潜在关系自动的得出类型实参的类型。
说的有点空洞,我们还是看具体的代码比较清晰。
View Code
1 int[] Number = new int[5] { 1, 2, 3, 4, 5 }; 2 var result = Filter(Number, (int item) => { return item > 3; });
我将上面的代码修改成了不需要显示指定泛型类型实参调用,这里也是可以的。
我们在定义Filter<T>泛型方法时将Func<T,bool>泛型委托中的T定义为匿名函数的参数类型,所以在我们使用的时候需要指定出类型实参(int item)中的item来表示委托将要使用的类型参数形参。在编辑器看来我们在定义泛型方法Filter时所用的泛型占位符T也恰巧是Filter方法的形参数据类型Func<T,bool>中使用的调用参数类型,所以这里的语法分析规则能准确的推断出我们使用的同一种泛型类型实参。(这里要记住目前IDE编辑器只支持方法调用的泛型类型推断,也就是说其他方面的泛型使用是不支持隐式的类型推断,还是需要我们手动加上类型实参。)
这里顺便提一下关于延迟加载技术,延迟加载技术在集合类遍历非常有用,尤其是在LINQ中。很多时候我们对集合的处理不是实时的,也就是说我获取集合的数据不是一次性的,需要在我需要具体的某一个项的时候才让我去处理关于获取的代码。我稍微的改动了一下Filter代码:
View Code
1 /// <summary> 2 /// 按照指定的逻辑过滤数据。具有延迟加载的特性。 3 /// </summary> 4 public static IEnumerable<T> FilterByYield<T>(IEnumerable<T> ObjectList, Func<T, bool> FilterFunc) 5 { 6 foreach (var item in ObjectList) 7 { 8 if (FilterFunc(item)) 9 yield return item; 10 } 11 }
这里使用了yield关键字,使用它我们可以在方法内部形成一个自动的状态机结构。简单点讲也就是说系统会帮我们自动的实现一个继承了IEnumerable<T>接口的对象,在之前我们需要自己去实现迭代器接口成员,很费时费力而且性能不好。用这种方式定义的方法后,我们只有在遍历具体的集合时方法才会被调用,也算是一个很大的性能提升。
泛型类型推断的不足之处;
当然类型推断还存在不足的地方,这里可以顺便参见一下我们老赵大哥的一篇文章:“C#编译器对泛型方法调用作类型推断的奇怪问题”;我在实际工作中也遇到过一个很头疼问题,这里顺便跟大家分享一下。按照常理说我在泛型方法的形参里面定义一个泛型的委托,他们的形参类型都是一样的占位符,但是如果我使用带有形参的方法作为委托的参数的话是无法进行类型推断的,然后使用无参数的方法作为委托参数是完全没有问题的。然后必须使用Lambda表达式才能做正确的类型推断,如果直接将带有参数的某个方法作为委托的参数进行传递是无法进行真确的类型推断,这里我表示很不理解。贴出代码与大家讨论一下这个问题。
我定义两个方法,这两个方法没有什么意义,只是一个有参数,一个没有参数。
无参数的方法:
View Code
1 public static List<Order> GetOrderList() 2 { 3 return new List<Order>(); 4 }
有参数方法:
View Code
1 public static List<Order> GetOrderListByModel(Order model) 2 { 3 return new List<Order>(); 4 }
Order对象只是一个类型,这里没有什么特别意义。
两个带有Func委托的方法,用来演示泛型的类型推断:
View Code
1 public static TResult GetModelList<TResult>(Func<TResult> GetFunc) 2 { 3 return default(TResult); 4 } 5 public static TResult GetModelList<TSource, TResult>(Func<TSource, TResult> GetFunc) 6 { 7 return default(TResult); 8 }
这里的问题是,如果我使用GetOrderList方法作为GetModelList<TResult>(Func<TResult> GetFunc)泛型方法的参数是没有任何问题的,编辑器能真确的推断出泛型的类型。但是如果我使用GetOrderListByModel作为GetModelList<TSource, TResult>(Func<TSource, TResult> GetFunc)重载版本的泛型方法时就不能真确的推断出类型。其实这里的Func中的TResult已经是方法的返回类型,TSource也是方法的参数类型,按道理是完全可以进行类型推断的。可是我尝试了很多种方式就是过不起。奇怪的是如果我使用带有参数和返回类型的Lambda表达式作为GetModelList<TSource, TResult>(Func<TSource, TResult> GetFunc)方法的参数时就能正确的类型推断。
方法调用的图例:

在图的第二行代码中,就是使用才有参数的方法调用GetModelList方法,无法进行真确的类型推断。
小结:按照这个分析,似乎对于方法的泛型类型推断只限于Lambda表达式?如果不是为什么多了参数就无法进行类型推断?我们先留着这个疑问等待答案吧;
-
2.4.扩展方法(允许在不修改类型的内部代码的情况下为类型添加独立的行为)
扩展方法的本意在于不修改对象内部代码的情况下对对象进行添加行为。这种方便性大大提高了我们对程序的扩展性,虽这小小的扩展性在代码上来看不微不足道,但是如果使用巧妙的话将发挥很大的作用。扩展方法对LINQ的支撑非常重要,很多对象原本构建与.NET2.0的框架上,LINQ是.NET3.0的技术,如何在不影响原有的对象情况下对对象进行添加行为很有挑战。
那么我们利用扩展方法就可以无缝的嵌入到之前的对象内部。这样的需求在做框架设计时很常见,最为典型的是我们编写了一个.NET2.0版本的DLL文件作为客户端程序使用,那么我们有需要在服务端中对.NET2.0版本中的DLL对象加以控制。比如传统的WINFORM框架,我们可以将ORM实体作为窗体的控件数据源,让ORM实体与窗体的控件之间形成自然的映射,包括对赋值、设置值都很方便。但是这样的实体经过序列化后到达服务层,然后经过检查进入到BLL层接着进入到DAL层,这个时候ORM框架需要使用该实体作相应的数据库操作。那么我们如何使用.NET3.0的特性为ORM添加其他的行为呢?如果没有扩展方法这里就很无赖了。有了扩展方法我们可以将扩展方法构建与.NET3.0DLL中,在添加对.NET2.0DLL的友元引用,再对ORM实体进行扩展。
我们来看一个小例子,看看扩展方法如果使用;
View Code
1 public class OrderCollection 2 { 3 public List<Order> list = new List<Order>(); 4 } 5 public class Order 6 { 7 public int Count; 8 public string OrderName; 9 public string OrderId; 10 }
这里仅仅是为了演示,比较简单。我定义了一个Order类和一个OrderCollection类,目前看来OrderCollection没有任何的方法,下面我们通过添加一个扩展方法来为OrderCollection类添加一写计算方法,比如汇总、求和之类的。
如何定义扩展方法?
扩展方法必须是静态类中的静态方法,我们定义一个OrderCollection类的扩展方法Count。
View Code
1 public static class OrderExtend 2 { 3 public static int Count(this OrderCollection OrderCollectionObject) 4 { 5 return OrderCollectionObject.list.Count; 6 } 7 }
扩展方法的第一个参数必须是this 关键开头然后经跟要扩展的对象类型,然后是扩展对象在运行时的实例对象引用。如果没有实例对象的引用我想扩展方法也毫无意识。所以这里我们使用Count方法来汇总一共有多少Order对象。通过OrderCollectionObject对象引用我们就可以拿到实例化的OrderCollection对象。
View Code
1 OrderCollection orderCollection = new OrderCollection(); 2 orderCollection.Count();
还有一个需要大家注意的是,如果我们定义的扩展方法在另外的命名空间里,我们在使用的时候一定要在当前的CS代码中应用扩展方法所在的命名空间,要不然编辑器是不会去寻找你目前在使用的对象的扩展方法的,切忌。这里还有一点是需要我们注意的,当我们在设计后期可能会被扩展方法使用的对象时需要谨慎的考虑对象成员访问权限,如果我们将以后可能会被扩展方法使用的对象设计成受保护的或者私有的,那么可能会涉及到无法最大力度的控制。
-
2.5.匿名类型(由对象初始化器推断得出的类型,该类型在编译后自动创建)
匿名类型其实也是比较好理解的,顾名思义匿名类型是没有类型定义的类型。这种类型是由编辑器自动生成的,仅限于当前上下文使用。废话少说了,我们还是看例子吧;
View Code
1 var Student1 = new { Name = "王清培", Age = 24, Sex = "男", Address = "江苏淮安" }; 2 var Student2 = new { Name = "陈玉和", Age = 23, Sex = "女", Address = "江苏盐城" };
定义匿名类型跟普通的定义类型差不多,只不过在new之后是一对大括号,然后经跟着你需要使用到的属性名称和值。
匿名类型的作用域;
匿名类型在使用上是有它先天性缺点的,由于缺乏显示的类型定义,所以无法在方法之间传递匿名类型。要想获取匿名类型的各属性值只能通过反射的方式动态的获取运行时的属性对象,然后通过属性对象去获取到属性的值。匿名类型在使用的时候才会被创建类型,所以它在运行时存在着完整的对象定义元数据,所以通过反射获取数据是完全可以理解的。
下面我们使用上面定义的类型来获取它的各个属性。
View Code
1 PrintObjectProperty(Student1, Student2); 2 3 public static void PrintObjectProperty(params object[] varobject) 4 { 5 foreach (object obj in varobject) 6 { 7 foreach (System.Reflection.PropertyInfo property in obj.GetType().GetProperties()) 8 { 9 Console.WriteLine(string.Format("PropertyName:{0},PropertyValue:{1}", 10 property.Name, property.GetValue(obj, null))); 11 } 12 } 13 }
图例:
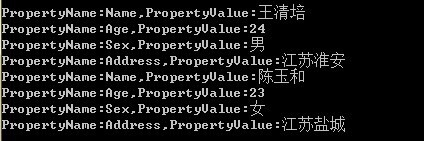
通过反射的方式我们就可以顺利的获取到匿名类型的属性成员,然后通过属性信息在顺利的获取到属性的值。
-
2.6.表达式目录树(用数据结构表示逻辑代码)
表达式目录树是LINQ中的重中之重,优雅其实就体现在这里。我们从匿名委托到Lambda拉姆达表达式在到现在的目录树,我们看到了.NET平台上的语言越来越强大。我们没有理由不去接受它的美。那么表达式目录树到底是啥东西,它的存在是为了解决什么样的问题又或者是为了什么需求而存在的?
我们上面已经讲解过关于Lambda表示式的概念,它是匿名函数的优雅编写方式。在Lambda表达式里面是关于程序逻辑的代码,这些代码经过编译器编译后就形成程序的运行时路径,根本无法作为数据结构在程序中进行操作。比如在Lambda表达式里面我编写了这样一段代码 :(Student Stu)=>Stu.Name=="王清培",那么这段代码经过编译器编译后就变成了大家耳熟能详的微软中间语言IL。那么在很多时候我们需要将它的运行特性表现为数据结果,我们需要人为的去解析它,并且转变为另外一种语言或者调用方式。那么为什么在程序里面需要这样的多此一举,不能用字符串的方式表达Lambda表达式等价的表达方式呢?这样的目的是为了保证强类型的操作,不会导致在编译时无法检查出的错误。而如果我们使用字符串的方式来表达逻辑的结构,那么我们只能在运行时才能知道它的正确性,这样的正确性是很脆弱的,不知道在什么样的情况下会出现问题。所以如果有了强类型的运行时检查我们就可以放心的使用Lambda这样的表达式,然后在需要的时候将它解析成各种各样的逻辑等式。
在.NET3.5框架的System.Linq.Expression命名空间中引入了以Expression抽象类为代表的一群用来表示表达式树的子对象集。这群对象集目的就是为了在运行时充分的表示逻辑表达式的数据含义,让我们可以很方便的获取和解析这中数据结构。为了让普通的Lambda表达式能被解析成Expression对象集数据结构,必须得借助Expression<T>泛型类型,该类型派生自LambdaExpression,它表示Lambda类型的表达式。通过将Delegate委托类型的对象作为Expression<T>中的类型形参,编辑器会自动的将Lambda表达式转换成Expression表达式目录树数据结构。我们看来例子;
View Code
1 Func<int> Func = () => 10; 2 Expression<Func<int>> Expression = () => 10;
编辑器对上述两行代码各采用了不同的处理方式,请看跟踪对象状态。

不使用Expression<T>作为委托类型的包装的话,该类型将是普通的委托类型。

如果使用了Expression<T>作为委托类型的包装的话,编译器将把它解析成继承自System.Linq.Expression.LambdaExpression类型的对象。一旦变成对象,那么一切就好办多了,我们可以通过很简单的方式获取到Expression内部的数据结构。
表达式目录树的对象模型;
上面简单的介绍了一下表达式目录树的用意和基本的原理,那么表达式目录树的继承关系或者说它的对象模型是什么样子的?我们只有理清了它的整体结构这样才能方便我们以后对它进行使用和扩展。
下面我们来分析一下它的内部结构。
(Student stu)=>stu.Name=="王清培",我定义了一个Lambda表达式,我们可以视它为一个整体的表达式。什么叫整体的表达式,就是说完全可以用一个表达式对象来表示它,这里就是我们的LambdaExpression对象。表达式目录树的本质是用对象来表达代码的逻辑结构,那么对于一个完整的Lambda表达式我们必须能够将它完全的拆开才能够进行分析,那么可以将Lambda表达式拆分成两部分,然后再分别对上一次拆开的两部分继续拆分,这样递归的拆下去就自然而然的形成一颗表达式目录树,其实也就是数据结构里面的树形结构。那么在C#里面我们很容易的构造出一个树形结构,而且这颗树充满着多态。
(Student stu)=>stu.Name="王清培",是一个什么样子的树形结构呢?我们来看一下它的运行时树形结构,然后在展开抽象的继承图看一下它是如何构造出来的。

上图中的第一个对象是Expression<T>泛型对象,通过跟踪信息可以看出,Expression<T>对象继承自LambdaExpression对象,而LambdaExpression对象又继承自Expression抽象类,而在抽象里重写了ToString方法,所以我们在看到的时候是ToString之后的字符串表示形式。
Lambda表达式对象主要有两部分组成,从左向右依次是参数和逻辑主题,也就对应着Parameters和Body两个公开属性。在Parameters是所有参数的自读列表,使用的是System.Collection.ObjectModel.ReadOnlyCollection<T>泛型对象来存储。
这里也许你已经参数疑问,貌似表达式目录树的构建真的很完美,每个细节都有指定的对象来表示。不错,在.NET3.5框架中引入了很多用来表示表达式树逻辑节点的对象。这些对象都是直接或间接的继承自Expression抽象类,该类表示抽象的表达式节点。我们都知道表达式节点各种各样,需要具体化后才能直接使用。所以在基类Expression中只有两个属性,一个是public ExpressionType NodeType { get; },表示当前表达式节点的类型,还有另外一个public Type Type { get; },表示当前表达式的静态类型。何为静态类型,就是说当没有变成表达式目录树的时候是什么类型,具体点讲也就是委托类型。因为在委托类型被Expression<T>泛型包装后,编译器是把它自动的编译成表达式树的数据结构类型,所以这里需要保存下当前节点的真实类型以备将来使用。
小结:到了这里其实已经把LINQ的一些准备工作讲完了,从一系列的语法增强到.NET5.0的类库的添加,已经为后面的LINQ的到来铺好了道路。下面的几个小结将是最精彩的时刻,请不要错过哦。
作者:王清培
出处:http://www.cnblogs.com/wangiqngpei557/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。