创建外键约束:
新建表添加外键约束:
[CONSTRAINT] [外键约束名称] FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名)
已有表添加外键约束:
ALTER TABLE 从表 ADD [CONSTRAINT] [外键约束名称] FOREIGN KEY (外键字段名) REFERENCES 主表(主 键字段名);
代码示例:
-- 先删除 employee表 DROP TABLE employee; -- 重新创建 employee表,添加外键约束 CREATE TABLE employee( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), age INT, dept_id INT, -- 添加外键约束 CONSTRAINT emp_dept_fk FOREIGN KEY(dept_id) REFERENCES department(id) );
ALTER TABLE employee ADD FOREIGN KEY (dept_id) REFERENCES department (id);
删除外键约束:
alter table 从表 drop foreign key 外键约束名称
删除外键示例:
-- 删除employee 表中的外键约束,外键约束名 emp_dept_fk ALTER TABLE employee DROP FOREIGN KEY emp_dept_fk;
级联删除操作:
现删除主表数据的同时,也删除掉从表数据。
-- 重新创建添加级联操作 CREATE TABLE employee( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), age INT, dept_id INT, CONSTRAINT emp_dept_fk FOREIGN KEY(dept_id) REFERENCES department(id) -- 添加级联删除 ON DELETE CASCADE );
内连接查询:
隐式内连接查询:
SELECT 字段名 FROM 左表, 右表 WHERE 连接条件;
# 隐式内连接 SELECT * FROM products,category WHERE category_id = cid
显式内连接查询:
SELECT 字段名 FROM 左表 [INNER] JOIN 右表 ON 条件 -- inner 可以省略
# 显式内连接查询 SELECT * FROM products p INNER JOIN category c ON p.category_id = c.cid;
外连接查询:
左外连接查询:
左外连接的特点 :
- 以左表为基准, 匹配右边表中的数据
- 如果匹配的上,就展示匹配到的数据
- 如果匹配不到, 左表中的数据正常展示, 右边的展示为null.
SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件
-- 左外连接查询 SELECT * FROM category c LEFT JOIN products p ON c.`cid`= p.`category_id`;
右外连接查询:
右外连接的特点:
- 以右表为基准,匹配左边表中的数据
- 如果能匹配到,展示匹配到的数据
- 如果匹配不到,右表中的数据正常展示, 左边展示为null
SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件
-- 右外连接查询 SELECT * FROM products p RIGHT JOIN category c ON p.`category_id` = c.`cid`;
子查询:
子查询概念:
- 一条select 查询语句的结果, 作为另一条 select 语句的一部分
子查询的特点:
- 子查询必须放在小括号中 子查询一般作为父查询的查询条件使用
子查询常见分类:
- where型 子查询: 将子查询的结果, 作为父查询的比较条件
- from型 子查询 : 将子查询的结果, 作为 一张表,提供给父层查询使用
- exists型 子查询: 子查询的结果是单列多行, 类似一个数组, 父层查询使用 IN 函数 ,包含子查 询的结果
子查询的结果作为查询条件:
SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
-- 将最高价格作为条件,获取商品信息 SELECT * FROM products WHERE price = (SELECT MAX(price) FROM products);
子查询的结果作为一张表:
SELECT 查询字段 FROM (子查询)表别名 WHERE 条件;
SELECT p.`pname`, p.`price`, c.cname FROM products p -- 子查询作为一张表使用时 要起别名 才能访问表中字段 INNER JOIN (SELECT * FROM category) c ON p.`category_id` = c.cid WHERE p.`price` > 500;
子查询结果是单列多行:
子查询的结果类似一个数组, 父层查询使用 IN 函数 ,包含子查询的结果:
# 查询家电类 与 鞋服类下面的全部商品信息 -- 先查询出家电与鞋服类的 分类ID SELECT cid FROM category WHERE cname IN ('家电','鞋服'); -- 根据cid 查询分类下的商品信息 SELECT * FROM products WHERE category_id IN (SELECT cid FROM category WHERE cname IN ('家电','鞋服'));
子查询总结:
- 子查询如果查出的是一个字段(单列), 那就在where后面作为条件使用.
- 子查询如果查询出的是多个字段(多列), 就当做一张表使用(要起别名).
数据库三范式(空间最省):
第一范式 1NF:
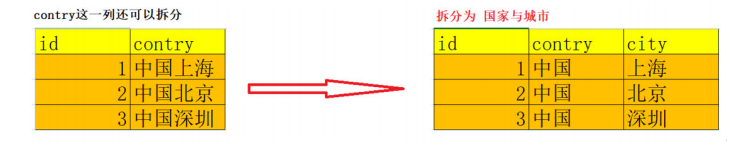
- 原子性, 做到列不可拆分 第一范式是最基本的范式。
- 数据库表里面字段都是单一属性的,不可再分, 如果数据表中每个 字段都是不可再分的最小数据单元,则满足第一范式。
第二范式 2NF:
- 在第一范式的基础上更进一步,目标是确保表中的每列都和主键相关。
- 一张表只能描述一件事.

第三范式 3NF:
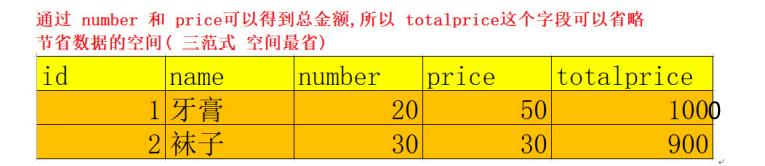
- 消除传递依赖
- 表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放
数据库反三范式:
- 反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能
- 浪费存储空间,节省查询时间 (以空间换时间)
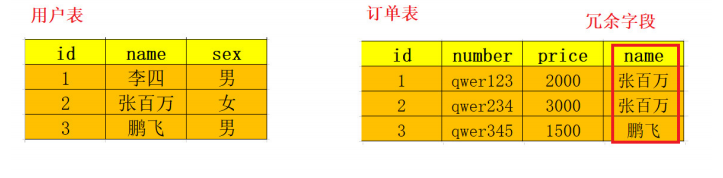
订单表有冗余字段name;
当订单有上百万数据,如果连表查询,性能较低,如果有冗余字段,可以提高效率。
总结:
创建一个关系型数据库设计,我们有两种选择
- 尽量遵循范式理论的规约,尽可能少的冗余字段,让数据库设计看起来精致、优雅、让人心 醉。
- 合理的加入冗余字段这个润滑剂,减少join,让数据库执行性能更高更快