Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet
Abstract
视觉transformers在图像分类和其他视觉任务上的强大性能通常归因于其multi-head attention层的设计。然而,注意力在多大程度上促成了这种强劲性能仍不清楚。在这篇简短的报告中,我们要问:注意力层是否真的有必要?具体来说,我们用在patch维度上的feed-forward层代替视觉transformer中的注意力层。所得到的体系结构只是在patch和特征维度上以交替方式应用的一系列feed-forward层。在ImageNet的实验中,该体系结构表现得出奇的好:一个ViT/DeiT-base-sized的模型获得了74.9%的top-1准确度,相比之下,ViT和DeiT分别获得了77.9%和79.9%的准确度。这些结果表明,除了注意力外视觉transformers的各个方面,如patch embedding,可能比之前认为的更能影响他们的性能。我们希望这些结果能促使社区花更多的时间来理解为什么我们当前的模型如此有效(https://github.com/lukemelas/do-you-even-need-attention)。
1. Introduction
由[4]引入的视觉transformers架构将一系列transformer块应用于一系列图像patches。每个块由一个multi-head注意力层[11]组成,其后跟着一个沿特征维度应用的feed-forward层(即线性层,或单层MLP)组成。这种架构的通用性质,加上它在图像分类基准上的强大性能,已经引起了视觉社区的极大兴趣。然而,仍然不清楚为什么视觉transformer是有效的。
transformer在视觉任务上成功的最主要原因是它的注意层的设计,这给了模型一个全局的接受域。这一层可以看作是一个依赖于数据的线性层,当应用于图像patches时,它类似于(但并不完全等同于)卷积。事实上,最近有大量的工作致力于提高注意力层的效率和效能。
在这篇简短的报告中,我们进行了一个实验,希望能解释一下为什么视觉转换器在一开始工作得那么好。具体来说,我们将注意力从视觉transformer上移开,取而代之的是在patch维度上应用feed-forward层。在此更改之后,模型就是在patch和特征维度上以交替的方式应用的一系列feed-forward层(图1)。
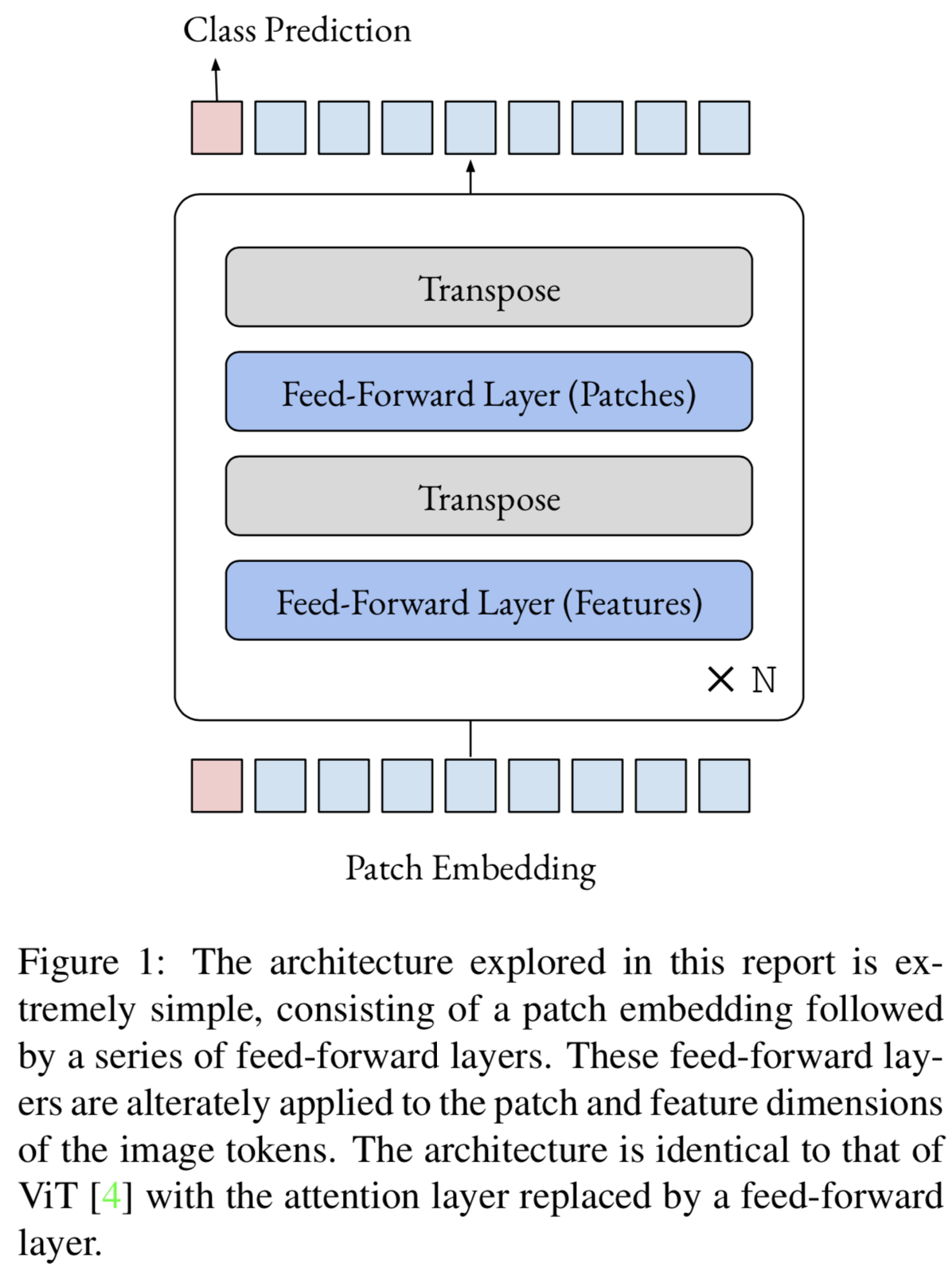
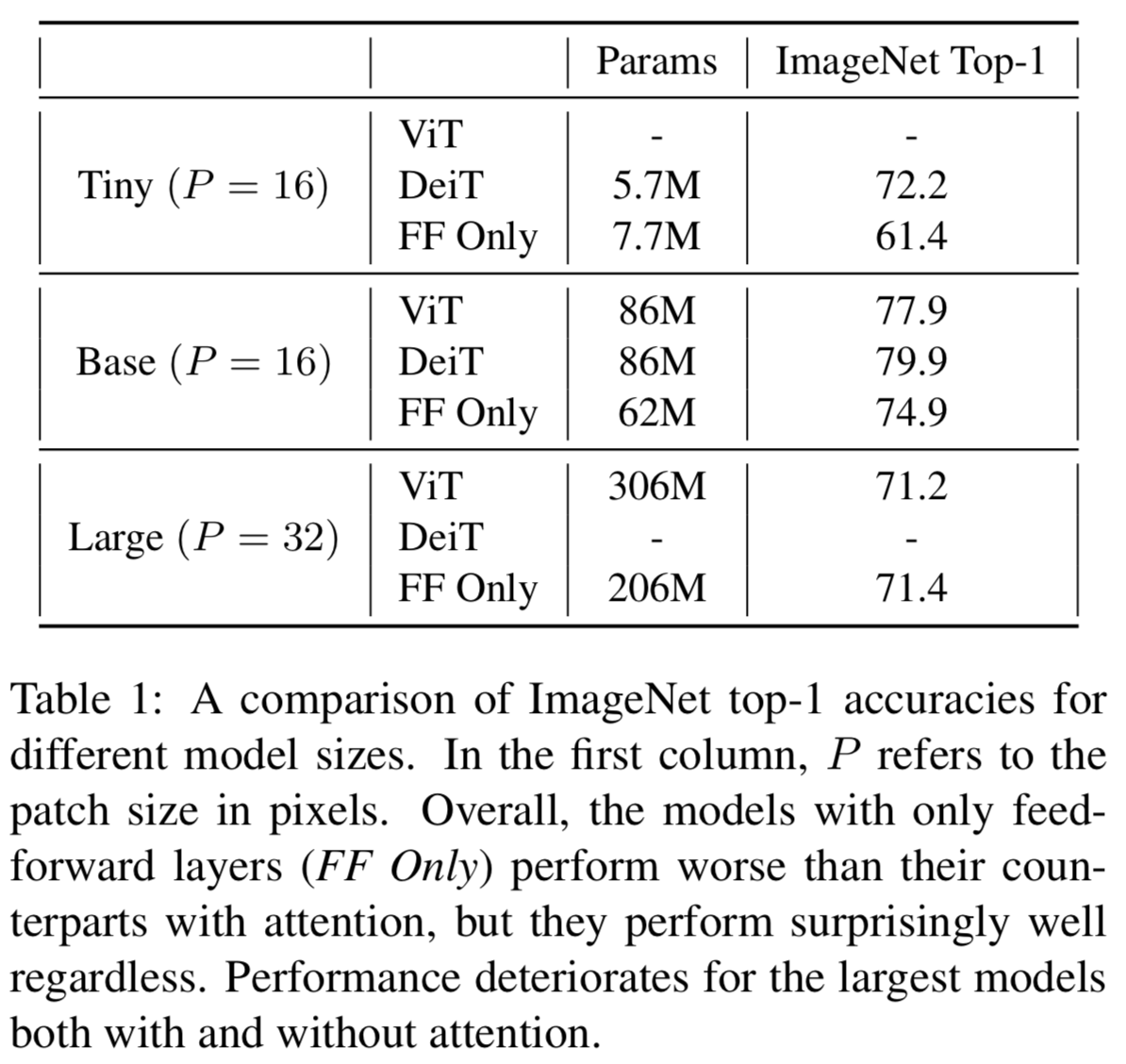
在ImageNet上进行的实验(表1)显示,即使没有注意力,也可以获得相当强的性能。值得注意的是,一个ViT-base-sized模型在没有任何超参数调优的情况下给出了74.9%的top-1准确度(即使用与ViT对照组相同的超参数)。这些结果表明,视觉transformers的较强性能可能较少归因于注意力机制,而更多地归因于其他因素,如patch嵌入产生的归纳偏差((inductive bias))和精心设计的训练增强集。
本报告的主要目的是探讨简单体系结构的局限性。我们的目的不是突破ImageNet基准;在这方面,神经结构搜索(如EfficientNet[8])等方法必然会表现最佳。尽管如此,我们希望社区发现这些结果有趣,并希望这些结果促使更多的研究人员调查为什么我们当前的模型如此有效。
2. Background
这份报告的背景是,在过去的几个月里,关于视觉transformer架构变体的研究出现了爆炸式增长:Deit[9]添加了蒸馏,DeepViT[14]混合了注意力头,CaiT[10]将注意层分为两个阶段,Token-to-Token ViT[13]聚合整个网络的相邻tokens,CrossViT[1]处理两个尺度的patches,PiT[6]添加池化层,LeViT[5]使用了卷积嵌入和改进的注意力/归一化层,CvT[12]在注意力层使用了depthwise卷积,Swin/Twins[2, 7]结合了全局和局部注意力,这只是其中的一些。
这些工作改进了视觉transformer的架构,每一个都在ImageNet上显示了强大的性能。然而,目前尚不清楚ViT的不同部分或它的许多变体如何对每个模型的最终性能作出贡献。本报告详细介绍了一个实验,该实验调查了这个问题的一个方面,即注意力层对ViT的成功有多重要。
3. Method and Experiments
3.1. Do You Even Need Attention?
我们将注意力层从ViT模型中移除,取而代之的是patch维度上的一个简单feed-forward层。我们在特征维数上使用与标准feed-forward网络相同的结构,也就是说我们将patch维数投影到高维空间,应用非线性,然后将其投影回原始空间。图2给出了feed-forward-only transformer的单个块的PyTorch代码。
我们应该注意到,就像视觉transformer及其许多变体一样,这种feed-forward-only网络与卷积网络非常相似。事实上,patch维度上的feed-forward层可以被看作是一种不同寻常的卷积类型,其具有一个完整的接受域和一个单一channel。由于特征维度上的feed-forward层可以看作是一个1x1的卷积,所以从技术上说,整个网络是一种伪装的卷积网络。话虽如此,它在结构上更像一个transformer,而不是传统设计的卷积网络(例如ResNet/VGG)。

3.2. Experimental Setup
我们使用DeiT[9]的设置在ImageNet[3]上训练三个模型,分别对应ViT/DeiT小型(tiny)网络、基础(base)网络和大型(large)网络。小型网络和基础网络的patch大小为16,而大型网络由于计算限制,patch大小为32。训练和评估的分辨率为224像素。值得注意的是,我们对所有模型都使用与DeiT完全相同的超参数,这意味着我们的性能很可能通过超参数调优得到改善。
3.3. Results
表1显示了ImageNet上简单feed-forward网络的性能。最值得注意的是,feed-forward-only版本的ViT/Deit-base实现了惊人的强大性能(74.9%的top-1 准确度),可以与一些较老的卷积网络(如VGG-16, ResNet-34)相媲美。这样的比较并不完全公平,因为feed-forward模型使用了更强的训练增强方法,但从绝对意义上来说,它仍然是一个相当强的结果。
对于大型模型,无论是有注意力还是没有注意力,性能都会下降,分别获得71.2%和71.4%的top-1准确度。正如[4]中详细介绍的,对于这样庞大的模型,使用更大的数据集进行预训练似乎是必要的。
3.4. Do You Even Need Feed-Forward Layers?
自然地,由于我们尝试了只使用feed-forward层来训练模型,我们也尝试了只使用注意力层来训练模型。在这个模型中,我们简单地将特征维度上的feed-forward层替换为特征维度上的注意力层。我们只实验了一个tiny-sized的模型(4.0M参数),但它表现得非常糟糕(100个epochs后得到28.2%的top-1准确度结果,此时我们结束了实验)。
3.5. Discussion
上述实验表明,在没有注意层的情况下,可以训练出相当强的transformer-style图像分类器。此外,没有feed-forward层的注意力层似乎不会产生类似的强大性能。这些结果表明,ViT的强大性能可能更多地归因于其patch嵌入和训练过程,而不是注意力层的设计。特别是patch嵌入提供了一个很强的归纳偏差(inductive bias),这可能是模型强大性能的主要驱动因素之一。
从实际的角度来看,feed-forward-only模型与视觉transformer相比有一个显著的优势,即它的复杂度相对于序列长度是线性的,而不是二次幂的。这种情况是由于应用于patches的feed-forward层的中间投影维数的大小不一定依赖于序列长度。通常中间维数被选择为输入特征数(即patches数)的倍数,在这种情况下它的模型确实是二次的,但这并不一定是必须的。
除了更糟糕的性能外,feed-forward-only模型的一个主要缺点是它只对固定长度的序列起作用(由于应用于patches的feed-forward层)。对于图像分类来说,这不是一个大问题,因为在图像分类中,图像被裁剪成标准大小,但这限制了该体系结构对其他任务的适用性。
feed-forward-only模型揭示了视觉transformer和注意力机制。未来,研究这些结论在多大程度上适用于图像领域之外的领域,比如在NLP/音频领域,将是一件有趣的事情。
3.6. Conclusion
令人惊讶的是,这篇简短的报告展示了没有注意力层的transformer-style的网络可以产生强大的图像分类器。这个方向的未来工作可以尝试更好地理解transformer体系结构的其他部分(例如,标准化层或初始化方案)的贡献。更广泛地说,我们希望这篇简短的报告能鼓励我们进一步调查为什么我们当前的模型表现得如此出色。