Project page: http://mmlab.ie.cuhk.edu.hk/projects/CDP/
Code: https://github.com/XiaohangZhan/cdp/
Consensus-Driven Propagation in Massive Unlabeled Data for Face Recognition
Abstract.
近年来,人脸识别取得了很大的进步,这主要归功于设计的高容量模型和收集到的丰富的标记数据。但是,扩展当前百万级的标识注释变得越来越难以实现。在这项工作中,我们证明了未标记人脸数据可以和标记人脸数据一样有效。在这里,我们考虑一个近似模拟真实世界场景的设置,其中未标记的数据是从无约束的环境中收集的,它们对应身份不出现在已标记的数据中。我们的主要观点是,尽管类信息不可用,但我们仍然可以通过自下而上的方式构建关系图来忠实地近似这些语义关系。为了解决这一难题,我们提出了共识驱动传播(Consensus-Driven Propagation,CDP)模块,即“committee”和“mediator”模块,通过仔细聚合多视图信息,稳健地选择正人脸对。大量实验验证了这两个模块在剔除离群值和挖掘hard正例上的有效性。在使用CDP的情况下,我们仅使用了9%的标签,在MegaFace识别挑战中获得了令人满意的78.18%的准确率,相比之下,未使用无标签数据时的正确率仅为61.78%,使用所有标签时的正确率为78.52%。
1 Introduction
现代人脸识别系统主要依赖于大容量深度神经网络结合大量标注数据去学习有效的人脸表征[26,14,21,29,11,3,32]。从CelebFaces [25] (200K张图)到MegaFace[13](470万张图),再到MS-Celeb-1M [9] (1000万张图),收集和标记的人脸数据库规模越来越大。虽然已经取得了令人印象深刻的结果,但我们现在陷入了一个困境,即在每一个百分比的准确率提高的背后,都要消耗成千上万个小时来手工标记数据。更糟糕的是,将当前注释的规模扩大到更多的身份变得越来越困难。现实中,几乎所有现有的大型人脸数据库都存在一定程度的标注噪声[5];这让我们质疑人类注释的可靠性。
为了缓解上述挑战,我们将重点从获取更多手动标签转移到利用更多未标记的数据。与大规模的身份标注不同,未标注的人脸图像非常容易获取。例如,使用一个由现成的人脸检测器提供的网络爬虫会产生大量的自然环境下的人脸图像或视频[24]。现在的关键问题是如何利用现有的大量未标记数据来提高大规模人脸识别的性能。这个问题让人想起了传统的半监督学习(SSL)[34],但在两个方面显著不同于SSL:首先,未标记的数据收集自无约束的环境,其中姿态、光照、遮挡变化非常大。在这种自然情况下,可靠地计算不同未标记样本之间的相似性是非常重要的。第二,收集的未标记数据与已有标记数据之间通常没有身份重叠。因此,流行的标签传播范式(label propagation paradigm)[35]在这里不再可行。
在这项工作中,我们研究了这一具有挑战性但有意义的半监督人脸识别问题,它可以被如下正式描述。除了一些已知人脸身份的标记数据外,我们还可以访问大量自然的未标记样本,这些样本的身份与已标记样本是不同的。我们的目标是最大限度地利用未标记的数据,以便最终的性能可以与使用所有已标记样本时的性能相比。这里的一个关键观点是,尽管未标记的数据没有为我们提供直接的语义类,但它的内部结构(可以用图表表示)实际上反映了高维人脸表征的分布。在跨任务调优[31]中也采用了使用图来反映结构的思想。利用这个图,我们可以对实例及其关系进行抽样,以建立一个辅助损失来训练我们的模型。
从嘈杂的人脸数据中找到可靠的内部结构并非易事。众所周知,由单一模型得到的表征通常容易产生偏差且对噪声敏感。为了解决上述挑战,我们采用自底向上的方法,首先通过可靠地识别正对来构造图。具体地说,我们提出了一种新的Consensus-Driven Propagation(CDP)12方法在大量无标记数据中构建图。它由两个模块组成:一个“committee”提供关于proposal对的多视图信息,另一个“mediator”收集所有信息以做出最终决定。
“committee”模块的灵感来自query-by-committee(QBC)[22],其最初是为了主动学习而提出的。与测量分歧的QBC不同,我们从committee收集同意,该committee包括一个基础模型和几个辅助模型。committee的异构性(即committee成员的模型使用不同类型的模型)揭示了对未标记数据结构的不同观点。然后,正对被选为committee成员最同意的pair实例,而不是基本模型最确信的pair实例。因此,除了简单的对之外,committee模块能够从未标记的数据中选择有意义且hard的正对,以补充从标记数据训练的模型。除了简单的投票方案,正如大多数QBC方法所实行的那样,我们还制定了一个新颖且更有效的“mediator”来汇集committee的意见。mediator是一个二进制分类器,它产生选择或不选择某对的最终决定。我们仔细设计了mediator的输入,以便它涵盖关于内部结构的分布信息。输入包括1)committee的投票结果,2)对的相似性,3)对间的局部密度。最后两个输入是在committee的所有成员和基础模型中测量的。借助“committee”模块和“mediator”模块,我们在未标记数据上构建了一个鲁棒的共识驱动图。最后,我们在图上传播伪标签,形成一个辅助任务,用无标签数据训练我们的基本模型。
综上所述,我们研究了使用大量未标记数据(超过6M张图像)进行大规模人脸识别。我们的设置非常类似于现实世界的场景,即未标记的数据是从无约束的环境中收集的,它们的身份与已标记的数据是独立的。为了解决这一难题,我们提出了consensus-driven propagation(CDP),其带有“committee”模块和“mediator”模块,通过聚合多视图信息,鲁棒地选择正对。我们表明,使用无标签数据可以补充稀缺的手工标签,以实现引人注目的结果。在consensus-driven propagation中,与完全监督的对照物 相比,我们只需使用9%的标签就可以获得类似的结果。
2 Related Work
Semi-supervised Face Recognition. 半监督学习[34,4]被提出利用大量的无标记数据,且只给定少量的标记数据。它的目标通常是通过各种方式,包括自我训练[30,19],联合训练[2,16],多视图学习[20],期望最大化[6]和基于图的方法[36],从有限的标签传播标签到整个数据集。在人脸识别方面,Roli and Marcialis[18]采用了基于PCA的分类器的自训练策略。在该研究中,使用一个初始分类器来推断未标记数据的标签,并加入标签数据集。 Zhao et al. [33]采用线性判别分析(Linear Discriminant Analysis,LDA)作为分类器,同样使用自训练来推断标签。Gao et al.[8]提出了一种基于半监督稀疏表征的方法来处理在few-shot学习上的问题,即标记的例子通常是带有令人讨厌的变量,如糟糕的照明、戴眼镜。所有上述方法都基于有标签数据和无标签数据之间共享类别集合的假设。然而,正如前面提到的,当人脸身份的数量巨大时,这种假设是不实际的。
Query-by-Committee. Query By Committee (QBC)[22]是一种依赖于多个判别模型来探索分歧的策略,从而为机器学习任务挖掘有意义的例子。Argamon-Engelson et al. [1]将QBC范式扩展到概率分类上下文中,并将其应用于自然语言处理任务。Loy et al.[15]对QBC进行了扩展,通过一个联合exploration-exploitation主动学习框架来发现未知类。这些前期作品都利用了committee的分歧来进行threshold-free选择。相反,我们利用committee的共识,并将其扩展到半监督学习场景。
3 Methodology
我们首先提供我们方法的概述。我们的方法包括三个阶段:
1) Supervised initialization - 给定小份的标签数据,以全监督的方式分开训练基础模型和committee成员。更具体来说,基础模型B和N个committee成员![]() 使用标记数据
使用标记数据![]() 学习一个从图像空间到特征空间
学习一个从图像空间到特征空间![]() 的映射。对于基础模型,该过程可表示为映射:
的映射。对于基础模型,该过程可表示为映射:![]() ;对于committee成员则是
;对于committee成员则是![]()
2)Consensus-driven propagation - CDP对无标记数据进行有价值样本的选择,并在其上进行标记猜想。框架如图1所示。我们使用第一阶段的训练模型来提取未标记数据的深度特征,并创建k-NN图。“committee”确保了图表的多样性。然后设计一个“mediator”网络,在k-NN图的局部结构中聚合不同意见以选择有意义的对。通过我们的标签传播算法,在未标记的数据上创建一个共识驱动的图,并为节点分配伪标签。
3)Joint training using labeled and unlabeled data - 最后,我们使用标记数据和伪标记数据对基础模型进行再训练。
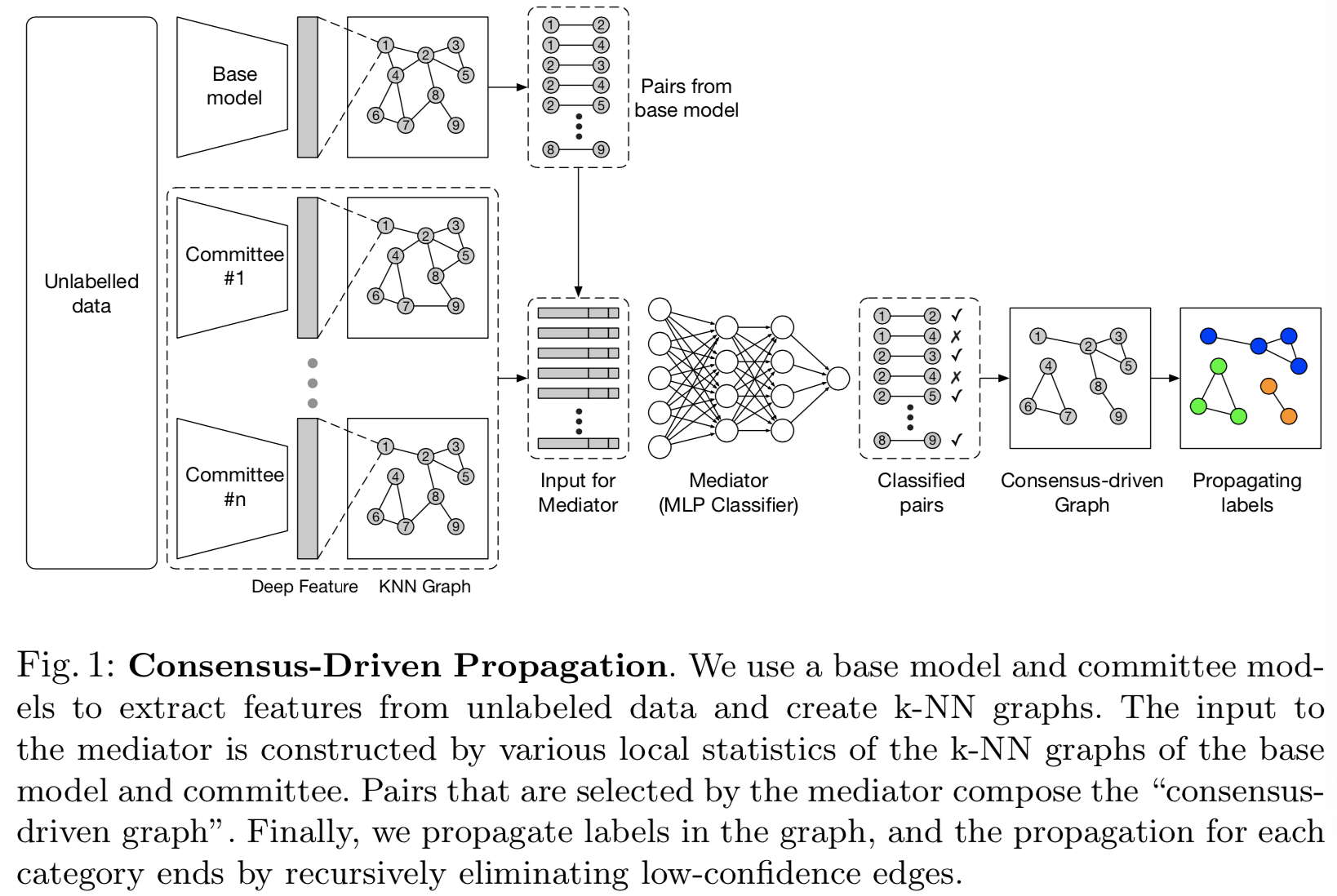
3.1 Consensus-Driven Propagation
在这节中,我们正式介绍CDP的细节
i. Building k-NN Graphs. 对于基础模型和所有committee成员,我们将无标签数据![]() 作为输入,抽取深度特征
作为输入,抽取深度特征![]() 和
和![]() 。使用该特征,通过cosine相似度去寻找
。使用该特征,通过cosine相似度去寻找![]() 中每个样本的k个最近邻。这样就得到了不同版本的k-NN图,基础模型的图是
中每个样本的k个最近邻。这样就得到了不同版本的k-NN图,基础模型的图是![]() ,committee成员的图是
,committee成员的图是![]() ,总共有N+1个图。图中的节点是无标签样本。k-NN图中的边表示两点是一个对,所有来自基础模型图
,总共有N+1个图。图中的节点是无标签样本。k-NN图中的边表示两点是一个对,所有来自基础模型图![]() 的对生成了用于后续选择的候选,可见图1。
的对生成了用于后续选择的候选,可见图1。
ii. Collecting Opinions from Committee. committee成员通过不同的映射函数![]()
![]() 将无标签数据映射到特征空间。假设任意两个在基础模型创建图中相连的点为
将无标签数据映射到特征空间。假设任意两个在基础模型创建图中相连的点为![]() 和
和![]() ,他们表示为不同的深度特征版本:
,他们表示为不同的深度特征版本:![]() 和
和![]() 。committee提供了如下的内容:
。committee提供了如下的内容:
1) The relationship, R(两个节点间)。直说,可以理解为从每个committee成员的视角看来,这两个节点是不是邻居
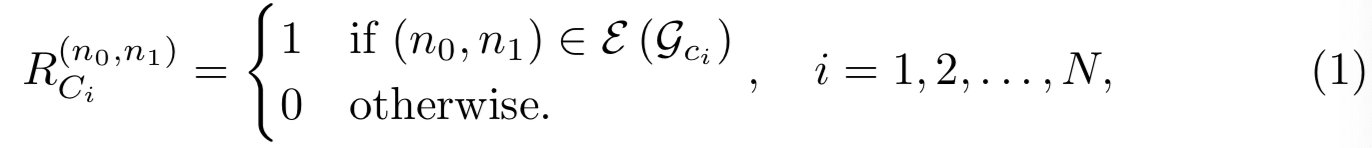
2) The affinity, A(两个节点间)。它可以用committee成员定义的映射函数来计算特征空间中的相似度。假设我们用余弦相似度作为度量,
![]()
3) The local structures w.r.t each node. 这个概念可以表示为节点一阶、二阶甚至高阶邻居的分布。其中对于一个节点来说,其一阶邻居在表示“局部结构”时是最重要的。这样的分布可以近似为节点x和其所有邻居xk(k=1,2,...,K)间相似度的分布。
![]()
如图2所示,给定从基础模型图中提取的一对节点,由于其异构性,committee成员对relationship、affinity和local structures提出了不同的意见。从这些不同的意见中,我们在下一步通过mediator来达成一致性。
iii. Aggregate Opinions via Mediator. mediator的作用是收集和传达committee成员的意见,以进行对的选择。我们将mediator定义为多层感知器(MLP)分类器,尽管其他类型的分类器也适用。回想一下,从基本模型的图中提取的所有对构成了候选对。mediator应重新权衡committee成员的意见,并通过为每一对分配一个概率来表明该对是具有相同的身份的,即是正对;还是具有不同的身份,即负对,从而做出最终决定。
每个对![]() 在mediator的输入是一个包含三个部分的串联向量(为了简化注释,将基础模型
在mediator的输入是一个包含三个部分的串联向量(为了简化注释,将基础模型![]() 表示为
表示为![]() )
)
from both base model and the committee for each node.
然后得到6N + 5维的输入向量。mediator在标记数据![]() 上训练,目标是最小化相应的交叉熵损失函数。为了检验,
上训练,目标是最小化相应的交叉熵损失函数。为了检验,![]() 对被输入到mediator中,并且那些高概率是正对的对被收集。由于大多数正对是冗余的,我们设置了一个较高的阈值来选择正对,牺牲召回率来获得高精度的正对。
对被输入到mediator中,并且那些高概率是正对的对被收集。由于大多数正对是冗余的,我们设置了一个较高的阈值来选择正对,牺牲召回率来获得高精度的正对。
iv. Pseudo Label Propagation. mediator在上一步中选择的对组成一个“共识驱动图”,其边由正对的概率加权。注意,图不需要是连通图。与传统的标签传播算法不同,我们不假设在图上有标签节点。为了准备后续的模型训练,我们根据节点的连通性传播伪标签。为了传播伪标签,我们设计了一种简单而有效的算法来识别连接组件。首先,我们根据图中当前的边找到连通的组件,并将其添加到队列中。对于每个被识别的组件,如果其节点数大于预先定义的值,我们在该组件中消除低得分边,从该组件中找到连通的组件,并将新的不相交组件添加到队列中。如果组件的节点数低于预定义的值,我们将用一个新的伪标签注释组件中的所有节点。我们迭代这个过程,直到所有符合条件的组件都被标记时 队列为空。
3.2 Joint Training using Labeled and Unlabeled Data
一旦给未标记的数据分配了伪标签,我们就可以使用它们来扩充已标记的数据并更新基础模型。由于两个数据集的身份交集未知,我们采用多任务训练的方式进行学习,如图3所示。这两个任务的CNN架构与基础模型完全相同,且权重共享。两个CNN后面都有一个全连接层(就是不共享的是全连接层),将深度特征映射到各自的标签空间。总的优化目标为![]()
![]() ,其中损失
,其中损失![]() 和训练基础模型和committee成员是相同。在接下来的实验中,我们使用softmax作为我们的损失函数。但请注意,没有限制CDP使用哪一种损失。在第4.3节中,我们展示了尽管对照组使用了高级的损失函数(arcface),CDP仍然能提高性能。在该等式中,
和训练基础模型和committee成员是相同。在接下来的实验中,我们使用softmax作为我们的损失函数。但请注意,没有限制CDP使用哪一种损失。在第4.3节中,我们展示了尽管对照组使用了高级的损失函数(arcface),CDP仍然能提高性能。在该等式中,![]() 表示有标签数据,
表示有标签数据,![]() 表示无标签但赋予了标签的数据。
表示无标签但赋予了标签的数据。![]() 是用来平衡两者的权重。它的值是固定的,根据已标记集合和未标记集合中图像的比例来设置。这个模型是从头开始训练的。
是用来平衡两者的权重。它的值是固定的,根据已标记集合和未标记集合中图像的比例来设置。这个模型是从头开始训练的。

4 Experiments
Training Set. MS-Celeb-1M[9]是一个大型人脸识别数据集,包含有着100K个身份的10M个训练样本。为了解决原始标注噪声,我们对官方训练集进行了清理,抓取了更多身份的图像,得到约7M幅图像,身份数为385K。我们将清理后的数据集按身份随机分成11个均匀的parts,以确保不同part之间没有身份重叠。请注意,尽管我们的实验采用了这种较困难的设置,但我们的方法可以很容易地应用于身份有重叠的设置,因为它没有对身份进行假设。在不同的parts中,其中一part视为有标签,其余10个parts视为无标签。我们还使用其中一个未标记的part作为验证集来调整超参数和进行消融研究。有标签part包含634K个图像,35012个身份。只在有标签part训练的模型作为下界(lower bound)性能。完全监督版本使用来自11个parts的所有带标签数据进行 训练。为了考察未标记数据的有效性,我们分别对未标记数据的2、4、6、8和10个parts进行了比较。
Testing Sets. MegaFace[13]是目前最大的人脸识别基准测试。它包括一个包含1M张图像的gallery集,以及一个来自FaceScrub[17]的包含3530张图像的probe集。但是FaceScrub中存在一些噪声图像,所以我们使用InsightFace(https://github.com/deepinsight/insightface/tree/master/src/megaface)提出的噪声列表进行清理。我们在MegaFace基准中采用rank-1 identification rate,即从1M大小的gallery中选择排名第1的图像,并对排名第1的命中率进行平均。IJB-A[17]是一个人脸验证基准,包含来自500个身份的5712张图像。为了评估,我们报告在false positive rate为0.001的情况下的true positive rate。
Committee Setup. 为了创建一个具有高异构性的“committee”,我们采用了流行的CNN架构,包括ResNet18 [10], ResNet34, ResNet50, ResNet101, DenseNet121 [12], VGG16 [23], Inception V3 [28], Inception-ResNet V2[27]和一个较小的NASNet-A[37]变体。在我们的实验中,committee成员数是8,同时我们也从0到8数目中探究committee成员数的选择。我们用数据的有标签数据部分训练了所有的体系结构,其性能如表1所示。还列出了参数的数量。Tiny NASNet-A在所有架构中表现出最好的性能,但使用的参数数量最少。给出了模型集成结果。根据经验,最佳的集合组合是装配四个性能最好的模型,即Tiny NASNet-A, Inception-ResNet V2, DenseNet121, ResNet101,在两个基准上分别得到68.86%和76.97%的结果。我们选择Tiny NASNet-A作为我们的基础架构,其他8个模型作为committee成员。下面的实验表明,即使“committee”的成员比基础架构要弱,它也能起到帮助作用。在第4.3节中,我们还展示了通过切换基本架构,我们的方法是具有广泛适用性的。
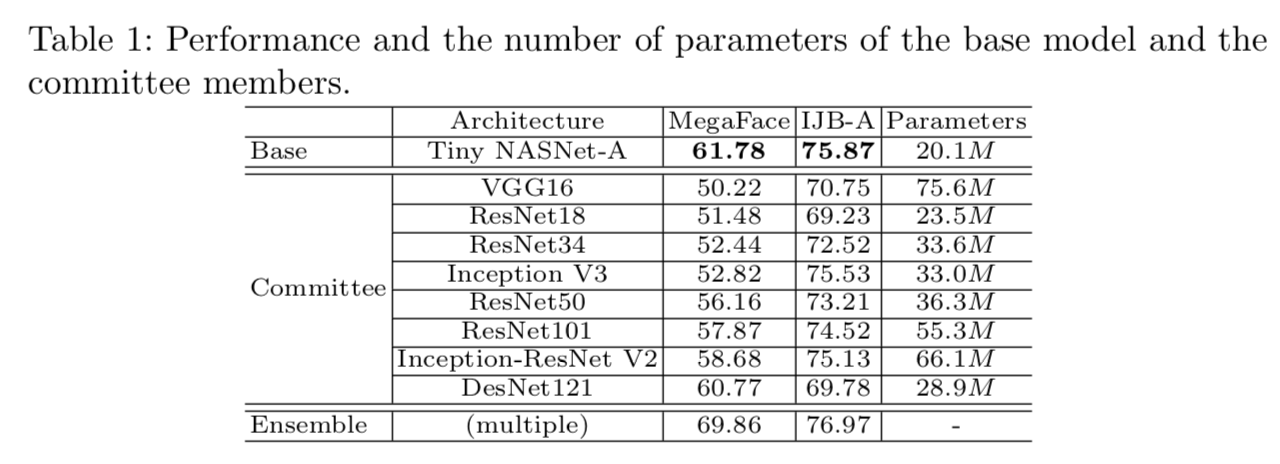
Implementation Details. “mediator”是一个MLP分类器,有2个隐藏层,每个层包含50个节点。它使用ReLU作为激活函数。在测试时,我们设置概率阈值为0.96,以选择高置信对。更多细节可在补充材料中找到。
4.1 Comparisons and Results
Competing Methods. 1)Supervised deep feature extractor + Hierarchical Clustering:利用监督深度特征提取器进行层次聚类,形成强基线。与其他聚类方法相比,层次聚类是一种处理海量数据的实用方法。对聚类分配伪标签并扩充训练集。为了获得最佳性能,我们小心地使用验证集调整层次聚类的阈值,并丢弃只有单一图像的聚类。2)Pair selection by naive committee voting:如果该对是由所有committee成员投票选出的(经验上其为最佳设置)。如果一个committee成员的k-NN图中有一条边,则计算投票数。
Benchmarking. 如图4所示,所提出的CDP方法在两个基准上都取得了令人印象深刻的结果。从结果中我们可以观察到:
1)与使用标记数据训练的CDP下界(lower bound)(无标记数据与有标记数据之比为0:1)相比,在不同的无标记数据量情况下,CDP得到了显著且稳定的改善。
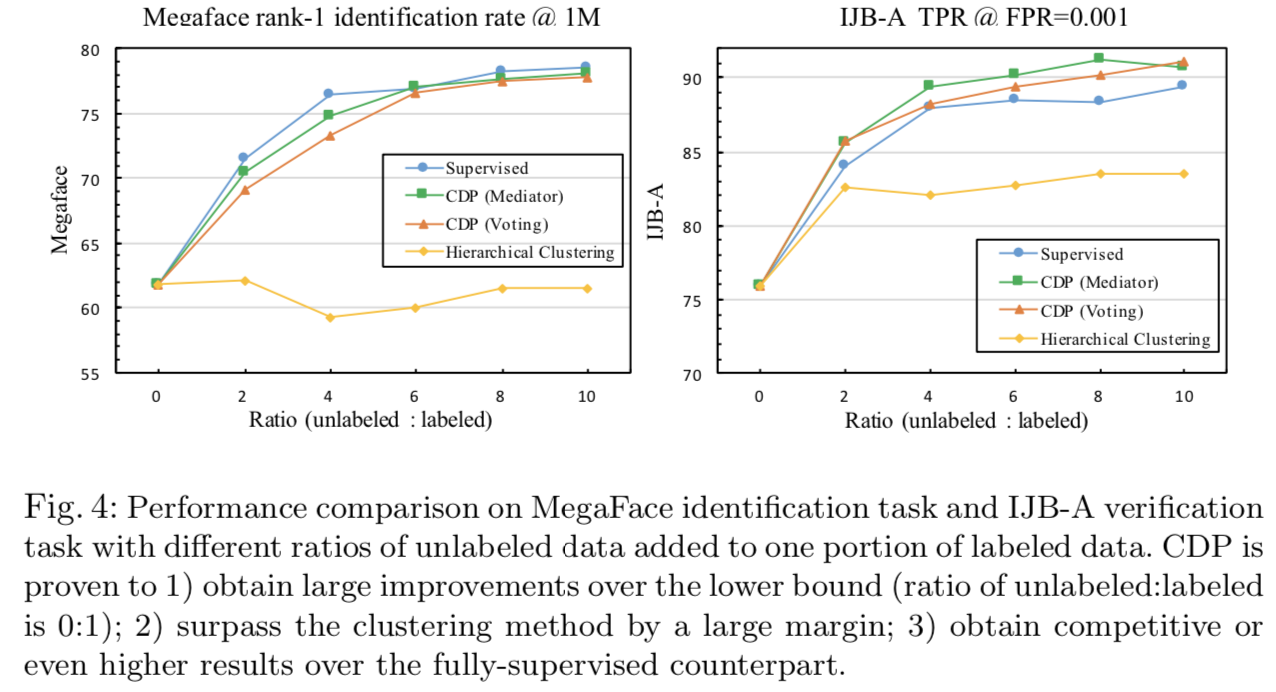
2) CDP在很大程度上超过了基线的“层次聚类”,获得了与完全监督对照组对等甚至更好的结果。在MegaFace基准测试中,添加了10倍的未标记数据,CDP的识别率为78.18%。与标注数据下界的61.78%相比,CDP得到了16.4%的改善。值得注意的是,CDP和完全监督设置之间只有0.34%的差距,达到78.52%。结果表明,CDP能够最大限度地利用未标记数据。
3)“mediator”的CDP比单纯投票的CDP表现更好,说明“mediator”更能收集committee意见。
4)在IJB-A人脸验证任务中,CDP的设置都超过了完全监督CDP的设置的效果。在完全监督基线上观察到的较差的结果表明,该任务对训练集中的噪声注释的脆弱性,如第1节所讨论的。相比之下,我们的方法对噪声更有弹性。我们接下来将根据图9对此进行讨论。

Visual Results. 我们将CDP的结果可视化在图9中。在不同背景、表情、姿势和光照条件下,CDP对身份标签的分配具有较高的准确性。此外,CDP在选择成对候选样本时具有选择性,因为它会自动丢弃1)不属于任何身份的错误注释的人脸;2)质量极低的样本,包括严重模糊和卡通图像。这就解释了为什么CDP在IJB-A人脸验证任务中表现优于完全监督基线(图4)。
4.2 Ablation Study
我们对验证组进行消融研究,以显示每个组件的增益,如表2所示。为了比较,还包括了几个指标。选择的对 较高的召回和精确度可以得到更好的共识驱动图,从而提高标签分配的质量。对于已分配的标签,pairwise召回和精度反映了标签的质量,并直接关联在两个基准上最终性能。pairwise召回越高,说明一个类别中的真例子越多,这对后续训练很重要。pairwise精度越高,类别噪声越小。
The Effectiveness of “Committee”. 当改变committee成员数量时,调整 对相似度阈值以获得固定的召回率。随着committee成员数的增加,一个有趣的观察结果是,精确度的峰值出现在数量为4的地方。但是,它并没有带来最好的质量分配标签,其出现的数字是6-8。这说明,更多的committee成员能带来更多有意义的对,而不仅仅是正确的对。这一结论与我们的假设是一致的,即相对于基本模型来说,committee能够选择更多的hard正对。
The Effectiveness of “Mediator”. 对于“mediator”,我们研究了不同输入设置的影响。仅以“relationship vector”![]() 作为输入时,这些指标的值与直接投票的值接近。“affinity vector”
作为输入时,这些指标的值与直接投票的值接近。“affinity vector”![]() 显著提高了所选对的召回和精度,同时也提高了赋值标签的pairwise召回和精度。“neighbors distribution vector”
显著提高了所选对的召回和精度,同时也提高了赋值标签的pairwise召回和精度。“neighbors distribution vector”![]() 和
和![]() 进一步提高了分配标签的质量。这种改进源于信息的这些方面所带来的效果,因此“mediator”比单纯投票方法表现得更好。
进一步提高了分配标签的质量。这种改进源于信息的这些方面所带来的效果,因此“mediator”比单纯投票方法表现得更好。
4.3 Further Analysis
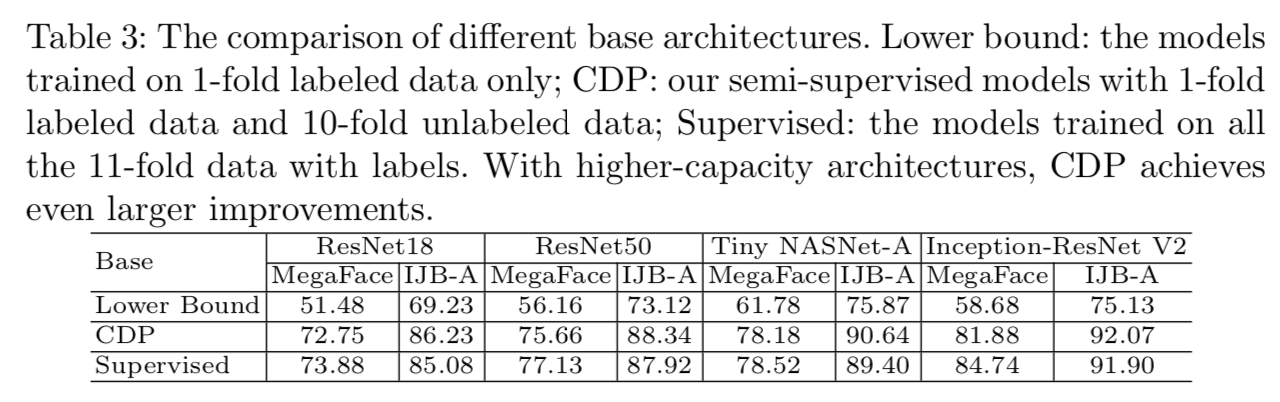
Different Base Architectures. 在之前的实验中,我们选择了Tiny NASNet-A作为基本模型,其他架构作为committee成员。为了研究基本模型的影响,这里我们将基本模型分别切换为ResNet18、ResNet50、Inception-ResNet V2,并在表3中列出了它们的性能。我们观察到所有基础架构相对于其下界都有了一致且较大的改进。具体来说,在高容量的Inception-ResNet V2中,我们的CDP在MegaFace和IJB-A基准上分别实现了81.88%和92.07%的效果,性能提高了23.20%和16.94%。考虑到CDP使用了与下界相同数量的标签数据(占所有标签的9%),这是很重要的。我们的性能也远远高于基础模型和committee的集成,这表明CDP实际上利用了未标记数据的内在结构来学习有效的表征。
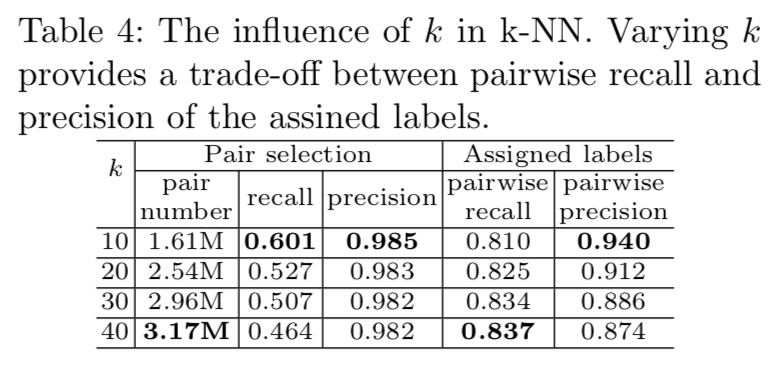
Different k in k-NN. 这里我们考察了k在k-NN中的作用。在这个可比性研究中,正对的概率阈值固定为0.96。如表4所示,k越高,被选择的对越多,共识驱动图就越密集,但精度几乎没有变化。请注意,召回率下降是因为基数真对数(分母)比被选择的对数(分子)增长得更快。实际上,如果选择的对数足够多,就没有必要追求高召回率。对于已分配的标签,图越密集,pairwise召回率越高,准确率越低。因此,这是pairwise召回和通过改变k后赋值的标签的精度之间的权衡。
Committee Heterogeneity. 为了研究committee异构性(就是使用了不同的模型)的影响,我们采用同构committee结构进行实验。同构committee由8个ResNet50模型组成,这些模型采用不同的数据输入顺序进行训练,基本模型和异构设置是相同的。为了进行公平的比较,ResNet50的模型容量处于异构性committee的中间值。如表5所示,无论是通过投票还是通过“mediator”,异构committee都比同构committee表现更好。研究证实committee异构性是有益的。

Inside Mediator. 为了评估每个输入的参与程度,我们在“mediator”中可视化了第一层的权重,如图5所示。为“mediator”中第一层的50 × 53权值,其中输入通道数为53,输出通道数为50。因此,每一列表示每个输入的权重。绿色表示接近于0,蓝色表示小于0,黄色表示大于0。黄色和蓝色的值都表示对相应输入的高响应。结果表明,committee的“affinity vector”(![]() )和“neighbors distribution”的平均向量
)和“neighbors distribution”的平均向量![]() )对响应的贡献大于“relationship vector”(
)对响应的贡献大于“relationship vector”(![]() )和“neighbors distribution”的方差向量(
)和“neighbors distribution”的方差向量(![]() )。相似性比投票结果包含了更多的信息,且邻居分布的平均值直接反映了局部密度,因此该结果是合理的。
)。相似性比投票结果包含了更多的信息,且邻居分布的平均值直接反映了局部密度,因此该结果是合理的。

Incorporating Advanced Loss Functions. 我们的CDP框架兼容各种形式的损失函数。除了softmax外,我们还在CDP上配备了一个高级的损失功能,ArcFace[7],这是当前MegaFace基准的top entry。对于ArcFace相关参数,我们设置margin m = 0.5,采用输出设置“E”,即“BN-Dropout-FC-BN”。我们还使用一个更干净的训练集,以获得更高的基线。如表6所示,我们观察到CDP在这个高得多的基线之上仍然带来了很大的改进。

Efficiency and Scalability. CDP的step-by-step运行时间列出如下:对于百万级数据,图构造(k-NN搜索)在有48个处理器的CPU上需要4分钟, “committee”+“mediator” 网络推理在八个GPUs上需要2分钟,和传播在一个CPU上需要2分钟。由于我们的方法以自底向上的方式构造图,并且“committee”+“mediator” 只对局部结构进行操作,CDP的运行时间随着未标记数据的数量线性增长。因此,CDP是高效和可扩展的。
5 Conclusion
我们提出了一种新的方法,共识驱动传播(CDP),利用大量的未标记数据来提高大规模人脸识别。仅使用9%的标签,我们就能与完全监督的对手取得可相竞争的结果。本文从committee成员数量、mediator输入、基础结构和committee异构性等方面对CDP的影响进行了深入分析。考虑到这个问题带来的实际和重要的挑战,其在本文献中第一次得到了很好的解决。
Appendix
这篇论文“Consensus-Driven Propagation in Massive unlabelled Data for Face Recognition”的补充材料主要包括了CDP (Consensus-Driven Propagation)的详细实现、一些进一步的分析、更多的视觉结果以及典型的失效案例。
A Detailed Implementation
使用PyTorch来实现我们的CNN模型和“mediator”
A.1 Supervised Initialization
对于“tiny NASNet-A”,我们使用“NASNet-A-Large”(https://github.com/Cadene/pretrained-models.pytorch)的实现,保留“x_conv0”、“x_stem_0-1”、“x_cell_0-1”、“x_reduction_cell_0”、“x_cell_6-7”,同时删除其他cells。
对于基础模型的所有主干架构和committee成员,我们将最后一个“平均池化”层替换为1 × 1卷积层,然后是“全连接”层,将每张图像嵌入到256维特征向量中。然后将特征向量输入一个线性层,对每个类别产生评分。模型从头开始训练,初始化策略为“Xavier”。batch size范围为256 ~ 1536,对于不同的架构,初始学习率范围为0.5 ~ 0.1。每个batch分散在8个GPUs上。学习率在epochs 2/3.5M和3/3.5M上衰减10倍,其中M是不同架构上范围为70 ~ 50的epochs中最大的epochs数。
A.2 Consensus-Driven Propagation
我们使用NMSLIB(https://github.com/searchivarius/nmslib)进行基于余弦相似度的k-NN搜索,k设为20。
“mediator”是一个MLP分类器,有2个隐藏层,每个层包含50个节点。它以ReLU作为激活函数,以“交叉熵”损失进行二值分类。请注意,“mediator”的配置参数对最终结果影响不大,只要不是过于复杂而导致过拟合训练对。我们在标记数据上从基础模型的k-NN图中提取的8.7M个对上训练“mediator”,训练4个epoch直到收敛。初始学习率为0.05,到epoch 3结束时衰减10倍。
在测试中,我们将未标记数据的对输入训练过的“mediator”,并获得每对的概率。我们设置概率阈值为0.96,以选择高置信度对构建“基于共识的图”。
我们的标签传播算法如算法1所示:

A.3 Joint Training
在此阶段,我们为未标记数据收集已分配的标签,并以多任务方式用已标记数据和未标记数据从头开始重新训练基本模型。损失权值等于总图像在每个part中的比例。对不同比例的无标记数据进行10 ~ 21个epochs的训练(ratio = 10时为10, ratio = 2时为21),学习率调度与监督初始化时相同。
B More Analysis
B.1 One-hot Labels v.s. Soft Labels.
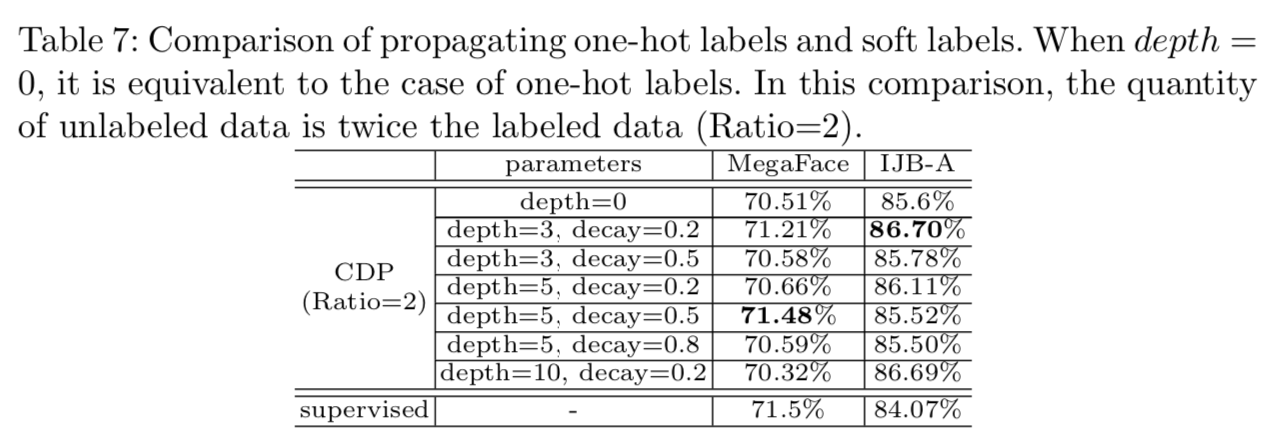
CDP中的标签传播过程非常灵活,可以适应其他标签方式。例如,它也可以传播软标签,即一个节点属于每个身份的概率向量。软标签的传播遵循一个one-hot标签的初始传播。然后,标签向量以宽度优先的方式从每个节点扩散到相邻节点,有两个超参数depth和decay,分别表示最大扩散深度和各扩散step上值的衰减比。最后在每个节点上,对身份的值进行归一化,形成一个概率向量。在实验中,我们采用“交叉熵损失”方法利用软标签进行多任务训练。如表7所示,通过适当的depth和decay组合,软标签有助于在MegaFace上提高1个点的性能,非常接近完全监督对照组的效果。
C Visual Results
图7为CDP“共识图”的部分视图。结果表明,CDP在同一类别的样本之间产生紧密的联系,而在不同类别的样本之间产生微弱的联系。这样的图便于下面的标签传播。

图8显示了5组人脸和分配的标签。对于大多数未标记数据的样本,CDP能够将属于同一人的人脸分为一组并分配相同的标签。

图9显示了4组人脸,CDP能够自动剔除噪声样本。(图在上面)
图10显示了我们的方法的典型失效案例。在某些情况下,CDP不能识别有严重遮挡的人脸和非典型人脸,甚至人类也不能轻易辨别。这是由于在标注数据中缺乏极限训练实例,因此无论是基础模型还是在标注数据上训练的committee都不能很好地处理这些情况。但是,随着基础模型和committee的不断加强,这些失效案例将得到处理,CDP的性能将不断提高。
