Cross-Domain Similarity Learning for Face Recognition in Unseen Domains
Abstract
在相同的训练和测试分布假设下训练的人脸识别模型,当面对未知的变化时,例如在测试时如果出现新的种族或不可预测的个人装扮,往往会出现泛化不良的情况。在本文中,我们引入了一种新的跨域度量学习损失,我们称之为 dub Cross-Domain Triplet (CDT)损失,以提高未知区域的人脸识别。CDT损失通过强制得到一个域的身份的紧凑特征集群去鼓励学习语义上有意义的特征,其中的紧凑性是通过属于不同统计数据的另一个训练域的潜在相似度度量来测量的。直观地说,它将来自一个域的显式度量标准与来自另一个域的triplet样本在一个统一的损失函数中有区分地关联在一起,然后进行最小化,从而能更好地将训练域对齐。在模型不可知的学习pipeline中,网络参数进一步被强制用于在域转移下学习泛化特征。不同于最近的Meta Face Recognition [18]的工作,我们的方法在训练期间不需要仔细的hard-pair样本挖掘和过滤策略。在各种人脸识别基准上的大量实验表明,与基线和最先进的方法相比,我们的方法在处理变化方面具有优势。
1. Introduction
使用深度神经网络的人脸识别在流行的评价基准上显示出了良好的结果[21,25,26,23]。目前许多方法都假设训练数据(CASIA-Webface[46]或MS-Celeb-1M[19]是广泛使用的数据)和测试数据具有相似的分布。然而,当部署到真实场景时,这些模型通常不能很好地泛化到未知统计数据的测试数据上。在人脸识别应用中,这可能意味着训练数据和评估数据之间的属性(如种族、性别或年龄)发生变化。另一方面,收集和标记更多有着代表性不足的属性的数据是很昂贵的。因此,给定现有数据,需要学习算法来产生通用的人脸表征,从而适用于各种不同的场景。
最近出现了域泛化来解决同样的挑战,但主要用于类数有限的目标分类[3,9,32]。它的目的是利用具有不同分布的多个标记源域来学习一个在测试时能很好地泛化未知目标数据的模型。然而,许多域泛化方法都是针对closed-set场景而定制的,因此,如果域的标签空间是不相交的,则不直接适用。泛化人脸识别确实是open-set应用的一个突出例子,具有非常多的类别,鼓励在这一领域的进一步研究。
在本文中,我们介绍了一种通过学习语义有意义的表征来改善未知领域的人脸识别问题的方法。为此,我们受到了最近在few-shot学习[31]、域泛化[9]和人脸识别[22]方面的工作的激励,揭示了一个普遍的事实,即在训练模型时,利用来自不同源的训练数据之间的语义一致性概念是十分有益的。因此,我们引入了基于triplet目标[36]的Cross-Domain Triplet (CDT) 损失,通过考虑两个域来学习有用的特征,其中一个域提供的相似性度量用在另一个域中去学习紧凑的身份特征集群(图1)。

这种相似性度量是通过协方差矩阵进行编码的,借鉴了[31]的思想。不同于[31],我们没有使用特定类的协方差矩阵,而是在域对齐机制中抛出问题,首先我们的模型估计了anchor和正/负样本之间的特征分布 ,即来自一个域的正/负对的相似性度量(即图1的Σ+和Σ−)。然后,我们利用这些相似度指标,并将其应用于另一个域的triplets,以学习紧凑的集群。由于理论见解和实验评估的支持,我们的CDT损失以一种有区分度的方式去对齐两个域的分布。此外,根据最近的研究[9,18],通过利用元学习框架,我们的网络参数可以在域转移下进一步学习泛化特征。
我们的实验证明了我们使用了Cross-Domain Triplet 损失方法的有效性,在使用 Cross-Ethnicity Faces (CEF) [39]和Racial Faces in-the-Wild (RFW) [44]基准数据集进行未知种族人脸识别的实际场景中,该方法始终优于目前最先进的方法。此外,经验评估表明,它可以很好地处理跨其他变化的人脸识别。
总之,我们引入了一种有效的Cross-Domain Triplet损失函数,利用一个域内存在的显式相似度度量,从另一个域学习紧凑的身份集群。这将有助于从未知领域中学习有意义的人脸识别表征。为了进一步将网络参数暴露于域偏移中,从而获得更泛化的特征,我们还将新的损失纳入模型不可知的学习pipeline中。我们的实验表明,我们提出的方法在未知域数据集的标准人脸识别方面取得了最先进的结果。
2. Related Work
Face Recognition. 随着深度神经网络的成功,近年来在人脸识别方面的研究极大地提高了性能[46,36,35,43,7,37,6],这要归功于大量可供处理的标记数据。许多损失设计在大规模网络训练中被证明是有效的,例如,CosFace[43]提出了利用余弦流形中的损失边际来挤压分类边界,ArcFace[7]将边界边际和角边际相结合来获得更好的分类效果。最近,URFace[37]提出了样本级置信度加权余弦损失和对抗性去相关损失,以得到更好的特征表征。
通常,人脸识别算法推测训练数据(如CASIA-WebFace[46]或MS-Celeb-1M[19])和测试数据遵循类似的分布。然而,最近的研究[18,39]表明,由于在实践中处理未知数据的泛化能力较差,这类系统的性能并不理想。这使得意识到测试时分布是变化的人脸识别模型更加有利。此外,在最小化分布差异时,考虑类别信息是至关重要的,以避免不同域[24]中不同类别样本的不对齐。
Meta-learning and Domain Generalization. 元学习(又称learning to learn[41])可以提高模型的泛化能力,这是一个公认的事实。起源于Model-Agnostic Meta-Learning(MAML)[16]的episodic训练方案已被广泛用于few-shot learning[40,38]、从未知的分布中识别目标的域泛化[29,3,32]和最近从未知域[18]进行人脸识别中。其基本思想是通过从可用的训练数据中创建episodic训练/测试splits来模拟训练/测试在每一轮训练中的分布差距。其他一些例子包括Model-Agnostic learning of Semantic Features (MASF)[9],它对齐一个soft混淆矩阵来保留类间关系的知识,Feature Critic Networks[32]提出了学习辅助损失来帮助泛化,而Meta-Learning Domain Generalization (MLDG)[28]通过在每批训练中合成虚域来产生域偏移。
解决未知场景的尝试要么是将现有的类方差转移到未充分表示的类[47],要么是通过各种扩展[37]学习通用特征。最近的一项研究是Meta Face Recognition(MFR)[18],它的损失是由hard样本的距离、身份分类和域中心之间的距离组成的。然而,简单地对训练域的中心进行对齐并不一定会对齐它们的分布,可能会导致不良的影响,例如,对齐来自不同域[24]的不同类样本。因此,这种损失组件并不总是能提高识别(see w/o da. rows in Asian and Caucasian sections of Table 10 in [18])。
3. Proposed Method
在这一节中,我们提出了我们的方法,通过学习语义上有意义的表征来改善未知域的人脸识别问题。为此,我们受到了近期研究的启发[31,9,22],这些研究表明,在训练模型时,利用来自不同分布的数据之间的语义一致性概念是十分有益的。我们通过强制得到一个域紧凑的身份集群来学习语义上有意义的特征,而该紧凑性是由属于不同统计数据的另一个领域的基础相似度度量来衡量的。事实上,我们提取了被编码为跨具有不同标签空间的域的相似性度量 的知识。
我们从介绍整个网络架构开始。我们的架构遵循了典型的图像/人脸识别设计。其包含了参数为![]() 的特征学习网络
的特征学习网络![]() 、参数为
、参数为![]() 的嵌入网络
的嵌入网络![]() 、参数为
、参数为![]() 的分类网络
的分类网络![]() 。遵循标准的设置[3,9,18],
。遵循标准的设置[3,9,18],![]() 和
和![]() 都是轻量级网络,即一组全连接层,以
都是轻量级网络,即一组全连接层,以![]() 的输出为输入。更具体来说,前向传播一张图
的输出为输入。更具体来说,前向传播一张图![]() 到
到![]() ,然后输出张量
,然后输出张量![]() ,经过flatten后,将其作为分类器
,经过flatten后,将其作为分类器![]() 和嵌入网络
和嵌入网络![]() 的输入。
的输入。
在深入研究更多细节之前,我们首先回顾一下我们公式中使用的一些基本概念。然后,我们说明了我们的主要贡献是从多个有着不相交的标签空间的源域中学习泛化特征。最后,我们将该解决方案合并到一个模型不可知算法中,该算法最初基于Model-Agnostic Meta-Learning (MAML)[16]。
3.1. Notation and Preliminaries
在论文中,我们使用加粗小写字母(如![]() )表示列向量,使用加粗大写字母(如
)表示列向量,使用加粗大写字母(如![]() )表示矩阵。dxd单位矩阵表示为
)表示矩阵。dxd单位矩阵表示为![]() 。使用张量
。使用张量![]() 表示k阶的多维数组,即
表示k阶的多维数组,即![]() 。
。![]() 表示
表示![]() 中在位置
中在位置![]() 的元素。
的元素。
在黎曼几何(Riemannian geometry)中,欧式空间![]() 是一个内积定义为
是一个内积定义为![]() 的黎曼流体。在
的黎曼流体。在![]() 中,
中,![]() ,Mahalanobis distances类被表示为:
,Mahalanobis distances类被表示为:

其中![]() 是一个Positive Semi-Definite (PSD) 矩阵 [27], 以特征的区域协方差矩阵为例[10,15]。当矩阵
是一个Positive Semi-Definite (PSD) 矩阵 [27], 以特征的区域协方差矩阵为例[10,15]。当矩阵![]() 趋近于
趋近于![]() 时,该距离将变为为欧式距离(L2)。Mahalanobis 度量学习的目的是确定
时,该距离将变为为欧式距离(L2)。Mahalanobis 度量学习的目的是确定![]() ,因此
,因此![]() 通过扩展或收缩
通过扩展或收缩![]() 的轴赋予某有用的特性。
的轴赋予某有用的特性。
在用于度量学习的通用深度神经网络中,在损失层(如contrastive[20]或triplet[36])前添加一个权重矩阵为![]() 的全连接层去将数据的嵌入转换一个降维空间中[12,13,36]。然后,因为
的全连接层去将数据的嵌入转换一个降维空间中[12,13,36]。然后,因为![]() 是一个PSD矩阵且可分解为
是一个PSD矩阵且可分解为![]() ,一个batch中的两个样本x和y的平方L2距离可计算为:
,一个batch中的两个样本x和y的平方L2距离可计算为:
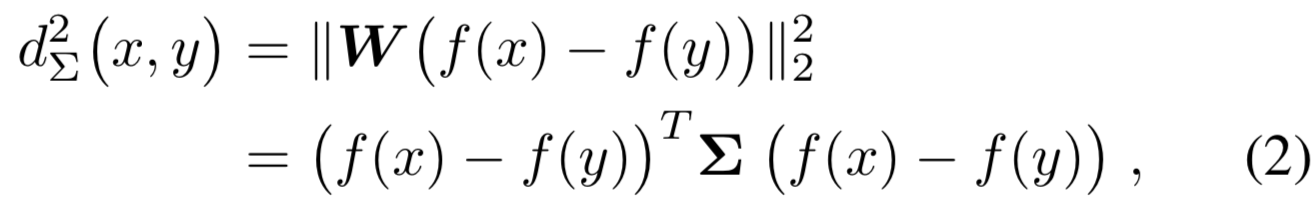
其中![]() 表示网络输入为x的输出
表示网络输入为x的输出
在本论文中,我们使用正(负)图像对来表示具有相同(不同)身份的人脸图像。此外,一个triplet(anchor、正、负)由一个anchor人脸图像、一个来自同一身份的样本和一个来自不同身份的图像组成。
3.2. Cross-Domain Similarity Learning
在这里,我们对人脸识别场景进行处理,在训练期间,我们观察k个源域,每个源域具有不同的属性,如种族。在测试时,将网络用于一个具有不同身份和属性的个体样本的新的目标域。我们将这一问题描述为在triplet损失[36]目标函数的基础上使用一种新的损失来优化网络,我们称之为dub Cross-Domain Triplet损失。Cross-Domain Triplet损失接受来自两个域![]() 和
和![]() 的输入,估计来自一个域(如
的输入,估计来自一个域(如![]() )的正负对的潜在分布,分别去测量其他域(如
)的正负对的潜在分布,分别去测量其他域(如![]() )(anchor,正)和(anchor,负)样本的距离。然后使用计算的距离和一个预先定义好的边际值,应用标准triplet损失函数。
)(anchor,正)和(anchor,负)样本的距离。然后使用计算的距离和一个预先定义好的边际值,应用标准triplet损失函数。
让![]() 表示来自第j域(
表示来自第j域(![]() )的一个batch中的
)的一个batch中的![]() 个triplets,我们能够考虑来自其的正样本
个triplets,我们能够考虑来自其的正样本![]() 。为了简化,我们省略了j上标。我们连接每个图像的所有局部描述符去通过一个协方差矩阵估计潜在分布。具体说来,我们前向传播每个正图像对(a,p),通过
。为了简化,我们省略了j上标。我们连接每个图像的所有局部描述符去通过一个协方差矩阵估计潜在分布。具体说来,我们前向传播每个正图像对(a,p),通过![]() 网络去获得特征张量表征
网络去获得特征张量表征![]() 。我们把问题放在成对差异的空间中。因此,我们定义张量
。我们把问题放在成对差异的空间中。因此,我们定义张量![]() 。接下来,我们将最终张量
。接下来,我们将最终张量![]() 展开成一个向量
展开成一个向量![]() 。这允许我们在成对差异空间中计算正对的协方差矩阵:
。这允许我们在成对差异空间中计算正对的协方差矩阵:

同样的,我们使用B个负对![]() ,我们计算每个(a,n)的
,我们计算每个(a,n)的![]() ,然后将
,然后将![]() 展开成一个向量
展开成一个向量![]() 。这样负对的协方差矩阵可定义为:
。这样负对的协方差矩阵可定义为:
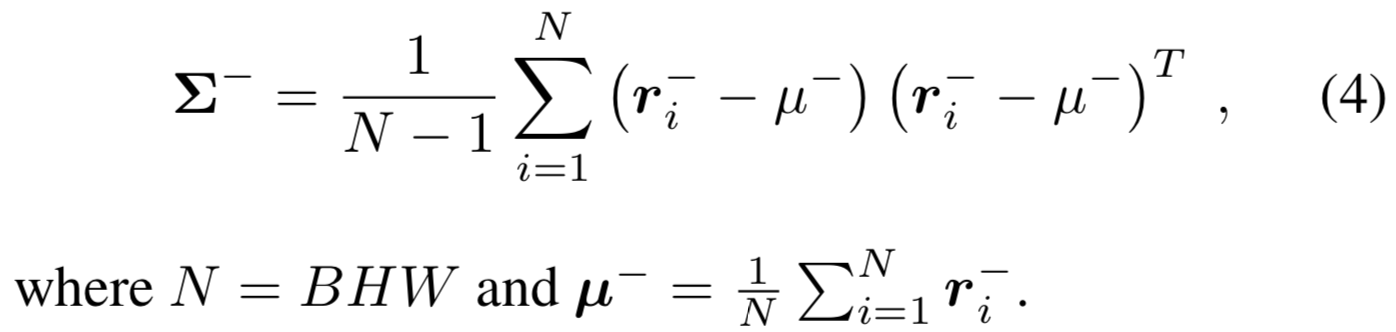
考虑到一批图像有足够的样本,由于在协方差计算中每个人脸图像都有HW个样本,因此可以得到一个有效的PSD协方差矩阵。此外,batch size大的样本可以根据[1,8]令人满意地近似得到相应的域分布。
我们的Cross-Domain Triplet损失![]() 通过利用利用定义在(2)的
通过利用利用定义在(2)的![]() 以相似的方式去实现,使用来自另一个域的相似性度量去计算样本的距离。给定来自域
以相似的方式去实现,使用来自另一个域的相似性度量去计算样本的距离。给定来自域![]() 的triplet图像
的triplet图像![]() 和使用(3)和(4)分别计算得到的来自域
和使用(3)和(4)分别计算得到的来自域![]() 的
的![]() ,该损失定义为:
,该损失定义为:

其中![]() 是预先定义好的边际值,
是预先定义好的边际值,![]() 是合页函数(hinge function)。我们利用类平衡采样为协方差和Cross-Domain Triplet损失计算提供输入,因为该采样已在长尾识别问题[18,33]中被证明能得到更有效的结果。
是合页函数(hinge function)。我们利用类平衡采样为协方差和Cross-Domain Triplet损失计算提供输入,因为该采样已在长尾识别问题[18,33]中被证明能得到更有效的结果。
Insights Behind our Method. 我们方法的重点是定义在两个有着不同分布的域上的样本的![]() 距离。如果从分布中得到
距离。如果从分布中得到![]() ,则与
,则与![]() 的乘积会根据经验协方差矩阵得到一个距离,这样对整个点的优化可以转化为对域的对齐。更具体来说,假设
的乘积会根据经验协方差矩阵得到一个距离,这样对整个点的优化可以转化为对域的对齐。更具体来说,假设![]() 为PSD,那么则存在特征分解,即
为PSD,那么则存在特征分解,即![]() 。将该项展开可得:
。将该项展开可得:
![]()
其将![]() 与被相应特征值加权的
与被相应特征值加权的![]() 的特征向量关联起来。当
的特征向量关联起来。当![]() 在经验协方差矩阵
在经验协方差矩阵![]() 的主特征向量的方向上时,该公式得到最大值。换句话说,因为
的主特征向量的方向上时,该公式得到最大值。换句话说,因为![]() 的特征向量是输入数据有着最大方差的方向,所以在r向量上最小化这一项会导致两个数据源的对齐。图2描述了我们损失的基础流程。
的特征向量是输入数据有着最大方差的方向,所以在r向量上最小化这一项会导致两个数据源的对齐。图2描述了我们损失的基础流程。

3.3. A Solution in a Model Agnostic Framework
遵循最近域泛化任务的趋势,我们在模型不可知的学习框架下使用基于梯度的meta-train/meta-test集,以进一步揭示分布转移的优化过程[9,32,18]。算法(1)总结了我们的整体训练过程。更具体地说,在每一轮训练中,我们将输入源域划分为一个meta-test,其余的作为meta-train域。我们从每个域随机抽取B个triplets来计算我们的损失。首先,我们基于分类和triplet损失的总和![]() 去计算两个协方差矩阵
去计算两个协方差矩阵![]() 和
和![]() 和临时的参数集
和临时的参数集![]() 。网络被训练为能在meta-test域表现良好的程度,因此
。网络被训练为能在meta-test域表现良好的程度,因此![]() 、
、![]() 和
和![]() 被用在meta-test域计算损失
被用在meta-test域计算损失![]() 。该损失还有额外的CDT损失
。该损失还有额外的CDT损失![]() ,其涉及用于域对齐的跨域相似度。最终,模型参数使用
,其涉及用于域对齐的跨域相似度。最终,模型参数使用![]() 和
和![]() 的累积梯度去更新,因为该更新方法被证明比原始的MAML[2,18]更有效。在这里,累积的
的累积梯度去更新,因为该更新方法被证明比原始的MAML[2,18]更有效。在这里,累积的![]() 损失提供了额外的正则化来使用高阶梯度更新模型。下面,我们提供了身份分类和triplet损失的细节。
损失提供了额外的正则化来使用高阶梯度更新模型。下面,我们提供了身份分类和triplet损失的细节。
分类训练信号对于人脸识别应用来说是十分重要的。因此,我们使用标准Large Margin Cosine Loss (LMCL) [43] 作为我们的身份分类损失,如下所示:

其中y是图像![]() 的ground truth身份,
的ground truth身份,![]() 是分类器网络,
是分类器网络,![]() 是
是![]() 中身份yi的权重向量,s是一个缩放乘数,m是边际值。
中身份yi的权重向量,s是一个缩放乘数,m是边际值。
我们进一步鼓励![]() 网络根据来自某个域的身份去学习紧凑的语义特征。最终我们使用的是triplet损失。triplet损失使用标准的L2距离函数
网络根据来自某个域的身份去学习紧凑的语义特征。最终我们使用的是triplet损失。triplet损失使用标准的L2距离函数![]() 为每个triplet提供训练信号,使a和n之间的距离比a和p之间的距离加上预定义的边际值ρ的值还要大。式子如下所示:
为每个triplet提供训练信号,使a和n之间的距离比a和p之间的距离加上预定义的边际值ρ的值还要大。式子如下所示:
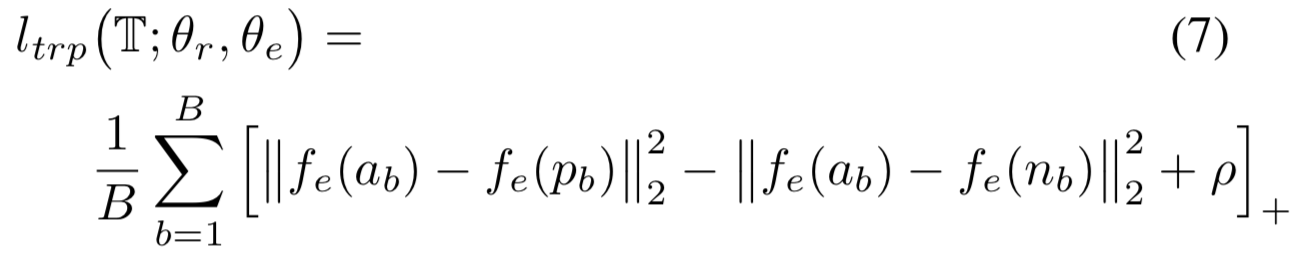
要注意的是,![]() 在计算损失前都进行了L2正则化。
在计算损失前都进行了L2正则化。![]() 操作的是
操作的是![]() 输出的表征。
输出的表征。

4. Experiments
在本部分中,为了复现模型,我们首先提供模型实现细节。在此基础上,给出了基于未知域的人脸识别实验结果。我们通过对算法的重要组成部分的消融分析来结束本节。据我们所知,Meta Face Recognition (MFR) [18]是解决同样问题的最新研究。因此,我们将我们的方法与MFR在所有评估中进行比较。我们还将CosFace[43]、Arcface[7]和URFace[37]的性能作为基线。
Implementation Details. 我们模型使用Pytorch[34]实现。我们的基线模型使用了一个最终层为一个全连接层的28层的ResNet模型,生成了一个![]() 的嵌入空间,即在测试时最终生成的特征空间。在我们的设计中,
的嵌入空间,即在测试时最终生成的特征空间。在我们的设计中,![]() 是全连接层前的backbone模型,
是全连接层前的backbone模型,![]() 接着生成对数结果,同时
接着生成对数结果,同时![]() 堆叠了一个额外的全连接层去映射输入到一个
堆叠了一个额外的全连接层去映射输入到一个![]() 低维空间。至于优化器,我们使用权重衰减为0.0005且momentum为0.9的随机梯度下降方法。在算法(1)中,batch size B设置为128,α和β设置为1e-4且每1000步衰减一半,λ设置为0.7。我们设置分类器边际值m为0.5,边际
低维空间。至于优化器,我们使用权重衰减为0.0005且momentum为0.9的随机梯度下降方法。在算法(1)中,batch size B设置为128,α和β设置为1e-4且每1000步衰减一半,λ设置为0.7。我们设置分类器边际值m为0.5,边际![]() 和ρ则设置为1。
和ρ则设置为1。
4.1. Cross Ethnicity Face Verification/Identification
作为我们的第一组实验,我们解决了从没见过的种族中识别人脸的问题。在这里,评估协议是将一个种族排除在外,即从训练集中排除某一个种族(域)的样本,然后在这个被搁置的域样本上评估模型的性能。
Datasets. 为了进行评估,目前推荐了两组用于研究人脸跨种族识别性能的数据集,即Cross-Ethnicity Faces (CEF) [39] 和Racial Faces in-the-Wild (RFW) [44]数据集。CEF数据集从MS-Celeb-1M[19]中选取,由高加索、非洲裔、东亚和南亚四种族裔图像组成。我们将最后两个集合合并为一个族域,即亚洲人。每个域有200个身份,每个身份有10张不同的图。请注意,CEF中的身份与我们用来训练模型的MS-Celeb-1M数据集是不相交的。类似地,RFW是MS-Celeb-1M数据集的另一个跨种族评估基准,该数据集有四个种族子集:高加索人、非洲人、亚洲人和印度人。CEF只有测试样本,而RFW提供跨域的训练和测试数据。
Effect of Ethnicity Bias in Trainning Data. 需要注意的是,大多数公开的人脸数据集都是通过查询名人来从网络上收集的。这导致了对白种人的显著性能偏好。例如,在MS-Celeb-1M数据集中,82%的数据是白人图像,而只有9.7%的非洲裔美国人,6.4%的东亚人和加在一起不到2%的拉丁裔和南亚人[39]。
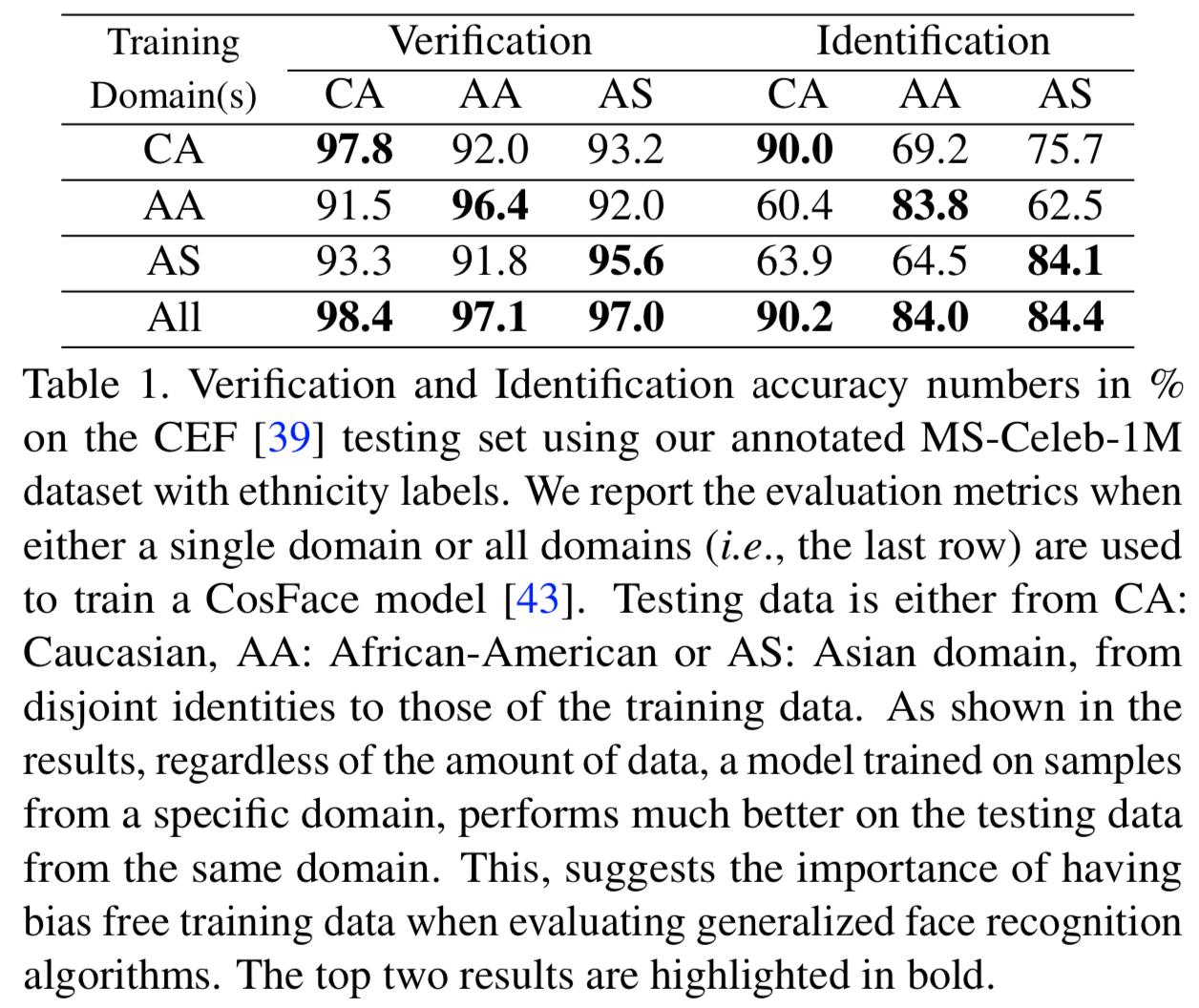
为了进一步强调种族偏好对人脸识别模型训练数据的影响,我们使用带有种族标签的注释MS-Celeb-1M数据集和CEF测试集进行了实验。为了训练模型,我们考虑了两种情况:1)只使用单个测试种族的训练样本;2)来自所有种族的所有训练样本。我们报告两个标准评估指标,即验证准确性和识别准确性。为了计算验证准确度,我们遵循[21]提出的标准协议,从中构造10个split,并报告总体平均值。每个split包含900个正对的和900个负对,每个split的准确度使用从其余9个split中找到的阈值计算。正如[39]所指出的,在人脸识别系统中,在测试时处理来自新种族的人脸图像时,识别准确度的下降幅度更大。因此,我们也报告了[39]提出的识别准确率数字。更具体地说,,如果没有其他来自不同身份的图像在距离上比查询更接近引用,那么我们认为一个引用和查询的正对是正确的(即引用图和查询图是同一个人)。
本实验结果见表1。这里可以得出几个结论。首先,结果表明,不管训练样本的数量如何, 仅在特定族群样本上训练的网络,往往在同一族群上表现得更好。第二,每一列中第二好的数字与最后一行中对应的上限非常接近(这里的“All”是指在训练过程中考虑所有种族的所有训练样本)。相比之下,identification分数下见过的域和没见过的测试域之间值的差距非常大,仅使用白种人样本)进行训练时,CA和AA之间的差距超过20%。这清楚地表明,这种偏好可能会使人脸识别系统在未知域上得出无效的结论。一项相关的研究[42]表明了训练数据中噪声对人脸识别的影响。
我们注意到,对于预训练,MFR方法利用了MS-Celeb-1M数据集,但没有从训练数据中移除目标族裔样本。正如我们在上面的实验观察和讨论,这在解决泛化人脸识别问题时造成了困难。因此,在本节中,我们采用MFR来考虑未知域的人脸识别。因此,我们首先的目标是从我们的训练数据中消除这种偏差。为此,我们在带有ground-truth族裔标签的手动标注的人脸图像上训练一个族裔分类器网络。每个种族的图像数量在5K到8K之间变化。然后,利用该网络找到数据集中每个个体的正确种族标签。这允许我们在处理跨种族人脸识别时,删除特定领域的所有已知样本。
Training Data. 为了训练我们的模型,我们使用了带种族标签注释的MS-Celeb-1M数据集。在RFW实验中,我们使用RFW训练集对模型进行进一步训练,同时遵循leave-one-ethnic-out测试协议。在每个身份只有一个训练样本的情况下,我们使用了图像的随机增强方法,以生成一个正对。[37]提出的增强方法是高斯模糊和遮挡的随机组合。由于RFW与MS-Celeb-1M具有重叠的身份,因此在MFR之后,我们首先删除这些重叠的身份样本,制作MS-C-w/o-RFW,即MS-Celeb-without-RFW数据集。
Evaluation Metrics. 在测试时,将提取的每幅图像及其翻转版本的特征向量进行串接,作为图像的最终表征。我们用余弦距离来计算距离。在性能评估方面,我们使用Receiver Operating Characteristic(ROC)曲线,报告了在不同的False Acceptance Rate(FAR)水平(0.001、0.01和0.1)下的True Acceptance Rate(TAR)。此外,我们报告了Rank-1准确性,即如果probe图像与所有gallery图像匹配后,排名第一的结果是相同的(即身份是相同的),则认为该对probe图像和gallery图像是正确的。
Results on the CEF Testing Set. 在表2中,我们将我们的结果与最先进的技术在所有四种leave-one-domain-out场景中的结果进行了比较。注意,在这里的源域中没有像印度种族那样的注释人脸图像。我们的方法,配备了 Cross-Domain Triplet 损失,优于最新的MFR方法。我们相信,这清楚地显示了我们方法的好处,它允许我们从标记的源人脸图像中学习跨域相似性,从而为没见过的域提供更好的表征。
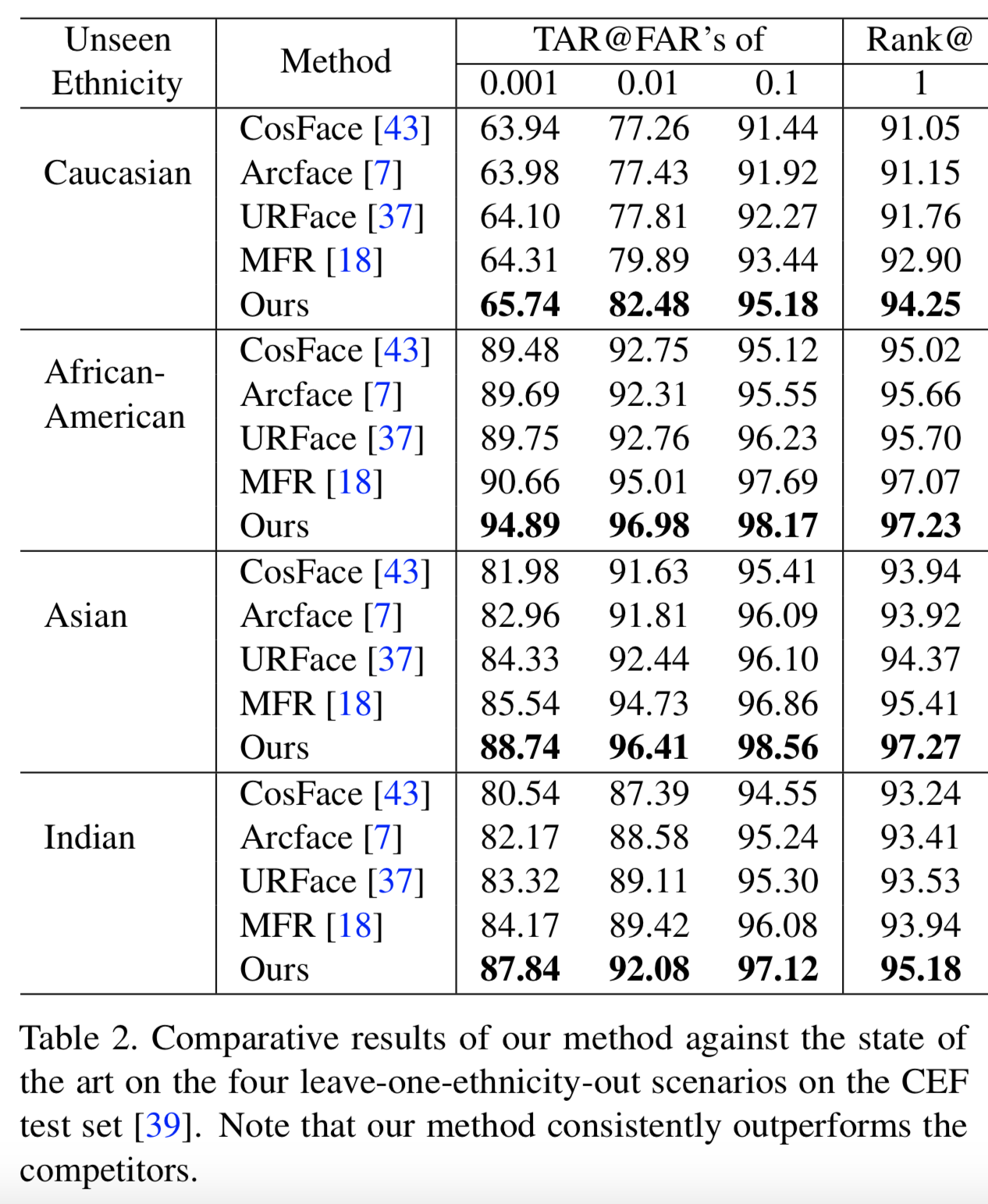
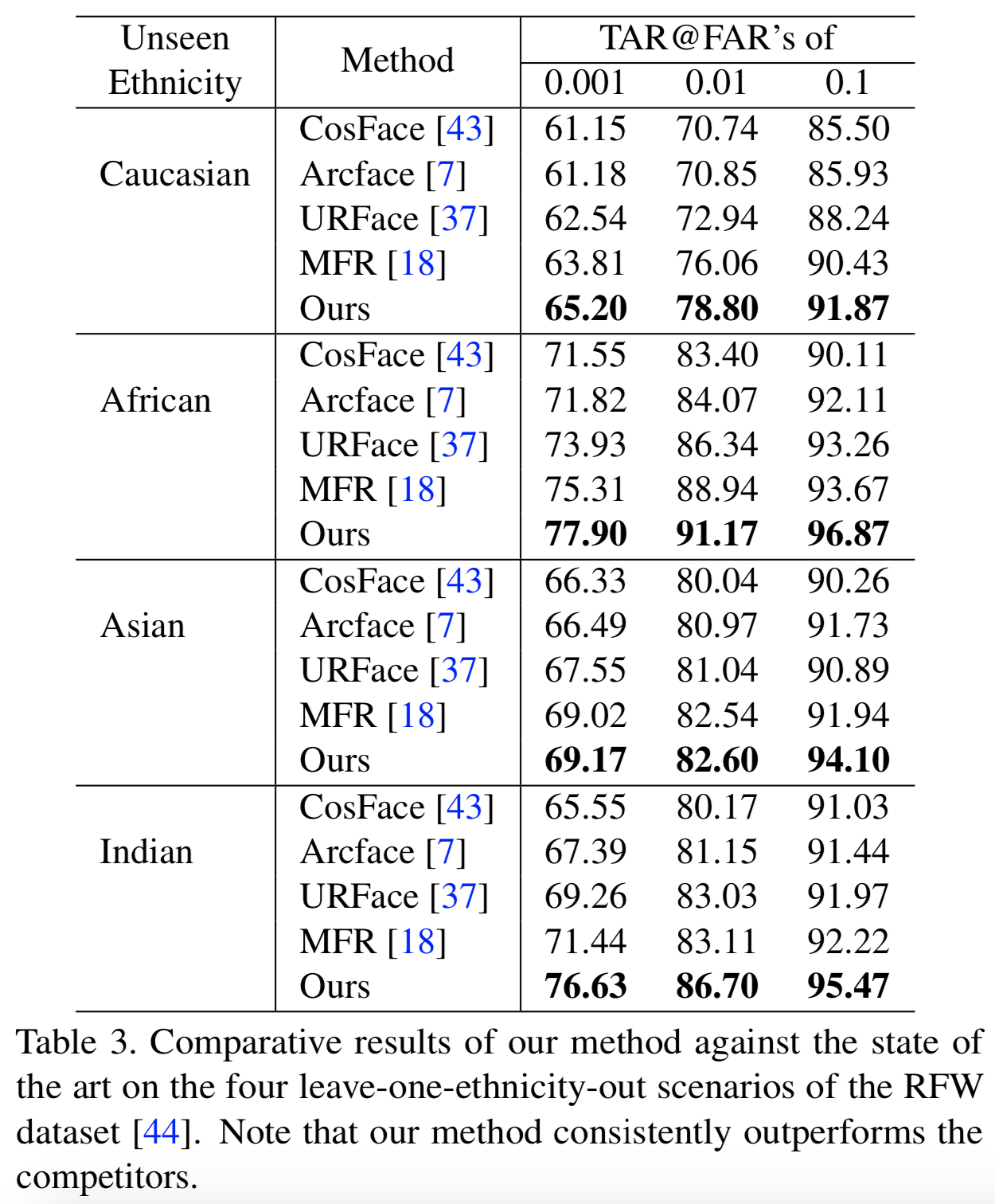
Results on the RFW Dataset. 在表3中,使用了RFW数据集,我们将我们的结果与上述leave-one-ethnic-out协议中描述的最先进方法的结果进行了比较。在前面的实验中,我们的方法在所有情况下都是最好的。在FAR@0.1 度量下,以非裔美国人和印度人的图像作为测试域,我们的算法与竞争对手MFR之间的差距超过3%。CosFace方法被认为是基线方法,是性能最差的方法,说明学习泛化特征在人脸识别中的重要性。
4.2. Handling Other Variations
为了证明我们的方法是通用的,并且可以在测试期间处理其他常见的变化,我们考虑了额外的实验。遵循MFR[18]提出的标准协议,在所有实验中,以种族标注的完整训练数据作为我们的源域。
Cross age face verification and identification. 首先,我们考虑使用跨年龄名人数据集(CACD-VS)[4]进行实验。该数据集提供等量的4k个正、负跨年龄图像对,构成人脸验证任务的测试子集。本实验结果如表4所示,其中我们也报道了ROC曲线下面积(Area Under The ROC Curve, AUC)以及验证准确度数字。该表表明,虽然我们的方法在FAR@0.001测量下优于最近的MFR方法,但在其他评估指标下,其工作竞争力非常接近。在AUC衡量下,我们获得了与MFR完全相同的性能。在所有的比较中,我们的方法优于LF-CNNs[45]之前的工作。

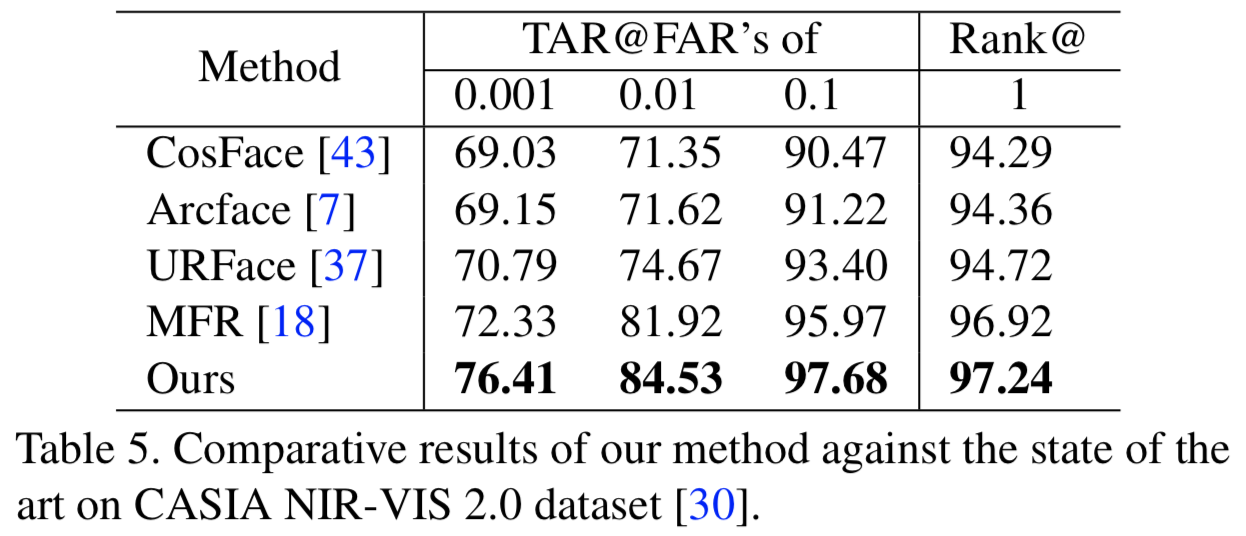
Near infrared vs. visible light face recognition. 接下来,我们考虑使用CASIA NIR-VIS 2.0人脸数据库[30]进行实验。在这里,gallery人脸图像是在可见光下拍摄的,而probe图像是在近红外光下拍摄的。表5显示,我们的方法始终优于竞争对手。
Cross pose face recognition. 最后,我们考虑了一个使用 Multi-PIE cross pose数据集的实验[17,35]。与之前的实验相似,我们的方法优于竞争对手,如表6所示。

4.3. Ablation Analysis
在本节中,我们进一步进行实验,展示算法1的重要组成部分对验证准确度的影响。在此分析中,我们使用RFW数据集的高加索人子集作为没见过的域,其他所有域的其余数据作为源域。
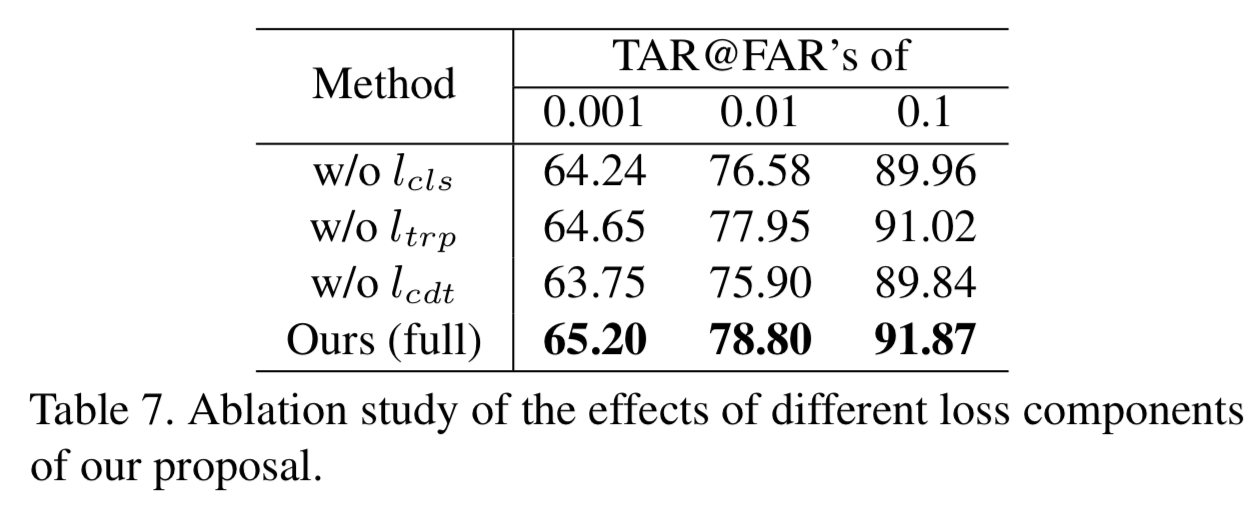
我们首先研究当不同的损失组件被排除在我们的算法之外时,最终识别精度数字是如何变化的。这里不同的组件是身份分类、triplet和cross-domain triplet损失,分别用![]() 、
、![]() 和
和![]() 表示。实验结果如表7所示。如表所示,我们总体损失的每个组成部分,都对最终的性能有重要的贡献,因为排除它们中的任何一个都会导致性能的持续下降。进一步比较不同的损失项,我们发现我们提出的CDT损失在这里扮演着更重要的角色,因为没有这个损失组件,性能会显著下降。例如,FAR@0.1在没有
表示。实验结果如表7所示。如表所示,我们总体损失的每个组成部分,都对最终的性能有重要的贡献,因为排除它们中的任何一个都会导致性能的持续下降。进一步比较不同的损失项,我们发现我们提出的CDT损失在这里扮演着更重要的角色,因为没有这个损失组件,性能会显著下降。例如,FAR@0.1在没有![]() 的情况下下降了2%以上。
的情况下下降了2%以上。
此外,我们方法中的一个超参数是meta-train和meta-test损失的贡献率,即![]() 和
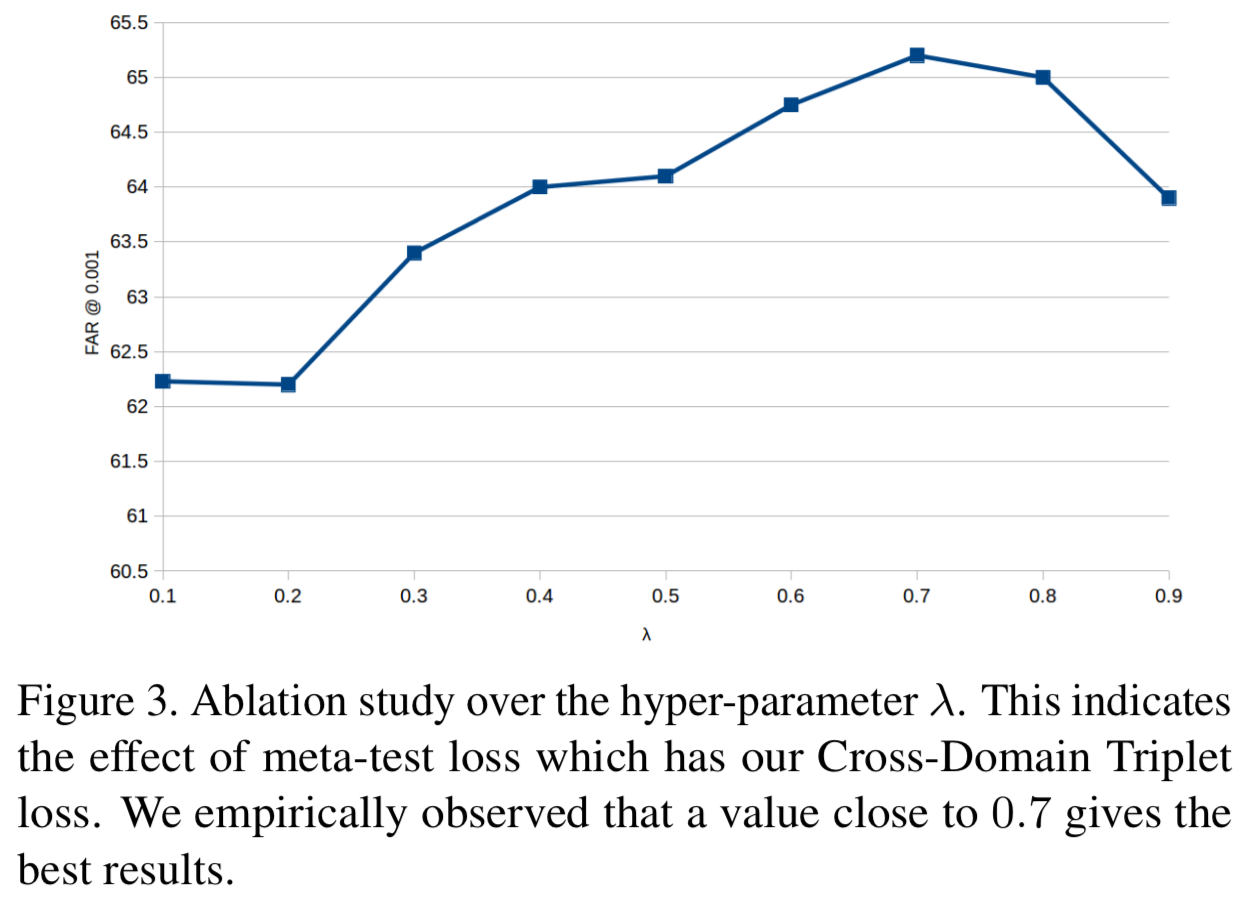
和![]() 。这是由算法1中的超参数λ决定的。在图3中,我们展示了在将RFW数据集的高加索人子集考虑为目标域时,改变λ对FAR@0.001度量的影响。我们观察到,接近0.7的值给出了最好的结果。
。这是由算法1中的超参数λ决定的。在图3中,我们展示了在将RFW数据集的高加索人子集考虑为目标域时,改变λ对FAR@0.001度量的影响。我们观察到,接近0.7的值给出了最好的结果。
5. Conclusions
我们已经引入了一个跨域度量学习损失,它被称为dubbed Cross-Domain Triplet (CDT) 损失,它利用两个观测域中共同包含的信息来提供更好的域对齐。本质上,它首先考虑一个数据分布的相似性度量,然后以类似于triplet损失的方式,使用度量来强制属于另一个域的身份得到紧凑的特征集群。直观地说,CDT损失将从一个域获得的显式度量值与从另一个域获得的triplet样本在一个统一的损失函数中有区别地关联起来,从而在网络中最小化,这将导致更好的训练域对齐效果。我们也在元学习pipeline中加入了损失,以进一步加强网络参数在域偏移下学习泛化特征。在各种人脸识别基准上的大量实验表明,我们的方法在处理变化方面具有优越性,其中种族是最重要的变化。在未来,我们将研究如何在我们的框架中使用协方差矩阵的通用形式(例如[5]中使用的协方差矩阵)。