End-to-end Learning of Deep Visual Representations for Image Retrieval
Abstract
虽然深度学习已经成为许多计算机视觉任务的top执行方法的关键组成部分,但到目前为止,它还没有在实例级图像检索方面带来类似的改进。在本文中,我们认为深度检索方法在图像检索方面的结果令人失望的原因有三:1)嘈杂的训练数据,2)不合适的深度架构,和3)次优的训练过程。我们解决了这三个问题。首先,我们利用了一个大规模但有噪声的地标数据集,并开发了一种自动清理方法,该方法可以产生一个适合深度检索的训练集。其次,我们基于最近的R-MAC描述符,表明它可以被解释为一个深层和可区分的架构,并提出改进来增强它。最后,我们用siamese结构来训练这个网络,它结合了三个streams并使用triplet loss的。在训练过程的最后,提出的架构在一个单一的前向传递后产生一个全局的图像表征,这非常适合于图像检索。大量的实验表明,我们的方法显著优于以前的检索方法,包括基于昂贵的局部描述符索引和空间验证的最新方法。在Oxford 5k、Paris 6k和Holidays数据集中,我们分别报告了94.7、96.6和94.8的mAP。我们的表征也可以使用乘积量化(product quantization)来进行高度压缩,而准确率只有很小的下降。为了确保我们研究的可重复性,我们还发布了数据集的clean注解和我们的预训练模型:http://www.xrce.xerox.com/Deep-Image-Retrieval。
1 Introduction
实例级图像检索是一个可视化搜索任务,目标是给定一个查询图像,在一个可能非常大的图像数据库中检索包含与查询图像有着相同对象实例的所有图像。图像检索和其他相关的可视化搜索任务具有广泛的应用,如web上的逆向图像搜索或个人照片收藏的组织。图像检索也被视为数据驱动方法的一个关键组件,这些方法使用可视化搜索将与检索图像关联的注释传输到查询图像(Torralba et al, 2008)。这已被证明对各种各样的注释都很有用,如图像级标签(Makadia et al,2008)、GPS坐标(Hays and Efros, 2008)或显著物体位置(Rodriguez- Serrano et al,2015)。
深度学习,尤其是深度卷积神经网络(Deep convolutional neural networks, CNN),已经成为计算机视觉领域一个极其强大的工具。在Krizhevsky et al(2012)使用卷积神经网络在2012年的ImageNet分类和定位的挑战(Russakovsky et al,2015)上获得第一名后,基于深度学习的方法显著提高了在目标检测等其他任务(Girshick et al,2014)和语义分割(Long et al,2015)的最新效果。最近,它们也在其他语义任务中发光发热,比如image captioning (Frome et al, 2013; Karpathy et al, 2014) 和visual question answering (Antol et al, 2015)。然而,到目前为止,深度学习在实例级图像检索方面还不太成功。在大多数检索基准,深度方法比依赖于局部描述符匹配和使用详尽空间验证 (Mikul ́ık et al, 2010; Tolias et al, 2015; Tolias and J ́egou, 2015; Li et al, 2015)进行重新排序的传统方法效果差。
大多数深度检索方法使用网络作为局部特征提取器,利用在大型图像分类数据集(如ImageNet)上预先训练的模型(Deng et al, 2009),并且只专注于在这些特征之上设计适合图像检索的图像表征。人们已经做出了一些贡献,使得深层架构能够准确地表示不同大小和长宽比的输入图像 (Babenko and Lempit- sky, 2015; Kalantidis et al, 2016; Tolias et al, 2016) 或解决基于CNN的特征缺乏几何不变性的问题(Gong et al, 2014; Razavian et al, 2014)。在此,我们认为,以往基于深度架构的图像检索方法无法取得良好效果的主要原因之一是缺乏针对实例级图像检索的具体任务的监督学习。
在这项工作中,我们集中在学习适合用于检索任务的表征这个问题上。不同于那些被学习来区分不同语义类别的特征,这些特征对于类内的变化来说是稳健的,在这里我们感兴趣的是区分特定的物体,即使它们属于相同的语义类别(如区分白马和黑马,语义类别都为马)。我们提出了一个解决方案,结合了一个为检索任务定制的表征和一个明确目标检索的训练过程。
对于表征,我们在卷积(R-MAC)描述符的区域最大激活 (Tolias et al, 2016)上构建。该方法对不同尺度下的多个图像区域计算基于CNN的描述子,并将其聚合成固定长度的紧凑特征向量,因此具有较好的缩放和平移鲁棒性。该方法的一个优点是,它可以编码高分辨率的图像,并不扭曲其长宽比。然而,在最初的形式中,R-MAC描述符使用了一个在ImageNet上预先训练好的CNN,我们认为这是次优的。在我们的工作中,我们注意到R-MAC管道的所有步骤都可以集成到一个单独的CNN中,我们建议以端到端的方式学习它的权值,因为它的计算所涉及的所有步骤都是可微的(就是打算自己训练一个CNN)。
在训练过程中,我们使用了一个包含三个streams和使用triplet loss的siamese网络,它明确地优化了网络的权值,以产生非常适合检索任务的表征(即训练新的CNN的方法)。此外,我们还提出学习R-MAC描述符的池化机制。在Tolias等人(2016)的原始架构中,一个rigid的网格决定了被池化的区域的位置,这些区域将产生最终的图像级描述符。在这里,我们建议显式学习如何使用区域推荐网络选择给定的图像内容的这些区域位置(即在网络中加上一个RPN网络,用于定位)。该训练过程产生了一种新的结构,它能够在一次前向传递中将一张图像编码成一个紧凑的固定长度的向量。然后可以使用dot-product对不同图像的表征进行比较。最后,我们提出了一种将不同分辨率的信息编码为单个描述符的方法。输入图像首先以不同的尺度调整大小,然后组合它们的表征,产生一个多分辨率描述符,这个方法将显著改善结果。
学习我们表征的权值需要适当的训练数据。为了实现这一目标,我们利用了Babenko等人(2014)的公共地标数据集,它与Babenko等人(2014)所示的标准实例级检索基准保持了良好的一致性,它的图像是通过使用几个著名地标的名称查询图像搜索引擎来检索得到的。我们建议对这个数据集进行清理,它可以自动丢弃大量错误标记的图像,并在不需要进一步注释或人工干预的情况下估计地标位置。
一项关于四种标准图像检索基准的广泛实验研究定量地评估了我们每一项贡献的影响。我们还展示了将我们的表征与查询扩展(query expansion)和数据库端特征增强相结合的效果,以及使用乘积量化进行压缩的影响。最终,我们得到的结果在很大程度上超越了所有数据集上的最新的效果,不仅与每个图像使用一个全局表征的方法对比, 而且还与更昂贵的与我们的方法不同的方法对比,其还需要进行后续匹配阶段或几何验证。
本文的其余部分组织如下。第2节讨论相关工作。第3节描述了产生合适训练集的清理过程。第4节描述了训练过程,而第5节提出了对深层架构的一些改进。第6节描述了最后的管道,并将其与最新研究进行比较。最后,第7节对本文进行总结。
本文以以下方式扩展了我们之前的工作(Gordo et al, 2016):在构建全局描述符时,我们将残差网络架构作为一种替代方法(其非常深层的本质需要调整我们的训练过程,参见4.3节)。我们构建描述符的多分辨率版本来处理查询图像和数据库图像之间的缩放变化(第5.3节)。我们建议将我们的方法与数据库端特征增强相结合,在测试时无需额外成本的情况下显著提高检索精度(第6.2节)。我们通过PCA和乘积量化方法来评估在我们的表征中压缩的效果(章节6.3)。这些新的贡献大大改善了结果。此外,我们还展示了定性的结果,说明学习在模型激活中的影响。
2 Related work on image retrieval
本节概述了一些对实例级图像检索有贡献的关键论文。
2.1 Conventional image retrieval
早期的实例级检索技术,如Sivic and Zisserman (2003), Nister and Stewenius (2006), and Philbin et al (2007) 的技术,都依赖于 bag-of-features表征、大型词汇表和inverted文件。无数的方法,提出了更好的近似匹配的描述符,看到的作品例如J ́egou et al (2008); J ́egou et al (2010); Mikulik et al (2013); Tolias et al (2015)。这些技术的一个优点是可以使用空间验证来重新排序候选结果列表(Philbin et al, 2007;Perdoch et al,2009年),尽管成本巨大,但仍取得了很大的改进。
同时,还考虑了聚合局部patch以构建全局图像表征的方法。编码技术,如Fisher vector(Perronnin and Dance, 2007;Perronnin et al,2010)或VLAD描述符(J́egou等,2010)已经被如(J ́egou et al, 2010) have been used for example by Perronnin et al (2010); Gordo et al (2012); J ́egou and Chum (2012); Radenovic et al (2015)等使用。所有这些方法都可以与查询扩展等后处理技术相结合(Chum et al,2007,2011;Arandjelovic and Zisserman, 2012)。一些研究还建议压缩描述符以提高存储要求和检索效率,但代价是降低准确性。尽管最常见的方法是通过PCA或乘积量化使用无监督压缩(Perronnin et al,2010;J́egou and Chum,2012;Radenovic et al,2015),有监督的降维方法也是有的(Gordo et al,2012)。
2.2 CNN-based retrieval
在Krizhevsky等人(2012)的开创性工作中,一个经过ImageNet分类训练的CNN的激活被用作实例级检索任务的图像特征,尽管这只进行了定性的评估。不久之后,Razavian等人(2014)对这些现成的CNN特征进行了定量评估。针对它们对缩放、裁剪和图像杂波缺乏鲁棒性的缺点,提出了一些改进措施。Razavian等人(2014)对每个查询区域进行区域交叉匹配并累积最大相似度,而Babenko和Lempitsky(2015)对白化区域描述符使用sum-pooling。Kalantidis等人(2016)扩展了Babenko和Lempitsky(2015)的工作,允许跨维加权和神经编码的聚合。其他提出的混合模型也涉及编码技术,如Perronnin和Larlus(2015)使用了FV,或Gong等人(2014)和Paulin等人(2015)考虑了VLAD。尽管这些方法的性能优于标准的全局描述符,但它们的性能明显低于传统方法的水平。
Tolias等(2016)提出在固定的空间区域布局中聚合CNN的激活特征。该方法使用一个预训练、全卷积的CNN提取图像的局部特征,且没有扭曲他们的长宽比和改变图像大小,然后聚合这些局部特色为使用归一化的全局表征,其已知在图像检索中效果很好(J ́egou and Chum, 2012)。这个方法的结果叫做R-MAC描述符,它是图像的固定长度向量表示,当与查询扩展结合使用时,可以获得接近最新技术水平的结果。我们的工作灵感来自于R-MAC管道,但以端到端的方式学习模型权重。
2.3 Finetuning for retrieval
使用在ImageNet上为分类而训练的模型的现成特征可能不是实例级检索任务的最佳选择,因为所训练的模型是为了实现类内泛化(即用来区分不同的类,如区分鱼和马;但是类内很难区分,如白马和黑马)。与使用预先训练好的模型作为特征提取器不同,一些方法提出了明确地学习更适合检索任务的权重。Babenko等人(2014)的工作表明,在ImageNet上预先训练的用于对象分类的模型可以通过在一组外部地标图像上微调来改进,即使使用了分类损失。
我们工作的初始版本 (Gordo et al, 2016)连同并发工作 (Radenovic et al, 2016),证实为了检索微调预训练的模型可以带来显著的性能改善,但也说明了更重要的是将 i)一个好的图像表征和 ii)用于排名的损失(其和使用在Babenko et al(2014)的分类损失相反)结合起来。Arandjelovic等人(2016)最近的NetVLAD也强调了学习排名的重要性。
3 Leveraging large-scale noisy data
(这里是用来得到带有边界框标注信息的干净的地标数据集)
为了学习用于实例级检索的信息化和有效的表征,我们需要适当的数据集。本节描述我们如何利用和自动清理现有数据集,以获得训练我们的模型所需的特征。
我们利用了Landmarks数据集(Babenko et al, 2014),这是一个大规模的图像数据集,包含672个著名地标的大约214k幅图像。它的图像是通过图像搜索引擎中的文本查询收集的,没有经过彻底的验证。因此,它们包含了各种各样的profiles: 如场地的一般视图、雕像或绘画等细节的特写镜头,以及所有中间案例,除此外还有场地地图图片、艺术素描,甚至是完全不相关的图像,如图1所示。

由于URLs的损坏,我们只能下载一部分图片。我们删除了图像太少的类。我们还小心翼翼地删除了所有与我们实验的Oxford 5k, Paris 6k和 Holidays数据集有重叠的类,见4.4节。我们获得了一组约192,000张分割成586个地标的图像。我们将此集合称为Landmarks-full。在我们的实验中,我们使用168,882张图像进行实际的微调,使用剩余的20,668张图像来验证参数。
leaning the Landmarks dataset. Landmarks数据集包含了不可忽略的大量不相关图像(图1)。虽然这在特定的框架(例如分类,通常网络可在训练中容纳这种多样性,甚至噪音)下可能是被允许的,在某些情况下我们需要学习有着相同的特定对象或场景的图像的表征。在这种情况下,这些图像的差异来自于不同的观图尺度、角度、光照条件和图像杂波(而不是类别)。我们对Landmarks数据集进行预处理,如下所示。
我们首先在每个地标类的图像中运行一个强图像匹配基线。我们使用不变关键点匹配和空间验证(Lowe, 2004)对每对图像进行比较。我们使用SIFT和Hessian-Affine关键点检测器(Lowe, 2004;Mikolajczyk and Schmid, 2004)和使用first-to-second neighbor ratio rule(Lowe, 2004)匹配关键点。众所周知,这种方法优于基于描述符量化的方法(Philbin et al, 2010)。然后,我们用Philbin等人(2007)提出的仿射变换模型验证所有成对匹配。这个沉重的过程是可负担的,因为它是离线执行,只在训练时间进行一次,并在每个类基础类中执行。
为了不失一般性,我们将描述单个地标类的清理过程的其余部分。一旦我们获得了所有图像对之间的成对分数集,我们构造一个图,其节点是图像,而边是成对匹配。我们修剪所有分数低的边。然后提取图的连通分量。它们对应着一个地标的不同profiles; 图1展示了St Paul’s Cathedral的两个最大的连接组建(一个是整个建筑外观,一个是他的内部景观,即与St Paul’s Cathedral建筑搜索相关的图一遍出来的就是其外观或内部图)。最后,我们只保留最大的连接组件,并丢弃其他组件,以确保类中的所有图像在视觉上是相关的。这个清理过程留下大约49,000张图像(分为42,410张训练图像和6,382张验证图像),仍然属于586个地标之一,该数据集称为Landmarks-clean。在32核服务器上,清理过程花费了大约一周的时间,在类上并行进行。
Bounding box estimation. 在我们的一个实验中,我们用一个学习过的感兴趣区域(ROI)选择器来替换R-MAC描述符中区域的均匀采样方法(第5.1节)。这个选择器是使用边界框标注进行训练的,我们会自动对所有地标图像进行估计。为了实现这个目标,我们利用了在清理步骤中获得的数据。经过验证的关键点匹配的位置是一个有意义的线索,因为感兴趣的对象在地标的图片上是一致可见的,而干扰的背景或前景对象是变化的,因此是不匹配的。
我们用图S = {VS, ES}表示每个地标的连通分量。每对连通图像(i,j)∈ES都对应一组验证过的关键点匹配和一个仿射变换Aij。我们首先在图像i和j中定义一个初始边界框,用Bi和Bj表示,作为包围所有匹配关键点的最小矩形。请注意,单个图像可以包含在许多不同的对中。在这种情况下,初始边界框是所有框的几何中值,如Vardi和Zhang(2004)中的有效计算。然后,我们运行一个扩散过程,如图2所示,在这个过程中,对于一对(i,j),我们使用Bi和仿射变换Aij来预测边界框Bj(反之亦然,即用Bj和仿射变换Aij预测边界框Bi)。在每次迭代中,边界框被更新为:![]() ,其中,α是小的更新步长(在我们的实验中我们设置了α= 0.1)。同样,对单一图像的多次更新使用几何中值合并,这是鲁棒的仿射变换估计。这个过程迭代直到收敛。从图2中可以看出,边界框的位置得到了改善,其在图像间的一致性也得到了改善。我们正在制作一份 Landmarks-clean图像及其估计的可用边界框列表(这样就为使用的数据得到了其对象对应的边界框)。
,其中,α是小的更新步长(在我们的实验中我们设置了α= 0.1)。同样,对单一图像的多次更新使用几何中值合并,这是鲁棒的仿射变换估计。这个过程迭代直到收敛。从图2中可以看出,边界框的位置得到了改善,其在图像间的一致性也得到了改善。我们正在制作一份 Landmarks-clean图像及其估计的可用边界框列表(这样就为使用的数据得到了其对象对应的边界框)。
接下来,我们利用我们清理的数据集为图像检索学习定制的强大图像表征。

4 Learning to rank: an end-to-end approach
本节首先回顾了Tolias等人(2016)在4.1节中的R-MAC表示,并表明,尽管它具有手工制作的特性,但它所涉及的所有操作都可以集成到单个CNN中,该CNN在一次前向传播过程中就能计算R-MAC表征。更重要的是,它的所有组件都由可微操作组成,因此,给定训练数据和适当的损失,就可以以端到端方式学习架构的最优权重。为了达到这个目的,我们利用了一个triplet ranking损失的three-stream siamese网络(章节4.2)。然后,我们将讨论允许此架构扩展到具有大内存需求的深度网络的实际细节(第4.3节)。最后,我们通过实验验证了在标准基准测试中所提出的训练策略所获得的有效性(第4.4节)。
4.1 The R-MAC baseline
最近由Tolias等人(2016)引入的R-MAC描述符是一种全局图像表征,特别适合于图像检索。其核心是使用一个“全卷积”的CNN作为一个强大的局部特征提取器,它独立于图像大小来工作,并且在不扭曲原始图像高宽比的情况下提取局部特征。Tolias等人(2016)的原始工作使用了AlexNet (Krizhevsky et al, 2012)和VGG16 (Simonyan and Zisserman, 2015)两种网络架构,模型在ImageNet数据集上预先训练,但也可以使用其他网络架构,如残差网络(He et al, 2016)。然后沿着从一个覆盖图像的刚性网格中获得的多个多尺度重叠区域中将这些局部特征max-pooled,其类似于空间金字塔,每个区域将产生一个单一的特征向量。这些区域层次上的特征都独立进行了L2归一化、PCA白化和再次L2归一化操作,这个已知的规范化管道在图像检索中效果很好 (J ́egou and Chum, 2012)。最后,再次对所有的区域描述符进行求和聚合和L2归一化。获得的全局图像表征是一个紧凑的向量,其大小(通常为256到2k维,取决于网络架构)独立于图像的大小和区域的数量。注意,区域池化与空间金字塔不同:后者连接区域描述符,而前者对它们进行求和聚合。用点积比较两幅图像的R-MAC向量可以被解释为一种加权的多对多区域匹配,其中权重取决于集合的区域描述符的范数。
4.2 Learning to retrieve
R-MAC管道的一个关键方面是,它的所有组件都是可微操作。更准确地说,不同区域的多尺度空间池化方法与He et al(2014)使用固定rigid网格的感兴趣区域(ROI)池化方法是等价的,在检测上下文中显示出是可微的(Girshick, 2015)。PCA投影可以被看作是shifting(对于平均centering)和全连接(FC)层(对于特征向量投影)的组合,具有可学习的权重。不同区域的总和聚合和L2归一化也是可微的。因此,我们可以实现这样一种网络架构:给定图像及其区域的预计算坐标,直接生成相当于R-MAC管道的表征。由于所有的组件都是可微的,人们可以通过网络架构反向传播来学习最优网络权值,即卷积层和用来替换PCA的shifting层和全连接层的权值。
Learning with a classification loss. 我们可以使用交叉熵损失在Landmarks数据集上轻松地微调一个标准分类架构(例如VGG16),就像之前由Babenko等人(2014)所做的那样,然后使用改进的卷积过滤器作为R-MAC管道的特征提取器,而不是使用原始的权重。我们使用这种方法作为我们的训练基线,并注意到它有重要的问题。首先,它不直接学习检索任务去解决问题,而是学习一个分类代理。其次,它没有利用R-MAC架构,因为它在原始的分类架构上学习,使用低分辨率的方形crop输入。卷积权值只有在训练完成后才与R-MAC架构一起使用(该微调方法其实就是用Landmarks数据集去微调CNN分类网络,然后再使用某层输出的特征作为提取的特征)。在我们的实验中,我们展示了这种朴素的微调方法是如何显著优于基线方法的,但与使用适当的结构和损失进行训练所获得的精确度并不匹配。
Learning with a ranking loss. 在我们的工作中,我们提出考虑基于图像triplets的排序损失。目标是显式强制执行的,即给定由查询图像、与查询相关的元素和不相关的元素组成的triplet,相关图像的R-MAC表征比不相关图像的表征更接近查询图像的表征。
我们设计了一个three-stream siamese网络架构,其中由每一stream产生的图像表征都被损失共同考虑。这种体系结构如图3所示。卷积滤波器和全连接层的权值在流之间共享,因为它们的大小与图像的大小无关。这意味着siamese架构可以处理任何大小和长宽比的图像,并且我们可以在测试时使用相同的(高)分辨率的图像来训练网络。

Siamese网络在metric learning (Song et al, 2016), dimensionality reduction (Hadsell et al, 2006), learning image descriptors (SimoSerra et al, 2015), and performing face identification (Chopra et al, 2005; Hu et al, 2014; Sun et al, 2014)中很好地实现了。最近,triplet网络(即three-stream siamese网络)被考虑用于metric learning (Hoffer and Ailon, 2015; Wang et al, 2014) and face identification (Schroff et al, 2015)。
我们使用下面的排名损失。让Iq表示为具有R-MAC描述符q的查询图像,I+为具有描述符d+的相关图像,I-为具有描述符d−的无关图像。我们将排序triplet损失定义为:

其中m是控制边际的标量。给定一个产生非零损失triplet,其子梯度为:

子梯度通过网络的三个stream反向传播,卷积层和“PCA”层(即shifting层和全连接层)都得到了更新。这种方法直接优化排序目标函数。
4.3 Practical considerations
在使用排序损失学习的过程中,要注意一些实际的考虑。第一个是对triplets进行抽样,因为随机抽样在大多数情况下会产生没有损失的三胞胎(即查询图像和不相关图像的不相关性太大,导致损失等式1损失L(Iq,I+,I-)总是为0),因此不能改进模型。为了保证采样的tripelts是有用的,我们首先随机选取N个训练样本,利用现有模型提取其特征,然后计算所有可能的triplets及其损失,一旦特征提取完成,计算速度很快。所有生成损失的triplets都被预选为优秀的候选人。triplets可以从这一组优秀的候选样本中取样,并倾向于hard triplets,即产生高损失的triplets。在实践中,这是通过随机抽样均匀分布的N个图像中的一个,然后随机选择25个包含前面选择的特定图像作为查询图像的triplets中损失最大的一个来实现的(这样一次次来,得到N对triplet)。请注意,理论上,每次更新模型时都应该重新计算好的候选集,这是非常耗时的。在实践中,我们假设对于一个给定的模型,即使模型更新了几次,大多数的hard triplets仍然hard,因此我们只在模型更新了k次之后才更新好的候选集合。在我们的实验中,我们使用N = 5,000个样本和k = 64次迭代,每次迭代的batch size为64个triplets。
第二个要考虑的问题是训练期间所需的内存量,因为我们同时训练大图像(较大的一侧调整为800像素)和三个stream。在使用VGG16架构时,我们在一个12Gb内存的M40 GPU上一次只能在内存中容纳一个triplet。为了对一批有效大小大于1的bs进行更新,我们依次计算和聚合每个triplet的网络参数损失梯度,仅在每bs个triplets后实现实际更新,bs = 64。
当使用更大的网络(如ResNet101)时,情况会变得更加复杂,因为我们没有足够的内存来处理一个triplet。为了避免减小图像尺寸会导致图像细节的丢失,我们提出了一种替代方法,具体在算法1中。这种方法允许我们使用单个stream顺序处理一个triplet的stream,而不是同时处理所有的stream。这将产生完全相同的梯度,但是由于重新计算(大约25%的开销),会牺牲一些计算效率来获得非常显著的内存减少(只需要三分之一的内存,从23 Gb减少到7.5 Gb)。这允许我们使用非常深的架构来训练模型,而不减少训练图像的大小。

4.4 Experiments
在本节中,我们将研究学习不同设置和架构的权重的影响。在所有这些实验中,我们假设描述符按照标准的R-MAC策略提取区域,即遵循预定义的rigid网格。
4.4.1 Experimental details
我们四个标准数据集上测试我们的方法:Oxford 5k building dataset (Philbin et al, 2007), the Paris 6k dataset (Philbin et al, 2008), the INRIA Holidays dataset (J ́egou et al, 2008), and the University of Kentucky Benchmark (UKB) dataset (Nister and Stewenius, 2006)。我们使用标准的评估协议,即对UKB使用recall@4,对其余的使用mean average precision(mAP)。按照标准做法,在Oxford和Paris数据集中,用户只使用查询图像的感兴趣的带注释的区域,而在Holidays和UKB数据集中,用户使用整个查询图像。此外,在对Holidays进行评估时,查询图像将从数据集中删除,在Oxford、Paris和UKB中则不需要。按照大多数基于CNN的方法,我们在Holidays数据集上手动校正图像的方向,并对校正后的图像进行评估。为了与不修正方向的方法进行公平比较,我们在最后的实验中也报告了不修正方向的结果。
对于我们网络的卷积部分,我们评估了两种流行的架构:VGG16 (Simonyan和Zisserman, 2015)和ResNet101 (He et al, 2016)。在这两种情况下,我们都从ImageNet ILSVRC数据上预先训练的公开可用模型开始。使用PCA投影对全连接层进行初始化,并根据每个区域的归一化描述符进行计算。所有的后续学习都在Landmarks数据集上进行。
为了使用分类进行微调,我们遵循标准做法,将训练图像调整为多个尺度(最短边在[256 - 512]范围内),并提取224×224像素的随机crop图像。为了使用我们提出的架构进行微调,我们还会执行随机裁剪(随机删除图像每一边的5%)来增强训练数据,然后调整结果裁剪的大小,比如较大的一边为800像素,同时保持高宽比不变。在测试时,所有数据库图像也进行了调整,使较大的一侧为800像素。所有模型都采用momentum为0.9、学习率为10−3、权值衰减为5·10−5的随机梯度下降(SGD)进行训练。当Landmarks的验证误差停止下降时,我们将分类微调的学习率降低到10-4。在学习排序时,我们没有看到降低学习率的操作得到任何改善,所以我们将学习率保持在10-3,直到最后。margin被设置为m = 0.1。
4.4.2 Results
Quantitative evaluation. 我们在表1中报告了网络卷积部分的两个可能选择的结果:VGG16(上)和ResNet101(下)。对于每个架构,我们首先使用R-MAC基线报告性能,其卷积层权重直接取自ImageNet预训练的网络,PCA是在Landmarks-full上学习的。对于已学习的模型,通过分类损失(Ft-Cls)或排序损失(Ft-Rnk)对地标的权重进行微调。对于后一种情况,我们考虑直接使用ImageNet预先训练过的网络来初始化权值,或者使用一个已经用分类损失对地标进行微调的预热模型来初始化权值。
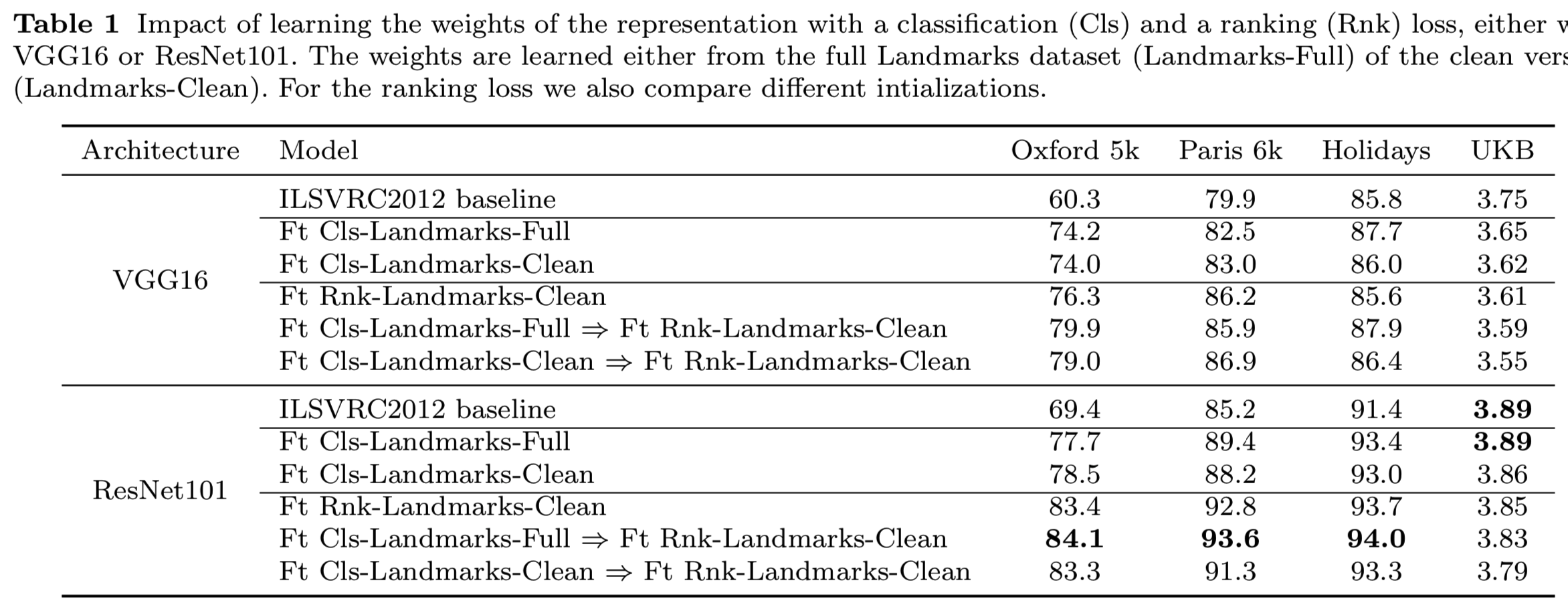
从表1报告的结果中,我们突出显示了以下观察结果。
- 对相关数据集使用原始分类损失进行微调,已经比在ImageNet上预先训练的模型有了显著的改进,正如Babenko等人(2014)在前三个数据集上观察到的那样(尽管采用了不同的架构)。在这种情况下,使用Landmarks-full进行训练或使用Landmarks-clean进行训练不会产生显著差异。
- 使用排序损失微调我们提出的体系结构能得到最佳的性能策略。对于前三个数据集,使用Landmarks数据集改进我们的模型的权重似乎非常有用。我们只报告使用Landmarks-clean学习排序的结果。我们发现这一点至关重要:在Landmarks-full上学习反而显著降低了模型的准确性。
- 为了利用排序损失获得好的结果,我们认为首先使用分类损失在Landmarks数据集上训练网络来预热是十分重要的,就像Gordo等人(2016)所做的那样。然而,在使用最近的ResNet101体系结构时,这就不是那么重要了:尽管预热网络会带来轻微的改进,但最终的结果是相似的。这也可以在图4中观察到,图4显示了在不同模型初始化的训练过程中,Oxford数据集的准确率的变化。
- 对于UKB数据集,“现成的”R-MAC已经提供了最先进的结果,并且训练稍微降低了它的性能,可能因为大的领域差异(章节6有关于UKB的更详细的讨论)。
正如预期的那样,基于ResNet101的模型优于基于VGG16的模型。然而,这种差距并不像训练带来的改善那么明显。

Impact of finetuning on the neurons. 我们定性地评估了为检索而微调表征的影响。为此,我们将图5中对最后一个卷积VGG16层的不同神经元反应最强烈(即激活值最大)的图像patches微调前和微调后的结果进行可视化。这些例子说明了在微调中经历了什么。一些最初专门用于识别对ImageNet分类至关重要的特定物体部分的神经元(例如“肩部神经元”或“腰部神经元”)被重新用于攻击视觉上相似的地标部分(例如圆顶、有平屋顶和两个窗户的建筑物)。然而,其他的神经元(例如“太阳镜神经元”)并没有被明确地重新利用,这表明在训练计划中的改进是可能的。

Computational cost. 为了训练和测试我们的模型,我们使用了12Gb内存的M40 NVIDIA GPU。当ResNet101在Landmarks-full上使用分类损失进行预训练时,大约需要4天时间来执行80000次迭代,batch size为128。这是我们在大多数实验中用来初始化我们的方法的模型。为了训练我们的排名模型,我们使用64个triplets的批处理大小和“单一流”方法(算法1),并调整我们的图像保持它们的高宽比,使更长的边有800像素。对于ResNet101,这个过程对每个样本的每个流大约需要7.5 Gb内存,并且可以在大约1小时内处理64次迭代,其中大约15分钟用于挖掘hard triplets。我们的模型用预先训练好的分类模型进行初始化后,经过大约3000次迭代即2天收敛。如果我们不在Landmarks数据集上预热模型并直接使用ImageNet模型,它将在大约8,000次迭代后收敛。在这两种情况下,整个训练大约需要一周时间。
一旦训练完成,提取一幅图像的描述符大约需要150毫秒,也就是说,在一个GPU上大约每秒7幅图像。计算两幅图像之间的相似性归结为计算它们表示之间的点积,这是非常高效的,也就是说,在一个标准处理器上每秒可以计算数百万次这样的比较。
5 Improving the R-MAC representation
R-MAC表征已被证明在深度检索方法中表现出色(Tolias et al, 2016)。在上一节中,我们已经展示了通过为图像检索定制目标函数和训练集,以端到端方式学习网络权重,可以进一步提高其有效性。在本节中,我们提出了几种修改网络架构本身的方法。首先,我们改进了区域池机制,引入了区域建议网络(region proposal network, RPN)来预测图像中最相关的区域,在这些区域中局部特征需要被提取(5.1节)。其次,我们注意到网络体系结构只考虑单一固定的图像分辨率,并建议对其进行扩展,以构建一个多分辨率描述符(第5.2节)。
5.1 Beyond fixed regions: proposal pooling
在R-MAC中使用rigid的多尺度网格去池化区域,以试图确保所关注的对象被至少一个区域覆盖。然而,这提出了两个问题。首先,任何网格区域都不可能与感兴趣的对象精确对齐。其次,很多区域只覆盖背景,特别是当检索对象规模较小时。这是一个问题,因为R-MAC签名之间的比较可以看作是一个多对多区域匹配,因此区域杂波将负面影响性能。增加网格中区域的数量可以提高一个区域与感兴趣的对象良好对齐的可能性,但也会增加不相关区域的数量。
我们建议修改R-MAC架构,以增强其聚焦于图像中相关区域的能力。为此,我们用区域建议网络(RPN)代替了rigid网格,该网络训练用于定位图像中感兴趣的区域,类似于Ren等人(2015)的建议机制。这个RPN是使用我们清洗过程的副产品获得的地标数据集的近似边界框标注来训练的。所得到的网络体系结构如图6所示。
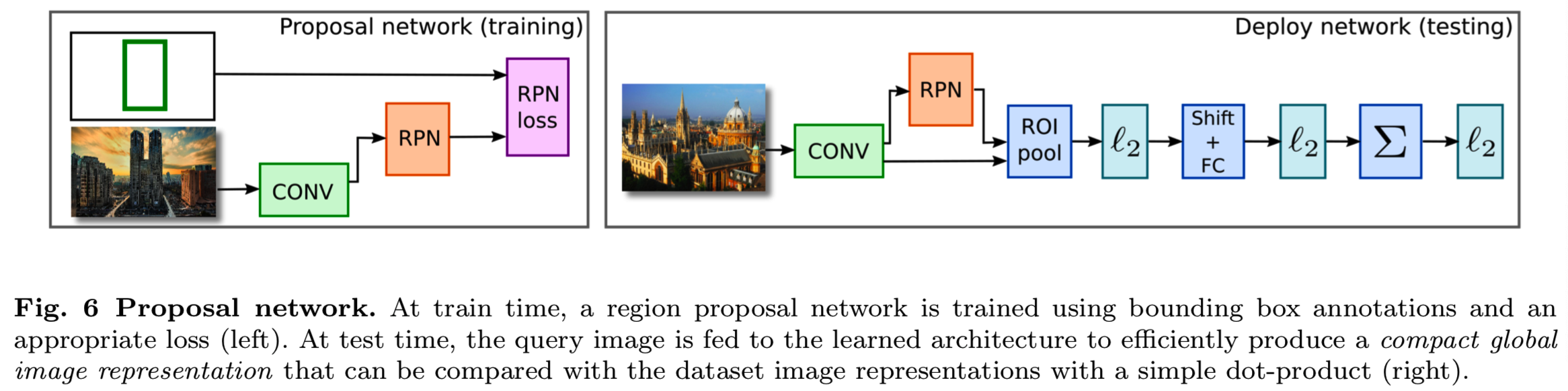
RPN背后的主要思想是为一组不同大小和长宽比的候选框预测一个分数,该分数描述每个候选框在每个可能的图像位置上包含感兴趣对象的可能性。同时,对每个候选框进行坐标回归,提高定位精度。这是通过一个由使用3×3过滤器的第一层和使用1×1过滤器的两个兄弟卷积层组成的“全卷积”网络,来对于图像中每个候选框的图片和每个位置预测目标分数和回归坐标。然后对排列的框执行非最大抑制方法(Non-maximum suppression),以为每个图像产生k个最终建议框,用于替代rigid网格。
对网络的这种修改有几个积极的结果。首先,区域推荐通常比死板的网格能更紧密地覆盖感兴趣的对象。其次,即使它们与感兴趣的区域没有完全重叠,但大多数推荐都与感兴趣的区域有明显的重叠,这意味着增加每张图像的推荐数量不仅有助于增加覆盖率,而且有助于多对多匹配。
Learning the RPN. 我们根据这个框与ground truth的感兴趣区域的重叠大小给每个候选框分配二进制类标签,然后我们使用包含分类损失(更准确地说是一个对象log损失 VS 背景类)和回归损失(类似于Girshick(2015)使用的光滑L1损失)的多任务损失来最小化目标函数和回归损失。通过反向传播和SGD优化目标函数。更详细的RPNs的实施和训练流程可以在Ren等人(2015)的工作中找到。
我们在网络的卷积层之上学习RPN。我们首先使用第4.2节中描述的rigid网格训练网络,然后固定卷积层的权值,从最后一个卷积层的输出训练RPN。这样一来,两个网络共享卷积部分的计算,并被合并到一个单一架构中(图6)。同时微调RPN和排名也是可行的,但我们观察到这样做并没有提高准确率。
5.2 Multi-resolution
在Tolias等人(2016)提出的原始R-MAC描述符中,图像是在单一尺度上考虑的。但是,可以考虑从被调整到不同分辨率的图像中提取和组合特征,以便集成来自不同尺度的信息。其目标是改进数据库图像中以不同尺度出现的对象和小对象的检索之间的匹配。
原始R-MAC网络的一个有趣特点是,不同的输入图像大小仍然产生相同长度的描述符。但是请注意,具有不同分辨率的同一图像的两个版本将不会产生相同的输出描述符。网络的第一部分是完全卷积的,它直接能够处理不同大小的输入,而聚合层将输入特征的大小相关的数量组合成固定长度的表征。根据这个想法,我们提出从调整到不同尺度大小的图像中提取不同的描述符,然后将它们组合成一个单一的最终表征。在实践中,我们使用3个尺度,在较大的一侧使用550、800和1050像素,保持高宽比。然后分别提取这三幅图像的描述符。最后,我们对它们进行相加聚合并对它们进行L2归一化,以获得最终的描述符。
这个多分辨率描述符可以在查询端和数据库端进行计算。这个过程在特征提取时带来了额外的计算成本(大约是三种分辨率成本的三倍),但是在搜索时的成本和存储成本是相同的。
我们的多分辨率方案可以与之前构建转换不变性(transformation-invariant)表征的论文相联系,如Schmidhuber (2012);Laptev et al(2016)。在我们的例子中考虑的变换是图像缩放。与multi-column网络或bagging方法相比(Schmidhuber, 2012),我们对所有图像尺度使用相同的网络。事实上,我们的方法在概念上接近Laptev等人(2016)的方法,这是一个权重共享的siamese网络,主要区别在于我们使用的是average-pooling,而不是sum-pooling。
5.3 Experiments
在本节中,我们将研究推荐池化和多分辨率描述符的影响。
Experimental details. 我们训练RPN网络200k次迭代,权值衰减为5·10−5,学习率为10−3,在100k次迭代后学习率降低了10倍。我们注意到只有RPN层被更新,而前面的卷积层保持不变。在M40 GPU上,这个过程只需要不到12个小时。
Region proposal network. 表2展示了VGG16和ResNet101体系结构中,与rigid网格相比,对于基线R-MAC(从ImageNet获得的卷积权值)和经过排名损失训练的版本,区域建议网络在越来越多的区域上的结果。使用VGG16,当区域数量足够多(128个或更多)时,我们观察到所有数据集和训练类型都有显著改善,这与我们在(Gordo et al, 2016)的初版中的发现一致。然而,在ResNet101中,这个差距要小得多,特别是在网络经过了排名损失的训练后。我们的直觉是,ResNet101能够学习更不变的区域表示,并降低背景的影响,因此它不需要像VGG16那样的推荐。这使得在使用ResNet101时推荐的使用不那么吸引人。鉴于ResNet101在所有情况下的表现都比VGG16要好(如表1和表2),我们去掉Gordo等人(2016)的版本,在本文的其余部分,我们只报告没有使用RPN的ResNet101结果。

Multi-resolution. 表3显示了使用受过排名损失训练的ResNet101的结果。多分辨率应用于查询图像(QMR)、数据库图像(DMR)或两者。所有情况都优于单分辨率描述符,表明使用多个尺度编码图像有助于匹配和检索对象。QMR和DMR似乎也是互补的。在接下来的实验中,我们同时使用QMR和DMR。

6 Evaluation of the complete approach
在前面的章节中,我们已经将R-MAC描述符描述为一个独立的网络架构,其中的权重可以以端到端方式有区别地学习,并提出了一些对原始管道的改进。在本节中,我们将所获得的表征与最新技术进行比较。我们的最后一个方法集成了另外两个改进:查询扩展(QE)和数据库端特征增强(DBA)。
6.1 Query expansion
为了提高检索结果,我们使用了查询扩展方法,这是Chum等人(2007)在图像搜索问题中引入的一种标准技术。查询扩展的工作方式如下:用查询图像的表征发出第一次查询,然后检索top k个结果。然后,这些顶部的k个结果可能会经历一个空间验证阶段,在这个阶段中,与查询不匹配的结果将被丢弃。然后对剩余的结果和原始查询表征进行求和集合(sum-aggregated)和重新归一化得到合并的表征。最后,使用组合的描述符发出第二次查询,生成检索到的图像的最终列表。查询扩展通常可以大幅提高准确性,但在查询时需要额外付出两个代价:空间验证和第二次查询操作。在我们的示例中,我们不执行空间验证(请注意,因为这通常需要访问局部关键点描述符,而我们没有),因此,由于第二次查询操作,查询扩展将使查询时间增加一倍。
6.2 Database-side feature augmentation
在Turcot and Lowe(2009)和Arandjelovic and Zisserman(2012)的研究中引入了数据库端增强(database-side augmentation, DBA),它可能在经过查询扩展的空间验证阶段之后去将数据库中的每一个图像签名都通过自身和相邻图像的结合来替代。其目的是通过利用相邻图像的特征来提高图像表示的质量。由于我们不使用空间验证,我们对最近的k个邻居进行求和聚合(sum-aggregated),就像在查询扩展的情况下一样。在我们的实验中,我们使用weights (r) = (k−r) / k作为一个加权方案,其中r是邻居的秩,k是考虑邻居的总数。
使用稀疏的反向文件的DBA不像查询扩展那么常见,因为它会增加数据库的大小和查询时间。在我们的例子中,签名已经很密集了,所以我们不受它的影响。因此,唯一的额外成本是在数据集中找到最近的邻居,这只需要在脱机状态下完成一次。对于不断增长的数据库,随着新示例的添加,数据库扩展可能也可以在线完成。
6.3 Experiments
6.3.1 Evaluation of QE and DBA
在图7中,我们评估了依赖于邻居数量k的查询扩展(QE)的效果,以及依赖于邻居数量k '的数据库端扩展(DBA)的效果。首先我们观察,在Oxford5k,许多查询很少有相关的物品(小于10个甚至小于5),对QE使用大的k值,不出所料,会降低而不是提高准确性,与是否使用DBA不相关。这在Paris上不是问题,因为所有查询在数据集中都有大量相关项。

加权DBA似乎在所有情况下都有帮助,即使是选择了较大的k'值,但是,有一个副作用,如果QE选择了不适当数量的邻居,也会使DBA结果恶化。一般看来,如果选择适当数量的邻居数量,QE和DBA可以极大地帮助对方,而且,作为一个经验法则,我们建议为DBA使用一个较大的值为(如k'= 20)和为QE使用一个小值(如k = 1或k = 2)。因为DBA是一个昂贵的预处理,它并不总是可行的。在这种情况下(对应于k' = 0), k最好使用一个中间值。对于我们包含QE和DBA的最后实验中,我们在所有数据集中固定k=1和k' =20。当只使用QE时,我们在所有数据集中固定k = 10。如果一个人有关于数据集的先验知识,修改这些值可能会导致改进的结果。
6.3.2 Comparison with the state of the art
我们在表4中将我们的方法与最新的技术进行了比较。在这些实验中,除了4.4节中介绍的四个数据集之外,我们还考虑了Oxford105k和Paris106k数据集,它们用100k的干扰图像扩展了Oxford5k和Paris6k数据集(Philbin et al, 2007)。在表的前半部分,我们展示了其他方法的结果,这些方法使用了图像的全局表哦正,并且在运行时不执行任何形式的空间验证或查询扩展。因此,它们在概念上更接近我们的方法。然而,我们在所有数据集上始终比他们都出色。在一个案例中(即Paris106k),我们的方法领先最佳竞争对手超过14个mAP(Radenovic et al, 2016)。

基于Holidays数据集中用于基于CNN特征的方法的评估协议包括手动旋转图像以纠正其方向。如果我们不手动旋转图像,我们的精度将从94.8下降到90.3,这仍然比当前的技术水平要好。不用使用oracle来旋转数据库图像,可以自动旋转查询图像并发出三个不同的查询(原始查询、查询旋转90度和查询旋转270度)。一个数据库图像的得分是通过三个查询获得的最大得分得到的。这使得查询过程慢了3倍,但是在没有oracle干预的情况下将准确率提高到了92.9。
我们还使用ResNet101代替VGG16重新实现了R-MAC基线(Tolias等人,2016)。虽然在使用ResNet101时精度的提高是不可忽略的,但是通过训练模型获得的精度仍然要高得多(在Oxford,训练时,无论是使用单分辨率还是多分辨率测试,在没有训练时是69.4,而训练时是84.1和86.1)。这一差距突出了设计良好的体系结构和有相关数据的完整的端到端训练的重要性,所有这些都是为图像检索的特定任务量身定做的。(所以对于特定任务使用特定数据集重新微调是很重要的)
表4的第二部分显示了不需要依赖全局表征的最新方法的结果。他们中的大多数的特点是比我们的方法更大的内存占用,如Tolias and J ́egou (2015); Tolias et al (2016); Danfeng et al (2011); Azizpour et al (2015)。这些方法在运行时执行一个昂贵的空间验证,通常需要在数据库中为每个图像存储成千上万的局部描述符(Tolias and J ́egou, 2015; Li et al, 2015; Mikulik et al, 2013)。它们中的大多数还执行查询扩展(QE)。为了进行比较,我们还在表的底部报告使用QE(有DBA或没有DBA)的结果。仅使用QE带来的改进只有同时使用QE和DBA时的一半左右,但是避免了对数据库的任何预处理。尽管不需要在运行时进行任何形式的空间验证,但我们的方法在所有数据集上都有很大的改进。特别是,我们的性能在所有数据集上领先最佳竞争对手5到14个mAP。
在文献 (Tolias and J ́egou, 2015; Azizpour et al, 2015)最好方法很难扩展,因为它们需要大量的存储内存和昂贵的验证。例如,Tolias and J ́egou(2015)需要一个缓慢的空间验证,每个查询图像需要1秒(不含描述符提取时间)。如果没有空间验证,他们的方法会丢失5个mAP,而且每次查询仍然需要大约200毫秒。Tolias等人(2016)的方法更具可扩展性,但仍需要额外的空间验证阶段,该阶段基于存储许多数据库图像的局部表征,尽管使用了先进的压缩技术,但最终会比我们的方法占用更大的内存。相比之下,我们的方法只计算两个矩阵向量积(如果不执行QE,则只计算一个),这是非常高效的。该操作在不到一秒的时间内计算数百万次图像比较。在不进行任何压缩的情况下,我们的方法需要为每个图像存储2048个浮点数,即8 kb,但是这种表征可以大幅压缩,而不会造成很大的精度损失,我们将在下一节中介绍。最后,我们想指出的是,当不执行QE和DBA(在测试时利用目标数据集的信息)时,我们的方法使用单一的通用模型——对所有测试数据集都是一样的——与 Danfeng et al (2011); Shen et al (2014); Tolias et al (2015)在目标数据集上进行一些学习的方法相反。
我们也报告使用我们的通用模型在UKB数据集上的结果。我们的方法在没有QE和DBA的情况下获得3.84的recall@4,在有QE和DBA的情况下获得3.91的recall@4。后者可与该数据集上发表的最佳结果相媲美,即Az- izpour等人(2015)报告的3.85结果,尽管这种方法的成本要高得多。其他结果显然更低(如Paulin et al (2015) reports 3.76, Deng et al (2013) reports 3.75, and Tolias and J ́egou (2015) reports 3.67),他们也是很难扩展的(见上面的讨论)。注意,训练略微降低了我们在UKB上的性能(表1)。这是由于我们的训练集(地标图像)和UKB图像(日常生活项目)之间的差异造成的。下降仍然是边际的,这表明我们的方法在适应其他检索上下文上效果很好。
6.3.3 Short image codes with PCA and PQ
我们研究了两种不同的方法来减少我们的方法的内存占用,同时保持最好的准确性。我们使用主成分分析(PCA)或乘积量化(PQ)压缩2048维图像描述符(Jegou et al, 2011)。在这两种情况下,我们在没有标记的图像上学习词汇表(PCA投影或PQ码本),并用我们学习到的表征进行编码。
在主成分分析的情况下,为了得到d维的描述符,我们只需要将特征集中起来,将它们投影到数据的d个最大特征值所对应的特征向量上,然后对其进行L2归一化。因此得到的描述符大小为4d字节,因为它们被存储为32位浮点数。PQ压缩是在k个子部分分割输入描述符,并分别对每个子部分进行矢量量化。尽管有些工作也在PQ编码之前将PCA应用于输入描述符,但我们发现它在我们的案例中没有任何明显的影响。训练PQ相当于为每个子部分学习一个码本,通过k-means聚类在一组代表性描述符上实现。每个子部分的码本大小通常设置为256,因为它允许它们恰好存储在1个字节上。因此,一个PQ编码的描述符的大小是k个字节。在测试时,高效的缓存技术允许高效地计算查询图像和PQ编码的数据库描述符之间的dot-product(Jegou et al,2011)。请注意,最近的改进使得PQ可以在不损失精度的情况下匹配高速的bitwise汉明距离计算(Douze et al, 2016)。
图8显示了我们的方法(不使用QE或DBA)和最新的检索结果,这些方法用于所有数据集和不同描述符大小(以字节为单位)。基于PCA的压缩,被标记为“Proposed (PCA)”,对于所有考虑的数据集和所有编码大小,都比其他现有方法取得了稍微好一点的结果,但是对于短编码,它的准确性会迅速下降。这种压缩方法仍然值得关注,因为它不需要对系统体系结构进行任何更改,而且与当前的技术相比,它仍然是比较好的。基于PQ的压缩,在图8中被标记为“Proposed (PQ)”,在所有数据集上,在性能和大小权衡方面大大优于所有已发布的方法。即使对于64字节的非常短的图像编码,它也能够超过大多数使用2048字节代码的最新技术。在这种设置中,我们可以在一台RAM为64 Gb的机器上存储数亿个图像,这说明了我们的方法的可扩展性。

6.4 Qualitative results
图9显示了我们基于ResNet101(包括QE和DBA)对一些Oxford5k查询图像(最左边图像上的紫色矩形)使用我们最终最好的检索系统得到的top检索图像。对于每个查询,我们还提供相应的平均精度(AP)曲线(绿色曲线),并将其与基线R-MAC(红色曲线)、我们学习的架构(蓝色曲线)及其多分辨率风格(紫色曲线)所获得的平均精度(AP)曲线进行比较。用所提出的训练模型得到的结果在精度方面始终较好。在许多情况下,通过我们的方法正确检索到的图像中,有几张在基线方法中没有得到很好的分数,且基线方法将它们排在结果列表的最下面。

7 Conclusions
我们提出了一种有效且可扩展的实例级图像检索方法,该方法将图像编码为紧凑的全局签名,可用dot-product进行比较。提出的方法结合了成功的三个关键因素。首先,我们通过自动清理一个已有的地标数据集来收集一个合适的训练集。其次,我们提出了一个学习框架,它依赖于基于triplet的排名损失,并利用这个训练集来训练一个深层架构。第三,对于我们建立在R-MAC描述符上的深度架构,将其转换为一个完全可微的网络,这样我们就可以学习它的权重,并通过一个专注于最相关图像区域的推荐网络(RPN)来增强它。在几个基准测试中进行的大量实验表明,在使用全局签名时,即使使用64或128字节的短编码,我们的正的性能也显著优于当前的技术水平。我们的方法的性能也优于现有的方法,因为这些方法更加复杂,依赖于代价高昂的匹配和验证,而且我们的运行速度更快,内存效率更高。