Data, networks, and code: cmp.felk.cvut.cz/cnnimageretrieval
https://github.com/filipradenovic/cnnimageretrieval-pytorch
Fine-tuning CNN Image Retrieval with No Human Annotation
ABSTRACT
基于卷积神经网络激活的图像描述符因其识别能力强、表征紧凑和搜索效率高而在图像检索中占据主导地位。训练CNNs,无论是从零开始还是微调,都需要大量的注释数据,而高质量的注释往往是至关重要的。在这项工作中,我们提出对CNNs进行微调,以完全自动化的方式对大量无序图像进行检索。使用最新检索得到的重建三维模型和structure-from-motion方法指导训练数据的选择。我们展示了通过利用三维模型中的几何图形和摄像机位置来选择的难正样本和难负样本,都提高了特殊对象检索的性能。从相同的训练数据中学习CNN描述符whitening的效果优于常用的PCA whitening。我们提出了一种新的可训练的Generalized-Mean(GeM)池化层,它概括了最大池化和平均池化,并证明了它提高了检索性能。将该方法应用于VGG网络,在标准基准数据上取得了最先进的性能,如:Oxford Buildings, Paris, and Holidays 数据集。
1 INTRODUCTION
在实例图像检索中,查询中描述的特定对象的图像在一个大型的、无序的图像集合中搜索。卷积神经网络(CNNs)最近为这个问题提供了一个有吸引力的解决方案。除了留下较小的内存占用,基于cnn的方法还可以获得较高的准确性。在Krizhevsky等人[1]在图像分类任务中取得成功后,神经网络受到了广泛的关注。他们的成功主要是由于使用了非常大的带注释的数据集,例如ImageNet[2]。训练数据的获取是一个代价高昂的人工标注过程,容易出现错误。经过图像分类训练的网络具有较强的自适应能力。具体来说,利用为分类任务而训练的CNNs的激活,将其作为现成的图像描述符[4]、[5],并将其用于多个任务[6]、[7]、[8],效果良好。特别是对于图像检索,许多方法直接使用网络激活作为图像特征,并成功地执行图像搜索[8]、[9]、[10]、[11]、[12]。
对网络进行微调,即先用预先训练好的分类网络进行初始化,然后再针对不同的任务进行训练,这是直接应用预先训练好的网络的另一种选择。微调显著提高了[13]、[14]的适应能力;但是,需要对训练数据进行进一步的注释。第一个用于图像检索的微调方法是由Babenko等人[15]提出的,其中需要大量的手工工作来收集图像并将其标记为特定的构建类。它们提高了检索的准确性;但是,它们的公式更接近于分类,而不是期望的实例检索属性。在另一种方法中,Arandjelovic等人[16]在geo-tagged的图像数据库的指导下进行微调,与我们的工作类似,他们通过选择匹配和非匹配对进行训练,直接优化最终任务中使用的相似性度量。与之前用于图像搜索的训练数据采集方法不同,我们无需手动标注数据或对训练数据集进行任何假设。我们利用structure-from-motion(SfM)管道自动重建三维模型的几何图形和摄像机位置来实现这一点。最先进的retrieval-sfm管道[17]以无序的图像集合作为输入,并尝试构建所有可能的3D模型。为了提高处理效率,采用了快速的图像聚类方法。引入了多种基于局部特征的图像聚类方法[18]、[19]、[20]。通过空间验证,这些方法发现的聚类是可靠的。实际上,这些方法不仅提供了集群,还提供了集群图像上的匹配图或子图。SfM过滤掉几乎所有不匹配的图像,并为集群中所有匹配的图像提供图像到模型的匹配和相机位置。整个过程,从无序的图像收集到详细的三维重建的过程是全自动的。最后,三维模型指导匹配和非匹配对的选择。我们提出利用描述符后处理阶段的训练数据去学习一个识别whitening(sfm就是用来构建训练数据的)。
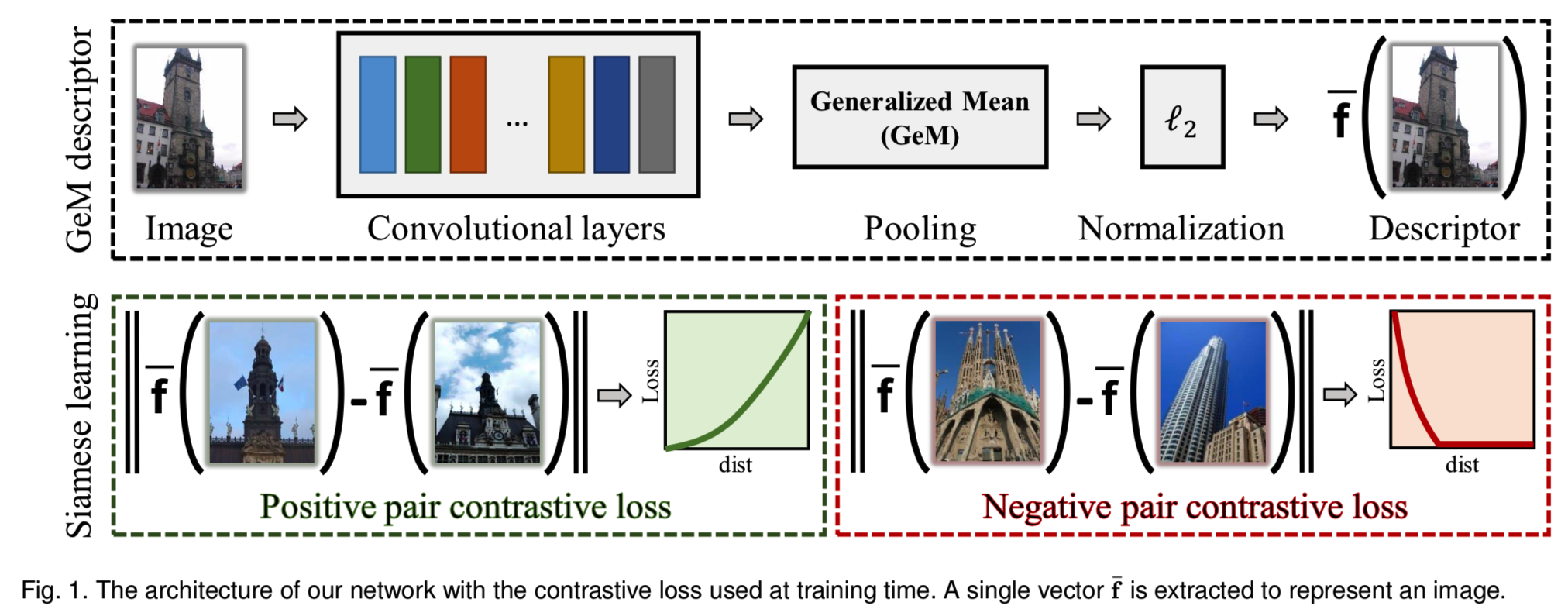
这项工作的另一个贡献是在卷积层之后引入了一个新的池化层。在此之前,使用了许多方法。这些范围从全连接层[8]、[15]到不同的global-pooling层,如max pooling [9], average pooling [10], hybrid pooling [21], weighted average pooling [11], and regional pooling [12]。我们提出了一个基于generalized-mean的池化层,它具有可学习的参数,可以是一个全局参数,也可以是每个输出维度一个参数。最大池和平均池都是它的特殊情况。我们的实验表明,与标准的不可训练池层相比,它提供了一个显著的性能提升。我们的体系结构如图1所示。
综上所述,我们讨论了用于图像检索的CNNs的无监督微调。特别是我们在以下方面做出了贡献:(1)我们利用SfM信息,在CNN训练中不仅执行难非匹配(negative)例子,而且执行难匹配(positive)例子。这显示了增强派生图像表征。我们表明,与以前的监督方法相比,三维重建训练数据的可变性在图像检索任务中提供了优越的表现。(2)我们表明,传统上在短表征[22]上进行的whitening在某些情况下是不稳定的。我们建议通过相同的训练数据来学习whitening。它的作用是对微调的补充,并进一步提高性能。另外,与从头到尾学习whitening相比,作为后处理步骤进行whitening训练效果更好,也更快。(3)我们提出了一个可训练的池化层,该池化层是对现有流行的CNNs池化方案的总结。在保持描述符维数不变的情况下,显著提高了检索性能。(4)此外,我们提出了一种新的α-weighted的查询扩展,与广泛用于压缩图像表征的标准平均查询扩展技术相比,该查询扩展具有更强的鲁棒性。(5)最后,通过对常用的CNN架构(如AlexNet [1], VGG [23], ResNet[24])的重新训练,我们在Oxford Buildings, Paris,和Holidays数据集中得到了一个新的最先进的结果。
这份手稿是我们之前工作[25]的延伸。此外,我们还提出了一种新的池化层(3.2)、一种新的多尺度图像表示(5.2节)和一种新的查询扩展方法(5.3节)。每一种新提出的方法都提高了图像检索的性能,并伴随着提供有用见解的实验。此外,我们提供了一个扩展的相关工作讨论,包括在以前的CNN研究中使用的不同pooling程序和描述符whitening中。最后,我们将我们的方法与Gordo等人[26]、[27]的并行相关工作进行比较。通过结合特定建筑区域建议的端到端学习,显著提高了检索性能。与他们的工作相反,我们关注hard-trainning数据示例的重要性,并使用了一个简单得多但同样强大的池化层。
本文的其余部分组织如下。第二节讨论了相关工作,第三节介绍了我们的网络架构、学习过程和搜索过程,第四节描述了我们提出的自动获取训练数据的方法。最后,在第5节中,我们对不同CNN架构下提出的所有新奇事物进行了广泛的定量和定性评估,并将其与当前的技术状态进行比较。
2 RELATED WORK
基于CNN的表征对于图像检索是一种很有吸引力的解决方案,特别是对于紧凑的图像表示。以前的紧凑描述符通常是由局部特征的集合构造的,其中代表是Fisher向量[28]、VLAD[29]和alternatives[30]、[31]、[32]。令人印象深刻的是,在这项工作中,我们发现CNNs在图像搜索任务中占据主导地位,通过合并大型可视码本[33]、[34]、空间验证[33]、[35]和查询扩展[36]、[37]、[38],其性能超过了目前最先进的方法。
在本研究中,将实例检索转换为一个度量学习问题,即学习图像embedding,使欧氏距离能很好地捕捉相似度。典型的度量学习架构,如双分支siamese[39]、[40]、[41]或triplet网络[42]、[43]、[44]采用匹配和非匹配对来执行训练,更好地适应这项任务。在这里,注释的问题更加明显,即,对于分类,只需要对象类别标签,而对于特定对象,标签必须是每个图像对。同一类物体的两幅图像可能完全不同,例如建筑物的不同视角或不同的建筑物。我们从一个大型无序的图像集合开始,以完全自动化的方式解决这个问题,不需要任何人工干预。
在接下来的文本中,我们将讨论我们的主要贡献的相关工作,即训练数据的收集,构建全局图像描述子的pooling方法,和描述子whitening。
2.1 Training data
之前的各种方法将CNN激活应用于图像检索[8]、[9]、[10]、[11]、[12]、[45]任务。在检索上取得的准确性是CNNs泛化特性的证据。利用ImageNet数据集[2]对所使用的网络进行分类训练,使分类误差最小化。Babenko等人更进一步,用更接近目标任务的数据集对这些网络进行重新训练。它们使用对应于特定地标/建筑物的对象类进行训练。性能提高了标准检索基准。尽管取得了成就,但最终的度量和被利用的层与在学习过程中实际优化的是不同的。
构建这样的训练数据集需要人的努力。在最近的工作中,带有时间戳的地理标记数据集为triplet网络[16]的弱监管微调提供了基础。两幅距离较远的图像很容易被认为是不匹配的,而匹配的例子选择的是最相似的附近图像。在后一种情况下,相似性是由CNN的当前表征来定义的。这是为图像检索,特别是地理定位任务执行端到端微调的第一种方法。使用的训练图像现在与最终任务更加相关。我们通过在无监督的方式发现匹配和非匹配的图像对来区分。此外,我们基于三维重建方法推出的匹配例子,这允许更难的例子。
虽然难负样本挖掘是一个标准过程[6],[16],但难正样本挖掘不是。在Simo-Serra等人的工作[46]中挖掘了难正样本,其中patch-level的样本是通过三维重建的指导提取的。必须仔细取样难正样本对。极端难正样本(例如图像之间最小的重叠或极端的尺度变化)不允许泛化并导致过度拟合。
我们的一个并行工作也使用局部特征和几何验证来选择正样本[26]。与我们完全无监督的方法相反,它们从必须手动清理的地标数据集开始,使用数据集的地标标签,而不是几何图形,以避免彻底评估。Noh等人[47]使用相同的训练数据集去学习使用saliency mask的全局图像描述符。然而,在测试期间,CNN激活被视为局部描述符,独立地建立索引,并用于随后的空间验证阶段。与全局描述符相比,这种方法提高了准确性,但代价是更高的复杂性。
2.2 Pooling method
早期将CNNs应用于图像检索的方法包括将全连接层激活设置为全局图像描述符[8]、[15]的方法。Razavian等人[9]的工作将重点转移到后面跟着global-pooling操作的卷积层的激活。用这种方法构造了一种紧凑的图像表示,其维数与对应卷积层的特征图个数相等。特别是,他们建议使用max pooling,这后来被近似为integral pooling[12]。
sum pooling最初是由Babenko和Lempitsky[10]提出的,它展示了良好性能,特别是由于随后的描述符whitening操作。进一步发展的是Kalantidis等人[11]的weighted sum pooling,也可以看作是进行迁移学习的一种方式。在Mohedano等人[48]、Arandjelovic等人[16]、Ong等人[49]的工作中,我们在使用CNN激活的情况下分别采用了常用的BoW、VLAD、Fisher vector等编码方法。一旦预先执行了适当的embedding,就会使用sum pooling。
一种混合方案是R-MAC方法[12],它对区域执行max pooling,最后对区域描述符进行sum pooling。Mixed pooling全局应用于检索[21],采用标准local pooling进行对象识别[50]。它是max pooling和sum pooling的线性组合。Cohen等人在[51]的工作中提出了一个类似于我们的泛化方案,但在不同的背景下。它们将标准的local 马戏pooling替换为通用的版本。最后,More're s等[52]使用generalized mean对多次变换下的相似度值进行聚类。
2.3 Descriptor whitening
自从Je ́gou and Chum [22]的研究后,发现对图像检索的数据表征进行whitening是非常必要的。他们的解释在于其能够降低共现的权重,从而处理over-counting的问题。在基于CNN的描述符[5],[10],[12]的情况下,whitening的好处被进一步强调。whitening通常是通过PCA在独立数据集上以无监督的方式从生成模型中学习。
我们建议以一种可区分的方式学习whitening变换,使用相同的3D模型训练数据的获取过程。Mikolajczyk和Matas[53]使用了类似的方法来whitening局部特征描述符。
而Gordo等[26]则在CNN中以端到端的方式学习whitening。在我们的实验中,我们发现这种选择最多和描述符后处理的方法一样好,而且由于学习收敛速度较慢,效率较低。(所以还是用后处理的方法)
3 ARCHITECTURE, LEARNING, SEARCH
在本节中,我们将描述网络架构,并介绍所提议的generalized-pooling层。然后,我们解释了利用contrastive loss和双分支网络进行微调的过程。我们描述了在经过微调之后,我们如何使用相同的训练数据来学习似乎是一个有效的后处理步骤的投影。最后,我们描述了图像的表征、搜索过程和一种新的查询扩展方案。我们建议的体系结构如图1所示。
3.1 Fully convolutional network
我们的方法适用于任何全卷积的CNN[54]。在实际应用中,我们采用了常用的用于通用对象识别的CNNs,如AlexNet[1]、VGG[23]、ResNet[24]等,舍弃了它们的全连接层。这为执行微调提供了良好的初始化。
现在,给定一个输入图像,输出是一个维度为WxHxK的3维tensor ![]() ,其中K是最后一层的特征映射数量。
,其中K是最后一层的特征映射数量。![]() 为特征映射的WxH激活集合,
为特征映射的WxH激活集合,![]() 。网络输出包含了K个这样的激活集合或2维特征映射。我们额外假设最后一层为Rectified Linear Unit (ReLU),这样
。网络输出包含了K个这样的激活集合或2维特征映射。我们额外假设最后一层为Rectified Linear Unit (ReLU),这样![]() 的值就是非负的。
的值就是非负的。
3.2 Generalized-mean pooling and image descriptor
我们现在添加一个以![]() 作为输入的pooling层,然后生成一个向量f作为pooling过程的输出。这个向量在往常的global max pooling(MAC vector [9], [12]) 情况下为:
作为输入的pooling层,然后生成一个向量f作为pooling过程的输出。这个向量在往常的global max pooling(MAC vector [9], [12]) 情况下为:
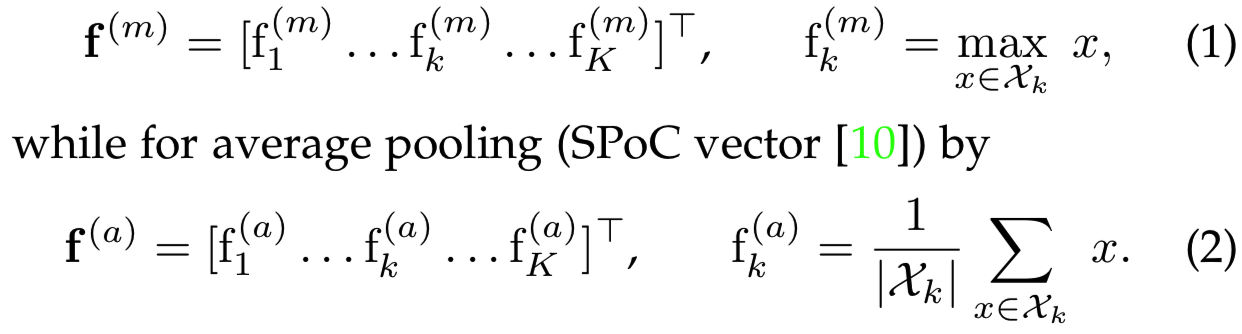
相反,我们利用generalized mean[55]和使用generalized-mean(GeM) pooling,其结果如下给出:
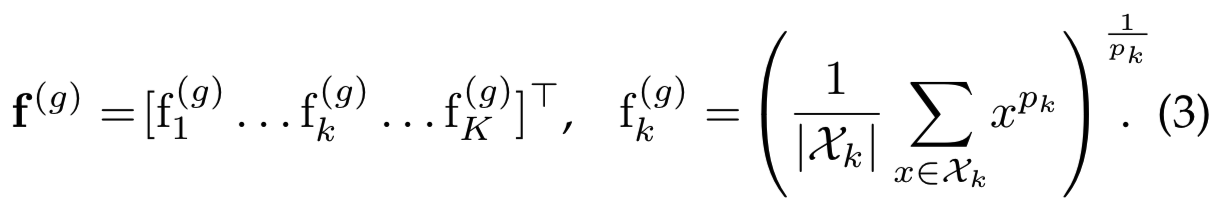
pooling方法(1)和(2)是(3)中给定的GeM pooling的特殊情况,即当![]() 时等价于max pooling,pk=1时等价于average pooling。最终特征映射由每个特征图的一个单一的值组成,即generalized-mean激活,其维数等于k。对于许多流行的网络来说,这等于256、512或2048,使其成为一种紧凑的图像表征。
时等价于max pooling,pk=1时等价于average pooling。最终特征映射由每个特征图的一个单一的值组成,即generalized-mean激活,其维数等于k。对于许多流行的网络来说,这等于256、512或2048,使其成为一种紧凑的图像表征。
pooling参数pk可以手动设置或学习,因为这个操作是可微的,并且可以作为反向传播的一部分。对应的导数(为了简洁跳过上标(g))如下给出:
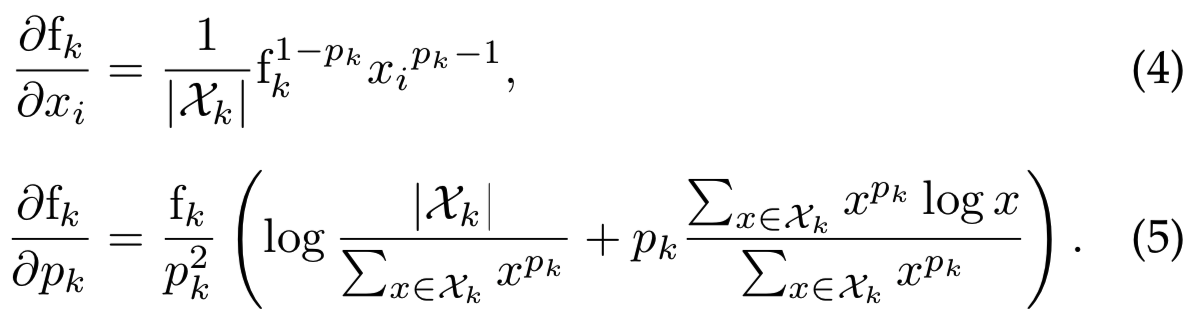
在(3)中,每个特征映射都有一个不同的pooling参数pk,但是也可以使用一个共享的pooling参数。在![]() 这种情况下,我们将pk其简化表示为p。我们在实验部分检查了这些选项,并与手动调优和固定参数值进行了比较。
这种情况下,我们将pk其简化表示为p。我们在实验部分检查了这些选项,并与手动调优和固定参数值进行了比较。
Max pooling,在MAC的情况下,每个2维特征映射保留一个激活。这样,每个描述符分量对应于一个等于接受域的图像patch(即选中的那个最大值激活对应的patch)。然后,通过描述子内积对图像相似度进行评估。因此,MAC相似度隐式地形成了patch correspondences。每个correspondence的强度由相关描述符分量的乘积给出。在图2中,我们展示了对相似度贡献最大的对应图像patch。通过微调,隐式对应得到了改善。此外,CNN较少在ImageNet类上fires,例如汽车和自行车。

在图4中,我们显示了激活的空间分布如何受到generalized mean的影响。p值越大,特征图响应的局部化程度越高。(因为p越大,generalized mean约类似max-pooling,那么得到的特征的一个分量就越类似于整个特征图中的最大激活值,一个值对应的接受域当然更小,所以更集中)

最后,在图3中,我们展示了一个查询示例和一个数据库图像,使用带有GeM池化层(简称GeM层)的微调VGG进行匹配。我们展示了在将数据库图像与具有很大相似性的非匹配图像区分开来方面贡献最大的特征映射。
最后的网络层包括l2归一化层。对向量f进行l2归一化,最终用内积计算两幅图像之间的相似性。在本文的其余部分,GeM向量对应l2-normalized向量̄f 且构成了图像描述符。

3.3 Siamese learning and loss function
我们采用siamese结构并训练一个双分支网络。每个分支都是另一个分支的克隆,这意味着它们共享相同的参数。训练输入由图像对(i,j)和标签Y(i,j)∈{0,1},声明对是不匹配的(label 0)还是匹配的(label 1),我们使用作用于匹配和不匹配对的contrastive 损失[39],定义为:
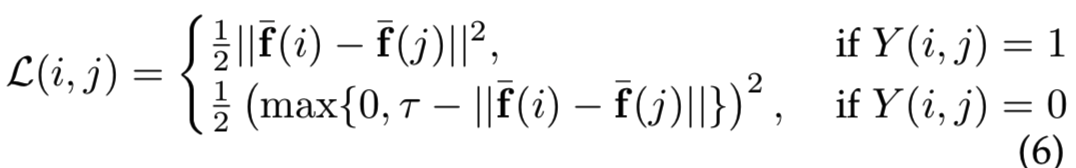
其中![]() 是图像i的L2归一化后的GeM向量,
是图像i的L2归一化后的GeM向量,![]() 是一个边际参数,即表示不匹配的对有足够大的距离可以被损失忽略(即如果不匹配对的距离差大于
是一个边际参数,即表示不匹配的对有足够大的距离可以被损失忽略(即如果不匹配对的距离差大于![]() ,那就说明他们的区别很大,对训练模型没有什么帮助)。我们使用自动创建的大量训练对 对网络进行训练(见第4节)。与其他方法[16]、[42]、[43]、[44]相比,我们发现contrastive损失比triplet损失具有更好的泛化性和更高的收敛性能。
,那就说明他们的区别很大,对训练模型没有什么帮助)。我们使用自动创建的大量训练对 对网络进行训练(见第4节)。与其他方法[16]、[42]、[43]、[44]相比,我们发现contrastive损失比triplet损失具有更好的泛化性和更高的收敛性能。
3.4 Whitening and dimensionality reduction
白化Whitening类似于PCA主成份分析,目的是降低数据的冗余性同时降维
在本节中,我们将考虑对经过微调的GeM向量进行后处理。以往的方法[10]、[12]采用独立集的主成分分析法(PCA)进行白化(whitening)和降维,即分析所有描述符的协方差矩阵。我们建议利用由3D模型提供的标记数据,并使用最初由Mikolajczyk和Matas[53]提出的线性判别投影。投影分解为两部分:白化和旋转。白化部分是类内(匹配对)协方差矩阵的平方根的逆-![]() ,即:
,即:
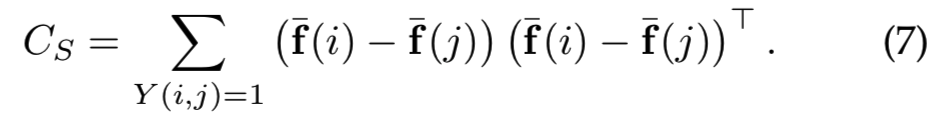
旋转部分是在白化空间![]() ,类间(不匹配对)协方差矩阵的PCA,即:
,类间(不匹配对)协方差矩阵的PCA,即:
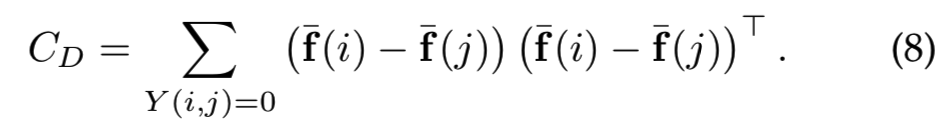
然后投射![]() 被应用成
被应用成![]() ,其中μ是实现中心化的mean GeM向量。为了将描述符维数降至D维,只使用与D个最大特征值对应的特征向量。投影向量随后被l2归一化。
,其中μ是实现中心化的mean GeM向量。为了将描述符维数降至D维,只使用与D个最大特征值对应的特征向量。投影向量随后被l2归一化。
我们的方法利用所有可用的训练对有效地优化白化。它不是以端到端的方式进行优化的,并且在执行时没有使用成批的训练数据。我们首先优化GeM描述符,然后优化白化。
一旦CNN的微调完成,所描述的方法作为一个后处理步骤。此外,我们还与端到端的白化学习方法进行了比较。白化由向量移动和投影组成,通过一个全连接层以一种直接的方式建模。结果支持我们的方法,并在实验部分进行了讨论。
3.5 Image representation and search
训练完成后,将图像输入到如图1所示的网络中。提取的GeM描述符被白化并重新规范化。这构成了图像在单一尺度上的全局描述符。通过训练样本在一定程度上学习了尺度不变性;在测试过程中,通过多尺度处理增加了额外的不变性,而不需要额外的学习。我们采用标准的[27]方法,以多种尺度将图像输入网络。最终将生成的描述符汇集并重新规范化。这个向量构成了一个多尺度的全局图像表征。我们对这种状态也采用了GeM pooling,在我们的实验中显示,它始终优于标准平均池化。
图像检索仅通过对数据库描述符w.r.t.查询描述符的穷举欧几里得搜索来实现。这等价于l2标准化向量(即vector-to-matrix的乘法和排序)的内积求值。基于CNN的描述符与近似近邻搜索方法高度兼容,事实上,它们是高度可压缩的[27]。为了直接评估学习的表示的有效性,我们在本研究中不考虑这种替代方法。实际上,每个描述符每个维度需要4个字节存储。
最近,将CNN全局图像描述符与简单平均查询扩展(AQE)[10],[11],[12],[27]相结合已经成为一种标准策略。(query expansion(QE)也是目前图像检索的常用手段,最基本的方法是average query expansion(AQE),即搜索图片后得到前n个最近似的图片,取它们和待检索图片的均值,再进行二次搜索,这样用近似图像填补了待检索图像的某些特征。)初始查询由欧几里得搜索发出,AQE通过对nQE图像的描述符进行平均池化对其进行处理。在这里,我们认为调优nQE以跨不同数据集工作并不容易。AQE对应一个加权平均,其中nQE描述符有着单位权重,剩下的即为零。我们推广了该方案,并提出了加权平均,其中排第i位的图像的权值为 ![]() 。每个检索图像的相似性很重要。我们的实验表明,AQE很难调优不同的统计数据集,但是我们提出的方法可以。我们将这种方法称为α-weighted的查询扩展(αQE)。对于α= 0,所提出的αQE方法将变为AQE方法。
。每个检索图像的相似性很重要。我们的实验表明,AQE很难调优不同的统计数据集,但是我们提出的方法可以。我们将这种方法称为α-weighted的查询扩展(αQE)。对于α= 0,所提出的αQE方法将变为AQE方法。
4 TRAINING DATASET
在本节中,我们简要总结了紧密耦合的Bag-of-Words (BoW) 图像检索和Structure-from-Motion (SfM)重建系统[17]、[56],该系统用于自动选择我们的训练数据。然后,我们描述了如何利用三维信息来选择差异性较大的难匹配配对和难非匹配配对。
4.1 BoW and 3D reconstruction
Schonberger et al.[17]工作中使用的检索引擎建立在具有快速空间验证[33]的BoW上。它使用Hessian仿射局部特征[57],RootSIFT描述符[58],以及带有16M大小的visual words[59]的精细词汇表。然后,通过如[18]中的min-hash和空间验证选择查询图像。采用基于BoW的图像检索方法对目标/地标进行图像采集。这些图像作为后续SfM重建的初始匹配图,该重建使用最先进的SfM管道[60],[61],[62]。不同的挖掘技术,如zoom in, zoom out[63],[64],sideways crawl[17],有助于构建更大更完整的模型。
在这项工作中,我们利用了这样一个系统的成果。对于一个大型的未注释图像集合,对图像进行聚类,每个聚类构建一个三维模型。我们可以互换使用术语3D模型、模型和聚类。对于每一幅图像,估计的相机位置以及注册在3D模型上的局部特征都是已知的。我们删除了冗余的(重叠的)3D模型,这些模型可能是由不同的种子构建的。从不同的、不相交的视点重建同一landmarks的模型被认为是不重叠的。
4.2 Selection of training image pairs
三维模型被描述为bipartite visibility graph G = (I∪P,E)[65],其中图像I和点P是图的顶点。这个图的边是由摄像机与点的可见性关系定义的,即,如果一个点p∈P在一个图像i∈I 中是可见的,那么存在一条边(i, p)∈ε。从图像i观察得到的点的集合为:
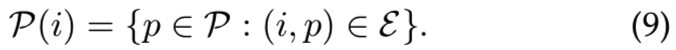
我们创建一个元组数据集(q, m(q),N(q)),其中q表示查询图像,m(q)是一张与查询匹配的正图像,N(q)是一组与查询不匹配的负图像。这些元组用来形成训练图像对,每个元组对应|N(q)| + 1对(即负样本集和查询图像是|N(q)|对,正样本和查询图像是1对)。对于查询图像q,根据q的聚类中摄像机的位置构造一个候选正图像池M(q),其由k幅相机中心最接近查询图像的图像组成。由于相机的方向范围很广,这些不一定描绘同一对象。因此,我们比较了三种不同的方法来选择正图像。三种策略的正样本在整个训练过程中都是固定的。
Positive images: CNN descriptor distance. 正式来说,将与查询图像有着最小的描述符距离的图像被选择为正样本:
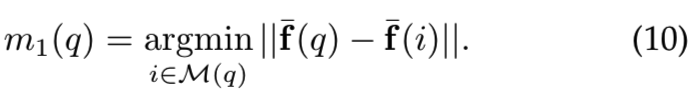
这种策略类似于Arandjelovic et al .[16]中的策略。他们采用这种选择,因为只有GPS坐标是可用的,而没有相机的方向。因此,所选择的匹配图像已经具有较小的描述符距离,因此损失也较小。这样,网络就不能通过匹配的例子来进行强的改变/学习(即不利于高效调参),这是这种方法的缺点。
Positive images: maximum inliers.在这种方法中,利用三维信息来选择正图像,而不依赖于CNN描述符。特别是,选择与查询图像有着最多co-observed 3D点的图像(即3D点交集最多的图)。也就是说,
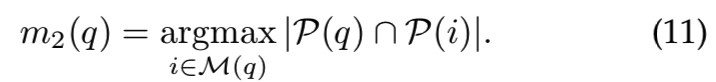
该度量对应于两幅图像之间空间验证的特征的数量,这是基于BOW的检索中常用的排序度量。由于这种选择独立于CNN的表示,它提供了更具挑战性的正样本。
Positive images: relaxed inliers.尽管前面的两种方法都选择与查询图像描述相同对象的图像作为正图像,但是这些图像的视点的变化是有限的。与使用具有相似相机位置的一组图像不同,这里的正样本是从一组图像中随机选择的,这些图像与查询图像有着多的co-observed点,但不会显示太极端的比例变化。这个方法的正样本是(即随机选择观察点在一定范围之内的,且比例变化不大的图作为正例):
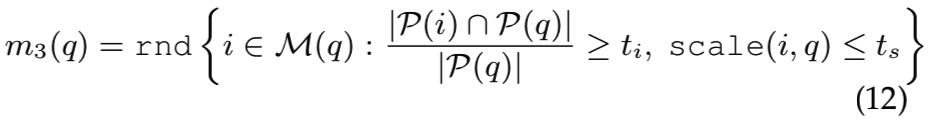
其中,scale(i,q)为两幅图像之间的尺度变化。这种方法的结果是选择了harder匹配的例子,但仍然保证描述相同的对象。方法m3在86.5%的查询中选择了与m1不同的图像。在图6中,我们展示了使用三种不同方法选择的查询图像和相应的正样本。该relaxed方法增加了视点的可变性。

Negative images.负样本从与查询图像的集群不同的集群中选择,因为这些集群没有重叠。我们选择难负样本[6]、[46],即描述符最相似的非匹配图像。提出了两种不同的策略:第一种,从所有非匹配图像中选择N1(q), 即k个最近邻。在第二组中,N2(q)使用了同样的准则,但每个集群最多允许一幅图像。N1(q)常常导致同一对象的多个非常相似的实例,而N2(q)则提供了更多的负样本,如图5所示。正的例子在整个训练过程中都是固定的,而难负样本则依赖于当前的CNN参数,并且在每个epoch中被重复挖掘多次。

5 EXPERIMENTS
在本节中,我们将讨论训练的实现细节,评估方法的不同组件,并与最新的技术进行比较。
5.1 Training setup and implementation details
Structure-from-Motion (SfM)。我们的训练样本来自Schonberger et al.[17]研究中使用的数据集,该数据集由740万张从Flickr下载的图片组成,使用的关键词是世界各地的流行地标、城市和国家。[18]聚类过程提供了大约20k幅图像作为查询种子。整个数据集的extensive retrieval-SfM reconstruction [56]得到1474个重建的三维模型。去除重叠的模型留给我们的是713个3D模型,其中包含了超过163k个来自原始数据集的unique图像。初始数据集包含Oxford5k和Paris6k数据集的所有图像。通过这种方式,我们能够从这些测试数据集中排除98个包含任何图像(或它们近似重复的图像)的集群。
Training pairs. 3D模型的大小从25到11k图像不等。我们随机选择551个模型(约133k张图像)进行训练,162个模型(约30k张图像)进行验证。每个3D模型的训练查询次数为其大小的10%,限制为小于或等于30。每个epoch分别选择大约6000和1700幅图像进行训练和验证查询。
每个训练和验证元组包含1个查询、1个正图像和5个负图像。候选正样本的集合由k = 100幅图像组成,这些图像的中心距离查询最近。特别地,对于m3方法,inlier-overlap阈值为ti = 0.2, scale-change阈值为ts = 1.5。难负样本在每个epoch中被重新挖掘3次,即大约每2000(=6000*3)个训练查询一次。给定所选择的查询和所选择的正样本,我们在每个模型中进一步添加20张图像,作为重新挖掘的候选负样本。当使用所有的3D训练模型时,这构成了一个大约每epoch有22k张图像的训练集。query-tuple的选择过程在每个epoch中重复。这略微改善了结果。
Learning configuration. 我们使用MatConvNet[66]对网络进行微调。为了执行第3节中描述的微调,我们通过AlexNet[1]、VGG16[23]或ResNet101[24]的卷积层进行初始化。AlexNet使用随机梯度下降(SGD)训练,而使用Adam训练VGG和ResNet更稳定[67]。我们对SGD使用初始学习速率等于l0 = 10−3,为Adam使用初始stepsize等于l0 = 10−6,在epoch i中一个指数衰减为l0*exp(−0.1i),momentum为0.9,权重衰减为5×10−4,对于AlexNet的contrastive loss设置margin τ=0.7, VGG设置τ=0.75,和ResNet为τ=0.85,由embedding维数的增加证明该设置的合理性,同时batch size设置为5。所有训练图像的最大大小为362×362,同时保持原始长宽比。训练最多进行30个epoch,并根据性能选择最佳网络,性能通过对验证元组测量mean Average Precision (mAP) [33]来得到。在一个12gb内存的TITAN X (Maxwell) GPU上,VGG的一次epoch微调大约需要2个小时。
我们通过将每个查询关联到一个元组来克服GPU内存限制,即,查询加6个图像(5个正的和1个负的)。而且,整个元组在同一批中处理。因此,我们将7幅图像输入网络,即6对图像。在一种简单的方法中,当每对查询图像不同时,6对需要12个图像(所以当这里6对只需要用7张图,就能够解决GPU内存限制问题)。
5.2 Test datasets and evaluation protocol
Test datasets. 我们对 Oxford buildings [33], Paris [68] and Holidays2 [69]数据集进行了评估。前两个更接近我们的训练数据,而最后一个是区分包含相似的场景,而不仅仅是人造物体或建筑物。这些还与来自Oxford100k数据集的干扰物相结合,以允许在更大的规模上进行评价。性能是通过mAP来衡量的。我们遵循Oxford和Paris的标准评估协议,并使用提供的边框来裁剪查询图像。裁剪后的图像作为输入输入给CNN。
Single-scale evaluation. 输入CNN的图像维数限制为1024×1024像素。在我们的实验中,如果没有其他说明,不应用vector post-processing 。
Multi-scale evaluation. 多尺度表征只在测试时使用。我们将输入图像的大小调整为不同的大小,然后将多个输入图像输入到网络中,最后将多个尺度的全局描述符组合成一个描述符。我们将基线平均池化[27]与我们的generalized mean相比较,我们方法的池化参数等于在网络全局池化层中学习到的值。在这种情况下,whitening是在最终的多尺度图像描述符中学习。在我们的实验中,如果没有其他说明,则使用单尺度评价。
5.3 Results on image retrieval
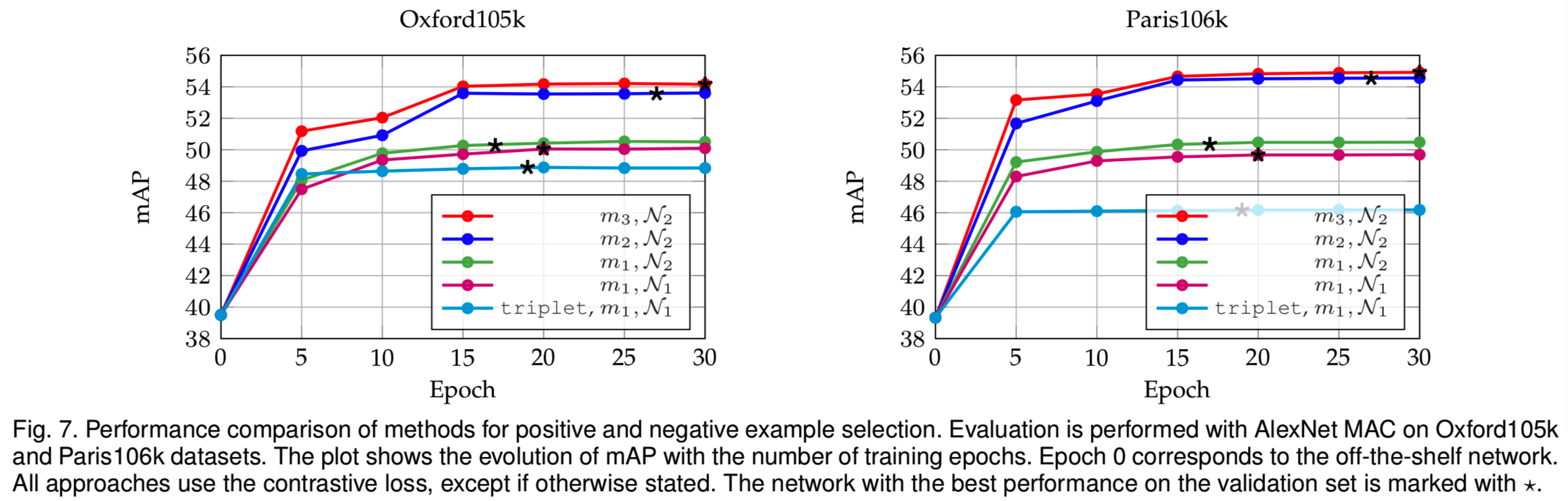
Learning. 我们在不同的训练epochs训练后,评估现成的CNN和我们的微调模型。不同的正和负样本选择的方法被独立地评估,以分离各自的好处。最后,我们还与triplet loss[16]进行了比较,其是在与contrastive loss相同的训练数据上训练的。注意,一个triplet构成两对数据。结果如图7所示。结果表明,具有较大视点可变性的正样本和具有较大内容可变性的负样本在性能上有一致的提高。在我们的环境中,triplet loss似乎效果不太好;我们观察到验证集早期误差的振荡,这意味着过拟合。在本文的其余部分,我们采用了m3,N2的方法。
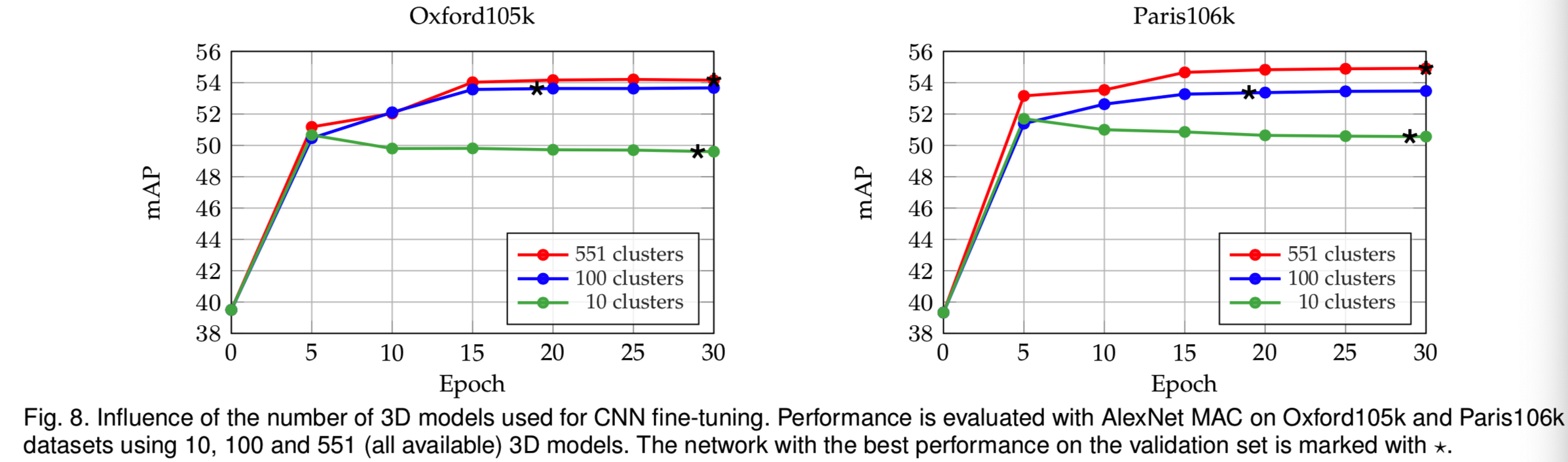
Dataset variability.我们通过使用可用的3D模型的一个子集来进行微调。图8显示了10、100和551(都是可用的)集群的结果,同时保持训练数据的数量,即训练查询的数量不变。在10个和100个models的情况下,我们使用最大的model。最好使用所有的3D模型进行训练,这样训练集的可变性会更高。值得注意的是,即使使用10个或100个模型,性能也会有显著提高。然而,在集群数量较少的情况下,网络会出现过度拟合。在接下来的实验中,我们使用551个3D模型进行训练。
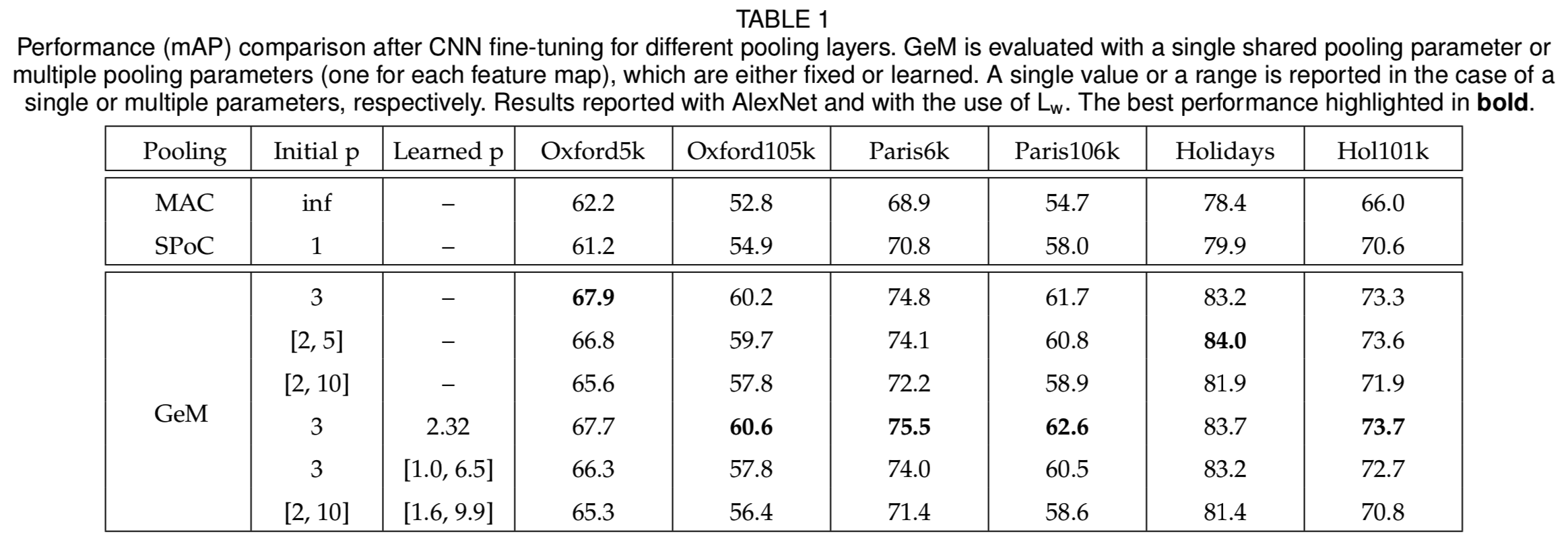
Pooling methods. 我们在CNN微调过程中评估不同池化层的效果。我们将结果显示在表1中。GeM层始终优于传统的最大和平均池化。这对以下情况都适用:(i)使用参数为p的单一共享池, (ii)每个特征映射有不同的pk, (iii)池参数(s)是固定的或可学习的。学习一个共享参数比学习多个参数更好,因为后者使代价函数更加复杂。此外,初始值似乎在某种程度上也很重要,并且偏好中间值。最后,共享的固定参数和共享的学习参数的性能类似,后者稍微好一些。这就是我们在剩下的实验中采用的情况,即一个被学习的共享参数p。
Learned projections. 研究表明,在某些基于CNN的描述符[10]、[12]、[15]中,PCA-whitening [22] (PCAw) 是必不可少的。另一方面,在一些数据集上,PCAw之后的性能与原始描述符(Oxford5k[10]上的最大池化)相比大幅下降。我们将传统的whitening方法与3.4节所述的可学习的鉴别whitening(Lw)方法进行比较。表2显示了未进行后处理(post-processing)、使用PCAw和使用Lw的结果。
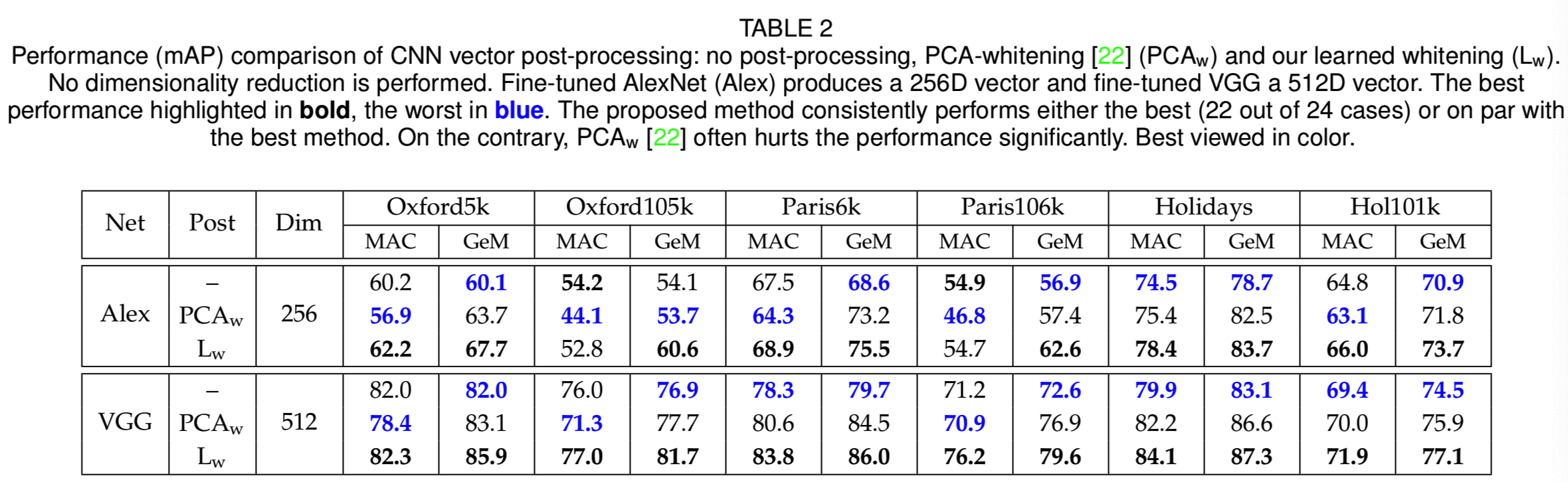
我们的实验证明,PCAw经常会降低性能。与之形成对比的是,所提出的Lw在大多数情况下都是最佳的,而不是最差的。与没有后处理的基线相比,Lw使AlexNet的性能降低了两倍,但是与PCAw相比,下降可以忽略不计。对于VGG,提出的Lw始终优于无后处理的基线。
我们进行了一个额外的实验,在微调过程中在网络末端添加了一个whitening层。通过这种方式,whitening以端到端的方式学习,同时使用卷积滤波器和以批处理模式学习相同的训练数据。Dropout[70]被另外用于这一层,我们发现这是必不可少的。我们观察到,在这种情况下,网络的收敛速度要慢得多,即需要60个epoch。而且,最终实现的性能并不高于我们的Lw。特别是,在AlexNet MAC上的端到端whitening在Oxford105k和Paris106k上结果分别为49.6 mAP和52.1 mAP,而我们在同一网络上的Lw在Oxford105k和Paris106k上结果分别为52.8和54.7 mAP。因此,我们采用Lw,因为它更快,更有效。
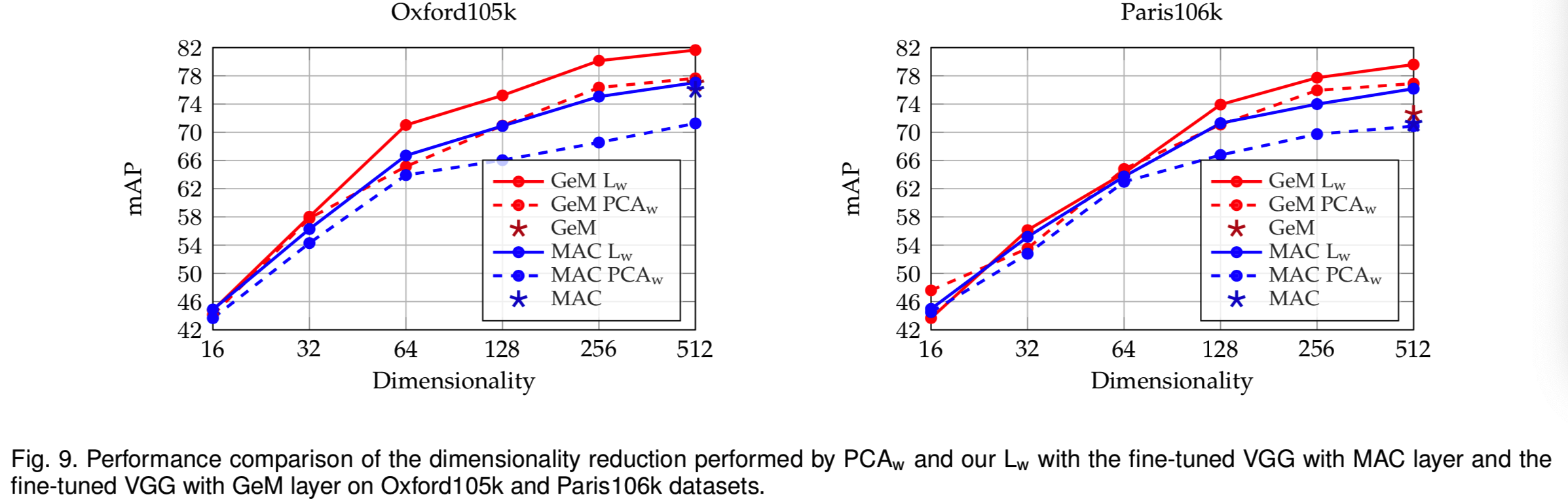
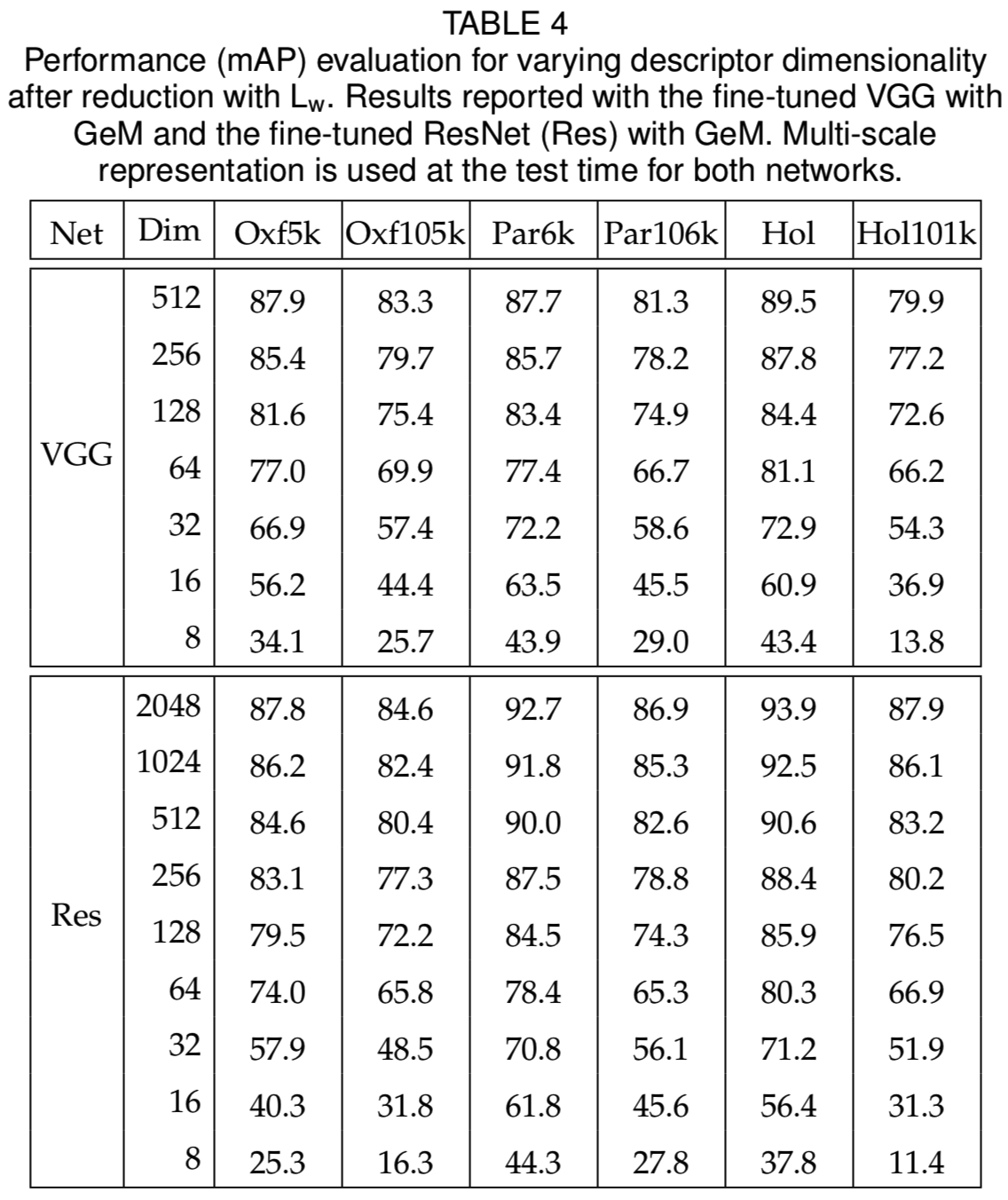
Dimensionality reduction. 我们比较了使用PCAw[22]和我们的Lw进行的降维。变化描述符维数的性能如图9所示。从图中可以看出,Lw在大多数维度上都更有效。
Multi-scale representation. 我们评估在测试时构造的多尺度表示法,而不需要任何额外的学习。我们在相同描述符伤比较了之前在多个图像尺度[27]上使用的描述符平均值和我们的generalized-mean。结果如表3所示,
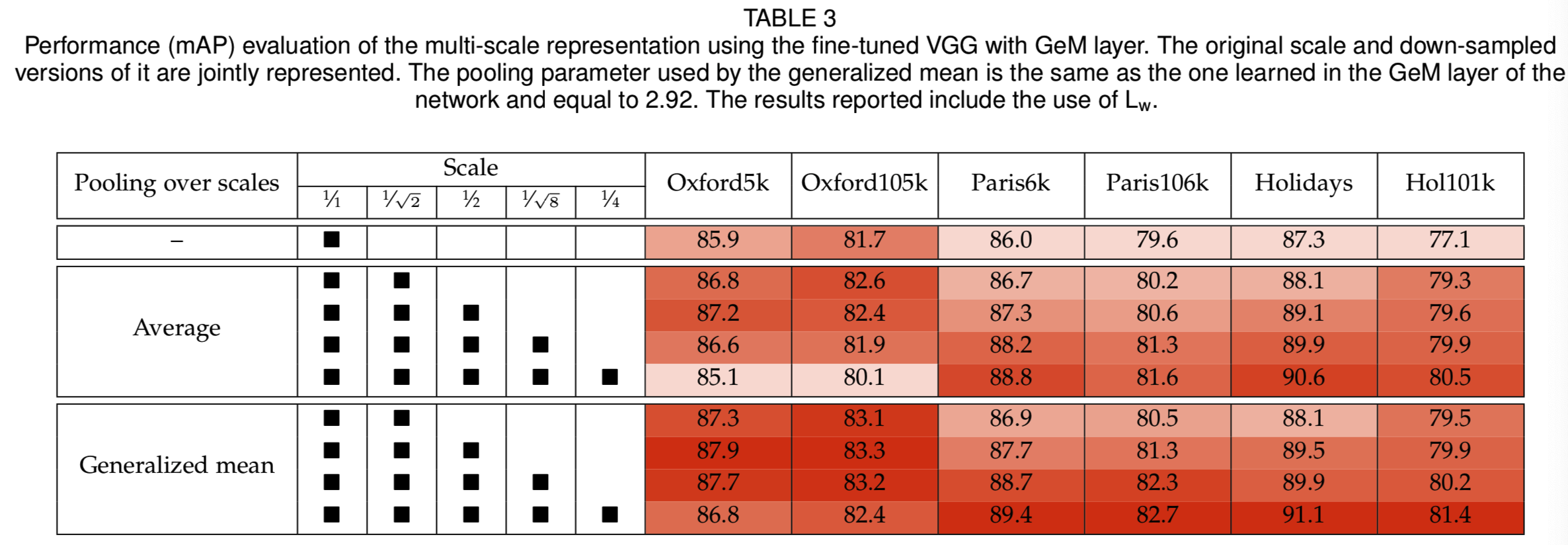
其中使用多尺度GeM有显著的好处。与平均池化相比,它还提供了一些改进。在我们的其他实验中,我们采用了多尺度表示,通过generalized mean池化,尺度为1,1/√2,和1/2。在多尺度GeM表示中使用Lw监督降维的结果如表4所示。
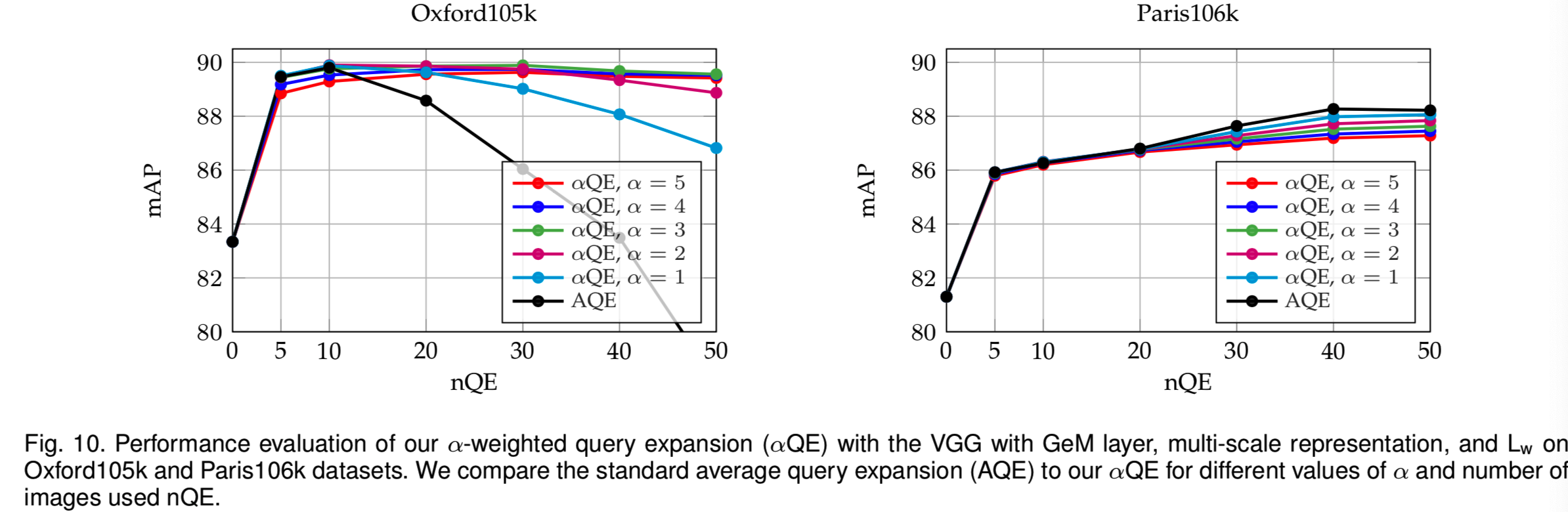
Query expansion. 我们评估了所提议的αQE,当α=0时其简化为AQE,并将结果显示在图10中。请注意,在每次查询的相关图像的数量方面,Oxford和Paris有不同的统计数据。在Oxford上,每次查询的正图像的平均、最小和最大数量分别为52、6和221。在Paris,同样的测量值是163、51和289。因此,AQE在这些数据集中以非常不同的方式运行,而我们的αQE是一个更稳定的选择。我们最终设置了α = 3,nQE = 50。
Over-fitting and generalization.在所有的实验中,包含任何来自Oxford5k或Paris6k数据集中的图像(不仅仅是查询地标)的聚类将被去除。我们现在使用所有的3D模型重复训练,包括那些Oxford和Paris地标。通过这种方式,我们评估网络是否倾向于过度拟合训练数据或泛化。为了进行公平的比较,使用了相同数量的训练查询。我们观察到网络在Oxford和Paris评估结果上的性能差异可以忽略不计,即mAP在所有测试数据集上的平均差异为+0.3。结果表明,该网络具有较好的泛化能力,对过拟合相对不敏感。
Comparison with the state of the art. 我们将我们的结果与压缩图像表示和查询扩展方法的最新性能进行了广泛的比较。表5将基于GeM的微调网络的结果与之前发布的结果汇总在一起。当使用VGG网络架构和初始化时,所提出的方法在所有数据集上的表现都超过了目前的水平。我们的方法被Gordo等人在Paris数据集上的ResNet架构的研究超越,而我们在Oxford的得分是最先进的。在Holidays数据集中,我们与最先进的水平相当。但是请注意,我们没有对我们的训练数据进行任何人工标记或清理,而在他们的工作中使用了landmarks标记。我们还将GeM与查询扩展(query expansion )相结合,进一步提高了性能。
6 CONCLUSIONS
我们讨论了用于图像检索的CNN的微调。训练数据是从一个应用在一个大的无序的照片收集上的自动三维重建系统中选择的。重建包括建筑物和流行地标;但是,相同的过程是适用于任何严格的3D对象的。该方法不需要任何手动注释,但在标准基准测试中获得了最佳性能。所获得的结果达到了基于局部特征的、具有空间匹配和查询扩展的最佳系统的水平,并且速度更快,所需内存更少。研究表明,所提出的池化层扩展了以往的检索机制,在提高检索精度的同时,也能有效地构造联合多尺度表示。训练数据、训练过的模型和代码都是公开可用的。