CurricularFace: Adaptive Curriculum Learning Loss for Deep Face Recognition
Abstract
作为人脸识别中的一个新兴课题,设计基于边界的损失函数可以增加不同类别之间的特征边界,增强识别能力。最近,采用了基于挖掘策略的思想来强调分类错误的样本,取得了良好的效果。然而,在整个训练过程中,以往的方法要么没有明确地根据样本的重要性来强调样本,使得困难样本没有被充分利用;或者在早期训练阶段就明确强调半困难/困难样本的效果,这可能会导致收敛问题。在这项工作中,我们提出一个新的自适应课程学习(Adaptive Curriculum Learning loss,CurricularFace)损失,其嵌入课程学习的想法到损失函数中来实现新的用于深度人脸识别的训练策略,主要解决训练早期阶段的容易样本和后期的困难样本。具体来说,我们的CurricularFace在不同的训练阶段自适应地调整容易和困难样本的相对重要性。在每个阶段,根据不同样本的难易程度,赋予不同的重要度。在流行的基准上进行的广泛实验结果证明了我们的CurricularFace对比最先进的竞争对手的优势。
1. Introduction
前三段又是介绍了下以前的人脸识别方法。基于边界的方法没能根据样本的重要性去显示地强调样本。基于挖掘的方法能够显示地强调半困难或困难样本的影响。
但是基于边界和基于挖掘的损失函数的训练策略都有缺点。传统的基于softmax的损失函数公式如下:
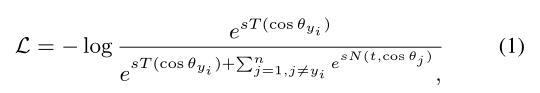
其中![]() 分别是定义正负cosine相似度的函数(即样本j的真实类别为yi,使用T函数计算cosine相似度;其他非对应类别使用N函数计算cosine相似度)。
分别是定义正负cosine相似度的函数(即样本j的真实类别为yi,使用T函数计算cosine相似度;其他非对应类别使用N函数计算cosine相似度)。![]() 表示负cosine相似度的调节系数,c为一个常数。对于基于边界的方法,挖掘策略是忽略的,因此每个样本的训练困难度并没有被探索。这样当在一个小的backbone,如MobileFaceNet, 中使用一个大的边界时,就会导致收敛问题。如图1所示:
表示负cosine相似度的调节系数,c为一个常数。对于基于边界的方法,挖掘策略是忽略的,因此每个样本的训练困难度并没有被探索。这样当在一个小的backbone,如MobileFaceNet, 中使用一个大的边界时,就会导致收敛问题。如图1所示:
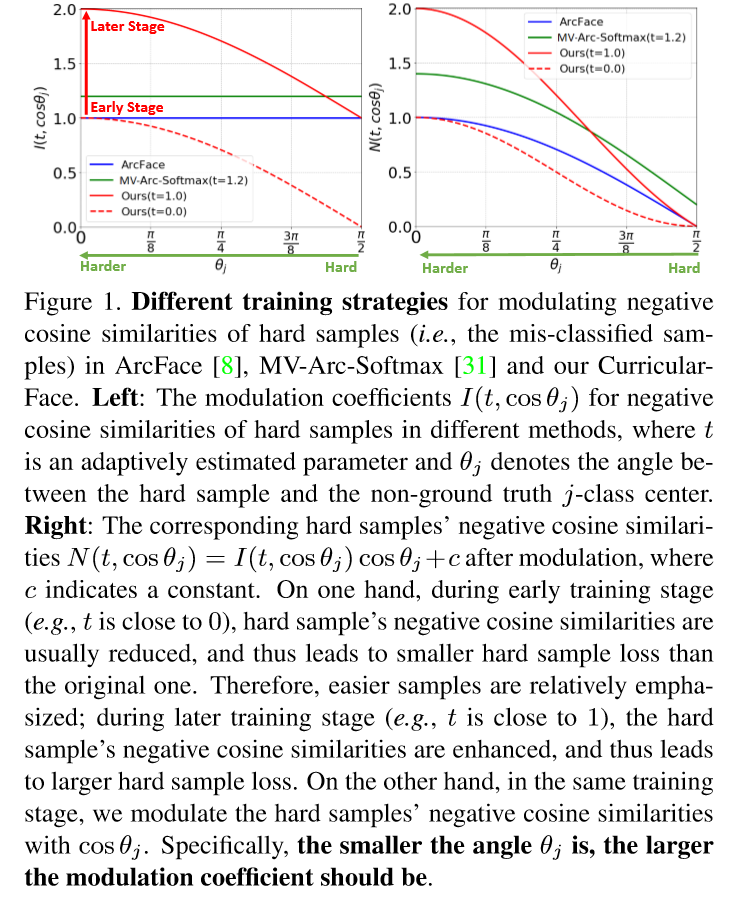
在ArcFace的整个训练过程中,所有样本的用于负cosine相似度的调节系数I(.)被固定为常数1。对于基于挖掘的方法,在早期训练阶段过于强调困难样本会阻碍模型的收敛。MV-Arc_softmax通过设置负样本相似度为![]() ,即
,即![]() ,其中t是一个手动定义的常量。如MV-Arc_softmax所说,t在模型收敛特性中有着重要作用。一个稍微增大的值(如1.4)可能导致模型难以收敛。因此t需要小心调整。
,其中t是一个手动定义的常量。如MV-Arc_softmax所说,t在模型收敛特性中有着重要作用。一个稍微增大的值(如1.4)可能导致模型难以收敛。因此t需要小心调整。
根据图1左边的图我们可见,ArcFace和MV-Arc_softmax两个负样本cosine相似度的调节系数I(.)都为一个常数,ArcFace的为1,没有强调困难样本;MV-Arc_softmax的大于1,从开始训练的时候就强调困难样本
我们提出了一个新的自适应课程学习损失,名为CurricularFace,为了在深度人脸识别中获得一个新的训练策略。受到人类学习的自然特性的启发,会先学习容易的样本,然后再学习难得样本。我们的CurricularFace以一个自适应的方式结合课程学习( Curriculum Learnin,CL)的想法到人脸识别中,其在两个方面上与传统的CL有着不同。首先,该课程结构是自适应的。在传统CL中,样本通过对应的困难度进行排序,该困难度会提前定义并固定用以建立课程。而在CurricularFace中,样本在每个mini-batch中随机选取,课程通过在线挖掘困难样本来自适应建立,其展示了有着不同困难度的样本的多样性。其次,困难样本的重要性是自适应的。一方面,容易样本和困难样本之间的相关重要性是动态的,能够在不同的训练阶段中被调整。另一方面,在当前mini-batch中每个困难样本的重要性取决于他自己的困难度
特别是,在mini-batch中错误分类的样本被选择为困难样本,通过调整样本和非ground truth类中心向量的cosine相似度,即负cosine相似度cosΘj,的调节系数![]() 来加权。为了在整个训练中达到自适应课程学习的目标,我们设计了一个新的系数函数I(.),其被两个因素决定:1)自适应估计参数t,其使用样本和对应ground truth类中心的正cosine相似度的移动平均值去解决手动调节的限制; 2)角度Θj,用来定义困难样本获得自适应分配的困难度。
来加权。为了在整个训练中达到自适应课程学习的目标,我们设计了一个新的系数函数I(.),其被两个因素决定:1)自适应估计参数t,其使用样本和对应ground truth类中心的正cosine相似度的移动平均值去解决手动调节的限制; 2)角度Θj,用来定义困难样本获得自适应分配的困难度。
总结,该工作的贡献是:
- 本文提出了用于人脸识别的自适应课程学习损失,自动地先强调简单样本,后强调困难样本。据我们所知,这是首次在人脸识别中引入自适应课程学习。
- 我们设计了一种新的调制系数函数I(·)来实现训练过程中的自适应课程学习,它可以同时连接正余弦和负余弦相似度,而不需要手动调整任何额外的超参数。
- 我们在流行的人脸基准上进行了广泛的实验,这证明了我们的CurricularFace的优势,超过了最先进的竞争对手。
2. Related Work
Margin-based loss function.(介绍省略)该方法没有考虑每个样本的困难度,然而我们的CurricularFace先强调了容易样本,后强调了困难样本
Mining-based loss function.(介绍省略)我们的方法与MV-Arc-Softmax的不同在三个方面:(MV-Arc-Softmax 可见人脸检测和识别以及检测中loss学习 - 17 - Mis-classified Vector Guided Softmax Loss for Face Recognition - 1 - 论文学习 )
1)没有从头到尾都在强调困难样本,尤其是在训练早期阶段;2)我们根据困难样本对应的困难度为其分配不同的权重;3)我们自适应地估计额外的超参数t,而不使用人工调节
Curriculum Learning.先从更简单的样本学习,再到更难的样本是课程学习CL[2, 42]中的常见策略。CL中的主要问题是如何定义每个样本的困难度。比如[1]在分类中将负距离设置到边界作为简单性的指示。但是ad-hoc课程设计显示在不同问题中很难实现。为了减轻这个问题,[12]设计了新的公式,叫做Self-Paced Learning (SPL),其中带有更低损失值的样本被认为是更容易的样本,并在训练中强调。我们的CurricularFace和SPL主要的不同在于:
1)我们的方法在训练的早期阶段关注于简单样本,在训练的后期阶段关注于困难样本;2)我们的方法提出了一个新的函数N(.)用于负样本cosine相似度计算,其不仅实现了在同一个训练阶段不同样本的调节系数I(.)上的自适应赋值,还实现了不同训练阶段的自适应课程学习策略
3. The Proposed CurricularFace
3.1. Preliminary Knowledge on Loss Function

修改后为:
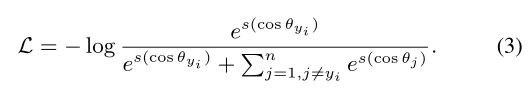
当原始softmax损失的可学习特征在实际的人脸识别中没有足够的区分度后,一些变体被提出,可写成下面的通用形式:

p(xi)是预测的ground truth概率,![]() 是一个指示函数。
是一个指示函数。![]() 和
和![]()
![]() 分别是正和负cosine相似度计算函数,其中c是一个常数。在基于边界的损失函数,如ArcFace,
分别是正和负cosine相似度计算函数,其中c是一个常数。在基于边界的损失函数,如ArcFace,![]()
![]() 它仅修改了每个样本的正cosine相似度去加强特征的区分。如图1所示,每个样本的负cosine相似度的调节系数I(.)都为1。另一个最近的方法MV-Arc-Softmax通过增加困难样本的
它仅修改了每个样本的正cosine相似度去加强特征的区分。如图1所示,每个样本的负cosine相似度的调节系数I(.)都为1。另一个最近的方法MV-Arc-Softmax通过增加困难样本的![]() 来强调困难样本。其中
来强调困难样本。其中![]() 如下:
如下:
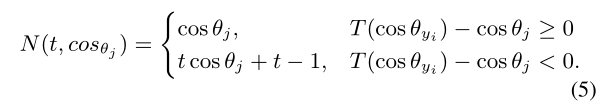
如果一个样本被定义为简单(即它不会被非它的类错误分类),它的负cosine相似度和原始的一样,为cosθj。如果是困难样本(即可能被非yi以外的类错误分类),其负cosine相似度将变为![]() 。 如图1所示,I(.)系数是一个常数,被预先设置好的超参数t决定。同时,因为t总是比1大,所以
。 如图1所示,I(.)系数是一个常数,被预先设置好的超参数t决定。同时,因为t总是比1大,所以![]() 大于cosθj,这将导致模型从头到尾都会专注于困难样本,甚至是在训练早期阶段。但是,参数t是敏感的,一个大的预定义值(如1.4)可能会导致收敛问题。
大于cosθj,这将导致模型从头到尾都会专注于困难样本,甚至是在训练早期阶段。但是,参数t是敏感的,一个大的预定义值(如1.4)可能会导致收敛问题。
3.2. Adaptive Curricular Learning Loss
我们的CurricularFace损失函数的公式也包含于通用格式,其中![]() 正和负cosine相似度函数定义如下:
正和负cosine相似度函数定义如下:
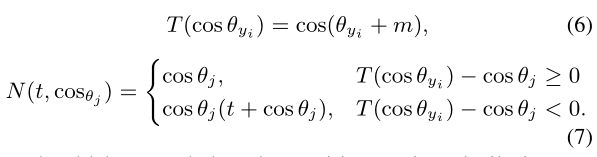
如图1所示,困难样本cosine相似度的调节系数![]() 取决于t和θj两个值。在训练早期,从简单样本中学习有益于模型收敛。因此t应该接近0,这样
取决于t和θj两个值。在训练早期,从简单样本中学习有益于模型收敛。因此t应该接近0,这样![]() 就会小于1(这样困难样本的权重就会小于简单样本)。因此,困难样本的权重会被减少,这样简单样本会相应被强调。当训练继续进行,模型逐渐关注困难样本,,即t的值逐渐增加,I(.)将大于1。因此困难样本将会因为更大的权重被强调。而且,在相同的训练阶段,I(.)是随着θj的值单调递减的,所以更困难的样本(即θj的值更小)根据其困难度将会被赋予更大的系数。参数t的值在我们的CurricularFace将被自动估计。
就会小于1(这样困难样本的权重就会小于简单样本)。因此,困难样本的权重会被减少,这样简单样本会相应被强调。当训练继续进行,模型逐渐关注困难样本,,即t的值逐渐增加,I(.)将大于1。因此困难样本将会因为更大的权重被强调。而且,在相同的训练阶段,I(.)是随着θj的值单调递减的,所以更困难的样本(即θj的值更小)根据其困难度将会被赋予更大的系数。参数t的值在我们的CurricularFace将被自动估计。
从图1左边的图我们可以看见,红色的虚线表示的就是训练早期的困难样本的系数I(.)值,可见小于等于1,这样早期就会强调简单样本; 而红色的实现表示的就是训练晚期的困难样本的系数I(.)值,可见小于等于1,这样晚期就会强调困难样本。且这两条线都是随着x轴的θj值的增大(表示越来越不困难),y轴的I(.)逐渐减少的
Optimization.接下来就是说明我们的CurricularFace能够被卷积随机梯度下降法简单优化的部分。假设xi表示第i个样本的深度特征,其属于yi类,推荐函数的输入是logit fj,其中j表示第j个类
在前向传播阶段,当j = yj时,其与ArcFace相同,![]()
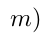 。当j不等于yj时,分两种情况,如果xi是简单样本,即j类对应的分类器没有将其错误分成j类,那么其也与原始的softmax相同,
。当j不等于yj时,分两种情况,如果xi是简单样本,即j类对应的分类器没有将其错误分成j类,那么其也与原始的softmax相同,![]() ;如果是困难样本,则该函数为
;如果是困难样本,则该函数为![]() ,其中
,其中![]()
在后向传播阶段,关于xi和Wj的梯度可以被分成三种情况,如下所示:

基于上面的公式,我们可以发现困难样本的梯度调节系数被决定![]() ,其包含两部分,负cosine相似度和t。如图2所示:
,其包含两部分,负cosine相似度和t。如图2所示:

一方面系数M随着自适应估计值t的增加而增加(可见红线表示的t随着迭代数的增加也是在逐渐增大的,系数也对应增大),用来强调困难样本。另一方面,根据困难样本对应的困难度的不同(即θj的不同),不同的重要性将会赋值到系数M中。所以从图2可见M的值在每个迭代中包含了一个范围的值。
Adaptive Estimation of t. 在不同的训练阶段决定一个恰当的t的值是十分重要的。理想情况下,t的值能够指示模型的训练阶段。我们通过经验发现正cosine相似度的平均值是一个好的指示器。可是min-batch的基于统计的方法往往面临一个问题:当许多极端数据被采样到一个mini-batch时,统计可能是一个很大的噪声,估计值可能很不稳定。Exponential Moving Average (EMA)方法是一个常用的解决该问题的方法。尤其是,假设r(k)是第k个batch的正cosine相似度的平均值,即![]() ,则有:
,则有:
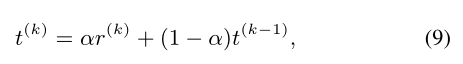
其中t0 = 0, α是momentum参数,并设置为0.99。在EMA中,我们避免超参数的调整,使得困难样本负cosine相似度的调节系数I(.)能自适应于当前的训练阶段。总之,我们CurricularFace的损失函数为:
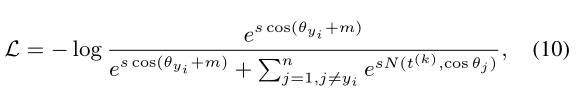
其中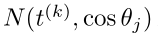 在等式7中定义。整个训练过程总结在算法1中:
在等式7中定义。整个训练过程总结在算法1中:

图3 说明了在训练中,损失是如何从ArcFace变为CurricularFace的:

这里的观察为:
1)困难样本(B和C)在早期训练中被压制,但后期被强调; 2)带有cosΘj的比率是单调增加的,因为cosΘj越大,表示越困难; 3)视角比较好的图像(正面图)的正cosine相似度较大。
但是,在早期训练中,视角良好的图片(A)的负cosine相似度也可能很大,因此它可能被错误分类为困难样本
3.3. Discussions with SOTA Loss Functions
Comparison with ArcFace and MV-Arc-Softmax. 从表1的决策边界函数的角度来看:
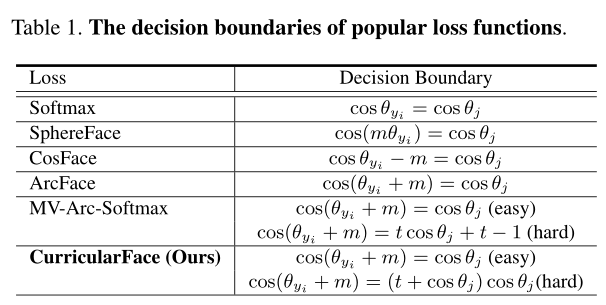
ArcFace从正cosine相似度的角度介绍了一个边界函数![]()
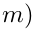 。如图4所示:
。如图4所示:

ArcFace的决策边界从Softmax的蓝线![]() 变为红线
变为红线![]() 。MV-Arc-Softmax从困难样本的负cosine相似度角度增加了附加边界d(即hard-easy增加的部分),决策边界变为绿线
。MV-Arc-Softmax从困难样本的负cosine相似度角度增加了附加边界d(即hard-easy增加的部分),决策边界变为绿线![]() 。相反地,我们自适应地调节困难样本的权重,决策边界从(早期的)紫线变成(晚期)的紫线,其先强调了容易样本,后强调困难样本。
。相反地,我们自适应地调节困难样本的权重,决策边界从(早期的)紫线变成(晚期)的紫线,其先强调了容易样本,后强调困难样本。
Comparison with Focal Loss. Focal Loss式子为![]() ,其中α和β都是人工调节的调节因子。在Focal loss中困难样本的定义是很模糊的,因此在整个训练过程中,其通过减少简单样本的权重来相应强调困难样本。相反,在我们的CurricularFace中困难样本的定义是清楚的,即错误分类的样本。同时,困难样本的权重能在不同的训练阶段被自适应决定
,其中α和β都是人工调节的调节因子。在Focal loss中困难样本的定义是很模糊的,因此在整个训练过程中,其通过减少简单样本的权重来相应强调困难样本。相反,在我们的CurricularFace中困难样本的定义是清楚的,即错误分类的样本。同时,困难样本的权重能在不同的训练阶段被自适应决定
4. Experiments
省略