AdaptiveFace: Adaptive Margin and Sampling for Face Recognition
Abstract
大规模非平衡数据的训练是人脸识别的核心问题。在过去的两年中,由于引入了基于边距(margin)的Softmax损失,人脸识别取得了显著的进步。然而,这些方法有一个隐含的假设,即所有的类都有足够的样本来描述其分布,因此手动设置的边距足够平均地压缩每个类内的差异。然而,真实的人脸数据集是高度不平衡的,这意味着类有巨大的不同样本数量。在这篇论文中,我们认为边距应该适应不同的类。我们提出了Adaptive Margin Softmax来自适应地调整不同类的边距。除了不平衡挑战之外,人脸数据总是由大规模的类和样本组成。聪明地选择有价值的类和样本参加训练,使训练更加有效和高效。为此,我们还从两个方面对采样过程进行了自适应:首先,我们提出了Hard Prototype Mining,自适应地选择少量的hard类参与分类;其次,在数据采样方面,我们引入了自适应数据采样来寻找有价值的样本进行自适应训练。我们将这三部分组合在一起作为AdaptiveFace。在LFW、LFW BLUFR和MegaFace上的大量分析和实验表明,我们的方法比使用相同的网络结构和训练数据集的最先进的方法有更好的性能。代码在https: //github.com/haoliu1994/AdaptiveFace(这里什么都没有,震惊!!!)
1. Introduction
在以前的方法,如L-Softmax [17]、SphereFace [16] 、CosFace [34, 32]和ArcFace [4]等,这些方法有一个隐含的假设,即所有的类都有足够的样本来描述它们的分布,因此一个恒定的边距足以均匀地挤压每个类内的差异。然而,公开的人脸数据集是高度不平衡的,这表明它们总是有非常不同的样本数量,如图1所示:
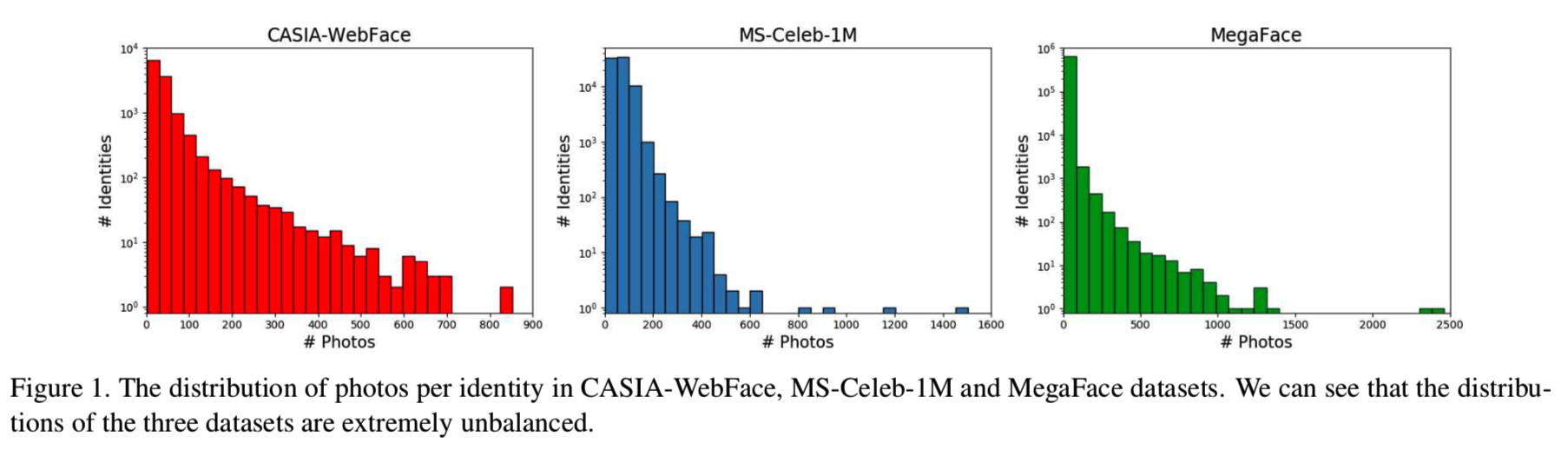
对于样本数量充足的rich类,现有训练样本所跨越的空间可以代表真实分布。然而,对于样本稀缺的poor类,现有训练样本所涵盖的空间可能只是实际分布的一小部分。因此,对于具有不同样本分布的类,统一边距的约束并不完美。我们倾向于用较大的边距来强压缩那些代表性不足的类的类内差异,以提高泛化能力。在本文中,我们提出了一种新的损失函数——Adaptive Margin Softmax损失(AdaM-Softmax),以自适应地找到适合于不同类别的边距。具体来说,我们让每个类的边距m是特定的,并且是可学习的,并直接训练CNN找到合适的边距。形式上来说,我们定义每个类mi的边距,即通过cosθ1 − m1 = cosθ2公式给定的决策边界,其中θi表示类i的特征和权重之前的角度。通过实验,我们展示了AdaM-Softmax是优于其他的方法的
此外,大规模的人脸数据往往包含数十万个类和数百万个样本,其中只有一小部分可以用于判别训练。如何选择有价值的类和样本进行训练是另一个重要的课题,但在Softmax损失中却很少有人关注它。在本文中,我们还使采样过程具有自适应性。采样是指在Softmax层进行原型选择,在数据层进行数据采样。首先,在深度度量学习中,hard样本挖掘是提高模型训练效率和性能的重要环节。Zhu等人的[47]表明,验证损失和分类损失都遵循相同的pair匹配和加权框架。唯一的区别在于候选项的配对(在特性 vs 原型特性之间)和加权方法(hard权重 vs soft权重之间)。因此,本文尝试将hard实例挖掘策略应用于Softmax损失问题。具体地,我们提出了Hard Prototype Mining(HPM),自适应地选择少量的hard类参与分类,使优化集中在hard类上。注意,在本文中,我们将每个类的权重向量作为其原型。其次,从大规模数据中学习是当前人脸识别任务的关键,由于时间和计算设备的限制,训练效率变得越来越重要。该论文受小批量级别的hard样本挖掘的启发,我们提出了Adaptive Data Sampling(ADS),该算法通过从分类层到数据层的反馈通道来寻找有价值的样本进行网络训练。基于这三个组件,我们将提出的人脸识别框架称为AdaptiveFace,如图2所示。
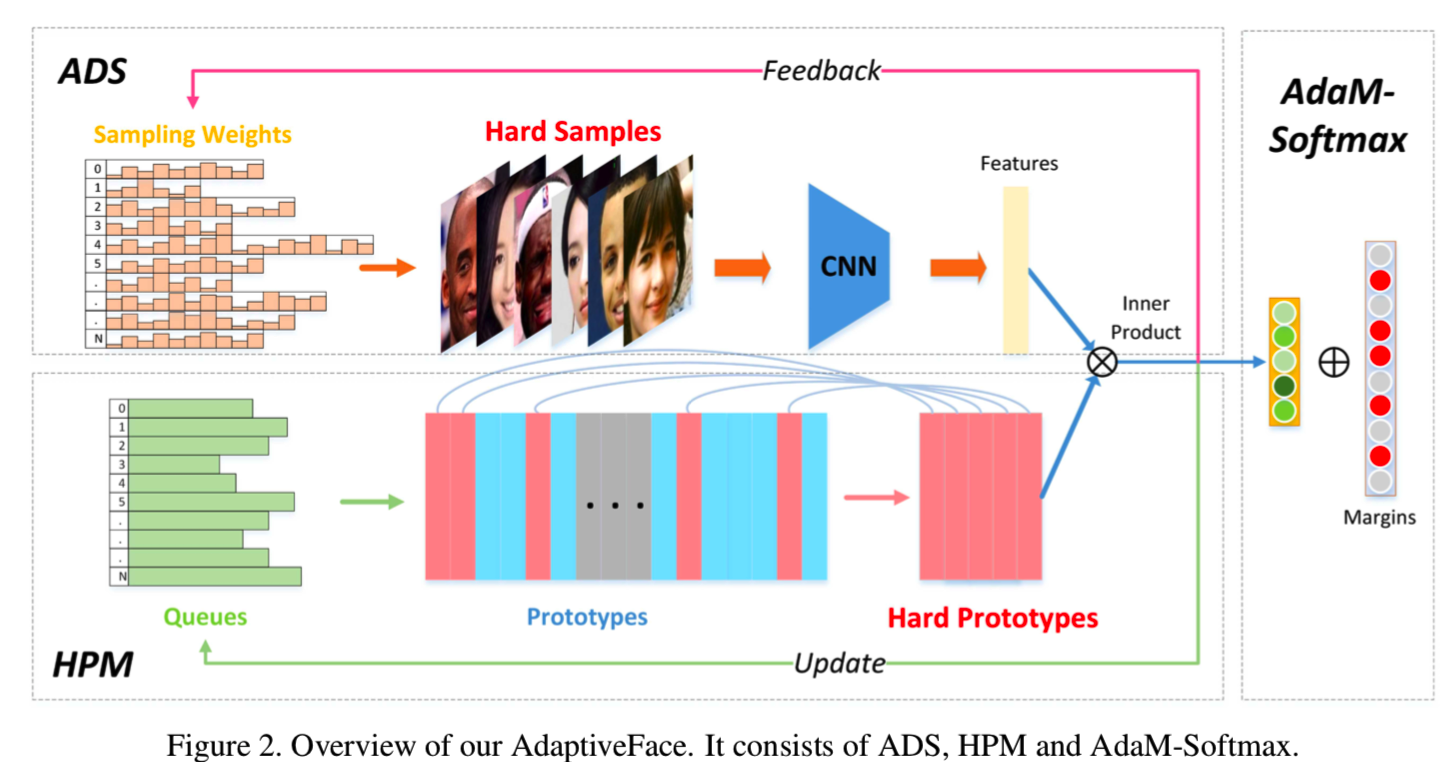
综上所述,我们的目标是使人脸识别框架更灵活地处理大规模和不平衡的数据。我们的主要贡献如下:
- 引入自适应边距,使模型学习每个类的特殊边距,自适应地挤压类内的差异。
- 我们提出了hard原型挖掘,通过在分类训练中自适应地挖掘少量的hard原型,使网络训练集中在hard类上。
- 我们从分类层向数据层建立一个反馈通道去为网络训练找寻有价值的样本
在LFW、LFW BLUFR和MegaFace上的实验表明,该方法有效地提高了识别精度,取得了较好的识别效果。
2. Related Works
在这一部分,我们回顾了基于深度学习的人脸识别,并讨论了两个相关的问题:(1)损失函数和(2)困难样本挖掘。
Loss Functions. 损失函数在人脸识别中起着重要的作用。我们将从两个方面介绍损失函数。一是验证损失函数。contrastive损失[3,6,27]优化了特征空间中的成对的欧氏距离。Triplet损失[24,9,35]将三个输入组成一组,通过一定距离margin来分离正的一对和负的一对。二是分类损失函数。该方案中最常见的损失是Softmax损失[28,30,31]。在此基础上,center损失[36]提出学习特定类的特征中心,使特征在嵌入空间中更加紧凑。L2-softmax[23]在特性上增加了L2约束,以促进代表性不足的类。NormFace[33]对特性和原型进行了标准化,使训练和测试阶段更加接近。近年来研究发现,增强不同类间的余弦和角边距是改善特征识别的有效方法。Large-margin Softmax[17]和A-Softmax[16]为每个身份增加乘法角边距,以改进特征识别。CosFace[34]和AM-Softmax[32]添加了附加的余弦边距,以实现更好的优化。ArcFace[4]将附加的余弦余量移动到角空间中,得到了清晰的几何解释,并在一系列人脸识别基准上获得了更好的性能。
Hard Example Mining. 困难样本挖掘是深度度量学习的重要组成部分,它可以提高模型的训练效率和性能。找到困难样本的方法通常是使用在线困难样本挖掘(OHEM)[10,39]。然而,在实践中,由于大规模数据中存在大量的噪声,因此最好使用在线半困难样本挖掘[24,21,22],在这种情况下,样本对是在小批量的“足够困难”的样本中随机选择的。此外,不仅困难对包含有用的信息[46],利用不同水平的“困难度”也被证明是有益的[37,41,7]。所有这些方法都改进了困难样本挖掘,还有其他方法可以挖掘困难类。N-pair损失[26]使用“困难样本挖掘”来查找类对来生成小批量。Doppelganger Mining[25]为每个身份维护一个具有最相似标识的列表,以生成更好的mini-batches。
3. The Proposed Approach
在本节中,我们将详细介绍我们的方法。在3.1节中,我们讨论了为什么相同的margin不能很好地用于不同样本数量的类,并引入了我们的Adaptive margin Softmax,以端到端的方式为每个类找到特殊的合适的margin。在第3.2节中,我们提出了在Softmax损失中智能选择困难类的困难原型挖掘方法。最后,我们在3.3节中引入一个反馈通道来寻找有价值的样本进行数据采样。
3.1. Adaptive Margin Softmax
3.1.1 Intuition and Motivation
最近关于基于边距的Softmax损失[17,16,34,32,4]的工作取得了显著的改进,其中手动调整的参数m被设置用来为所有类来挤压类内的差异。在这些方法中有一个隐含的假设,即所有类的样本分布都是相同的,因此手动设置边界就足以约束所有类。然而,现有的人脸训练数据存在严重的样本不平衡,如图1所示。对于那些有着丰富样本和大的类内差距的类,由现有的训练样本span成的空间可以代表所有样本的实际分布,但对那些只有少量的类,且类内差距小的poor类,由现有的样品span成的空间可能只有一小部分真正的这个类的分布。注意,那些拥有连续的tracklet帧的类仍然被认为是poor类,因为这些帧提供的类内信息很少。当所有的类都设置一个统一的margin时,poor类的特征分布可能不像rich类的特征分布那么紧凑,因为poor类的实际展成空间可能比观测空间大,导致泛化能力差。
我们通过一个如图3 (a)所示的二分类任务进一步将这一现象可视化。蓝色区域表示样本稀少且类内变化小的poor类C1的特征空间。半透明的蓝色区域表示C1下的真实特征空间,由于样本稀少,无法观测到。红色区域表示类C2的特征空间,样本丰富,类内变化较大。由于C2中有丰富的样本,我们认为观测到的特征空间与底层的真实特征空间几乎相同,所以半透明的红色区域与红色区域相同。可以看出,CosFace loss不能很好的压缩C1的特征,因为它不能看到真实的边界样本。因此,C1下的底层的特征空间(即半透明蓝色部分)不能像C2下的底层特征空间那样紧凑。为了解决这一问题,我们提出了Adaptive margin Softmax损失(AdaM-Softmax),它将固定边界m改进为一个可学习的类相关参数。

3.1.2 Adaptive Margin Softmax Loss
让我们从最广泛使用的Softmax损失开始。Softmax损失通过最大化真实类的后验概率来分离不同类的特征。给定输入特征向量xj及其对应的标记y(j),没有bias的Softmax损失可表示为:
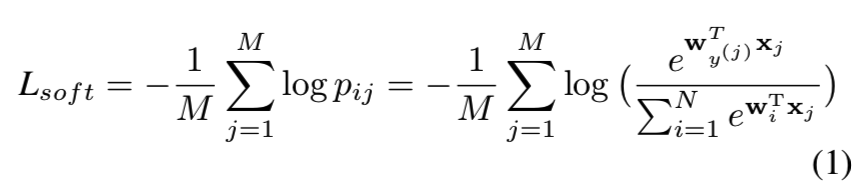
其中pij表示xj的后验概率被正确划分为类y(j), M是batch大小,N是类的数量,wi表示类i的原型。应用L2正则化wi和xj来优化球面上的特征,该特征的距离可以作为特征角度制定如下:
![]()
其中θij表示wi和xj之间的角度。在此基础上,如A-softmax[16]、Cos-Face[34, 32]和ArcFace[4]等方法使用边距margin来提高类内紧凑度。以CosFace为例:
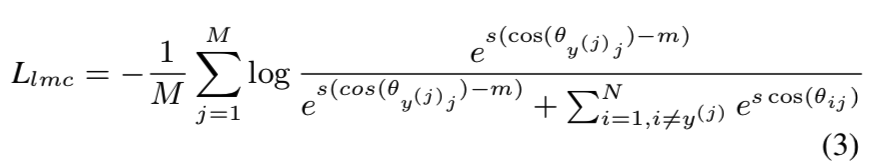
其中s为尺度因子。CosFace中的边距m通常是手动设置的,并在训练过程中保持不变。为了处理3.1.1节中描述的问题,我们的目标是将margin改进为一个可学习的、与类相关的参数。等式3可以修改为:
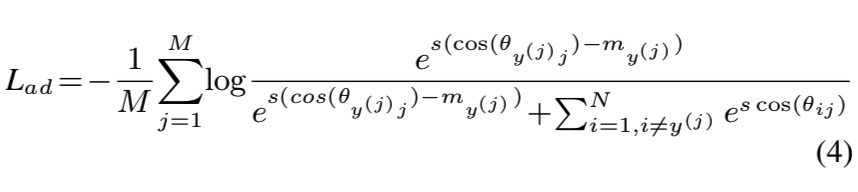
其中my(j)是类y(j)对应的边距。直观地说,我们更喜欢用较大的m来减少类内部的差异。在这项工作中,我们在数据库角度约束边距:
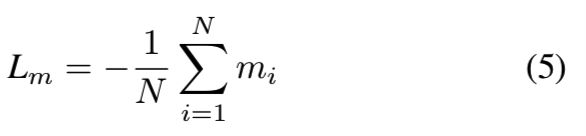
这是所有类的平均边距。结合这两部分是我们的Adaptive margin Softmax损失(AdaM-Softmax)为:
![]()
λ控制margin约束Lm的强度,这将在实验中进行讨论。注意,如果没有Lm,存在一个平凡解mi = 0。所提出的自适应margin可应用于任何基于margin的Softmax损失,如Arcface,只需将余弦margin改为角margin即可。
3.1.3 Comparison with Other Loss Functions
为了更好地理解我们的方法与其他基于margin的Softmax损失之间的区别,我们给出了表1和图4中二元分类情况下的决策边界:

这些方法之间的主要区别是我们的margin是可学习的和与类相关的。从图4中可以看出,虽然CosFace和ArcFace给出了两个类之间的清晰的边界,但是对于较差的类C1,其真实分布可能大于观测到的分布,使得真实的边界越来越小,导致泛化效果较差。与AdaM-Softmax不同的是,它可以通过网络训练期间的参数更新,为C1学习更大的m1,使C1观察到的特征更加紧凑,并隐式地将C1的真实边界推离C2。
此外,为了直观地展示AdaM-softmax的效果,我们设计了一个toy实验来演示不同损失函数训练的特征分布。我们从MS-Celeb-1M中的8个身份中选择人脸图像来训练几个输出三维特征的10层ResNet模型。其中,类0(红色)包含的样本数量最多(超过400个),类1、2(橙色、金色)包含的样本数量次多(约200个),类3∼7(5个冷颜色)包含的样本数量较少(约50个)(这个比例大致模拟了MS-Celeb-1M的样本数量分布)。我们将得到的三维特征归一化并绘制在球面上。参加的损失有Softmax损失,CosFace,和我们提出带有不同的λ的AdaM-Softmax。如图5所示:
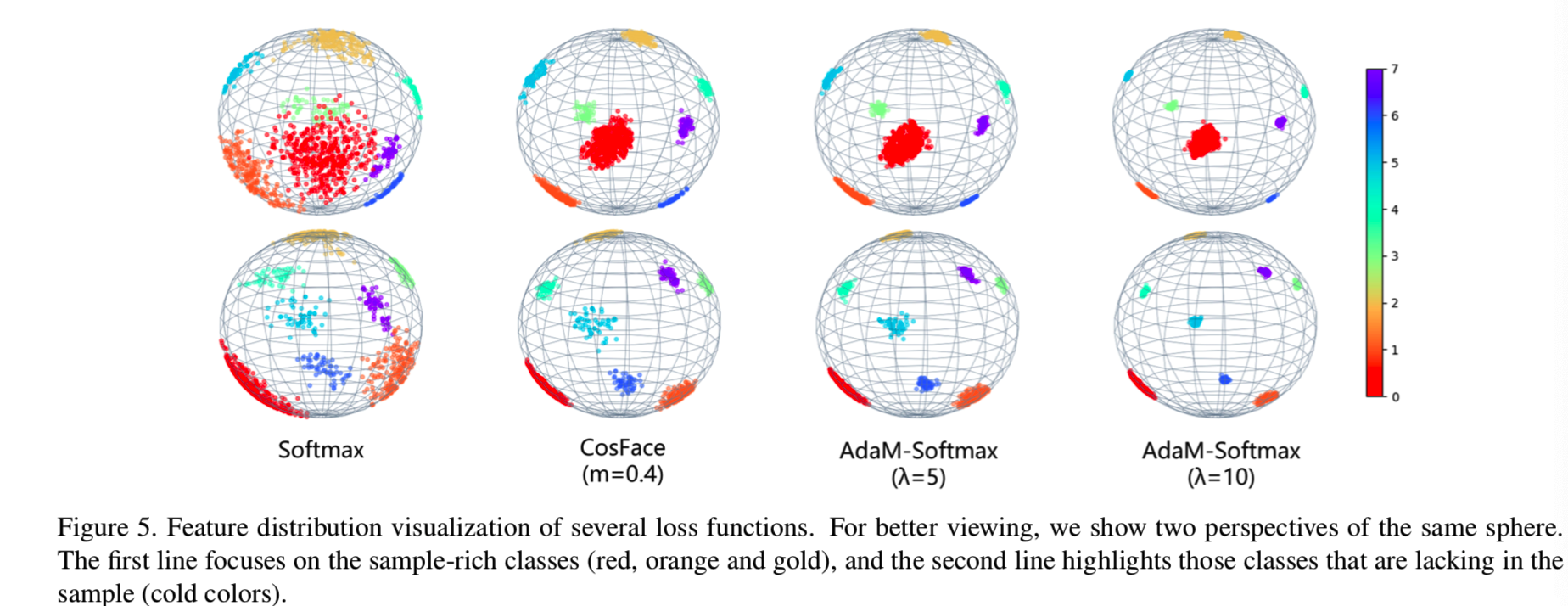
我们可以观察到Softmax损失更喜欢rich类(例如类0),并为它们分配了大量空间,从而导致错误的决策边界。CosFace在不考虑样本分布的情况下,减少了类内差异,并为每个类分配了相同的空间。例如,浅蓝色的点和红色的点占据了几乎相同的空间区域。AdaM-Softmax侧重于优化poor类(冷颜色),使其更紧凑。通过比较CosFace和AdaM-Softmax(λ= 5),我们可以看到,被poor类0占据的区域(红点)几乎是相同的,而对于poor的类(蓝色,淡蓝色和紫色),我们的方法的特征更紧凑。此外,通过增加λ,这些poor样本类的特征几乎是聚集在一个点。
3.2. Hard Prototype Mining
采样在验证损失(如contrastive[27]、triplet[24])中得到了广泛的研究,这是一种困难样本挖掘策略[24,21,10]。困难样本挖掘的目的是挖掘最有价值的对或triplets(三个一对)。为了将困难样本挖掘的思想应用到Softmax损失中,提高效率和性能,我们提出了困难原型挖掘(HPM,原型即权重w),即在每次迭代中选择与小批样本最相似的类。HPM是对在[47]中的原型选择策略的改进。具体地,我们将每个类的权值wi作为其原型。我们为所有类的原型构建一个ANN图,找到与每个类最相似的k个类,并将它们放入各自的队列中。我们称这些队列被Qi指示的优势队列。当每次迭代开始时,我们选择与小批样本对应的优势队列中的原型,构造本次迭代的权值矩阵W。在前向传播后,我们根据分类层内积计算的分数来更新优势队列。首先,对于一个特征xj,如果它的最高激活类cp是它对应的类y(j),则不需要更新。其次,如果cp̸= y(j),我们通过排序所有类分数大于cos(θy (j) j)的类来更新该优势队列。最后,与[47]不同的是,我们设置了一个超参数h来控制每个类的优势队列的大小。对于队列中的每个类,如果它与队列所有者的相似度大于h,则它将保留在队列中,否则将弹出。利用h,我们可以控制所选原型的相似度,通过调整h,逐步增加训练难度。整个HPM增加的计算成本很小。
3.3. Adaptive Data Sampling
当网络已经大致收敛时,数据集中的大多数样本已经被很好地分类,很难对网络训练做出贡献。为了提高训练的有效性和效率,我们建立了一个从分类层到数据层的反馈通道,自适应地找到有价值的样本,形成小批量,我们称之为Adaptive Data Sampling (ADS)。具体来说,我们给每个样本分配抽样概率。在训练过程中,当样本在本次迭代中被正确分类时,我们将信号传递给数据层,降低其采样概率。否则,我们增加了它的采样概率,使得那些经常被正确分类的样本会随着训练的进行而逐渐被忽略。我们还设置了最小抽样概率smin,以防那些简单的样本永远不会被抽样。
此外,由于大规模人脸数据不可避免地会有大量的噪声数据[42],随着训练的进行,噪声样本会不断被误分类,采样概率较大。为了减轻噪声数据的影响,我们对噪声样本进行了反馈。对于mini-batch中的每一个样本,如果其特征与对应的原型之间的分数低于一个阈值,我们就会将消息传递给数据层,从而大大降低该样本的抽样概率。
4. Experiments
4.1. Experimental Settings
Preprocessing. 我们通过FaceBox[43]检测器检测人脸,通过简单的6层CNN定位5个landmarks(两个眼睛、鼻尖和两个嘴角)。所有的人脸都经过相似变换归一化,并裁剪成120×120 RGB的图像。
CNN Architecture. 使用PyTorch[1]实现我们提出的方法。实验中所有的CNN模型都遵循了与本文相同的架构,即与[4]中的LResNet50A-IR相同的50层残差网络[8]。它有四个residual块,最后通过平均池化层得到一个512维的特征。这些网络是在TITANX GPU上训练的,batch大小被设置为能填满所有的GPU内存的大小。
Training Data. 对于本文中的所有模型,我们都在MS-Celeb-1M数据集[5]上进行训练[5],其是包含98,685位名人和1,000万张图像的最大自然环境下的数据集之一。由于有很多噪音,数据被[38]的列表清除。现有79,077个身份和500万张训练数据。这些人脸图像经过水平翻转的,以实现数据增强。
Evaluation Setup. 对于每个图像,我们只从原始图像中提取特征作为最终表示。我们没有从原始图像和翻转后的图像中提取特征,并将它们连接起来作为最终的表示。分数是由两个特征的余弦距离来衡量的。最后,通过阈值化和评分排序进行人脸验证和识别。我们在LFW [12], LFW BLUFR[14]和MegaFace[13]上对我们的模型进行了评估。
4.2. Overall Benchmark Comparisons
4.2.1 Experiments on MegaFace
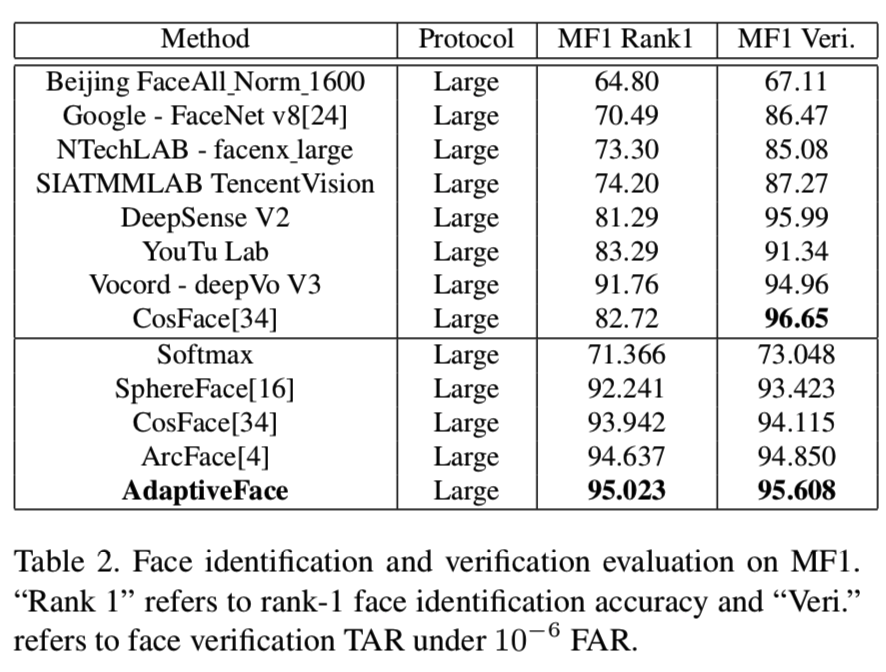
在MegaFace[13]上的实验。为了公平的比较,我们使用相同的50层CNN网络实现了Softmax、A-Softmax、Cos-Face、ArcFace和AdaptiveFace。表2显示了我们的模型在MegaFace large协议上的训练结果。
4.2.2 Experiments on LFW and LFW BLUFR
在LFW[12]上的实验。如表3所示,AdaptiveFace将LFW的性能从99.53%提高到了99.62%。考虑到LFW已经被很好地解决了,我们进一步评估了我们的方法在更具挑战性的LFW BLUFR协议[14]上的性能,该协议主要针对低FARs。我们在表4中报告了结果。由此可见,我们的方法优于目前所有最先进的方法。
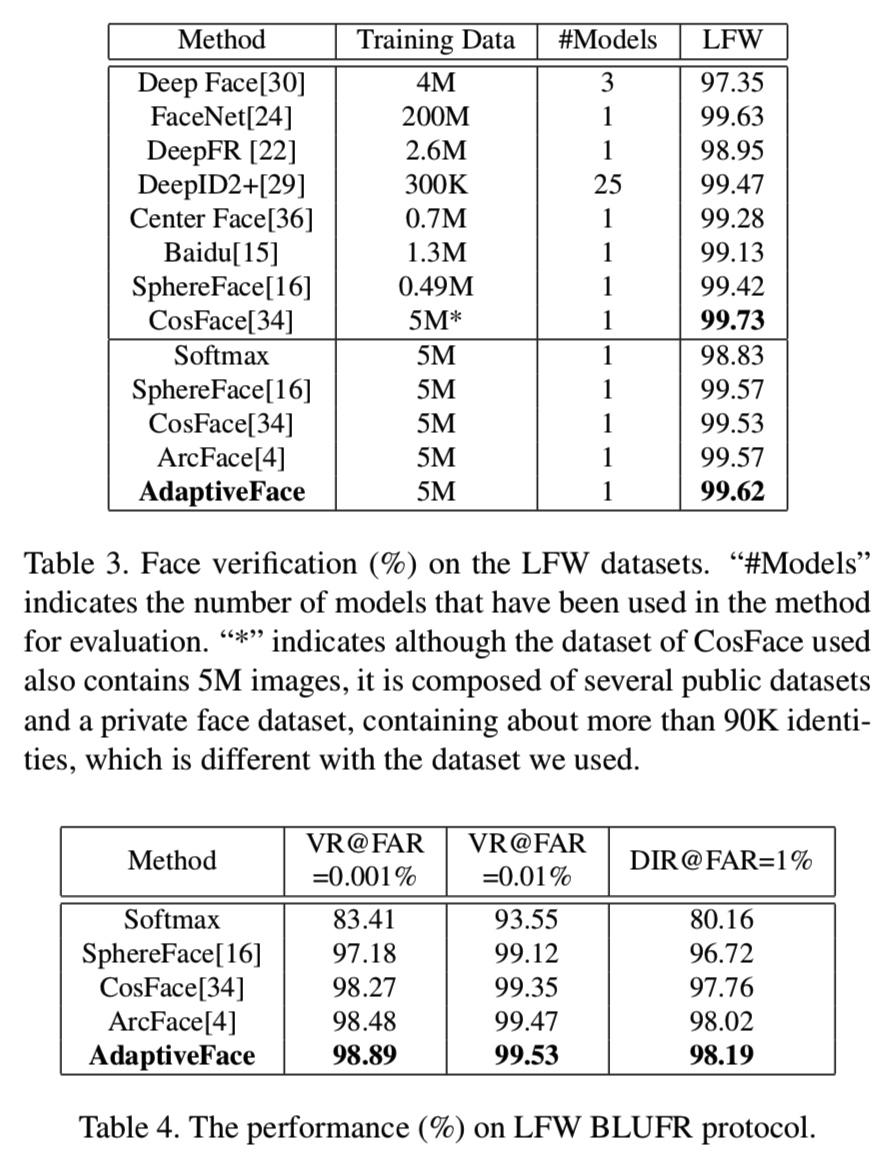
4.3. Ablation Study
为了证明在我们的框架中三个组件的有效性,我们运行了一些ablations来分别分析AdaM-Softmax、困难原型挖掘和自适应数据采样方法作出的改进。当没有一个被采用时,基线是CosFace。从表5可以看出,从AdaM-Softmax的改进是最明显的(从MF1 Veri的94.115%到95.032%)。在MF1 Rank1中,当ADS和HPM与AdaM-Softmax联合使用时,也可以将性能从94.373%提高到95.023%。当这三个部分结合在一起时,AdaptiveFace在所有的评估中都比CosFace有显著的改进。

4.4. Exploratory Experiments
Effect of λ in Adaptive Margin Softmax Loss. Adaptive Margin Softmax损失包括分类损失Lad和margin平均损失Lm两部分。第二部分对防止mi在训练中变得越来越小起着重要的作用。在这一部分,我们进行了一个实验来探索它的影响。通过改变λ从0到150,我们使用MS-Celeb-1M训练我们的模型和使用LFW, LFW BLUFR及MegaFace进行验证。所有类的m的初始值为0.4。如表6所示,我们可以看到在增加λ时,LFW和MegaFace Rank1的性能得到了改进与提高,并在当λ= 100时得到饱和:
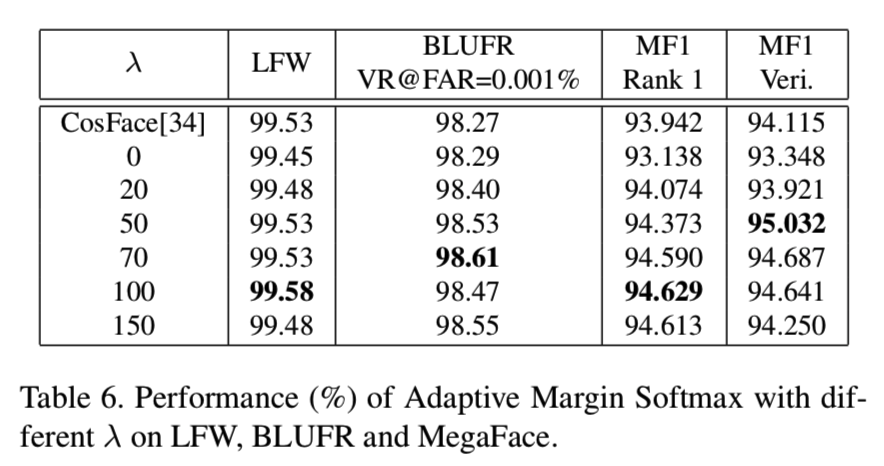
而对于在BLUFR和MegaFace的验证,一开始性能得到了增加,在λ= 50或70时性能达到最高,然后稍微减少。为了进一步研究不同λs下每个类的margin,我们在图6绘制了当λ= 20,50和100时m的分布:
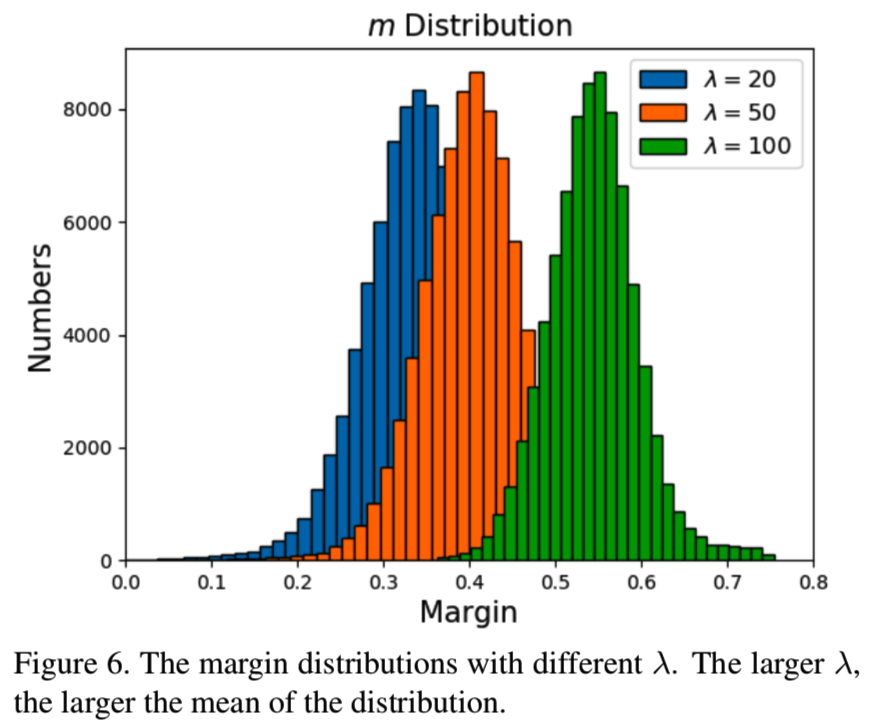
可以看出,在不同的λs下,m的分布是有着相似标准差的近似高斯分布,差别在于分布的均值因更大的λ而有所增加。在图7中,我们展示了与类的平均样本数量相应的可学习的m:
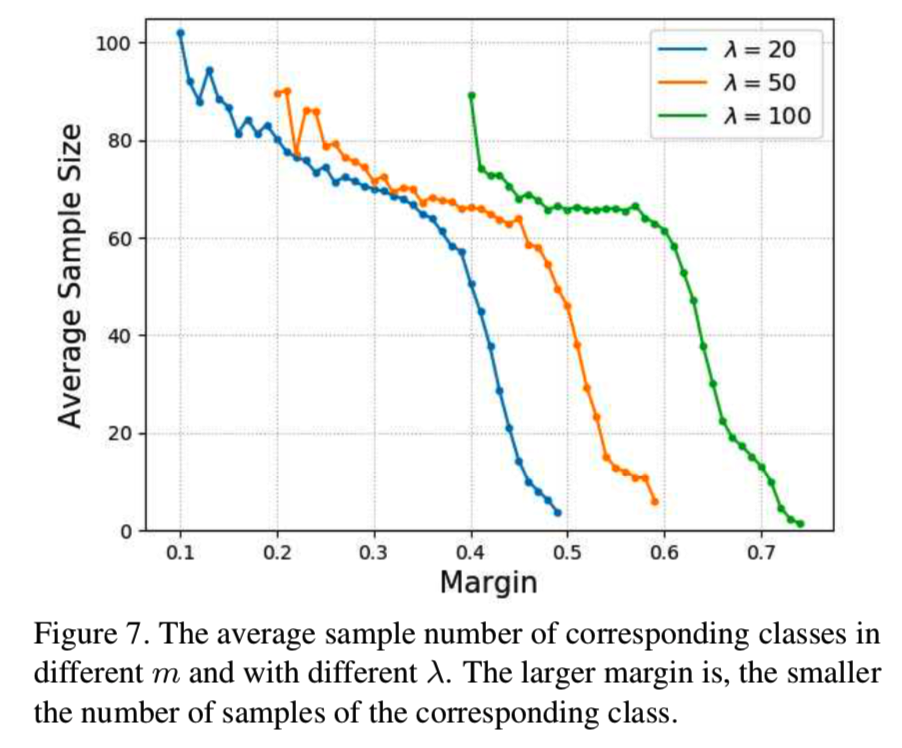
可以发现,随着样本数量的减少,m的价值是增加的,其证明了我们的AdaM-Softmax方法可以自适应地分配大margin给poor类和分配小margin给rich类。很明显,网络可以根据样本分布自适应地学习每个类的margin,以处理不平衡的数据。
Effect of threshold h in Hard Prototype Mining. 为了探讨相似阈值h对困难原型挖掘(HPM)方法的影响,我们将有着不同h值的模型从小到大进行训练,并比较它们在LFW和LFW BLUFR协议下的性能。我们在这个实验中使用的损失函数是CosFace。表7显示了不同h下的结果和选择的原型数,其中h = 0表示我们不使用HPM,即直接使用CosFace进行训练:
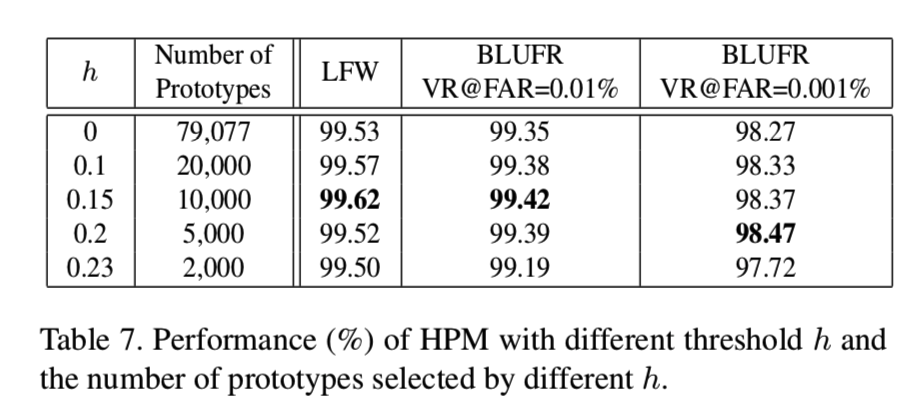
我们可以看到,阈值h可以减少每次迭代中选择的原型的数量,提高最终的性能。注意,当h = 0.23时,所选择的原型数量不够而且太困难,导致性能下降。
5. Conclusion
本文提出了一种新的自适应人脸识别方法,该方法由三个部分组成。第一个是AdaM-Softmax,它为每个类引入了自适应margin,以自适应地最小化类内差异。第二种是困难原型挖掘,通过自适应地选择少量的困难原型,使模型专注于困难类。最后一种是自适应数据采样,通过从分类层到数据层的反馈通道自适应地发现有价值的样本。我们的方法在几个人脸基准测试中都有显著的改进,如实验部分所示。我们相信,我们的方法在实践中对大规模的非平衡数据训练很有帮助。