https://docs.docker.com/engine/swarm/swarm-tutorial/
1)Getting started with swarm mode
本教程向你介绍Docker Engine Swarm模式的特性。在开始之前,你可能想先熟悉一下关键概念。
本教程通过以下活动指导你:
- 在集群swarm模式下初始化Docker引擎集群
- 向集群swarm中添加节点nodes
- 将应用程序服务services部署到集群swarm中
- 一旦所有东西都在运行,就开始管理集群
Set up设置
要运行本教程,你需要以下内容:
- 安装了Docker后,可以通过网络进行通信的三个Linux主机
- 安装Docker引擎1.12或更高版本
- 管理机器的IP地址
- 在主机之间打开端口
Three networked host machines三台联网主机
本教程需要安装了Docker并可以通过网络进行通信的三个Linux主机。它们可以是物理机器、虚拟机、Amazon EC2实例,或者以其他方式托管。你甚至可以在Linux、Mac或Windows主机上使用Docker机器。检查开始-群集为主机的一个可能的设置。
我使用的是virtualBox安装的三台Linux主机,如下图所示:

其中一台机器是manager(称为manager1),其中两台是worker (worker1和worker2)。
注意:你也可以按照教程中的许多步骤来测试单节点群,在这种情况下,你只需要一台主机。多节点命令不起作用,但是你可以初始化集群、创建服务并扩展它们。
这里只是文档,如果想要看在机器上的实现过程,可见本博客的docker swarm 实例
Docker Engine 1.12 or newer
本教程要求在每台主机上安装Docker Engine 1.12或更新的引擎。安装Docker引擎并验证Docker引擎守护进程是否在每台机器上运行。
The IP address of the manager machine 管理主机的IP地址
IP地址必须分配给主机操作系统可用的网络接口。集群中的所有节点都需要在IP地址上连接到管理器。
因为其他节点在其IP地址上与manager节点联系,所以应该使用固定的IP地址。
你可以在Linux或macOS上运行ifconfig来查看可用网络接口的列表。
如果你正在使用Docker Machine,你可以使用docker-machine ls或docker-machine ip <MACHINE-NAME>来得到管理器IP地址,例如:
docker-machine ip manager1
本教程使用manager1: 192.168.99.100。
Open protocols and ports between the hosts在主机之间打开协议和端口
以下端口必须可用。在某些系统上,这些端口默认情况下是打开的。
- 用于集群管理通信的TCP端口2377
- 用于节点间通信的TCP和UDP端口7946
- 用于覆盖网络流量的UDP端口4789
如果你计划使用加密(--opt encryption)创建覆盖网络,还需要确保允许ip protocol 50 (ESP)流量。
2)Create a swarm创建集群
完成教程设置步骤后,就可以创建集群了。确保Docker引擎守护进程在主机上启动。
1.打开终端并ssh到要运行管理器节点的机器中。本教程使用名为manager1的机器。如果你使用Docker Machine,你可以使用以下命令通过SSH连接到它:
$ docker-machine ssh manager1
2.运行下面的命令去创建一个新集群
$ docker swarm init --advertise-addr <MANAGER-IP>
注意:如果你在Mac上使用Docker或者Windows上使用Docker来测试单节点集群,只需运行Docker swarm init,不带参数。在本例中没有必要指定--advertising -addr。要了解更多信息,请参见Use Docker for Mac or Docker for Windows主题。
在该教程中,下面的命令在manager1机器上创建了一个集群:
$ docker swarm init --advertise-addr 192.168.99.100 Swarm initialized: current node (dxn1zf6l61qsb1josjja83ngz) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-49nj1cmql0jkz5s954yi3oex3nedyz0fb0xx14ie39trti4wxv-8vxv8rssmk743ojnwacrr2e7c 192.168.99.100:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
--advertise-addr标志将manager节点配置为将其地址发布为192.168.99.100。集群中的其他节点必须能够访问IP地址上的管理器。
输出包括将新节点加入集群的命令。根据--token标志的值,节点将作为管理器或工作者连接。
3.运行docker info查看集群的当前状态:
$ docker info Containers: 2 Running: 0 Paused: 0 Stopped: 2 ...snip... Swarm: active NodeID: dxn1zf6l61qsb1josjja83ngz Is Manager: true Managers: 1 Nodes: 1 ...snip...
4.运行docker node ls命令查看节点消息:
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
dxn1zf6l61qsb1josjja83ngz * manager1 Ready Active Leader
节点ID旁边的*表示你当前正在此节点上连接。
Docker引擎集群模式自动为机器主机名命名节点。本教程将在后面的步骤中介绍其他列。
3)Add nodes to the swarm添加节点到集群中
一旦你已经创建了具有管理节点的集群之后,就可以添加工作节点了。
1.打开终端并ssh到要运行工作节点的机器中。本教程使用名称worker1。
2.运行从Create a swarm教程步骤中生成的docker swarm init输出命令,创建一个连接到现有swarm的工作节点:
$ docker swarm join --token SWMTKN-1-49nj1cmql0jkz5s954yi3oex3nedyz0fb0xx14ie39trti4wxv-8vxv8rssmk743ojnwacrr2e7c 192.168.99.100:2377 This node joined a swarm as a worker.
如果没有可用的命令,可以在manager节点上运行以下命令来检索worker的join命令:
$ docker swarm join-token worker To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-49nj1cmql0jkz5s954yi3oex3nedyz0fb0xx14ie39trti4wxv-8vxv8rssmk743ojnwacrr2e7c 192.168.99.100:2377
3.打开终端并ssh到要运行第二个工作节点的机器中。本教程使用名称worker2。
4.运行从Create a swarm教程步骤中生成的docker swarm init输出命令,创建连接到现有swarm的第二个工作节点:
$ docker swarm join --token SWMTKN-1-49nj1cmql0jkz5s954yi3oex3nedyz0fb0xx14ie39trti4wxv-8vxv8rssmk743ojnwacrr2e7c 192.168.99.100:2377 This node joined a swarm as a worker.
5.打开终端ssh进入管理节点运行的机器,运行docker node ls命令查看工作节点:
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
03g1y59jwfg7cf99w4lt0f662 worker2 Ready Active
9j68exjopxe7wfl6yuxml7a7j worker1 Ready Active
dxn1zf6l61qsb1josjja83ngz * manager1 Ready Active Leader
MANAGER列标识群中的MANAGER节点。worker1和worker2的MANAGER列中的空状态表示将它们标识为工作节点。
像docker node ls这样的集群管理命令只在管理器节点上工作。
4)Deploy a service to the swarm在集群中部署服务
在创建集群之后,可以将服务部署到集群中。在本教程中,你还添加了工作节点,但这不是部署服务的必要条件。
1.打开终端并ssh到运行管理器节点的机器中。例如,本教程使用名为manager1的机器。
2.运行以下命令:
$ docker service create --replicas 1 --name helloworld alpine ping docker.com 9uk4639qpg7npwf3fn2aasksr
- docker service create命令创建服务。
- --name标志将服务命名为helloworld。
- --replicas标志指定1个正在运行的实例的所需状态。
- alpine ping docker.com参数将服务定义为一个alpine Linux容器,它执行ping docker.com命令。
3.运行docker service ls,查看正在运行的服务列表:
$ docker service ls ID NAME SCALE IMAGE COMMAND 9uk4639qpg7n helloworld 1/1 alpine ping docker.com
5)Inspect a service on the swarm检查集群中的服务
在集群中部署服务后,可以使用Docker CLI查看集群中运行的服务的详细信息。
1.如果还没有,那么打开终端并ssh到运行manager节点的机器中。例如,本教程使用名为manager1的机器。
2.运行docker service inspect --pretty <SERVICE-ID>,以一种易于阅读的格式显示关于服务的详细信息。
为了查看helloworld服务的详情:
[manager1]$ docker service inspect --pretty helloworld ID: 9uk4639qpg7npwf3fn2aasksr Name: helloworld Service Mode: REPLICATED Replicas: 1 Placement: UpdateConfig: Parallelism: 1 ContainerSpec: Image: alpine Args: ping docker.com Resources: Endpoint Mode: vip
提示:要以json格式返回服务细节,请运行相同的命令,但不要使--pretty标志。
[manager1]$ docker service inspect helloworld [ { "ID": "9uk4639qpg7npwf3fn2aasksr", "Version": { "Index": 418 }, "CreatedAt": "2016-06-16T21:57:11.622222327Z", "UpdatedAt": "2016-06-16T21:57:11.622222327Z", "Spec": { "Name": "helloworld", "TaskTemplate": { "ContainerSpec": { "Image": "alpine", "Args": [ "ping", "docker.com" ] }, "Resources": { "Limits": {}, "Reservations": {} }, "RestartPolicy": { "Condition": "any", "MaxAttempts": 0 }, "Placement": {} }, "Mode": { "Replicated": { "Replicas": 1 } }, "UpdateConfig": { "Parallelism": 1 }, "EndpointSpec": { "Mode": "vip" } }, "Endpoint": { "Spec": {} } } ]
3.运行docker service ps <SERVICE-ID>去查看是那个节点正在运行服务:
[manager1]$ docker service ps helloworld NAME IMAGE NODE DESIRED STATE LAST STATE helloworld.1.8p1vev3fq5zm0mi8g0as41w35 alpine worker2 Running Running 3 minutes
在这种情况下,helloworld服务的一个实例在worker2节点上运行。你可能会看到服务在manager节点上运行。默认情况下,集群中的管理节点可以像工作节点一样执行任务。
Swarm还向你显示服务任务的DESIRED STATE和LAST STATE,这样你就可以看到任务是否根据服务定义运行。
4.在任务运行的节点上运行docker ps,以查看关于任务容器的详细信息。
提示:如果helloworld运行在管理器节点以外的节点上,则必须ssh到该节点。
[worker2]$docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e609dde94e47 alpine:latest "ping docker.com" 3 minutes ago Up 3 minutes helloworld.1.8p1vev3fq5zm0mi8g0as41w35
6)Scale the service in the swarm在集群中扩展服务
一旦将服务部署到集群中,就可以使用Docker CLI来扩展服务中的容器数量。在服务中运行的容器称为“任务tasks”。
1如果还没有,那么打开终端并ssh到运行manager节点的机器中。例如,本教程使用名为manager1的机器。
2.运行以下命令来更改群集中运行的服务的期望状态:
$ docker service scale <SERVICE-ID>=<NUMBER-OF-TASKS>
例如:
$ docker service scale helloworld=5 helloworld scaled to 5
3.运行命令去查看更新的任务列表:
$ docker service ps helloworld NAME IMAGE NODE DESIRED STATE CURRENT STATE helloworld.1.8p1vev3fq5zm0mi8g0as41w35 alpine worker2 Running Running 7 minutes helloworld.2.c7a7tcdq5s0uk3qr88mf8xco6 alpine worker1 Running Running 24 seconds helloworld.3.6crl09vdcalvtfehfh69ogfb1 alpine worker1 Running Running 24 seconds helloworld.4.auky6trawmdlcne8ad8phb0f1 alpine manager1 Running Running 24 seconds helloworld.5.ba19kca06l18zujfwxyc5lkyn alpine worker2 Running Running 24 seconds
你可以看到swarm创建了4个新任务,以扩展到总共5个Alpine Linux运行实例。这些任务分布在群体的三个节点之间。一个在manager1上运行。
4.运行docker ps查看连接节点上运行的容器。下面的例子展示了在manager1上运行的任务:
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 528d68040f95 alpine:latest "ping docker.com" About a minute ago Up About a minute helloworld.4.auky6trawmdlcne8ad8phb0f1
如果希望看到容器在其他节点上运行的信息,请将ssh导入这些节点并运行docker ps命令。
7)Delete the service running on the swarm 删除运行在集群中的服务
本教程的其余步骤不使用helloworld服务,因此现在可以从集群中删除该服务。
1.如果还没有,那么打开终端并ssh到运行manager节点的机器中。例如,本教程使用名为manager1的机器。
2.运行docker service rm helloworld来删除helloworld服务。
$ docker service rm helloworld
helloworld
3.运行docker service inspect <SERVICE-ID>去检查移除了服务的管理机。CLI返回服务找不到的信息:
$ docker service inspect helloworld
[]
Error: no such service: helloworld
4.即使服务不再存在,任务task容器还需要一点时间去清除。你可以在节点中使用docker ps去核查什么时候任务被移除:
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES db1651f50347 alpine:latest "ping docker.com" 44 minutes ago Up 46 seconds helloworld.5.9lkmos2beppihw95vdwxy1j3w 43bf6e532a92 alpine:latest "ping docker.com" 44 minutes ago Up 46 seconds helloworld.3.a71i8rp6fua79ad43ycocl4t2 5a0fb65d8fa7 alpine:latest "ping docker.com" 44 minutes ago Up 45 seconds helloworld.2.2jpgensh7d935qdc857pxulfr afb0ba67076f alpine:latest "ping docker.com" 44 minutes ago Up 46 seconds helloworld.4.1c47o7tluz7drve4vkm2m5olx 688172d3bfaa alpine:latest "ping docker.com" 45 minutes ago Up About a minute helloworld.1.74nbhb3fhud8jfrhigd7s29we $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
8)Apply rolling updates to a service对服务应用滚动更新
在本教程的前一步中,你扩展了服务实例的数量。在本教程的这一部分中,你将部署一个基于Redis 3.0.6容器镜像的服务。然后使用滚动更新将服务升级为使用Redis 3.0.7容器镜像。
1.如果还没有,那么打开终端并ssh到运行manager节点的机器中。例如,本教程使用名为manager1的机器。
2.将Redis 3.0.6部署到集群中,并将集群配置为10秒更新延迟:
$ docker service create --replicas 3 --name redis --update-delay 10s redis:3.0.6 0u6a4s31ybk7yw2wyvtikmu50
在服务部署时配置滚动更新策略。
--update-delay标志配置服务任务或任务集更新之间的时间延迟。你可以将时间T描述为Ts秒数、Tm分钟数或Th小时数的组合。所以10m30s表示10分30秒的延迟。
默认情况下,调度程序每次更新一个任务。你可以传--update-parallelism标志来配置调度程序同时更新的服务任务的最大数量。
默认情况下,当对单个任务的更新返回一个 RUNNING的状态时,调度器将调度另一个任务进行更新,直到所有任务都被更新。如果在更新期间某个任务返回 FAILED,调度程序将暂停更新。你可以使用docker service create或docker service update的--update-failure-action标志来控制该行为。
3.查看redis服务:
$ docker service inspect --pretty redis ID: 0u6a4s31ybk7yw2wyvtikmu50 Name: redis Service Mode: Replicated Replicas: 3 Placement: Strategy: Spread UpdateConfig: Parallelism: 1 Delay: 10s ContainerSpec: Image: redis:3.0.6 Resources: Endpoint Mode: vip
4.现在可以为redis更新容器镜像。集群管理器根据UpdateConfig策略对节点进行更新:
$ docker service update --image redis:3.0.7 redis redis
调度程序在默认情况下应用滚动更新如下:
- 停止第一个任务。
- 为已停止的任务安排更新。
- 启动更新任务的容器。
- 如果某个任务的更新返回RUNNING,则等待指定的延迟期,然后启动下一个任务。
- 如果更新期间某个任务返回FAILED,则暂停更新。
5.运行docker service inspect --pretty redis看到的新镜像在所需的状态的信息:
$ docker service inspect --pretty redis ID: 0u6a4s31ybk7yw2wyvtikmu50 Name: redis Service Mode: Replicated Replicas: 3 Placement: Strategy: Spread UpdateConfig: Parallelism: 1 Delay: 10s ContainerSpec: Image: redis:3.0.7 Resources: Endpoint Mode: vip
service inspect的输出显示你的更新暂停是否是因为失败:
$ docker service inspect --pretty redis ID: 0u6a4s31ybk7yw2wyvtikmu50 Name: redis ...snip... Update status: State: paused Started: 11 seconds ago Message: update paused due to failure or early termination of task 9p7ith557h8ndf0ui9s0q951b ...snip...
运行docker service update <SERVICE-ID>命令去重启一个暂停的更新。比如:
docker service update redis
为了避免重复某些更新失误,你可能需要通过传递标志到docker service update去重新配置服务
6.运行docker service ps <SERVICE-ID>命令去查看回滚更新:
$ docker service ps redis NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR redis.1.dos1zffgeofhagnve8w864fco redis:3.0.7 worker1 Running Running 37 seconds \_ redis.1.88rdo6pa52ki8oqx6dogf04fh redis:3.0.6 worker2 Shutdown Shutdown 56 seconds ago redis.2.9l3i4j85517skba5o7tn5m8g0 redis:3.0.7 worker2 Running Running About a minute \_ redis.2.66k185wilg8ele7ntu8f6nj6i redis:3.0.6 worker1 Shutdown Shutdown 2 minutes ago redis.3.egiuiqpzrdbxks3wxgn8qib1g redis:3.0.7 worker1 Running Running 48 seconds \_ redis.3.ctzktfddb2tepkr45qcmqln04 redis:3.0.6 mmanager1 Shutdown Shutdown 2 minutes ago
在Swarm更新所有的任务之前,你可以看到一些在运行redis:3.0.6,而另一些在运行redis:3.0.7。上面的输出显示了滚动更新完成后的状态。
9)Drain a node on the swarm
在本教程的前面步骤中,所有节点都以ACTIVE可用性运行。集群管理器可以将任务分配给任何ACTIVE节点,因此到目前为止,所有节点都可以接收任务。
有时,例如计划的维护时间,你需要设置一个节点来DRAIN(耗尽)可用性。DRAIN可用性阻止节点从集群管理器接收新任务。它还意味着管理器停止节点上运行的任务,并在具有ACTIVE可用性的节点上启动副本任务。
重要提示:将节点设置为DRAIN并不会从该节点删除独立容器,例如使用docker run、docker- composition或docker Engine API创建的容器。节点的状态(包括DRAIN)只影响节点调度集群服务工作负载的能力。
1.如果还没有,那么打开终端并ssh到运行manager节点的机器中。例如,本教程使用名为manager1的机器。
2.验证所有节点的AVAILABILITY都是Active:
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
1bcef6utixb0l0ca7gxuivsj0 worker2 Ready Active
38ciaotwjuritcdtn9npbnkuz worker1 Ready Active
e216jshn25ckzbvmwlnh5jr3g * manager1 Ready Active Leader
3.如果你还没有在rolling update教程中运行redis,那就现在开始:
$ docker service create --replicas 3 --name redis --update-delay 10s redis:3.0.6 c5uo6kdmzpon37mgj9mwglcfw
4.运行docker service ps redis去查看swarm管理器如何分配任务给不同的节点:
$ docker service ps redis NAME IMAGE NODE DESIRED STATE CURRENT STATE redis.1.7q92v0nr1hcgts2amcjyqg3pq redis:3.0.6 manager1 Running Running 26 seconds redis.2.7h2l8h3q3wqy5f66hlv9ddmi6 redis:3.0.6 worker1 Running Running 26 seconds redis.3.9bg7cezvedmkgg6c8yzvbhwsd redis:3.0.6 worker2 Running Running 26 seconds
在这种情况下,集群管理器将一个任务分配给每个节点。你可能会看到任务在你的环境中的节点之间以不同的方式分布。
5.运行docker node update --availability drain <NODE-ID>命令去耗尽一个有任务分配的节点:
docker node update --availability drain worker1
worker1
6.查看节点去检查它的可用性:
$ docker node inspect --pretty worker1
ID: 38ciaotwjuritcdtn9npbnkuz
Hostname: worker1
Status:
State: Ready
Availability: Drain
...snip...
耗尽的节点显示其AVAILABILITY属性为Drain
7.运行docker service ps redis命令去看swarm管理器是如何为redis服务更新任务分配的:
$ docker service ps redis NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR redis.1.7q92v0nr1hcgts2amcjyqg3pq redis:3.0.6 manager1 Running Running 4 minutes redis.2.b4hovzed7id8irg1to42egue8 redis:3.0.6 worker2 Running Running About a minute \_ redis.2.7h2l8h3q3wqy5f66hlv9ddmi6 redis:3.0.6 worker1 Shutdown Shutdown 2 minutes ago redis.3.9bg7cezvedmkgg6c8yzvbhwsd redis:3.0.6 worker2 Running Running 4 minutes
群管理器通过在节点上以Drain可用性结束任务并在具有Active可用性的节点上创建新任务来维护所需的状态。
8.运行docker node update --availability active <NODE-ID>去将耗尽节点返回活跃状态:
$ docker node update --availability active worker1
worker1
9.查看节点去看更新状态:
$ docker node inspect --pretty worker1
ID: 38ciaotwjuritcdtn9npbnkuz
Hostname: worker1
Status:
State: Ready
Availability: Active
...snip...
当你将节点设置回Active可用性时,当下面的状况发生时,它就可以接收新任务了:
- 在服务更新期间进行扩展
- 在滚动更新期间
- 当你设置另一个节点以Drain可用性时
- 当另一个活动节点上的任务失败时
10)Use swarm mode routing mesh使用集群模式路由网格
Docker Engine swarm模式使发布服务端口变得很容易,从而使服务端口对集群之外的资源可用。所有节点都参与一个ingress路由网格。路由网格允许集群中的每个节点接受集群中运行的任何服务的已发布端口上的连接,即使节点上没有运行任务。路由网格将所有传入的请求路由到可用节点上的已发布端口到活跃容器。
要在集群中使用入口网络,在启用群模式之前,需要在群节点之间打开以下端口:
- 用于容器网络发现的端口7946 TCP/UDP。
- 用于容器入口网络的端口4789 UDP。
你还必须在集群节点和任何外部资源(如外部负载平衡器)之间打开已发布的端口,这些外部资源需要访问该端口。
你还可以绕过给定服务的路由网格。
Publish a port for a service为服务发布端口
创建服务时,使用--publish标志发布端口。target用于指定容器内的端口,published用于指定要在路由网格上绑定的端口。如果不使用已发布的端口,则为每个服务任务绑定一个随机的高编号端口。你需要检查任务以确定端口。
$ docker service create --name <SERVICE-NAME> --publish published=<PUBLISHED-PORT>,target=<CONTAINER-PORT> <IMAGE>
注意:这种语法的旧形式是冒号分隔的字符串,其中发布的端口是第一个,目标端口是第二个,例如-p 8080:80。新的语法是首选的,因为它更容易阅读,并允许更多的灵活性。
<PUBLISHED-PORT>是集群提供服务的端口。如果省略它,则会绑定一个随机的高编号端口。<CONTAINER-PORT>是容器监听的端口。此参数是必需的。
例如,下面的命令将nginx容器中的端口80发布到集群中任意节点的端口8080:
$ docker service create --name my-web --publish published=8080,target=80 --replicas 2 nginx
当你访问任何节点上的端口8080时,Docker将你的请求路由到活跃容器。在集群节点本身上,端口8080实际上可能没有被绑定,但是路由网格知道如何路由流量并防止任何端口冲突的发生。
路由网格监听发布端口上分配给节点的任何IP地址。对于外部可路由的IP地址,端口可以从主机外部获得。对于所有其他IP地址,只能从主机内部访问。

从上面的图可以看出来,当从外部访问192.168.99.100:8080、192.168.99.101:8080或192.168.99.101:8080其中之一的服务时,其实会通过swarm的负载均衡去调用对应的10.0.0.1:80或10.0.0.2:80之一的容器
你可以使用下面的命令去为存在的服务发布节点:
$ docker service update --publish-add published=<PUBLISHED-PORT>,target=<CONTAINER-PORT> <SERVICE>
你可以使用docker service inspect命令去查看服务的发布端口。比如:
$ docker service inspect --format="{{json .Endpoint.Spec.Ports}}" my-web [{"Protocol":"tcp","TargetPort":80,"PublishedPort":8080}]
输出显示来自容器的<CONTAINER-PORT>(标记为TargetPort)和节点侦听服务请求的<PUBLISHED-PORT>(标记为PublishedPort)。
Publish a port for TCP only or UDP only 仅发布TCP端口或UDP端口
默认情况下,当你发布端口时,它是TCP端口。你可以专门发布UDP端口,而不是TCP端口,或者在TCP端口之外发布。当你同时发布TCP和UDP端口时,如果你省略了protocol说明符,则该端口将作为TCP端口发布。如果使用较长的语法(建议使用Docker 1.13或更高版本),则将protocol密钥设置为tcp或udp。
TCP ONLY
长语法:
$ docker service create --name dns-cache --publish published=53,target=53 dns-cache
短语法:
$ docker service create --name dns-cache -p 53:53 dns-cache
TCP AND UDP
长语法:
$ docker service create --name dns-cache --publish published=53,target=53 --publish published=53,target=53,protocol=udp dns-cache
短语法:
$ docker service create --name dns-cache -p 53:53 -p 53:53/udp dns-cache
UDP ONLY
长语法:
$ docker service create --name dns-cache --publish published=53,target=53,protocol=udp dns-cache
短语法:
$ docker service create --name dns-cache -p 53:53/udp dns-cache
Bypass the routing mesh绕过路由网格
你可以绕过路由网格,以便在访问给定节点上的绑定端口时,你总是在访问该节点上运行的服务的实例。这称为host模式。有几件事要记住。
如果你访问的节点不运行服务任务,则该服务不会监听该端口。可能没有什么在监听,或者是一个完全不同的应用程序在监听。
如果希望在每个节点上运行多个服务任务(例如有5个节点但运行10个副本),则无法指定静态目标端口。要么允许Docker分配一个随机的高编号端口(通过删除已发布的端口),要么通过使用全局服务而不是副本服务,或者通过使用位置约束,确保在给定的节点上只运行一个服务实例。
要绕过路由网格,必须使用长 --publish服务并将mode设置为host。如果省略mode键或将其设置为ingress,则使用路由网格。下面的命令使用host主机模式并绕过路由网格创建全局服务。
$ docker service create --name dns-cache --publish published=53,target=53,protocol=udp,mode=host --mode global dns-cache
总结:使用路由网络就是不管你的节点上是否运行了某个任务,是否监听着端口80,你这个节点都会去接受集群中发布的连接;而绕过路由网络就是如果你的节点上没有运行某个任务,那么你就不会去接受集群中发布的连接,只有有这个任务的节点才接受
Configure an external load balancer配置一个外部负载均衡
你可以为集群服务配置外部负载平衡器,可以与路由网格结合使用,也可以完全不使用路由网格。
Using the routing mesh使用路由网格
你可以配置外部负载均衡器来将请求路由到集群服务。例如,你可以配置HAProxy来平衡对发布到端口8080的nginx服务的请求。
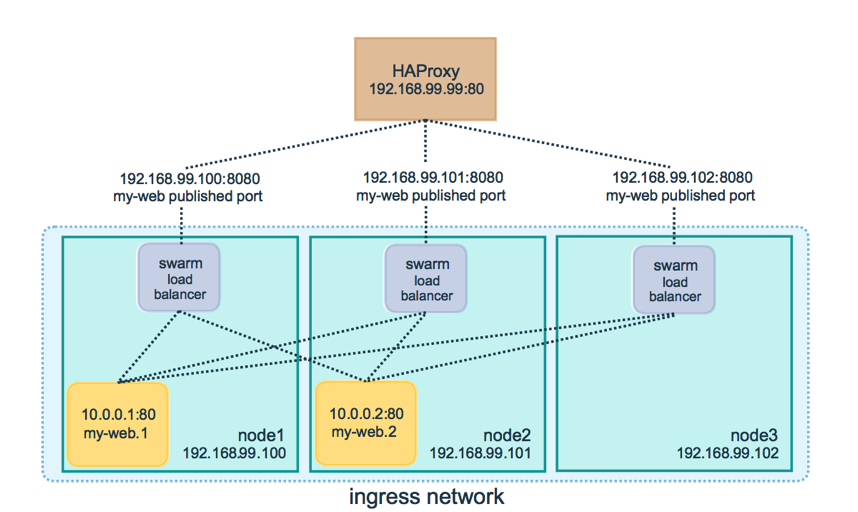
在这种情况下,负载均衡器和集群中的节点之间的端口8080必须打开。集群节点可以驻留在代理服务器可以访问的私有网络上,但不能公开访问。
你可以配置负载均衡器来平衡集群中每个节点之间的请求,即使节点上没有调度任务。例如,你可以在/etc/haproxy/haproxy.cfg中配置以下HAProxy:
global log /dev/log local0 log /dev/log local1 notice ...snip... # Configure HAProxy to listen on port 80 frontend http_front bind *:80 stats uri /haproxy?stats default_backend http_back # Configure HAProxy to route requests to swarm nodes on port 8080 backend http_back balance roundrobin server node1 192.168.99.100:8080 check server node2 192.168.99.101:8080 check server node3 192.168.99.102:8080 check
当你访问端口80上的HAProxy负载均衡器时,它将请求转发给集群中的节点。集群路由网格将请求路由到一个活动任务。如果由于任何原因,集群调度器将任务分派到不同的节点,则不需要重新配置负载均衡器。
你可以配置任何类型的负载均衡器来将请求路由到集群节点。要了解更多关于HAProxy的信息,请参阅HAProxy文档HAProxy documentation。
Without the routing mesh
若要在没有路由网格的情况下使用外部负载均衡器,请将--endpoint-mode设置为dnsrr,而不是vip的默认值。在这种情况下,没有一个虚拟IP。相反,Docker为服务设置DNS条目,以便服务名称的DNS查询返回一个IP地址列表,客户端直接连接到其中之一。你负责向负载均衡器提供IP地址和端口的列表。更多信息参见配置服务发现 Configure service discovery。