整理并翻译自吴恩达深度学习系列视频:结构化机器学习2.8。
与迁移学习的对比
在迁移学习时,你有一个顺序执行的过程,先学习任务A,然后迁移到任务B。
在多任务学习中,你开始就使用一个神经网络同时做几个任务,并且希望这些任务里的每一个都可以帮助到其他的任务。

如上图,你需要同时检测行人、车辆、停止标志、交通信号灯。
多任务学习的网络结构
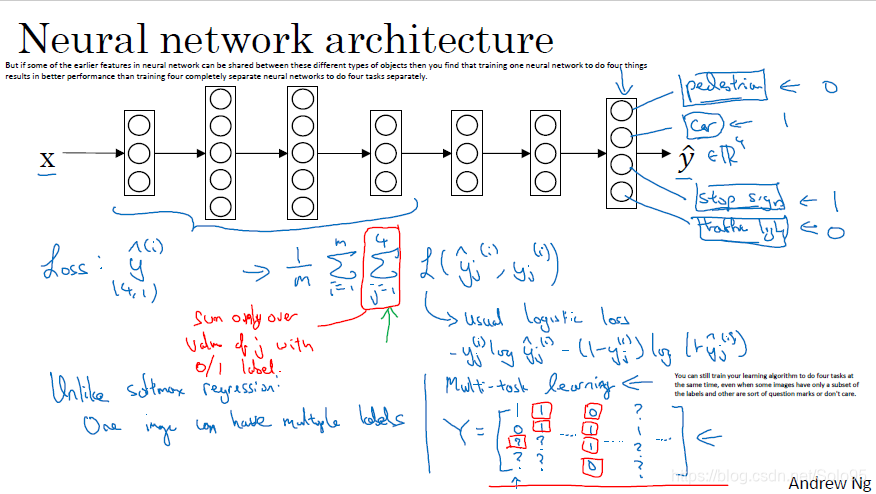
重点在最后一层,有四个神经元。输出
y
h
a
t
y^{hat}
yhat是一个4*1的vector。
它跟softmax regression的区别在于,softmax regression只给一个图像输出一个标签,而多任务学习给一个图像输出了多个标签(如本例4*1向量中有四个标签)。
计算损失函数时,多了从第一个标签产生的loss到最后一个标签产生的loss的求和(图中红色部分)。
l
o
s
s
:
y
h
a
t
→
1
m
∑
i
=
1
m
∑
j
=
1
4
l
(
y
i
h
a
t
(
i
)
,
y
i
(
i
)
)
loss:y^{hat}
ightarrowfrac{1}{m}sum_{i=1}^msum_{j=1}^4l(y_i^{hat (i)},y_i^{ (i)})
loss:yhat→m1i=1∑mj=1∑4l(yihat (i),yi(i))
l使用的是logistic regression。
什么时候使用多任务学习

- 在一系列任务上进行训练,它们有共享的底层特征,这使得任务之间相互获益。
- 常见用例:你每个任务的数据量过小。
- 你可以训练一个足够大的网络使得它在所有的任务上都表现良好。
原字幕:
If you can train a big enough neural network, then multi-task learning certainly should not or should rarely hurt performance. And hopefully it will actually help performance compared to if you were
training neural networks to do different tasks in isolation.
In practice, multi-task learning is used much less often than transfer learning.
关键点在于,你的网络必须足够大,在这个条件下多任务学习才不会对总体性能产生有害影响。
实践中,多任务学习比迁移学习用得少得多。