来自吴恩达深度学习系列视频:序列模型第二周作业1:Operations on word vectors。如果英文对你来说有困难,可以参照:【中文】【吴恩达课后编程作业】Course 5 - 序列模型 - 第二周作业 - 词向量的运算与Emoji生成器,参照对英文的翻译并不能说完全准确,请注意这点。
完整的ipynb文件参见博主github:
https://github.com/Hongze-Wang/Deep-Learning-Andrew-Ng/tree/master/homework
在读取data/glove.6B.50d.txt你可能会遇到这样一个问题:
'gbk' codec can't decode byte 0x93 in position 3136
解压作业文件夹同名压缩包,并更改w2v_utils.py文件中的读取函数的with open部分如下:

Basically,增加了隐藏参数encoding指定了打开文件的编码是“utf-8”。
更改之后重启jupyter kernel即可正常运行。
Operations on word vectors
Welcome to your first assignment of this week!
Because word embeddings are very computionally expensive to train, most ML practitioners will load a pre-trained set of embeddings.
After this assignment you will be able to:
- Load pre-trained word vectors, and measure similarity using cosine similarity
- Use word embeddings to solve word analogy problems such as Man is to Woman as King is to ______.
- Modify word embeddings to reduce their gender bias
Let’s get started! Run the following cell to load the packages you will need.
import numpy as np
from w2v_utils import *
Using TensorFlow backend.
Next, lets load the word vectors. For this assignment, we will use 50-dimensional GloVe vectors to represent words. Run the following cell to load the word_to_vec_map.
words, word_to_vec_map = read_glove_vecs('data/glove.6B.50d.txt')
You’ve loaded:
words: set of words in the vocabulary.word_to_vec_map: dictionary mapping words to their GloVe vector representation.
You’ve seen that one-hot vectors do not do a good job cpaturing what words are similar. GloVe vectors provide much more useful information about the meaning of individual words. Lets now see how you can use GloVe vectors to decide how similar two words are.
1 - Cosine similarity
To measure how similar two words are, we need a way to measure the degree of similarity between two embedding vectors for the two words. Given two vectors u u u and v v v, cosine similarity is defined as follows:
(1) CosineSimilarity(u, v) = u . v ∣ ∣ u ∣ ∣ 2 ∣ ∣ v ∣ ∣ 2 = c o s ( θ ) ext{CosineSimilarity(u, v)} = frac {u . v} {||u||_2 ||v||_2} = cos( heta) ag{1} CosineSimilarity(u, v)=∣∣u∣∣2∣∣v∣∣2u.v=cos(θ)(1)
where u . v u.v u.v is the dot product (or inner product) of two vectors, ∣ ∣ u ∣ ∣ 2 ||u||_2 ∣∣u∣∣2 is the norm (or length) of the vector u u u, and θ heta θ is the angle between u u u and v v v. This similarity depends on the angle between u u u and v v v. If u u u and v v v are very similar, their cosine similarity will be close to 1; if they are dissimilar, the cosine similarity will take a smaller value.
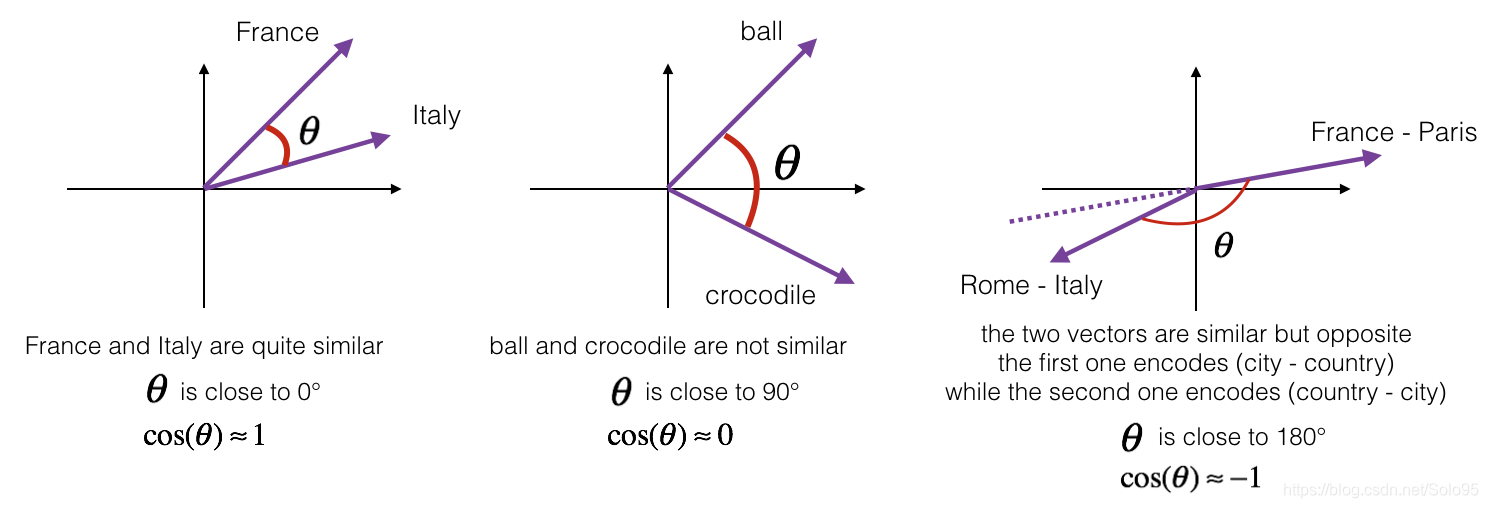
Exercise: Implement the function cosine_similarity() to evaluate similarity between word vectors.
Reminder: The norm of u u u is defined as $ ||u||2 = sqrt{sum{i=1}^{n} u_i^2}$
# GRADED FUNCTION: cosine_similarity
def cosine_similarity(u, v):
"""
Cosine similarity reflects the degree of similariy between u and v
Arguments:
u -- a word vector of shape (n,)
v -- a word vector of shape (n,)
Returns:
cosine_similarity -- the cosine similarity between u and v defined by the formula above.
"""
distance = 0.0
### START CODE HERE ###
# Compute the dot product between u and v (≈1 line)
dot = np.dot(u, v)
# Compute the L2 norm of u (≈1 line)
norm_u = np.sqrt(np.sum(np.power(u, 2)))
# Compute the L2 norm of v (≈1 line)
norm_v = np.sqrt(np.sum(np.square(v)))
# Compute the cosine similarity defined by formula (1) (≈1 line)
cosine_similarity = np.divide(dot, norm_u*norm_v)
### END CODE HERE ###
return cosine_similarity
father = word_to_vec_map["father"]
mother = word_to_vec_map["mother"]
ball = word_to_vec_map["ball"]
crocodile = word_to_vec_map["crocodile"]
france = word_to_vec_map["france"]
italy = word_to_vec_map["italy"]
paris = word_to_vec_map["paris"]
rome = word_to_vec_map["rome"]
print("cosine_similarity(father, mother) = ", cosine_similarity(father, mother))
print("cosine_similarity(ball, crocodile) = ",cosine_similarity(ball, crocodile))
print("cosine_similarity(france - paris, rome - italy) = ",cosine_similarity(france - paris, rome - italy))
cosine_similarity(father, mother) = 0.8909038442893615
cosine_similarity(ball, crocodile) = 0.2743924626137942
cosine_similarity(france - paris, rome - italy) = -0.6751479308174201
After you get the correct expected output, please feel free to modify the inputs and measure the cosine similarity between other pairs of words! Playing around the cosine similarity of other inputs will give you a better sense of how word vectors behave.
2 - Word analogy task
In the word analogy task, we complete the sentence “a is to b as c is to ____”. An example is ‘man is to woman as king is to queen’ . In detail, we are trying to find a word d, such that the associated word vectors e a , e b , e c , e d e_a, e_b, e_c, e_d ea,eb,ec,ed are related in the following manner: e b − e a ≈ e d − e c e_b - e_a approx e_d - e_c eb−ea≈ed−ec. We will measure the similarity between e b − e a e_b - e_a eb−ea and e d − e c e_d - e_c ed−ec using cosine similarity.
Exercise: Complete the code below to be able to perform word analogies!
# GRADED FUNCTION: complete_analogy
def complete_analogy(word_a, word_b, word_c, word_to_vec_map):
"""
Performs the word analogy task as explained above: a is to b as c is to ____.
Arguments:
word_a -- a word, string
word_b -- a word, string
word_c -- a word, string
word_to_vec_map -- dictionary that maps words to their corresponding vectors.
Returns:
best_word -- the word such that v_b - v_a is close to v_best_word - v_c, as measured by cosine similarity
"""
# convert words to lower case
word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower()
### START CODE HERE ###
# Get the word embeddings v_a, v_b and v_c (≈1-3 lines)
e_a, e_b, e_c = word_to_vec_map[word_a], word_to_vec_map[word_b], word_to_vec_map[word_c]
### END CODE HERE ###
words = word_to_vec_map.keys()
max_cosine_sim = -100 # Initialize max_cosine_sim to a large negative number
best_word = None # Initialize best_word with None, it will help keep track of the word to output
# loop over the whole word vector set
for w in words:
# to avoid best_word being one of the input words, pass on them.
if w in [word_a, word_b, word_c] :
continue
### START CODE HERE ###
# Compute cosine similarity between the combined_vector and the current word (≈1 line)
cosine_sim = cosine_similarity((e_b-e_a), (word_to_vec_map[w]-e_c))
# If the cosine_sim is more than the max_cosine_sim seen so far,
# then: set the new max_cosine_sim to the current cosine_sim and the best_word to the current word (≈3 lines)
if cosine_sim > max_cosine_sim:
max_cosine_sim = cosine_sim
best_word = w
### END CODE HERE ###
return best_word
Run the cell below to test your code, this may take 1-2 minutes.
triads_to_try = [('italy', 'italian', 'spain'), ('india', 'delhi', 'japan'), ('man', 'woman', 'boy'), ('small', 'smaller', 'large')]
for triad in triads_to_try:
print ('{} -> {} :: {} -> {}'.format( *triad, complete_analogy(*triad,word_to_vec_map)))
italy -> italian :: spain -> spanish
india -> delhi :: japan -> tokyo
man -> woman :: boy -> girl
small -> smaller :: large -> larger
Once you get the correct expected output, please feel free to modify the input cells above to test your own analogies. Try to find some other analogy pairs that do work, but also find some where the algorithm doesn’t give the right answer: For example, you can try small->smaller as big->?.
Congratulations!
You’ve come to the end of this assignment. Here are the main points you should remember:
- Cosine similarity a good way to compare similarity between pairs of word vectors. (Though L2 distance works too.)
- For NLP applications, using a pre-trained set of word vectors from the internet is often a good way to get started.
Even though you have finished the graded portions, we recommend you take a look too at the rest of this notebook.
Congratulations on finishing the graded portions of this notebook!
3 - Debiasing word vectors (OPTIONAL/UNGRADED)
In the following exercise, you will examine gender biases that can be reflected in a word embedding, and explore algorithms for reducing the bias. In addition to learning about the topic of debiasing, this exercise will also help hone your intuition about what word vectors are doing. This section involves a bit of linear algebra, though you can probably complete it even without being expert in linear algebra, and we encourage you to give it a shot. This portion of the notebook is optional and is not graded.
Lets first see how the GloVe word embeddings relate to gender. You will first compute a vector g = e w o m a n − e m a n g = e_{woman}-e_{man} g=ewoman−eman, where e w o m a n e_{woman} ewoman represents the word vector corresponding to the word woman, and e m a n e_{man} eman corresponds to the word vector corresponding to the word man. The resulting vector g g g roughly encodes the concept of “gender”. (You might get a more accurate representation if you compute g 1 = e m o t h e r − e f a t h e r g_1 = e_{mother}-e_{father} g1=emother−efather, g 2 = e g i r l − e b o y g_2 = e_{girl}-e_{boy} g2=egirl−eboy, etc. and average over them. But just using e w o m a n − e m a n e_{woman}-e_{man} ewoman−eman will give good enough results for now.)
g = word_to_vec_map['woman'] - word_to_vec_map['man']
print(g)
[-0.087144 0.2182 -0.40986 -0.03922 -0.1032 0.94165
-0.06042 0.32988 0.46144 -0.35962 0.31102 -0.86824
0.96006 0.01073 0.24337 0.08193 -1.02722 -0.21122
0.695044 -0.00222 0.29106 0.5053 -0.099454 0.40445
0.30181 0.1355 -0.0606 -0.07131 -0.19245 -0.06115
-0.3204 0.07165 -0.13337 -0.25068714 -0.14293 -0.224957
-0.149 0.048882 0.12191 -0.27362 -0.165476 -0.20426
0.54376 -0.271425 -0.10245 -0.32108 0.2516 -0.33455
-0.04371 0.01258 ]
Now, you will consider the cosine similarity of different words with g g g. Consider what a positive value of similarity means vs a negative cosine similarity.
print ('List of names and their similarities with constructed vector:')
# girls and boys name
name_list = ['john', 'marie', 'sophie', 'ronaldo', 'priya', 'rahul', 'danielle', 'reza', 'katy', 'yasmin']
for w in name_list:
print (w, cosine_similarity(word_to_vec_map[w], g))
List of names and their similarities with constructed vector:
john -0.23163356145973724
marie 0.315597935396073
sophie 0.31868789859418784
ronaldo -0.31244796850329437
priya 0.17632041839009402
rahul -0.16915471039231716
danielle 0.24393299216283895
reza -0.07930429672199553
katy 0.2831068659572615
yasmin 0.23313857767928758
As you can see, female first names tend to have a positive cosine similarity with our constructed vector g g g, while male first names tend to have a negative cosine similarity. This is not suprising, and the result seems acceptable.
But let’s try with some other words.
print('Other words and their similarities:')
word_list = ['lipstick', 'guns', 'science', 'arts', 'literature', 'warrior','doctor', 'tree', 'receptionist',
'technology', 'fashion', 'teacher', 'engineer', 'pilot', 'computer', 'singer']
for w in word_list:
print (w, cosine_similarity(word_to_vec_map[w], g))
Other words and their similarities:
lipstick 0.2769191625638267
guns -0.1888485567898898
science -0.06082906540929701
arts 0.008189312385880337
literature 0.06472504433459932
warrior -0.20920164641125288
doctor 0.11895289410935041
tree -0.07089399175478091
receptionist 0.33077941750593737
technology -0.13193732447554302
fashion 0.03563894625772699
teacher 0.17920923431825664
engineer -0.0803928049452407
pilot 0.0010764498991916937
computer -0.10330358873850498
singer 0.1850051813649629
Do you notice anything surprising? It is astonishing how these results reflect certain unhealthy gender stereotypes. For example, “computer” is closer to “man” while “literature” is closer to “woman”. Ouch!
We’ll see below how to reduce the bias of these vectors, using an algorithm due to Boliukbasi et al., 2016. Note that some word pairs such as “actor”/“actress” or “grandmother”/“grandfather” should remain gender specific, while other words such as “receptionist” or “technology” should be neutralized, i.e. not be gender-related. You will have to treat these two type of words differently when debiasing.
3.1 - Neutralize bias for non-gender specific words
The figure below should help you visualize what neutralizing does. If you’re using a 50-dimensional word embedding, the 50 dimensional space can be split into two parts: The bias-direction g g g, and the remaining 49 dimensions, which we’ll call g ⊥ g_{perp} g⊥. In linear algebra, we say that the 49 dimensional g ⊥ g_{perp} g⊥ is perpendicular (or “othogonal”) to g g g, meaning it is at 90 degrees to g g g. The neutralization step takes a vector such as e r e c e p t i o n i s t e_{receptionist} ereceptionist and zeros out the component in the direction of g g g, giving us e r e c e p t i o n i s t d e b i a s e d e_{receptionist}^{debiased} ereceptionistdebiased.
Even though
g
⊥
g_{perp}
g⊥ is 49 dimensional, given the limitations of what we can draw on a screen, we illustrate it using a 1 dimensional axis below.
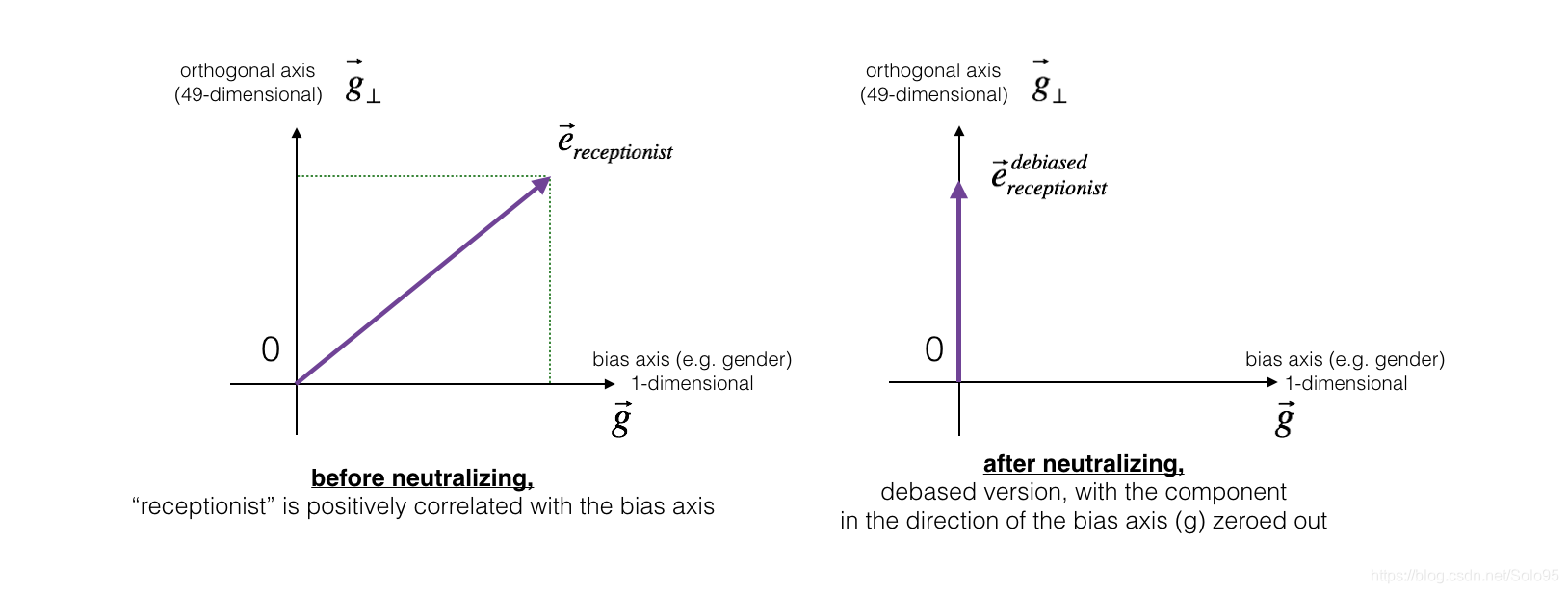
Exercise: Implement neutralize() to remove the bias of words such as “receptionist” or “scientist”. Given an input embedding
e
e
e, you can use the following formulas to compute
e
d
e
b
i
a
s
e
d
e^{debiased}
edebiased:
(2)
e
b
i
a
s
_
c
o
m
p
o
n
e
n
t
=
e
⋅
g
∣
∣
g
∣
∣
2
2
∗
g
e^{bias\_component} = frac{e cdot g}{||g||_2^2} * g ag{2}
ebias_component=∣∣g∣∣22e⋅g∗g(2)
(3)
e
d
e
b
i
a
s
e
d
=
e
−
e
b
i
a
s
_
c
o
m
p
o
n
e
n
t
e^{debiased} = e - e^{bias\_component} ag{3}
edebiased=e−ebias_component(3)
If you are an expert in linear algebra, you may recognize e b i a s _ c o m p o n e n t e^{bias\_component} ebias_component as the projection of e e e onto the direction g g g. If you’re not an expert in linear algebra, don’t worry about this.
def neutralize(word, g, word_to_vec_map):
"""
Removes the bias of "word" by projecting it on the space orthogonal to the bias axis.
This function ensures that gender neutral words are zero in the gender subspace.
Arguments:
word -- string indicating the word to debias
g -- numpy-array of shape (50,), corresponding to the bias axis (such as gender)
word_to_vec_map -- dictionary mapping words to their corresponding vectors.
Returns:
e_debiased -- neutralized word vector representation of the input "word"
"""
### START CODE HERE ###
# Select word vector representation of "word". Use word_to_vec_map. (≈ 1 line)
e = word_to_vec_map[word]
# Compute e_biascomponent using the formula give above. (≈ 1 line)
e_biascomponent = np.divide(np.dot(e, g), np.square(np.linalg.norm(g))) * g
# Neutralize e by substracting e_biascomponent from it
# e_debiased should be equal to its orthogonal projection. (≈ 1 line)
e_debiased = e - e_biascomponent
### END CODE HERE ###
return e_debiased
e = "receptionist"
print("cosine similarity between " + e + " and g, before neutralizing: ", cosine_similarity(word_to_vec_map["receptionist"], g))
e_debiased = neutralize("receptionist", g, word_to_vec_map)
print("cosine similarity between " + e + " and g, after neutralizing: ", cosine_similarity(e_debiased, g))
cosine similarity between receptionist and g, before neutralizing: 0.33077941750593737
cosine similarity between receptionist and g, after neutralizing: -2.099120994400013e-17
3.2 - Equalization algorithm for gender-specific words
Next, lets see how debiasing can also be applied to word pairs such as “actress” and “actor.” Equalization is applied to pairs of words that you might want to have differ only through the gender property. As a concrete example, suppose that “actress” is closer to “babysit” than “actor.” By applying neutralizing to “babysit” we can reduce the gender-stereotype associated with babysitting. But this still does not guarantee that “actor” and “actress” are equidistant from “babysit.” The equalization algorithm takes care of this.
The key idea behind equalization is to make sure that a particular pair of words are equi-distant from the 49-dimensional
g
⊥
g_perp
g⊥. The equalization step also ensures that the two equalized steps are now the same distance from
e
r
e
c
e
p
t
i
o
n
i
s
t
d
e
b
i
a
s
e
d
e_{receptionist}^{debiased}
ereceptionistdebiased, or from any other work that has been neutralized. In pictures, this is how equalization works:
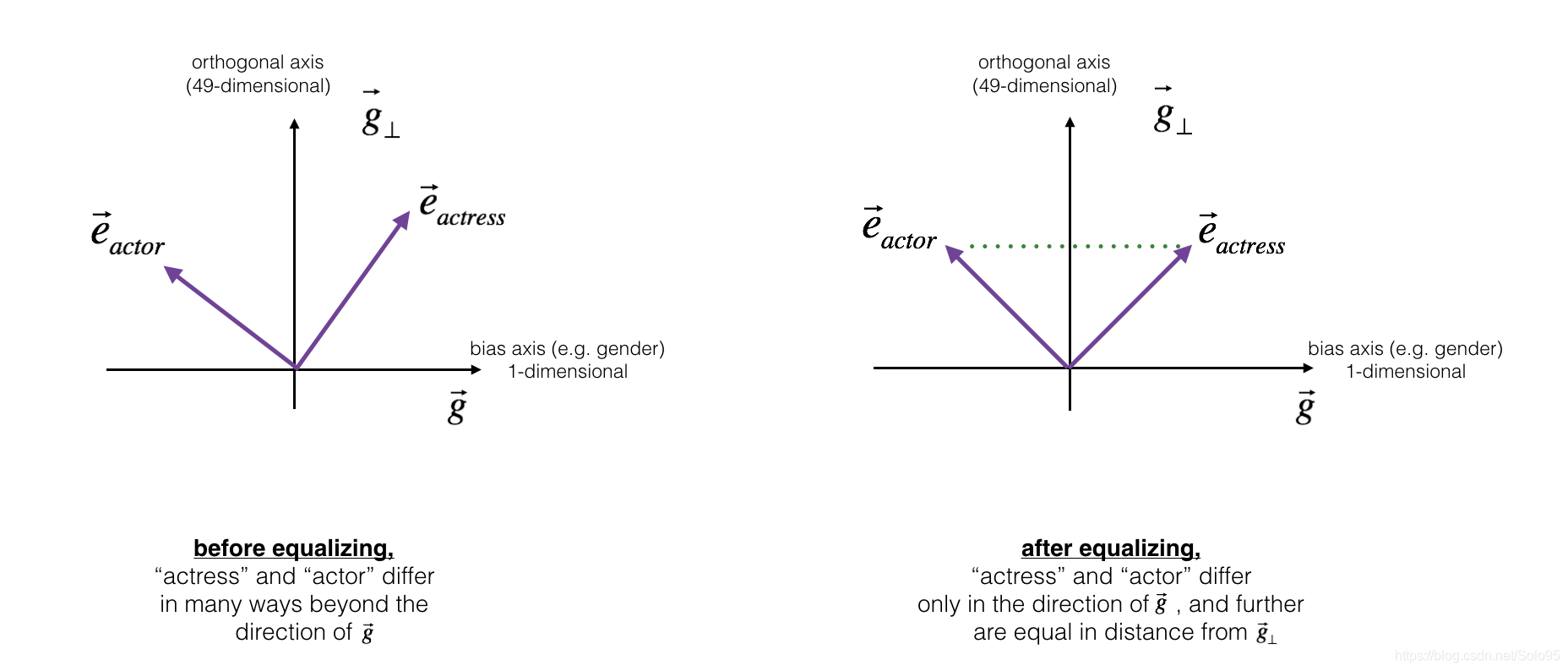
The derivation of the linear algebra to do this is a bit more complex. (See Bolukbasi et al., 2016 for details.) But the key equations are:
(4) μ = e w 1 + e w 2 2 mu = frac{e_{w1} + e_{w2}}{2} ag{4} μ=2ew1+ew2(4)
KaTeX parse error: Expected '}', got '_' at position 39: …cdot ext{bias_̲axis}}{|| ext{…
(6) μ ⊥ = μ − μ B mu_{perp} = mu - mu_{B} ag{6} μ⊥=μ−μB(6)
KaTeX parse error: Expected '}', got '_' at position 42: …cdot ext{bias_̲axis}}{|| ext{…
KaTeX parse error: Expected '}', got '_' at position 42: …cdot ext{bias_̲axis}}{|| ext{…
(9) e w 1 B c o r r e c t e d = ∣ 1 − ∣ ∣ μ ⊥ ∣ ∣ 2 2 ∣ ∗ e w1B − μ B ∣ ( e w 1 − μ ⊥ ) − μ B ) ∣ e_{w1B}^{corrected} = sqrt{ |{1 - ||mu_{perp} ||^2_2} |} * frac{e_{ ext{w1B}} - mu_B} {|(e_{w1} - mu_{perp}) - mu_B)|} ag{9} ew1Bcorrected=∣1−∣∣μ⊥∣∣22∣∗∣(ew1−μ⊥)−μB)∣ew1B−μB(9)
(10) e w 2 B c o r r e c t e d = ∣ 1 − ∣ ∣ μ ⊥ ∣ ∣ 2 2 ∣ ∗ e w2B − μ B ∣ ( e w 2 − μ ⊥ ) − μ B ) ∣ e_{w2B}^{corrected} = sqrt{ |{1 - ||mu_{perp} ||^2_2} |} * frac{e_{ ext{w2B}} - mu_B} {|(e_{w2} - mu_{perp}) - mu_B)|} ag{10} ew2Bcorrected=∣1−∣∣μ⊥∣∣22∣∗∣(ew2−μ⊥)−μB)∣ew2B−μB(10)
(11)
e
1
=
e
w
1
B
c
o
r
r
e
c
t
e
d
+
μ
⊥
e_1 = e_{w1B}^{corrected} + mu_{perp} ag{11}
e1=ew1Bcorrected+μ⊥(11)
(12)
e
2
=
e
w
2
B
c
o
r
r
e
c
t
e
d
+
μ
⊥
e_2 = e_{w2B}^{corrected} + mu_{perp} ag{12}
e2=ew2Bcorrected+μ⊥(12)
Exercise: Implement the function below. Use the equations above to get the final equalized version of the pair of words. Good luck!
def equalize(pair, bias_axis, word_to_vec_map):
"""
Debias gender specific words by following the equalize method described in the figure above.
Arguments:
pair -- pair of strings of gender specific words to debias, e.g. ("actress", "actor")
bias_axis -- numpy-array of shape (50,), vector corresponding to the bias axis, e.g. gender
word_to_vec_map -- dictionary mapping words to their corresponding vectors
Returns
e_1 -- word vector corresponding to the first word
e_2 -- word vector corresponding to the second word
"""
### START CODE HERE ###
# Step 1: Select word vector representation of "word". Use word_to_vec_map. (≈ 2 lines)
w1, w2 = pair
e_w1, e_w2 = word_to_vec_map[w1], word_to_vec_map[w2]
# Step 2: Compute the mean of e_w1 and e_w2 (≈ 1 line)
mu = (e_w1 + e_w2)/2.0
# Step 3: Compute the projections of mu over the bias axis and the orthogonal axis (≈ 2 lines)
mu_B = np.divide(np.dot(mu, bias_axis), np.square(np.linalg.norm(bias_axis))) * bias_axis
mu_orth = mu - mu_B
# Step 4: Use equations (7) and (8) to compute e_w1B and e_w2B (≈2 lines)
e_w1B = np.divide(np.dot(e_w1, bias_axis), np.square(np.linalg.norm(bias_axis))) * bias_axis
e_w2B = np.divide(np.dot(e_w2, bias_axis), np.square(np.linalg.norm(bias_axis))) * bias_axis
# Step 5: Adjust the Bias part of e_w1B and e_w2B using the formulas (9) and (10) given above (≈2 lines)
corrected_e_w1B = np.sqrt(np.abs(1-np.square(np.linalg.norm(mu_orth)))) * np.divide((e_w1B-mu_B), np.abs(e_w1-mu_orth-mu_B))
corrected_e_w2B = np.sqrt(np.abs(1-np.square(np.linalg.norm(mu_orth)))) * np.divide((e_w2B-mu_B), np.abs(e_w2-mu_orth-mu_B))
# Step 6: Debias by equalizing e1 and e2 to the sum of their corrected projections (≈2 lines)
e1 = corrected_e_w1B + mu_orth
e2 = corrected_e_w2B + mu_orth
### END CODE HERE ###
return e1, e2
print("cosine similarities before equalizing:")
print("cosine_similarity(word_to_vec_map["man"], gender) = ", cosine_similarity(word_to_vec_map["man"], g))
print("cosine_similarity(word_to_vec_map["woman"], gender) = ", cosine_similarity(word_to_vec_map["woman"], g))
print()
e1, e2 = equalize(("man", "woman"), g, word_to_vec_map)
print("cosine similarities after equalizing:")
print("cosine_similarity(e1, gender) = ", cosine_similarity(e1, g))
print("cosine_similarity(e2, gender) = ", cosine_similarity(e2, g))
cosine similarities before equalizing:
cosine_similarity(word_to_vec_map["man"], gender) = -0.11711095765336832
cosine_similarity(word_to_vec_map["woman"], gender) = 0.35666618846270376
cosine similarities after equalizing:
cosine_similarity(e1, gender) = -0.7165727525843935
cosine_similarity(e2, gender) = 0.7396596474928909
Please feel free to play with the input words in the cell above, to apply equalization to other pairs of words.
These debiasing algorithms are very helpful for reducing bias, but are not perfect and do not eliminate all traces of bias. For example, one weakness of this implementation was that the bias direction g g g was defined using only the pair of words woman and man. As discussed earlier, if g g g were defined by computing g 1 = e w o m a n − e m a n g_1 = e_{woman} - e_{man} g1=ewoman−eman; g 2 = e m o t h e r − e f a t h e r g_2 = e_{mother} - e_{father} g2=emother−efather; g 3 = e g i r l − e b o y g_3 = e_{girl} - e_{boy} g3=egirl−eboy; and so on and averaging over them, you would obtain a better estimate of the “gender” dimension in the 50 dimensional word embedding space. Feel free to play with such variants as well.
Congratulations
You have come to the end of this notebook, and have seen a lot of the ways that word vectors can be used as well as modified.
Congratulations on finishing this notebook!
References:
- The debiasing algorithm is from Bolukbasi et al., 2016, Man is to Computer Programmer as Woman is to
Homemaker? Debiasing Word Embeddings - The GloVe word embeddings were due to Jeffrey Pennington, Richard Socher, and Christopher D. Manning. (https://nlp.stanford.edu/projects/glove/)