前些天,运维告诉我刚上线的java服务占用CPU过高。
以下是发现解决问题的具体流程。
1:通过#top命令查看,我的java服务确实把CPU几乎占满了,如图
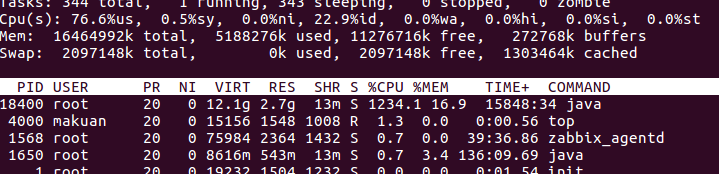
可看到18400这个进程CPU占用达到了1200%,这确实不太正常,那么我们接下来分析到底哪些线程占用了CPU
2:通过#top -Hp 18400这条命令我们可以看到这个进程中线程的情况,部分截图如下。
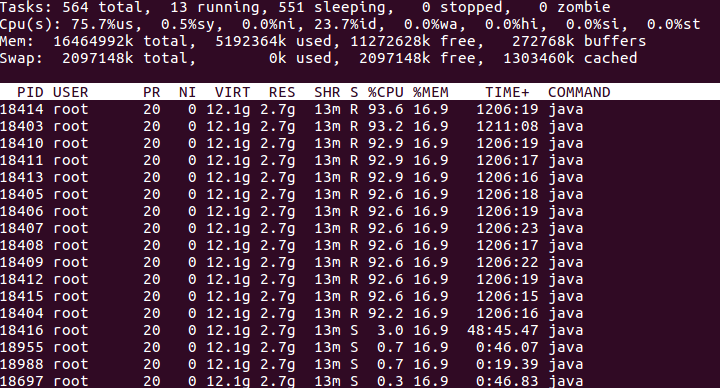
通过截图可以看到,前面的线程占用的CPU是比较高的,那我们就具体分析这些线程
3:我们通过#jstack 18400>18400.txt命令将这个java进程的线程栈给抓出来,可以多抓几次做个对比。
我们以18414这个线程为例,将它转成16进制,linux可以用终端通过命令#printf "%x" 18414将线程id转为16进制为47ee,那么我们接下来在文件里找47ee这个线程在干什么,部分截图如下
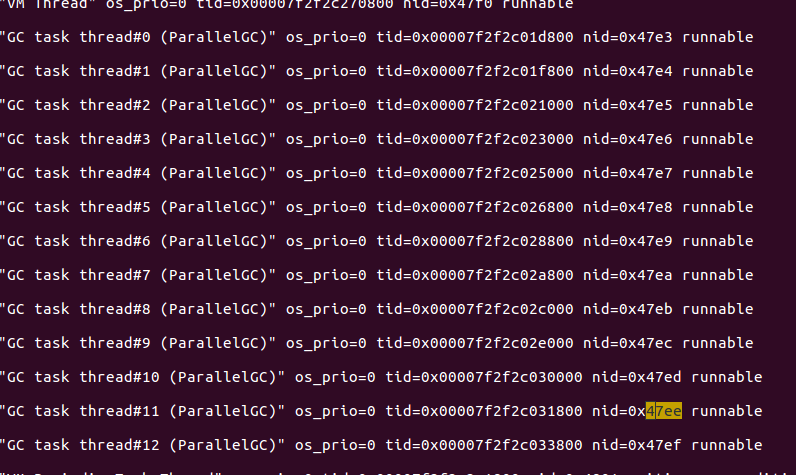
我们可以看到47ee是个垃圾回收线程;我们对其他占用CPU高的线程做相同的操作,发现都是GC线程。说明这个java服务一直在GC,这很不正常。那么我们接下来分析GC情况。
4:我们通过命令#jstat -gcutil 18400 1000 100来查看接下来的GC情况,部分截图如下
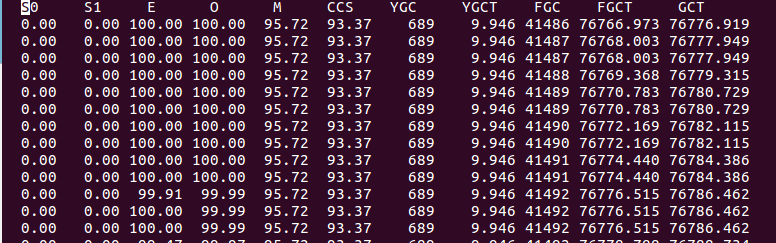
是不是很直观,通过YGC这一列发现younggc次数没有增加,但是通过FGC这一列看到fullgc的次数一直在增加,可怕的是老年代并没有回收(通过O这列看出来)。
这时候你是不是想起来了一个名词:内存泄露。没错,接下来我们就需要分析哪里出现了内存泄露。
5:我们可以通过#jmap -dump:live,format=b,file=18400.dump 18400将这个进程当前的堆给dump下来。注意,这个文件可以看成是堆的快照,所以当前堆有多大,dump下来差不多也有多大。我dump下来的差不多2G。
有了这个文件,我们需要分析,你可以用命令jhat分析,当然我们常用的是功能比较强大的图形化工具,如JDK自带的visualvm,也可以用第三方的JProfiler(我用的是这个),如果你用Eclipse,也可以安装MAT插件。这些工具都能分析堆dump文件。
需要注意的是,由于dump文件可能比较大,所以所需分析工具的内存也比较大,最好在性能比较好的机器上进行分析。
下面是我的JProfiler分析的部分截图
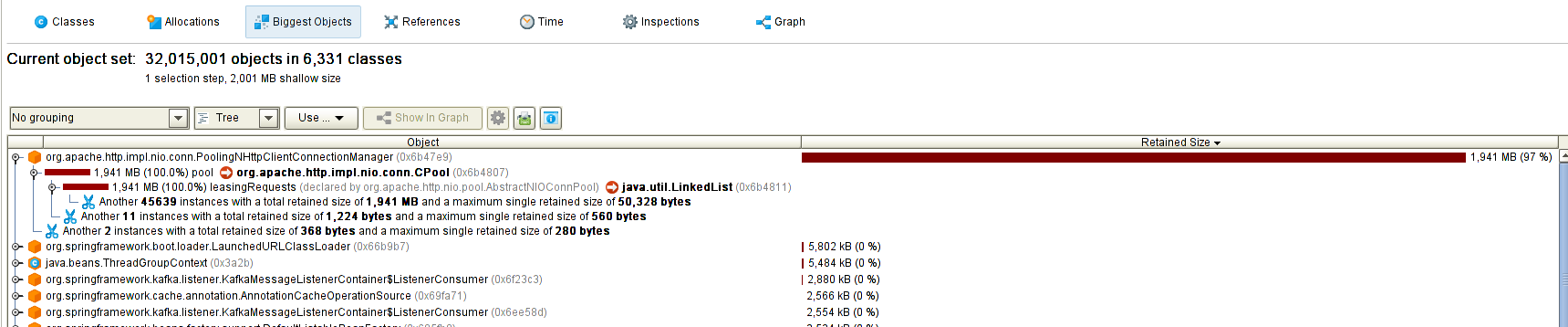
是不是很直观,有个对象占了97%的内存。那么接下来需要分析这个对象在哪产生,在哪被引用。我这里很明显是这个LinkedList占用了全部空间,那么就去分析这个LinkedList里面都存了些什么,这些有可能需要结合你的代码,我就不细说了。
我分析出来的是ElasticSearch的客户端工具JestClient的异步请求队列太长了,整个List里面的节点都是异步请求信息,大概生成了10多万个。消费不及时又无法被回收,所以产生了内存泄露。(注意,使用线程池也有可能会出现这个情况)
6:分析出了原因,那么接下来就解决问题。因为我当时急着上线,不知道JestClient的异步队列长度怎么配,就暂时把异步改成了同步,暂时解决了这个问题。上线后查看CPU,垃圾回收等情况确实恢复了正常。
总的来说,上面的6步是一个完整的分析解决jvm虚拟机内存泄露的流程,当然可能有不完善的地方,但大体思路是没错的。
通过这篇文章,我们可以总结出以下几点:
1:如何分析Java服务占用CPU过高的问题
2:使用Java各种队列的时候一定要关注队列的长度,预防内存泄露。
3:最好熟悉一下jvm的内存模型