注意:本文档中有部分公司产品的介绍和内容,禁止转载。
性能测试工作小结
许多同事对性能测试有着很大的兴趣,对该工作有着很大的热情。但是有时候苦于没有实践的机会或者测试的方法而无从下手,在这里我根据自己的一些测试经验,和大家共享一下有关性能测试的方法,希望对大家能有所帮助。
1 背景 知识
首先我们来了解下一些性能测试的基本概念和基础知识。
1.1 概念
首先我们来讨论下,什么是性能测试?在许多的资料上,都对性能测试有着狭义和广义上的定义。
狭义:模拟生产场景、业务压力或者用户的实际使用场景,测试系统的性能是否能够满足生产性能需要。
广义:则是压力测试、负载测试、并发测试、配置测试等一系列相关测试的统称。
压力测试:
通常我们是指对系统分阶段的不断增加压力,监控系统达到一个性能瓶颈或者低于性能指标。该测试用于获得系统最大的服务能力。
负载测试:
对系统不断增加压力,直到系统的一些性能指标达到极限或者出现性能拐点。该测试类型与压力测试相类似,个人认为是测试的重点不同。压力测试强调系统能承受多大的压力,而负载测试更强调服务的持续能力。
并发测试:
该测试是指测试多个用户,在同一时间段同时访问系统中的某一模块或者业务服务,来测试系统是否存在性能瓶颈。
配置测试:
该测试主要侧重硬件以及软件的配置测试,如硬件配置,中间件的参数配置,数据库的参数配置等等,通过测试达到资源的最优化。
可靠性测试:
该测试给予系统一定的业务负载、并发压力,长时间运行,以检测系统是否稳定。
大数据量测试:
在系统存在大数据量情况下进行并发或者压力测试,查看系统在大数据下的性能表现,或者短时间内处理大数据量的性能表现。
笔者以为,概念和定义都是死的,对于性能测试的理解每个人都可以有自己不同的看法,关键还是如何根据测试需求制定合理的测试策略。
1.2 测试术语
并发:
该测试术语一直以来都存在的争议。很多资料上也把他从广义和狭义上进行区分。
广义:多个用户对系统同时进行访问,但是请求的服务和业务可以是相同的也可以是不同。
狭义:多个用户对系统中的某一个服务或模块同时进行访问或者操作。
个人认为广义上的并发更接近用户的实际情况,但是我们在测试时更倾向于狭义上的并发测试。毕竟测试的目的是用来检验系统的并发处理的能力和性能表现。广义上的并发,我们可以认为是同时在线并使用系统的用户场景。
吞吐量:
指系统在单位时间内处理的业务数。
请求响应时间:
指客户端发出的请求到得到所有响应的时间,包括request时间,网络传输时间,服务器响应时间(中间件+数据库),客户端下载时间。
事务请求响应时间:
完成某个事务所用时间,通常由测试人员或者用户定义的某一个操作或者流程,用于在宏观上能对系统的一些典型业务的处理时间有直观的认识。
资源利用率:
对不同资源的使用的程度,如硬件的CPU,I/O使用,软件的资源占用等等。
有关性能测试的一些基本概念,初步介绍到这里,接下给大家简单介绍下如何进行一次完整的性能测试。
2 性能测试流程
通常情况下,一次完整的性能测试过程主要有以下几个步骤组成:
- 性能测试需求分析与整理
- 编写测试用例,设计测试场景
- 制定、确认测试计划
- 测试脚本、测试环境准备(软硬件,测试数据)
- 测试执行与性能监控
- 性能调优
- step5-step6 通常会有数次的迭代操作
- 测试报告编写
接下来将向大家简单介绍下本人对整个测试流程的理解和认识,部分内容将结合具体的例子进行分析。本文所有内容为个人理解,仅供参考。
3 需求分析
3.1工作准备
在我们接到一个测试任务或者系统时,通常测试要求都是模糊的、不明确的。当我们在进行需求分析时,需要思考以下几个问题:
- 我们测试的系统是一个什么样的架构?包括使用环境、中间件、网络、数据库等等。
- 测试系统的设计文档、开发计划、功能测试计划、需求文档等等存放位置、详细内容是什么?
- 用户、潜在用户关注的典型业务是那些?
- 系统的核心模块是那些?
- 系统中那些模块存在大数据量、多用户的并发操作?
- 哪些模块可能存在性能瓶颈?
- 历史版本或者上一版本中已知的性能问题有哪些?
- 测试需求由谁进行评审?
- 性能指标如何确认?
- 有哪些指标需要确认?
- 性能指标是否合理?
通过思考这些问题,我们可以对系统有进一步的了解,梳理出可能需要关注的测试功能点,得到相关的性能测试指标,为后续的用例设计和计划做好准备。三军未动粮草先行,做好需求分析时整个测试过程中较为关键的一步。
整个分析阶段的核心工作主要是以下几点:
- 确认系统的整体架构
- 系统的核心测试模块分析确认
- 事务、业务性能指标确认
- 需求评审、确认
3.2示例说明
我结合具体的示例来看下需求分析的工作该如何做,这里有刚做完的一个公司内部系统Ehealth Platfrom的性能测试工作。首先接到这个测试任务时,需要向项目经理(PM)或者开发人员需求项目、产品的需求文档以及产品设计文档。需求文档中,我们主要关注产品在什么的网络环境下运行,客户端配置是什么、运行环境是什么。还可以初步的判断需求中有没有对性能有测试要求。
3.2.1确认项目框架
例如Ehealth需求文档中对产品的整体框架有详细的定义。

Figure-1. EHealth Platform Architecture
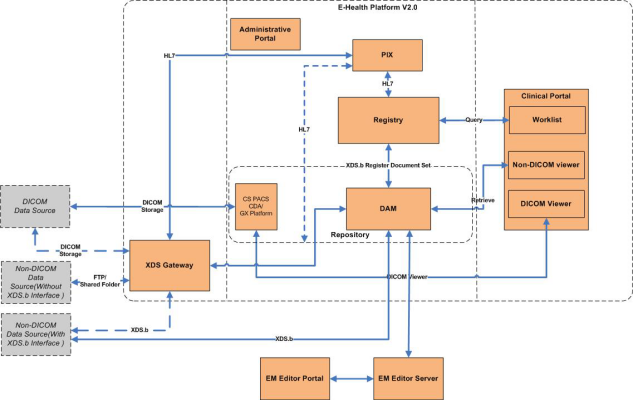
Figure-2. EHealth Platform V2.0 Components
通过对需求文档的梳理我们可以基本可以得到以下的基本信息:
产品由四个主要产品组成 XDS GateWay、DAM、Registry、Portal组成。
3.2.2确认用户基本流程
用户的基本流程如下:
1.第三方的病人信息、报告、影像资料通过XDS GateWay进行收集,并将所有信息转完成符合XDS协议标准的数据格式类型。
2. XDS GateWay 将符合标准的数据发送到Registry,请求向Registry注册病人的病人信息。
3. Registry注册成功后,XDS Gatway会将附件内容发送到DAM服务器的共享目录。
3. DAM会读取共享目录中的文件,发送请求向Registry注册病人的报告、图像信息信息。
4. Registry 根据规则关联病人信息和报告信息。
5. DAM在病人报告注册完成后,将病人的报告和影像资料存储到本地硬盘。
6. 用户可以在clinical portal通过web浏览病人信息、影像资料、诊断报告。
3.2.2确认测试对象
通过基本流程的梳理确认,我们得到一个初步的测试思路,该系统需要对数据收集存储和数据web显示这两个业务进行测试,即:
- GateWay—DAM—Registry三个服务器端的压力测试。
- 基于Web协议的并发测试。
3.2.3细化测试对象
接下里的工作则要进一步对测试对象进行细化,分析其需要测试的核心模块和可能存在的性能瓶颈:
服务器端:
XDS GateWay:作为数据的处理端,要测试其对数据的处理能力,在大数据量输入的情况下,能否正常的将数据发送到Registry、DAM服务器端。
关注点:磁盘读写、网络传送和数据库。
DAM:作为数据的收集和存储服务器,其核心模块为数据接收和数据存储。
关注点:磁盘读写和数据库。(Registry和DAM一般安装在同一硬件设备上)。
Registry:作为病人信息注册和处理中心,核心模块为病人注册和报告注册。
关注点:数据库中是否有死锁。
Web端:
Clinical Portal:作为一个web协议的网站,其核心的模块为:用户的登陆,病人查询,报告的浏览。
关注点:病人查询为模糊查询,注意数据库的响应。注意对并发的关注。
细化后的业务模块进行整理,形成初步文档,详细标明测试的功能点和可能存在的缺陷。对每个测试的功能点,要有自己对其性能指标初步认识,以便在制定测试指标时有自己的观点。
3.2.3确认测试环境
在确认性能指标前,我们还要确认系统的运行环境和软硬件的配置,通常在需求文档中都会对系统的运行环境有明确的定义,如在ehealth platfrom中对三个子系统都有明确的需求定义:
XDS GateWay:
|
Hardware Requirements |
|
|
PRS003001 |
XDS Gateway will be installed in data source site as front end data collection point, it should be installed in a PC or server, Suggested Hardware Configuration: Minimum: CPU: Intel Core Duo 2.93G, 4Gb Ram, 500G HDD Recommended: Intel Core Quad 2.93G,8Gb Ram, 500G HDD |
|
Operating Systems |
|
|
PRS003002 |
Windows 7(X32/X64) |
|
PRS003003 |
Windows 2008 Server(X32/X64) |
|
Database |
|
|
PRS003004 |
Ms SQL Server 2008(Standard or Express) |
DAM:
|
Hardware Requirements |
|
|
PRS004001 |
DAM is the core module of data canter, it is responsible for storing and managing data. Suggested Hardware Configuration: Recommended: Intel Core Quad 2.93G,8Gb RAM, 1TB HDD |
|
Operating Systems |
|
|
PRS004002 |
Windows 2008 Server(X64) |
|
Database |
|
|
PRS004003 |
Ms SQL Server 2008(Standard or Enterprise) |
系统的软硬件的配置,是衡量性能指标的一个背景,即在什么样的配置下达到一个什么的性能,这是一个前提。
3.2.4 确认测试指标
接下要做的便是确认各功能点的性能指标和硬件性能指标。硬件和软件的性能指标是比较好进行定义的,而且有一定的固定参考值,比如硬件的CPU使用率不能大于90%,内存使用不要超过80%,磁盘读写不能超过磁盘的读写能力等等。
对于核心业务和功能模块的定义,真要根据实际情况,结合产品的特点进行定义。一般这一类的性能指标由PM、开发人员和测试人员进行讨论后得出。当没有经验可遵循的时候,我一般会先对产品对一次简单的测试工作,得出一个基线的指标作为参考,或者参考类似的产品得出一个宽泛的性能指标。
例如在Ehealth Platfrom的性能测试工作中,项目组成员要求在client(GateWay,DAM和Registry)端一条病人的资料的注册和归档时间要低于1秒/每条,而对web端的事务响应时间没有具体的要求,通过讨论初步的性能指标如下:
Client端:一个标准的病人信息注册、归档时间小于1秒。
Web端: 由于没有标准的情况下,我们遵循一般web网站的测试标准即:3/6/10法则。每个时事务的响应时间应小于10秒。
资源使用:各项测试中不能出现硬件瓶颈,内存泄露,中间件不能出现性能故障。
而这些指标只是一个初步的指标,还需要进一步的定义和细化,如:
- 限定测试的硬件环境,即在什么样的硬件配置下,什么样的软件参数配置下,性能指标要达到什么样的程度。
- 限定测试的数据量,在多大的历史数据下,性能指标达到什么样的程度。
- 对于并发测试,要预先定义并发数,即在多大的并发情况下,性能指标要达到什么样的程度。
在进一步细化需求的过程中,我们可能会遇到一些困难和问题,比如:
实际测试环境与需求说明不符:
这种情况在测试中经常遇到,当测试环境配置较低时,可以适当的放宽指标。最好的策略是,以当前的硬件配置讨论,系统的性能指标。测试中通过不断的后续调优,在测试报告中限定在当前的配置情况下,性能能够达到什么样水平,类似于配置测试。
数据量定义:
我们知道,系统在不同的背景数据下,由于数据库的性能表现会直接影响程序的执行效率,所以我们在测试时需要关注系统基础数据量。在定义需求时,我们可以参考系统前一版本中的数据来考量:
在ehealth palfrom 1.0中Client日平均的事务处理量为1000条,那么一年的平均处理量在36万条左右。通过与项目相关人员的通沟,产品的预计寿命在3年左右,那么我们可以得到系统最大的数据量在100万左右,那么对于需求的定义,我们可以按照使用时间来划分:产品初期—使用一年后—使用三年后,
在5-10万历史数据下,事务平均响应时间小于1秒。
在50万历史数据下,事务平均响应时间小于1秒。
在100万历史数据下,事务平均响应时间小于1秒。
对于并发用户数的定义,我们可以根据上一版系统或者用户的实际使用情况来进行判断和定义。
比如ehealth platform 1.0 在上海仁济医院上线,实际web Portal端使用的用户数在100人左右,这100个用户实际上是系统的使用人数,并不是并发用户数,在我们进行测试可以悲观的认为这些用户,全部是并发用户来进行测试,以提高产品的测试指标。
仁济医院目前有30多个放射科,其第三方的终端设备为30台(CR、DR、Workstaion等等),按照其实际的工作量,平均每天1000条数据,按照8小时工作时间来看,其并发量为: 8*60*60/1000=28.8秒/条,如果按照设备来进行估算:平均每个病人检查时间为5分钟,则5*60/30=10秒/条。根据这两种的计算方式,我们都会发现这些并发量实际上对系统的压力都非常的小,我们预估或者按照悲观估算一个较大的压力值给系统,已达到进行压力测试和调优的目的,比如每秒发送5-10条病人信息。
对于这种并发量的计算,许多资料上都有一些所谓的公式或者方法,其中很多有关web的统计的方式比较科学化。比如按照实际网站的点击率,后台日志统计出的某一时间段的在线人数等等,大家可以灵活的采用。对于一些统计不是很方便,或者模糊的系统,可以根据实际情况进行预估。并将并发量加大一个级别,以更高的要求对系统进行调优和测试。
根据以上几步的对需求的细化和梳理,我们可以得到以下的性能测试需求:
1. 在标准的硬件、软件配置、50000历史数据的背景下,Portal web页面在100用户并发情况下,登陆、查询、打开查看报告的平均响应时间应低于10秒。
2. 在标准的硬件、软件配置、50万历史数据的背景下,Portal web页面在100用户并发情况下,登陆、查询、打开查看报告的平均响应时间应低于10秒。
3. 在标准的硬件、软件配置、100万历史数据的背景下,Portal web页面在100用户并发情况下,登陆、查询、打开查看报告的平均响应时间应低于10秒。
4. 在标准的硬件、软件配置、50000历史数据的背景下,每秒向系统发送标准大小的第三方文件(需进一步定义),病人信息注册、存储平均时间应小于1秒。
5. 在标准的硬件、软件配置、50万历史数据的背景下,每秒向系统发送标准大小的第三方文件(需进一步定义),病人信息注册、存储平均时间应小于1秒。
6. 在标准的硬件、软件配置、100万历史数据的背景下,每秒向系统发送标准大小的第三方文件(需进一步定义),病人信息注册、存储平均时间应小于1秒。
7.在测试期间不能存在软硬件瓶颈。
8.测试期间不能出现数据错误。
当初步的性能需求完成后,则要思考确立的性能指标是否合理,比如有关client端的指标,要求病人信息注册、存储的时间小于1秒。实际上系统是一个数据处理中心,数据的每一步转化和处理都有一个轮询的时间,根本不能保证一条信息的处理时间小于1秒。我们不能孤立的看一条数据的处理时间,我们应该这样思考,在一定时间内该系统能够处理多少条数据,这就提出了一个吞吐量的概念。我们可以优化这个性能需求和性能指标如下:
4. 在标准的硬件、软件配置、50000历史数据的背景下,每秒向系统发送标准大小的第三方文件(需进一步定义),模拟发送8小时,所有病人信息注册、存储总体平均处理时间应小于1秒。
不论是从需求文档也好,会议讨论也好,一定要有意识的去思考,需求和指标是否合理。否则会给后续的测试工作带来一些的麻烦。
需求初步确认后,可以和项目的相关人员进行会议沟通,最终确认测试需求,以便后续工作的展开。
4 测试用例、场景设计
当我们确认了测试需求后,可以进行下一步的工作:测试用例、测试场景的设计工作。这一步的工作主要确认测试用例和场景,为测试计划的制定做好准备,实际上也可以认为是测试计划的一部分。
在开始测试设计之前,我们要思考一下的一些问题:
- 系统的开发环境是什么?
- 如何设计测试用例?
- 使用何种工具进行模拟操作?
- 需要监控的资源有哪些?
- 如何设计测试场景?
- 场景是否符合用户的实际情况?
带着这些问题,我们可以简单的梳理出在设计阶段所要做的一些工作:
- 根据测试需求编写测试用例。
- 根据测试用例和测试要求制定合理的测试场景。
- 确认测试工具。
- 确认监控工具和监控指标。
在用例设计和场景设计期间主要的工作是对测试需求进一步细化,并根据测试要求和需求,设计出合理的测试场景。
4.1设计测试用例
对于性能测试用例的设计,内容上和功能测试是非常相似的,用来描述每个测试模块或者业务的详细内容。用于定义和描述测试的对象和步骤,确认测试业务和模块正确性和一致性。换而言之,测试的设计其实是对测试功能点的梳理和确认。
所要做的工作如下:
- 根据需求梳理出测试功能点
- 描述测试的目的
- 描述该功能或者业务的详细步骤
我们还是拿Ehealth Platfrom 2.0 来做示例说明,以下是对client端发送、注册、存储的测试点的用例设计。
Transactions: XDS Gateway upload data to DAM , Registry Server
This transaction is general work flow for user. We will record the time for the work flow which work as the flow:
- XDS GateWay collects the 3rd party meta data in source folder.
- The submission set info will process and store in the XDS GateWay system.
- The GateWay will registry the patient info to Registry system.
- After the patient registry successfully, the related reports, attachments will upload to DAM system.
- The DAM system will process, store the reports and attachments in database and local disk.
- DAM system will send request to Registry system to related the patient and report, attachments info. Then user can query and view the patient info and report in Portal web site.
We will record the cost time from step1 to step6 in this transaction. Collect the records and we will know the thought for the all system.
Web Portal端对测试功能点的描述示例:
Clinical Portal transactions
Transaction: User login
User open the Clinical web site page , input user name and password. Click the ‘login’ button and check on the ‘login force’ potation to login the main web page.
Record the time from user click ‘login’ button to the main page display successfully.
Check the performance of login module.
以上两个示例只是向大家介绍下用例的编写,用例的形式可以是多种多样的,根据自己的测试重点灵活使用。关键是对用例的描述和定义是准确的,合理的,符合实际的业务模型和用户实际使用习惯。
4.2设计测试场景
完成测试用例的初步设计后我们就可以开始对测试场景进行设计。场景设计的重点是将测试模块结合起来,在不同的数据量,不同的并发人数,或者压力下进行组合,来实现模拟系统真实使用情况。
场景模型构建和设计主要考虑以下几个因素
- 用户的实际使用情况
- 系统并发人数
- 系统的使用时间
- 数据量的大小
- 特殊测试需求和目的
看到这里,我们会发现我们在性能测试需求分析的时候,已经做了不少这方面的工作。这里只需要在进一步的进行细化分析,结合不同的测试模型进行设计。
我们举例说明:
在测试需求中有要求对web portal端有以下的测试需求:
1. 在标准的硬件、软件配置、50000历史数据的背景下,Portal web页面在100用户并发情况下,登陆、查询、打开查看报告的平均响应时间应低于10秒。
从这条测试需求中我们可以梳理出场景许多因素,并发人数(100人),数据量的大小(50,000历史数据),已经确认的测试对象(登陆、查询、打开)。还缺少的是一些测试策略和场景的运行时间,我们可以用户的实际使用情况去分析,一般医院的门诊工作时间为8小时,并发时间估算为1小时,用户登录时间会集中在10-30分钟内。根据这些信息,我们可以设计如下的一个测试场景:
Clinic Portal performance test scenario
Test the performance about the system.
- Create 100 virtual users for test.
- Set the think time to 5-30 seconds randomly in the end of iteration.
- Do this test one time with 50,000 records in Registry database -> Person table and 50,000 records in DAM database -> StorageSet table.
- Repeat this test with 500,000 records in Registry database -> Person table and 500,000 records in DAM database -> StorageSet table.
- Repeat this test with 1,000,000 records in Registry database -> Person table and 1,000,000 records in DAM database -> StorageSet table.
- Runtime setting:
|
Transaction |
Total Load |
Load |
Ramp up |
Duration |
Ramp down |
Response Time |
|
User login &logout |
100 virtual users |
100 |
5 virtual users per min |
1 hours |
5 virtual users per min |
|
|
Query the Patient By Name &SIN |
100 |
|
||||
|
View Patient Case |
100 |
|
该场景的设计是根据用户的实际使用情况和数据量来进行设计的,在某些时候,我们还可以根据某些特殊的测试目的来设计测试场景。
比如需求中有以下要求:
8.测试期间不能出现数据错误。
实际上需求背后的含义是,系统在长时间运行后不会出现任何数据错误和系统事故,根据这种需求我们结合用户的实际使用情况,可以设计一个稳定性的混合测试场景:
Complex Scenario
Run the performance test scenario (4.2.1.1) and clinic portal scenario (4.2.2.2) for 7 days. Monitor the performance of the server and record the result.
Client and server configuration:
- Prepare a XDS GateWay, Registry and DAM system.
- Configure XDS GateWay, Registry and DAM system option to make the work flow is correct.
- Use the test tool to send 1 data record XDS GateWay source data folder every minute.
- Monitor the XDS GateWay, Registry and DAM system machine hardware resource.
- Monitor the XDS GateWay, Registry and DAM system database resource.
- Do the test in one scenario which database data is 1,000,000 records in table ‘person’ of Registry database and 1,000,000 records in table ’StorageSet’of DAM database.
- This scenario will run for 7 days.
Portal configuration:
- Create 100 virtual users for test in database.
- Set the think time to 30-60 seconds randomly in the end of iteration.
- Set the think time of every transaction to 5 seconds.
- Do the test in the scenario which data is 1,000,000 records in table ‘person’ of Registry database and 1,000,000 records in table ’StorageSet’ of DAM database.
- Runtime setting:
|
Transaction |
Total Load |
Load |
Ramp up |
Duration |
Ramp down |
Response Time |
|
User login &logout |
100 virtual users |
100 |
5 virtual users per min |
7 days |
5 virtual users per min |
|
|
Query the Patient By Name &SIN |
100 |
|
||||
|
View Patient Case |
100 |
|
对场景的设计主要是要考虑上文中所提到设计因素,根据实际情况进行设计。其本质的原则就是真实,真实的使用习惯,使用人数,业务流程,我们要尽可能的模拟实际的使用情况,否则偏之毫厘,失之千里。
4.2确认测试工具
当我们完成测试用例和场景的设计后,我们需要思考使用什么样的测试工具比较合理。
目前市面上商业、开源的性能测试工具很多,贵死人不偿命的Loadrunner,不怎么好使的VSTS,开源的Jmeter,总有一款适合您。
在选择测试工具的时候,需要考虑以下几个因素:
- 工具的难易程度,测试人员能否熟练掌握
- 脚本的开发成本,免费或者开源
- 协议的支持力度,能否支持你的测试工作
- 工具时候提供监控工具
对于工具的选择,可以根据个人的喜好进行,前提是工具能够满足你对脚本的开发需求。主流的测试工具,主要有脚本探测生成器,场景控制台,性能监控器和报告生成器组成,大同小异,掌握其工作的原理和机制基本上对脚本的编写不会造成太大的影响。测试人员需要的是对测试对象开发环境和协议的深刻理解。
大家可以到网上收集查阅一下loadrunner和Jmeter的使用资料。掌握一个开源的和付费成熟的工具就足够了。
4.2确认监控工具和监控指标
在进行性能测试时,我们需要对测试系统软、硬件进行性能监控,以便掌握整个系统的健康状态,比如硬件的资源使用情况,中间件的资源使用情况,数据库的当前状态等等。
在进行监控之前,我们首先要考虑以下的问题:
- 有哪些设备需要监控?
- 有哪些指标需要监控?
- 使用什么工具进行监控?
对于监控对象的确认比较简单,服务器的硬件、网络、中间件、数据库都是通常意义上要监控的重要对象。
对于工具的选择,很多工具都可以对这些监控对象进行监控,包括一些测试工具也提供了部分的功能。
比如loadrunner就可以对计算机硬件,网络,主流的中间件和数据库进行监控。如果测试工具是开源或者没有监控工具,我们也可以使用一些其他的工具进行监控。
服务器硬件:每个操作系统都提供对硬件的监控工具。比如windows里面的性能监控器,UNIX环境下的top、topas、vmsats、iostats等命令。实际上一些测试工具也是通过RPC服务调用这些组件或者命令,用于生成性能监测信息。开发水平高的同事,也可以进行开发一个简单的监控工具。
网络:监测网络的工具非常多。链接为目前用的比较多的免费的网络检测工具,希望能对大家有所帮助。http://www.chinaz.com/free/2011/1128/223040.shtml
中间件:对于中间件的监控,一般主流的中间件都会有自己的监控工具,比如websphere、weblogic都有自身的监控工具,直观有效,我们可以灵活使用。
数据库:商业数据库一般都有专门的监控工具,比如MS SQL—sqlprofiler,Oracle—statspack、Top SQL,MySQL—phpMyAdmin,mycat等等。http://hi.baidu.com/higkoo/item/f0603e27528b3144469962da
最为复杂的是对监控指标的确认,每个监控对象的指标都很多,如何正确的选择是一些十分有挑战的工作,需要具有一些背景知识和经验。这些指标的定义需要和项目团队进行良好的沟通来确认。
对于服务器的硬件检测,主要考虑的是服务器的CPU、硬盘、缓存、page、线程、内存等等。
网络的监控主要去考虑当前的流量,发送和接受的数据大小等等。
中间件则主要考虑当前线程数、JVM池、内存的使用、连接池、http request等等,需要根据测试系统的不同灵活定义。
数据库的监控指标非常多,通常要监控死锁、栅、当前用户连接数、内存使用、缓存命中数等等。
有些测试人员当拿到工具进行监控时,看到满屏幕的测试指标时,无从下手。除了在平时要积累写这方面的知识,我们也可以在测试时征求开发团队的一些建议。
5 制定测试计划
测试计划的编写是对测试需求、测试用例场景、测试工具、人力资源分配、时间安排等测试因素的进一步的确认。因为在前几步的工作中,我们已经明确了需求,用例,场景,工具,实际上我们在计划中更注重测试环境、人员分配、风险方面的工作。在开始制定计划时,我们要思考一下的问题:
- 现有的软硬件资源是否能够满足测试需要?
- 现有的人力资源是否能够满足测试需要?
- 测试的准入和退出基线是什么?
- 调优、辅助的开发人员有哪些?
- 测试过程中可能存在的风险有哪些?
- 测试的交付物有哪些?
在制定计划时,我们需要明确的内容也和这些问题息息相关。一般情况下要明确以下内容:
- 确认测试目的、测试背景
- 确认测试环境(软硬件、网络、中间件硬件信息和软件参数配置)
- 确认测试工具
- 确认测试用例
- 确认测试场景
- 确认人员职责
- 确认测试准入、准出条件
- 确认测试的交付物
- 确认时间安排
- 定义测试风险
在计划阶段,我们根据已有的一些资源,构建整个测试的流程和测试规则,合理安排时间和人员分配,规避风险和确认交付物。
确认测试目的、背景
在测试计划中,要首先明确本次测试的目的。测试目的是开展测试工作的根本需求,在计划中明确测试目的,可以明确后续工作的开展,比如用例的设计和场景的设计,同时也可以对测试工作进行明确,提高测试工作的准确性和一致性。
确认测试环境
在计划中明确测试的测试环境,在许多的测试工作中,测试环境的硬件和实际需求中的配置有所出入。所以我们要在计划中明确实际测试环境中的配置信息,计划中要标明所有硬件的配置(CPU、内存、硬盘、存储结构、网卡)、网络环境,所有硬件信息力求详细、具体、准确,网络拓扑结构图要清晰准确。对于软件方面的配置,则要对其关键参数进行说明,比如数据库中连接数的大小、内存大小、JAVA池的大小、连接池的大小、DBF文件的大小等等。
确认测试工具
在计划中,要明确测试工具。针对需求分析中提及的测试工具、脚本进行明确和定义,明确工具版本和用途。
测试用例
测试计划中,要对测试用例进行详细描述和定义,规定测试过程中测试的核心业务和测试对象。这些用例通常在测试需求分析中,进行过初步或者详细的描述,这里则是进一步的细化和确认。
确认测试场景
测试计划中,对测试场景做进一步的细化和描述,以文字的形式确认测试场景的相关内容。
确认人员职责
在计划中,要明确测试相关人员的职责规范,如测试计划撰写、脚本的编写由谁负责,调优和技术支持由谁负责等等。
确认测试准入、准出条件
限定测试工作的准入、准出条件。这个部分主要限定测试开始、结束条件,如测试开始的版本、结束版本、结束标准,以及出现什么的测试故障可以暂停或者终止测试(功能有缺陷、服务不稳定等等)。
确认测试的交付物
该部分主要定义测试结束后,测试人员的交付物,通常会有测试报告、测试脚本、调优脚本、调优后的软件参数列表等等。
确认时间安排
该部分主要是对后续测试工作的时间安排进行定义。比如什么时间段构建测试环境,什么时间撰写脚本,什么时间段开始第几轮测试等等。定义这部分内容时,要注意对时间留有余量,确保测试工作在规定时间内能够完成。
定义测试风险
该部分的内容主要是对测试过程中,可能出现的风险进行定义。比如时间安排上如果出现冲突,该如何处理;人员变动时,该如何处理;测试需求变化时的处理策略等等。
好的测试计划是成功的一半,在测试计划中,我们力求对所有内容都是详细的、所有的定义都是准确的。计划是整个团队对测试工作的预先定义,让整个团队能够对所有工作能够达成共识,同时内容要清晰明确,使项目组中所有相关人员都能够理解。
测试计划编写完成后,需要进行相关的评审工作,通过邮件或者会议的形式进行讨论、修正,最终达成共识,形成最终文档。
6 设计环境和脚本
在测试计划完成后,我们的工作重点转移到测试环境的搭建和脚本开发上。
6.1搭建测试环境
在搭建测试环境的过程中,我们主要有两方面的工作:
- 安装系统的运行环境(OS、中间件、数据库等等)
- 为测试环境准备合理的背景数据
安装系统的工作一般并不复杂,一般情况下根据安装文档或者相关测试人员的帮助下都可以非常顺利的完成。这里要给大家强调的是,环境的安装不仅仅是安装相关的软件,还要对软件的一些配置进行修改。比如中间件连接数、线程数的修改,数据库中DBF文件大小的修改,内存模式的修改等等,这些常用参数可以根据经验或者要求进行初步设定,已达到环境的合理性。
测试数据准备是非常重要的一个工作。我们知道性能测试需要在一定的数据背景下进行,那么构建的历史数据是否合理则决定了测试环境的正确性和准确性。
通常情况下有以下几种构建数据的方式:
- 历史数据导入:从上版本或者用户环境中,将数据直接导入到测试环境中。其优点是数据的结构真实合理。缺点和局限是,有时候新系统的数据库结构发生变化,其次这样的数据可遇而不可求,很难在实际测试中获取。
- 编写数据库脚本创建:我们更多的是自己编写数据库脚本来实现数据建造。优点是对数据的控制更灵活,速度较快,但是要注意脚本效率的问题。同时也要关注生成的数据,是否符合实际的业务场景。
- 通过前台模拟:也可以编写一些的前台脚本或者使用一些自动化工具,进行模拟。通常在一些C/S结构的程序或者有文件上传、下载的一些系统使用该方法,即有本地文件操作的一些系统。
在Ehealth 2.0的测试工作中,数据构造时就是用了两种方式,一部分有关Web Portal的数据使用数据库脚本进行。Client和Server端的数据模拟,则使用了vb、.Net 脚本,因为系统对report文件有多次磁盘复制、删除、存储的工作。
对于数据的模拟的工作方式只是手段,关键是要把握准确、合理这一原则。
6.2测试脚本开发
对于测试脚本的开发工作,我们要思考一下几个问题:
- 使用何种工具开发?
- 系统的运行协议是什么?
- 那些参数需要进行参数化?
- 参数化的数据是否合理?
- 如何插入检查点?
- 如何验证脚本的正确性?
带着这些问题我们可以基本确认脚本开发过程中需要做好以下的工作:
- 确认开发工具
- 确认测试对象的使用协议
- 录制或者编写测试脚本
- 参数化测试脚本
- 设置检查点。
- 验证测试脚本
6.2.1 确认开发工具
对于开发工具的确认在需求和计划中都已经确认,这里需要对工具的特性有足够的认识,有初步的编写和开发思路。
6.2.2 确认测试对象的使用协议
对于测试对象的协议要有明确的认识,许多测试工具都是根据测试系统的协议进行脚本的录制工作,同时协议确认也方便自主脚本开发的相关工作。
6.2.3 录制和编写测试脚本
在脚本录制或编写,一定要严格按照测试用例进行,力求准确。同时做好事务点的定义和划分,以便增强在性能分析时可视性、直观化。同时要关注其运行效率,在大并发条件下,脚本的效率也影响这整个测试的成败。
6.2.4 参数化测试脚本
初步录制或者编写的脚本,需要对其进行必要的参数化操作,目的是模拟实际的运行操作,拓展脚本的可用性。很多工具都对参数化提供了强大的支持,如提供了各种类型的数据、各种不同的读取参数的方式等等。这里我要强调的是对参数的设置要合理,不能随心所欲的滥用。如在Ehealth Platform 2.0 中,病人查询使用的是模糊查询,那么我们该怎么设置参数哪?医生在使用时,肯定是遇到了一些比较生僻字时才会使用模糊查询,所以在参数化是就要考虑到这一点,不能所有的查询都是模糊查询。
6.2.5 设置检查点
检查点的概念通常在自动化测试中比较常见,在性能测试中我们也经常使用。用于检查测试过程中,页面扭转是否正确、系统运行是否健康。检查点设置通常设置在页面扭转、新界面打开、结果输出等等地方,比如在输入了用户密码登陆后,需要设置检查点检查页面是否正确打开,登陆是否成功等等,设置检点可以确保脚本运行的正确性。
6.2.6 脚本验证
完成的测试脚本,首先要通过验证后才能进行后续的测试工作。首先应该单独运行脚本,看是否会出现测试错误。其次在多用户并发的情况下运行脚本,检查是否有测试错误。同时在运行脚本的时候,要注意查看数据库和系统日志,查看脚本中设计的插入、删除、查询的语句是否正确执行,数据库中的数据是否正确,界面数据显示是否正确,系统后台日志是否报错等等。
数据环境和测试脚本工作完成后,我们可以进行下一步的测试工作,开始正式的测试执行工作。
7 测试执行与性能分析
测试脚本经过验证后,就可以根据计划中的场景进行组装,开始每一轮或者每个场景的测试工作,测试工作进入执行和监控阶段。根据需求设计和测试计划中的描述,搭建测试场景,设置好所要监控的各项性能计数器,开始测试。
在正式开始前,需要再次检查脚本和各个服务器的状态,最好记录软件的初始状态的参数和状态。同时对数据库进行备份,当测试出现故障时,可以及时恢复数据和测试环境。
在开始测试时,我们不能运行脚本后就一走了之,要时刻注意观察测试状态,每个时间段都要对测试状态,性能计数器进行观察分析。在测试过程中,我们会经常遇到一些测试故障,服务器运行不稳定停止服务、事务响应时间超出指标等等。这个时候我们要去进行初步的性能故障定位,许多人这个时候会去找开发人员寻求帮助。实际上我们可以在此之前,做更多的工作,首先去看各个系统的日志,数据库、中间件、测试系统的日志,成熟的产品都会提供详细的日志,许多错误和故障都会反应在日志文件中,甚至会提供简单的解决方案。其次检查网络、硬件是否正常。
不论是测试完成后还是测试进行中,我在进行性能故障定位时,一般的检查定位步骤如下:
- 网络瓶颈确认
- 数据库瓶颈(参数、SQL语句)
- 中间件瓶颈确认
- 服务器硬件瓶颈确认
- 系统应用瓶颈确认
- 服务器操作系统瓶颈确认
7.1网络瓶颈
对于网络的瓶颈的定位主要查看网络工作是否正常。简单的方式比如使用ping命令查看客户端到服务器端的延时是否正常。
其次使用网络检测工具,当前测试压力下,网卡的吞吐量是否达到峰值或者网络带宽的限定值。
通常情况下网络不会是主要的性能瓶颈。
|
Network interface (对于TCP/IP) |
Bytes received/sec |
该数据结合Bytes total/sec看 |
|
Bytes sent/sec |
该数据结合Bytes total/sec看 |
|
|
Bytes total/sec |
推荐不要超过带宽的50% |
|
|
Packets/sec |
根据实际数据量大小,无建议阈值,该数据结合Bytes total/sec看 |
7.2数据库瓶颈
在许多的测试故障中,后台数据库SQL运行效率低下是造成性能的主要瓶颈。在定位这类问题时,我们一般关注数据库的两个方面:参数设置和SQL语句。
本着从易到难的原则,我们首先去关注事务运行时执行的SQL语句,使用监控工具捕获到执行缓慢的SQL语句,查看其执行计划分析可能存在的性能瓶颈,如使用全表扫描。同时对数据库的死锁、全表扫描、缓存命中数等监控计数器的值,进行分析查看可能存在的性能瓶颈。
对于数据库参数的瓶颈定位则需要对其他的一些指标进行监控,如当前连接数、redo log requests、内存使用等等进行监控,查看其数值是否合理,是否有瓶颈存在的可能性。
对于公司内部的产品大多使用的SQL server,其自带的SQL Profiler是一款不错的工具,可以对SQL进行监控,同时对一些查询方面的瓶颈可以给出一定的优化。
http://cs-rnd.carestreamhealth.com/confluence/pages/viewpage.action?pageId=121831441
下面是一些SQL Server的一些监控计数器和建议:
1. SQL Server:Access Methods with counter : Forwarded Records/sec
Preferred value : less than 10 of 100 Batch Requests/Sec
2. SQL Server:Access Methods with counter : Full Scans/sec
Preferred value : (Index searches/sec)/(Full scans/sec) should be greater than 1000
3. SQL Server:Access Methods with counter : Index Searches/sec
Preferred value : same with point 2
4. 4. SQL Server:Access Methods with counter : Page Splits/sec
Preferred value : less than 20 of 100 Batch Requests/sec
5. SQL Server:Buffer Manager with counter : Buffer Cache Hit Ratio
Preferred value : greater than 90%
6. SQL Server:Buffer Manager with counter : Free List Stalls/sec
Preferred value : less than 2
7. SQL Server:Buffer Manager with counter : Free Pages
Preferred value : greater than 640
8. SQL Server: Buffer Manager with counter : Lazy Writes/Sec
Preferred value : less than 20
9. SQL Server: Buffer Manager with counter : Page Life Expectancy
Preferred value : greater than 600 seconds.
10. SQL Server: Buffer Manager with counter : Page Lookup/sec
Preferred value : (Page Lookup/sec)/(Batch Requests/sec) should less than 100
11. SQL Server: Buffer Manager with counter : Page Reads/sec
Preferred value : less than 90
12. SQL Server: Buffer Manager with counter : Page Writes/sec
Preferred value : same with point 11
13. SQL Server: General Statistics with counter : Logins/sec
Preferred value : less than 2
14. SQL Server: General Statistics with counter : Logouts/sec
Preferred value : less than 2
15. SQL Server: Latches with counter : Latch Waits/sec
Preferred value : (Total Latch Wait Time)/(Latch Waits/Sec) less than 10
16. SQL Server: Latches with counter : Total Latch Wait Time (ms)
Preferred value : same with point 15
17. SQL Server: Locks with counter : Lock Wait Time(ms)
Preferred value : should not exceeds 60 seconds.
18. SQL Server: Locks with counter : Lock Waits/sec
Preferred value : should be zero
以上只是一些常用的一些性能计数器,可以帮助我们定位一些基础的性能瓶颈。以下是一些经常用的一些即时的SQL 命令,希望能对大家有所帮助:
7.3中间件瓶颈确认
对于中间的监控和瓶颈定位,我们主要通监控中间件的一些性能计数器来确认,比如线程池、数据库连接池、当前线程数、最大线程数、JVM、内存使用等等,通过这些监控的数据来定位可能存在的瓶颈。不要忽略中间件系统日志和自身性能监控工具的作用,通常出现的性能故障都可以在这里找到原因和解决方案。
有时候中间件的瓶颈需要和数据库联合起来分析,比如中间件的延时等待有可能是数据库的连接数较小造成的。比如中间件连接数500,而数据库只有50,大量的访问会积压在中间件里,而实际上是数据库连接数较少的造成的。瓶颈的定位和分析需要把系统看做一个整体去分析。
以下是网络整理过来的有关IIS中间件的一些计数器的说明文件,希望能对大家有所帮助:
7.4服务器硬件瓶颈确认
针对服务器硬件的瓶颈分析确认,是去分析服务器系统资源是否充足,是否能够满足测试的需求。这部分的问题的定位,是通过对系统的各方面的性能计数器来进行的,一般在操作系统都提供了大量的监控计数器,我们只需要冲过对其进行分析,可以得到部分答案。
如监控系统的CPU资源,关注Processor % Processor Time、Server Work Queues Queue Length、System Processor Queue Length等指标,当Processor % Processor Time一直大于90% ,System Processor Queue Length大于2*CPU数目时,则可能CPU资源可能存在性能瓶颈。
通过对这些计数器的学习,可以很好的定位到一些服务器硬件出现的一些性能故障。但是要注意这些计数器不能孤立的去看,CPU使用率高,也有可能是其他硬件低效率造成的。磁盘读写过高,也有可能是内存不足,系统不断使用缓存造成的,需要全面分析这些计数器。以下我整理的部分内容希望对大家有所帮助:
7.4系统应用瓶颈确认
通常我们去定位应用服务的瓶颈,主要是从测试对象的内部去发现错误,比如BS结构的中页面元素的下载、CS系统中的内存泄露等等。这些问题的定位通常会结合服务器硬件的一些表现来进行分析、定位。通过这些系统的一些系统日志也能够得到一些可能存在瓶颈的原因。
我们使用一些页面分析工具可以跟踪定位web页面中各元素的信息,如某个图片的大小、JS的运行时间等等。通过这对这些元素的分析,可能定位一些应用级的问题。这类工具包括loadrunner的页面分析器、httpwatch等等。
对于一些CS结构的应用系统,我们结合计算机硬件性能计数器,可以定位服务对服务器哪方面的压力较大,CPU?内存?硬盘?。然后逆向定位到系统的那些操作、模块可能存在问题。
7.5服务器操作系统瓶颈确认
有时候有些瓶颈会存在与服务器操作系统层面,但是这种可能性比较小。通常这种瓶颈会出现在一些UNIX系统中,AIX、HP-unix等等。此类的一些OS,可以根据需要对系统文件进行调整,通常这些系统在交付前会有系统管理员进行配置,一般出现的概率不大,但是作为测试人员我们要有一定的相关知识作为储备。
有关UNIX命令的基础知识和使用,参见文档:
http://cs-rnd.carestreamhealth.com/confluence/pages/viewpage.action?pageId=109840406
有关心性能定位的流程和方法,每个人都有自己的一些看法和理解,这里给大家一张示例图,希望能对大家有所帮助。在遇到问题时能够有思路怎样去定位问题:

故障的定位需要测试人员抽丝剥茧一点点的去分析问题,找出问题的最终本源。
8 性能调优
有关如何开展性能优化的工作,一直以来是大家所关注的话题。这方面需要很多的专业知识和经验。根据个人的一些工作经历,我个人认为在条有的过程中最关键的要素试一下几点:
- 问题的定位和调整
- 性能调整的代价
- 迭代优化与验证
- 性能调整的平衡性
8.1问题的定位和调整
调优的基础是对问题的精确定位,借助一些监控工具和系统日志,分析性能的瓶颈在哪里,根据具体的问题进行分层次的调优工作,有关问题定位在上一章节已经有所提及。但是一定注意,在定位问题和调优时不要孤立,要从全局方面去思考。内存出现问题,并不意味着内存不足,而要去思考为什么内存消耗的这么快,什么模块对内存影响最大,是否是参数设置不合理。
比如在测试ehealth platform 2.0时,我们就发现系统运行一段时间后,内存被耗尽,表象上看可能是存在内存泄露,实际上是数据库的内存参数设置为MAX系统内存,设置不合理。将其内存最大最小都设置为物理内存的60%后,该问题解决。
在定位问题时,要用中医的诊断方式,望闻问切,看表现,溯根源。同样在调优的时候也是一样,不能像西医一样哪里痛医哪里,哪里坏了就割哪里。
这里有些基本的调优思路共享给大家:
8.1.1数据库优化
在许多的系统中,优化数据库一般是最方便、最直接的方式,也是首选的优化步骤。但是并不是所有的问题都是数据库的原因,有时候不合理的调整,反倒会引起系统性能下降,因此在对数据库进行优化时,最好能征求数据库管理员或者程序开发者的意见。
- 建立正确的主键,外键,以及索引机制
- 分离原则:最好能够读写分离,业务数据分离
- 分库
- 分区
- 分表
- 分列(将大字段,不常用的隔离到他表,按需查询)
- 选择隔离级别:某些对数据一致性要求不高的,可以牺牲部分一致性,降低加锁阻塞
- 保证事务简短以及减少不必要的锁机制。
- 查询优化规则:
- 避免表内的进行相关子查询。
- 避免排序或尽可能减少的行排序。
- 做大数据量排序时,相关数据可以放到临时表中。
- 尽量在where后多传查询条件,以减少不必要返回的行。
- 使用绑定变量,减少解析次数。
- 尽量select只需要的字段,以减少不必要返回的列。
- 使用分页存储,大列表的查询也可以利用分页存储过程达到优化效果。
- 利用数据库缓存,视图,临时表等最大程度优化系统,并对存储过程和函数进行必要的优化。
- 如有需要,可以冗余表中字段,避免联合查询。
- 如有需要,也可以将表内的大字段分离到单独表中,使其单独查询。
- 必做多表关联时,尽量过滤不符条件表中数据,减少计算量。
- 复杂表实时性要求不高时,尽量后台任务计算,避免动态查询。
8.1.2应用层面优化
应用层方面的优化测试于系统或者客户端的一些特性,一般倾向于应用逻辑、算法或者代码。相关的一些调整可以和代码开发人员进行沟通。
- 优化算法,选择合适高效的算法,降低不必要的递归,循环、多层循环嵌套等计算。
- 避免申请过多的不必要的内存开销。
- 降低避免内存泄露的情况。
- 使用频率较低的大文件,大对象,大数组等使用完毕后,及时释放。
- 使用频率较高的大文件,大对象,大数组尽量缓存。
- 考虑多线程技术。
- 选择适当的通信方式,注意连接的时间间隔。
- 降低应用之间通信次数,例用户认证服务,工作流服务,数据库服务。
- 降低应用之间传输数据量。
- 合理使用缓存机制:缓存常用的、不易变化的。偶有变化的资源,可以考虑缓存依赖机制。
- 支持异步计算,降低或者增加等待时间。
- 考虑延迟加载,或者提前加载两种方式。
- 分离原则:分离业务模块,如分离大I/O模块、分离高耗内存模块,分离高耗宽带模块。
8.1.3 Web方面的一些简单优化
- 减少http请求。
- 避免404错误。
- 在html页面header加入缓存标签。
- Gzip压缩网页。
- 减少cookie体积。
- 使用外部的js和css。
- 消减js和css。
- 压缩js。
- 使用css sprites技术,众多图片合成在一起,通过CSS切分,降低图片传输的频率和数据量。
- 可以使用静态网页的,避免使用动态网页。
8.1.4其他方面的优化
- 硬件方面使用高性能的小型机、存储设备。
- 使用内部网或者高速网络带宽。
- 物理分离Web Server和DB Server或者其他服务如:用户认证服务。
- 使用缓存。
- 数据缓存机制
- 页面缓存机制
- 物理分离业务模块,单业务单独部署一台服务器。
- 部署多台Web Server,建立集群服务器。
- 使用负载均衡机制。
- 数据读写分离。
- 使用消息队列 进行各种应用间进行同步/异步计算。
- 应用间选择合适的通信方式,通信协议。
- Web分布式,应用分布式,数据分布式。
- 分布式的节点使用高性能服务器,小型机群,辅以高速网络带宽等。
8.1.5 一些工具介绍
- 任务管理器,CPU,内存,I/O。
- 日志:IIS日志,Windows日志,系统本身日志。
- Sql Profiler跟踪SQL耗时情况,针对查询进行优化。
- HttpWatch跟踪请求耗时,以及发送和收到数据量。
- Performance Count,使用计数器,统计相关性能指标。
- CLRProfiler内存泄露检测工具。
- LoadRunner,压力测试,发现性能瓶颈。
8.2性能调整的代价
在我们进行性能调整或者优化的时候,我们在潜意识里面一定要有一个概念:调整是有代价的!
对应用服务、数据库、应用程序的调整,都会带来一定的资源消耗或者压力的转移,要考虑到这一点。比如数据库参数调整、中间件连接数的改变、应用程序工作方式的改变等等。
举例来说明,在ehealth platform 2.0 的测试过程中,Portal web主要用于病人信息的查询,其中查询的事务响应时间很高,基本保持在10秒以上。通过SQL profiler对问题的定位和跟踪,发现需要增加一些索引。当我们添加索引的时候,一定要想到索引的增加,会影响数据插入和修改的性能,在验证的过程中发现cient-server端,病人的信息注册、登记、存储的时间从0.4秒增大到0.9秒。
所以说优化是有成本的,比如增加的硬件设备、延长的开发周期等等,我们要充分考虑到这些问题,合理的进行调整。
8.3迭代优化与验证
当我们定位好问题,调整好参数后,我们需要对优化的成果进行验证。任意参数的更改都会带来预期或者不可预期的结果,所以需要我们进行一次验证,一方面考察更改的实际效果,另一方面检查是否带不可接受的性能变化。
所以就要求我们在进行调整时,要循序渐进,对调整的参数或者方案,以小粒度的方式逐步调整。每一次的调整和优化都必须进行验证。因此,调整和优化是一个迭代的过程,以便避免蝴蝶效应带来的不可估量的后果。
8.4性能调整的平衡性
通过迭代式性能调整,我们会得到一次又一次的性能增强或者下降。那么究竟调整到什么样的状态才是最终的结果哪?
一般来讲,当我们调整到符合测试需求或者达到性能指标时,优化工作可以基本告一段落。优化的工作的初期目标是解决测试故障或者说排除测试瓶颈,其最终的目标和追求是系统健康的运行,系统各个资源使用、开销、调用达到一个平衡。我们在调优的过程中,实际上就是在平衡分配各个组件和资源。
比如在测试一个系统时,我们发现数据库的资源非常空闲,压力不大,那么我们可以适当的增大中间件的连接数,同时增大数据库的连接数或者增大内存的使用率,提高系统的资源利用率。
而遇到一些有的资源紧张而一些资源比较空闲时,我们也可以根据实际情况进行调整。比如中间件资源比较紧张,数据库比较空闲,我们可以适当减少中间件的连接数,而增大数据库的连接池或者加大数据库工作压力等方式。
举例:在ehealth platform 2.0中,我们队client-server进行测试时,发现这个流程处理时间比较慢,没有达到预期目标,其主要原因是XDSGateWay 向DAM 上传文件的效率不高,其要等待registry服务返回病人注册成功后才会激发上传的动作,DAM一直在等待文件上传,造成效率低下。那么我们可以调整应用程序,将病人的注册行为改成多线程。但是更改后的结果是,病人注册的效率调高了,但是大量的数据上传后,DAM来不及进行处理和存储,大量的数据积压在DAM端,造成DAM性能低下,整体性能下降。平衡点从registry倒向了DAM,解决的方式两种,让DAM也实现多线程读取本地文件或者降低registry线程数,通过几轮的调整,最终系统达到较为平衡的状态:每次1000个病人去注册,注册完毕后开32个线程去上传病例,全部上传完毕后再进行下一轮的上传操作。
从全局层面考虑,优化的目的是,在满足测试需求的情况下,让所有资源的利用率达到最大。我们把客户端、中间件、数据库比作三个水管,每个水管的尺寸都不一样,怎么更改这三个部件中水的流速和水管的尺寸,达到最终出水口的流量最大化才是我们优化的最终目标。
有关优化的内容简单介绍这里,希望对大家有所帮助。能力有限,不足之处也请大家指正。
9 测试报告编写和测试总结
当我们完成所有的测试工作后,我们需要对整个测试进行总结,提供测试报告。因为在需求和计划中我们对一些背景和场景指标都有所描述,对于报告的编写,我们主要做好以下的工作:
- 阐明测试的结果
- 对于测试中故障的定位和分析
- 性能调优的建议
- 产品配置清单
- 其他计划中规定的交付物
9.1阐明测试的结果
在撰写测试报告时,我们首先要对测试的结果进行阐明,对每个场景下的运行完的结果进行说明。比如A场景下,每个事务的平均响应时间、事务响应时间方差、成功、失败的事务数,期望性能指标、是否通过测试等等。可以利用表格形式进行记录,清晰明了,并且可以对比多次或者多个版本的运行结果。
在结果的阐明中,要明确给出测试成功或者失败的结论,不能模棱两可。如果测试失败,则要说明测试失败的原因,如:指标不达标、服务停止等等,还要给与下一步的工作计划,比如:继续优化或者停止测试等等。
9.2 故障定位和分析
在测试报告中,如何体现对问题的定位与分析?问题的定位与分析,是一个思考、研究和举证的过程。在报告中要举出日志、图片、分析报表等说明故障、瓶颈出现的原因。论证的过程要简单明了,对于可能出现的出现技术术语,要给与足够的说明,力求让团队中的非技术人员也能有一定的理解和认识。
在这一部分内容中,可以给予一些初步的调整思路、计划或者将该优化工作分配给适当的人员处理。
9.3性能调优的建议
瓶颈分析完毕后,我们可以根据自身的能力或者要求,给出一定的调优建议。比如一些数据库、中间件的参数的修改、应用程序的修改思路等等。
这些建议不一定成熟,但是可以在后续的会议中进行讨论,征询开发团队、DBA、系统管理员的相关意见,尝试调优和验证工作。
这方面我个人的建议,测试人员可以大胆的提出自己的一些意见和思路,同时也可以事先进行验证工作,这样会更具有说服力。
9.4产品配置清单
在进行不断优化的过程中,系统、硬件、软件的一些配置会发生改变,在报告中要及时更新配置清单和参数列表,这些配置可以包括硬件配置的变化、测试对象运行模式的变化、代码的部分更改、补丁、数据库DBF文件增长的大小、软件参数的变化。记录这些资料,可以使测试人员和团队,清晰的了解当前的测试对象的工作状态和状态变化。
9.5其他计划中规定的交付物
另外在计划中提及的一些其他的交付物也需要上传或者记录到报告中。比如测试脚本、脚本参数列表、建造数据的SQL脚本、自动化脚本等等。
10 后记
性能测试并不是一件非常有难度的工作,要求较高的是需要有比较广的知识面,代码层、中间件、数据库等等都有所涉及。但是不需要过多的担心,只要掌握性能测试工作基本流程,按部就班、抽丝剥茧,遇到问题时有足够的耐心,都能够胜任相关的工作。
以上只是简单的和大家介绍了以下有关性能测试的一点基本知识,希望能够给大家一点启示和帮助。
注意:本文档中有部分公司产品的介绍和内容,禁止转载。
Ralf Wang
2012-11-30