KMP算法是字符串匹配功能的一个优化。
所谓字符串匹配的问题意思是说,给一个字符串和一个匹配串,判断这个匹配串是否被这个字符串包含。或者说求匹配字符串在给的字符串中出现的位置。
在C语言中,strstr函数就是这个字符串功能的实现,既然你看到了这篇博客,我就默认你已经了解strstr函数。
举个例子:
给一个字符串 string:abcabcabcabcacabxy 求字符串pattern:abcabcacab在string中字符串的位置。
如果按照暴力算法,就是一个一比对过去:
暴力破解的思路就是字符串和匹配串一路比过去,若相等,就一起往后移一位,但是如果不相等,匹配串就要回到起点,字符串回到开始匹配位置的下一个字符串。
/* match.cpp */ #include<cstdio> #include<cstring> int main() { char *string = "abcabcabcabcacabxy"; char *pattern = "abcabcacab"; int len_string = strlen(string); int len_pattern = strlen(pattern); int i = 0; int j = 0; int mark_i = 1; bool flag = false; while(i < len_string && j < len_pattern) { while (string[i] == pattern[j]) { i++; j++; } if (j == len_pattern) { flag = true; break; } if (i == len_string || len_string - mark_i < len_pattern) { break; } j = 0; i = mark_i; mark_i++; } if (flag == true) { printf("The [%s] is in [%s] ", pattern, string); } else { printf("The [%s] is NOT in [%s] ", pattern, string); } return 0; }
上面的代码我还加了点优化方案在里,比如说字符串剩下的长度小于匹配串的长度,那么直接退出,返回false了。
暴力破解的时间复杂度都是O(m*n),其中m是字符串的长度,n是匹配串的长度。如果m和n都不大还好,一旦两个都是1000以上了,计算时间就很长了。
其中KMP算法就是优化字符串匹配方法的其中一种优化程度较好的算法。
KMP算法是这个算法建立的三个人Knuth、Morris、Pratt的首字母缩写。
它的思路就是对匹配串进行一定的算法处理,减少重新比对的次数。
对匹配字符串的处理方法就是对它建立一个match数组,来表示以当前字符为结束的子串中是否有相同的真字符串。其中,建立的公式为:
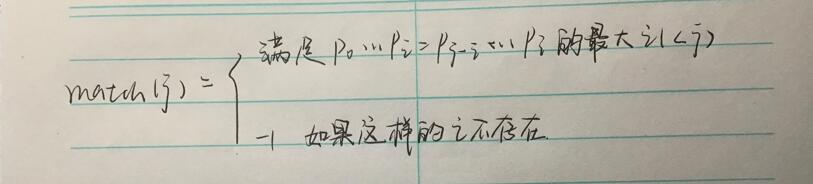
具体求KMP match数组计算过程如下:

具体的算法实现:
void BuildMatch( char *pattern, int *match ) { Position i, j; int m = strlen(pattern); match[0] = -1; for ( j=1; j<m; j++ ) { i = match[j-1]; while ( (i>=0) && (pattern[i+1]!=pattern[j]) ) i = match[i]; if ( pattern[i+1]==pattern[j] ) match[j] = i+1; else match[j] = -1; } } Position KMP( char *string, char *pattern ) { int n = strlen(string); int m = strlen(pattern); Position s, p, *match; if ( n < m ) return NotFound; match = (Position *)malloc(sizeof(Position) * m); BuildMatch(pattern, match); s = p = 0; while ( s<n && p<m ) { if ( string[s]==pattern[p] ) { s++; p++; } else if (p>0) p = match[p-1]+1; else s++; } return ( p==m )? (s-m) : NotFound; }
练习题:
https://www.cnblogs.com/wanghao-boke/p/12006005.html
参考:中国mooc网浙江大学数据结构课程视频讲义