-
first_value和last_value函数
作用:first_value和last_value取收尾记录的值
用法:FIRST_VALUE ( [scalar_expression )OVER ( [ partition_by_clause ] order_by_clause )
LAST_VALUE ( [scalar_expression )OVER ( [ partition_by_clause order_by_clause )
例子:查询部门最早发生销售记录日期和最近发生的销售记录日期


1 select 2 dept_id 3 ,sale_date 4 ,goods_type 5 ,sale_cnt 6 ,first_value(sale_date) over (partition by dept_id order by sale_date) first_value 7 ,last_value(sale_date) over (partition by dept_id order by sale_date desc) last_value 8 from criss_sales;

-
substr()函数
作用:截取字符串
格式一:substr(string string,int a,int b);
格式二:substr(string string,int a);
解释:格式一:string是需要截取的字符串,a字符串开始的位置(注:当a为0或1时都是从第一位开始截取,)b是要截取的字符串长度
格式二:string是要截取的字符串,a是从第a个字符串开始截取后面所有的字符串
例子:
1 select substr('HelloWorld',0,3) value from dual; //返回结果:Hel,截取从“H”开始3个字符 2 select substr('HelloWorld',1,3) value from dual; //返回结果:Hel,截取从“H”开始3个字符 3 select substr('HelloWorld',2,3) value from dual; //返回结果:ell,截取从“e”开始3个字符 4 select substr('HelloWorld',0,100) value from dual; //返回结果:HelloWorld,100虽然超出预处理的字符串最长度,但不会影响返回结果,系统按预处理字符串最大数量返回。 5 select substr('HelloWorld',5,3) value from dual; //返回结果:oWo 6 select substr('Hello World',5,3) value from dual; //返回结果:o W (中间的空格也算一个字符串,结果是:o空格W) 7 select substr('HelloWorld',-1,3) value from dual; //返回结果:d (从后面倒数第一位开始往后取1个字符,而不是3个。原因:下面红色 第三个注解) 8 select substr('HelloWorld',-2,3) value from dual; //返回结果:ld (从后面倒数第二位开始往后取2个字符,而不是3个。原因:下面红色 第三个注解) 9 select substr('HelloWorld',-3,3) value from dual; //返回结果:rld (从后面倒数第三位开始往后取3个字符) 10 select substr('HelloWorld',-4,3) value from dual; //返回结果:orl (从后面倒数第四位开始往后取3个字符)
-
decode()函数
使用方式:decode(条件,值1,返回值,值2,返回值2...值n,返回值n);
和if 条件 = 值1 then
return(返回值1)
else if条件 = 值2
return(返回值2)...
else
retuen 缺省值
end if 效果是一致的
例子:
select id, username, age, decode(sex,0,'男',1,'女') from users;

-
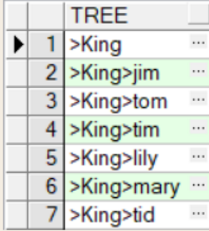
sys_connect_by_path函数
oracle函数sys_connect_by_path主要用于树查询(层级查询)以及列转行,
语法:select ... sys_connect_by_path(column_name,'connect_symbol') from table start with ... connect by ... prior
解释:start with开始的地方为根节点,将遍历数据库根据函数中的分隔符,重新组成一个新的字符串,通过connect by来寻找下一条记录,指导迭代找不到记录为止
例子:
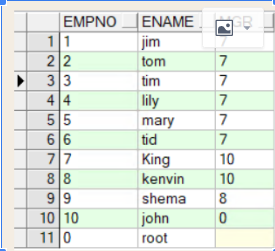
select sys_connect_by_path(ename,'>') tree from emp start with ename='King' connect by prior empno = mgr
-
instr()函数
格式一:instr(string1,string2)/instr(源字符串,目标字符串)
格式二:instr(string1,string2[,start_position[,nth_appearance]])//instr(源字符串,目标字符串,起始位置,匹配序列号)
解析:string2字符的值要在string1中查找,是从start_position给出的数值,(即位置)在开始string1检索,检索到nth_appearance(几)次出现string2
注:在oracle/plsql中,instr函数返回要截取的字符在字符串的位置。只检索一次,也就是说从字符串的开始到字符串的结束
select instr('helloworld','l') from dual; --返回结果:3 默认第一次出现“l”的位置 select instr('helloworld','lo') from dual; --返回结果:4 即:在“lo”中,“l”开始出现的位置 select instr('helloworld','wo') from dual; --返回结果:6 即“w”开始出现的位置
select instr('helloworld','l',2,2) from dual; --返回结果:4 也就是说:在"helloworld"的第2(e)号位置开始,查找第二次出现的“l”的位置 select instr('helloworld','l',3,2) from dual; --返回结果:4 也就是说:在"helloworld"的第3(l)号位置开始,查找第二次出现的“l”的位置 select instr('helloworld','l',4,2) from dual; --返回结果:9 也就是说:在"helloworld"的第4(l)号位置开始,查找第二次出现的“l”的位置 select instr('helloworld','l',-1,1) from dual; --返回结果:9 也就是说:在"helloworld"的倒数第1(d)号位置开始,往回查找第一次出现的“l”的位置 select instr('helloworld','l',-2,2) from dual; --返回结果:4 也就是说:在"helloworld"的倒数第1(d)号位置开始,往回查找第二次出现的“l”的位置 select instr('helloworld','l',2,3) from dual; --返回结果:9 也就是说:在"helloworld"的第2(e)号位置开始,查找第三次出现的“l”的位置 select instr('helloworld','l',-2,3) from dual; --返回结果:3 也就是说:在"helloworld"的倒数第2(l)号位置开始,往回查找第三次出现的“l”的位置