论文地址:https://arxiv.org/abs/1904.07601
代码:https://github.com/Yochengliu/Relation-Shape-CNN
项目主页:https://yochengliu.github.io/Relation-Shape-CNN/
作者直播:https://www.bilibili.com/video/av61824733
作者维护了一个收集一系列点云论文、代码、数据集的github仓库:https://github.com/Yochengliu/awesome-point-cloud-analysis
这篇paper是CVPR 2019 Oral & Best paper finalist
摘要
点云分析非常具有挑战性,因为很难捕获隐含在不规则点中的形状。
在本文中,提出了RS-CNN,即关系形状卷积神经网络,它将规则网格CNN扩展到不规则配置,以进行点云分析。
RS-CNN的关键是从关系中学习,即点之间的几何拓扑约束。
具体地,局部点集的卷积权重从该点集的采样点与其他点之间的预定义几何先验中学习高级关系表达式。以此方式,可以获得具有明确的关于点的空间布局的推理的归纳局部表示,这导致了很多形状感知和鲁棒性。使用这种卷积作为RS-CNN的基本运算符,可以开发出层次结构来实现上下文形状感知学习,以进行点云分析。
通过在三个任务上进行具有挑战性的基准测试的广泛实验,证明RS-CNN达到了最新水平。
一、引言
近年来,三维点云分析由于在自动驾驶和机器人操作等方面的应用越来越受到人们的关注。但是,这个任务非常具有挑战性,因为很难推断出这些不规则点所形成的基本形状(详见图1)。
对于这个问题,很多工作集中在复制卷积神经网络(CNN)对规则网格数据(如图像) 分析的显著成功 [17,32]到不规则点云处理[26,15,45,29,27,34,38]上。一些工作将点云转换为常规体素[42,22,3]或多视图图像[35,2,5]便于应用经典网格CNN。然而,这些变换通常会导致对三维点的固有几何信息造成了很大的损失云,以及高度的计算复杂性。
为了直接处理点云,PointNet[24]对每个点进行独立学习,并收集全局表示的最终特征。虽然令人印象深刻,但这个设计忽略了局部结构,而这些局部结构已被证明是图像CNN[49]提取高级视觉概念的重要因素。为了解决这个问题,一些工作通过采样[26]或超点[18]将点云划分为多个子集。然后建立层次结构来学习从局部到全局的上下文表示。然而,这非常依赖于对局部子集的有效的归纳学习,这是很难实现的。
通常,从点集 进行学习主要面临三个挑战:
(1) P是无序的,因此要求学习的表示是置换不变的;
(2) P分布在3D几何空间中,因此要求学习的表示形式对刚性变换(例如旋转和平移)具有鲁棒性;
(3) P构成一个基本形状,因此,学习到的表示应具有判别性形状意识。
问题(1)已通过对称函数得到了很好的解决,而(2)和(3)仍然要求全面探索。这项工作的目标是将常规网格CNN扩展到不规则配置,以便一起处理这些问题。
为此,我们提出了一种关系形状卷积神经网络(别名为RS-CNN)。 RS-CNN的关键是从关系中学习,即点之间的几何拓扑约束,我们认为这可以在3D点云中编码有意义的形状信息。
特别地,每个局部卷积邻域都是通过将采样点x作为质心来构造,周围的点作为其邻居N(x)。
卷积权重从预定义的几何先验中学习高级关系表达式,即x和N(x)之间的直观低级关系。通过以这种方式进行卷积,可以获得具有关于点的空间布局的明确推理的归纳表示。它可辨别地反映不规则点形成的潜在形状,因此可以识别形状。此外,它可以受益于几何先验,包括对点置换的不变性和对刚性变换(例如,平移和旋转)的鲁棒性。
通过将卷积作为基本运算符,可以开发类似于CNN的分层体系结构,即RSCNN,以实现上下文形状感知学习以进行点云分析。
主要的贡献如下:
提出了一种新的从关系中学习卷积算子,称为关系形卷积。它可以显式地编码点的几何关系,从而获得更多的形状意识和鲁棒性;=》RS-Conv
提出了一种具有关系形状卷积的深层次结构,即RS-CNN。它可以将规则的网格CNN扩展到不规则的配置,以实现点云的上下文形状感知学习;=>RS-CNN
跨三个任务在具有挑战性的基准上进行了广泛的实验,以及详尽的经验和理论分析,证明RS-CNN达到了最先进的水平。
二、相关工作
基于视图和体素的方法
基于视图的方法将3D形状表示为来自不同角度的一组2D视图。最近,许多研究[35,2,5,43,6,25]被提出用深度神经网络识别这些视图图像。他们经常微调一个预先训练过的基于图像的架构来精确识别。然而,二维投影可能会由于自遮挡而导致形状信息丢失,而且它通常需要大量的视图来获得良好的性能。
体素方法将输入的3D形状转换为常规3D网格,可以在其上使用经典的CNN [42, 22, 3]。主要限制是由于3D网格强制执行的低分辨率而导致形状的量化损失。最近的空间划分方法,例如K-d树[16]或八叉树[39, 36, 28]挽救了一些分辨率问题,但仍然依赖于边界体积的细分而不是局部几何形状。
点云上的深度学习
PointNet [24]通过在每个点上独立学习并通过最大池收集最终特征来开创了这条路线。然而,这种设计忽略了局部结构,事实证明,局部结构对于CNN的成功至关重要。为了解决这个问题,PointNet ++ [26]建议将PointNet分层应用到点云。在[4,30]中也研究了基于PointNet的局部结构开发。此外,提出了用超点[18]将点云划分为几何单元。图卷积网络应用于由邻近点创建的局部图[38,37,20]。然而,这些方法没有显式地建模点的局部空间布局,从而获得较少的形状感知。相比之下,我们的工作通过学习点之间的高级关系表达来捕捉点的空间布局。
一些论文将点云映射到高维空间,以促进经典CNN的应用。SPLA TNet [34]将输入点映射到稀疏网格上,然后使用双边卷积[14]进行处理。PCNN[1]将点云上的函数扩展为环境空间上的连续体积函数。这些方法可能会导致几何信息丢失,而我们的方法直接在点云上运行而不会引起这种丢失。
另一个关键问题是点云的不规则性。一些论文着重于分析与点集学习[24, 27, 48, 19].等价的对称函数。一些论文[24, 21]开发了对齐网络,以增强3D空间中刚性转换的鲁棒性。但是,对齐学习是此问题的次佳解决方案。一些传统的描述符(例如快速点特征直方图)对于平移和旋转可能是不变的,但是对于高层形状理解而言,它们通常效率较低。我们的方法学习了点之间的几何关系,对刚性变换是自然鲁棒的,同时由于深度网的强大而非常有效。
相关性学习
在图像和视频分析领域,从关系中学习依赖数据的权值已被探讨。Spatial transformer [13]学习一个过渡矩阵来对齐二维图像。Non-local network [40]学习跨视频帧的长期关系。Relation networks [9]学习对象之间的位置关系。
也有一些关于三维点云中的关系学习的研究。DGCNN[41]通过学习高维特征空间中的点关系来捕获相似的局部形状,但这种关系在某些情况下可能不可靠。Wang等人提出了一种基于点间可计算关系的参数连续卷积,但他们没有像经典CNN那样明确地从局部到全局学习。与此相反,我们的方法从三维空间的几何先验中学习高级的关系表达,并执行上下文的局部到全局的形状学习。
三、形状意识表示学习
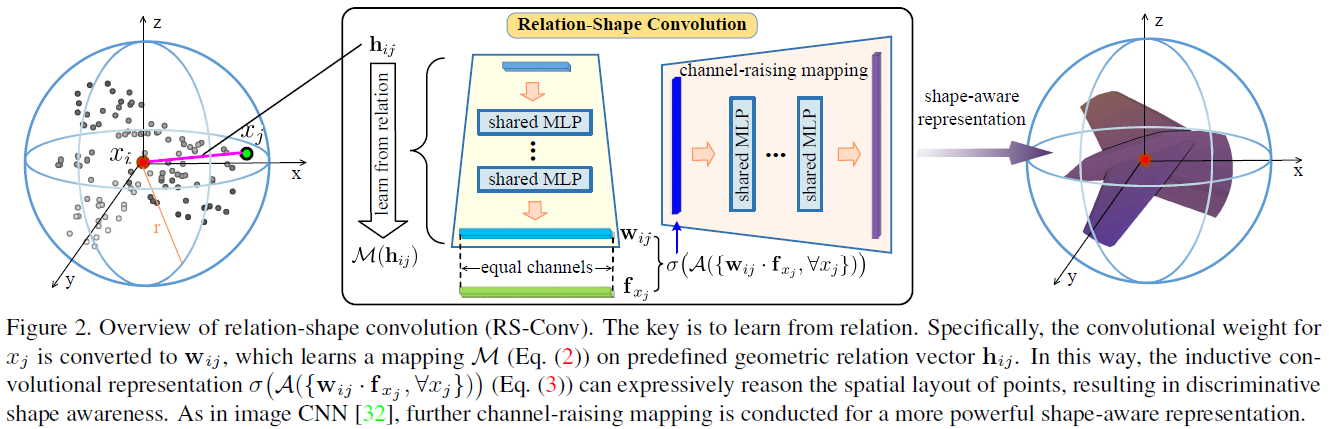
点云分析的核心是在鲁棒性的前提下区分地表示隐含的形状。在这里,我们通过一种新的关系-形状卷积(RS-Conv)将规则网格CNN扩展到不规则配置,从而学习上下文形状感知表示。
3.1关系-形状卷积
Local-to-global学习在图像CNN中取得了显著的成功[17,32],是一种很有前途的上下文形状表示方法。然而,它极度依赖于不规则点子集的形状感知的归纳学习,这仍然是一个相当棘手的问题。
建模
为了克服这个问题,这篇论文将局部点子集Psub建模为球面邻域,其中采样点xi为质心,周围的点为邻居x j∈N(xi)。图2的最左侧部分说明了此建模。目标是学习该邻域的归纳表示fPsub,其应有区别地编码基础形状信息。为此,将一般的卷积运算表述为:
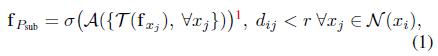
经典CNN的局限性
在经典的CNN中,τ被实现为τ ( fxj ) = w j • f xj,其中wj是可学习的权重,“•”表示逐元素相乘。
当将卷积应用于点云时,主要有两个局限性:
1)不具备置换不变性:wj在N ( x i )中的每个点上不共享,导致点置换的方差和不能处理不规则Psub的能力(例如,不同的数量);
2)没有学到形状信心:wj反向传播的梯度仅与孤立点xj有关,从而导致隐式学习策略,这不会带来太多的fPsub的形状意识和鲁棒性。
变换:从关系中学习
我们认为,上述限制可以通过从关系中学习来缓解。在三维空间的邻域中,xi与其所有邻域N(xi)之间的几何关系是关于点的空间布局的显式表达,进一步区分地反映了基本形状。为了捕捉这种关系,我们将经典CNN中的wj替换为wij, wij为学习一个关系向量hij的映射M,即预定义的xi和xj之间的几何先验。我们称hij为低级关系。这个过程可以描述为
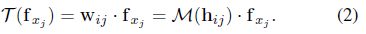
因此,Eq.(1)中的fPsub变成
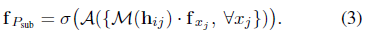
我们将在实验部分详细讨论hij。
通道提升映射
在等式(3)中,fPsub的通道号与输入特征f x j 相同。这与经典图像CNN不一致,经典CNN在增加通道数量的同时降低图像分辨率以实现更抽象的表示。例如,在VGG网络[34]中设置了通道号64-128-256-512。因此,我们在fPsub上添加了一个共享的MLP,用于进一步的信道提升映射。它显示在图2的中间部分。
补充:
RS-Conv的流程如下:
(1)首先通过FPS进行采样,得到质心Xi;
(2)在球形邻域寻找近邻Xj;
(3)对每个近邻Xj,计算Xj和Xi的low-level信息,即几何先验hij,hij的表示方法有许多,作者论文中定义hij=[3D-Ed,Xi-Xj,Xi,Xj],即两点的欧普是距离(1维)、相对坐标(3维)、Xi的坐标(3维)和Xj的坐标(3维)进行拼接,得到一个10维的low-level信息;
(4)使用MLP将hij映射到high level高维信息,即wij=M(hij),注意,wij的维度要和fxj的特征维度相同,才可以进行点乘;
(5)将得到的wij和fxj点乘;
(6)max操作,聚合所有近邻的信息作为质心Xi的新特征,接着为了实现更强大的形状感知表示,将Xi进行进一步的通道提升映射(这个模仿了CNN中卷积之后通道数不断增加),即channel-raising mapping
最远点采样FPS的步骤:
假设一共有n个点,整个点集为N = {f1, f2,…,fn}, 目标是选取n1个起始点做为下一步的中心点:
- 随机选取一个点fi为起始点,并写入起始点集 B = {fi};
- 选取剩余n-1个点计算和fi点的距离,选择最远点fj写入起始点集B={fi,fj};
- 选取剩余n-2个点计算和点集B中每个点的距离,将最短的那个距离作为该点到点集B的距离, 这样得到n-2个到点集的距离,选取最远的那个点写入起始点B = {fi, fj,fk},同时剩下n-3个点, 重复上面步骤直到选取n1个起始点为止.
以上就是RS-Conv的操作过程。有点复杂,类比成2D图像的卷积的话,一个明显的区别是RS-Conv的卷积核Wij是通过hij(即低维关系信息)学习来的,这也是本文的最大创新点,但实际上,这个操作在其他论文中也有出现,比如GACnet,DGCNN只是他们定义hij的方式不同。
3.2性质
Xi
RS-Conv中等式3可以保持四个相当好的属性:
置换不变性
在内部映射函数中M(h),即低级关系h和共享的MLP M对于点的输入顺序是不变的。因此,在外部聚集函数A对称的情况下,可以满足置换不变性。
对刚性变换鲁棒
这个属性在高级关系编码M(h)中很好地保持了。当一个合适的h(例如3D欧几里得距离)被定义时,它可以对刚性变换(例如平移和旋转)具有鲁棒性。
点相互作用
点不是孤立的,附近的点在几何空间中形成有意义的形状。因此,他们内在的相互作用对甄别形状意识是至关重要的。我们的关系学习解决方案显式地编码点之间的几何关系,自然地捕获了点之间的相互作用。
权重共享
这是关键特性,可将相同的学习功能应用于不同的不规则点子集,以实现鲁棒性和低复杂度。在式(3)中,对称的A、共享的MLP M和预定义的几何先验h都与点的不规则性无关。因此,这个属性也被满足。
3.3再讨论2D网格卷积
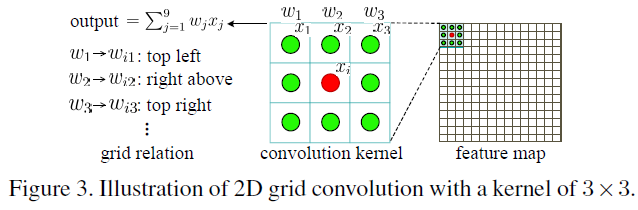
3.4用于点云分析的RS-CNN
利用RS-Conv(图2)作为基本算子,并采用统一采样策略,实现了像经典CNN一样的分层形状感知学习架构,即RS-CNN,用于点云分析,例如
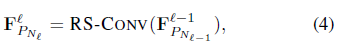
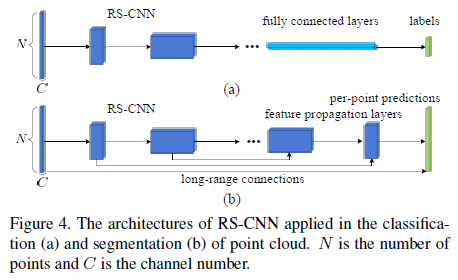
对于分割,通过特征传播[26]对学习的多级表示进行连续上采样以生成每点预测。两者都可以端到端的方式进行训练。
3.5应用细节
在Eq.(3)中的RS-Conv 使用对称函数max pooling作为聚集函数A。ReLU[23]作为非线性激活器。对于映射函数M,部署了一个三层共享的MLP,因为理论上它可以适应任意的连续映射[8]。低层关系hij被定义为一个有10个通道的紧凑向量,即(3D欧氏距离,xi−xj, xi, xj)。通道提升映射是通过单层共享的MLP实现的。批量标准化[12]应用于每个MLP。
用于点云分析的RS-CNN从点云中选取最远点,以便对局部子集进行采样去执行RS-Conv。在每个邻域中,随机抽取固定数量的邻域进行批处理。它们以质心为原点被标准化。为了捕捉更充分的几何关系,强制RSCNN在以共享权重的采样点为中心的三尺度邻域中学习。这与多尺度分组(MSG)[26]不同,后者使用多组权重来学习多尺度特征。部署3层RS-CNN和4层RS-CNN分别进行分类和分割。注意,只有3D坐标xyz被用作RS-CNN的输入特性。
我们的RS-CNN是使用Pytorch实现的。采用Adam优化算法进行训练,最小批量为32。BN的动量从0.9开始,然后每20个epochs以0.5的速率衰减。学习速率从0.001开始,然后每20个epochs以0.7的速率衰减。RS-CNN的权值使用He等[7]引入的技术进行初始化。
四、实验
在本节中,我们安排了全面的实验来验证所提出的RS-CNN。首先,我们评估RSCNN在三个任务上的点云分析(4.1节)。然后,我们提供了详细的实验来仔细研究RSCNN(4.2节)。最后,我们可视化RS-CNN捕捉的形状特征并分析了复杂性(第4.3节)。
4.1点云分析
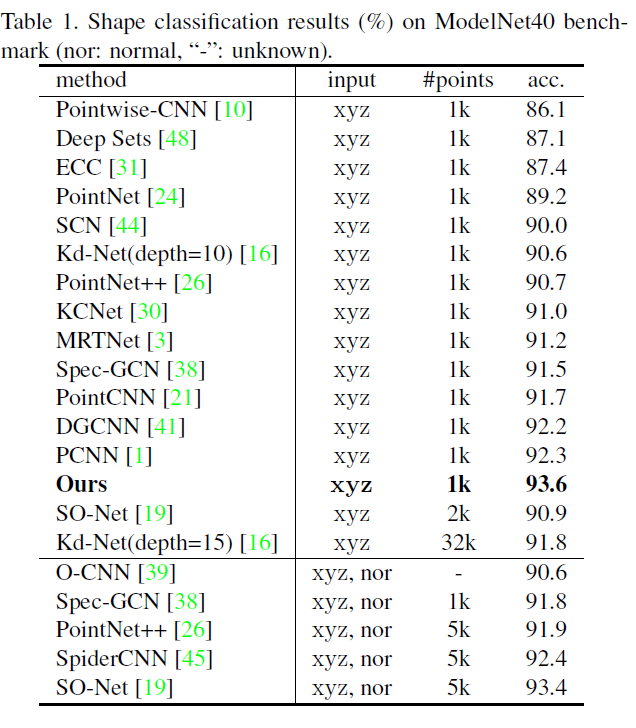
形状分类
我们在Model Net40分类基准[42]上评估RS-CNN。它是由9843个训练模型,2468个测试模型,共40个类。通过[24]对这些模型的点云数据进行采样。我们均匀采样1024个点,并将其归一化为一个单位球体。在训练过程中,我们在[-0.66,1.5]范围内使用随机各向异性缩放并在[-0应用了比率为50%的dropout 技术。在测试过程中,使用随机缩放执行十次投票测试,并对预测取平均。
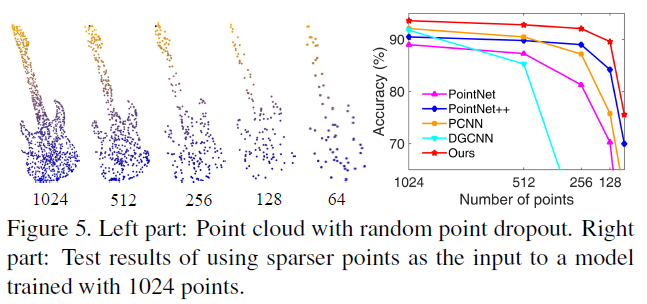
形状部件分割
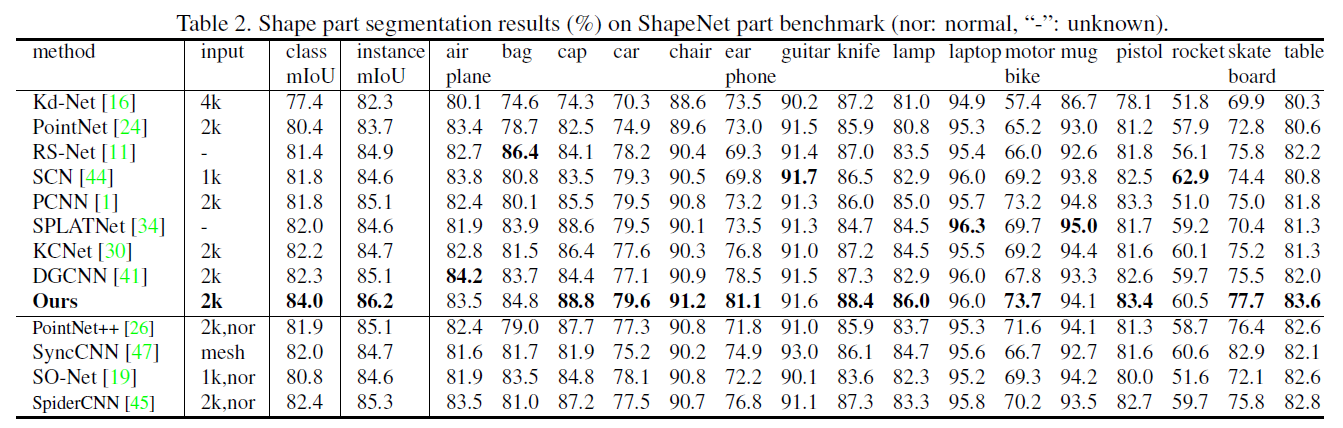
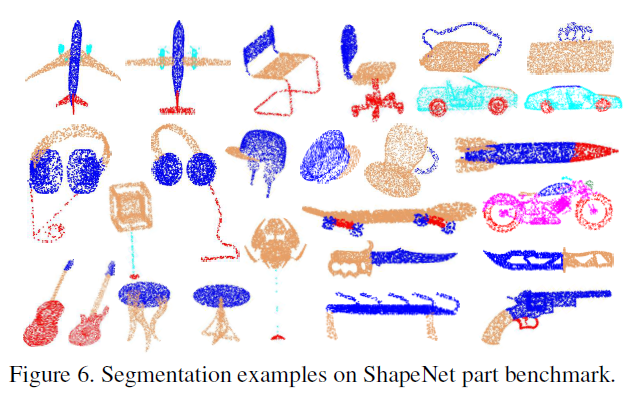
部件分割是一项具有挑战性的细粒度形状分析任务。我们在ShapeNet part benchmark[46]上执行此任务来评估RS-CNN,并遵循[24]中的数据分割。该数据集包含16881个形状,16个类别,总共被标注为50个部分。按照在[24]中,我们随机选择2048个点作为输入,并将对象标签的单个点编码连接到最后一个特征层。在测试期间,我们还使用随机缩放应用了10个投票测试。除了每个类别的标准IoU (Inter- overunion),我们还报告了两种MIoU,分别是所有类和所有实例的平均值。
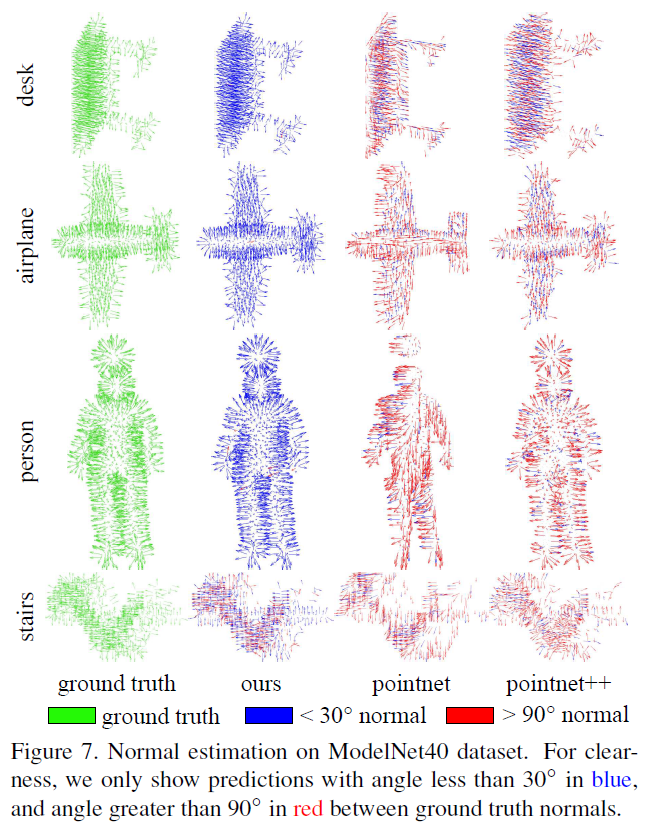
法向量估计
点云的法向量估计是曲面重建和绘制等众多应用中的关键步骤。这项任务非常具有挑战性,因为它需要更高层次的推理,而这超出了基本的形状识别。我们将法向量作为一个监督回归任务,并利用分割网络来实现。使用归一化输出与ground truth normal之间的余弦损失进行回归训练。评价采用ModelNet40数据集,输入均匀采样1024点。

4.2 RS-CNN设计分析
在本节中,我们首先在RS-CNN上进行详细的消融研究。然后讨论了Eq.(3)中聚合函数A、映射函数M和底层关系h的选择,最后验证了RS-CNN对点置换和刚性变换的鲁棒性。所有实验都在ModelNet40分类数据集上进行。
消融研究

为了研究输入点的数量对RS-CNN的影响。
为了研究输入点的数量对RS-CNN的影响,我们也训练了2048个点的网络,但没有发现任何改善(模型H)。该模型(模型I)适用于除关系学习之外的所有技术。准确度达到90.1%,RS-CNN也可以超过3.5%。
我们推测,具有几何关系推理的RS-CNN能够获得更强的形状识别能力,而多尺度关系学习可以极大地增强这种识别能力。
聚合函数A

映射函数M
表5所示的前三行总结了不同层部署M的结果。我们可以看到,通过共享的三层MLP得到了93.6%的最佳精度,当增加层数时但它下降了0.9%。原因可能是四层结构给网络训练带来了一定的困难。值得注意的是,RS-CNN仅使用两层就可以获得92.4%的精度。验证了关联学习在点云基础形状捕获中的有效性。
低级关系h

仅使用3D欧式距离作为h,精度也可以达到92.5%(模型A)。这证明了我们的RS-CNN对于高级几何关系学习的有效性。通过包括坐标差(模型B)和坐标自身(模型C)在内的其他关系,性能逐渐提高。利用两个点的法线向量及其余弦距离作为h,结果(模式D)是92.8%。这表明RS-CNN也能够从法线中的关系中提取形状信息。
直观地,点云的2D视图中的点之间的关系也可以反映基础形状。为了验证RS-CNN在2D关系上的形状抽象,将3D坐标中的一维值强制设置为零,即将3D点投影到XY,XZ和YZ的2D平面上。结果大约是92.2%(E型),这进一步验证了所提出的关系学习方法的有效性。
点置换和刚性变换的鲁棒性

可以看出,所有方法对于排列都是不变的。但是,PointNet易受平移和旋转的影响,而PointNet ++对旋转敏感。相比之下,我们的带有几何关系学习的RS-CNN对于这些扰动是不变的,从而使其对于强大的形状识别具有强大的功能。
4.3 可视化和复杂性分析
可视化
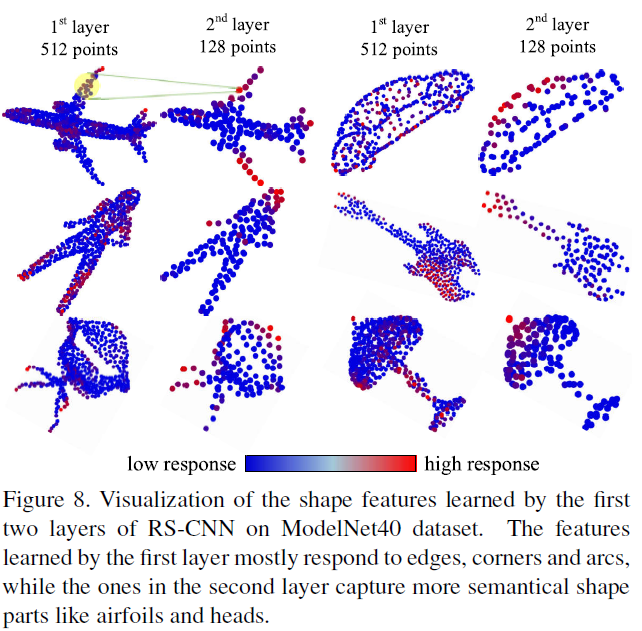
如图所示,第一层学习的特征主要对棱角和弧线做出反应,而第二层的特征捕获了更多语义形状的部分,如机翼和头部。这验证了RS-CNN可以学习渐进性的形状感知表示用于点云分析。
复杂性分析
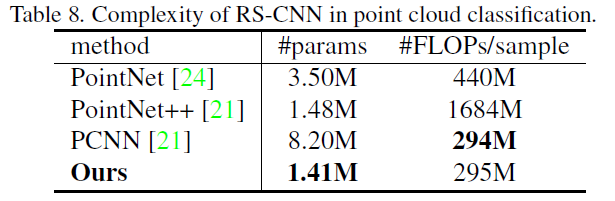
五、总结
在这项工作中,提出了RS-CNN,即关系形状卷积神经网络,它将规则网格CNN扩展到不规则配置以进行点云分析。RS-CNN的核心是一种新颖的卷积算子,它可以从关系(即点之间的几何拓扑约束)中学习。通过这种方式,可以对点的空间布局进行明确的推理,从而获得有区别的形状意识。此外,还可以获得几何关系的良好特性,例如对刚性变换的鲁棒性。结果,配备有该运算符的RSCNN可以实现上下文形状感知学习,从而使其高效。跨三个任务的具有挑战性的基准测试的广泛实验,以及详尽的经验和理论分析,证明RS-CNN达到了最先进的水平。
六、代码分析
(略)
参考:https://blog.csdn.net/Dujing2019/article/details/104387630/?utm_medium=distribute.pc_relevant.none-task-blog-title-2&spm=1001.2101.3001.4242
https://www.cnblogs.com/SuperLab/p/11672161.html