参考:
https://blog.csdn.net/Zsigner/article/details/115306506
https://www.jianshu.com/p/30eb687e0b94
转自:https://www.modb.pro/db/390885
元数据管理是数据治理的基石,hive hook是一种实现元数据采集的方式,本文将介绍hive hook的优缺点,以及hive的多种hook机制,最后使用一个案例分析hook的执行过程。Hive客户端支持Hive Cli、HiveServer2等,一个完整的HQL需要经过解析、编译、优化器处理、执行器执行共四个阶段。
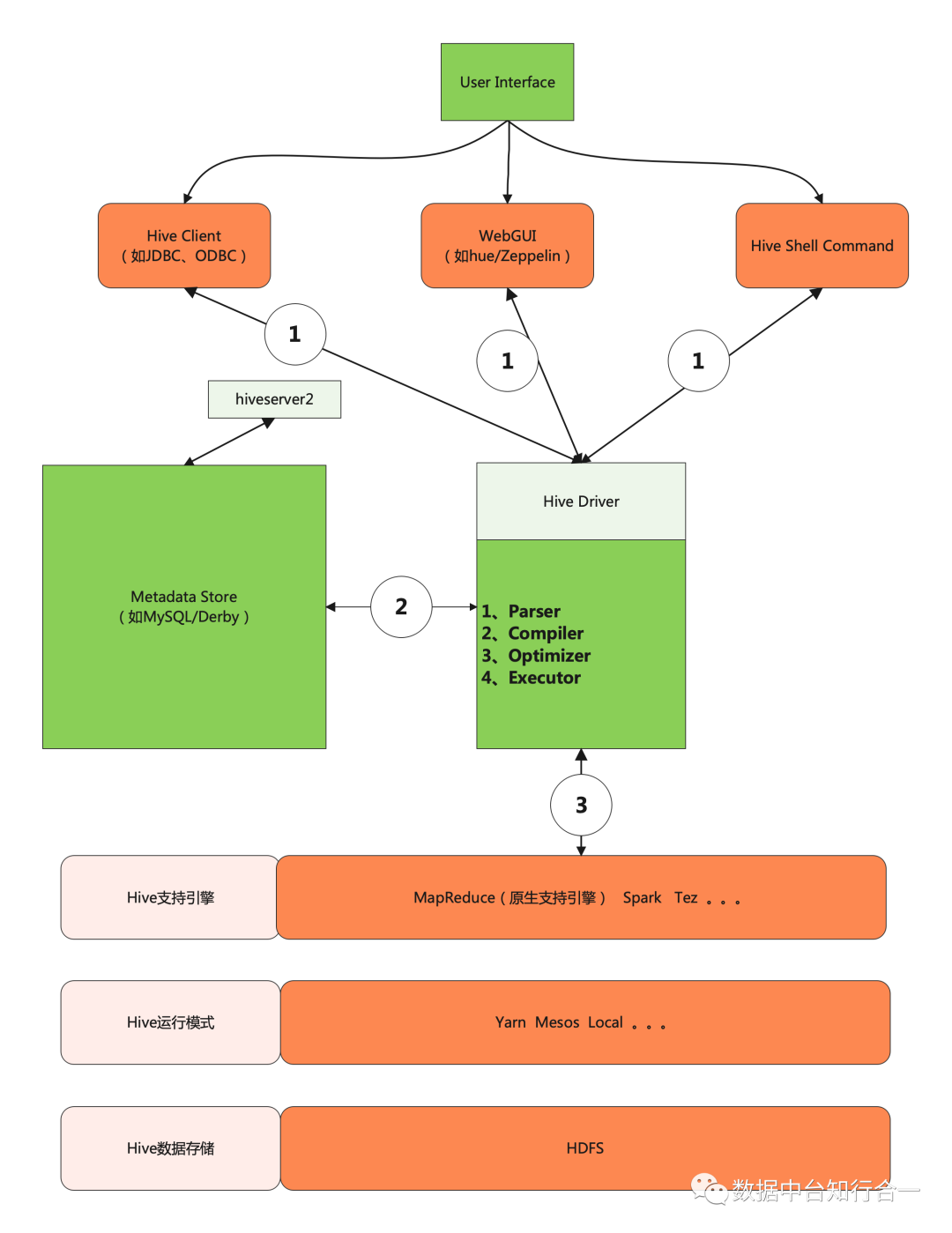
以Hive目前原生支持计算引擎MapReduce为例,具体处理流程如下:
1、HQL解析生成AST语法树,Antlr定义SQL的语法规则,完成SQL词法和语法解析,将SQL转化为AST;
2、语法分析得到QueryBlock遍历AST,抽象出查询的基本组成单元QueryBlock;
3、生成逻辑执行计划遍历QueryBlock,翻译为执行操作树Operator Tree;
4、逻辑优化执行器进行逻辑优化,逻辑层优化器进行Operator Tree变换,合并不必要的Reduce Sink Operator,减少shuffle数据量;
5、生成物理执行计划Task Plan,遍历Operator Tree,翻译为MapReduce任务;
6、物理优化Task Tree,构建执行计划QueryPlan,物理层优化器进行MapReduce任务的变换,生成最终的执行计划;
7、表以及其他鉴权操作;
8、执行执行引擎。
本文我们重点关注hook的分类及应用。
一、hive hook优缺点分析
(1)优点
-
可以很方便地在各种查询阶段嵌入或者运行自定义的代码;
-
可以被用来更新元数据;
(2)缺点
-
使用Hooks获取到的元数据通常需要进一步解析,否则很难理解,可读性不高;
-
会影响查询的性能。
二、hive hook的分类
Hooks (钩子)是一种事件和消息机制, 可以将事件绑定在内部 Hive 的执行流程中,而无需重新编译 Hive。Hook 提供了扩展和继承外部组件的方式。前面提到HQL的执行过程包括:HQL解析(生成AST语法树) => 语法分析(得到QueryBlock) => 生成逻辑执行计划(Operator) => 逻辑优化(LogicalOptimizer Operator) => 生成物理执行计划(TaskPlan) => 物理优化(Task Tree) => 构建执行计划(QueryPlan) => 执行引擎执行八个阶段,根据不同的 Hook 类型,可以在不同的阶段运行。关于Hooks的类型,主要分为以下几种:
(1)hive.exec.pre.hooks
生命周期:在执行引擎执行前被调用,需要对查询计划优化后才可以使用。
使用方式:修改hive-site.xml为如下配置,多个实现类使用逗号分割
<property><name>hive.exec.pre.hooks</name><value>org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext<value/></property>
(2)hive.exec.post.hooks
生命周期:在执行计划结束后,返回查询结果给客户端前被调用
使用方式:修改hive-site.xml为如下配置,多个实现类使用逗号分割
<property><name>hive.exec.post.hooks</name><value>org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext<value/></property>
(3)hive.exec.failure.hooks
生命周期:在执行计划失败后被调用
使用方式:修改hive-site.xml为如下配置,多个实现类使用逗号分割
<property><name>hive.exec.failure.hooks</name><value>org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext<value/></property>
(4)hive.metastore.init.hooks
生命周期:在HMSHandler初始化是被调用
使用方式:修改hive-site.xml为如下配置,多个实现类使用逗号分割
<property><name>hive.metastore.init.hooks</name><value>org.apache.hadoop.hive.metastore.MetaStoreInitListener<value/></property>
(5)hive.exec.driver.run.hooks
生命周期:在Driver.run开始或结束时被调用
使用方式:修改hive-site.xml为如下配置,多个实现类使用逗号分割
<property><name>hive.exec.driver.run.hooks</name><value>org.apache.hadoop.hive.ql.HiveDriverRunHook<value/></property>
(6)hive.semantic.analyzer.hook
生命周期:在对查询语句进行语义分析时被调用
使用方式:修改hive-site.xml为如下配置,多个实现类使用逗号分割
<property><name>hive.semantic.analyzer.hook</name><value>org.apache.hadoop.hive.ql.parse.AbstractSemanticAnalyzerHook<value/></property>
(7)hive.exec.query.redactor.hooks
生命周期:语法分析之后,生成执行计划之前被调用
使用方式:修改hive-site.xml为如下配置,多个实现类使用逗号分割
<property><name>hive.exec.query.redactor.hooks</name><value>org.apache.hadoop.hive.ql.hooks.Redactor<value/></property>
三、hive hook应用案例
本案例演示“执行计划执行后的hook”,相应的hive-site.xml需要修改为:
<property><name>hive.exec.post.hooks</name><value>org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext<value/></property>
示例代码:
package com.demo.hive;import com.fasterxml.jackson.databind.ObjectMapper;import org.apache.hadoop.hive.metastore.api.Database;import org.apache.hadoop.hive.ql.QueryPlan;import org.apache.hadoop.hive.ql.hooks.*;import org.apache.hadoop.hive.ql.plan.HiveOperation;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.util.HashSet;import java.util.Set;public class CustomPostHook implements ExecuteWithHookContext {private static final Logger LOGGER = LoggerFactory.getLogger(CustomPostHook.class);// 存储Hive的SQL操作类型private static final HashSet<String> OPERATION_NAMES = new HashSet<>();// HiveOperation是一个枚举类,封装了Hive的SQL操作类型// 监控SQL操作类型static {// 建表OPERATION_NAMES.add(HiveOperation.CREATETABLE.getOperationName());// 修改数据库属性OPERATION_NAMES.add(HiveOperation.ALTERDATABASE.getOperationName());// 修改数据库属主OPERATION_NAMES.add(HiveOperation.ALTERDATABASE_OWNER.getOperationName());// 修改表属性,添加列OPERATION_NAMES.add(HiveOperation.ALTERTABLE_ADDCOLS.getOperationName());// 修改表属性,表存储路径OPERATION_NAMES.add(HiveOperation.ALTERTABLE_LOCATION.getOperationName());// 修改表属性OPERATION_NAMES.add(HiveOperation.ALTERTABLE_PROPERTIES.getOperationName());// 表重命名OPERATION_NAMES.add(HiveOperation.ALTERTABLE_RENAME.getOperationName());// 列重命名OPERATION_NAMES.add(HiveOperation.ALTERTABLE_RENAMECOL.getOperationName());// 更新列,先删除当前的列,然后加入新的列OPERATION_NAMES.add(HiveOperation.ALTERTABLE_REPLACECOLS.getOperationName());// 创建数据库OPERATION_NAMES.add(HiveOperation.CREATEDATABASE.getOperationName());// 删除数据库OPERATION_NAMES.add(HiveOperation.DROPDATABASE.getOperationName());// 删除表OPERATION_NAMES.add(HiveOperation.DROPTABLE.getOperationName());}@Overridepublic void run(HookContext hookContext) throws Exception {assert (hookContext.getHookType() == HookType.POST_EXEC_HOOK);// 执行计划QueryPlan plan = hookContext.getQueryPlan();// 操作名称String operationName = plan.getOperationName();logWithHeader("执行的SQL语句: " + plan.getQueryString());logWithHeader("操作名称: " + operationName);if (OPERATION_NAMES.contains(operationName) && !plan.isExplain()) {logWithHeader("监控SQL操作");Set<ReadEntity> inputs = hookContext.getInputs();Set<WriteEntity> outputs = hookContext.getOutputs();for (Entity entity : inputs) {logWithHeader("Hook metadata输入值: " + toJson(entity));}for (Entity entity : outputs) {logWithHeader("Hook metadata输出值: " + toJson(entity));}} else {logWithHeader("不在监控范围,忽略该hook!");}}private static String toJson(Entity entity) throws Exception {ObjectMapper mapper = new ObjectMapper();// entity的类型// 主要包括:// DATABASE, TABLE, PARTITION, DUMMYPARTITION, DFS_DIR, LOCAL_DIR, FUNCTIONswitch (entity.getType()) {case DATABASE:Database db = entity.getDatabase();return mapper.writeValueAsString(db);case TABLE:return mapper.writeValueAsString(entity.getTable().getTTable());}return null;}/*** 日志格式** @param obj*/private void logWithHeader(Object obj) {LOGGER.info("[CustomPostHook][Thread: " + Thread.currentThread().getName() + "] | " + obj);}}
pom.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>javademo</artifactId><groupId>org.example</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>CustomPostHook</artifactId><dependencies><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>2.3.4</version></dependency></dependencies></project>
源码分析:
(1)加载jar包,在Hive的客户端中执行添加jar包的命令
hive> add jar root/CustomPostHook-1.0-SNAPSHOT.jar;(2)修改hive-site.xml或直接在命令行修改,此处我们选择在命令行直接修改进行演示
hive> set hive.exec.post.hooks=com.demo.hive.CustomPostHook;(3)查看表操作
hive> show tables;查看日志:
为了更方便我们查看日志,配置一下hive的临时日志目录:
mkdir hive-log-tmpcd hive-log-tmp/chmod 777 .hive --hiveconf hive.log.dir=/root/hive-log-tmp/$USER
日志详情:
INFO [873f75ee-51e6-458d-8273-44fa04b5859f main] hive.CustomPostHook: [CustomPostHook][Thread: 873f75ee-51e6-458d-8273-44fa04b5859f main] | 执行的SQL语句: show tablesINFO [873f75ee-51e6-458d-8273-44fa04b5859f main] hive.CustomPostHook: [CustomPostHook][Thread: 873f75ee-51e6-458d-8273-44fa04b5859f main] | 操作名称: SHOWTABLESINFO [873f75ee-51e6-458d-8273-44fa04b5859f main] hive.CustomPostHook: [CustomPostHook][Thread: 873f75ee-51e6-458d-8273-44fa04b5859f main] | 不在监控范围,忽略该hook!
(4)建表操作
CREATE TABLE testposthook(id int COMMENT "id",name string COMMENT "姓名")COMMENT "建表_测试Hive Hooks"ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'LOCATION '/user/hive/warehouse/';
(5)查看建表操作的日志
INFO [873f75ee-51e6-458d-8273-44fa04b5859f main] hive.CustomPostHook: [CustomPostHook][Thread: 873f75ee-51e6-458d-8273-44fa04b5859f main] | 操作名称: CREATETABLEINFO [873f75ee-51e6-458d-8273-44fa04b5859f main] hive.CustomPostHook: [CustomPostHook][Thread: 873f75ee-51e6-458d-8273-44fa04b5859f main] | 监控SQL操作INFO [873f75ee-51e6-458d-8273-44fa04b5859f main] hive.CustomPostHook: [CustomPostHook][Thread: 873f75ee-51e6-458d-8273-44fa04b5859f main] | Hook metadata输入值: nullINFO [873f75ee-51e6-458d-8273-44fa04b5859f main] hive.CustomPostHook: [CustomPostHook][Thread: 873f75ee-51e6-458d-8273-44fa04b5859f main] | Hook metadata输出值: {"name":"default","description":"Default Hive database","locationUri":"hdfs://localhost:8020/user/hive/warehouse","parameters":{},"privileges":null,"ownerName":"public","ownerType":"ROLE","createTime":1638515629,"setOwnerName":true,"setOwnerType":true,"setPrivileges":false,"setName":true,"setDescription":true,"setLocationUri":true,"setParameters":true,"setCreateTime":true,"parametersSize":0}INFO [873f75ee-51e6-458d-8273-44fa04b5859f main] hive.CustomPostHook: [CustomPostHook][Thread: 873f75ee-51e6-458d-8273-44fa04b5859f main] | Hook metadata输出值: {"tableName":"testposthook","dbName":"default","owner":"root","createTime":1641284654,"lastAccessTime":0,"retention":0,"sd":{"cols":[],"location":null,"inputFormat":"org.apache.hadoop.mapred.SequenceFileInputFormat","outputFormat":"org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat","compressed":false,"numBuckets":-1,"serdeInfo":{"name":null,"serializationLib":"org.apache.hadoop.hive.serde2.MetadataTypedColumnsetSerDe","parameters":{"serialization.format":"1"},"setName":false,"setParameters":true,"parametersSize":1,"setSerializationLib":true},"bucketCols":[],"sortCols":[],"parameters":{},"skewedInfo":{"skewedColNames":[],"skewedColValues":[],"skewedColValueLocationMaps":{},"setSkewedColNames":true,"setSkewedColValues":true,"setSkewedColValueLocationMaps":true,"skewedColNamesSize":0,"skewedColNamesIterator":[],"skewedColValuesSize":0,"skewedColValuesIterator":[],"skewedColValueLocationMapsSize":0},"storedAsSubDirectories":false,"setLocation":false,"setOutputFormat":true,"setSerdeInfo":true,"setBucketCols":true,"setSortCols":true,"setSkewedInfo":true,"colsIterator":[],"setCompressed":false,"setNumBuckets":true,"bucketColsSize":0,"bucketColsIterator":[],"sortColsSize":0,"sortColsIterator":[],"setStoredAsSubDirectories":false,"setParameters":true,"parametersSize":0,"colsSize":0,"setInputFormat":true,"setCols":true},"partitionKeys":[],"parameters":{},"viewOriginalText":null,"viewExpandedText":null,"tableType":"MANAGED_TABLE","privileges":null,"temporary":false,"ownerType":"USER","setOwnerType":true,"setTableName":true,"setPrivileges":false,"setOwner":true,"setPartitionKeys":true,"setViewOriginalText":false,"setViewExpandedText":false,"setTableType":true,"setRetention":false,"partitionKeysIterator":[],"setTemporary":false,"setDbName":true,"setSd":true,"setParameters":true,"setCreateTime":true,"setLastAccessTime":false,"parametersSize":0,"partitionKeysSize":0}
以上,本文对六种hive hook的配置方式进行了讲解,最后使用一个案例演示了“hive.exec.post.hooks”的执行效果,这就是使用hive hook采集技术元数据的一种方式,需要说明的是,开启hive hook会对作业的执行性能有一定的影响,在生产环境是否开启hive hook,需要根据实际使用场景灵活配置。
PS:文章参考了一部分网上的文章,感谢!