项目中有这么一个需求,需要监控datax的执行,获取相关配置数据。本来想着可以从datax.py进去写段Python把参数读到发到kafka,但毕竟还是对datax是有侵入的。
经过研究,发现不仅hive有hivehook,datax也有datax的hook。
一、dataX的hook原理
在datax的JobContainer类的start()方法中,调用了一个this.invokeHooks()方法。
看源码是调用一个外部提供的的hook。那hook放在哪里呢?这个方法明确了路径${DATAX_HOME}/hook
/** * 调用外部hook */ private void invokeHooks() { Communication comm = super.getContainerCommunicator().collect(); HookInvoker invoker = new HookInvoker(CoreConstant.DATAX_HOME + "/hook", configuration, comm.getCounter()); invoker.invokeAll(); }
那hook里写啥呢,这个要看你自己的需求,我的需求是要把各种配置参数发个kafka消息出来。
我们接着往下看,invoker.invokeAll()
先判断/hook目录存在不存在,不存在就直接return,存在就遍历子目录,然后对每个子目录进行doInvode()方法。
public void invokeAll() { if (!baseDir.exists() || baseDir.isFile()) { LOG.info("No hook invoked, because base dir not exists or is a file: " + baseDir.getAbsolutePath()); return; } String[] subDirs = baseDir.list(new FilenameFilter() { @Override public boolean accept(File dir, String name) { return new File(dir, name).isDirectory(); } }); if (subDirs == null) { throw DataXException.asDataXException(FrameworkErrorCode.HOOK_LOAD_ERROR, "获取HOOK子目录返回null"); } for (String subDir : subDirs) { doInvoke(new File(baseDir, subDir).getAbsolutePath()); } }
doInvode()里面的代码就很熟悉了。就是ClassLoader加载我们自定义的jar包,通过SPI的方式拿到我们自定义的Hook接口的实现,然后执行hook.invoke(conf, msg);
private void doInvoke(String path) { ClassLoader oldClassLoader = Thread.currentThread().getContextClassLoader(); try { JarLoader jarLoader = new JarLoader(new String[]{path}); Thread.currentThread().setContextClassLoader(jarLoader); Iterator<Hook> hookIt = ServiceLoader.load(Hook.class).iterator(); if (!hookIt.hasNext()) { LOG.warn("No hook defined under path: " + path); } else { Hook hook = hookIt.next(); LOG.info("Invoke hook [{}], path: {}", hook.getName(), path); hook.invoke(conf, msg); } } catch (Exception e) { LOG.error("Exception when invoke hook", e); throw DataXException.asDataXException( CommonErrorCode.HOOK_INTERNAL_ERROR, "Exception when invoke hook", e); } finally { Thread.currentThread().setContextClassLoader(oldClassLoader); } }
Hook接口是datax定义的,内容如下
public interface Hook { /** * 返回名字 * * @return */ public String getName(); /** * TODO 文档 * * @param jobConf * @param msg */ public void invoke(Configuration jobConf, Map<String, Number> msg); }
这样一路下来,逻辑理清楚了,我们就可以自定义自己的Hook实现了。
二、自定义dataXHook
我们新建一个项目datax-hook,目录接口如下
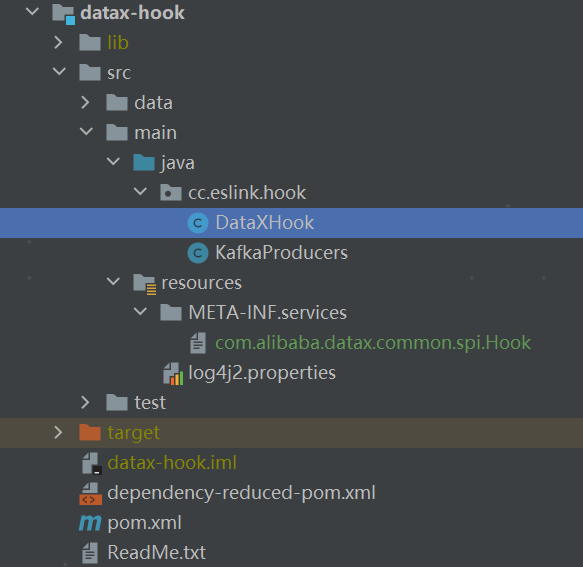
先配置maven依赖。我们的逻辑很简单,拿到执行中的datax任务的conf直接发消息给kafka,pom文件如下
<dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.3.0</version> </dependency> <!-- maven仓库没有datax-common的jar包,需要本地构建--> <dependency> <groupId>com.alibaba.datax</groupId> <artifactId>datax-common</artifactId> <version>0.0.1-SNAPSHOT</version> <scope>system</scope> <systemPath>${project.basedir}/lib/datax-common-0.0.1-SNAPSHOT.jar</systemPath> </dependency> </dependencies>
kafka的依赖没问题,datax的发生了意外,因为maven中央仓库仓库没有datax的jar包。
那么只好给datax-common打一个本地jar包,然后拷贝到项目的lib目录下。
在pom文件中通过依赖本地jar包完成依赖配置。
自定义类实现Hook接口
public class DataXHook implements Hook { @Override public String getName() { return "DataXHook"; } @Override public void invoke(Configuration jobConf, Map<String, Number> msg) { KafkaProducer<String, String> kafkaProducer = KafkaProducers.getKafkaProducer(); kafkaProducer.send(new ProducerRecord<>("test2", jobConf.toJSON())); kafkaProducer.close(); } }
然后打一个胖jar,在datax_home目录创建hook目录,在hook目录下创建kafka子目录,将我们的胖jar上传到这目录即可。
执行一个datax任务,只要收到kafka的消息,就成功了。
备注:
Java SPI要求在jar包根本目的META-INF/services目录下创建一个文件,文件名是被我们实现的接口的全路径,文件内容是我们的实现类的全路径名