本文内容是Instrumenting a library的笔记,一般来说不需要自己写跟踪代码库,因为Zipkin已经有许多现有的各个语言的代码库了(Existing instrumentations)阅读本文只是为了更加深入的了解Zipkin的内部设计而已。
概述
你的代码库需要解决三个问题
- 用什么数据结构表示跟踪数据
- 如何创建Trace ID, Span ID和在服务间传递跟踪信息
- 如何记录操作的用时和时间戳
数据结构
openzipkin/zipkin-api 定义了跟踪数据的数据结构,它包含如下模块:
- 注解:用于标记事件
- 最基本的事件就是一个RPC请求的开始和结束
- cs - Client Send: 记录客户端发送请求的事件,是一次跟踪记录Span的开始
- sr - Server Receive: 记录服务器端收到请求的事件。sr和cs两个事件的时间差能反应网络延时或者两个机器时钟的差异。
- ss - Server Send: 记录服务器端处理完请求发送回复的事件。ss和sr的时间差就是服务器处理请求的时间
- cr - Client Receive: 记录客户端收到服务器回复的事件。客户端收到了回复,也表示跟踪记录Span的结束。
- 如果是采用消息队列而不是RPC的方式,有如下两个事件可以记录
- ms - Message Send: 生产者发送了一个消息到队列里
- mr - Message Receive: 消费者从消息队列里收到了一个消息。
- 二进制注解:不包含时间信息,仅仅是一些附加的信息。比如对于一个HTTP请求,可以把请求的路径作为二进制注解记录下来进行分析。
- Span:
- 标记一次RPC跟踪的数据,包含了一些注解信息和二进制注解信息,同时也包含ID信息比如Trace ID, Span ID, Parent ID 和RPC名字
- 一般<1KB大小。但注意不要包含太多的信息,避免Span太大超过Kafka的消息大小限制(1MB)
- Trace:
- 一次端对端的系统跟踪(Trace)包含多个内部RPC跟踪(Span)的数据。形成一棵树,树根叫Root Span,树的节点都有一个共同的Trace Id
ID标识
- ID种类
- Trace ID: 64 或者128bit
- Span ID: 64bit
- Parent ID: 当两个Span之间有父子关系的时候,子Span就要记录Parent ID,根Rpan没有Parent ID
- ID的产生
- 如果一个请求没有附带的Trace Id和Span Id,我们会创建一个新的。Span ID可以用Trace ID里下64-bit表示,也可以重新产生
- 如果请求自带Trace ID和Span ID,应该使用他们,因为这表示当前的Span还没有结束
- 如果服务发起另一个RPC调用给下游的服务,要产生一个新的Span作为当前Span的子Span,新的Span的Trace ID和当前Span的Trace ID一样,新的Span的Span ID是随机生成的64bit,新的Span的Parent ID是当前Span的ID
- 如果服务发起多个请求,每个请求产生一个新的子Span
- 在服务调用之间传递的跟踪信息包括(具体请看openzipkin/b3-propagation):
- Trace ID
- Span ID
- Parent ID
- Sampled - 如果Sampled=1,下游知道要记录这个Trace,如果没有Sampled信息,那么下游自己随机决定是否要记录。
- Debug Flag - 告诉下游这是一次调试,不要Sample任何数据,完整记录下来
时间的记录
使用微秒来记录时间戳和操作用时(Span.Timestamp && Span.Duration)
- 所有的Zipkin时间戳都应该用微秒来表示,可以使用clock_gettime来获得。用64位的整数来存储
- 因为时钟偏差的因素,时间戳可能会倒退,因此应该尽可能的记录Span操作用时
设置Span时间戳和操作用时的时机
- 必须由Span的建立者在结束Span的时候设置时间戳和操作用时,Zipkin会合并所有具有相同Trace ID和Span ID的跟踪数据。
- 例子:
- 客户端发起一个请求,建立了一个Span,记录cs和cr的时间点,因为它是发起者,所以它负责记录Span时间戳和操作用时
- 服务器端收到请求和跟踪信息,它用相同的Trace Id和Span ID记录sr和ss的时间点,但它不需要记录时间戳和操作用时
单方向RPC跟踪
单方向RPC的跟踪和一般的跟踪一样,唯一的区别是请求没有回复。因此单方向的请求只有cs和sr两个数据点,也没有记录Span时间戳和操作用时。具体如下图:
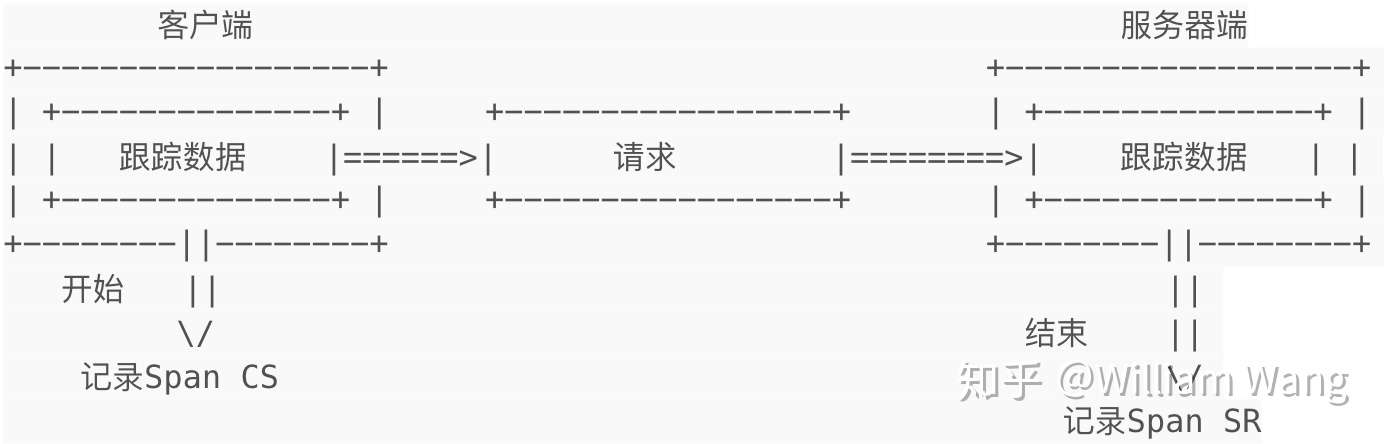
- 客户端代码
// 把跟踪信息加到请求的头部里
tracing.propagation().injector(Request::addHeader)
.inject(span.context(), request);
// 发送请求
client.send(request);
// 记录Span CS并发送到Zipkin
span.kind(Span.Kind.CLIENT)
.start().flush();- 服务器端代码
// 从请求的头部获得跟踪信息
TraceContextOrSamplingFlags result =
tracing.propagation().extractor(Request::getHeader).extract(request);
// 使用跟踪信息里面的Span ID
span = tracer.joinSpan(result.context())
// 记录Span SR并发送到Zipkin
span.kind(Span.Kind.SERVER)
.start().flush();消息跟踪
消息跟踪跟RPC跟踪不一样,因为消息的生产者和消费者不共用Span ID。在消息模型中,一个消息可能有多个消费者。和单方向跟踪一样,消息跟踪没有回复,只记录两个数据点ms和mr。因为生产者和消费者用不同的Span,所以他们可以分别记录Span的时间戳和操作用时,具体如下图:
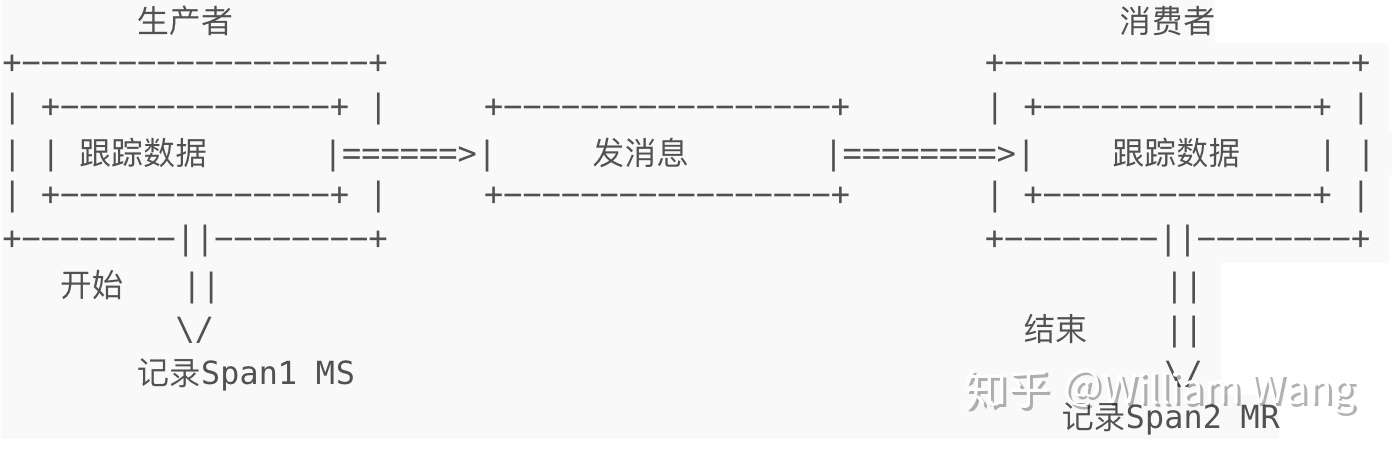
- 生产者端代码
// 添加跟踪信息到消息头部
tracing.propagation().injector(Message::addHeader)
.inject(span.context(), message);
// 生产者发送消息
producer.send(message);
// 记录Span MS并存储到Zipkin里
span.kind(Span.Kind.PRODUCER)
.remoteEndpoint(broker.endpoint())
.start().finish();- 消费者端代码
// 从消息头部获得跟踪信息
TraceContextOrSamplingFlags result =
tracing.propagation().extractor(Message::getHeader).extract(message);
// 基于生产者的Span建立一个子Span
span = tracer.newChild(result.context())
// 记录Span MR并存储到Zipkin里
span.kind(Span.Kind.CONSUMER)
.remoteEndpoint(broker.endpoint())
.start().finish();- 因为一个消费者可能会处理多个消息,最好把Span信息放到消息的头部里面,以方便以后建立子Span可以直接从消息头部取出相信的跟踪信息,以下为Kafka的代码:
public ConsumerRecords<K, V> poll(long timeout) {
ConsumerRecords<K, V> records = delegate.poll(timeout);
for (ConsumerRecord<K, V> record : records) {
handleConsumed(record);
}
return records;
}
void handleConsumed(ConsumerRecord record) {
// 处理一个消息并获得当前Span
Span span = startAndFinishConsumerSpan(record);
// 用当前Span覆盖消息的头部
injector.inject(span.context(), record.headers());
}