前言
前情回顾
上一讲看了Eureka 注册中心的自我保护机制,以及里面提到的bug问题。
哈哈 转眼间都2020年了,这个系列的文章从12.17 一直写到现在,也是不容易哈,每天持续不断学习,输出博客,这一段时间确实收获很多。
今天在公司给组内成员分享了Eureka源码剖析,反响效果还可以,也算是感觉收获了点东西。后面还会继续feign、ribbon、hystrix的源码学习,依然文章连载的形式输出。
本讲目录
本讲主要是EurekaServer集群模式的数据同步讲解,主要目录如下。
目录如下:
- eureka server集群机制
- 注册、下线、续约的注册表同步机制
- 注册表同步三层队列机制详解
技术亮点:
- 3层队列机制实现注册表的批量同步需求
说明
原创不易,如若转载 请标明来源!
博客地址:一枝花算不算浪漫
微信公众号:壹枝花算不算浪漫
源码分析
eureka server集群机制
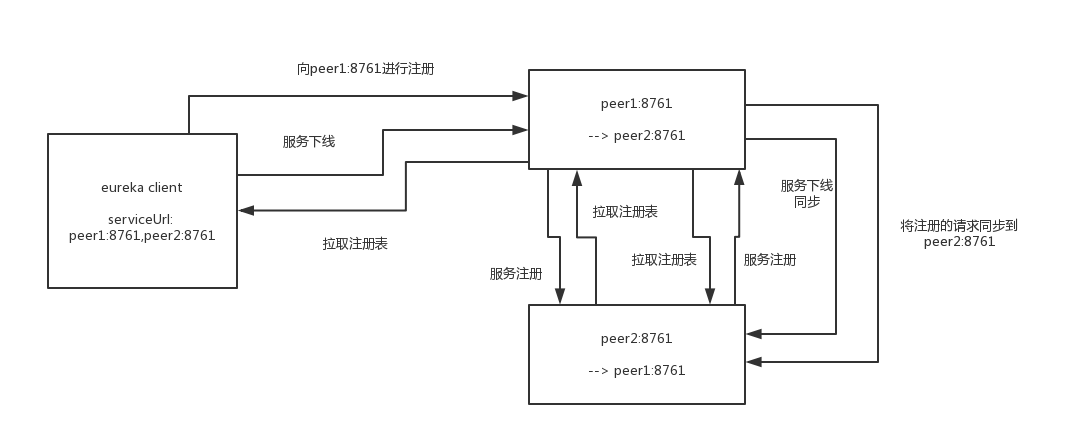
Eureka Server会在注册、下线、续约的时候进行数据同步,将信息同步到其他Eureka Server节点。
可以想象到的是,这里肯定不会是实时同步的,往后继续看注册表的同步机制吧。
注册、下线、续约的注册表同步机制
我们以Eureka Client注册为例,看看Eureka Server是如何同步给其他节点的。
PeerAwareInstanceRegistryImpl.java :
public void register(final InstanceInfo info, final boolean isReplication) {
int leaseDuration = Lease.DEFAULT_DURATION_IN_SECS;
if (info.getLeaseInfo() != null && info.getLeaseInfo().getDurationInSecs() > 0) {
leaseDuration = info.getLeaseInfo().getDurationInSecs();
}
super.register(info, leaseDuration, isReplication);
replicateToPeers(Action.Register, info.getAppName(), info.getId(), info, null, isReplication);
}
private void replicateToPeers(Action action, String appName, String id,
InstanceInfo info /* optional */,
InstanceStatus newStatus /* optional */, boolean isReplication) {
Stopwatch tracer = action.getTimer().start();
try {
if (isReplication) {
numberOfReplicationsLastMin.increment();
}
// If it is a replication already, do not replicate again as this will create a poison replication
if (peerEurekaNodes == Collections.EMPTY_LIST || isReplication) {
return;
}
for (final PeerEurekaNode node : peerEurekaNodes.getPeerEurekaNodes()) {
// If the url represents this host, do not replicate to yourself.
if (peerEurekaNodes.isThisMyUrl(node.getServiceUrl())) {
continue;
}
replicateInstanceActionsToPeers(action, appName, id, info, newStatus, node);
}
} finally {
tracer.stop();
}
}
private void replicateInstanceActionsToPeers(Action action, String appName,
String id, InstanceInfo info, InstanceStatus newStatus,
PeerEurekaNode node) {
try {
InstanceInfo infoFromRegistry = null;
CurrentRequestVersion.set(Version.V2);
switch (action) {
case Cancel:
node.cancel(appName, id);
break;
case Heartbeat:
InstanceStatus overriddenStatus = overriddenInstanceStatusMap.get(id);
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.heartbeat(appName, id, infoFromRegistry, overriddenStatus, false);
break;
case Register:
node.register(info);
break;
case StatusUpdate:
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.statusUpdate(appName, id, newStatus, infoFromRegistry);
break;
case DeleteStatusOverride:
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.deleteStatusOverride(appName, id, infoFromRegistry);
break;
}
} catch (Throwable t) {
logger.error("Cannot replicate information to {} for action {}", node.getServiceUrl(), action.name(), t);
}
}
- 注册完成后,调用
replicateToPeers(),注意这里面有一个参数isReplication,如果是true,代表是其他Eureka Server节点同步的,false则是EurekaClient注册来的。 replicateToPeers()中一段逻辑,如果isReplication为true则直接跳出,这里意思是client注册来的服务实例需要向其他节点扩散,如果不是则不需要去同步peerEurekaNodes.getPeerEurekaNodes()拿到所有的Eureka Server节点,循环遍历去同步数据,调用replicateInstanceActionsToPeers()replicateInstanceActionsToPeers()方法中根据注册、下线、续约等去处理不同逻辑
接下来就是真正执行同步逻辑的地方,这里主要用了三层队列对同步请求进行了batch操作,将请求打成一批批 然后向各个EurekaServer进行http请求。
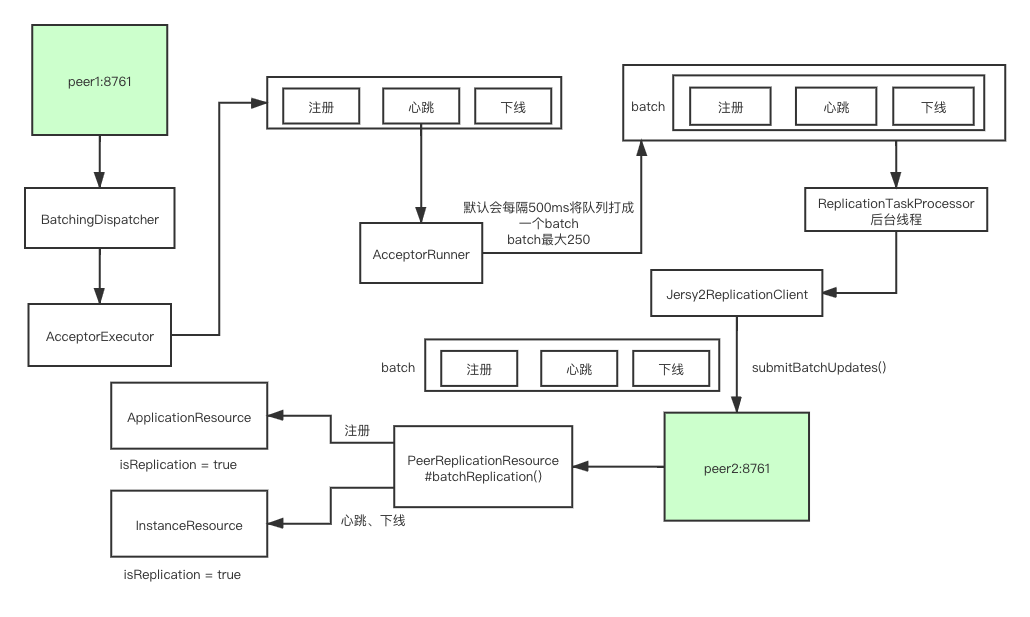
注册表同步三层队列机制详解
到了这里就是真正进入了同步的逻辑,这里还是以上面注册逻辑为主线,接着上述代码继续往下跟:
PeerEurekaNode.java :
public void register(final InstanceInfo info) throws Exception {
long expiryTime = System.currentTimeMillis() + getLeaseRenewalOf(info);
batchingDispatcher.process(
taskId("register", info),
new InstanceReplicationTask(targetHost, Action.Register, info, null, true) {
public EurekaHttpResponse<Void> execute() {
return replicationClient.register(info);
}
},
expiryTime
);
}
这里会执行batchingDispatcher.process() 方法,我们继续点进去,然后会进入 TaskDispatchers.createBatchingTaskDispatcher() 方法,查看其中的匿名内部类中的process()方法:
void process(ID id, T task, long expiryTime) {
// 将请求都放入到acceptorQueue中
acceptorQueue.add(new TaskHolder<ID, T>(id, task, expiryTime));
acceptedTasks++;
}
将需要同步的Task数据放入到acceptorQueue队列中。
接着回到createBatchingTaskDispatcher()方法中,看下AcceptorExecutor,它的构造函数中会启动一个后台线程:
ThreadGroup threadGroup = new ThreadGroup("eurekaTaskExecutors");
this.acceptorThread = new Thread(threadGroup, new AcceptorRunner(), "TaskAcceptor-" + id);
我们继续跟AcceptorRunner.java:
class AcceptorRunner implements Runnable {
@Override
public void run() {
long scheduleTime = 0;
while (!isShutdown.get()) {
try {
// 处理acceptorQueue队列中的数据
drainInputQueues();
int totalItems = processingOrder.size();
long now = System.currentTimeMillis();
if (scheduleTime < now) {
scheduleTime = now + trafficShaper.transmissionDelay();
}
if (scheduleTime <= now) {
// 将processingOrder拆分成一个个batch,然后进行操作
assignBatchWork();
assignSingleItemWork();
}
// If no worker is requesting data or there is a delay injected by the traffic shaper,
// sleep for some time to avoid tight loop.
if (totalItems == processingOrder.size()) {
Thread.sleep(10);
}
} catch (InterruptedException ex) {
// Ignore
} catch (Throwable e) {
// Safe-guard, so we never exit this loop in an uncontrolled way.
logger.warn("Discovery AcceptorThread error", e);
}
}
}
private void drainInputQueues() throws InterruptedException {
do {
drainAcceptorQueue();
if (!isShutdown.get()) {
// If all queues are empty, block for a while on the acceptor queue
if (reprocessQueue.isEmpty() && acceptorQueue.isEmpty() && pendingTasks.isEmpty()) {
TaskHolder<ID, T> taskHolder = acceptorQueue.poll(10, TimeUnit.MILLISECONDS);
if (taskHolder != null) {
appendTaskHolder(taskHolder);
}
}
}
} while (!reprocessQueue.isEmpty() || !acceptorQueue.isEmpty() || pendingTasks.isEmpty());
}
private void drainAcceptorQueue() {
while (!acceptorQueue.isEmpty()) {
// 将acceptor队列中的数据放入到processingOrder队列中去,方便后续拆分成batch
appendTaskHolder(acceptorQueue.poll());
}
}
private void appendTaskHolder(TaskHolder<ID, T> taskHolder) {
if (isFull()) {
pendingTasks.remove(processingOrder.poll());
queueOverflows++;
}
TaskHolder<ID, T> previousTask = pendingTasks.put(taskHolder.getId(), taskHolder);
if (previousTask == null) {
processingOrder.add(taskHolder.getId());
} else {
overriddenTasks++;
}
}
}
认真跟这里面的代码,可以看到这里是将上面的acceptorQueue放入到processingOrder, 其中processingOrder也是一个队列。
在AcceptorRunner.java的run()方法中,还会调用assignBatchWork()方法,这里面就是将processingOrder打成一个个batch,接着看代码:
void assignBatchWork() {
if (hasEnoughTasksForNextBatch()) {
if (batchWorkRequests.tryAcquire(1)) {
long now = System.currentTimeMillis();
int len = Math.min(maxBatchingSize, processingOrder.size());
List<TaskHolder<ID, T>> holders = new ArrayList<>(len);
while (holders.size() < len && !processingOrder.isEmpty()) {
ID id = processingOrder.poll();
TaskHolder<ID, T> holder = pendingTasks.remove(id);
if (holder.getExpiryTime() > now) {
holders.add(holder);
} else {
expiredTasks++;
}
}
if (holders.isEmpty()) {
batchWorkRequests.release();
} else {
batchSizeMetric.record(holders.size(), TimeUnit.MILLISECONDS);
// 将批量数据放入到batchWorkQueue中
batchWorkQueue.add(holders);
}
}
}
}
private boolean hasEnoughTasksForNextBatch() {
if (processingOrder.isEmpty()) {
return false;
}
// 默认maxBufferSize为250
if (pendingTasks.size() >= maxBufferSize) {
return true;
}
TaskHolder<ID, T> nextHolder = pendingTasks.get(processingOrder.peek());
// 默认maxBatchingDelay为500ms
long delay = System.currentTimeMillis() - nextHolder.getSubmitTimestamp();
return delay >= maxBatchingDelay;
}
这里加入batch的规则是:maxBufferSize 默认为250
maxBatchingDelay 默认为500ms,打成一个个batch后就开始发送给server端。至于怎么发送 我们接着看 PeerEurekaNode.java, 我们在最开始调用register() 方法就是调用PeerEurekaNode.register(), 我们来看看它的构造方法:
PeerEurekaNode(PeerAwareInstanceRegistry registry, String targetHost, String serviceUrl,
HttpReplicationClient replicationClient, EurekaServerConfig config,
int batchSize, long maxBatchingDelayMs,
long retrySleepTimeMs, long serverUnavailableSleepTimeMs) {
this.registry = registry;
this.targetHost = targetHost;
this.replicationClient = replicationClient;
this.serviceUrl = serviceUrl;
this.config = config;
this.maxProcessingDelayMs = config.getMaxTimeForReplication();
String batcherName = getBatcherName();
ReplicationTaskProcessor taskProcessor = new ReplicationTaskProcessor(targetHost, replicationClient);
this.batchingDispatcher = TaskDispatchers.createBatchingTaskDispatcher(
batcherName,
config.getMaxElementsInPeerReplicationPool(),
batchSize,
config.getMaxThreadsForPeerReplication(),
maxBatchingDelayMs,
serverUnavailableSleepTimeMs,
retrySleepTimeMs,
taskProcessor
);
}
这里会实例化一个ReplicationTaskProcessor.java, 我们跟进去,发下它是实现TaskProcessor的,所以一定会执行此类中的process()方法,执行方法如下:
public ProcessingResult process(List<ReplicationTask> tasks) {
ReplicationList list = createReplicationListOf(tasks);
try {
EurekaHttpResponse<ReplicationListResponse> response = replicationClient.submitBatchUpdates(list);
int statusCode = response.getStatusCode();
if (!isSuccess(statusCode)) {
if (statusCode == 503) {
logger.warn("Server busy (503) HTTP status code received from the peer {}; rescheduling tasks after delay", peerId);
return ProcessingResult.Congestion;
} else {
// Unexpected error returned from the server. This should ideally never happen.
logger.error("Batch update failure with HTTP status code {}; discarding {} replication tasks", statusCode, tasks.size());
return ProcessingResult.PermanentError;
}
} else {
handleBatchResponse(tasks, response.getEntity().getResponseList());
}
} catch (Throwable e) {
if (isNetworkConnectException(e)) {
logNetworkErrorSample(null, e);
return ProcessingResult.TransientError;
} else {
logger.error("Not re-trying this exception because it does not seem to be a network exception", e);
return ProcessingResult.PermanentError;
}
}
return ProcessingResult.Success;
}
这里面是将List<ReplicationTask> tasks 通过submitBatchUpdate() 发送给server端。
server端在PeerReplicationResource.batchReplication()去处理,实际上就是循环调用ApplicationResource.addInstance() 方法,又回到了最开始注册的方法。
到此 EurekaServer同步的逻辑就结束了,这里主要是三层队列的数据结构很绕,通过一个batchList去批量同步数据的。
注意这里还有一个很重要的点,就是Client注册时调用addInstance()方法,这里到了server端PeerAwareInstanceRegistryImpl会执行同步其他EurekaServer逻辑。
而EurekaServer同步注册接口仍然会调用addInstance()方法,这里难不成就死循环调用了?当然不是,addInstance()中也有个参数:isReplication, 在最后调用server端方法的时候如下:registry.register(info, "true".equals(isReplication));
我们知道,EurekaClient在注册的时候isReplication传递为空,所以这里为false,而Server端同步的时候调用:
PeerReplicationResource:
private static Builder handleRegister(ReplicationInstance instanceInfo, ApplicationResource applicationResource) {
applicationResource.addInstance(instanceInfo.getInstanceInfo(), REPLICATION);
return new Builder().setStatusCode(Status.OK.getStatusCode());
}
这里的REPLICATION 为true
另外在AbstractJersey2EurekaHttpClient中发送register请求的时候,有个addExtraHeaders()方法,如下图:

如果是使用的Jersey2ReplicationClient发送的,那么header中的x-netflix-discovery-replication配置则为true,在后面执行注册的addInstance()方法中会接收这个参数的:
总结
仍然一图流,文中解析的内容都包含在这张图中了:
申明
本文章首发自本人博客:https://www.cnblogs.com/wang-meng 和公众号:壹枝花算不算浪漫,如若转载请标明来源!
感兴趣的小伙伴可关注个人公众号:壹枝花算不算浪漫
