原文地址:https://dblab.xmu.edu.cn/blog/290-2/
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核心组件之一,如果已经安装了Hadoop,其中就已经包含了HDFS组件,不需要另外安装。
在学习HDFS编程实践前,执行如下命令,启动Hadoop。

一、利用Shell命令与HDFS进行交互
Hadoop支持很多Shell命令,其中fs是HDFS最常用的命令,利用fs可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。
有三种shell命令方式。
1. hadoop fs 适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
2. hadoop dfs 只能适用于HDFS文件系统
3. hdfs dfs 只能适用于HDFS文件系统
我们可以在终端输入如下命令,查看fs总共支持了哪些命令

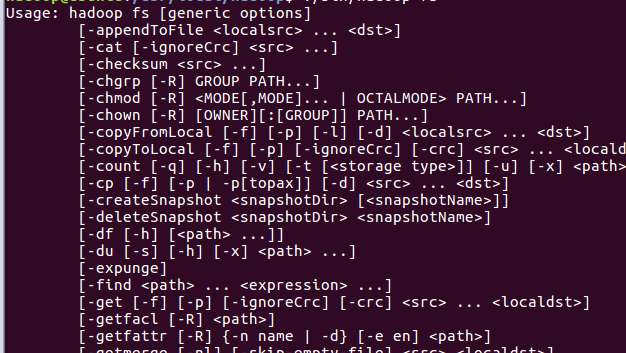
1.目录操作
需要注意的是,Hadoop系统安装好以后,第一次使用HDFS时,需要首先在HDFS中创建用户目录。本教程全部采用hadoop用户登录Linux系统,因此,需要在HDFS中为hadoop用户创建一个用户目录,命令如下:

该命令中表示在HDFS中创建一个“/user/hadoop”目录,“–mkdir”是创建目录的操作,“-p”表示如果是多级目录,则父目录和子目录一起创建,这里“/user/hadoop”就是一个多级目录,因此必须使用参数“-p”,否则会出错。
“/user/hadoop”目录就成为hadoop用户对应的用户目录,可以使用如下命令显示HDFS中与当前用户hadoop对应的用户目录下的内容:


该命令中,“-ls”表示列出HDFS某个目录下的所有内容,“.”表示HDFS中的当前用户目录,也就是“/user/hadoop”目录,因此,上面的命令和下面的命令是等价的:

如果要列出HDFS上的所有目录,可以使用如下命令:

下面,可以使用如下命令创建一个input目录:


在创建input目录时,采用了相对路径形式,实际上,这个input目录创建成功以后,它在HDFS中的完整路径是“/user/hadoop/input”。
如果要在HDFS的根目录下创建一个名称为input的目录,则需要使用如下命令:

可以使用rm命令删除一个目录,比如,可以使用如下命令删除刚才在HDFS中创建的“/input”目录(不是“/user/hadoop/input”目录):

上面命令中,“-r”参数表示如果删除“/input”目录及其子目录下的所有内容,如果要删除的一个目录包含了子目录,则必须使用“-r”参数,否则会执行失败。
2.文件操作
在实际应用中,经常需要从本地文件系统向HDFS中上传文件,或者把HDFS中的文件下载到本地文件系统中。
首先,使用vim编辑器,在本地Linux文件系统的“~/hadoop/”目录下创建一个文件myLocalFile.txt,里面可以随意输入一些单词,比如,输入如下三行:

然后,可以使用如下命令把本地文件系统的“~/hadoop/myLocalFile.txt”上传到HDFS中的当前用户目录的input目录下,也就是上传到HDFS的“/user/hadoop/input/”目录下:


可以使用ls命令查看一下文件是否成功上传到HDFS中,具体如下:

下面使用如下命令查看HDFS中的myLocalFile.txt这个文件的内容:

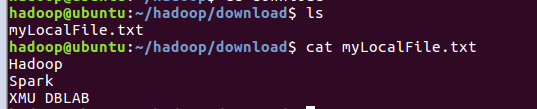
下面把HDFS中的myLocalFile.txt文件下载到本地文件系统中的“~/hadoop/download/”这个目录下,命令如下:


可以使用如下命令,到本地文件系统查看下载下来的文件myLocalFile.txt:
最后,了解一下如何把文件从HDFS中的一个目录拷贝到HDFS中的另外一个目录。比如,如果要把HDFS的“/user/hadoop/input/myLocalFile.txt”文件,拷贝到HDFS的另外一个目录“/input”中(注意,这个input目录位于HDFS根目录下),可以使用如下命令:


二、利用Web界面管理HDFS
打开Linux自带的Firefox浏览器,点击此链接 http://localhost:50070 ,即可看到HDFS的web管理界面。

三、利用Java API与HDFS进行交互
Hadoop不同的文件系统之间通过调用Java API进行交互,上面介绍的Shell命令,本质上就是Java API的应用。下面提供了Hadoop官方的Hadoop API文档,想要深入学习Hadoop,可以访问如下网站,查看各个API的功能。
http://hadoop.apache.org/docs/stable/api/
(一) 在Ubuntu中安装Eclipse
选择“File->New->Java Project”菜单,开始创建一个Java工程,
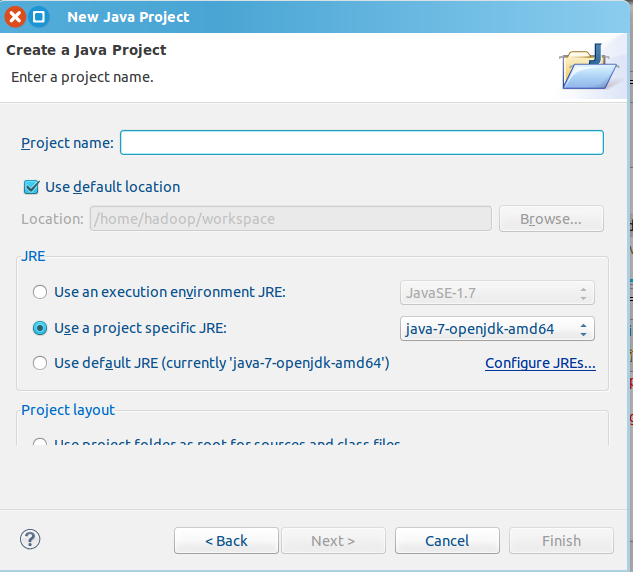
在“Project name”后面输入工程名称“HDFSExample”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/HDFSExample”目录下。
在“JRE”这个选项卡中,可以选择当前的Linux系统中已经安装好的JDK,比如java-7-openjdk-amd64。然后,点击界面底部的“Next>”按钮,进入下一步的设置。(二)为项目添加需要用到的JAR包

需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了可以访问HDFS的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下,对于本教程而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮,
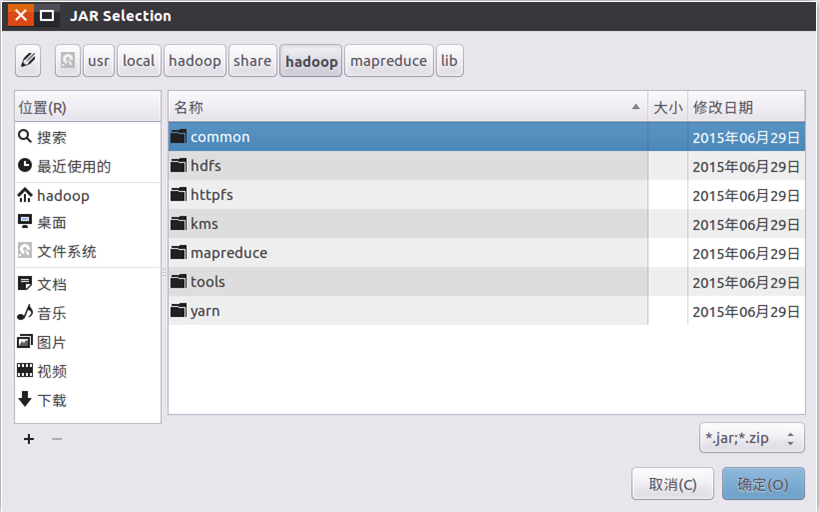
在该界面中,上面的一排目录按钮(即“usr”、“local”、“hadoop”、“share”、“hadoop”、“mapreduce”和“lib”),当点击某个目录按钮时,就会在下面列出该目录的内容。
为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)”/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar;
(2)/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的haoop-hdfs-2.7.1.jar和haoop-hdfs-nfs-2.7.1.jar;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
全部添加完毕以后,就可以点击界面右下角的“Finish”按钮,完成Java工程HDFSExample的创建。