元组,集合,字符串操作 字符编码:
元组
跟列表是一样的,存数据的,但是他是只读列表,不可更改
name =("aaa","bbb")
dir(name)#把传入的数据类型 的所有方式以列表的型 式返回
help(name)
元组的作用
n2 = list(name)元组转成列表
tuple(n2) 列表转成元组
##################################################
集合
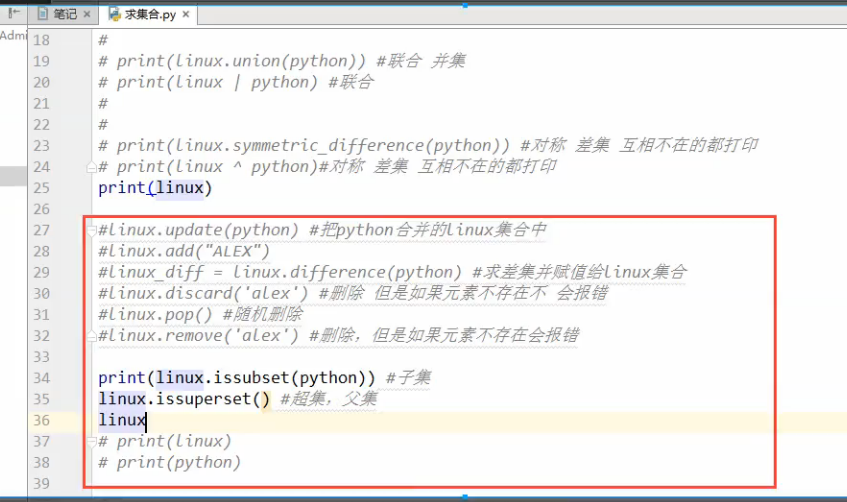
重要的作用就是关系测试
集合也是无序的
判断成员是否在集合用in 方法
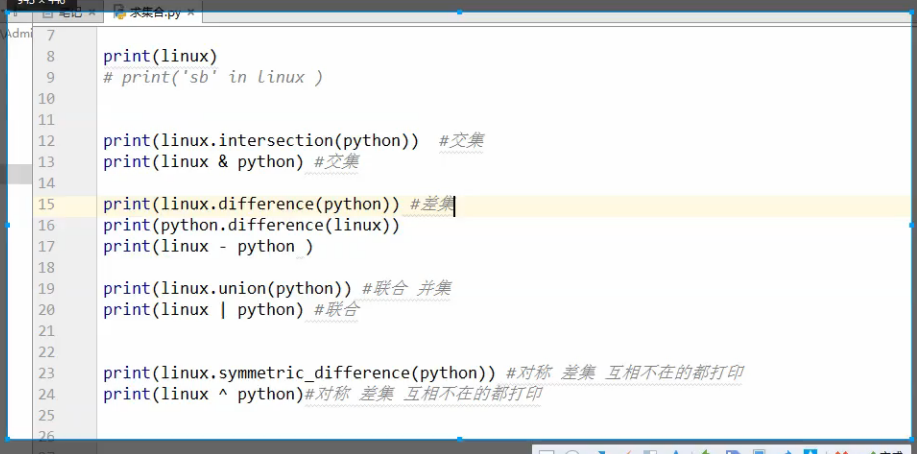
交集 两个都有,
差集 列表A有,B没有
并集把两个列表里的元素合并到一起,去重
重要功能,天然去重
name = {"a","b"}

######################################################################
字符串操作
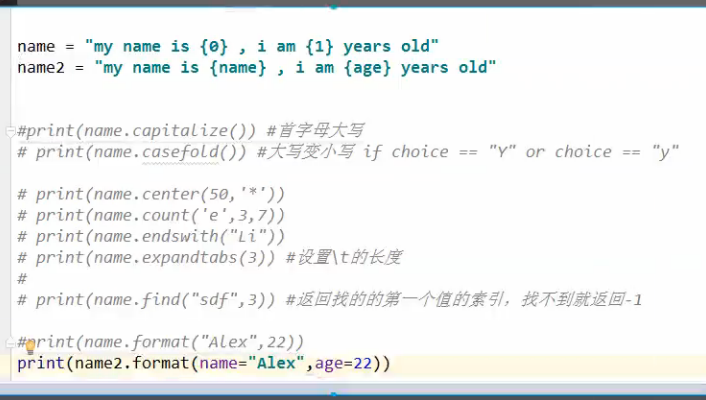


常用

name = " Wqn ggang oei"
# print(name.center(18,'*'))#字符串如果不够这个长度,两边用给的字符串填充
# print(name.strip())#字符串两边脱掉指定的字符,默认为空格,tab,换行
# print(name.count('w'))#查找字符在字符串中出现多少次
# print(name.find('w',6,9))#从起始查找字符,不存在返回-1
# print(name.lower())#变小写
# print(name.upper())#变大写
# print('****'.join(['a', 'b', 'c']))#a****b****c
# print('#'.join(name))## # # #W#q#n# #g#g#a#n#g# #o#e#i
print(name.split('ggang'))#[' Wqn ', ' oei']
print(name.endswith('oei'))#True以给定的为结尾,真为true
print(name.startswith('',0,6))#判断开始
print(name.replace('w','W'))#替换
print(name.index('w')) #找到某字母的下标,
##########################



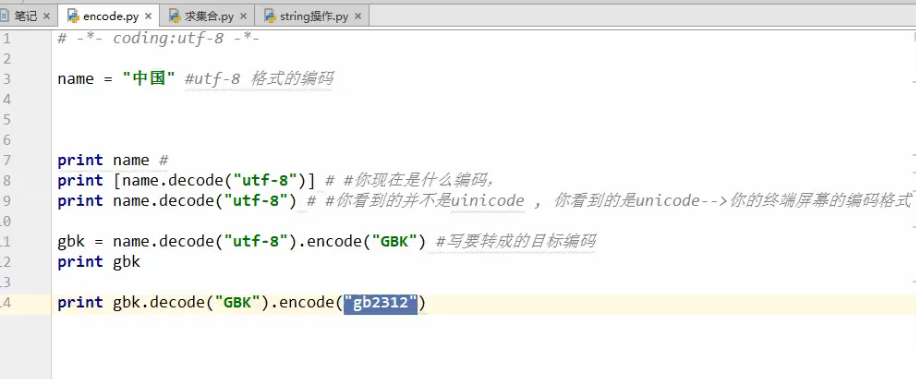
字符编码:
python2的默认编码是AsCii,如果你没指定编码格式的话
./yourpy.py 必须在文件头声明解释器
python x.py不需要,因为python就是解释器
###########################################################################
三元运算
16进制
Oct() 转成8进制
hex() 转成16进制
元组
跟列表一样一样的
但它是只读列表
dir() 把传入的数据类型的 所有方法以列表的形式返回
TypeError: 'tuple' object does not support item assignment
类型错误 元组 对象 不支持 元素 指定
作用?
明确的表示 元组里存储的数据是不应该被修改的
list( tuple元组) 变成列表
tuple(list列表) 变成元组
集合 set
关系测试
交集 两个都有
差集 在列表a里有,b里没有
并集 把两个列表里 的元素 合并在一起 ,去重
去重,天然去重
无序的
string
strip
center
count
find
lower ? casefold
upper
join
split
endwith
startwith
replace
index
字符编码
ASCII 英文
GB2312 1980
GBK 1995
GB18030
1990 unicode
utf-8
japan
JK3000
windows GBK
GBK
把JK3000 转成 GBK
翻译官 unicode
python 2
SyntaxError: Non-ASCII character 'xe4' in file encode.py on line 3,
but no encoding编码 declared声明; see http://python.org/dev/peps/pep-0263/ for details详细
Python will default to ASCII as standard encoding if no other encoding hints are given.
python2的默认编码是ASCII, 如果你没指定编码格式的话
./yourpy.py #必须在文件头声明 解释器
Python yourpy.py 不需要声明解释器
[u'u4e2du56fd'] #uicode
如果内存里都是unicode的话? 还会有乱码的问题么?
python3
所有字符在内存里都是unicode
解释器读取文件的默认编码是utf-8
但是有个文件,编码是gbk, 读到内存里,还是需要解码
数据类型
str # 它只是一种人类可读的抽象的表示形式
int
float
bool
list
tuple
dict
set
bytes 字节类型(二进制类型), 就是一个8bits的字节
所有的字符要存到内存里,硬盘里,都是bytes格式
在py2里,你看到的字符串,就是bytes str == bytes
str == bytes
unicode
在py3里
str == unicode
bytes == bytes
数据存到硬盘上,或者网络发送, 都必须是bytes 格式。。。
三级菜单优化版
