package com.swust.java.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class SparkTest {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("wordCount");
conf.setMaster("local");
JavaSparkContext jsc = new JavaSparkContext(conf);
jsc.setLogLevel("Error");
String inpath = "./data/csvdata.csv";
JavaRDD<String> lines = jsc.textFile(inpath);
//2011-07-13 00:00:00+08,352024,29448-51331,0,0,0,0,0,G,0
//0 1 2 3 4 5 6 7 8 9
//record_time,imei,cell,ph_num,call_num,drop_num,duration,drop_rate,net_type,erl
/**
* record_time:通话时间
* imei:基站编号
* cell:手机编号
* drop_num:掉话的秒数
* duration:通话持续总秒数
*/
// 1 5 6
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
//StringBuffer sb = new StringBuffer();
String[] ls = line.split(",");
if(!ls[0].equals("2011-07-13 00:00:00+08")){
ls[1]="352024";
ls[5]="0";
ls[6]="0";
}
String wd=ls[1]+" "+ls[5]+" "+ls[6];
return Arrays.asList(wd).iterator();
}
});
// List<String> test = words.take(5);
// System.out.println(test);
JavaPairRDD<String, String> wordPairs = words.mapToPair(new PairFunction<String, String, String>() {
@Override
public Tuple2<String, String> call(String line) throws Exception {
String[] words = line.split(" ");
String key = words[0];
String value = words[1] + " " + words[2];
Tuple2<String, String> tp = new Tuple2<>(key, value);
return tp;
}
});
JavaPairRDD<String, String> res = wordPairs.reduceByKey(new Function2<String, String, String>() {
@Override
public String call(String value1, String value2) throws Exception {
String[] v1 = value1.split(" ");
String[] v2 = value2.split(" ");
Double drop1 = Double.parseDouble(v1[0]);
Double drop2 = Double.parseDouble(v2[0]);
Double sum1 = Double.parseDouble(v1[1]);
Double sum2 = Double.parseDouble(v2[1]);
return (drop1 + drop2) + " " + (sum1 + sum2);
}
});
// System.out.println(res.take(3));
JavaPairRDD<String, Double> result = res.mapToPair(new PairFunction<Tuple2<String, String>, String, Double>() {
@Override
public Tuple2<String, Double> call(Tuple2<String, String> text) throws Exception {
String key = text._1;
String[] splits = text._2.split(" ");
Double drop = Double.parseDouble(splits[0]);
Double sum = Double.parseDouble(splits[1]);
Double value = 0.0;
if (sum != 0.0) {
value = drop / sum;
}
Tuple2<String, Double> tp2 = new Tuple2<>(key, value);
return tp2;
}
});
JavaPairRDD<Double, String> rest = result.mapToPair(new PairFunction<Tuple2<String, Double>, Double, String>() {
@Override
public Tuple2<Double, String> call(Tuple2<String, Double> tp) throws Exception {
return tp.swap();
}
});
JavaPairRDD<Double, String> resort = rest.sortByKey(false);
JavaPairRDD<String, Double> trueResult = resort.mapToPair(new PairFunction<Tuple2<Double, String>, String, Double>() {
@Override
public Tuple2<String, Double> call(Tuple2<Double, String> tp) throws Exception {
return tp.swap();
}
});
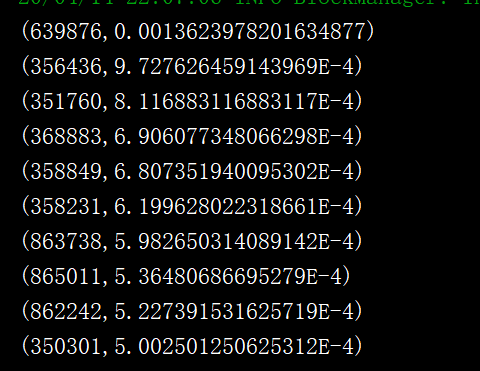
List<Tuple2<String, Double>> ts = trueResult.take(10);
Iterator<Tuple2<String, Double>> iterator = ts.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
基站掉话率:找出掉线率最高的前10基站
record_time:通话时间
imei:基站编号
cell:手机编号
drop_num:掉话的秒数
duration:通话持续总秒数