GAN的原始损失函数,咋一看是非常难以理解的,但仔细理解后就会发现其简洁性和丰富的含义。
损失函数定义:
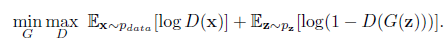
一切损失计算都是在D(判别器)输出处产生的,而D的输出一般是fake/true的判断,所以整体上采用的是二进制交叉熵函数。
左边包含两部分minG和maxD。
首先看一下maxD部分,因为训练一般是先保持G(生成器)不变训练D的。D的训练目标是正确区分fake/true,如果我们以1/0代表true/fake,则对第一项E因为输入采样自真实数据所以我们期望D(x)趋近于1,也就是第一项更大。同理第二项E输入采样自G生成数据,所以我们期望D(G(z))趋近于0更好,也就是说第二项又是更大。所以是这一部分是期望训练使得整体更大了,也就是maxD的含义了。
第二部分保持D不变,训练G,这个时候只有第二项E有用了,关键来了,因为我们要迷惑D,所以这时将label设置为1(我们知道是fake,所以才叫迷惑),希望D(G(z))输出接近于1更好,也就是这一项越小越好,这就是minG。当然判别器哪有这么好糊弄,所以这个时候判别器就会产生比较大的误差,误差会更新G,那么G就会变得更好了,这次没有骗过你,只能下次更努力了。
大概就是这样一个博弈过程了。自娱自乐,高手刷到请略过。
代码参考:50行代码实现GAN-pytorch。