转自:http://www.codelast.com/?p=8052
牛顿法是最优化领域的经典算法,它在寻优的过程中,使用了目标函数的二阶导数信息,具体说来就是:用迭代点的梯度和二阶导数对目标函数进行二次逼近,把二次函数的极小点作为新的迭代点,不断重复此过程,直到找到最优点。
『1』历史
话说,牛顿法为什么叫牛顿法?这个近乎“废话”的问题,谁又真正查过?
Wiki里是这样写的:牛顿法(Newton's method)是一种近似求解方程的方法,它使用函数f(x)的泰勒级数的前面几项来寻找方程f(x)=0的根。
它最初由艾萨克•牛顿在《流数法》(Method of Fluxions,1671年完成,在牛顿死后的1736年公开发表)。
按我的理解,起初牛顿法和最优化没什么关系(在那个年代应该还没有最优化这门学科分支),但是在最优化研究兴起后,人们把牛顿法的思想应用在最优化领域,于是也就叫它牛顿法了。
『2』原理
下面我们就来推导一下牛顿法的实现。
目标函数
其中,
文章来源:http://www.codelast.com/
由此便可得到迭代公式:
在最优化line search的过程中,下一个点是由前一个点在一个方向d上移动得到的,因此,在牛顿法中,人们就顺其自然地称这个方向为“牛顿方向”,由上面的式子可知其等于:
『3』优缺点
优点:充分接近极小点时,牛顿法具有二阶收敛速度——挺好的,不是么。
缺点:
①牛顿法不是整体收敛的。
②每次迭代计算
③线性方程组
(注:在代数方程中,有的多项式系数有微小扰动时其根变化很大,这种根对系数变化的敏感性称为不稳定性(instability),这种方程就是病态多项式方程)
为了解决“原始”牛顿法的这些问题,人们想出了各种办法,于是就有了下面的各种改进方案,请听我一一道来。
文章来源:http://www.codelast.com/
『4』牛顿法的改进1——阻尼牛顿法
前面说过了,牛顿法不是整体收敛的,在远离最优解时,牛顿方向
我觉得“阻力”这个词还是比较形象的——原来只有一个
问题是,
可以在确定
满足了这个条件,会发生什么?
大家还记得《使用一维搜索(line
search)的算法的收敛性》定理吗?仔细看里面的“适用于使用精确line search技术的算法”的收敛性定理,你就会发现,当满足了上面所说的条件时,(阻尼)牛顿法的整体收敛性就得到了保证。
当然,满足上面所说的条件的前提,就是所有的
文章来源:http://www.codelast.com/
那么问题就来了:阻尼牛顿法确实offer了整体收敛性,但是它并没有解决一个问题:
『5』Goldstein-Price修正
首先,Goldstein和Price是两个人名,他们的具体生平事迹我没研究过。他们在1967年提出,如果
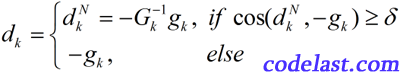
其中,
在这样的条件下,就使得
文章来源:http://www.codelast.com/
『6』Goldfeld修正
与上面的Goldstein-Price修正的思路不同,Goldfeld在1966年也提出了一种方法,他的方法虽然还是在搜索方向
其中,
具体要满足什么条件呢?一个关于矩阵
Goldfeld修正没有解决的问题就是:难以给出选取
文章来源:http://www.codelast.com/
『7』Gill-Murray的Cholesky分解法
看到这个小标题你可能就有点晕——请尽情地晕吧,这里光是人名就有三个。最重要的就是Cholesky,这里我要补充一个小插曲,给大家说点轻松的知识(从网上复制来的,链接不记得了):
Cholesky是一个法国数学家,生于19世纪末。Cholesky分解是他在学术界最重要的贡献。后来,Cholesky参加了法国军队,不久在一战初始阵亡。
Cholesky分解是一种分解矩阵的方法, 在线性代数中有重要的应用。Cholesky分解把矩阵分解为一个下三角矩阵以及它的共轭转置矩阵的乘积(那实数界来类比的话,此分解就好像求平方根)。与一般的矩阵分解求解方程的方法比较,Cholesky分解效率很高。
Gill和Murray这两个人,用Cholesky分解法实现了对牛顿法的改进,我个人觉得,他们的改进可以算是对Goldfeld修正的一种改进(或补充)吧,因为他们提供了求
这里的Cholesky分解(牛顿法),是这么一回事:对
文章来源:http://www.codelast.com/
至于这个修正过程的具体做法,我只能说我不甚清楚,我不想在这里误导大家,只想把我自己理解的写下来:
若
若
如果
我感觉上面的修正过程,用妹子来做一个比喻就是:一个妹子本来已经长得挺漂亮了,你为她化个妆(只要不是故意黑她),她还是那么漂亮。反之,如果一个妹子长得很搓,那么,你为她化妆,是有可能让她看上去变靓的。总之,都得到了我们想要的结果。
Cholesky分解算法我没看过,这里就没办法说了。
有书上说,Gill-Murray的Cholesky分解牛顿法是“对牛顿法改造得最彻底、最有实用价值的方法”。
看来,有时候真的是:最复杂的就是最好的,没有捷径可走啊。
文章来源:http://www.codelast.com/
『8』信赖域牛顿法
在这篇解释信赖域算法的文章里,我们说过了,信赖域算法具有整体收敛性。利用这一点,可以将其与牛顿法“合体”,创造出具有整体收敛性的信赖域牛顿法,即,我们要求的问题是:
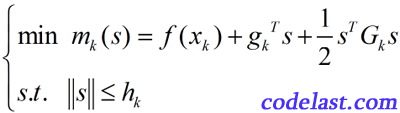
其中,
为什么它叫信赖域牛顿法?首先,它没有line search,求的是位移s,所以是一种信赖域算法;其次,它在求解的时候用到了梯度和二阶导数,因此是一种牛顿法。所以整体上叫它信赖域牛顿法是讲得过去的。
信赖域牛顿法有一个特点是令人欣慰的:没有要求
至于信赖域算法的具体求解步骤是怎样的,这里就不说了,还是请大家参考这篇文章。
文章来源:http://www.codelast.com/
『9』总结
对牛顿法及其众多改进的介绍就到这里结束了。大家会看到,里面有很多定理没给出证明,有些推导可能也不够严谨,但是它们的结论基本上是正确的,如果纠结于细节,那真的是要去做理论研究,而不是应用到工程实践了。所以,学习最优化的时候,我们可以在一定程度上“着眼全局,忽略细节”,这会极大地有助于理解。