通过hadoop自带的demo运行单词统计(测试)
在家目录下操作:
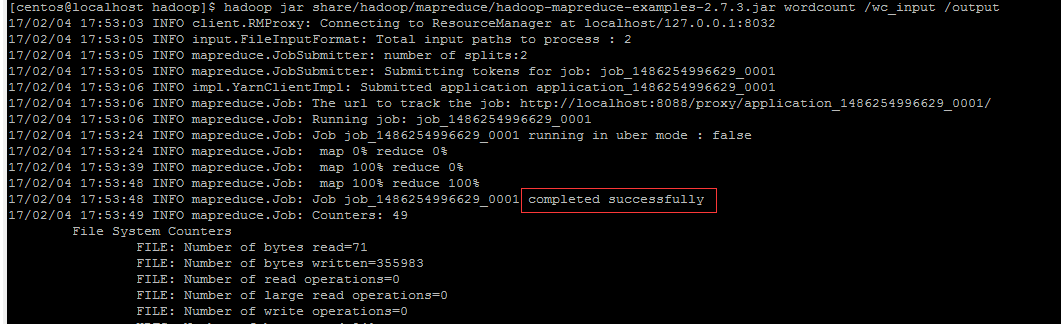
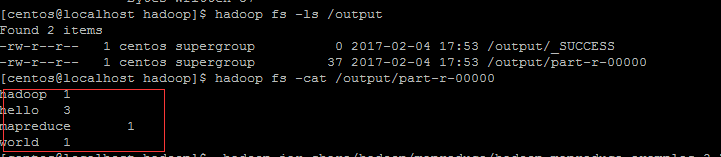
1)mkdir input 2)cd intput 3)echo “hello word” > file1.txt 4)echo “hello hadoop” > file2.txt 5)echo “hello mapreduce” >> file2.txt 6) more file2.txt 7) hadoop fs -mkdir /wc_input 8) hadoop fs -ls / 9) hadoop fs -put ~/input/fi* /wc_input 10)hadoop fs -ls /wc_input 11) hadoop jar /soft/wang/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /wc_input /output(输出目录不能提前存在) 12)hadoop fs -ls /output 13)hadoop fs -text /output/part-r-00000
执行结果截图: