1 可变类型和不可变类型
部分参考博客:https://www.cnblogs.com/blackmatrix/p/5614086.html
1 可变类型
列表 字典 可变集合
2 不可变类型
数字 元组 字符串 不可变集合
3 可变不可变的区别
''' 当进行修改操作时,可变类型传递的是内存中的地址,也就是说,直接修改内存中的值,并没有开辟新的内存 不可变类型被改变时,并没有改变原内存地址中的值,而是开辟一块新的内存,将原地址中的值复制过去,对这块新开辟的内存中的值进行操作 对不可变类型的变量重新赋值,实际上是重新创建一个不可变类型的对象,并将原来的变量重新指向新创建的对象(如果没有其他变量引用原有对象的话(即引用计数为0), 原有对象就会被回收) '''
4 不可变类型案例
注意
不可变类型
以int类型为例:实际上 i += 1 并不是真的在原有的int对象上+1,而是重新创建一个value为6的int对象,i引用自这个新的对象。
i = 5 i += 1 print(i)
通过id函数查看变量i的内存地址进行验证
>>> i = 5 >>> i += 1 >>> i 6 >>> id(i) 140243713967984 >>> i += 1 >>> i 7 >>> id(i) 140243713967960
可以看到执行 i += 1 时,内存地址都会变化,因为int 类型是不可变的。
再改改代码,但多个int类型的变量值相同时,看看它们内存地址是否相同。
>>> i = 5 >>> j = 5 >>> id(i) 140656970352216 >>> id(j) 140656970352216 >>> k = 5 >>> id(k)
对于不可变类型int,无论创建多少个不可变类型,只要值相同,都指向同个内存地址。同样情况的还有比较短的字符串。
对于其他类型则不同,以浮点类型为例,从代码运行结果可以看出它是个不可变类型:对i的值进行修改后,指向新的内存地址。
>>> i = 1.5
>>> id(i)
140675668569024
>>> i = i + 1.7
>>> i
3.2
>>> id(i)
140675668568976
修改代码声明两个相同值的浮点型变量,查看它们的id,发现它们并不是指向同个内存地址,这点和int类型不同(这方面涉及Python内存管理机制,Python对int类型和较短的字符串进行了缓存,无论声明多少个值相同的变量,实际上都指向同个内存地址。)。
>>> i = 2.5 >>> id(i) 140564351733040 >>> j = 2.5 >>> id(j) 140564351733016
5 可变类型案例
以list为例。list在append之后,还是指向同个内存地址,因为list是可变类型,可以在原处修改。
a = [1, 2, 3] print(id(a)) a.append(4) print(id(a)) # 140117557567176 # 140117557567176
改改代码,当存在多个值相同的不可变类型变量时,看看它们是不是跟可变类型一样指向同个内存地址
>>> id(a)
4435060856
>>> b = [1, 2, 3]
>>> id(b)
4435102392
从运行结果可以看出,虽然a、b的值相同,但是指向的内存地址不同。我们也可以通过b = a 的赋值语句,让他们指向同个内存地址:
>>> a = [1, 2, 3] >>> id(a) 4435060856 >>> b = [1, 2, 3] >>> id(b) 4435102392 >>> b = a >>> id(b) 4435060856
这个时候需要注意,因为a、b指向同个内存地址,而a、b的类型都是List,可变类型,对a、b任意一个List进行修改,都会影响另外一个List的值。
>>> b.append(4) >>> a [1, 2, 3, 4] >>> b [1, 2, 3, 4] >>> id(a) 4435060856 >>> id(b) 4435060856
2 深浅拷贝
参考博客:https://www.cnblogs.com/where1-1/p/12657715.html
1 浅拷贝
拷贝规则:
- 如果被拷贝对象是不可变对象,则不会生成新的对象
- 如果被拷贝对象是可变对象,则会生成新的对象,但是只会对可变对象最外层进行拷贝
import copy a = 4343.23 # 不可变类型 b = copy.copy(a) print(id(a)) print(id(b)) ''' 140406918152552 140406918152552 '''
上面的代码对一个float类型的数据进行了浅拷贝,根据规则,不会生成新的对象,因此a,b两个变量的内存地址是相同的。
下面是一个可变对象的拷贝示例
import copy a = [1, [1]] b = copy.copy(a) print(id(a), id(b)) print(id(a[1]), id(b[1])) '''47391206484387519880
4739160904 4739160904'''
a和b的内存地址是不相同的,说明生成了一个新的数据,但由于是浅拷贝,因此列表里的元素并不进行拷贝,只对最外层进行了拷贝。
通过对内存的观察,我们可以更清楚了解浅拷贝的过程,下图是浅拷贝之前的内存示意图
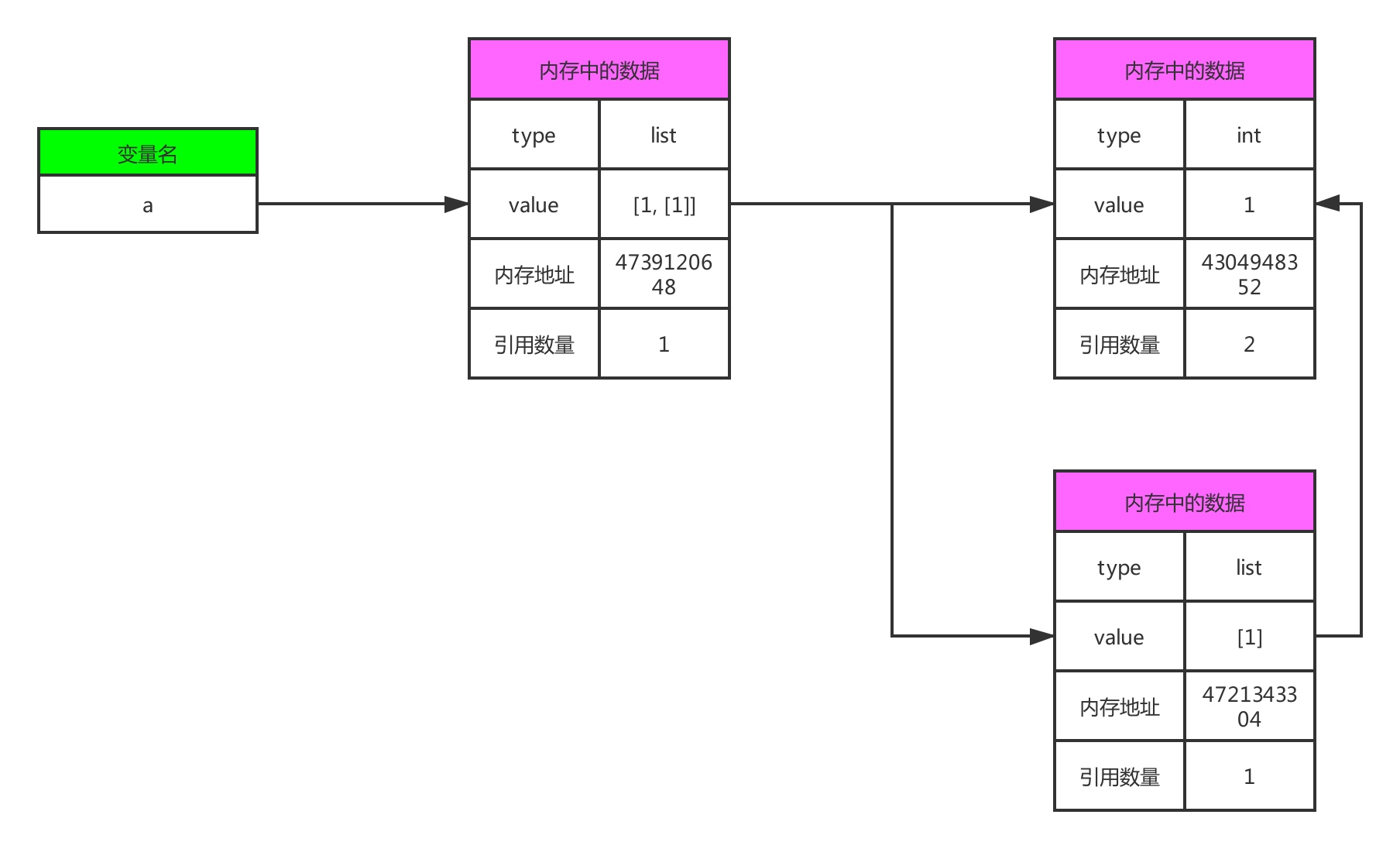
浅拷贝发生之后,内存变成如下图所示

为了便于识别,我特地将代表引用的线条加粗并加上颜色来区分,通过对比浅拷贝前后的示意图,你可以看到,仅仅生成了一个新的对象,地址是4350709128。
a[1], b[1] 的数据类型是列表,是可变对象,他们的内存地址相同,因此,对b[1]的操作,将会影响到a[1]
import copy a = [1, [1]] b = copy.copy(a) b[1].append(2) print(a)
程序输出结果
[1, [1, 2]]
2. 深拷贝
拷贝规则:
- 如果被拷贝对象是不可变对象,深拷贝不会生成新对象,因为被拷贝对象是不可变的,继续用原来的那个,不会产生什么坏的影响
- 如果被拷贝对象是可变对象,那么会彻底的创建出一个和被拷贝对象一模一样的新对象
import copy a = [1, [1]] b = copy.deepcopy(a) print(id(a), id(b)) print(id(a[1]), id(b[1]))
程序输出结果
4739124744 4350819720 4739165000 4739236104
为了清晰的理解深拷贝的作用,还是放上拷贝前后的内存对比图
深拷贝前
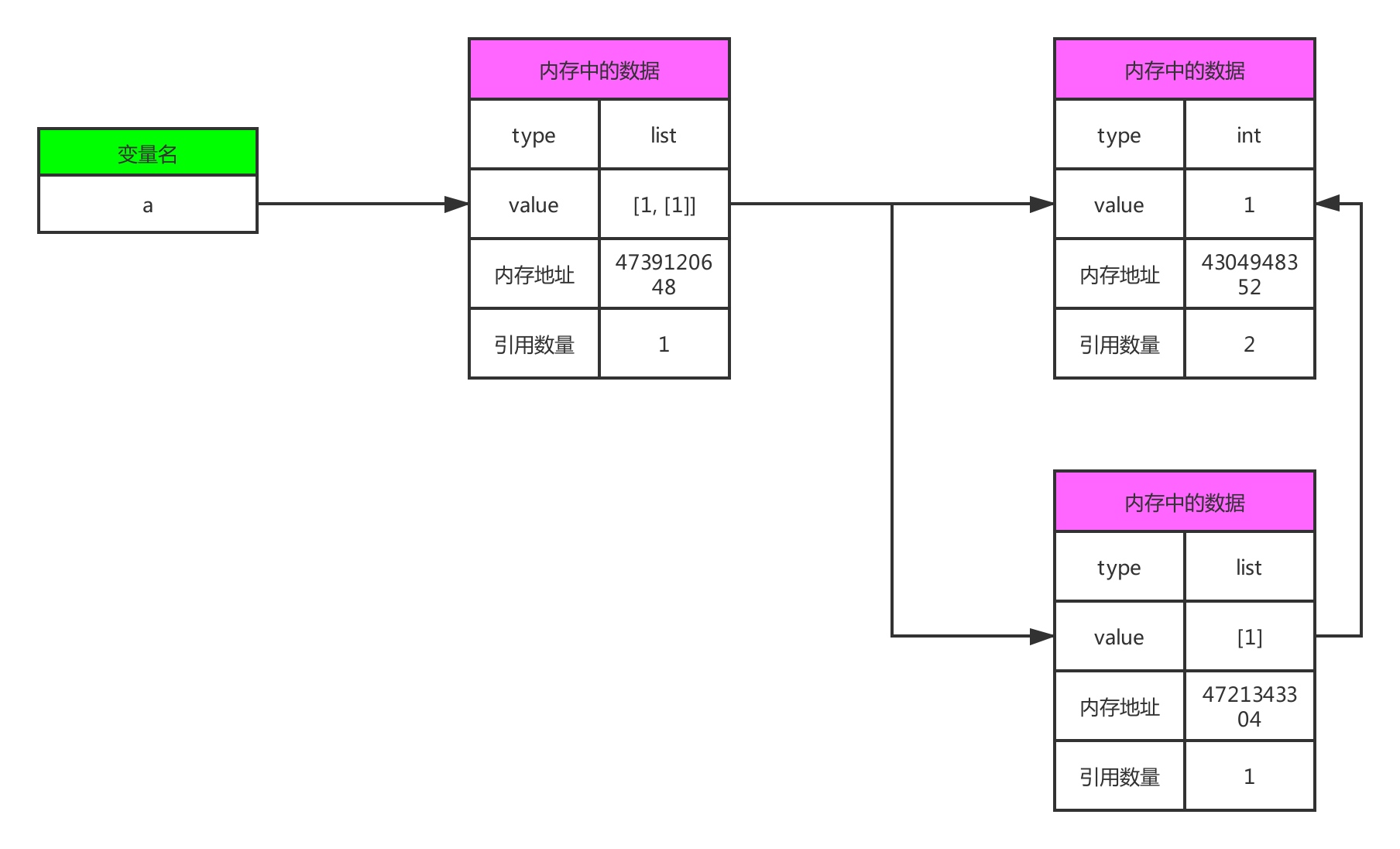
深拷贝之后
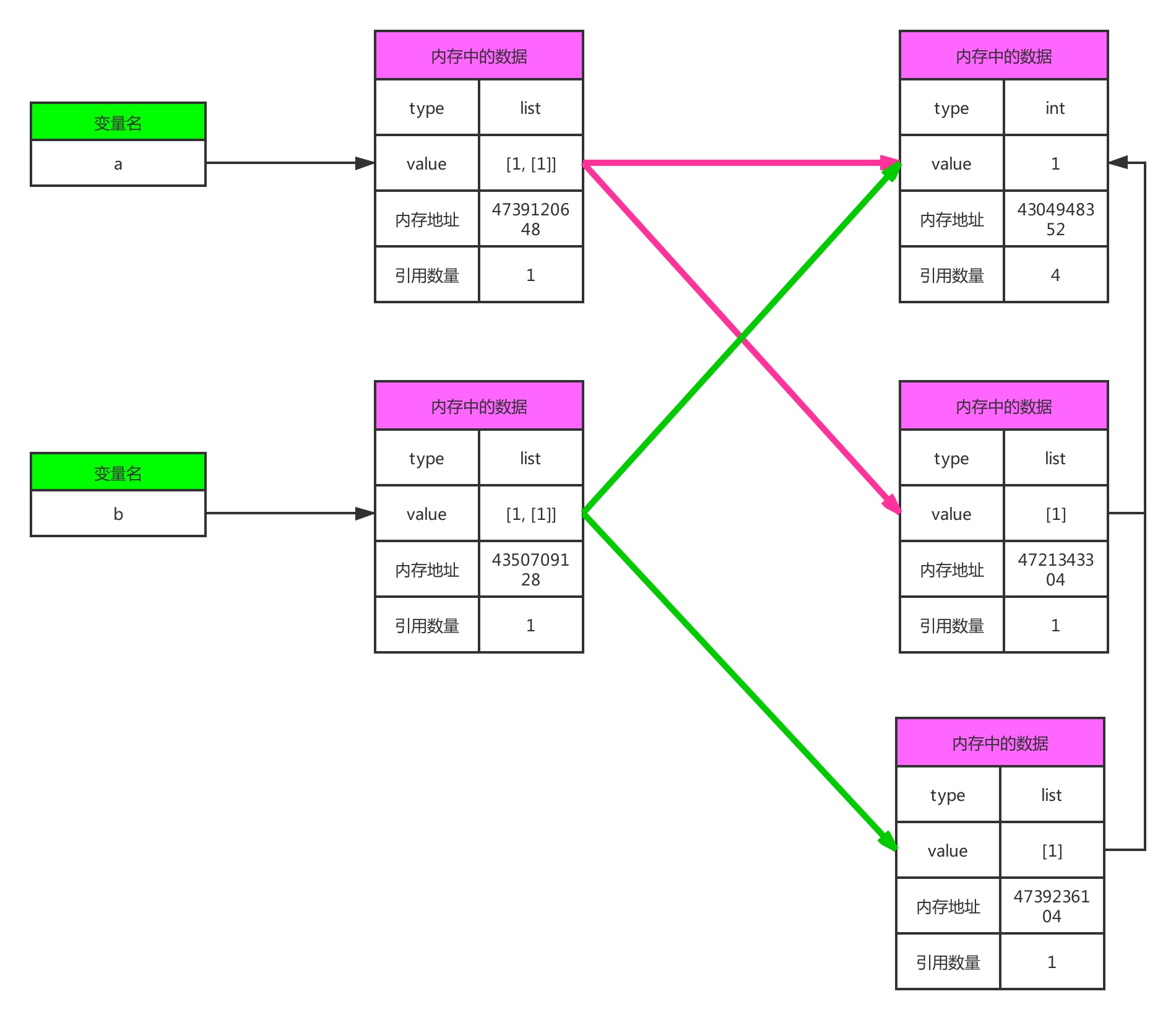
和浅拷贝相比,最大的不同在于,新生成了一个列表[1],内存地址和a[1]不一样,深拷贝之后,对b的任何操作,都不会影响到a,虽然多耗费了一些内存,但是更加安全
3 值传递 引用传递
''' 不可变对象作为函数参数,相当于C语言的值传递。 可变对象作为函数参数,相当于C语言的引用传递。 ...
''' 值传递(passl-by-value)过程中,被调函数的形式参数作为被调函数的局部变量处理, 即在堆栈中开辟了内存空间以存放由主调函数放进来的实参的值, 从而成为了实参的一个副本。值传递的特点是被调函数对形式参数的任何操作都是作为局部变量进行, 不会影响主调函数的实参变量的值。(被调函数新开辟内存空间存放的是实参的副本值) '''
def test(x):
print("test before")
print(id(x),2222)
x += 1
print("test after")
print(id(x),3333)
return x
if __name__ == '__main__':
a = 2
print(id(a),1111)
n = test(a)
print(a)
print(id(a),4444)
'''
140722942210336 1111
test before
140722942210336 2222
test after
140722942210368 3333
2
140722942210336 4444
'''
''' 引用传递(pass-by-reference)过程中,被调函数的形式参数虽然也作为局部变量在堆栈中开辟了内存空间, 但是这时存放的是由主调函数放进来的实参变量的地址。被调函数对形参的任何操作都被处理成间接寻址, 即通过堆栈中存放的地址访问主调函数中的实参变量。 正因为如此,被调函数对形参做的任何操作都影响了主调函数中的实参变量。(被调函数新开辟内存空间存放的是实参的地址) '''
def test(list2):
print("test before")
print(id(list2))
list2[1] = 30
print("list after")
print(id(list2))
return list2
if __name__ == '__main__':
list1 = ["limei", 25, 'female']
print(id(list1))
list3 = test(list1)
print(list1)
print(id(list1))
print(id(list3))
'''
1848503063112
test before
1848503063112
list after
1848503063112
['limei', 30, 'female']
1848503063112
1848503063112
'''