目录
1 restful规范
1 Representational State Transfer:表征性状态转移
2 Web API接口的设计风格,尤其适用于前后端分离的应用模式中
3 与语言,平台无关,任何框架都可以写出符合restful规范的api接口
4 规范:10条
-1 数据的安全保障:url链接一般都采用https协议进行传输
-2 接口特征表现:api关键字标识
-https://api.baidu.com/books/
-https://www.baidu.com/api/books/
-3 多版本共存:url链接中标识接口版本
-https://api.baidu.com/v1/books/
-https://api.baidu.com/v2/books/
-4 数据即是资源,均使用名词(可复数)***********
-接口一般都是完成前后台数据的交互,交互的数据我们称之为资源
-一般提倡用资源的复数形式,不要使用动词
-查询所有图书
-https://api.baidu.com/books/
-https://api.baidu.com/get_all_books/ # 错误示范
-https://api.baidu.com/delete-user # 错误的示范
-https://api.baidu.com/user # 删除用户的示例:疑问:到底是删还是查?
-5 资源操作由请求方式决定:
https://api.baidu.com/books - get请求:获取所有书
https://api.baidu.com/books/1 - get请求:获取主键为1的书
https://api.baidu.com/books - post请求:新增一本书书
https://api.baidu.com/books/1 - put请求:整体修改主键为1的书
https://api.baidu.com/books/1 - patch请求:局部修改主键为1的书
https://api.baidu.com/books/1 - delete请求:删除主键为1的书
-6 过滤,通过在url上传参的形式传递搜索条件
https://api.example.com/v1/zoos?limit=10 :指定返回记录的数量
https://api.example.com/v1/zoos?offset=10&limit=3:指定返回记录的开始位置
https://api.example.com/v1/zoos?page=2&per_page=100:指定第几页,以及每页的记录数
https://api.example.com/v1/zoos?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序
https://api.example.com/v1/zoos?animal_type_id=1:指定筛选条件
-7 响应状态码
-返回数据中带状态码
-{'code':200}
-8 返回结果中带错误信息
-{'code':100,'msg':'因为xx原因失败'}
-9 返回结果,该符合以下规范
GET /collection:返回资源对象的列表(数组)
GET /collection/resource:返回单个资源对象(字典)
POST /collection:返回新生成的资源对象 (新增后的对象字典)
PUT /collection/resource:返回完整的资源对象 (修改后的对象字典)
PATCH /collection/resource:返回完整的资源对象 (修改后的对象字典)
DELETE /collection/resource:返回一个空文档 ()
-10 返回的数据中带链接地址
-查询id为1的图书接口,返回结果示例
{'code':100,
'msg':'成功',
'result':
{'title':'三国演义',
'price':12.3,
'publish':'https://127.0.0.1/api/v1/publish/3'
}
}
2 APIview源码分析
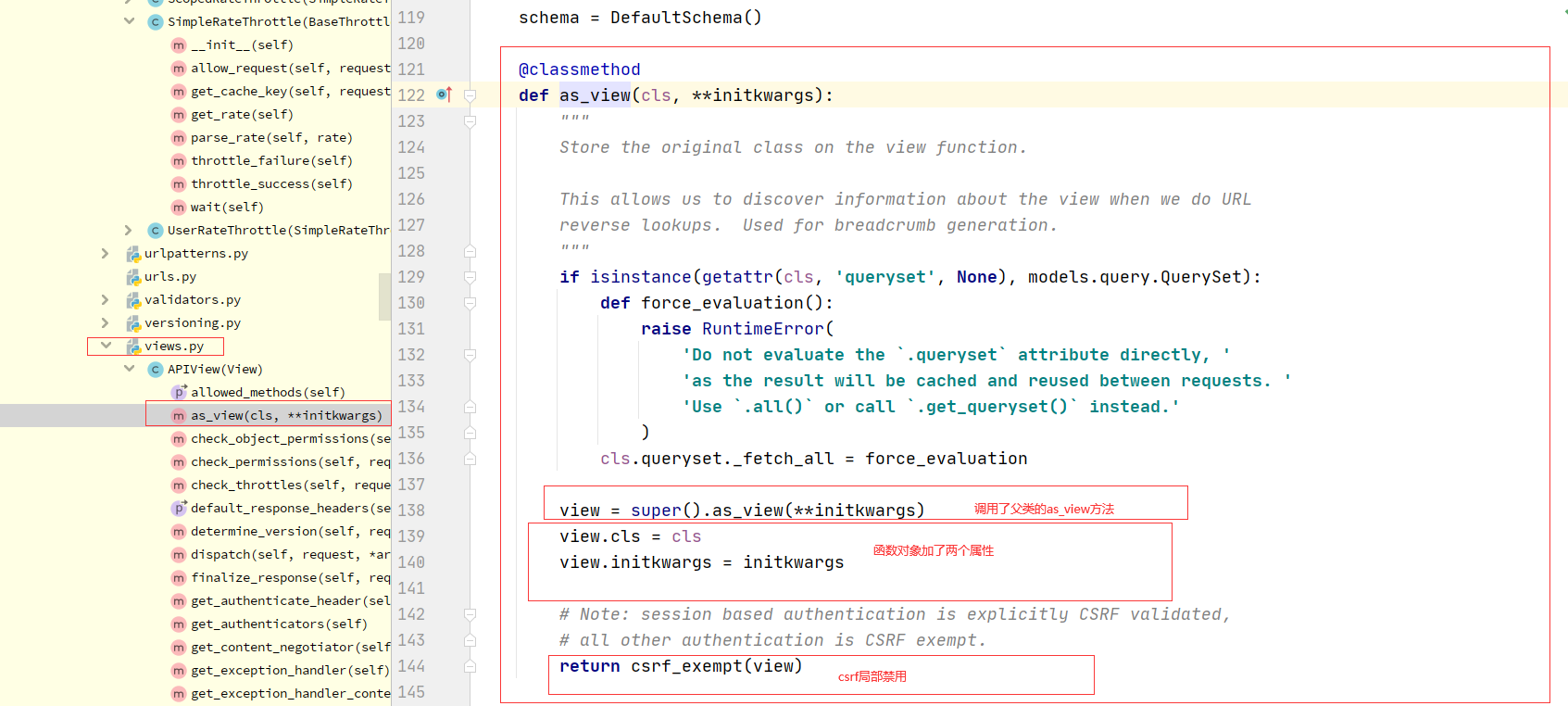
1 APIview的as_view
-内部还是执行了View的闭包函数view
-禁用掉了csrf
-一切皆对象,函数也是对象 函数地址.name=lqz
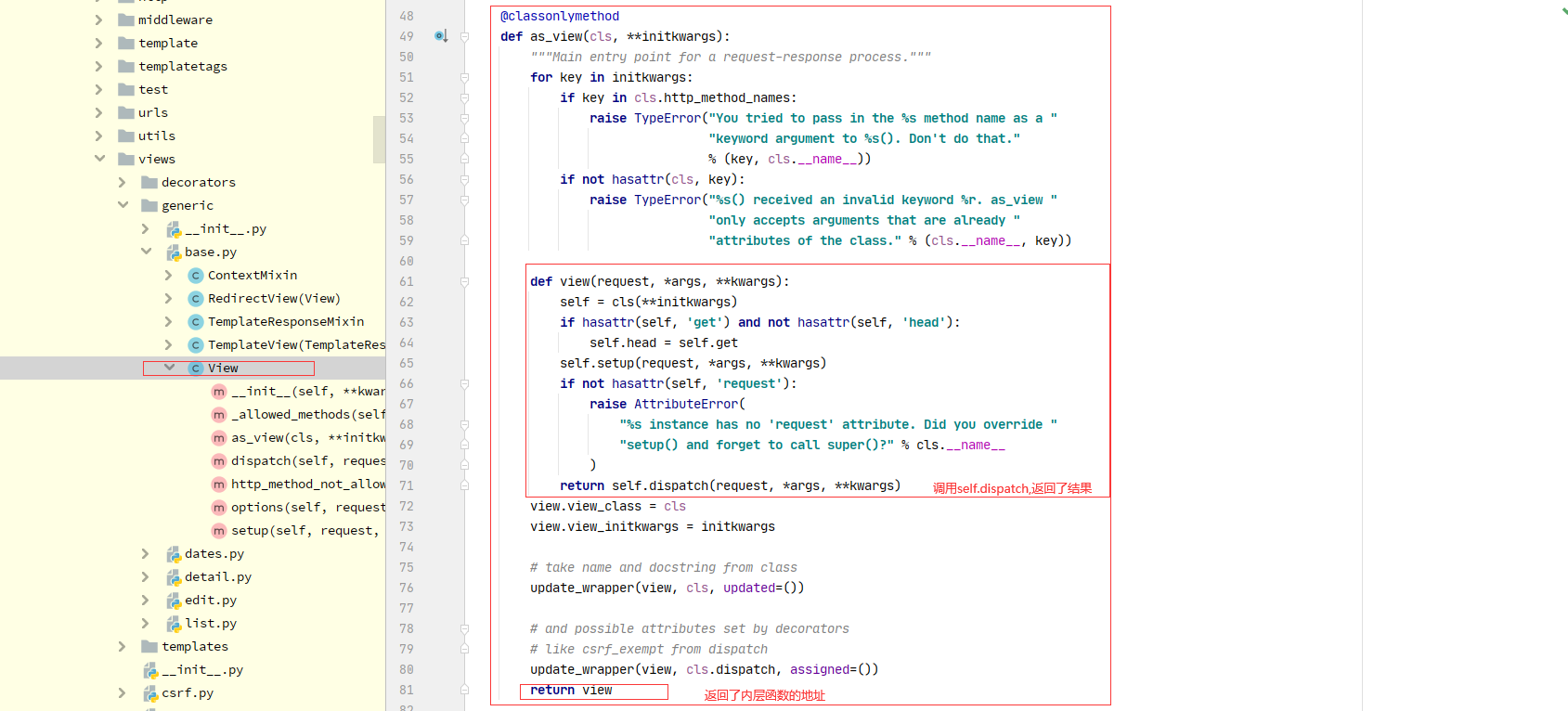
2 原生View类中过的as_view中的闭包函数view
-本质执行了self.dispatch(request, *args, **kwargs),执行的是APIView的dispatch
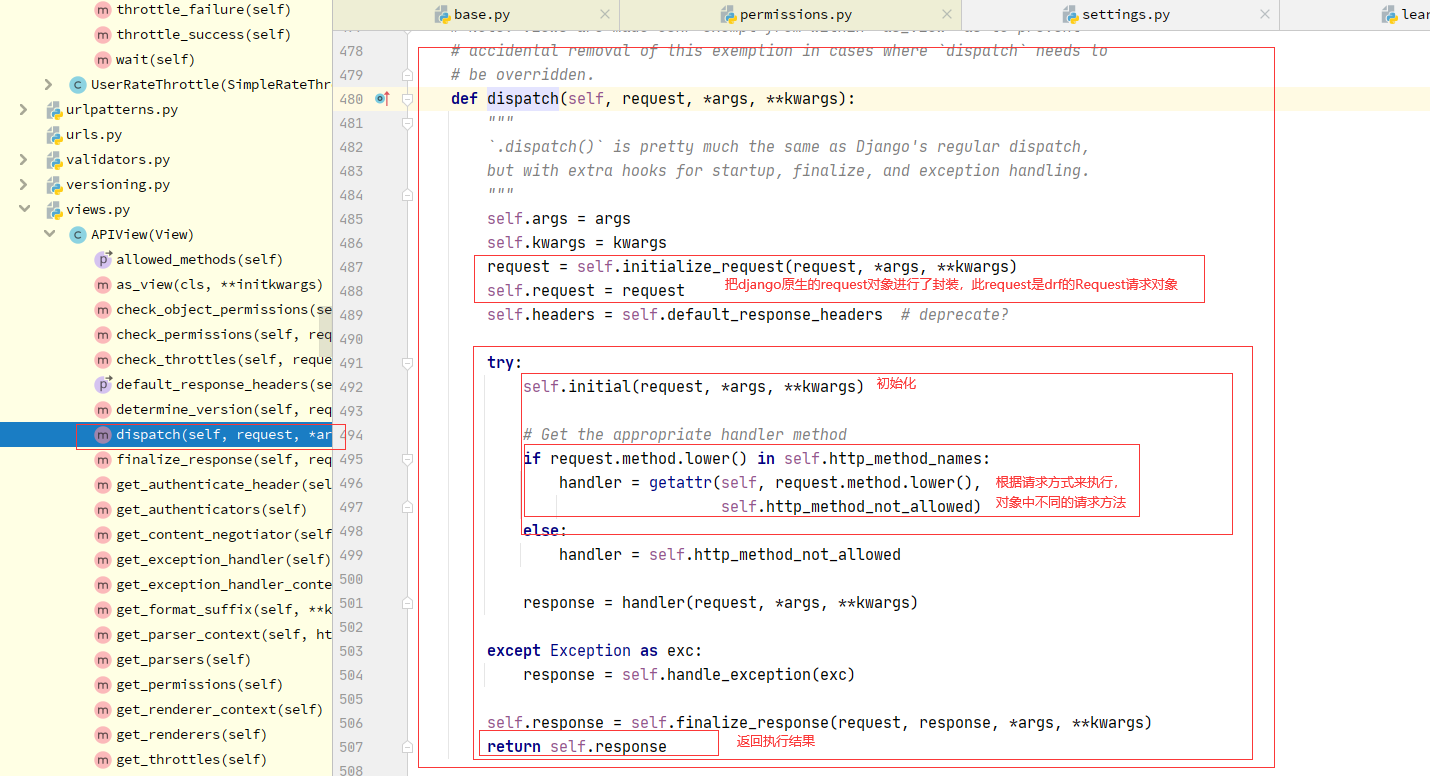
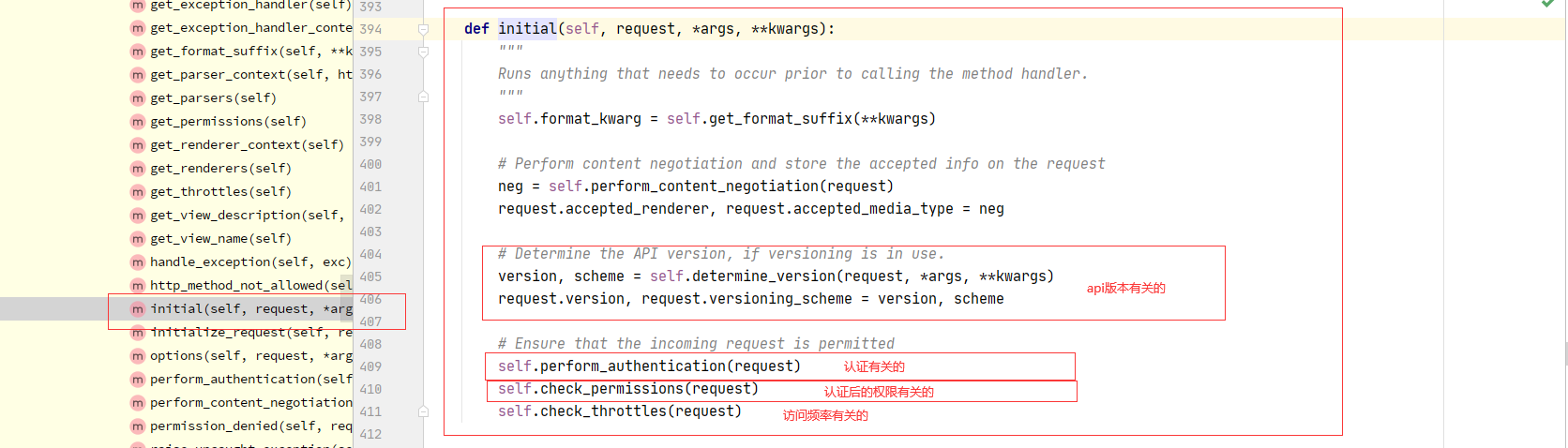
3 APIView的dispatch
def dispatch(self, request, *args, **kwargs):
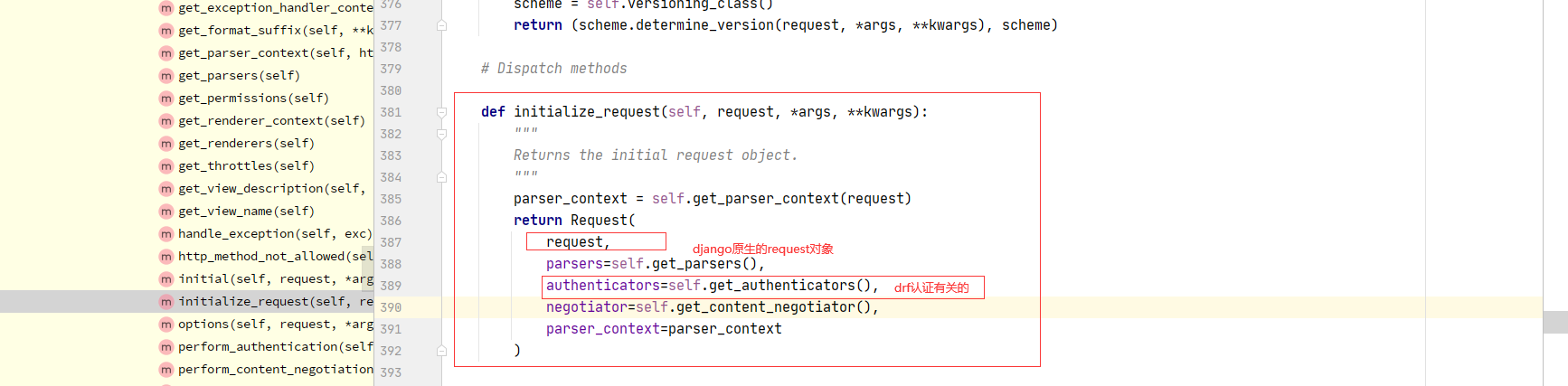
# DRF的Request类的对象,内部有request._request,是原生request
request = self.initialize_request(request, *args, **kwargs)
self.request = request
try:
self.initial(request, *args, **kwargs)
'''
#认证,权限,频率
self.perform_authentication(request)
self.check_permissions(request)
self.check_throttles(request)
'''
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),
self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
response = handler(request, *args, **kwargs)
except Exception as exc:
# 全局的异常捕获
response = self.handle_exception(exc)
# 把视图函数(类)返回的response,又包装了一下
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response
3 Request类分析
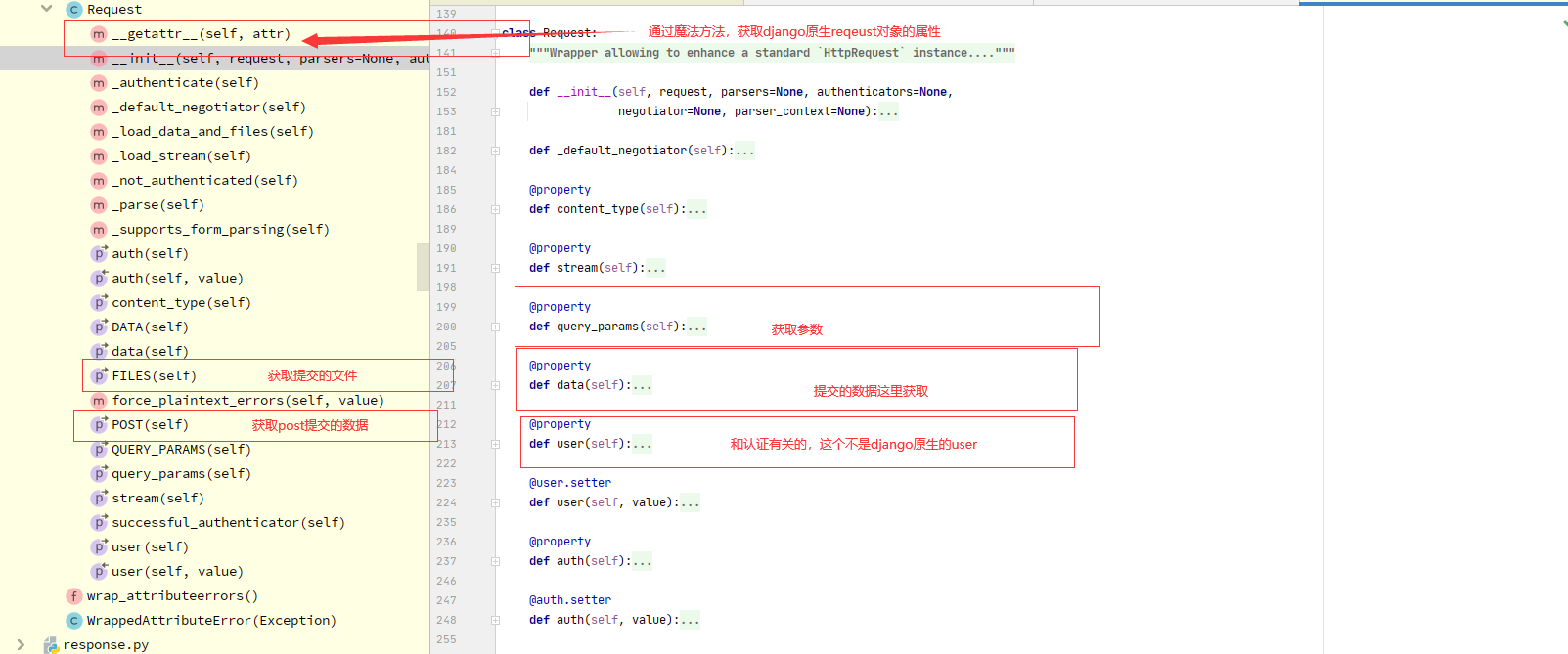
1 Request类
-request._request:原生request
-request.data : post请求提交的数据(urlencoded,json,formdata)
-request.user :不是原生的user了
-request.query_params :原生的request.GET,为了遵循restful规范
-requset.FILES :新的
-重写了__getattr__,新的request.原来所有的属性和方法,都能直接拿到
def __getattr__(self, attr):
return getattr(self._request, attr)
4 序列化组件介绍
1 作用:
1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串
-Book--序列化器--->字典--同过drf:Response--》json格式字符串--->传给前端
2. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型
json格式数据---drf:Request-->字典---序列化器---》Book
3. 反序列化,完成数据校验功能
5 序列化组件简单使用
1 序列化的使用
-写一个序列化类继承serializers.Serializer
-在类中写要序列化的字段
-在视图类中,实例化得到一个序列化类的对象,把要序列化的数据传入
ser=BookSerializer(instance=res,many=True)
-得到字典
ser.data就是序列化后的字典
5.1 代码实现
1:models.py
from django.db import models
# Create your models here.
class Book(models.Model):
id = models.AutoField(primary_key=True,help_text='id')
title = models.CharField(max_length=32,help_text='标题')
price = models.DecimalField(max_digits=5, decimal_places=2,help_text='标题')
publish = models.CharField(max_length=32,help_text='出版社')
2:serializer.py
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
# 要序列化哪个字段
id = serializers.IntegerField(help_text='id')
# id=serializers.CharField()
title = serializers.CharField(max_length=32,help_text='标题')
price = serializers.DecimalField(max_digits=5, decimal_places=2,help_text='书籍价格')
publish=serializers.CharField(max_length=32,help_text='出版社')
# publish=serializers.CharField(max_length=32)
3:views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from .bookserializer import BookSerializer
from . import models
class Book(APIView):
def get(self, request, *args, **kwargs):
query_set = models.Book.objects.all()
# 借助序列化器
# 如果是多条,就是many=True
# 如果是单个对象,就不写
ser = BookSerializer(many=True, instance=query_set)
# 通过序列化器得到的字典
# ser.data
data = ser.data
print(data)
return Response(data)
4:urls.py
path('books/', views.Book.as_view()),
6 序列化类字段类型和字段参数
# 字段类型(记列的这几个)
-IntegerField
-CharField
-DecimalField
-DateTimeField
-跟models中大差不差
# 常用字段参数
-选项参数
max_length 最大长度
min_lenght 最小长度
allow_blank 是否允许为空,这个是序列化层面,不是数据层面
trim_whitespace 是否截断空白字符
max_value 最小值
min_value 最大值
-通用参数
#重点
read_only 表明该字段仅用于序列化输出,默认False
write_only 表明该字段仅用于反序列化输入,默认False
# 掌握
required 表明该字段在反序列化时必须输入,默认True
default 反序列化时使用的默认值
allow_null 表明该字段是否允许传入None,默认False
# 了解
validators 该字段使用的验证器
error_messages 包含错误编号与错误信息的字典
7 序列化器的保存功能
# 如果序列化类继承的是Serializer,必须重写create方法
# 使用方式
-视图类
def post(self,request,*args,**kwargs):
ser = BookSerializer(data=request.data)
# ser.is_valid(raise_exception=True)
# ser.save()
# return Response(ser.data)
# 等同于下面
if ser.is_valid():
ser.save()
return Response(ser.data)
else:
return Response(ser.errors)
-序列化类
class BookSerializer(serializers.Serializer):
...
def create(self, validated_data):
# 为什么要重写create?因为不能自动保存
res=models.Book.objects.create(**validated_data)
print(res)
return res
8 序列化器的字段校验功能
# 三种方式
-字段自己的校验规则(max_length...)
-validators的校验
publish = serializers.CharField(max_length=32,validators=[check,])
def check(data):
if len(data)>10:
raise ValidationError('最长不能超过10')
else:
return data
-局部和全局钩子
# 局部钩子,validate_字段名,需要带一个data,data就是该字段的数据
def validate_title(self, data):
if data.startswith('sb'):
raise ValidationError('不能以sb开头')
else:
return data
# 全局钩子
def validate(self, attrs):
title=attrs.get('title')
publish=attrs.get('publish')
if title==publish:
raise ValidationError('书名不能跟出版社同名')
else:
return attrs
from rest_framework import serializers
from . import models
from rest_framework.exceptions import ValidationError
filter_word = [
'alex',
'sb',
'ss',
'xx',
]
class BookSerializer(serializers.Serializer):
# 要序列化哪个字段
id = serializers.IntegerField(help_text='id',)
# id=serializers.CharField()
title = serializers.CharField(max_length=32,help_text='标题')
price = serializers.DecimalField(max_digits=5, decimal_places=2,help_text='书籍价格')
def check_len(data):
if len(data) > 10:
raise ValidationError('太长了')
else:
return data
publish = serializers.CharField(max_length=32, help_text='出版社', validators=[check_len, ])
def validate_title(self, data):
for word in filter_word:
if word in data:
raise ValidationError('违法字段')
else:
return data
def validate(self, attrs):
title = attrs.get('title')
publish = attrs.get('publish')
if title == publish:
raise ValidationError('可恶标题和出版社名字不能一样')
return attrs
def create(self, validated_data):
print(validated_data)
book_obj = models.Book.objects.create(**validated_data)
return book_obj
9 read_only和write_only
read_only 表明该字段仅用于序列化输出,默认False
write_only 表明该字段仅用于反序列化输入,默认False
class BookSerializer(serializers.Serializer):
# 要序列化哪个字段
id = serializers.IntegerField(required=False)
# id=serializers.CharField()
title = serializers.CharField(max_length=32,min_length=2,read_only=True)
price = serializers.DecimalField(max_digits=5, decimal_places=2)
# 序列化的时候看不到
publish = serializers.CharField(max_length=32,validators=[check,],write_only=True)