YARN(Yet Another Resource Negotiator)是Hadoop2.0集群中负责资源管理和调度以及监控运行在它上面的各种应用,是hadoop2.0中的核心,它类似于一个分布式操作系统,通过它的api编写的应用可以跑在它上面,支持临时和常驻的应用,集群的资源可以得到最大限度的共享。资源是指CPU,内存,硬盘,带宽等可以量化的东西。
Hadoop1.0和2.0架构对比

- 1.0的绝对核心是mapreduce,只能跑mapreduce的任务;2.0的绝对核心是YARN,除了可以跑mapreduce,还可以跑其它各种各样的任务,每个应用向YARN申请资源
- 1.0的JobTracker和NameNode是单点,一旦挂掉,整个集群会瘫痪;2.0核心组件不再是单点,基于ZooKeeper实现了HA(RM Hadoop2.4版本及后才支持)
- 2.0没有了JobTracker和TaskTracker,增加了ResourceManager,NodeManager,Application Master,Container
- 2.0资源使用效率更高,资源使用更加弹性灵活
- 2.0把资源管理以及调度和任务管理以及调度拆开,使得组件功能变得更简单,程序更加稳定健壮,1.0时都由JobTracker负责
- 2.0比1.0架构更加复杂了
- YARN的出现解决了1.0时代设计的缺陷,让Hadoop集群功能越来越完善,让Hadoop集群越来越稳定
YARN架构设计

(图片来源:hadoop官方文档)
- Client客户端,提交任务到ResourceManager
- ResourceManager(RM),负责接收任务,管理集群中的资源和调度,以及监控运行在YARN上的应用,它有2个核心的组件:1 可插拔的Scheduler资源调度器,2 ResoucerManagerApplicationMaster管理和监控应用
- NodeManager(NM),负责管理单台机器的资源,通过心跳定时上报机器资源状态,启动和停止和监控Container,定时检查机器可用情况
- ApplicationMaster(AM),运行在NM Container上的程序,由RM选择某台NM上的某个Container来运行这个程序,AM负责向RM申请应用所需资源,协调NM启动Container,负责应用任务的管理和调度,通过心跳定时向RM上报任务执行情况
- Container,资源容器,不限定应用类型,可以跑任何任务,比如map任务,reduce任务,spark driver任务等,资源类型有:CPU,内存,硬盘,带宽等可量化的东西或者它们的组合。资源需要按照最小单位的倍数申请。
- 执行流程概述;
1 客户端准备好任务各种资源,包括代码,依赖包,配置文件等,通过RM客户端向RM提交任务
2 RM进行权限检查和集群负载情况,如果通过,接受提交的任务,加入任务队列,等待调度器调度
3 当有空闲资源时,RM选择一个NM,指示NM启动一个Container运行这个任务的AM
4 这个应用的AM启动后,AM看看自己完成任务需要多少资源,然后向RM Scheduler申请资源
5 Scheduler根据策略分配资源,返回资源信息给AM
6 AM拿到已分配的资源信息后,协商NM启动Container,然后在Container运行自己的任务程序
7 AM调度自己的任务,监控自己的任务状态(Container和AM通信),并定时向RM汇报任务状态
8 AM执行完成,释放Container资源 - RM出现异常;其它备份的RM接管,新的RM通知AM重新启动
- NM出现异常:RM监控到NM异常,RM通知AM,AM做进一步处理
- AM出现异常:RM负责重新启动AM,RM已经记录了AM任务状态信息,已经完成的任务不会再执行
RM实现HA
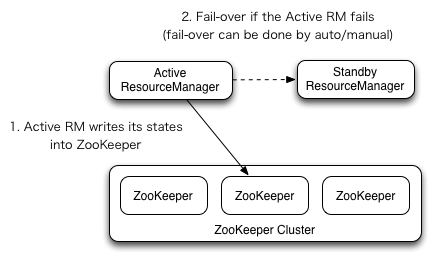
(图片来源:hadoop官方文档)
- 大于等于2.4版本才支持HA
- RM有2种状态,提供服务的处于Active状态,备份的是Standby状态
- 通过ZooKeeper协调,实现故障转移
- RM有内置ZKFC,只需开启配置,不需要单独启动额外的监控进程
- RM状态信息存储方式:
1 ZooKeeper
2 HDFS
3 本地文件系统,故障转移需要考虑信息如何同步,人工实现故障转移
调度策略
- FIFO Scheduler(先进先出)
先来的先执行,如果有任务执行时间长,占用资源多,后面的任务只能等待,即使是执行快,占用资源少的应用,也必须等待那个耗时耗资源的任务执行完 - Capacity Scheduler(预先分配资源模式)
N个任务队列,每个队列分配一定资源,每个队列资源互不共享,每个队列只有有权限的人或者组织才能使用。
如果某些任务队列没有任务,会造成资源的浪费。相比FIFO模式,任务执行时间会变的更长,因为耗时耗资源的应用可用资源更少了。 - Fair Scheduler(公平调度模式)
先来的任务先执行,当有新的任务到来时,虽然上一个任务没有执行完,上一个任务释放的Container优先分配给这个新任务,当新任务执行完成时,释放的资源再给上一个任务使用。
这样就能达到即不影响耗时的任务又能执行执行新任务的目的。在兼顾公平使用的基础上,最大化利用集群的资源。
参考资料
【0】八斗学院内部YARN学习资料
【1】YARN官方文档
http://hadoop.apache.org/docs/r2.6.5/hadoop-yarn/hadoop-yarn-site/YARN.html