编码的原因可以总结为:
- 计算机中存储信息的最小单元是一个字节即 8 个 bit,所以能表示的字符范围是 0~255 个
- 人类要表示的符号太多,无法用一个字节来完全表示
- 要解决这个矛盾必须需要一个新的数据结构 char,从 char 到 byte 必须编码
编码格式一览
各种语言需要交流,经过翻译是必要的,那又如何来翻译呢?计算中提拱了多种翻译方式,常见的有 ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16 等。它们都可以被看作为字典,它们规定了转化的规则,按照这个规则就可以让计算机正确的表示我们的字符。目前的编码格式很多,例如 GB2312、GBK、UTF-8、UTF-16 这几种格式都可以表示一个汉字,那我们到底选择哪种编码格式来存储汉字呢?这就要考虑到其它因素了,是存储空间重要还是编码的效率重要。根据这些因素来正确选择编码格式
ASCII 码
ASCII 码,总共有 128 个,用一个字节的低 7 位表示,0~31 是控制字符如换行回车删除等;32~126 是打印字符,可以通过键盘输入并且能够显示出来。
ISO-8859-1
128 个字符显然是不够用的,于是 ISO 组织在 ASCII 码基础上又制定了一些列标准用来扩展 ASCII 编码,它们是 ISO-8859-1~ISO-8859-15,其中 ISO-8859-1 涵盖了大多数西欧语言字符,所有应用的最广泛。ISO-8859-1 仍然是单字节编码,它总共能表示 256 个字符。
GB2312
它的全称是《信息交换用汉字编码字符集 基本集》,它是双字节编码,总的编码范围是 A1-F7,其中从 A1-A9 是符号区,总共包含 682 个符号,从 B0-F7 是汉字区,包含 6763 个汉字。
GBK
全称叫《汉字内码扩展规范》,是国家技术监督局为 windows95 所制定的新的汉字内码规范,它的出现是为了扩展 GB2312,加入更多的汉字,它的编码范围是 8140~FEFE(去掉 XX7F)总共有 23940 个码位,它能表示 21003 个汉字,它的编码是和 GB2312 兼容的,也就是说用 GB2312 编码的汉字可以用 GBK 来解码,并且不会有乱码。
GB18030
全称是《信息交换用汉字编码字符集》,是我国的强制标准,它可能是单字节、双字节或者四字节编码,它的编码与 GB2312 编码兼容,这个虽然是国家标准,但是实际应用系统中使用的并不广泛。
UTF-16
说到 UTF 必须要提到 Unicode(Universal Code 统一码),ISO 试图想创建一个全新的超语言字典,世界上所有的语言都可以通过这本字典来相互翻译。Unicode 是 Java 和 XML 的基础,下面详细介绍 Unicode 在计算机中的存储形式。UTF-16 具体定义了 Unicode 字符在计算机中存取方法。UTF-16 用两个字节来表示 Unicode 转化格式,这个是定长的表示方法,不论什么字符都可以用两个字节表示,两个字节是 16 个 bit,所以叫 UTF-16。UTF-16 表示字符非常方便,每两个字节表示一个字符,这个在字符串操作时就大大简化了操作,这也是 Java 以 UTF-16 作为内存的字符存储格式的一个很重要的原因。
UTF-8
UTF-16 统一采用两个字节表示一个字符,虽然在表示上非常简单方便,但是也有其缺点,有很大一部分字符用一个字节就可以表示的现在要两个字节表示,存储空间放大了一倍,在现在的网络带宽还非常有限的今天,这样会增大网络传输的流量,而且也没必要。而 UTF-8 采用了一种变长技术,每个编码区域有不同的字码长度。不同类型的字符可以是由 1~6 个字节组成。
UTF-8 有以下编码规则:
- 如果一个字节,最高位(第 8 位)为 0,表示这是一个 ASCII 字符(00 - 7F)。可见,所有 ASCII 编码已经是 UTF-8 了。
- 如果一个字节,以 11 开头,连续的 1 的个数暗示这个字符的字节数,例如:110xxxxx 代表它是双字节 UTF-8 字符的首字节。
- 如果一个字节,以 10 开始,表示它不是首字节,需要向前查找才能得到当前字符的首字节
编码输出对比
public class CodeTest { public static void main(String[] args) { String name = "I am 君山"; System.out.println(parseStr2HexStr(name)); try { byte[] iso8859 = name.getBytes("ISO-8859-1"); System.out.println(parseByte2HexStr(iso8859)); byte[] gb2312 = name.getBytes("GB2312"); System.out.println(parseByte2HexStr(gb2312)); byte[] gbk = name.getBytes("GBK"); System.out.println(parseByte2HexStr(gbk)); byte[] utf16 = name.getBytes("UTF-16"); System.out.println(parseByte2HexStr(utf16)); byte[] utf8 = name.getBytes("UTF-8"); System.out.println(parseByte2HexStr(utf8)); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } } public static String parseStr2HexStr(String str) { StringBuffer hexString = new StringBuffer(); for (int i = 0; i < str.length(); i++) { int ch = (int) str.charAt(i); String strHex = Integer.toHexString(ch); hexString.append(strHex); } return hexString.toString(); } public static String parseByte2HexStr(byte buf[]){ StringBuffer sb = new StringBuffer(); for(int i = 0; i < buf.length; i++){ String hex = Integer.toHexString(buf[i] & 0xFF); if (hex.length() == 1) { hex = '0' + hex; } sb.append(hex.toUpperCase()); } return sb.toString(); } }
I a m 君 山
char 49 20 61 6d 20 541b 5c71
iso 49 20 61 6D 20 3F 3F
gb2312 49 20 61 6D 20 BEFD C9BD
gbk 49 20 61 6D 20 BEFD C9BD
u-16 0049 0020 0061 006D 0020 541B 5C71
u-8 49 20 61 6D 20 E5909B E5B1B1
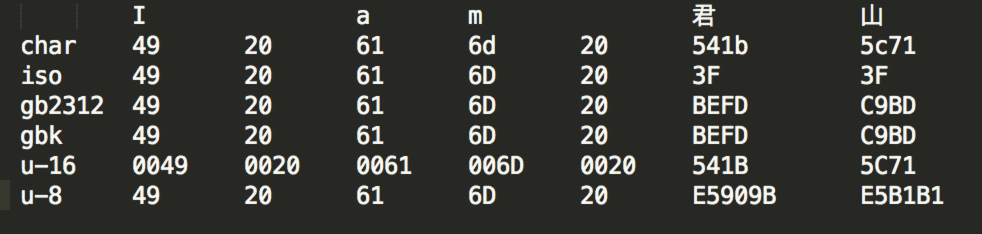
ISO-8859-1 编码
7 个 char 字符经过 ISO-8859-1 编码转变成 7 个 byte 数组,ISO-8859-1 是单字节编码,中文“君山”被转化成值是 3f 的 byte。3f 也就是“?”字符,所以经常会出现中文变成“?”很可能就是错误的使用了 ISO-8859-1 这个编码导致的。中文字符经过 ISO-8859-1 编码会丢失信息,通常我们称之为“黑洞”,它会把不认识的字符吸收掉。
GB2312 编码
GB2312 字符集有一个 char 到 byte 的码表,不同的字符编码就是查这个码表找到与每个字符的对应的字节,然后拼装成 byte 数组。
查表的规则如下:如果查到的码位值大于 oxff 则是双字节,否则是单字节。双字节高 8 位作为第一个字节,低 8 位作为第二个字节.
GBK 编码
GBK 与 GB2312 编码结果是一样的,由此可以得出 GBK 编码是兼容 GB2312 编码的,它们的编码算法也是一样的。不同的是它们的码表长度不一样,GBK 包含的汉字字符更多。所以只要是经过 GB2312 编码的汉字都可以用 GBK 进行解码,反过来则不然。
UTF-16 编码
UTF-16 编码将 char 数组放大了一倍,单字节范围内的字符,在高位补 0 变成两个字节,中文字符也变成两个字节。从 UTF-16 编码规则来看,仅仅将字符的高位和低位进行拆分变成两个字节。特点是编码效率非常高,规则很简单,由于不同处理器对 2 字节处理方式不同,Big-endian(高位字节在前,低位字节在后)或 Little-endian(低位字节在前,高位字节在后)编码,所以在对一串字符串进行编码是需要指明到底是 Big-endian 还是 Little-endian,所以前面有两个字节用来保存 BYTE_ORDER_MARK 值。UTF-16 是用16位(2字节)来表示的 UCS-2 或 Unicode 转换格式,通过代理对来访问 BMP 之外的字符编码。
UTF-8 编码
UTF-16 虽然编码效率很高,但是对单字节范围内字符也放大了一倍,这无形也浪费了存储空间,另外 UTF-16 采用顺序编码,不能对单个字符的编码值进行校验,如果中间的一个字符码值损坏,后面的所有码值都将受影响。而 UTF-8 这些问题都不存在,UTF-8 对单字节范围内字符仍然用一个字节表示,对汉字采用三个字节表示。UTF-8 编码与 GBK 和 GB2312 不同,不用查码表,所以在编码效率上 UTF-8 的效率会更好,所以在存储中文字符时 UTF-8 编码比较理想。
几种编码格式的比较
GB2312 与 GBK 编码规则类似,但是 GBK 范围更大,它能处理所有汉字字符,所以 GB2312 与 GBK 比较应该选择 GBK。
UTF-16 与 UTF-8 都是处理 Unicode 编码,它们的编码规则不太相同,相对来说 UTF-16 编码效率最高,字符到字节相互转换更简单,进行字符串操作也更好。它适合在本地磁盘和内存之间使用,可以进行字符和字节之间快速切换,如 Java 的内存编码就是采用 UTF-16 编码。但是它不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,想比较而言 UTF-8 更适合网络传输,对 ASCII 字符采用单字节存储,另外单个字符损坏也不会影响后面其它字符,在编码效率上介于 GBK 和 UTF-16 之间,所以 UTF-8 在编码效率上和编码安全性上做了平衡,是理想的中文编码方式。
Java Web中的编解码
数据经过网络传输都是以字节为单位的,所以所有的数据都必须能够被序列化为字节。在 Java 中数据被序列化必须继承 Serializable 接口。
有一个问题,你是否认真考虑过一段文本它的实际大小应该怎么计算,我曾经碰到过一个问题:就是要想办法压缩 Cookie 大小,减少网络传输量,当时有选择不同的压缩算法,发现压缩后字符数是减少了,但是并没有减少字节数。所谓的压缩只是将多个单字节字符通过编码转变成一个多字节字符。减少的是 String.length(),而并没有减少最终的字节数。例如将“ab”两个字符通过某种编码转变成一个奇怪的字符,虽然字符数从两个变成一个,但是如果采用 UTF-8 编码这个奇怪的字符最后经过编码可能又会变成三个或更多的字节。同样的道理比如整型数字 1234567 如果当成字符来存储,采用 UTF-8 来编码占用 7 个 byte,采用 UTF-16 编码将会占用 14 个 byte,但是把它当成 int 型数字来存储只需要 4 个 byte 来存储。所以看一段文本的大小,看字符本身的长度是没有意义的,即使是一样的字符采用不同的编码最终存储的大小也会不同,所以从字符到字节一定要看编码类型。
另外一个问题,你是否考虑过,当我们在电脑中某个文本编辑器里输入某个汉字时,它到底是怎么表示的?我们知道,计算机里所有的信息都是以 01 表示的,那么一个汉字,它到底是多少个 0 和 1 呢?我们能够看到的汉字都是以字符形式出现的,例如在 Java 中“淘宝”两个字符,它在计算机中的数值 10 进制是 28120 和 23453,16 进制是 6bd8 和 5d9d,也就是这两个字符是由这两个数字唯一表示的。Java 中一个 char 是 16 个 bit 相当于两个字节,所以两个汉字用 char 表示在内存中占用相当于四个字节的空间。
用户从浏览器端发起一个 HTTP 请求,需要存在编码的地方是 URL、Cookie、Parameter。服务器端接受到 HTTP 请求后要解析 HTTP 协议,其中 URI、Cookie 和 POST 表单参数需要解码,服务器端可能还需要读取数据库中的数据,本地或网络中其它地方的文本文件,这些数据都可能存在编码问题,当 Servlet 处理完所有请求的数据后,需要将这些数据再编码通过 Socket 发送到用户请求的浏览器里,再经过浏览器解码成为文本。一次 HTTP 请求设计到很多地方需要编解码,它们编解码的规则是什么?
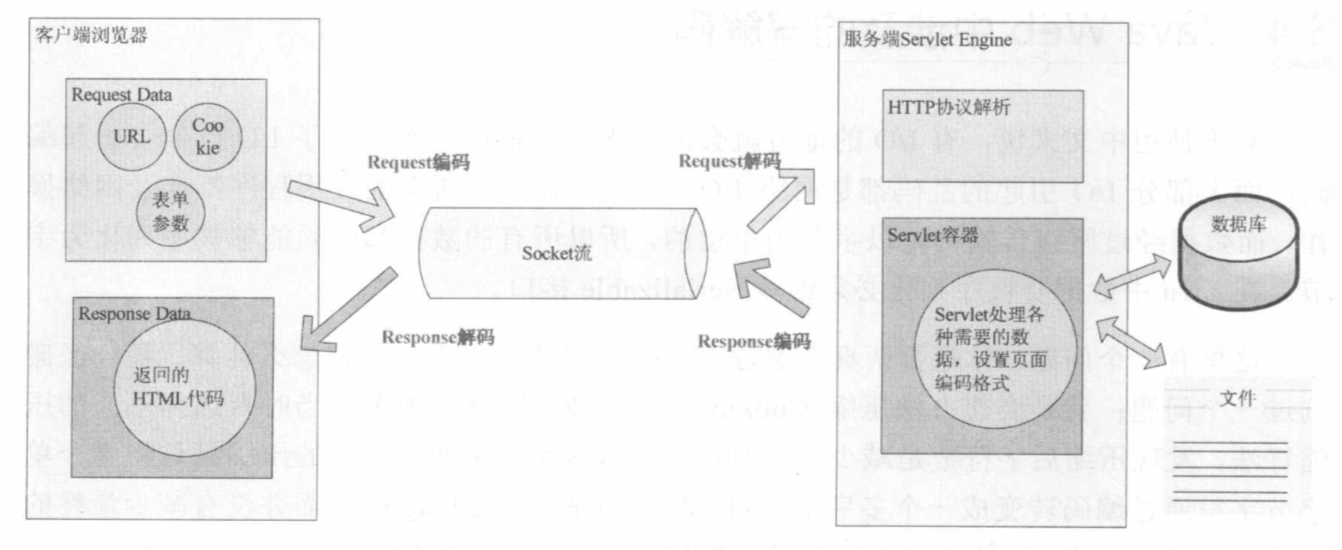
URL 的编解码
用户提交一个 URL,这个 URL 中可能存在中文,因此需要编码。
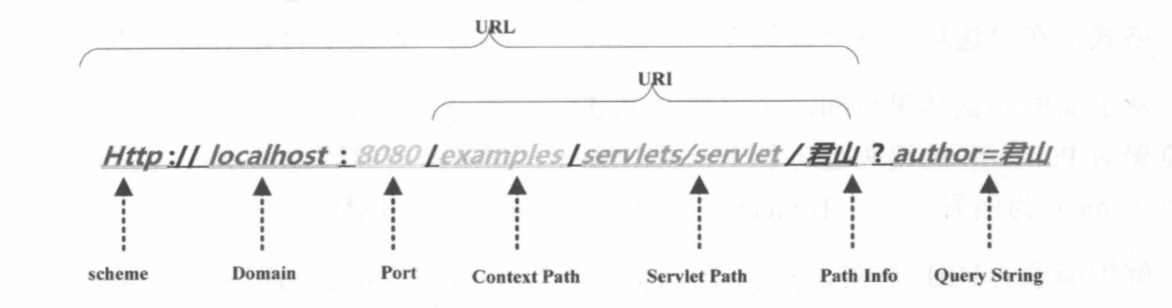
以 Tomcat 作为 Servlet Engine 为例,它们分别对应到下面这些配置文件中:
- Port 对应在 Tomcat 的 <Connector port="8080"/> 中配置
- Context Path 对应在 Tomcat 的<Context path="/examples"/> 中配置
- Servlet Path 在 Web 应用的 web.xml 的<url-pattern> 中配置
<servlet-mapping> <servlet-name>example</servlet-name> <url-pattern>/servlets/servlet/*</url-pattern> </servlet-mapping>
- PathInfo是我们请求的具体的 Servlet
- QueryString是要传递的参数,浏览器里直接输入URL通过Get方法请求的,如果是POST方法请求的话,QueryString将通过表单方式提交到服务器端。
PathInfo&QueryString浏览器客户端编码
PathInfo 和 QueryString 出现了中文,当我们在浏览器中直接输入这个 URL 时,在浏览器端和服务端会如何编码和解析这个 URL 呢?
http://localhost:8080/examples/servlets/servlet/君山?author=君山
![]()
PathInfo 是 UTF-8 编码而 QueryString 是经过 GBK 编码,至于为什么会有“%”?查阅 URL 的编码规范 RFC3986 可知浏览器编码 URL 是将非 ASCII 字符按照某种编码格式编码成16进制数字然后将每个16进制表示的字节前加上“%”,所以最终的 URL 就成了上图的格式了。
浏览器对 PathInfo 和 QueryString 的编码是不一样的,不同浏览器对 PathInfo 也可能不一样,这就对服务器的解码造成很大的困难。
PathInfo 服务端解码
下面我们以 Tomcat 为例看一下,Tomcat 接受到这个 URL 是如何解码的。解析请求的 URL 是在 org.apache.coyote.HTTP11.InternalInputBuffer 的 parseRequestLine 方法中,这个方法把传过来的 URL 的 byte[] 设置到 org.apache.coyote.Request 的相应的属性中。这里的 URL 仍然是 byte 格式,转成 char 是在 org.apache.catalina.connector.CoyoteAdapter 的 convertURI 方法中完成的。从代码中可以知道对 URL 的 URI 部分进行解码的字符集是在 connector 的 <Connector URIEncoding=”UTF-8”/> 中定义的,如果没有定义,那么将以默认编码 ISO-8859-1 解析。所以如果有中文 URL 时最好把 URIEncoding 设置成 UTF-8 编码。
QueryString 服务端解码
GET 方式 HTTP 请求的 QueryString 与 POST 方式 HTTP 请求的表单参数都是作为 Parameters 保存,都是通过 request.getParameter 获取参数值。对它们的解码是在 request.getParameter 方法第一次被调用时进行的。request.getParameter 方法被调用时将会调用 org.apache.catalina.connector.Request 的 parseParameters 方法。这个方法将会对 GET 和 POST 方式传递的参数进行解码,但是它们的解码字符集有可能不一样。
GET 方式
QueryString 的解码字符集本身是通过 HTTP 的 Header 传到服务端的,并且也在 URL 中,但和 URI 的解码字符集并不一样,QueryString 的解码字符集要么是 Header 中 ContentType 中定义的 Charset 要么就是默认的 ISO-8859-1,要使用 ContentType 中定义的编码就要设置 connector 的 <Connector URIEncoding=”UTF-8” useBodyEncodingForURI=”true”/> 中的 useBodyEncodingForURI 设置为 true。它并不是对整个 URI 都采用 BodyEncoding 进行解码而仅仅是对 QueryString 使用 BodyEncoding 解码。
POST 方式
POST 表单参数传递方式与 QueryString 不同,它是通过 HTTP 的 BODY 传递到服务端的。当我们在页面上点击 submit 按钮时浏览器首先将根据 ContentType 的 Charset 编码格式对表单填的参数进行编码然后提交到服务器端,在服务器端同样也是用 ContentType 中字符集进行解码。所以通过 POST 表单提交的参数一般不会出现问题,而且这个字符集编码是我们自己设置的,可以通过 request.setCharacterEncoding(charset) 来设置。另外针对 multipart/form-data 类型的参数,也就是上传的文件编码同样也是使用 ContentType 定义的字符集编码,值得注意的地方是上传文件是用字节流的方式传输到服务器的本地临时目录,这个过程并没有涉及到字符编码,而真正编码是在将文件内容添加到 parameters 中,如果用这个编码不能编码时将会用默认编码 ISO-8859-1 来编码。
HTTP上的编解码
当客户端发起一个 HTTP 请求除了上面的 URL 外还可能会在 Header 中传递其它参数如 Cookie、redirectPath,上面讲的body 等,这些用户设置的值很可能也会存在编码问题,Tomcat 对它们又是怎么解码的呢?
header的编解码
对 Header 中的项进行解码也是在调用 request.getHeader 是进行的,如果请求的 Header 项没有解码则调用 MessageBytes 的 toString 方法,这个方法将从 byte 到 char 的转化使用的默认编码也是 ISO-8859-1,而我们也不能设置 Header 的其它解码格式,所以如果你设置 Header 中有非 ASCII 字符解码肯定会有乱码。不要在 Header 中传递非 ASCII 字符,如果一定要传递的话,我们可以先将这些字符用 org.apache.catalina.util.URLEncoder 编码然后再添加到 Header 中,这样在浏览器到服务器的传递过程中就不会丢失信息了,如果我们要访问这些项时再按照相应的字符集解码就好了。
body的编解码
当用户请求的资源已经成功获取后,这些内容将通过 Response 返回给客户端浏览器,这个过程先要经过编码再到浏览器进行解码。这个过程的编解码字符集可以通过 response.setCharacterEncoding 来设置,它将会覆盖 request.getCharacterEncoding 的值,并且通过 Header 的 Content-Type 返回客户端,浏览器接受到返回的 socket 流时将通过 Content-Type 的 charset 来解码,如果返回的 HTTP Header 中 Content-Type 没有设置 charset,那么浏览器将根据 Html 的 <meta HTTP-equiv="Content-Type" content="text/html; charset=GBK" /> 中的 charset 来解码。如果也没有定义的话,那么浏览器将使用默认的编码来解码。
其它需要编码的地方
除了 URL 和参数编码问题外,在服务端还有很多地方可能存在编码,如可能需要读取 xml、velocity 模版引擎、JSP 或者从数据库读取数据等。
xml 文件可以通过设置头来制定编码格式 <?xml version="1.0" encoding="UTF-8"?>
Velocity 模版设置编码格式: services.VelocityService.input.encoding=UTF-8
JSP 设置编码格式: <%@page contentType="text/html; charset=UTF-8"%>
JDBC需与数据库的内置编码保持一致,设置URL来制定如url="jdbc:mysql://localhost:3306/DB?useUnicode=true&characterEncoding=GBK"。
常见问题分析
当我们碰到一些乱码时,应该怎么处理这些问题?出现乱码问题唯一的原因都是在 char 到 byte 或 byte 到 char 转换中编码和解码的字符集不一致导致的,由于往往一次操作涉及到多次编解码,所以出现乱码时很难查找到底是哪个环节出现了问题,下面就几种常见的现象进行分析。
encodeURIComponent编码2次
encodeURIComponent 使用的是 UTF-8 编码规则来编的,如果 request.getParameter(paramName) 时,容器也按 UTF-8 解的话,是正确的.如果 request.getParameter()容器没有按 UTF-8 解的话, 结果就是乱码! 容器按什么编码来解码,决定于 request.setCharacterEncoding().
URLEncoder和URLDecoder这两个类可以将所有“%”加utf-8码值用utf-8解码,从而得到原始值。由于服务器没有设置相应的utf-8编码,默认会用gdk来解码,而gdk对%不能正确解码。两次encodeURIComponent是因为第一次encodeURIComponent的时候出现了"%",这个符号在解析参数的时候是无法解析的,必须把"%"也进行编码,"%"编码后就是"%25",这样就不会出现问题了。
- 第一次编码,你的参数内容便不带有多字节字符了,成了纯粹的 Ascii 字符串。(这里把编第一次的结果叫成 [STR_ENC1] 好了。[STR_ENC1] 是不带有多字节字符的)
- 再编一次后,提交,接收时容器自动解一次 (容器自动解的这一次,不管是按 GBK 还是 UTF-8 还是 ISO-8859-1 都好,都能够正确的得到 [STR_ENC1])
- 然后,再在程序中实现一次 decodeURIComponent (Java中通常使用 java.net.URLDecoder(***, "UTF-8")) 就可以得到想提交的参数的原值。
中文变成了看不懂的字符
例如,字符串“淘!我喜欢!”变成了“Ì Ô £ ¡Î Ò Ï²»¶ £ ¡”编码过程如下图所示
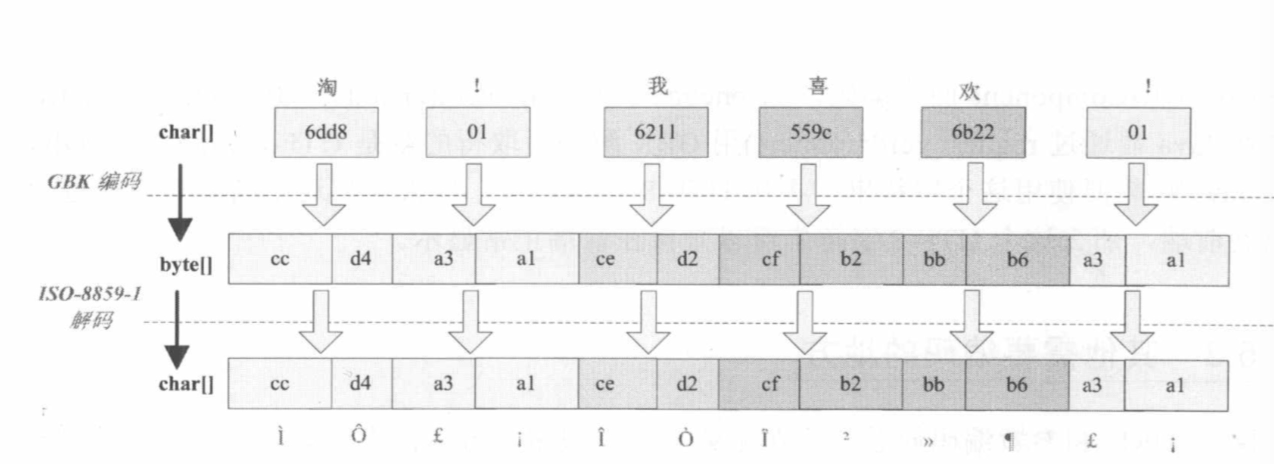
字符串在解码时所用的字符集与编码字符集不一致导致汉字变成了看不懂的乱码,而且是一个汉字字符变成两个乱码字符。
一个汉字变成一个问号
字符串“淘!我喜欢!”变成了“??????”编码过程如下图所示
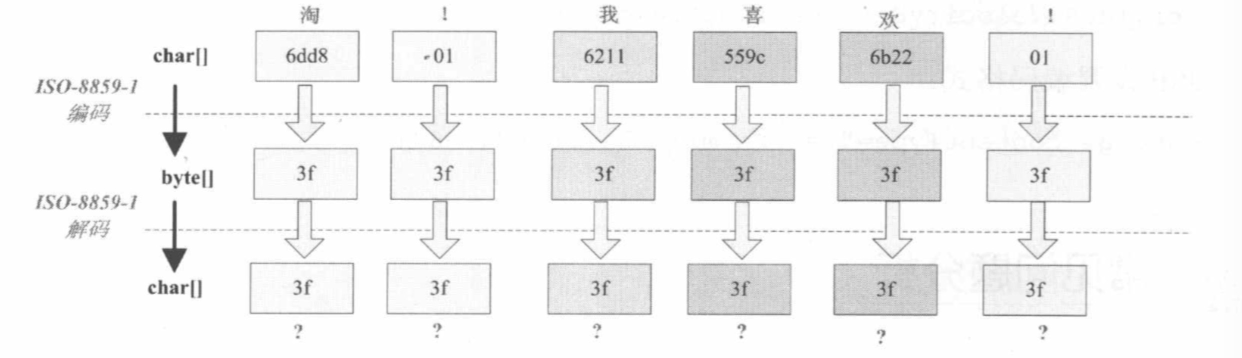
将中文和中文符号经过不支持中文的 ISO-8859-1 编码后,所有字符变成了“?”,这是因为用 ISO-8859-1 进行编解码时遇到不在码值范围内的字符时统一用 3f 表示,这也就是通常所说的“黑洞”,所有 ISO-8859-1 不认识的字符都变成了“?”。
一个汉字变成两个问号
字符串“淘!我喜欢!”变成了“????????????”编码过程如下图所示

这种情况比较复杂,中文经过多次编码,但是其中有一次编码或者解码不对仍然会出现中文字符变成“?”现象,出现这种情况要仔细查看中间的编码环节,找出出现编码错误的地方。