网易云音乐用户画像大数据项目实战
之前本人整理的大多为学习笔记进行知识点的整理,而这篇将会把以前的大部分知识点串联起来,搞一个完整的项目,主要涉及的流程为模拟用户日志数据的生成,ETL以及编写sql分析函数进行最终的APP层数据的生成,由于该项目之前有做过,因此本次会在以前基础上做一些改进,将大数据组件的选型由原来的Hive变为Hive + Spark,提高计算速度,好,现在我们正式开始!
1. 项目整体框架
本人使用的集成开发环境仍然为IntelliJ IDEA,项目的Module取名为"music164",项目的代码所在文件夹以及资源文件夹截图如下所示:
其中项目的pom文件的依赖导入如下所示,同时,由于项目中还涉及到部分scala代码,因此在一开始添加框架支持时不要忘了添加scala插件:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.oldboy</groupId> <artifactId>music164</artifactId> <version>1.0-SNAPSHOT</version> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>6</source> <target>6</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.54</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.44</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.4.3</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.4.3</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.11</artifactId> <version>2.4.3</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>com.maxmind.db</groupId> <artifactId>maxmind-db</artifactId> <version>1.1.0</version> </dependency> </dependencies> </project>
2. 项目代码细节分析
2.1 用户日志数据生成
该项目的第一步将会是生成一份模拟的用户日志数据,这里先做一个简单说明:互联网时代下,数据可谓是无处不在,而如果做一个简单分类,可将日常数据的产生大致分为这几类,客户端产生、手机移动端产生、网页产生等等,而用户无时无刻不在进行的手机屏幕点击事件最终都将变成一条条的数据发送到服务器,而服务器会进行数据的收集、处理以及分析和预测,海量数据就是这样来的,而在本项目中,我们处理的日志数据均为JSON格式的数据(Javascript object notation),下面,我们会先说明这样的数据究竟是如何产生的
2.1.1 各类日志抽象成的java对象
AppBaseLog类:
package com.oldboy.music164.common; import java.io.Serializable; /** * 日志基础类 */ public abstract class AppBaseLog implements Serializable { public static final String LOGTYPE_ERROR = "error"; public static final String LOGTYPE_EVENT = "event"; public static final String LOGTYPE_PAGE = "page"; public static final String LOGTYPE_USAGE = "usage"; public static final String LOGTYPE_STARTUP = "startup"; private String logType; //日志类型 private Long createdAtMs; //日志创建时间 private String deviceId; //设备唯一标识 private String appVersion; //App版本 private String appChannel; //渠道,安装时就在清单中制定了,appStore等。 private String appPlatform; //平台 private String osType; //操作系统 private String deviceStyle; //机型 public String getLogType() { return logType; } public void setLogType(String logType) { this.logType = logType; } public Long getCreatedAtMs() { return createdAtMs; } public void setCreatedAtMs(Long createdAtMs) { this.createdAtMs = createdAtMs; } public String getDeviceId() { return deviceId; } public void setDeviceId(String deviceId) { this.deviceId = deviceId; } public String getAppVersion() { return appVersion; } public void setAppVersion(String appVersion) { this.appVersion = appVersion; } public String getAppChannel() { return appChannel; } public void setAppChannel(String appChannel) { this.appChannel = appChannel; } public String getAppPlatform() { return appPlatform; } public void setAppPlatform(String appPlatform) { this.appPlatform = appPlatform; } public String getOsType() { return osType; } public void setOsType(String osType) { this.osType = osType; } public String getDeviceStyle() { return deviceStyle; } public void setDeviceStyle(String deviceStyle) { this.deviceStyle = deviceStyle; } }
AppErrorLog类:
package com.oldboy.music164.common; /** * errorLog * 分析用户对手机App使用过程中的错误 * 以便对产品进行调整 */ public class AppErrorLog extends AppBaseLog { private String errorBrief; //错误摘要 private String errorDetail; //错误详情 public AppErrorLog() { setLogType(LOGTYPE_ERROR); } public String getErrorBrief() { return errorBrief; } public void setErrorBrief(String errorBrief) { this.errorBrief = errorBrief; } public String getErrorDetail() { return errorDetail; } public void setErrorDetail(String errorDetail) { this.errorDetail = errorDetail; } }
AppEventLog类:
package com.oldboy.music164.common; /** * 应用上报的事件相关信息 */ public class AppEventLog extends AppBaseLog { private String eventId; //事件唯一标识,包括用户对特定音乐的操作,比如分享,收藏,主动播放,听完,跳过,取消收藏,拉黑 private String musicID; //歌曲名称 private String playTime; //什么时刻播放 private String duration; //播放时长,如果播放时长在30s之内则判定为跳过 private String mark; //打分,分享4分,收藏3分,主动播放2分,听完1分,跳过-1分,取消收藏-3, 拉黑-5分 public AppEventLog() { setLogType(LOGTYPE_EVENT); } public String getEventId() { return eventId; } public void setEventId(String eventId) { this.eventId = eventId; } public String getMusicID() { return musicID; } public void setMusicID(String musicID) { this.musicID = musicID; } public String getPlayTime() { return playTime; } public void setPlayTime(String playTime) { this.playTime = playTime; } public String getDuration() { return duration; } public void setDuration(String duration) { this.duration = duration; } public String getMark() { return mark; } public void setMark(String mark) { this.mark = mark; } }
AppPageLog类:
package com.oldboy.music164.common; /** * 应用上报的页面相关信息 */ public class AppPageLog extends AppBaseLog { /* * 一次启动中的页面访问次数(应保证每次启动的所有页面日志在一次上报中,即最后一条上报的页面记录的nextPage为空) */ private int pageViewCntInSession = 0; private String pageId; //页面id private String visitIndex; //访问顺序号,0为第一个页面 private String nextPage; //下一个访问页面,如为空则表示为退出应用的页面 private String stayDurationSecs; //当前页面停留时长 public AppPageLog() { setLogType(LOGTYPE_PAGE); } public int getPageViewCntInSession() { return pageViewCntInSession; } public void setPageViewCntInSession(int pageViewCntInSession) { this.pageViewCntInSession = pageViewCntInSession; } public String getPageId() { return pageId; } public void setPageId(String pageId) { this.pageId = pageId; } public String getNextPage() { return nextPage; } public void setNextPage(String nextPage) { this.nextPage = nextPage; } public String getVisitIndex() { return visitIndex; } public void setVisitIndex(String visitIndex) { this.visitIndex = visitIndex; } public String getStayDurationSecs() { return stayDurationSecs; } public void setStayDurationSecs(String stayDurationSecs) { this.stayDurationSecs = stayDurationSecs; } }
AppStartupLog类:
package com.oldboy.music164.common; /** * 启动日志 */ public class AppStartupLog extends AppBaseLog { private String country; //国家,终端不用上报,服务器自动填充该属性,通过GeoLite private String province; //省份,终端不用上报,服务器自动填充该属性 private String ipAddress; //ip地址 private String network; //网络 private String carrier; //运营商 private String brand; //品牌 private String screenSize; //分辨率 public AppStartupLog() { setLogType(LOGTYPE_STARTUP); } public String getCountry() { return country; } public void setCountry(String country) { this.country = country; } public String getProvince() { return province; } public void setProvince(String province) { this.province = province; } public String getIpAddress() { return ipAddress; } public void setIpAddress(String ipAddress) { this.ipAddress = ipAddress; } public String getNetwork() { return network; } public void setNetwork(String network) { this.network = network; } public String getCarrier() { return carrier; } public void setCarrier(String carrier) { this.carrier = carrier; } public String getBrand() { return brand; } public void setBrand(String brand) { this.brand = brand; } public String getScreenSize() { return screenSize; } public void setScreenSize(String screenSize) { this.screenSize = screenSize; } }
AppUsageLog类:
package com.oldboy.music164.common; /** * 应用上报的使用时长相关信息 */ public class AppUsageLog extends AppBaseLog { private String singleUseDurationSecs; //单次使用时长(秒数),指一次启动内应用在前台的持续时长 private String singleUploadTraffic; //单次使用过程中的上传流量 private String singleDownloadTraffic; //单次使用过程中的下载流量 public AppUsageLog() { setLogType(LOGTYPE_USAGE); } public String getSingleUseDurationSecs() { return singleUseDurationSecs; } public void setSingleUseDurationSecs(String singleUseDurationSecs) { this.singleUseDurationSecs = singleUseDurationSecs; } public String getSingleUploadTraffic() { return singleUploadTraffic; } public void setSingleUploadTraffic(String singleUploadTraffic) { this.singleUploadTraffic = singleUploadTraffic; } public String getSingleDownloadTraffic() { return singleDownloadTraffic; } public void setSingleDownloadTraffic(String singleDownloadTraffic) { this.singleDownloadTraffic = singleDownloadTraffic; } }
AppLogAggEntity类:
简单说明:该类实际上相当于一个聚合体,将所有类型的日志归纳到了一个类中去了,既包含基础信息,又包含各类的以数组形式出现的其他App类
package com.oldboy.music164.common; import java.util.List; /** * App日志聚合体,phone端程序上报日志使用 */ public class AppLogAggEntity { private String deviceId; //设备唯一标识 private String appVersion; //版本 private String appChannel; //渠道,安装时就在清单中制定了,appStore等。 private String appPlatform; //平台 private String osType; //操作系统 private String deviceStyle; //机型 private List<AppStartupLog> appStartupLogs; //启动相关信息的数组 private List<AppPageLog> appPageLogs; //页面跳转相关信息的数组 private List<AppEventLog> appEventLogs; //事件相关信息的数组 private List<AppUsageLog> appUsageLogs; //app使用情况相关信息的数组 private List<AppErrorLog> appErrorLogs; //错误相关信息的数组 public String getDeviceId() { return deviceId; } public void setDeviceId(String deviceId) { this.deviceId = deviceId; } public String getAppVersion() { return appVersion; } public void setAppVersion(String appVersion) { this.appVersion = appVersion; } public String getAppChannel() { return appChannel; } public void setAppChannel(String appChannel) { this.appChannel = appChannel; } public String getAppPlatform() { return appPlatform; } public void setAppPlatform(String appPlatform) { this.appPlatform = appPlatform; } public String getOsType() { return osType; } public void setOsType(String osType) { this.osType = osType; } public String getDeviceStyle() { return deviceStyle; } public void setDeviceStyle(String deviceStyle) { this.deviceStyle = deviceStyle; } public List<AppStartupLog> getAppStartupLogs() { return appStartupLogs; } public void setAppStartupLogs(List<AppStartupLog> appStartupLogs) { this.appStartupLogs = appStartupLogs; } public List<AppPageLog> getAppPageLogs() { return appPageLogs; } public void setAppPageLogs(List<AppPageLog> appPageLogs) { this.appPageLogs = appPageLogs; } public List<AppEventLog> getAppEventLogs() { return appEventLogs; } public void setAppEventLogs(List<AppEventLog> appEventLogs) { this.appEventLogs = appEventLogs; } public List<AppUsageLog> getAppUsageLogs() { return appUsageLogs; } public void setAppUsageLogs(List<AppUsageLog> appUsageLogs) { this.appUsageLogs = appUsageLogs; } public List<AppErrorLog> getAppErrorLogs() { return appErrorLogs; } public void setAppErrorLogs(List<AppErrorLog> appErrorLogs) { this.appErrorLogs = appErrorLogs; } }
2.1.2 JDBC连接池类
由于在项目中,多处需要与关系型数据库进行交互,因此自定义一个JDBC连接池类将有助于优化数据库连接并且有效避免“too many connections”异常的出现,该类使用到的技术点如下:
1.java“懒汉式”单例设计模式
2.使用LinkedList作为数据库连接池技术底层实现
3.线程休眠
4.java接口的匿名内部类实现以及高级特性——callback回调机制
JDBCPool类:
package com.oldboy.music164.jdbc; import com.oldboy.music164.constant.Constants; import com.oldboy.music164.util.PropUtil; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.util.LinkedList; public class JDBCPool { private static JDBCPool instance = null; //实现线程安全 public static JDBCPool getInstance() { if (instance == null) { synchronized (JDBCPool.class) { if (instance == null) { instance = new JDBCPool(); } } } return instance; } //数据库连接池 private LinkedList<Connection> dataSource = new LinkedList<Connection>(); private JDBCPool() { int datasourceSize = PropUtil.getIntValue(Constants.DS_SIZE); String driver = PropUtil.getValue(Constants.JDBC_DRIVER); String url = PropUtil.getValue(Constants.JDBC_URL); String username = PropUtil.getValue(Constants.JDBC_USER); String password = PropUtil.getValue(Constants.JDBC_PASS); for (int i = 0; i < datasourceSize; i++) { try { Class.forName(driver); Connection conn = DriverManager.getConnection(url, username, password); dataSource.push(conn); } catch (Exception e) { e.printStackTrace(); } } } public synchronized Connection getConnection() { while (dataSource.size() == 0) { try { Thread.sleep(10); } catch (Exception e) { e.printStackTrace(); } } return dataSource.poll(); } public void executeQuery(String sql, Object[] params, QueryCallback callback) { Connection conn = null; PreparedStatement ppst = null; ResultSet rs = null; try { conn = getConnection(); ppst = conn.prepareStatement(sql); for (int i = 0; i < params.length; i++) { ppst.setObject(i + 1, params[i]); } rs = ppst.executeQuery(); callback.process(rs); } catch (Exception e) { e.printStackTrace(); }finally { if (conn != null){ dataSource.push(conn); } } } public interface QueryCallback { void process(ResultSet rs) throws Exception; } }
2.1.3 Constants常量类
Constants类:该类定义了一个常量类,将一些诸如数据库连接的驱动,表名,连接池初始化的连接数量等等设置成了一个个的常量,这样在项目进展过程中,如果一部分的配置发生了变化,就不需要每次在代码中做大量更改,而是只需要更改配置文件即可,这样增加了项目的可维护性
package com.oldboy.music164.constant; /* 此类的作用是用来定义一些做数据库连接的常量,而这些常量从配置文件中读取 */ public class Constants { public static final String JDBC_DRIVER = "jdbc.driver"; public static final String JDBC_URL = "jdbc.url"; public static final String JDBC_USER = "jdbc.username"; public static final String JDBC_PASS = "jdbc.password"; public static final String DS_SIZE = "datasource.poolsize"; public static final String MUSIC_TABLENAME = "music.tablename"; }
2.1.4 项目涉及到的所有工具类
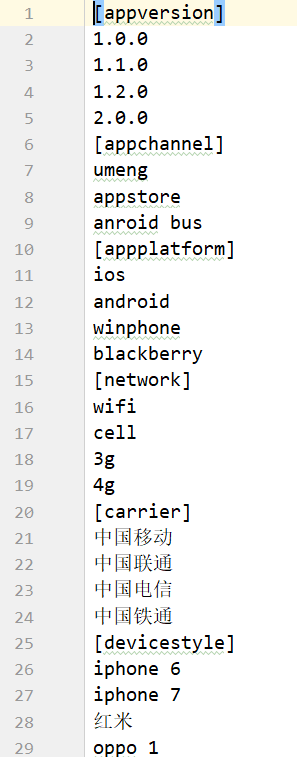
DictUtil类:在资源文件夹中事先已经存入了一个数据字典,在生成数据时,成员变量的取值都会从这个数据字典中随机获取,该数据字典的格式如下所示:
DictUtil类的代码如下所示:
package com.oldboy.music164.util; /* 此类的作用是读取数据字典文件,并从文件中随机获取到一个值作为随机生成的数据 */ import java.io.BufferedReader; import java.io.InputStream; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.HashMap; import java.util.Map; import java.util.Random; public class DictUtil { //先初始化一个字典 private static Map<String, ArrayList<String>> map = new HashMap<String, ArrayList<String>>(); //将dictionary.dat中的数据加载到一个字典中去,并且只加载一次 //因此考虑使用静态代码块的方式实现 static { try { //使用以下固定方法来从资源文件夹中加载数据 InputStream is = Thread.currentThread().getContextClassLoader().getResourceAsStream("dictionary.dat"); BufferedReader br = new BufferedReader(new InputStreamReader(is)); //以下开始将数据放入map中去 String line = null; ArrayList<String> list = null; while((line = br.readLine()) != null){ if(line.startsWith("[")){ list = new ArrayList<String>(); map.put(line.substring(1, line.length() - 1), list); }else{ list.add(line); } } is.close(); br.close(); } catch (Exception e) { } } //再写一个方法从字典中的一个key对应的list中获取到任意的值 public static String getRandomValue(String key){ Random r = new Random(); ArrayList<String> list = map.get(key); //避免出现字典中不存在的值,使用try-catch语句块 try { return list.get(r.nextInt(list.size())); } catch (Exception e) { return null; } } //在生成音乐事件日志中需要使用到,需要区分生成喜欢的和不喜欢的音乐事件 public static String randomValue_positive(){ Random r = new Random(); ArrayList<String> values = map.get("eventid"); if(values == null){ return null; } //0-3 return values.get(r.nextInt(values.size() - 4)); } public static String randomValue_negative(){ Random r = new Random(); ArrayList<String> values = map.get("eventid"); if(values == null){ return null; } //4-7 return values.get(r.nextInt(values.size() - 4) + 4); } }
GenLogTimeUtil类:由于在生成数据时需要大量使用到时间戳,因此此类中专门设定了时间戳生成的逻辑
package com.oldboy.music164.util; /* 此类的作用是用于随机生成一个时间戳 */ import java.text.DecimalFormat; import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.Date; import java.util.Random; public class GenLogTimeUtil { //随机生成某一天的时间戳 //如果是周中,尽量生成13-14点的时间 //而如果是周末,就尽量生成10-11点的时间 public static long genTime(String date){ try { SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); Date d = sdf.parse(date); Calendar calendar = Calendar.getInstance(); calendar.setTime(d); //获取该日期是星期几 int i = calendar.get(Calendar.DAY_OF_WEEK); Random r = new Random(); if(i == 7 || i == 1){ return genWeekendTime(date, r.nextInt(3)); } return genWeekdayTime(date, r.nextInt(3)); } catch (Exception e) { } return 0; } //生成周末的时间戳中的时间部分 private static long genWeekendTime(String date, int i){ Random r = new Random(); String hour; String minute; String newDate; switch (i){ case 0: hour = intFormat(r.nextInt(24)); minute = intFormat(r.nextInt(59)); newDate = date + " " + hour + ":" + minute; return parseTime(newDate); case 1: hour = "10"; minute = intFormat(r.nextInt(59)); newDate = date + " " + hour + ":" + minute; return parseTime(newDate); case 2: hour = intFormat(r.nextInt(24)); minute = intFormat(r.nextInt(59)); newDate = date + " " + hour + ":" + minute; return parseTime(newDate); } return 0; } //生成周中的时间戳的时间部分 private static long genWeekdayTime(String date, int i){ Random r = new Random(); String hour; String minute; String newDate; switch (i){ case 0: hour = intFormat(r.nextInt(24)); minute = intFormat(r.nextInt(59)); newDate = date + " " + hour + ":" + minute; return parseTime(newDate); case 1: hour = "13"; minute = intFormat(r.nextInt(59)); newDate = date + " " + hour + ":" + minute; return parseTime(newDate); case 2: hour = intFormat(r.nextInt(24)); minute = intFormat(r.nextInt(59)); newDate = date + " " + hour + ":" + minute; return parseTime(newDate); } return 0; } //将一个时间串转化为时间戳 private static long parseTime(String newDate){ try { SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm"); Date date = sdf.parse(newDate); return date.getTime(); } catch (Exception e) { } return 0; } //将一个数字转换成00的格式 private static String intFormat(int i){ DecimalFormat df = new DecimalFormat("00"); return df.format(i); } }
MusicTableUtil类:
package com.oldboy.music164.util; /* 此类的作用很简单,就是将所有不同种类的音乐用数字映射出来 */ public class MusicTableUtil { public static String parseTable(int type){ switch (type) { case 1: return "music_mix"; //流行歌曲 case 2: return "music_folk"; //民谣 case 3: return "music_custom"; //古风 case 4: return "music_old"; //老歌 case 5: return "music_rock1"; //欧美摇滚 case 6: return "music_rock2"; //国与摇滚 case 7: return "music_comic"; //二次元 case 8: return "music_yueyu"; //粤语 case 9: return "music_light"; //轻音乐 default: try { throw new Exception("参数必须为1-9"); } catch (Exception e) { e.printStackTrace(); } break; } return null; } }
MusicUtil类:
package com.oldboy.music164.util; /* 此类的作用是连接mysql数据库,并将对应的信息存放在Map中去 */ import com.oldboy.music164.constant.Constants; import com.oldboy.music164.jdbc.JDBCPool; import java.sql.ResultSet; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; public class MusicUtil { public static final Map<String, List<Map<String, String>>> MUSIC_MAP_LIST = new HashMap<String, List<Map<String, String>>>(); //初始化时候,将所有Music信息放在一个Map中 static { JDBCPool pool = JDBCPool.getInstance(); Object[] objs = {}; String tablenames = PropUtil.getValue(Constants.MUSIC_TABLENAME); String[] tablenameArr = tablenames.split(","); for (String tablename : tablenameArr) { final List<Map<String, String>> list = new ArrayList<Map<String, String>>(); pool.executeQuery("select mname,mtime from " + tablename, objs, new JDBCPool.QueryCallback() { @Override public void process(ResultSet rs) throws Exception { while (rs.next()) { Map<String, String> map = new HashMap<String, String>(); map.put("mname", rs.getString("mname")); map.put("mtime", rs.getString("mtime")); list.add(map); } } }); MUSIC_MAP_LIST.put(tablename,list); } } public static final Map<String, String> MARK_MAPPING = new HashMap<String, String>(); static { MARK_MAPPING.put("share", "4"); MARK_MAPPING.put("favourite", "3"); MARK_MAPPING.put("play", "2"); MARK_MAPPING.put("listen", "1"); MARK_MAPPING.put("skip", "-1"); MARK_MAPPING.put("black", "-5"); MARK_MAPPING.put("nofavourite", "-3"); MARK_MAPPING.put("null", "0"); } }
ParseIPUtil类:需要注意的是,由于该类需要使用到解析IP的功能,因此需要从外部导入包com.maxmind.db
package com.oldboy.music164.util; /* 此类的作用是从一个给定的IP地址解析出国家和省份信息 */ import com.fasterxml.jackson.databind.JsonNode; import com.maxmind.db.Reader; import java.io.InputStream; import java.net.InetAddress; import java.util.HashMap; import java.util.Map; public class ParseIPUtil { private static Reader reader; private static Map<String,String> map = new HashMap<String,String>(); static { try { InputStream is = Thread.currentThread().getContextClassLoader().getResourceAsStream("GeoLite2-City.mmdb"); reader = new Reader(is); } catch (Exception e) { } } private static String processIp(String ip){ try { //其中,"country"代表国家,而"subdivisions"代表省份 JsonNode jsonNode = reader.get(InetAddress.getByName(ip)); String country = jsonNode.get("country").get("names").get("zh-CN").asText(); String province = jsonNode.get("subdivisions").get(0).get("names").get("zh-CN").asText(); map.put(ip,country+","+province); } catch (Exception e) { map.put(ip,"unknown,unknown"); } return map.get(ip); } public static String getCountry(String ip){ return processIp(ip).split(",")[0]; } public static String getProvince(String ip){ return processIp(ip).split(",")[1]; } }
PropUtil类:
package com.oldboy.music164.util; /* 此类的作用是从配置文件中获取到连接数据库所需要用到的字符串 */ import java.io.InputStream; import java.util.Properties; public class PropUtil { private static Properties prop; static { try { prop = new Properties(); InputStream is = Thread.currentThread().getContextClassLoader().getResourceAsStream("music.properties"); prop.load(is); } catch (Exception e) { } } public static String getValue(String key){ try { return prop.getProperty(key); } catch (Exception e) { return null; } } public static Integer getIntValue(String key){ try { return Integer.parseInt(prop.getProperty(key)); } catch (Exception e) { return 0; } } }
2.1.5 正式处理业务逻辑,生成数据类
说明:由于项目需要生成大量数据,这就意味着需要给大量的字段赋值,这里使用到了java反射技术,通过反射的方式获取到所有App类的所有字段,并给字段进行赋值
GenLogUtil类:
package com.oldboy.music164.genlog; /* 此类用于生成日志聚合体 */ import com.oldboy.music164.common.AppBaseLog; import com.oldboy.music164.common.AppEventLog; import com.oldboy.music164.util.DictUtil; import com.oldboy.music164.util.GenLogTimeUtil; import com.oldboy.music164.util.MusicTableUtil; import com.oldboy.music164.util.MusicUtil; import java.lang.reflect.Field; import java.util.Map; import java.util.Random; public class GenLogUtil { static Random r = new Random(); public static int type; public static String date; public GenLogUtil(String date) { this.date = date; } public GenLogUtil(int type, String date) { this.type = type; this.date = date; } public static <T> T genLog(Class<T> clazz) throws Exception{ T t1 = clazz.newInstance(); //先赋值数据字典中有的那部分 if(t1 instanceof AppBaseLog){ Field[] fields = clazz.getDeclaredFields(); for (Field field : fields) { //这里需要加一个判断,只有是字符串才给字段赋值 if(field.getType() == String.class){ field.setAccessible(true); field.set(t1, DictUtil.getRandomValue(field.getName().toLowerCase())); } } ((AppBaseLog)t1).setCreatedAtMs(GenLogTimeUtil.genTime(date)); } if(t1 instanceof AppEventLog){ AppEventLog eventLog = (AppEventLog) t1; //设置一个逻辑,如果是0就使用喜欢的音乐,如果是1就使用不喜欢的音乐 switch (r.nextInt(2)) { case 0: genPositive(eventLog); break; case 1: genNegative(eventLog); break; } } return t1; } //生成喜欢的音乐对应的各项参数 private static void genPositive(AppEventLog eventLog){ String table = MusicTableUtil.parseTable(type); String positive = DictUtil.randomValue_positive(); int i = r.nextInt(MusicUtil.MUSIC_MAP_LIST.get(table).size()); Map<String, String> music_time = MusicUtil.MUSIC_MAP_LIST.get(table).get(i); //设置歌曲名称 eventLog.setMusicID(music_time.get("mname")); //设置播放时间和播放时长 if(positive.equals("play") || positive.equals("listen")){ eventLog.setDuration(music_time.get("mtime")); eventLog.setPlayTime(eventLog.getCreatedAtMs() + ""); } //设置事件ID和得分 eventLog.setEventId(positive); eventLog.setMark(MusicUtil.MARK_MAPPING.get(positive)); } //生成不喜欢的音乐对应的各项参数 private static void genNegative(AppEventLog eventLog){ String table = MusicTableUtil.parseTable(type); //negative变量是差评的eventid String negative = DictUtil.randomValue_negative(); int i = r.nextInt(MusicUtil.MUSIC_MAP_LIST.get(table).size()); Map<String, String> music_time = MusicUtil.MUSIC_MAP_LIST.get(table).get(i); //设置歌曲名称 eventLog.setMusicID(music_time.get("mname")); //设置打分 eventLog.setMark(MusicUtil.MARK_MAPPING.get(negative)); //设置播放时间和播放时长 if (negative.equals("skip")) { eventLog.setDuration("00:20"); eventLog.setPlayTime(eventLog.getCreatedAtMs() + ""); } eventLog.setEventId(negative); eventLog.setMark(MusicUtil.MARK_MAPPING.get(negative)); } }
GenLogAgg类:
package com.oldboy.music164.genlog; /* 用来测试生成日志聚合体 */ import com.alibaba.fastjson.JSON; import com.oldboy.music164.common.*; import com.oldboy.music164.util.DictUtil; import java.lang.reflect.Field; import java.util.*; public class GenLogAgg { public static String genLogAgg(int type, String deviceId, String date){ try { Class clazz = AppLogAggEntity.class; Object t1 = clazz.newInstance(); Field[] fields = clazz.getDeclaredFields(); for (Field field : fields) { field.setAccessible(true); field.set(t1, DictUtil.getRandomValue(field.getName().toLowerCase())); } ((AppLogAggEntity) t1).setAppErrorLogs(genLogList(AppErrorLog.class, date, type)); ((AppLogAggEntity) t1).setAppEventLogs(genLogList(AppEventLog.class, date, type)); ((AppLogAggEntity) t1).setAppPageLogs(genLogList(AppPageLog.class, date, type)); ((AppLogAggEntity) t1).setAppStartupLogs(genLogList(AppStartupLog.class, date, type)); ((AppLogAggEntity) t1).setAppUsageLogs(genLogList(AppUsageLog.class, date, type)); ((AppLogAggEntity) t1).setDeviceId(deviceId); return JSON.toJSONString(t1,true); } catch (Exception e) { } return null; } public static <T>List<T> genLogList(Class<T> clazz, String date, int type) throws Exception{ List<T> list = new ArrayList<T>(); Random r = new Random(); if(clazz.equals(AppStartupLog.class)){ for(int i = 0; i < 2; i++){ list.add(new GenLogUtil(date).genLog(clazz)); } } else if(clazz.equals(AppEventLog.class)){ for(int i = 0; i < r.nextInt(10); i++){ list.add(new GenLogUtil(type, date).genLog(clazz)); } } else { for(int i = 0; i < 3; i++){ list.add(new GenLogUtil(date).genLog(clazz)); } } return list; } }
2.1.6 发送数据代码实现
2.1.6.1 发送数据类
DataSender类:该类使用的是之前已经封装好了的功能,进行数据的生成,并且生成的时间设定为2018年12月份一整个月的数据,设定100个用户并且每个用户产生100条日志,总计300,000条日志
package com.oldboy.music164.phone; import com.oldboy.music164.genlog.GenLogAgg; import java.io.OutputStream; import java.net.HttpURLConnection; import java.net.URL; import java.text.DecimalFormat; /** * 模拟音乐手机客户端手机日志生成主类 */ public class DataSender { public static void main(String[] args) throws Exception { DecimalFormat df = new DecimalFormat("00"); //生成2018年12月份1号到30号的日志 for (int i = 1; i <= 30; i++) { genUser(100, "2018-12-" + df.format(i), 100); } } /** * 产生指定日期的日志 * * @param userNum 用户总数 * @param date 指定日期 * @param logNum 每个用户生成日志包数(日志包作为上传到服务端日志的最小单元) */ public static void genUser(int userNum, final String date, final int logNum) { //产生 for (int i = 0; i < userNum; i++) { DecimalFormat df = new DecimalFormat("000000"); final String deviceID = "Device" + df.format(i); //表映射 eg:1 => music_mix,参见TypeUtil final int type = (i % 9) + 1; genData(deviceID, type, date, logNum); } } /** * 为指定用户,根据用户喜欢歌曲类型生成带有音乐偏好的指定数目的日志包 * * @param deviceID 用户id或用户设备id * @param type 用户喜欢歌曲类型 * @param date 指定日期 * @param num 指定用户生成日志包个数 */ public static void genData(String deviceID, int type, String date, int num) { for (int i = 0; i < num; i++) { //生成日志工具类 String logAgg = GenLogAgg.genLogAgg(type, deviceID, date); doSend(logAgg); } } private static void doSend(String json) { try { String strUrl = "http://s201:80"; URL url = new URL(strUrl); HttpURLConnection conn = (HttpURLConnection)url.openConnection(); //设置请求方式 conn.setRequestMethod("POST"); //设置可以传输数据 conn.setDoOutput(true); conn.setRequestProperty("client_time",System.currentTimeMillis() +""); OutputStream os = conn.getOutputStream(); os.write(json.getBytes()); os.flush(); os.close(); System.out.println(conn.getResponseCode()); } catch (Exception e) { e.printStackTrace(); } } }
2.1.6.2 Nginx反向代理服务器搭建
本项目涉及到的主机共有5台,s201-s205,其中,发送数据时会使用到nginx搭建一个反向代理,并将s201作为反向代理服务器,将数据发送到s202-s204三台虚拟机上去,架构如下图所示:
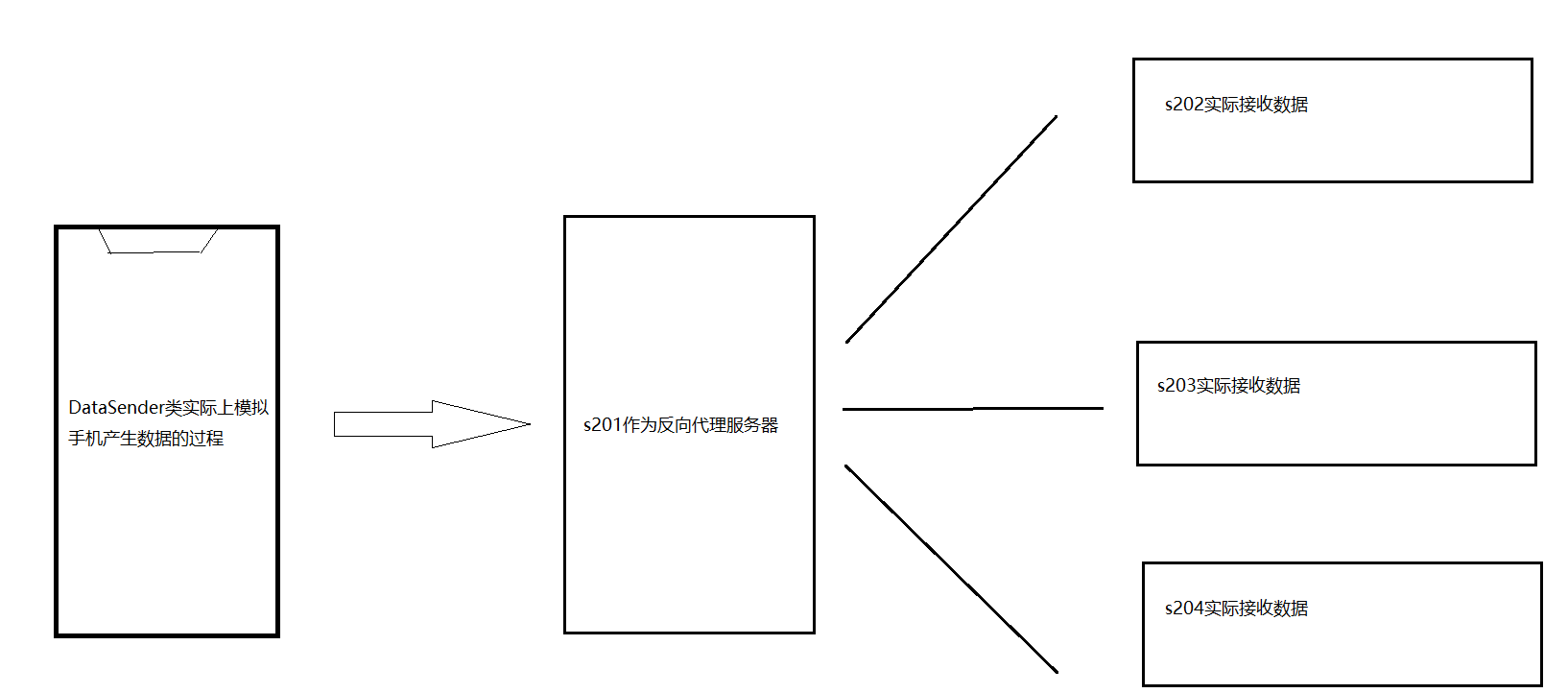
事实上,本项目实际使用到的软件为openresty,本质上就是nginx加上了一堆插件,由于openresty是用C++写的,因此在进行该软件的安装部署时,需要进行编译,安装后,最终软件的目录是在/usr/local/openresty下
s201的配置文件如下,注意,该配置文件只需要指定upstream server即可,需要重点配置的地方为黑体加粗部分,其他地方基本不需要动,s201的nginx.conf文件如下:
worker_processes 4;
events { worker_connections 10240; } http { include mime.types; default_type application/octet-stream;
sendfile on; keepalive_timeout 65; underscores_in_headers on; upstream nginx_server{ server s202:80 max_fails=2 fail_timeout=2 weight=2; server s203:80 max_fails=2 fail_timeout=2 weight=2; server s204:80 max_fails=2 fail_timeout=2 weight=2; } server { listen 80; server_name localhost; #charset koi8-r; #access_log logs/host.access.log main; location / { root html; index index.html index.htm; proxy_pass http://nginx_server; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } # proxy the PHP scripts to Apache listening on 127.0.0.1:80 # #location ~ .php$ { # proxy_pass http://127.0.0.1; #} } }
作为数据实际接收方的s202-s204的配置文件如下所示:
#user nobody; worker_processes 4;
events { worker_connections 10240; } http { include mime.types; default_type application/octet-stream; underscores_in_headers on; log_format main escape=json $msec#$remote_addr#$http_client_time#$status#$request_body; access_log logs/access.log main; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; #gzip on; server { listen 80; server_name localhost; #charset koi8-r; #access_log logs/host.access.log main; location / { root html; index index.html index.htm; error_page 405 =200 $uri; lua_need_request_body on; content_by_lua 'local s = ngx.var.request_body'; } error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } } }
2.1.6.3 日志收集工具Flume的跃点功能实现
说明:至此,nginx反向代理生成数据已经搭建完毕,所有的数据都将会落在s202-s204的 /usr/local/openresty/nginx/logs/access.log文件中,接下去,我们将会使用到Flume作为一个日志的收集工具将所有服务器的数据统一传输到HDFS分布式文件系统上去
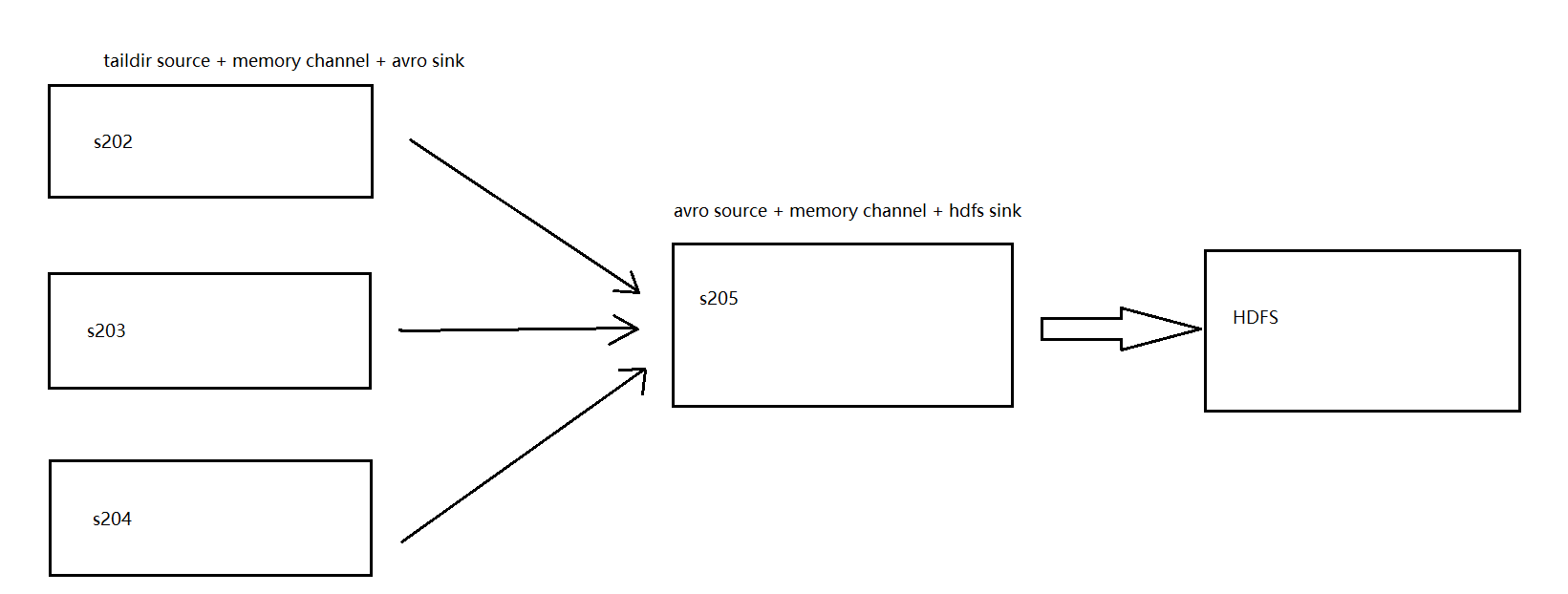
跃点使用时的细节说明:使用Flume将数据上传,这件事本身并不难实现,本人一开始的想法就是通过写多个配置文件,每个配置文件都指定将数据传输到HDFS的某个文件夹上去就行了,而这些文件夹将会以主机名进行命名,但是,这样势必会产生一个问题,最终我们要分析的仍然是全量数据,因此最终还是要将所有数据收集到一块儿去,如果使用这样的架构,每当我们新增一台主机,就需要重新手动进行数据的聚合,这样极大地提高了维护的成本,此问题的发生导致本人进行了一个改进,那就是使用Flume跃点技术,该技术将会使用一台机器充当一个数据的中间层收集端,所有其他机器上的数据都会统一将数据发送给它,然后由它进行最终的统一上传,这样就避免了很多维护带来的问题,中间传输过程,我们在本项目使用的是avro技术,这是一种数据的串行化系统,可以大幅缩短数据的大小以及传输时间,该架构如下图所示:
s202-s204端发送组Flume配置文件,sender.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /usr/local/openresty/nginx/logs/access.log
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.153.205
a1.sinks.k1.port = 4444
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
s205端聚合组Flume配置文件,collector.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4444
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/events/%Y/%m/%d/
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 设置滚动大小
a1.sinks.k1.hdfs.rollSize = 134217728
# 文件如果未激活状态超过60s,则会自动滚动
a1.sinks.k1.hdfs.idleTimeout = 60
# 文件类型 纯文本
a1.sinks.k1.hdfs.fileType = DataStream
# 将间隔滚动设为0
a1.sinks.k1.hdfs.rollInterval = 0
# 单个文件中事件个数
a1.sinks.k1.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.2 项目数据仓库搭建
至此,所有模拟用户生成的原生的log日志文件已经在HDFS的/flume/events/目录下出现,并且还有更细的以年月日为基础的文件夹层次,现在开始进入到整个项目的第二阶段——ETL阶段,即将用户产生的原生数据转化成数据仓库的一张张维表,即从ods层转化为dw层,这里需要特别说明的是,在实际生产环境中,应将hive表构造成分区表,而在本项目中,为演示方便,直接加载一个月的全量数据,因此未使用分区表
ods层建表以及加载数据语句如下:
create table ODS_MUSIC_APP(line String); load data inpath '/flume/events/2020/04/02' into table ODS_MUSIC_APP
dw层建表语句如下,使用了优化的数据格式parquet文件对数据进行列式存储,除此之外,这些DW层的表在设计时还遵循了两大原则:
1.为防止后续出现过多的无谓的连表过程,如device_id, client_ip, log_create_time等公共字段将会出现在所有的表当中
2.所有数据类型全部统一为string,这样省去了之后数据类型转换给开发带来的困扰
-- 创建dw_log_music_error表 create table DW_LOG_MUSIC_ERROR(DEVICE_ID string, DEVICE_MODEL string, CLIENT_IP string, CLIENT_TIME string, SERVER_TIME string, LOG_CREATE_TIME string, ERROR_BRIEF string, ERROR_DETAIL string, APP_VERSION string, APP_STORE string, APP_PLATFORM string, APP_OSTYPE string) row format delimited fields terminated by ' ' lines terminated by ' ' stored as parquet; -- 创建dw_log_music_event表 create table DW_LOG_MUSIC_EVENT(DEVICE_ID string, DEVICE_MODEL string, CLIENT_IP string, CLIENT_TIME string, SERVER_TIME string, LOG_CREATE_TIME string, EVENT_TYPE string, EVENT_MARK string, EVENT_MUSIC string, EVENT_PLAYTIME string, EVENT_DURATION string, APP_VERSION string, APP_STORE string, APP_PLATFORM string, APP_OSTYPE string) row format delimited fields terminated by ' ' lines terminated by ' ' stored as parquet; -- 创建dw_log_music_page表 create table DW_LOG_MUSIC_PAGE(DEVICE_ID string, DEVICE_MODEL string, CLIENT_IP string, CLIENT_TIME string, SERVER_TIME string, LOG_CREATE_TIME string, PAGE_ID string, PAGE_NEXT string, PAGE_VIEW_CNT string, PAGE_DURATION string, PAGE_VISIT_INDEX string, APP_VERSION string, APP_STORE string, APP_PLATFORM string, APP_OSTYPE string) row format delimited fields terminated by ' ' lines terminated by ' ' stored as parquet; -- 创建dw_log_music_startup表 create table DW_LOG_MUSIC_STARTUP(DEVICE_ID string, DEVICE_BRAND string, DEVICE_MODEL string, DEVICE_SCREENSIZE string, DEVICE_CARRIER string, CLIENT_IP string, CLIENT_COUNTRY string, CLIENT_PROVINCE string, CLIENT_TIME string, SERVER_TIME string, LOG_CREATE_TIME string, CLIENT_NETWORK string, APP_VERSION string, APP_STORE string, APP_PLATFORM string, APP_OSTYPE string) row format delimited fields terminated by ' ' lines terminated by ' ' stored as parquet; - 创建dw_log_music_usage表 create table DW_LOG_MUSIC_USAGE(DEVICE_ID string, DEVICE_MODEL string, CLIENT_IP string, CLIENT_TIME string, SERVER_TIME string, LOG_CREATE_TIME string, APP_VERSION string, APP_STORE string, APP_PLATFORM string, APP_OSTYPE string, ONCE_USE_DURATION string, ONCE_UPLOAD_TRAFFIC string, ONCE_DOWNLOAD_TRAFFIC string) row format delimited fields terminated by ' ' lines terminated by ' ' stored as parquet;
至此,原表以及目标表都已经创建完成,之后我们只需要集中精力完成数据的ETL过程即可,注意,在此过程中会涉及到JSON串的解析,因此需要导入阿里的fast json包,并注意将其放入spark的lib文件夹下(第三方包)
ETL过程思路详解:本人在第一次做这个项目时,仅仅使用了hive,当时java频繁gc导致出现了OOM以及速度慢等问题,因此本次进行升级,改用hive + spark这样的架构,更为稳定,也提升了速度,我们的思路是直接使用spark读取HDFS文件并将其转化为rdd,再使用scala的隐式转换包将rdd转化为Dataframe,最后通过spark sql完成整个过程;而在使用fastjson解析日志时,则将日志的层次结构划分成了0、1、2这三个层级,并将这些层级结构记录在了mysql的table_shadow数据库中,建库建表语句如下所示:
/* Navicat Premium Data Transfer Source Server : big13 Source Server Type : MySQL Source Server Version : 50724 Source Host : localhost:3306 Source Schema : table_shadow Target Server Type : MySQL Target Server Version : 50724 File Encoding : 65001 Date: 15/01/2019 18:10:52 */ SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- create the database create database table_shadow; -- ---------------------------- -- Table structure for music_log_error -- ---------------------------- DROP TABLE IF EXISTS `music_log_error`; CREATE TABLE `music_log_error` ( `id` int(10) NOT NULL AUTO_INCREMENT, `table_key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `type` int(10) NOT NULL COMMENT 'key在日志串中的位置,client_time#{appErrorLogs:{errorBrief:xxx}}#', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 13 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of music_log_error -- ---------------------------- INSERT INTO `music_log_error` VALUES (1, 'appErrorLogs', 'deviceId', 1); INSERT INTO `music_log_error` VALUES (2, 'appErrorLogs', 'deviceStyle', 1); INSERT INTO `music_log_error` VALUES (3, 'appErrorLogs', 'remote_addr', 0); INSERT INTO `music_log_error` VALUES (4, 'appErrorLogs', 'http_client_time', 0); INSERT INTO `music_log_error` VALUES (5, 'appErrorLogs', 'msec', 0); INSERT INTO `music_log_error` VALUES (6, 'appErrorLogs', 'createdAtMs', 2); INSERT INTO `music_log_error` VALUES (7, 'appErrorLogs', 'errorBrief', 2); INSERT INTO `music_log_error` VALUES (8, 'appErrorLogs', 'errorDetail', 2); INSERT INTO `music_log_error` VALUES (9, 'appErrorLogs', 'appVersion', 1); INSERT INTO `music_log_error` VALUES (10, 'appErrorLogs', 'appChannel', 1); INSERT INTO `music_log_error` VALUES (11, 'appErrorLogs', 'appPlatform', 1); INSERT INTO `music_log_error` VALUES (12, 'appErrorLogs', 'osType', 1); -- ---------------------------- -- Table structure for music_log_event -- ---------------------------- DROP TABLE IF EXISTS `music_log_event`; CREATE TABLE `music_log_event` ( `id` int(10) NOT NULL AUTO_INCREMENT, `table_key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `type` int(10) NOT NULL COMMENT 'key在日志串中的位置,client_time#{appErrorLogs:{errorBrief:xxx}}#', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 16 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of music_log_event -- ---------------------------- INSERT INTO `music_log_event` VALUES (1, 'appEventLogs', 'deviceId', 1); INSERT INTO `music_log_event` VALUES (2, 'appEventLogs', 'deviceStyle', 1); INSERT INTO `music_log_event` VALUES (3, 'appEventLogs', 'remote_addr', 0); INSERT INTO `music_log_event` VALUES (4, 'appEventLogs', 'http_client_time', 0); INSERT INTO `music_log_event` VALUES (5, 'appEventLogs', 'msec', 0); INSERT INTO `music_log_event` VALUES (6, 'appEventLogs', 'createdAtMs', 2); INSERT INTO `music_log_event` VALUES (7, 'appEventLogs', 'eventId', 2); INSERT INTO `music_log_event` VALUES (8, 'appEventLogs', 'mark', 2); INSERT INTO `music_log_event` VALUES (9, 'appEventLogs', 'musicID', 2); INSERT INTO `music_log_event` VALUES (10, 'appEventLogs', 'playTime', 2); INSERT INTO `music_log_event` VALUES (11, 'appEventLogs', 'duration', 2); INSERT INTO `music_log_event` VALUES (12, 'appEventLogs', 'appVersion', 1); INSERT INTO `music_log_event` VALUES (13, 'appEventLogs', 'appChannel', 1); INSERT INTO `music_log_event` VALUES (14, 'appEventLogs', 'appPlatform', 1); INSERT INTO `music_log_event` VALUES (15, 'appEventLogs', 'osType', 1); -- ---------------------------- -- Table structure for music_log_page -- ---------------------------- DROP TABLE IF EXISTS `music_log_page`; CREATE TABLE `music_log_page` ( `id` int(10) NOT NULL AUTO_INCREMENT, `table_key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `type` int(10) NOT NULL COMMENT 'key在日志串中的位置,client_time#{appErrorLogs:{errorBrief:xxx}}#', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 16 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of music_log_page -- ---------------------------- INSERT INTO `music_log_page` VALUES (1, 'appPageLogs', 'deviceId', 1); INSERT INTO `music_log_page` VALUES (2, 'appPageLogs', 'deviceStyle', 1); INSERT INTO `music_log_page` VALUES (3, 'appPageLogs', 'remote_addr', 0); INSERT INTO `music_log_page` VALUES (4, 'appPageLogs', 'http_client_time', 0); INSERT INTO `music_log_page` VALUES (5, 'appPageLogs', 'msec', 0); INSERT INTO `music_log_page` VALUES (6, 'appPageLogs', 'createdAtMs', 2); INSERT INTO `music_log_page` VALUES (7, 'appPageLogs', 'pageId', 2); INSERT INTO `music_log_page` VALUES (8, 'appPageLogs', 'nextPage', 2); INSERT INTO `music_log_page` VALUES (9, 'appPageLogs', 'pageViewCntInSession', 1); INSERT INTO `music_log_page` VALUES (10, 'appPageLogs', 'stayDurationSecs', 1); INSERT INTO `music_log_page` VALUES (11, 'appPageLogs', 'visitIndex', 1); INSERT INTO `music_log_page` VALUES (12, 'appPageLogs', 'appVersion', 1); INSERT INTO `music_log_page` VALUES (13, 'appPageLogs', 'appChannel', 1); INSERT INTO `music_log_page` VALUES (14, 'appPageLogs', 'appPlatform', 1); INSERT INTO `music_log_page` VALUES (15, 'appPageLogs', 'osType', 1); -- ---------------------------- -- Table structure for music_log_startup -- ---------------------------- DROP TABLE IF EXISTS `music_log_startup`; CREATE TABLE `music_log_startup` ( `id` int(10) NOT NULL AUTO_INCREMENT, `table_key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `type` int(10) NOT NULL COMMENT 'key在日志串中的位置,client_time#{appErrorLogs:{errorBrief:xxx}}#', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 18 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of music_log_startup -- ---------------------------- INSERT INTO `music_log_startup` VALUES (1, 'appStartupLogs', 'deviceId', 1); INSERT INTO `music_log_startup` VALUES (2, 'appStartupLogs', 'brand', 2); INSERT INTO `music_log_startup` VALUES (3, 'appStartupLogs', 'deviceStyle', 1); INSERT INTO `music_log_startup` VALUES (4, 'appStartupLogs', 'screenSize', 2); INSERT INTO `music_log_startup` VALUES (5, 'appStartupLogs', 'carrier', 2); INSERT INTO `music_log_startup` VALUES (6, 'appStartupLogs', 'remote_addr', 0); INSERT INTO `music_log_startup` VALUES (7, 'appStartupLogs', 'country', 1); INSERT INTO `music_log_startup` VALUES (8, 'appStartupLogs', 'province', 1); INSERT INTO `music_log_startup` VALUES (9, 'appStartupLogs', 'http_client_time', 0); INSERT INTO `music_log_startup` VALUES (10, 'appStartupLogs', 'msec', 0); INSERT INTO `music_log_startup` VALUES (11, 'appStartupLogs', 'createdAtMs', 2); INSERT INTO `music_log_startup` VALUES (12, 'appStartupLogs', 'network', 2); INSERT INTO `music_log_startup` VALUES (13, 'appStartupLogs', 'appVersion', 1); INSERT INTO `music_log_startup` VALUES (14, 'appStartupLogs', 'appstore', 1); INSERT INTO `music_log_startup` VALUES (15, 'appStartupLogs', 'appPlatform', 1); INSERT INTO `music_log_startup` VALUES (16, 'appStartupLogs', 'osType', 1); -- ---------------------------- -- Table structure for music_log_usage -- ---------------------------- DROP TABLE IF EXISTS `music_log_usage`; CREATE TABLE `music_log_usage` ( `id` int(10) NOT NULL AUTO_INCREMENT, `table_key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `type` int(10) NOT NULL COMMENT 'key在日志串中的位置,client_time#{appUsageLogs:{errorBrief:xxx}}#', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 14 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of music_log_usage -- ---------------------------- INSERT INTO `music_log_usage` VALUES (1, 'appUsageLogs', 'deviceId', 1); INSERT INTO `music_log_usage` VALUES (2, 'appUsageLogs', 'deviceStyle', 1); INSERT INTO `music_log_usage` VALUES (3, 'appUsageLogs', 'remote_addr', 0); INSERT INTO `music_log_usage` VALUES (4, 'appUsageLogs', 'http_client_time', 0); INSERT INTO `music_log_usage` VALUES (5, 'appUsageLogs', 'msec', 0); INSERT INTO `music_log_usage` VALUES (6, 'appUsageLogs', 'createdAtMs', 2); INSERT INTO `music_log_usage` VALUES (7, 'appUsageLogs', 'singleDownloadTraffic', 2); INSERT INTO `music_log_usage` VALUES (8, 'appUsageLogs', 'singleUploadTraffic', 2); INSERT INTO `music_log_usage` VALUES (9, 'appUsageLogs', 'singleUseDurationSecs', 2); INSERT INTO `music_log_usage` VALUES (10, 'appUsageLogs', 'appVersion', 1); INSERT INTO `music_log_usage` VALUES (11, 'appUsageLogs', 'appChannel', 1); INSERT INTO `music_log_usage` VALUES (12, 'appUsageLogs', 'appPlatform', 1); INSERT INTO `music_log_usage` VALUES (13, 'appUsageLogs', 'osType', 1); SET FOREIGN_KEY_CHECKS = 1;
最终ETL的scala代码如下所示:
package com.oldboy.music164.odsdw /* 此类的作用是ETL,通过解析JSON串将数据从ODS导入到DW */ import java.sql.DriverManager import com.alibaba.fastjson.{JSON, JSONObject} import com.oldboy.music164.util.ParseIPUtil import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession import scala.collection.mutable.ListBuffer object GenDW { def main(args: Array[String]): Unit = { //将HDFS文件夹下所有文件/flume/events/2020/04/02写入到Hive的所有表中去 val conf = new SparkConf() conf.setAppName("spark_dw") conf.setMaster("spark://s201:7077") val spark = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate() val rdd1 = spark.sparkContext.textFile("hdfs:///flume/events/2020/04/02") val tablelist = Array[String]("music_log_error", "music_log_event", "music_log_page", "music_log_startup", "music_log_usage") spark.sql("use music164") import spark.implicits._ for(table <- tablelist){ if(table.equals("music_log_error")){ val df = rdd1.map(e => parseErrorLog(table, e)).toDF() df.createOrReplaceTempView("v1") spark.sql("insert into dw_log_music_error select * from v1") } if(table.equals("music_log_event")){ val df = rdd1.map(e => parseEventLog(table, e)).toDF() df.createOrReplaceTempView("v1") spark.sql("insert into dw_log_music_event select * from v1") } if(table.equals("music_log_page")){ val df = rdd1.map(e => parsePageLog(table, e)).toDF() df.createOrReplaceTempView("v1") spark.sql("insert into dw_log_music_page select * from v1") } if(table.equals("music_log_startup")){ val df = rdd1.map(e => parseStartupLog(table, e)).toDF() df.createOrReplaceTempView("v1") spark.sql("insert into dw_log_music_startup select * from v1") } if(table.equals("music_log_usage")){ val df = rdd1.map(e => parseUsageLog(table, e)).toDF() df.createOrReplaceTempView("v1") spark.sql("insert into dw_log_music_usage select * from v1") } } } def parseJson(tableName : String, line : String) : ListBuffer[String] = { val buf = new ListBuffer[String] val res = line.replaceAll("\\n", "").replaceAll("\\t", "").replaceAll("\\", "") val jsonString = res.split("#")(4) val jo = JSON.parseObject(jsonString) //单独写一个逻辑用来处理startuplog的数据 if(tableName.equals("music_log_startup")){ val JArray = jo.getJSONArray("appStartupLogs") val jo1: JSONObject = JArray.get(0).asInstanceOf[JSONObject] buf.append(jo.getString("deviceId")) buf.append(jo1.getString("brand")) buf.append(jo.getString("deviceStyle")) buf.append(jo1.getString("screenSize")) buf.append(jo1.getString("carrier")) buf.append(res.split("#")(1)) buf.append(ParseIPUtil.getCountry(res.split("#")(1))) buf.append(ParseIPUtil.getProvince(res.split("#")(1))) buf.append(res.split("#")(2)) buf.append(res.split("#")(0)) buf.append(jo1.getString("createdAtMs")) buf.append(jo1.getString("network")) buf.append(jo.getString("appVersion")) buf.append("null") buf.append(jo.getString("appPlatform")) buf.append(jo.getString("osType")) }else{ val url = "jdbc:mysql://s201:3306/table_shadow" val username = "root" val password = "root" val conn = DriverManager.getConnection(url, username, password) val stmt = conn.createStatement() val rs = stmt.executeQuery("select * from " + tableName) while (rs.next()) { val table_key = rs.getString("table_key") val field_name = rs.getString("field_name") val field_type = rs.getInt("field_type") //根据field_type所提供的层级信息来判断如何对该字符串进行截取 if (field_type == 0) { if (field_name == "msec") { buf.append(res.split("#")(0)) } if (field_name == "remote_addr") { buf.append(res.split("#")(1)) } if (field_name == "http_client_time") { buf.append(res.split("#")(2)) } } if (field_type == 1) { if(jo.getString(field_name) == null){ buf.append("null") }else{ buf.append(jo.getString(field_name)) } } if (field_type == 2) { val JArray = jo.getJSONArray(table_key) if (JArray != null && JArray.size() > 0) { //进行判断,只有当arr中有元素的时候,我们才进行后续操作,并且我们默认拿出第一个索引 //进行判断,出现null的时候用空值填充 val jo1: JSONObject = JArray.get(0).asInstanceOf[JSONObject] if(jo1.getString(field_name) == null){ buf.append("null") }else{ buf.append(jo1.getString(field_name)) } } } } conn.close() } buf } //由于scala中Tuple必须先指定元组中元素的个数,因此需要定义多个函数进行转换 def parseErrorLog(tableName : String, line : String) : Tuple12[String,String,String,String, String,String,String,String,String,String,String,String] = { val buf = parseJson(tableName, line) if(buf.size == 12){ val tuple = Tuple12[String,String,String,String,String,String,String,String,String, String,String,String](buf(0),buf(1),buf(2),buf(3),buf(4),buf(5),buf(6),buf(7),buf(8), buf(9),buf(10),buf(11)) tuple }else{ val tuple = Tuple12[String,String,String,String,String,String,String,String,String, String,String,String]("null","null","null","null","null","null","null","null", "null","null","null","null") tuple } } def parseEventLog(tableName : String, line : String) : Tuple15[String,String,String,String, String,String,String,String,String,String,String,String,String,String,String] = { val buf = parseJson(tableName, line) if(buf.size == 15){ val tuple = Tuple15[String,String,String,String,String,String,String,String,String, String,String,String,String,String,String](buf(0),buf(1),buf(2),buf(3),buf(4),buf(5),buf(6),buf(7),buf(8), buf(9),buf(10),buf(11),buf(12),buf(13),buf(14)) tuple }else{ val tuple = Tuple15[String,String,String,String,String,String,String,String,String, String,String,String,String,String,String]("null","null","null","null","null","null","null","null", "null","null","null","null","null","null","null") tuple } } def parsePageLog(tableName : String, line : String) : Tuple15[String,String,String,String, String,String,String,String,String,String,String,String,String,String,String] = { val buf = parseJson(tableName, line) if(buf.size == 15){ val tuple = Tuple15[String,String,String,String,String,String,String,String,String, String,String,String,String,String,String](buf(0),buf(1),buf(2),buf(3),buf(4),buf(5),buf(6),buf(7),buf(8), buf(9),buf(10),buf(11),buf(12),buf(13),buf(14)) tuple }else{ val tuple = Tuple15[String,String,String,String,String,String,String,String,String, String,String,String,String,String,String]("null","null","null","null","null","null","null","null", "null","null","null","null","null","null","null") tuple } } def parseStartupLog(tableName : String, line : String) : Tuple16[String,String,String,String, String,String,String,String,String,String,String,String,String,String,String,String] = { val buf = parseJson(tableName, line) if(buf.size == 16){ val tuple = Tuple16[String,String,String,String,String,String,String,String,String, String,String,String,String,String,String,String](buf(0),buf(1),buf(2),buf(3),buf(4),buf(5),buf(6),buf(7),buf(8), buf(9),buf(10),buf(11),buf(12),buf(13),buf(14),buf(15)) tuple }else{ val tuple = Tuple16[String,String,String,String,String,String,String,String,String, String,String,String,String,String,String,String]("null","null","null","null","null","null", "null","null","null","null","null","null","null","null","null","null") tuple } } def parseUsageLog(tableName : String, line : String) : Tuple13[String,String,String,String, String,String,String,String,String,String,String,String,String] = { val buf = parseJson(tableName, line) if(buf.size == 13){ val tuple = Tuple13[String,String,String,String,String,String,String,String,String, String,String,String,String](buf(0),buf(1),buf(2),buf(3),buf(4),buf(5),buf(6),buf(7),buf(8), buf(9),buf(10),buf(11),buf(12)) tuple }else{ val tuple = Tuple13[String,String,String,String,String,String,String,String,String, String,String,String,String]("null","null","null","null","null","null","null","null", "null","null","null","null","null") tuple } } }
除此之外,原本存放于mysql数据库的两张表user以及music也需要通过sqoop转到Hive中去,脚本如下:
sqoop import --connect jdbc:mysql://192.168.153.201:3306/big14 --username root --password root --table user --hive-import --create-hive-table --hive-table users --hive-database music164 --delete-target-dir --fields-terminated-by ' ' --lines-terminated-by '
' -m 1
sqoop import --connect jdbc:mysql://192.168.153.201:3306/big14 --username root --password root --table music --hive-import --create-hive-table --hive-table music --hive-database music164 --delete-target-dir --fields-terminated-by ' ' --lines-terminated-by '
' -m 1
其中,由于表格user与系统中的user表重名,为避免报错,使用如下设置,但是建议不要使用user作为自定义表名,建议更改为"users"
set hive.support.sql11.reserved.keywords = false ;
至此,DW层的所有表全部ETL完成!!!
最终使用IDEA对项目进行打包,然后使用spark-submit命令提交到集群上运行即可,提交脚本如下所示:
spark-submit --master spark://s201:7077 --class com.oldboy.music164.odsdw.GenDW /home/centos/music164.jar
2.3 APP层数据搭建——各项业务指标分析
业务需求:
1.活跃度:
计算指标是以活跃度指数计算的
计算每个用户的:播放次数 + 收藏数量 x 2 + 日均播放时长 = 活跃度指数
根据活跃度指数将所有的数值划分为10档,分数为0-100分
日均播放时长计算方式改进:正常计算该指标的方式应为先计算出一个月的某个用户的总播放时长,然后除以天数即可,然而这会导致一个问题,那就是当某用户在一个月的某几天播放时长特别高而在剩余天数里播放时长几乎为零时,他的平均值计算出来有可能是和每天播放时长都一样的用户是一样的,因此本人改进了计算方式,将播放时长的波动情况,即标准差看成是一个惩罚,将平均值除以这个标准差,这样对于每天坚持听歌的用户来说就更为公平了
2.音乐风格排行榜:
统计每个用户最喜欢的音乐风格的前十名
3.歌手榜
统计每个用户最喜欢的歌手的前十名
4.歌曲榜
统计每个用户最喜欢的歌曲的前十名
5.周中播放时刻倾向
统计周中(即周一至周五)每个用户最喜欢的播放时刻的前十名
6.周末播放时刻倾向
统计周末(即双休日)每个用户最喜欢的播放时刻的前十名
7.播放语言击败用户百分比
根据每个用户的每种播放语言统计各自超过了其他百分之多少的用户
8.付费度
统计付费用户击败其他用户的百分比
最终代码实现如下所示,其中,在从一个时间戳解析出周中还是周末中使用了spark的udf注册函数:
GenApp.scala
package com.oldboy.music164.odsdw import java.util.{Calendar, Date} import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession object GenApp { def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setAppName("spark_dw") conf.setMaster("spark://s201:7077") val spark = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate() //使用spark注册周中或周末函数 spark.udf.register("dayofweek_type", (time : Long) => { val d = new Date(time) val calendar = Calendar.getInstance() calendar.setTime(d) val i = calendar.get(Calendar.DAY_OF_WEEK) if(i == 1 || i == 7){ "weekend" } else{ "weekday" } }) spark.sql("use music164") //1.将数据转储入活跃度统计表 spark.sql("create table if not exists APP_ACTIVE(DEVICE_ID string,ACTIVE_LEVEL int ) stored as parquet") spark.sql("insert overwrite table APP_ACTIVE select device_id, if(activity = 0, 0, ntile(10)over(order by activity) * 10) as active_level from (select device_id, (play_count + fav_count * 2 + daily_avg) as activity from (select play_sum.device_id, play_count, fav_count, daily_avg from (select device_id, count(*) as play_count from dw_log_music_event where event_mark = '1' or event_mark = '2' group by device_id) play_sum full outer join (select device_id, count(*) as fav_count from dw_log_music_event where event_mark = '3' group by device_id) fav_sum on play_sum.device_id = fav_sum.device_id full outer join (select device_id, (play_avg / play_stddev) as daily_avg from (select device_id, avg(play_day_sum) as play_avg, stddev_pop(play_day_sum) as play_stddev from (select device_id, day, sum(play_time) as play_day_sum from (select device_id, from_unixtime(cast(substr(log_create_time, 1, 10) as bigint), 'dd') as day, if(event_duration = 'null', 0, cast(split(event_duration,":")[0] as double) + cast(split(event_duration,":")[1] as double) / 60) as play_time from dw_log_music_event where device_id <> 'null' and from_unixtime(cast(substr(log_create_time, 1, 10) as bigint), 'yyyy') = 2018 and from_unixtime(cast(substr(log_create_time, 1, 10) as bigint), 'MM') = 12) a group by device_id, day) b group by device_id) c) d on play_sum.device_id = d.device_id) e) f") //2.将数据转储入音乐风格表 spark.sql("create table if not exists APP_MUSIC_TYPE(DEVICE_ID string,MUSIC_TYPE string,MUSIC_TYPE_COUNT int)stored as parquet") spark.sql("insert into APP_MUSIC_TYPE select device_id, style, count from (select device_id, style, count, row_number()over(partition by device_id order by count desc) as rank from (select device_id, style, count from (select device_id, style, count(style) as count from (select b.device_id, b.event_music, a.style from (select mname, style from music lateral view explode(split(mstyle, '\\|')) xxx as style) a, dw_log_music_event b where a.mname = b.event_music and b.event_mark > 0) c group by device_id, style) d order by device_id, count desc) e) f where rank < 11") //3.将数据转储入歌手榜 spark.sql("create table if not exists APP_FAVOURITE_SINGER(DEVICE_ID string,MUSIC_SINGER string,SINGER_RANK string) stored as parquet") spark.sql("insert overwrite table APP_FAVOURITE_SINGER select device_id,msinger,SINGER_RANK from (select device_id,msinger,cnt,row_number() over(partition by device_id order by cnt desc) SINGER_RANK from (select a.device_id, b.msinger,count(*) cnt from dw_log_music_event a join music b on a.event_music = b.mname and event_mark in ('4','3','2','1') group by a.device_id, b.msinger) c) d where SINGER_RANK < 11") //4.将数据转储入歌曲榜 spark.sql("create table if not exists APP_FAVOURITE_SONG(DEVICE_ID string,MUSIC_NAME string,MUSIC_RANK string) stored as parquet") spark.sql("insert overwrite table APP_FAVOURITE_SONG select DEVICE_ID,event_music,music_rank from (select DEVICE_ID, event_music, row_number()over(partition by DEVICE_ID order by count desc) as music_rank from (select DEVICE_ID, event_music, count(event_music) as count from (select DEVICE_ID, event_music from dw_log_music_event where event_mark in ('4','3','2','1') and event_music <> 'null') a group by DEVICE_ID,event_music) b) c where music_rank <11") //5.周中播放时刻倾向 spark.sql("create table if not exists APP_MUSIC_PLAY_WORKTIME(DEVICE_ID string,TIME string,TIME_RANK int)stored as parquet") spark.sql("insert overwrite table APP_MUSIC_PLAY_WORKTIME select device_id, day_hour, count from (select device_id, day_hour, count, row_number()over(partition by device_id order by count desc) as rank from (select device_id, day_hour, count(*) as count from (select device_id, dayofweek_type(event_playtime) as day_type, from_unixtime(cast(substr(event_playtime, 1, 10) as bigint), 'HH') as day_hour from dw_log_music_event where event_playtime <> 'null') a where day_type = 'weekday' group by device_id, day_hour) b) c where rank < 11") //6.周末播放时刻倾向 spark.sql("create table if not exists APP_MUSIC_PLAY_WEEKEND(DEVICE_ID string,TIME string,TIME_RANK int)stored as parquet") spark.sql("insert overwrite table APP_MUSIC_PLAY_WEEKEND select device_id, day_hour, count from (select device_id, day_hour, count, row_number()over(partition by device_id order by count desc) as rank from (select device_id, day_hour, count(*) as count from (select device_id, dayofweek_type(event_playtime) as day_type, from_unixtime(cast(substr(event_playtime, 1, 10) as bigint), 'HH') as day_hour from dw_log_music_event where event_playtime <> 'null') a where day_type = 'weekend' group by device_id, day_hour) b) c where rank < 11") //7.播放语言百分比 spark.sql("create table if not exists APP_MUSIC_LANGUAGE_PERCENTAGE(DEVICE_ID string, MUSIC_LANGUAGE string, COUNT int, PERCENTAGE double) stored as parquet") spark.sql("insert overwrite table APP_MUSIC_LANGUAGE_PERCENTAGE select device_id, MUSIC_LANGUAGE, COUNT, cume_dist()over(partition by MUSIC_LANGUAGE order by COUNT) as cum from (select device_id , MUSIC_LANGUAGE,count(*) as count from (select device_id,mlanguage as MUSIC_LANGUAGE from music join dw_log_music_event where event_music = mname and event_mark in ('4','3','2','1')) a group by device_id, MUSIC_LANGUAGE) b") //8.付费度 spark.sql("create table if not exists APP_MUSIC_PAY(DEVICE_ID string, PAYMENT string) stored as parquet") spark.sql("insert overwrite table APP_MUSIC_PAY select device_id, cume_dist()over(order by cnt)*100 from (select a.device_id, count(*) cnt from dw_log_music_event a join music b on a.event_music = b.mname and event_mark in ('4','3','2','1') and misfree=1 group by a.device_id ) c") } }
将该应用程序提交到spark集群的脚本如下:
spark-submit --master spark://s201:7077 --class com.oldboy.music164.odsdw.GenApp /home/centos/music164.jar
最终Hive的表结构如下所示:
至此,大数据开发部分全部完成!!!接下去只需和前端开发人员对接,商讨数据可视化方案即可,由于此部分内容已经超出了本文讨论范畴,因此不再描述
3. 项目优缺点讨论
技术可以改变时间,但是技术也不是万能的,但是将合适的技术用在合适的地方就能最大化的发挥技术的优势,做项目也是一样,知道项目的优势在哪儿,劣势在哪儿,就能因地制宜,真正帮助企业解决问题,发现问题,那么接下去,本人将会罗列以下本项目的优势和劣势:
项目优势
架构优势
Flume中:
1、基于HDFS块大小,设定Flume上传单个文件大小
2、使用容灾措施,避免丢失数据
3、使用跃点,统一对数据进行上传,避免多用户写入
Hive + Spark中:
1、清晰数据结构
2、减少重复开发
3、统一数据接口
4、复杂问题简单化
5、Spark运行速度快
成本优势
开源框架降低成本
产品优势
1、将用户信息标签化
2、用于千人千面、个性化推荐、精准营销.....用户画像优势
项目劣势:
1、未能真正使用分区表,不完全是真实生产环境
2、虽然集群提交过程一切正常,Spark在IDEA运行时却时常出现初始任务资源分配不足的问题,配置文件中各项参数的设置有待提升
3、Flume使用memory channel时会有内存溢出的风险,更好的方法是使用更为稳定的file channel或是一步到位,使用kafka channel