HBase与其他大数据组件的整合
HBase作为一个以列作为存储形式的大数据组件,具有查询快,存储的数据量大等特点,那么,该组件是如何与Hadoop生态圈中的其他组件进行整合并进行数据的各种导入导出的呢,这篇博客会就这个问题做一个详细的整理,那么废话不多说,我们直接开始吧!
1. Hbase与Hive的整合
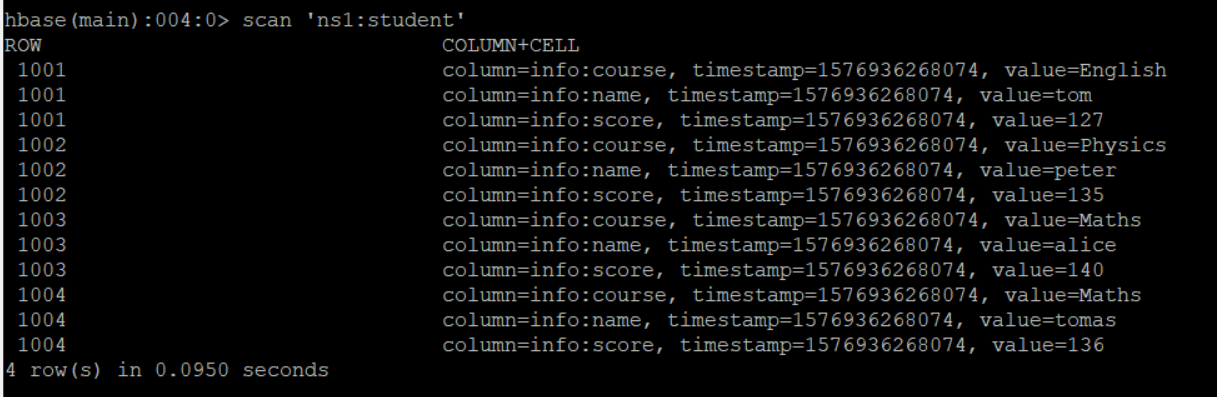
我们先在HBase中保存了一张学生表,进入hbase shell命令行窗口,然后输入命令 scan 'ns1:student',得到以下信息:
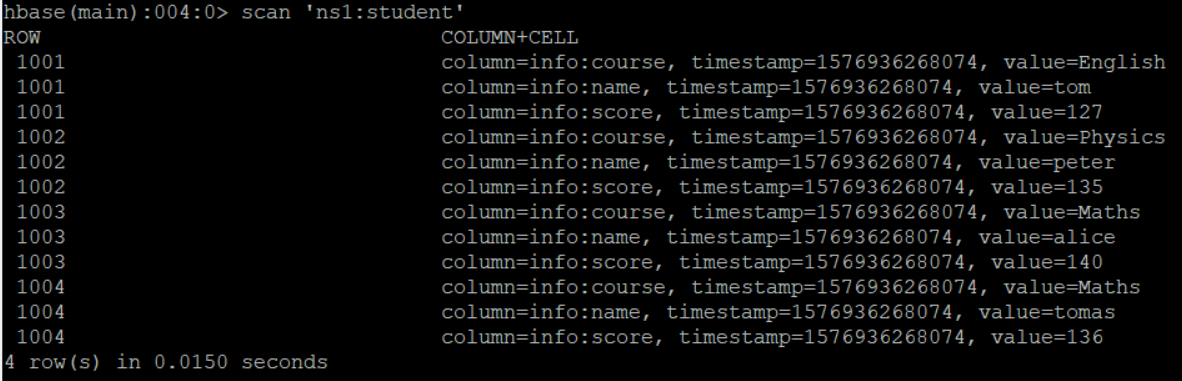
现在我们需要将这个学生表插入到hive的一张表中去,建表语句如下,注意,如果hbase中的表已经存在,那么在Hive中建表的时候就必须使用外部表,并且在Hive中的以及在HBase中的表的字段命名完全可以不一样,只需要顺序是一样的就行了!
create external table hive_mapping_hbase_student(
id string ,
name string ,
course string ,
score string)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" =
":key,
info:name,
info:course,
info:score")
tblproperties("hbase.table.name" = "ns1:student");
使用hiveserver2进入hive命令行窗口,将上述代码进行拷贝,然后查询数据查看是否插入成功,select * from hive_mapping_hbase_student;
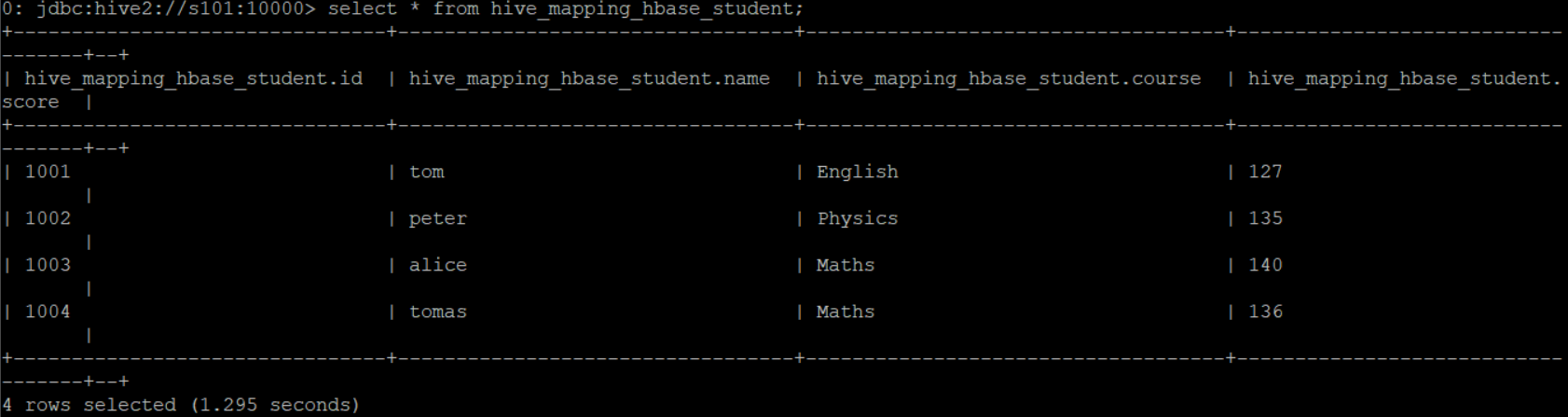
数据插入成功!
现在我们再来做一个实验,那就是当我们往hive中插入数据的时候,不指定主键列时会不会报错?执行插入语句:insert into hive_mapping_hbase_student(name) values('Mary'); 结果在hiveserver2中报如下错误信息:
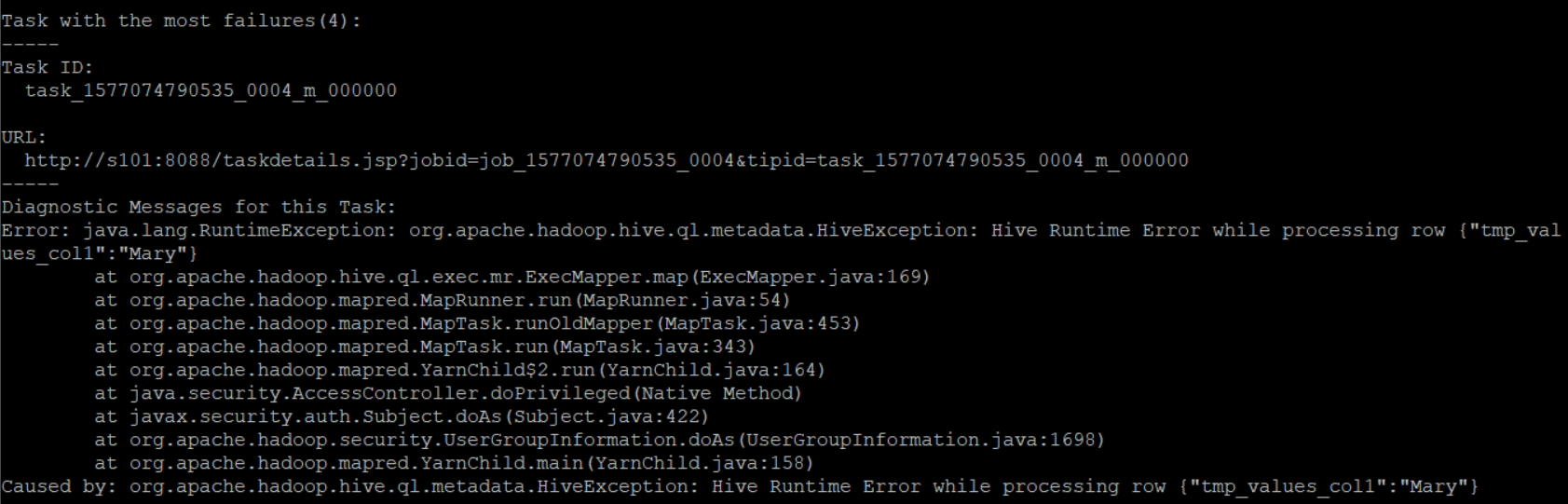
这说明了两个问题:
1. HBase的表和Hive的表是相互关联的
2. 往HBase中插入数据时必须要指定rowkey,否则就一定会报错
2. HBase与sqoop的整合
首先我们在mysql中保存了一张emp表来展现员工信息,具体信息查询如下所示:
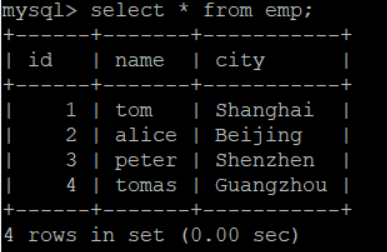
现在我们要使用sqoop将这些数据插入到HBase的表中去,具体指令如下,并且观察执行过程,可以发现该过程是会开启mapreduce的:
sqoop import --connect jdbc:mysql://s101:3306/test --username root --password w51056789 --table emp --hbase-create-table --hbase-table ns1:emp --hbase-row-key id --column-family info -m 1
插入成功,我们来看一下HBase中的具体的数据吧!
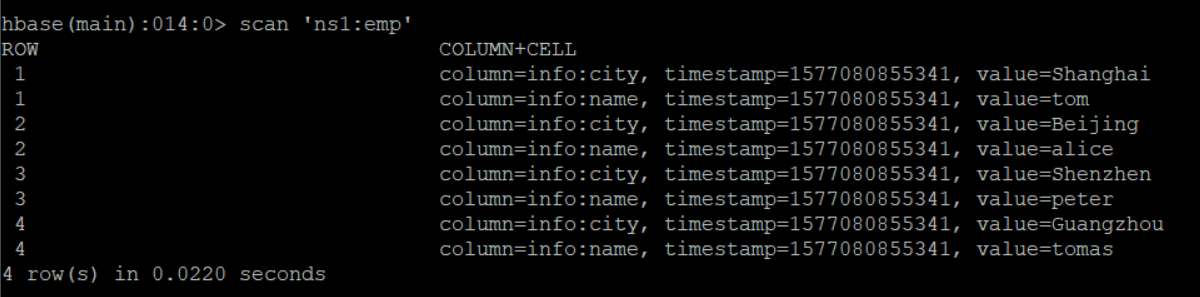
3. HBase与Mapreduce的整合
HBase最为经典的应用为它和MR的整合,有两种方式将数据通过MR计算框架插入HBase表中,第一种方式使用到TableOutputFormat类,数据是一条一条地插入到数据库的;第二种方式使用到HFileOutputFormat2类,实现方式为批量数据导入,因此效率较高,推荐使用。
首先需要注意的是,因为要用到一些依赖的库,第一件事要在pom文件中写入以下依赖:
<dependencies> <!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client --> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.2.8</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.2.8</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.44</version> </dependency> </dependencies>
3.1 TableOutputFormat方式导入
首先我们先准备一份已经保存在HBase中的word count文件,然后使用mapreduce执行单词计数程序,最后再输出回HBase中的另一张表,准备的原始数据表如下:

然后开始编写代码:
WCApp类:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.mapreduce.TableInputFormat; import org.apache.hadoop.hbase.mapreduce.TableOutputFormat; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; public class WCApp { public static void main(String[] args) throws Exception { //这里也必须写成Hbase的Configuration Configuration conf = HBaseConfiguration.create(); //在这里设定输入和输出的Hbase表名 conf.set(TableInputFormat.INPUT_TABLE,"ns1:wc"); conf.set(TableOutputFormat.OUTPUT_TABLE,"ns1:wcres"); Job job = Job.getInstance(conf); //设置作业名称以及各个class对象 job.setJobName("Hbase job"); job.setJarByClass(WCApp.class); job.setMapperClass(WCMapper.class); job.setReducerClass(WCReducer.class); //使用TableInputFormat和TableOutputFormat job.setInputFormatClass(TableInputFormat.class); job.setOutputFormatClass(TableOutputFormat.class); //设置Mapper和Reducer的输出KV job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Put.class); job.waitForCompletion(true); } }
WCMapper类:
import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class WCMapper extends Mapper<ImmutableBytesWritable, Result, Text, IntWritable> { @Override protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException { //因为一个字段因此直接get(0)即可 Cell cell = value.listCells().get(0); String line = new String(CellUtil.cloneValue(cell)); String[] arr = line.split(" "); for (String s : arr) { context.write(new Text(s), new IntWritable(1)); } } }
WCReducer类:
import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class WCReducer extends Reducer<Text, IntWritable, NullWritable, Put> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } Put put = new Put(key.toString().getBytes()); //为了让输出的不是字节数组,变得容易看得懂,应该转化成字符串 put.addColumn("info".getBytes(), "value".getBytes(), (sum + "").getBytes()); context.write(NullWritable.get(),put); } }
查看最终结果'ns1:wcres'表,成功:

3.2 HFileOutputFormat2方式导入
HBase可使用put命令向一张已经建好了的表中插入数据,然而,当遇到数据量非常大的情况,一条一条的进行插入效率将会大大降低,因此第二种方法将会整理提高批量导入效率的一种可行方案,那就是使用Mapper类先进行数据清洗,再在APP中批量导入。
首先我们准备好一份csv文件学生表,其中包含的是学生信息,具体信息如下:

对于此文件来说,每一行有四个字段,第一个代表rowkey,第二个代表name,第三个代表course,第四个代表score
接着,我们在hbase shell中建立一张学生表,之后数据将会直接导入至这张表中去:
hbase shell
> create_namespace 'ns1'
> create 'ns1:student', 'info'
HfileMapper类:
package bulkload; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class HfileMapper extends Mapper<LongWritable,Text,ImmutableBytesWritable,Put> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] strs = line.split(","); //首先获取到学生的学号 String id = strs[0]; ImmutableBytesWritable rowKey = new ImmutableBytesWritable(Bytes.toBytes(id)); //然后新建一个Put对象并分别获取到name,course以及score字段 Put put = new Put(Bytes.toBytes(id)); put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(strs[1])); put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("course"), Bytes.toBytes(strs[2])); put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("score"), Bytes.toBytes(strs[3])); // context.write(rowKey,put); } }
HfileApp类:
package bulkload; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2; import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; public class HfileApp { public static void main(String[] args) throws Exception { //这里也必须写成Hbase的Configuration Configuration conf = HBaseConfiguration.create(); conf.set("fs.defaultFS","file:///"); System.setProperty("HADOOP_USER_NAME","root"); Job job = Job.getInstance(conf); //设置作业名称以及各个class对象 job.setJobName("bulkload"); job.setJarByClass(HfileApp.class); job.setMapperClass(HfileMapper.class); job.setOutputFormatClass(HFileOutputFormat2.class); //设置Mapper的输出KV job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); FileInputFormat.addInputPath(job,new Path("d:/student.csv")); HFileOutputFormat2.setOutputPath(job,new Path("hdfs://mycluster/hfile")); //由于Hbase是有特定结构的,不像Hive那样可以很轻松地load data,因此需要指定表进行生成 Connection conn = ConnectionFactory.createConnection(conf); HFileOutputFormat2.configureIncrementalLoad(job,conn.getTable(TableName.valueOf("ns1:student")), conn.getRegionLocator(TableName.valueOf("ns1:student"))); boolean b = job.waitForCompletion(true); //开始进行bulk load批量导入程序 if(b){ LoadIncrementalHFiles incr = new LoadIncrementalHFiles(conf); incr.doBulkLoad(new Path("hdfs://mycluster/hfile"),conn.getAdmin(),conn.getTable(TableName.valueOf("ns1:student")), conn.getRegionLocator(TableName.valueOf("ns1:student"))); } conn.close(); } }
去HBase中查看学生表信息,成功插入!!!