高可用模式下的Hadoop集群搭建
本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学会部署高可用模式了,其他模式的搭建也会比较驾轻就熟,关于各种配置文件的讲解,如果有时间会在后期另开一篇博客进行详细的解读,现在正式开始部署流程!
1. 安装准备
基本思路讲解:在做正式安装之前,首先需要整理有哪些软件包是一定需要安装的,尽量先在一台机器上(一般我们称这台机器为“母机”)把所有需要的软件以及配置文件部署到位,然后再以这台机器作为母体实行克隆,然后再准备好几个同步的脚本方便以后部署各种分布式组件的时候把软件包分发到各个节点上去,各节点名称为:s101,主节点,s102-s104,三个分节点,s105,备用节点,在主节点挂掉之后用来顶替,每个节点的内存设置为2GB,zookeeper配置到s102-s104这三台主机上以保证datanode的正常运行
1.1 软件准备
我们首先需要准备以下三个tar.gz文件,没有的直接在网上(推荐apache官网)下载即可,下载时务必注意要选择稳定的而不是测试的版本:
Linux端需要的软件包

Windows端需要的软件包:由于在后期使用IntelliJ IDEA的时候会遇到在Windows端运行mapreduce程序的情况,因此在Windows端也需要相应的hadoop软件包

1.2 脚本文件准备
我们需要准备三个脚本文件,xsync.sh filepath,用来分发软件包;xcall.sh args,用来在所有的节点上执行相同的指令;xzk.sh [start | stop],用来同时启动或关闭所有的zkServer
nano /usr/local/bin/xsync.sh
# 拷入以下内容
# 增加执行权限
chmod a+x /usr/local/bin/xsync.sh
#!/bin/bash if [[ $# -lt 1 ]] ; then echo no params ; exit ; fi p=$1 #echo p=$p dir=`dirname $p` #echo dir=$dir filename=`basename $p` #echo filename=$filename cd $dir fullpath=`pwd -P` #echo fullpath=$fullpath user=`whoami` for (( i = 102 ; i <= 105 ; i = $i + 1 )) ; do echo =================s$i============== scp -r $filename ${user}@s$i:$fullpath done ;
nano /usr/local/bin/xcall.sh
# 拷入以下内容
# 增加执行权限
chmod a+x /usr/local/bin/xcall.sh
#!/bin/bash if [ $# -lt 1 ] ; then echo 需要参数 ; exit ; fi for (( i = 101 ; i <= 105 ; i = $i + 1 )) ; do tput setaf 2 echo =================s$i============== tput setaf 9 ssh s$i "source /etc/profile ; $@" done ;
nano /usr/local/bin/xzk.sh
# 拷入以下内容
# 增加执行权限
chmod a+x /usr/local/bin/xzk.sh
#!/bin/bash if [ $# -lt 1 ] ; then echo 需要参数 ; exit ; fi for (( i = 102 ; i <= 104 ; i = $i + 1 )) ; do tput setaf 2 echo =================s$i============== tput setaf 9 ssh s$i "source /etc/profile ; zkServer.sh $1" done ;
2. 软件包安装 & 配置环境变量
部署jdk
1. 在/home/centos下创建一个downloads文件夹用来统一存放tar.gz软件包
mkdir /home/centos/downloads
2. 在根目录/下创建soft文件夹用来统一存放安装完成的各种软件
mkdir /soft
3. 使用WinScp或Xftp等远程传输软件将文件jdk-8u201-linux-x64.tar.gz放到/home/centos/downloads下去
4. 将jdk-8u201-linux-x64.tar.gz解压到/soft目录下
tar -xzvf /home/centos/downloads/jdk-8u201-linux-x64.tar.gz -C /soft
5. 创建符号链接,使用jdk引向jdk1.8.0_201
cd /soft
ln -s jdk1.8.0_201 jdk
6. 配置环境变量
nano /etc/profile
添加以下信息
#java环境变量
export JAVA_HOME=/soft/jdk
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
部署hadoop
1. 使用远程传输软件将文件hadoop-2.7.3.tar.gz放到/home/centos/downloads下去
2. 将hadoop 2.7.3解压到/soft目录下
tar -xzvf /home/centos/downloads/hadoop-2.7.3.tar.gz -C /soft
3. 创建符号链接,使用hadoop引向hadoop-2.7.3
cd /soft
ln -s hadoop-2.7.3 hadoop
4. 配置环境变量
nano /etc/profile
添加以下信息
#hadoop环境变量
export HADOOP_HOME=/soft/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
5. 修改以下配置文件:
cd /soft/hadoop/etc/hadoop
nano hadoop-env.sh
修改:export JAVA_HOME=/soft/jdk
nano core-site.xml
删除原有的配置,添加以下信息
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/centos/ha</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/centos/ha/journal</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>s102:2181,s103:2181,s104:2181</value> </property> </configuration>
nano hdfs-site.xml
删除原有的配置,添加以下信息
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定名字服务 --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- 指定名字服务下的节点 --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!-- 指定两个节点的地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>s101:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>s105:8020</value> </property> <!-- 指定web地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>s101:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>s105:50070</value> </property> <!-- 指定QJM的地址 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://s102:8485;s103:8485;s104:8485/mycluster</value> </property> <!-- 容灾处理方式 --> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 容灾的隔离措施 --> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
nano mapred-site.xml
删除原有的配置,添加以下信息
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
nano yarn-site.xml
删除原有的配置,添加以下信息
<?xml version="1.0"?> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>s101</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>mycluster2</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>s101</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>s105</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>s101:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>s105:8088</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>s102:2181,s103:2181,s104:2181</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> </property> </configuration>
nano masters
删除原有的配置,添加以下信息
s101
s105
nano slaves
删除原有的配置,添加以下信息
s102
s103
s104
修改yarn的启动脚本,使得resourcemanager也配置成高可用模式
cd /soft/hadoop/sbin
nano start-yarn.sh
修改以下代码
"$bin"/yarn-daemons.sh --config $YARN_CONF_DIR --hosts masters start resourcemanager
修改yarn的关闭脚本
cd /soft/hadoop/sbin
nano stop-yarn.sh
修改以下代码
"$bin"/yarn-daemons.sh --config $YARN_CONF_DIR --hosts masters stopresourcemanager
部署zookeeper
1. 使用远程传输软件将文件zookeeper-3.4.10.tar.gz放到/home/centos/downloads下去
2. 将zookeeper-3.4.10.tar.gz解压到/soft目录下
tar -xzvf /home/centos/downloads/zookeeper-3.4.10.tar.gz -C /soft
3. 创建符号链接,使用zk引向zookeeper-3.4.10
cd /soft
ln -s zookeeper-3.4.10 zk
4. 配置环境变量
nano /etc/profile
添加以下信息
#zk环境变量
export ZK_HOME=/soft/zk
export PATH=$PATH:$ZK_HOME/bin
source /etc/profile
5. 修改配置文件名称
cd /soft/zk/conf
mv zoo_sample.cfg zoo.cfg
6. 修改配置文件
nano zoo.cfg
修改
dataDir=/home/centos/zk
添加
server.102=s102:2888:3888
server.103=s103:2888:3888
server.104=s104:2888:3888
7. 在/home/centos/zk下创建myid文件,并指定id号,注意这一步写在后面克隆虚拟机之后!!!!!!!!!!!!!!!!!!!!!!!
3. 克隆
完成上述步骤后,母机涉及到的基本配置就已完成了,接下去开始对母机s100进行克隆,并将之克隆成s101-s105这五台虚拟机,我们使用完整克隆模式,在克隆之前,不要忘记将s100做一个快照,以备后续搭建出错之需
确认基本配置:内存为2GB,处理器个数是8个,并且网络适配器使用网络地址转换模式
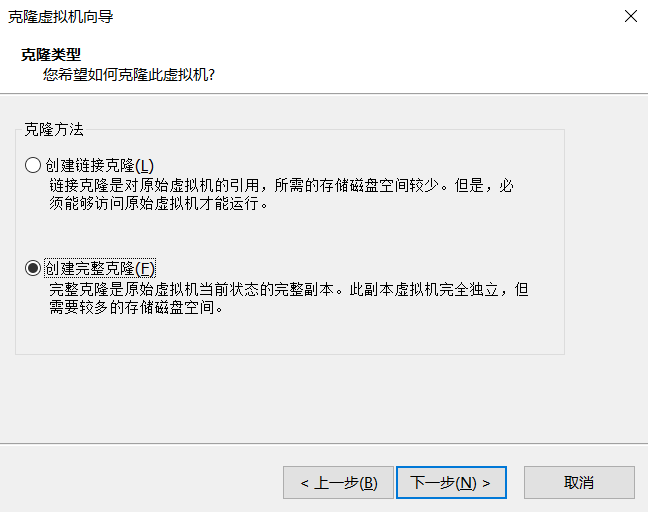
右键管理 -> 克隆,一直下一步至以下页面,选择“创建完整克隆” ,点击下一步
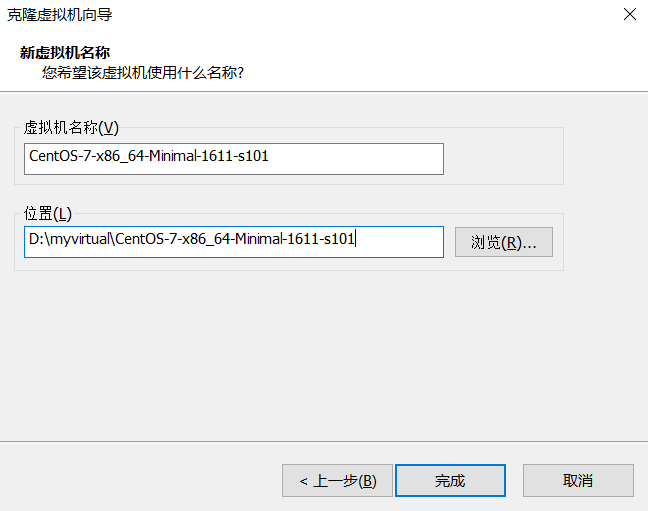
将虚拟机名称最后改成s101,然后点击完成
克隆成功!
重复上述步骤,完成s102-s105的克隆过程
依次克隆完成后,接下去需要进行三步操作,以s101为例,分为修改静态IP地址,修改hostname以及建立主机名和IP地址的映射这三步
修改静态IP地址
打开VMware,注意,不使用MTPuTTy,并且以root权限进入,输入指令nano /etc/sysconfig/network-scripts/ifcfg-ens33,将IPADDR最后改为101之后保存退出
修改主机名
nano /etc/hostname,将s100改为s101之后reboot重启虚拟机
对s102-s105重复以上操作
先对s101主机更改hosts文件,更改内容如下:
nano /etc/hosts
添加以下命令
192.168.153.101 s101
192.168.153.102 s102
192.168.153.103 s103
192.168.153.104 s104
192.168.153.105 s105
使用之前写好的xsync.sh脚本将hosts文件同步到所有节点上去,中途需要输入密码
xsync.sh /etc/hosts
4. 配置免密登录
首先配置s101节点到其他4个节点的免密登录
首先进入s101节点
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
ssh-copy-id root@s101
ssh-copy-id root@s102
ssh-copy-id root@s103
ssh-copy-id root@s104
ssh-copy-id root@s105
测试:ssh s103,登录成功!然后exit退出
然后进入s105节点,再用相同的方法配置s105节点到其他节点的免密登录
5. 其他步骤 & 测试启动
在/home/centos/zk下创建myid文件,并指定id号
xcall.sh "mkdir /home/centos/zk"
ssh s102 "echo -n 102 > /home/centos/zk/myid"
ssh s103 "echo -n 103 > /home/centos/zk/myid"
ssh s104 "echo -n 104 > /home/centos/zk/myid"
启动zookeeper,xzk.sh start
启动s102-s104的journalnode:hadoop-daemons.sh start journalnode
格式化namenode:hdfs namenode -format
将s101的ha文件夹发送到s105:scp -r /home/centos/ha root@s105:/home/centos
启动进程:start-all.sh
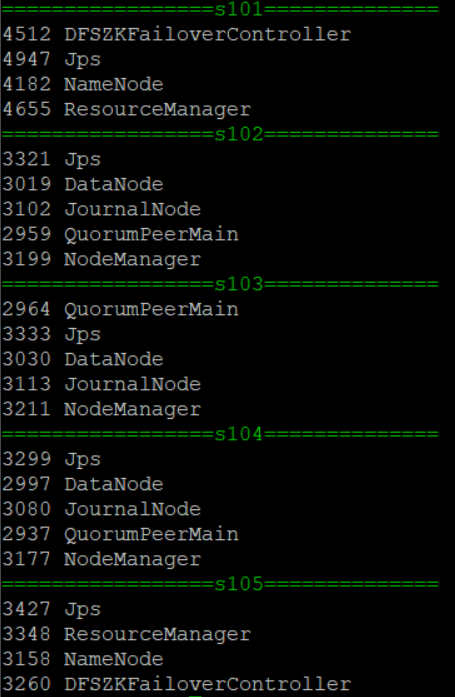
查看jps进程,发现自动容灾进程并未启动,xcall.sh jps

在zk上初始化数据:hdfs zkfc -formatZK
然后stop-all.sh,xzk.sh stop,再重新开启集群,注意启动zk一定要在启动hadoop之前,再次查看jps进程,xcall.sh jps,所有进程均已启动
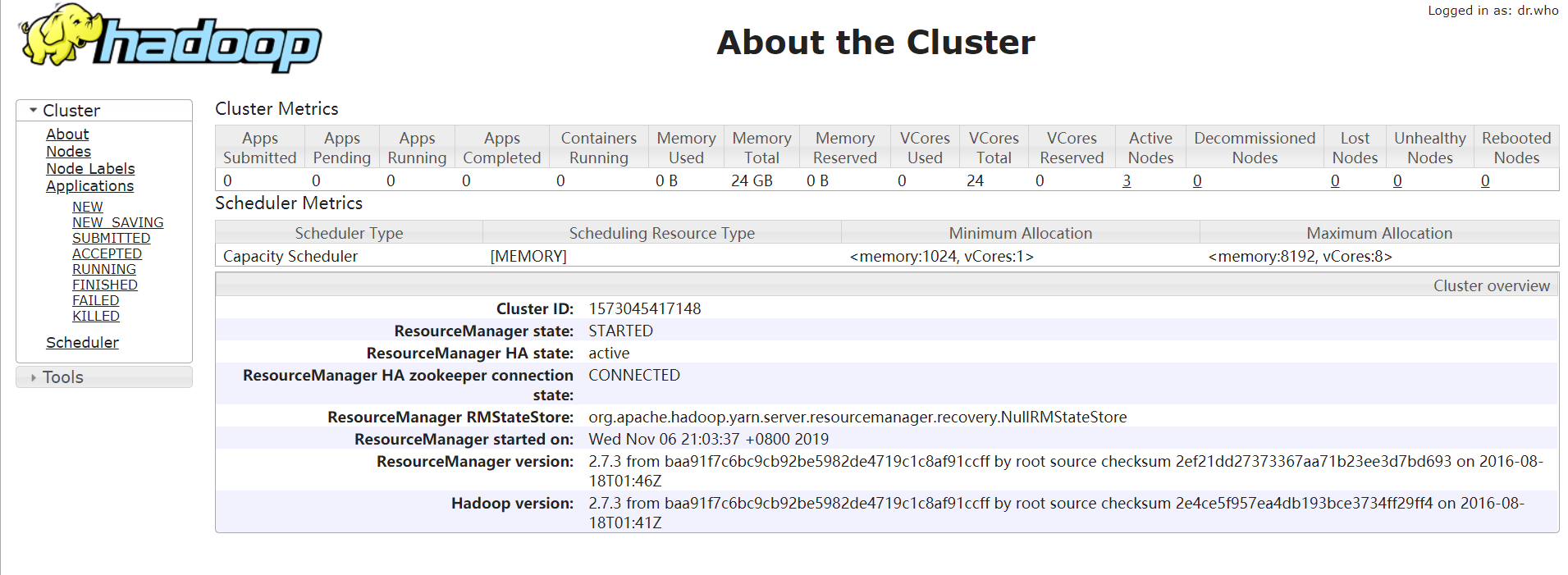
查看WebUI页面,s101:50070,成功进入!

查看8088页面,s101:8088,成功进入!