Spring Cloud
初识Spring Cloud与微服务
- 在传统的软件架构中,我们通常采用的是单体应用来构建一个系统,一个单体应用糅合了各种业务模块。起初在业务规模不是很大的情况下,对于单体应用的开发维护也相对容易。但随着企业的发展,业务规模与日递增,单体应用变得愈发臃肿。由于单体应用将各种业务模块聚合在一起,并且部署在一个进程内,所以通常我们对其中一个业务模块的修改也必须将整个应用重新打包上线。为了解决单体应用变得庞大脯肿之后产生的难以维护的问题,微服务架构便出现在了大家的视线里
什么是微服务
-
微服务(
Microservices)是一种软件架构风格,起源于Peter Rodgers博士于 2005 年度云端运算博览会提出的微 Web 服务 (Micro-Web-Service) 。微服务主旨是将一个原本独立的系统 拆分成多个小型服务,这些小型服务都在各自独立的进程中运行,服务之间通过基于HTTP的RESTful API进行通信协作。下图展示了单体应用和微服务之间的区别: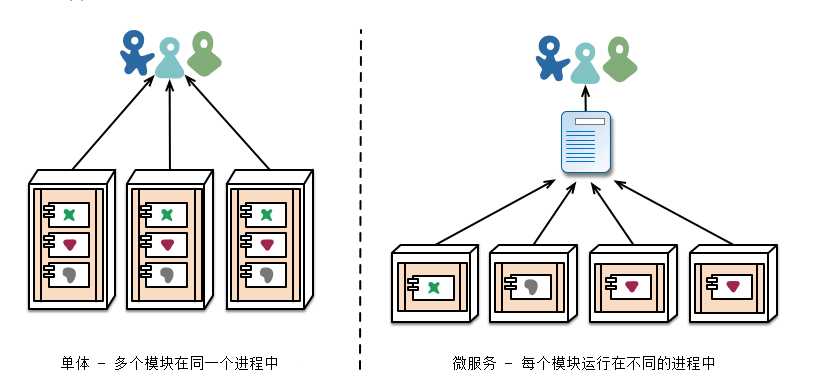
-
在微服务的架构下,单体应用的各个业务模块被拆分为一个单独的服务并部署在单独的进程里,每个服务都可以单独的部署和升级。这种去中心化的模式使得后期维护和开发变得更加灵活和方便,由于各个服务单独部署,所以可以使用不同的语句来开发各个业务服务模块
什么是Spring Cloud
- Spring Cloud是一种基于Spring Boot实现微服务架构的开发工具。它的微服务架构中涉及的配置管理、服务治理、断路器、智能路由、微代理、控制总线、全局锁、决策竞选、分布式会话和集群状态管理等操作提供了一种简单的开发方式。Spring Cloud的诞生并不是为了解决微服务中的某一个问题,而是提供了一套解决微服务架构实施的综合性解决方案
- Spring Cloud是一个由各个独立项目组成的综合项目,每个独立项目有着不同的发布节奏,为了管理每个版本的子项目清单,避免Spring Cloud的版本号与其子项目的版本号混淆,没有采用版本号的方式,而是通过命名的方式。这些版本的名字采用了伦敦地铁站的名字,根据字母表的顺序来对应版本时间顺序,比如“Angel”是Spring Cloud的第一个发行版名称,‘
Brixton’是Spring Cloud的第二个发行版名称,当一个发行版本的Spring Cloud项目发布内容积累到临界点或者一个严重bug解决可用后,就会发布一个”service releases”版本,简称SRX版本,其中X是一个递增的数字,所以Brixton.SR5就是Brixton的第5个Release版本
上篇 Spring Boot 2.X版和Spring Cloud H版
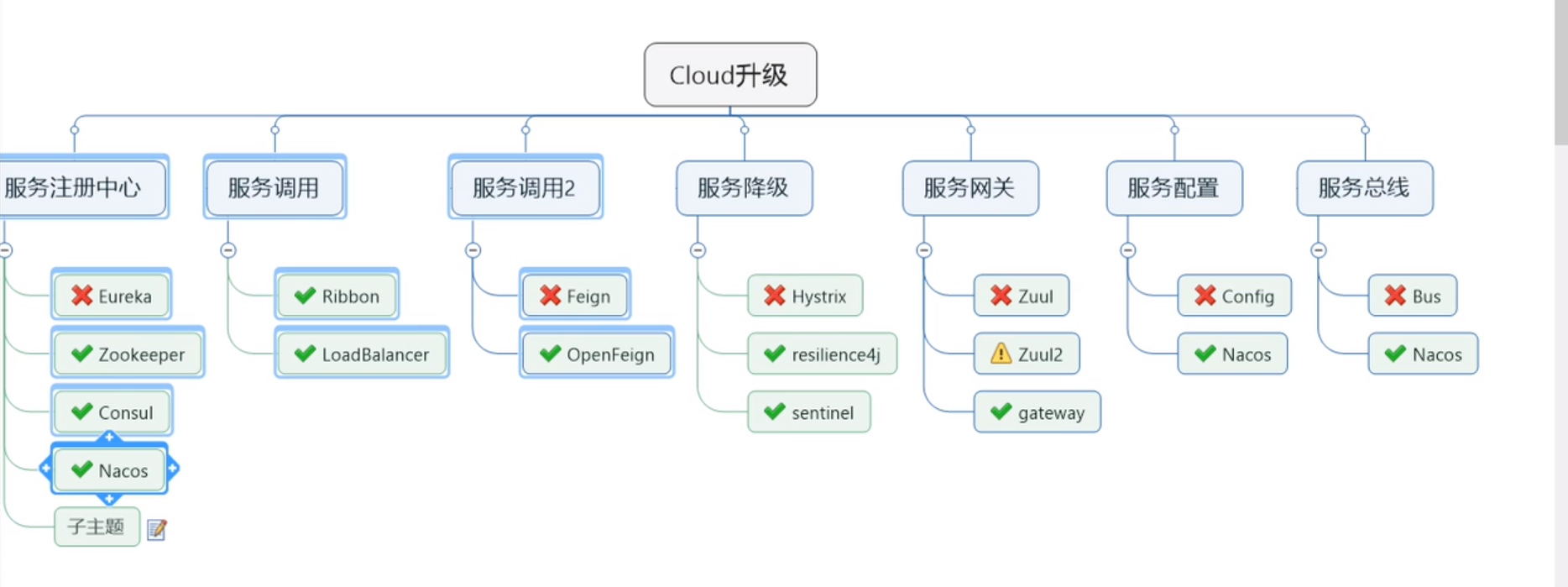
版本选型
-
spring boot 版本选型
- git源码地址
- spring boot 2.0 新特性(官网强烈建议升级到
2.x版本) - 官网看boot版本
-
spring cloud版本选择
- git源码地址
- 官网
- 官网看Cloud版本
- 命名规则 采用了英国伦敦地铁站名称命名,并由地铁站字母A-Z依次类推的形式来发布迭代版本
-
Spring cloud和Spring boot之间的依赖关系如何看
-

-
更详细的版本查看信息
https://start.spring.io/actuator/info- 查看
json串返回结果

-
-
版本确定(截止2020.2.15)
1.cloud :Hoxston.SR1 2.boot :2.2.2.RELEASE 3.cloud alibaba :2.1.0.RELEASE 4.Java :Java8 5.Maven : 3.5及以上 6.MySql :5.7及以上 7.题外话:booot版本最新已经到2.2.4,为什么选择2.2.2? 答:1. 只用boot 直接最新 2. 同时使用boot和cloud 需照顾cloud 由Spring cloud来决定boot版本
关于Cloud 各种组件的停更/升级/替换
-
由停更引发的“升级惨案”
-
停更不停用
- 被动修复bugs
- 不再接受合并请求
- 不再发布新版本
-
明细条目
- 以前
- now 2020
-
搭建父工程
- Maven结构
- dependency Management :Maven 使用dependency Management 元素来提供了一种管理依赖版本号的方式。通常会在一个组织或者项目的最顶层的父
POM中看到dependency Management元素。 - 使用
pom.xml中的dependency Management元素能够让所有在子项目中引用的一个依赖而不用显式的列出版本号。Maven会沿着父子层次向上走,直到找到一个拥有dependency Management元素的项目,然后他就会使用这个dependency Management 元素中指定的版本号 - 这样做的好处就是:如果有对个子项目都引用同一个依赖,则可以避免在每个使用的子项目里都声明一个版本号,这样当想升级或者切换到另一个版本时,只需要在顶层父容器里更新,而不需要一个一个子项目的修改;另外如果某个子项目需要另外的版本,只需要声明version就可
- dependency Management 里只是声明依赖,并不实现引入,因此子项目需要显式的声明需要用的依赖。
- 如果不在子项目中声明依赖,是不会从父项目中继承下来的;只有在子项目中写了该依赖项,并且没有指定具体版本,才会从父项目中继承该项,并且version和scope都读取自父
pom - 如果子项目中指定了版本号,那么就会使用子项目指定的jar包
- dependency Management :Maven 使用dependency Management 元素来提供了一种管理依赖版本号的方式。通常会在一个组织或者项目的最顶层的父
微服务子模块构建
-
微服务模块
- 建module
- 改
POM - 写
YML - 主启动
- 业务类
-
微服务运行
- 通过修改idea的
workspace.xml的方式来快速打开Run Dashboard窗口 - 开启Run Dashboard
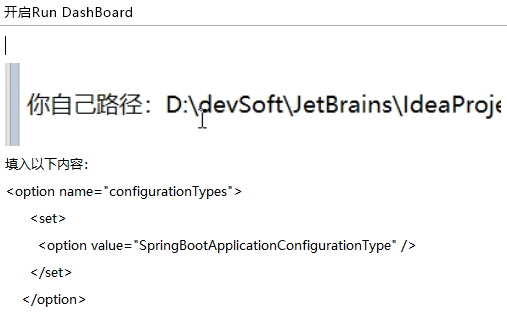
- 通过修改idea的
-
热部署
Devtools-
Adding
devtoolsto your project<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-devtools --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <scope>runtime</scope> <optional>true</optional> </dependency> -
Adding
pluginto yourpom.xml下一段配置黏贴到父工程当中的pom里 <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <fork>true</fork> <addResources>true</addResources> </configuration> </plugin> </plugins> </build> -
Enabling automatic build

-
Update the value of

-
重启IDEA
-
-
(订单支付服务远程调用)原始方法
RestTemplate提供了多种便捷访问远程Http服务的方法,是一种简单便捷的访问restful服务模板类,是Spring提供的用于访问Rest服务的客户端模板工具集- 使用
restTemplate访问restful接口非常简单粗暴无脑,(url、requestMap、ResponseBean.class)这三个参数分别代表Rest请求地址、请求参数、HTTP响应转换被转换成的对象类型 
-
工程重构
- 重复代码 冗余
- 建立公共模块
服务注册与发现
Eureka服务注册与发现
是什么
-
Eureka基础知识
- 什么是服务治理:Spring Cloud 封装了
Netflix公司开发的Eureka模块来实现服务治理。 - 在传统的
rpc远程调用框架中,管理每个服务与服务之间依赖关系比较复杂,管理比较复杂,所以需要使用服务治理,管理服务与服务之间依赖关系,可以实现服务调用、负载均衡、容错等,实现服务发现与注册。
- 什么是服务治理:Spring Cloud 封装了
-
什么是服务注册
- Eureka采用了CS的设计架构,Eureka Server作为服务注册功能的服务器,它是服务注册中心。而系统中的其他微服务,使用Eureka的客户端连接到Eureka server 并维持心跳连接,这样系统的维护人员就可以通过 Eureka Server 来监控系统中的各个微服务是否正常运行
- 在服务注册与发现中,有一个注册中心。当服务器启动的时候,会把当前自己的服务器的信息比如服务地址通讯等以别名的方式注册到注册中心上。另一方(消费者|服务提供者),以该别名的方式去注册中心上获取到实际的服务通讯地址,然后在实现本地
RPC调用。RPC远程调用框架核心设计思想:在于注册中心,因为使用注册中心管理每个服务与服务之间的一个依赖关系(服务治理概念)。在任何rpc远程框架中,都会有一个注册中心(存放服务地址相关信息(接口地址)) 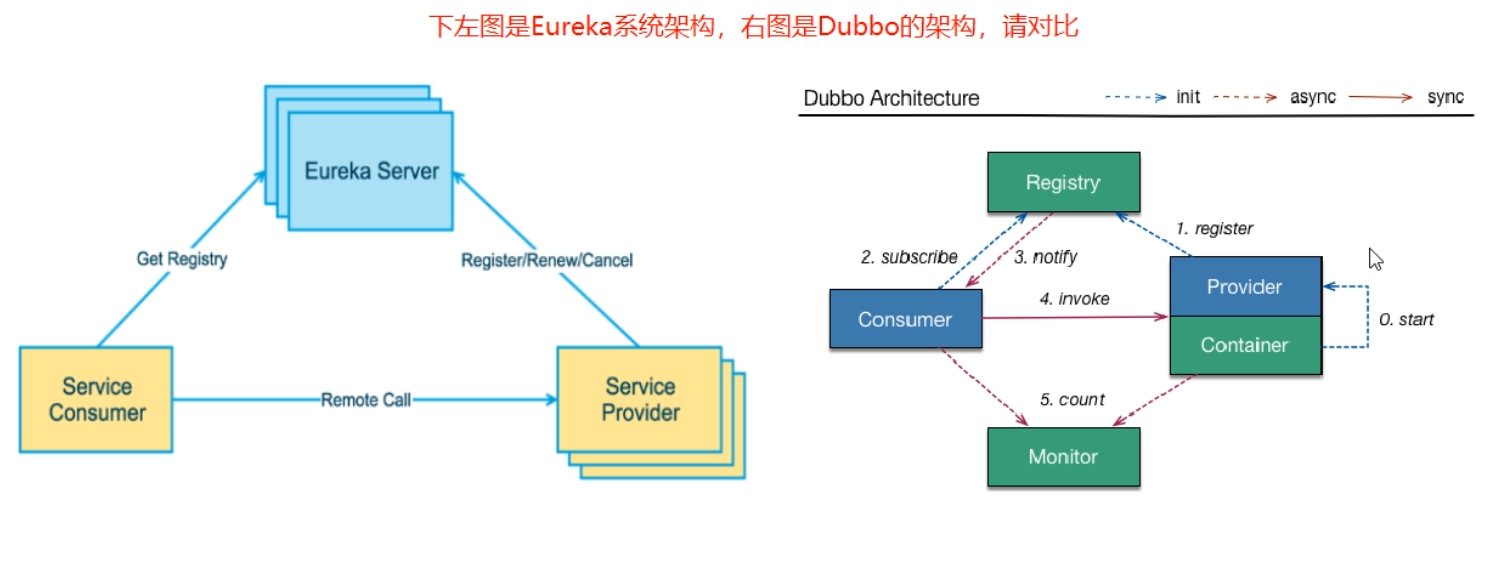
-
Eureka的两个组件
-
Eureka Server:提供服务注册服务
各个微服务节点通过配置启动后,会在Eureka Server中进行注册,这样Eureka Server中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到。
-
Eureka Client
是一个Java客户端,用于简化Eureka Server 的交互,客户端同时也具备一个内置的、使用轮询(round-robin)负载算法的负载均衡器。在应用启动后,将会向Eureka Server发送心跳(默认周期为30秒),如果Eureka server 在多个心跳周期内没有收到某个节点的心跳,Eureka Server 将会从服务注册表中把这个服务节点移除(默认90秒)
-
怎么用
-
IDEA生成Eureka Server 端服务注册中心(类似物业公司)

-
Eureka Client 端
cloud-peovider-payment8001将注册进Eureka Server成为服务提供者provider(类似学校提供授课服务)-
Eureka Client yml配置
-
Eureka Client启动类
-
-
Eureka Client 端
cloud-consumer-order80将注册进 Eureka Server 成为服务消费者consumer(类似上课消费的学生)- 如2的图
-
集群的Eureka原理说明
- 微服务
RPC远程调用最核心是什么: 高可用 - 解决办法:搭建Eureka注册中心集群,实现负载均衡+故障容错
- 互相注册 相互守望
- 微服务
-
集群的Eureka的搭建步骤
-
修改映射配置 :找到
C:\Windows\System32\drivers\etc路径下的hosts文件 -
添加进hosts文件:
127.0.0.1 eureka7001127.0.0.1 eureka7002
-
编写
yml -
启动类
-
-
将支付服务8001 发布到两台eureka集群配置中
-
其他配置不需要动
-
修改eureka配置的
defaultZone
-
-
Eureka集群服务
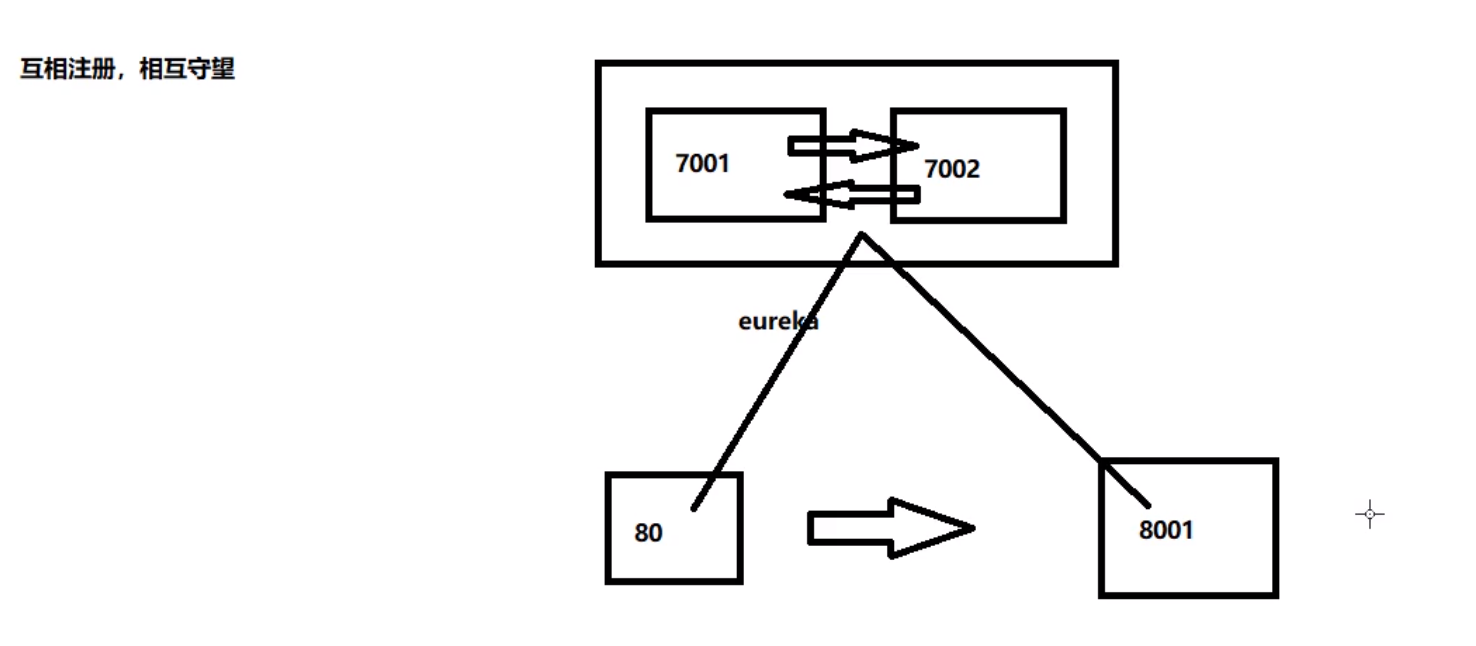
-
支付服务者提供者8001集群环境搭建
-

-
复制8001服务为8002
-
application name 一致

-

-
80消费8001/8002 服务地址不能写死,在微服务中 统一调用application name
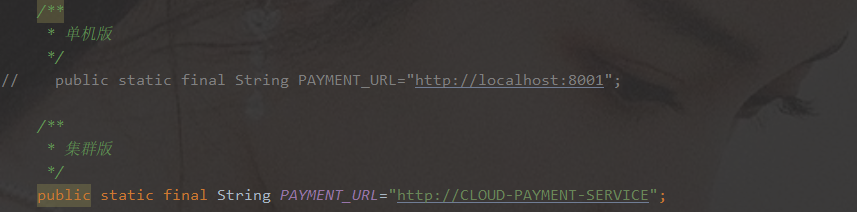
-
使用@
LoadBalanced -
注解赋予
RestTemplate负载均衡的能力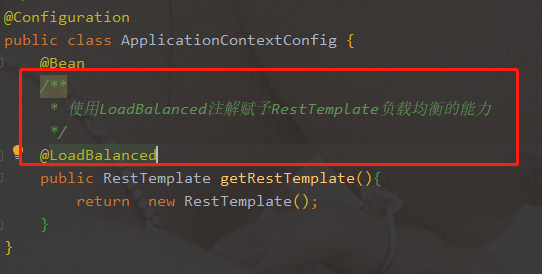
-
测试结果
- 先要启动
EurekaServer,7001/7002服务 - 再要启动服务提供者provider,8001/8002服务
- 负载均衡端口效果达到 8001/8002端口交替出现
- Ribbon和Eureka整合后Consumer可以直接调用服务不用再关心地址和端口号,且该服务还有负载均衡功能
- 先要启动
-
-
actuator微服务信息完善
- 主机名称:服务名称修改·
ymleureka.instance.instance-id
- 访问信息有
IP信息提示ymleureka,instance.prefer-ip-address:true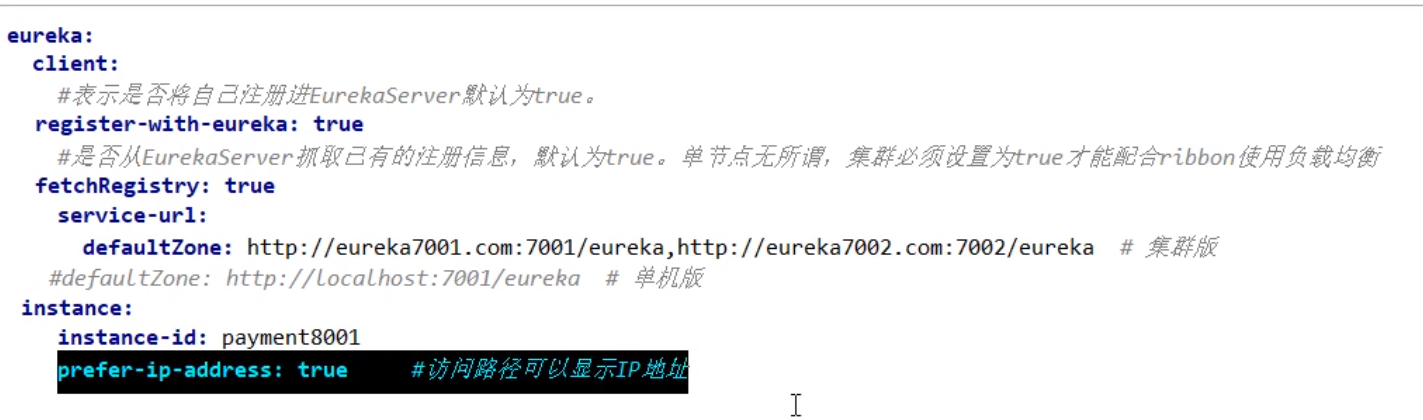
- 主机名称:服务名称修改·
-
Eureka服务发现Discovery
- 对于注册进eureka里面的微服务,可以通过服务发现来获得该服务的信息
controller DiscoveryClient- Application启动类 添加
@EnableDiscoveryClient注解
-
Eureka自我保护
-
概述:保护模式主要用于一组客户端和Eureka Server之间存在的网络分区场景下的保护,一旦进入保护模式,Eureka Server将会尝试保护去服务注册表中的信息,不再删除服务注册表中的数据,也就是不会注销任何微服务。
- 一句话:某时刻某一个微服务不可用了,Eureka不会立刻清理,依旧会对该微服务的信息进行保存。属于CAP里面的AP分支
-
为什么会产生Eureka自我保护机制
- 为了防止
EurekaClient可以正常运行,但是与EurekaServer网络不通的情况下,EurekaServer不会立刻将EurekaClient服务剔除 - 什么是自我保护机制:当
EurekaServer节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式 - 在自我保护模式中,Eureka Server会保护服务注册表中的信息,不再注销任何服务实例。它的设计哲学就是宁可保留错误的服务注册信息,也不盲目注销任何可能健康的服务实例(好死不如赖活着)
- 综上,自我保护模式是一种应对网络异常的安全保护措施,它的架构哲学是宁可同时保留所有的微服务(健康的微服务和不健康的微服务都会保留)也不会盲目的注销任何健康的微服务。使用自我保护模式,可以让Eureka集群更加的健壮、稳定
- 为了防止
-
Eureka服务停更说明:停更不停用
-


Zookeeper服务注册与发现
是什么
-
Zookeeper概述Zookeeper是一个开源的,分布式系统状态下的,多系统之间的协调调度、通知机制以达到一致性原则的一个服务功能架构- 管理者
-
设计模式来理解
- 是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,
Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应,从而实现集群中类似的Master/Slave管理模式。
- 是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,
-
一句话理解
-
文件系统+通知机制
-
Zookeeper安装-
官网下载
-
解压 tar
-zxvf -
conf文件夹中zoo_sample.cfg参数解读tickTime:通信心跳数,Zookeeper服务器心跳时间,单位毫秒。用于心跳机制,并且设置最小的session超时时间为两倍心跳时间(session的最小超时时间为2*tickTime)initLimit:LF初识通信时限(follower和leader):集群中follower跟随者服务器(F)与leader领导者服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量),用它来限定集群中的Zookeeper服务器连接到Leader的时限syncLimit:LF同步通信时限:集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit*tickTime,Leader认为Follower死掉,从服务器列表中删除FollowerdataDir:实际存储位置clientPort:默认端口号
-
开启服务+客户端连接
-
启动
./zkServer.sh start -
关闭 .
/zkServer.sh stop -
客户端连接
./zkCli.sh -
退出 quit
-
查看服务是否启动:
ps -ef|grep zookeeper|grep -v grep -
创建+删除节点:
create /testNode v1
delete /testNode
set /testNode v2
get /testnode
-
-
查看+获取
zookeeper服务器上的数据存储信息-
文件系统:
Zookeeper维护一个类似文件系统的数据结构,所使用的的数据模型风格很像文件系统的目录树结构,简单来说,有点类似windows中注册表的结构,有名称,有树节点,有Key/Value 的关系,可以看做一个树形结构的数据库,分布在不同的机器上做名称管理 -
初识
znode节点:Zookeeper数据模型的结构与Unix文件系统很类似,整体上可以看做是一棵树,每个节点称作一个Znode,很显然zookeeper集群自身维护了一套数据结构,这个存储结构是一个树形结构,其上每一个节点,我们称之为“znode”,每一个znode默认能够存储1MB的数据,每个znode都可以通过其路径唯一标识。 -
数据模型/
znode节点深入:-
Znode的数据模型- 是什么 (/stat):
zookeeper内部维护了一套类型UNIX的树形数据结构,由znode构成的集合,znode的集合又是一个树形结构,每一个znode又有很多属性进行描述。Znode=path+nodeValue+Stat zookeeper的Stat结构体czxid:引起这个znode创建的zxid,创建节点的事务的zxid(ZookeeperTransaction Id)ctime:znode被创建的毫秒数(从1970年开始)mzxid:znode最后更新的zxidmtime:znode最后修改的毫秒数(从1970年开始)pZxid:znode最后更新的子节点zxidcversion:znode子节点变化号,znode子节点修改次数dataversion:znode数据变化号aclVersion:znode访问控制列表的变化号ephemeralOwner:如果是临时节点,这个是znode拥有者的session id,如果不是临时节点则是0dataLength:znode的数据长度numChildren:znode子节点数量
- 是什么 (/stat):
-
znode的存在类型-
持久
- PERSISTENT:持久化目录节点 客户端与
zookeeper断开连接后,该节点依旧存在 - PERSISTENT_SEQUENTIAL:持久化顺序编号目录节点 客户端与
zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
- PERSISTENT:持久化目录节点 客户端与
-
临时
-
EPHEMERAL:临时目录节点 客户端与
zookeeper断开连接后,该节点被删除 -
EPHEMERAL_SEQUENTIAL:临时顺序编号目录节点 客户端与
zookeeper断开连接后,该节点被删除,只有Zookeeper给该节点名称进行顺序编号
-
-
create /name create -e /name create -s /name create -e -s /name -s:代表序列号 -e:代表临时 什么都不加代表p:持久化
-
-
-
-
-
典型应用场景(能干嘛)
- 命名服务
- 配置维护
- 集群管理
- 分布式消息同步和协调机制
- 负载均衡
- 对
Dubbo的支持 - 备注:
ZooKeeper提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中节点进行有效管理。从而可以设计出多种多样的分布式的数据管理模型,作为分布式系统的沟通调度桥梁
-
实际运用(怎么玩)
- 统一命名服务(Name Service如
Dubbo服务注册中心) - 配置管理(Configuration Management如淘宝开源配置框架Diamond)
- 集群管理(Group Membership如
Hadoop分布式集群管理) - Java操作
API
- 统一命名服务(Name Service如
-
基础命令和Java客户端操作
-
zkCli的常用命令操作- 和
redis的KV键值对类似,只不过key变成了一个路径节点值,v就是data。Zookeeper表现为一个分层的文件系统目录树结构,不同于文件系统之处在于:zk节点可以有自己的数据,而unix文件系统中的目录节点只有子节点。 一个节点对应一个应用,节点存储的数据就是应用需要的配置信息 - 常用命令:
- help
- ls
ls2: 是否有结构体 stat的内容- stat
- set
- get
- create
- delete
rmr
- 和
-
四字命令
-
是什么
zookeeper支持某些特定的四字命令,他们大多是用来查询ZK服务的当前状态及相关信息的,通过telnet或nc向zookeeper提交相应的命令,如echo | ruok | nc 127.0.0.1 2181得到结果imok启动正常- 运行公式:echo 四字命令 |
nc主机IPzookeeper端口
-
常用命令
ruok:测试服务是否处于正确状态,如果确实如此,返回imok,否则不做任何响应- stat:输出关于性能和连接的客户端列表
conf:输出相关服务配置的详细信息- cons:列出所有连接到服务器的客户端的完全的连接/会话的详细信息。包括接受/发送的包数量、
- dump:列出未经处理的会话个临时节点
envi:输出关于服务环境的详细信息(区别于conf命令)reqs:列出未经处理的请求wchs:列出服务器watch的详细信息wchc:通过session列出服务器watch的详细系信息,它的输出是一个与watch相关的会话的列表wchp:通过路径列出服务器watch的详细信息,它输出一个与session相关的路径
-
-
java客户端操作zkclient zookeeperjar包导入
-
-
通知机制
-
session是什么
-
watch
-
通知机制:客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,
zookeeper会通知客户端 -
是什么
- 观察者的功能:
ZooKeeper支持watch(观察)的概念。客户端可以在每个znode节点上设置一个观察。如果被观察服务端的znode变更,那么watch就会被触发,这个watch所属的客户端将接收到一个通知包被告知节点已经发生变化,把相应的时间通知给设置watch的Client端ZooKeeper里的所有读取操作:getData()、getChildren()和exists()都有设置watch的选项
- 一句话:异步+回调+触发机制
- 观察者的功能:
-
watch事件理解:
- 一次触发(one-time trigger):
- 当数据发生变化时,
zkserver向客户端发送一个watch,它是一次性的动作,即触发一次就不再有效,类似一次性纸杯。 - 只监控一次
- 如果想继续watch的话,需要客户端重新设置watcher,因此如果你得到一个watch事件且想在将来的变化得到通知,必须重新设置另一个watch
- 当数据发生变化时,
- 发送客户端(send to client):Watchers是异步发往客户端的,
ZooKeeper提供一个顺序保证:在看到watch事件之前绝不会看到变化,这样不同客户端看待的是一致性的顺序。 - 为数据设置watch:节点有不同的改变方式,可以认为
ZooKeeper维护两个观察列表:数据观察和子节点观察。getData、exists设置数据观察,getChildren设置子节点观察。setData将为znode触发数据观察。成功的create将为创建节点触发数据观察,为其父节点触发子节点观察。delete触发节点的数据观察以及子节点观察,为其父节点触发子节点观察 - 时序性和一致性
- 变化备注
- data watches and child watches
- watch之数据变化
- watch之节点变化
- 一次触发(one-time trigger):
-
code
- 一次性 one-time trigger -------
WatchOne - 多次(命名服务------
WatchMore - 子节点----
WatchChild
- 一次性 one-time trigger -------
-
-
-
ZooKeeper集群-
是什么
ZooKeeper分为2部分:服务器端和客户端,客户端只连接到整个ZooKeeper服务的某个服务器上。客户端使用并维护一个TCP连接,通过这个连接发送请求、接受响应、获取观察的事件以及发送心跳。如果这个TCP连接中断,客户端将尝试连接到另外一个ZooKeeper服务器。客户端第一次连接到ZooKeeper服务时,接受这个连接的ZooKeeper服务器会为这个客户端建立一个会话。当这个客户端连接到另外的服务器时,这个会话会被新的服务器重新建立。
-
伪分布式单机配置
-
说明
-
服务器名称与地址:集群信息(服务器编号,服务器地址,
LF通信端口,选举端口) -
这个配置项的书写格式比较特殊,规则如下:
server.N=YYY:A:B,其中 -
N表示服务器编号,
-
YYY表示服务器的IP地址, -
A为
LF通信端口,表示该服务器与集群中的leader交换的信息端口(leader follower/master slave 主从通信端口) -
B为选举端口,表示选举新Leader时服务器间相互通信的端口(当leader挂掉时,其余服务器会相互通信,选择出新的leader)
-
一般来说,集群中每个服务器的A端口都是一样,每个服务器的B端口也是一样。下面是一个集群的例子:
server.0=233.34.9.144:2008:6008server.1=233.34.9.145:2008:6008server.2=233.34.9.146:2008:6008server.3=233.34.9.147:2008:6008
-
但是当所采用的的为集群时,
IP地址都是一样的,只能是A端口和B端口不一样:server.0=127.0.0.1:2008:6008server.1=127.0.0.1:2007:6007server.2=127.0.0.1:2006:6006server.3=127.0.0.1:2005:6005
-
-
配置步骤
zookeeper.tar.gz解压后拷贝到/zookeeper目录下并重命名为zk01,在复制zk01形成zk02、zk03- 进入
zk01/2/3分别新建文件夹mydata、mylog - 分别进入
zk01/2/3各自的conf新增zoo.cfg - 编辑
zoo.cfg - 在各自
mydata下面创建myid的文件,在里面写入server的数字 - 分别启动三个服务器
zkCli连接server,带参数指定 -server:./zkCli.sh -server 127.0.0.1:2191
-
-
SpringCloud整合ZooKeeper代替Eureka
-
注册中心
ZooKeeperZooKeeper是一个分布式协调工具,可以实现注册中心功能- 关闭Linux服务器防火墙后启动
ZooKeeper服务器 ZooKeeper服务器取代Eureka服务器,ZK作为服务注册中心
-
服务提供者
cloud-provider-payment8004- 服务节点是临时性的 心跳检测机制:一定时间内为收到心跳包 就移除。
- CAP:一致性(Consistency)、高可用(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是:这三个要素最多只能同时实现两点,不可能三者兼顾
-
服务消费者
cloud-consumerzk-order80
Consul服务注册与发现
是什么
- Consul是
HashiCorp公司推出的开源工具,用于实现分布式系统的服务发现与配置。Consul是分布式的、高可用的、 可横向扩展的。它具备以下特性:- 服务发现: Consul提供了通过
DNS或者HTTP接口的方式来注册服务和发现服务。一些外部的服务通过Consul很容易的找到它所依赖的服务。 - 健康检测: Consul的Client提供了健康检查的机制,可以通过用来避免流量被转发到有故障的服务上。
- Key/Value存储: 应用程序可以根据自己的需要使用Consul提供的Key/Value存储。 Consul提供了简单易用的HTTP接口,结合其他工具可以实现动态配置、功能标记、领袖选举等等功能。
- 多数据中心: Consul支持开箱即用的多数据中心. 这意味着用户不需要担心需要建立额外的抽象层让业务扩展到多个区域。
- 服务发现: Consul提供了通过
- 下载安装并运行
- 具体方法官网都有
- win:进入
consul.exe所在目录--->cmd--->consul --version (查看版本信息) --->consul agent -dev启动 - http://localhost:8500 访问页面
怎么用
- 服务提供者
cloud-providerconsul-payment8006
- 服务消费者
cloud-consumerconsul-order80
三个注册中心的异同点(Eureka、ZooKeeper、Consul)
-
组件名 语言 CAP 服务健康检测 对外暴露接口 SpringCloud集成Eureka Java AP 可配支持 HTTP 已集成 ZooKeeper Java CP 支持 客户端 已集成 Consul Go CP 支持 HTTP/DNS 已集成 -
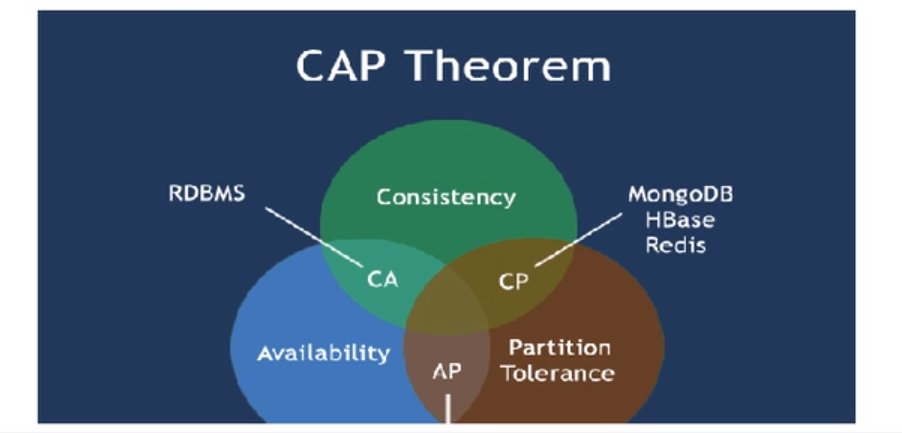
-
CAP
C:Consistency(强一致性)A:Availability(可用性)P:Partition tolerance(分区容错性)- CAP理论关注粒度是数据,而不是整体系统设计的
-
经典CAP图
- AP(Eureka)
- CP(
Zookeeper/Consul)
Ribbon负载均衡服务调用
概述
- Spring Cloud Ribbon是基于
NetFlixRibbon实现的一套客户端负载均衡的工具。简单地说,Ribbon是NetFlix发布的开源项目,主要功能是提供客户端的软件负载均衡算法和服务调用。Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。简单的说,就是在配置文件中列出Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。我们很容易使用Ribbon实现自定义的负责均衡算法。
能干嘛
-
LB(Load Balance)负责均衡:将用户的请求平摊的分配到多个服务器上,从而达到系统的HA(高可用),常见的负载均衡有软件
Nginx、LVS硬件F5等- 集中式LB
- 即在服务的消费方和提供方之间是有独立的LB设施(可以是硬件,如
F5,也可以是软件,如nginx),由该设施负责把访问请求通过某种策略转发至服务的提供方
- 即在服务的消费方和提供方之间是有独立的LB设施(可以是硬件,如
- 进程式LB
- 将LB逻辑集成到消费方,消费方从服务注册中心获知到有哪些地址可用,然后自己再从这些地址中选择出一个合适的服务器。
- Ribbon就属于进程内的LB,它只是一个类库,集成于消费方进程,消费方通过它来获取到服务提供方的地址。
- 集中式LB
-
Ribbon本地负责均衡客户端 vs
Nginx服务端负载均衡区别Nginx是服务器负载均衡,客户端所有请求都会交给Nginx,然后由nginx实现转发请求。即负载均衡是由服务端实现的- Ribbon本地负载均衡,在调用微服务接口时,会在注册中心上获取注册信息服务列表之后缓存到
JVM本地,从而在本地实现RPC远程服务调用技术。 - 一句话总结:负载均衡+
RestTemplate调用
Ribbon负责均演示
-
架构说明
- 总结:Ribbon其实就是一个软负载均衡的客户端组件,它可以和其他需要请求的客户端结合使用,和eureka结合只是其中的一个实例。
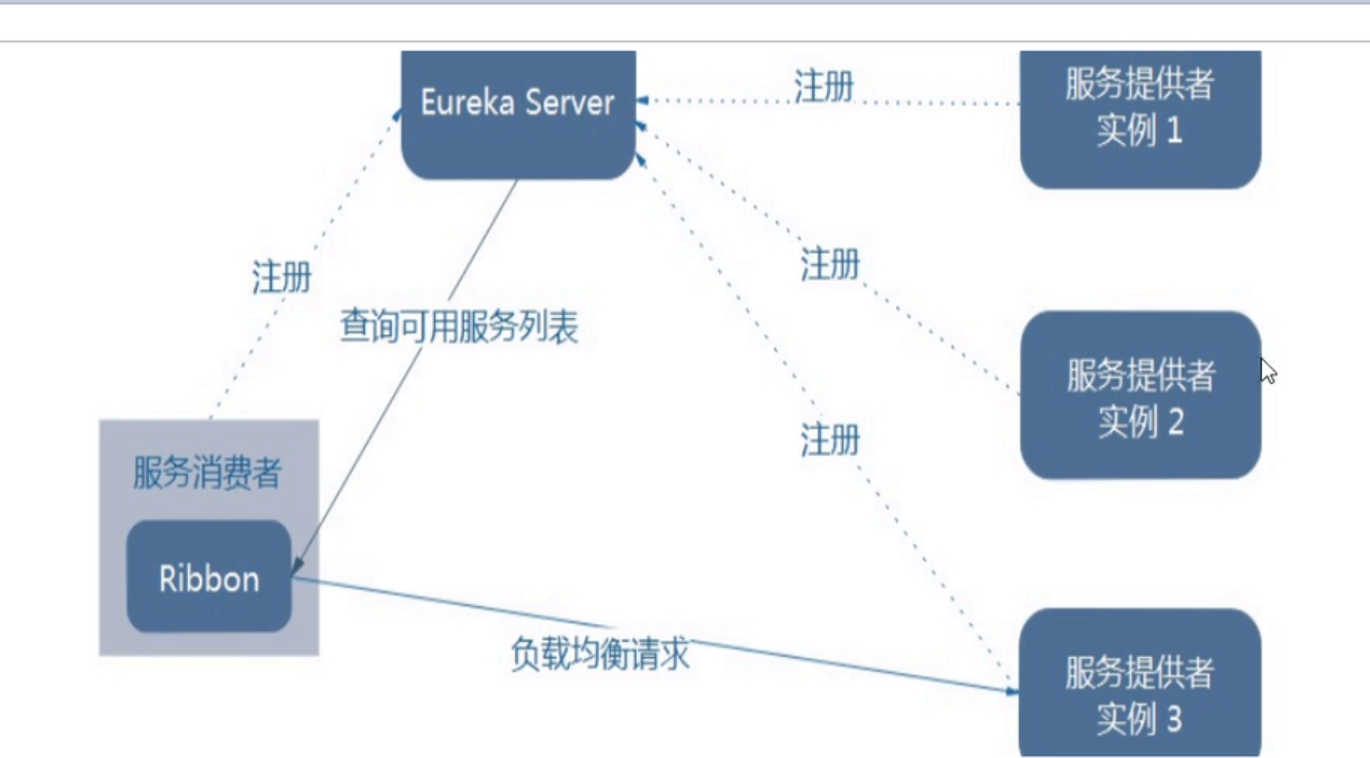
- Ribbon在工作时分成两步
- 第一步先选择
EurekaServer,它优先选择在同一个区域内负载较少的server - 第二步再根据用户指定的策略,再从server取到的服务注册列表中选择一个地址
- 其中Ribbon提供了多种策略:比如轮询、随机和根据响应时间加权
- 第一步先选择
- Eureka中的
spring-cloud-stater-netflix-eureka-client引入了Ribbon
-
二说
RestTemplate的使用getForObject方法/getForEntity方法getForObject方法:返回对象为响应体中数据转化成的对象,基本可以理解为JsongetForEntity方法:返回对象为ResponseEntity对象,包含了响应中的一些重要信息,比如响应头、响应状态吗、响应体等。
postForObject/postForEntity- GET请求方法
- POST请求方法
Ribbon核心组件IRule
IRule:根据特定算法从服务列表中选取一个要访问的服务com.netflix.loadbalancer.RoundRobinRule轮询com.netflix.loadbalancer.RandomRule随机com.netflix.loadbalancer.RetryRule先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试WeightedResponseTimeRule对RoundRobinRule的扩展,响应速度越快的实例选择权重越大,越容易被选择BestAvailableRule会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务AvailabilityFilteringRule先过滤掉故障实例,再选择并发较小的实例ZoneAvoidanceRule默认规则,复合判断server所在区域的性能和server的可用性选择服务器
- 如何替换负载均衡策略
- 修改
cloud-consumer-order80 - 配置细节:官方文档明确给出了警告:这个自定义配置类不能放在@
ComponentScan所扫描的当前包下以及子包下,否则我们自定义的这个配置类就会被所有的Ribbon客户端所共享,达不到特殊定制化的目的了。 - 新建package 不能跟主启动类所在包同包以及其子包
- 新建自定义规则的配置类
- 主启动类添加@
RibbonClient注解,指定服务名称以及自定义规则类
- 修改
Ribbon负责均衡算法剖析
- 原理
- 负载均衡算法(轮询):rest接口第几次请求数 % 服务器集群总数量 =实际调用服务器位置下标,每次服务重启后,rest接口计数从1开始
- 源码
- 继承了
AbstractLoadBalancerRule抽象类
- 继承了
- 手写
- 原理+
JUC(CAS+自旋锁)- 7001,7002集群启动
- 8001/8002微服务改造
- 80订单微服务改造
- 原理+
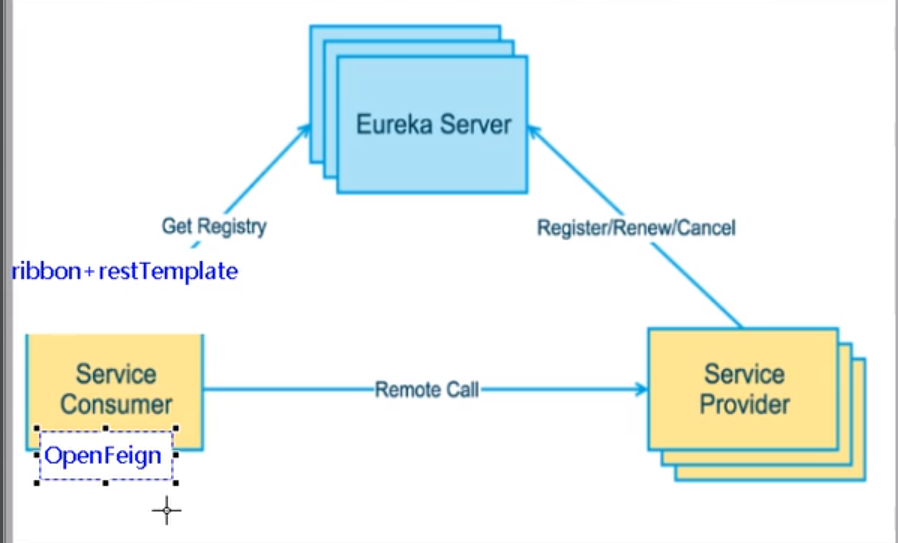
OpenFeign服务
概述
-
OpenFeign是什么Fegin是一个声明式Web Service客户端。使用Feign能让编写Web Service客户端更简单。它的使用方法是定义一个服务接口然后在上面添加注解。Fegin也支持可拔插式的编码器和解码器。Spring Cloud对Fegin进行了封装,使其支持了Spring MVC标准注解和HttpMessageConverters。Fegin可以与Eureka和Ribbon组合使用以支持负载均衡
-
能干嘛
Fegin旨在使编写JavaHttp客户端变得更容易- 前面在使用Ribbon+
RestTemplate时,利用RestTemplate对http请求的封装处理,形成了一套模板化的调用方法。但是在实际开发中,由于对服务依赖的调用可能不止一处,往往接口会被多处调用,所以通常都会针对每个微服务自行封装一些客户端类来包装这些依赖服务的调用。所以,Fegin在此基础上做了一进一步封装,由他来帮助我们定义和实现依赖服务接口的定义。在Fegin的实现下,我们只需要创建一个接口并使用注解的方式来配置它(以前是Dao接口上面标注Mapper注解,现在是一个微服务接口上面标注一个Fegin注解即可),即可完成对服务提供方的接口绑定,简化了使用Spring cloud Ribbon时,自动封装服务调用客户端的开发量。 - Fegin集成了Ribbon
- 利用Ribbon维护了Payment的服务列表信息,并且通过轮询的方式实现了客户端的负载均衡。而与Ribbon不同的是,通过Fegin只需要定义服务绑定接口且以声明式的方法,优雅而简单的实现了服务调用
-
Fegin与OpenFegin两者区别

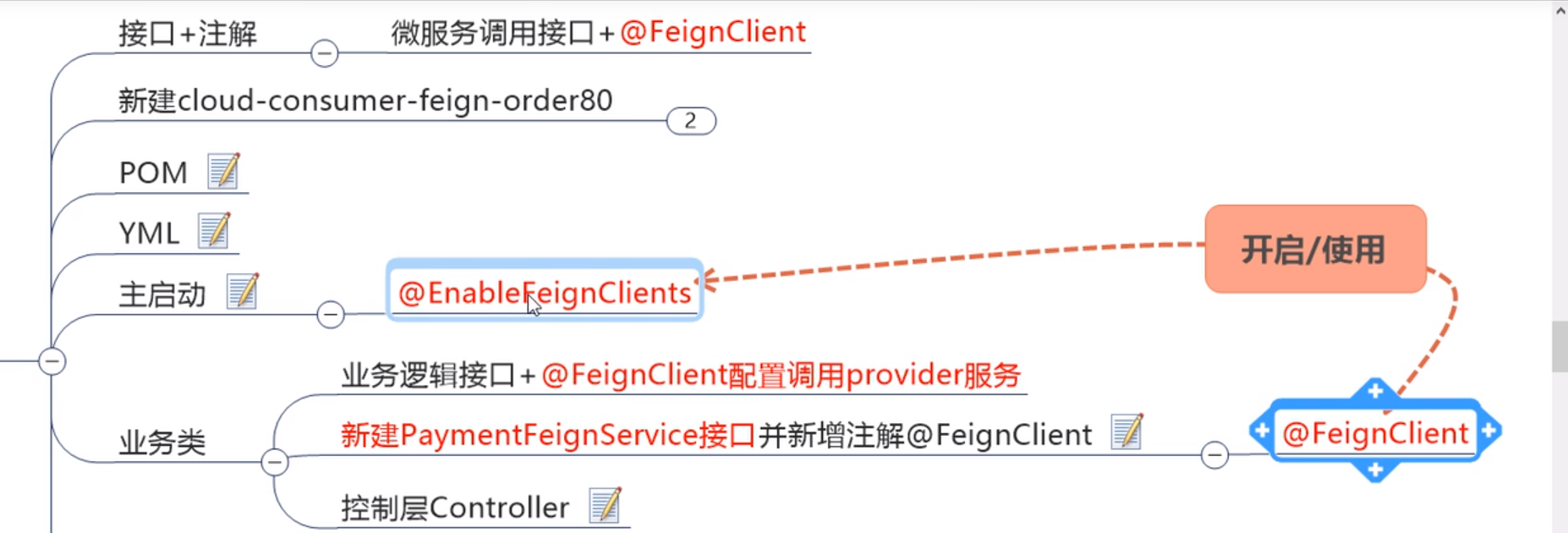
OpenFegin使用步骤
-
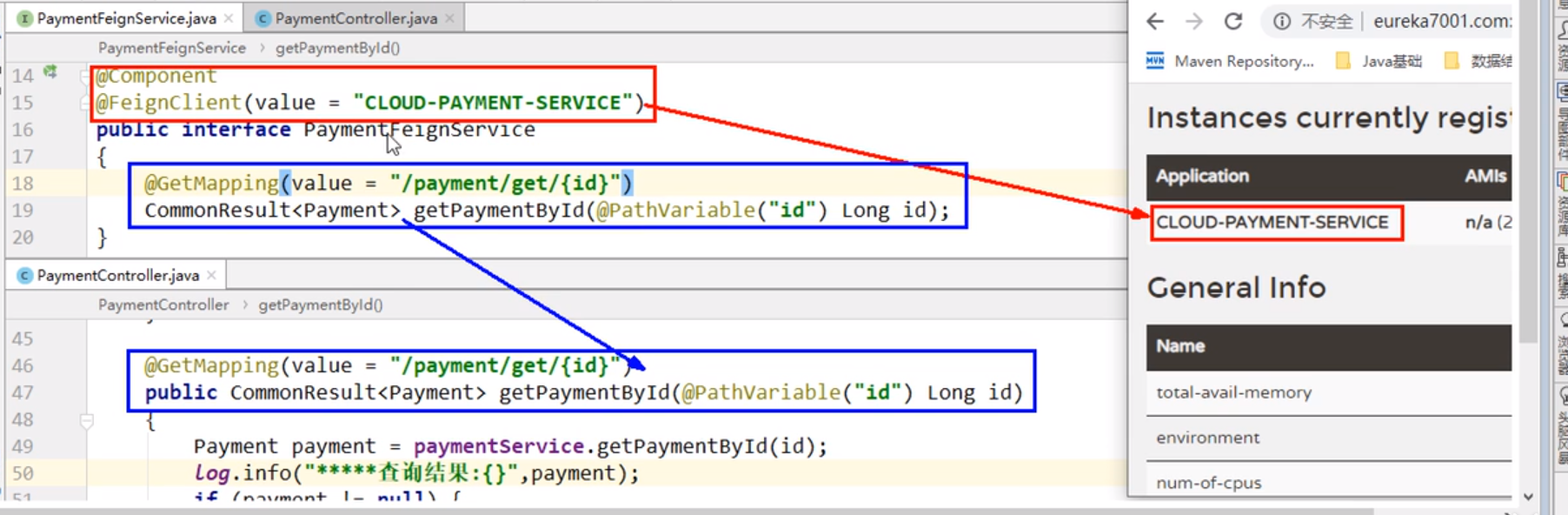
创建一个接口并使用注解的方式来配置它:微服务调用接口+注解(@FeignClient)
-
代替原有的
Ribbon+RestTemplate的服务调用模式 -
-
-
OpenFegin超时控制
- 超时设置,故意设置超时演示出错情况
- 服务提供方8001,故意写暂停程序
2. 服务消费方80添加超时方法PaymentFeignService
- 服务提供方8001,故意写暂停程序
- OpenFeign客户端默认等待一秒,但是服务器端处理需要超过1秒钟,导致OpenFeign客户端不想等待了,直接返回报错。为了避免这样的情况,有时候我们需要设置feign客户端的超时控制。
- OpenFeign默认支持Ribbon
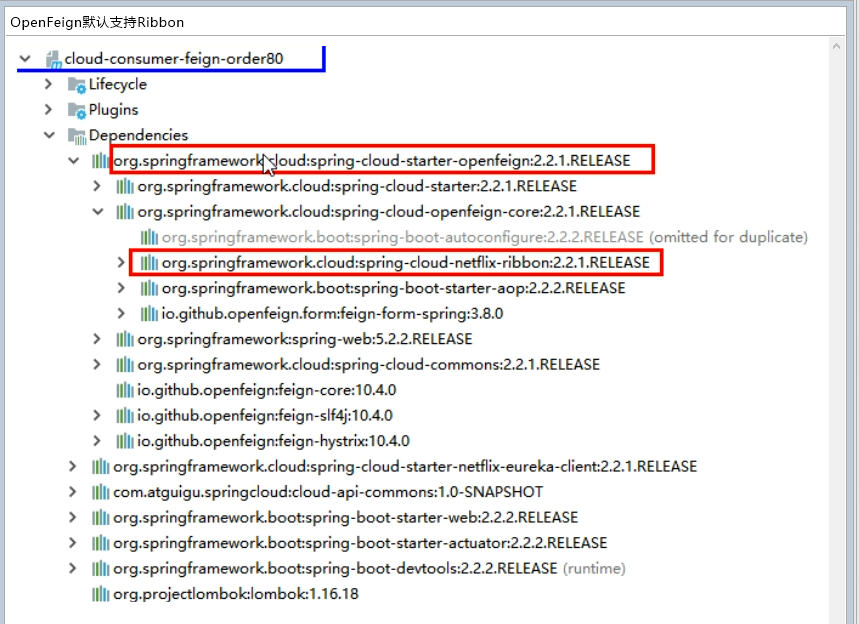
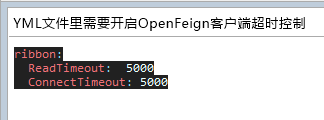
- yml文件中开启配置
OpenFegin日志打印功能
-
日志级别
- NONE:磨人的,不显示任何日志
- BASIC:仅记录请求方法、URL、响应状态码及执行时间
- HEADERS:除了BASIC中定义的信息之外,还有请求和响应的头信息
- FULL:除了HEADERS中定义的信息之外,还有请求和相应的正文及元数据
-
配置日志Bean
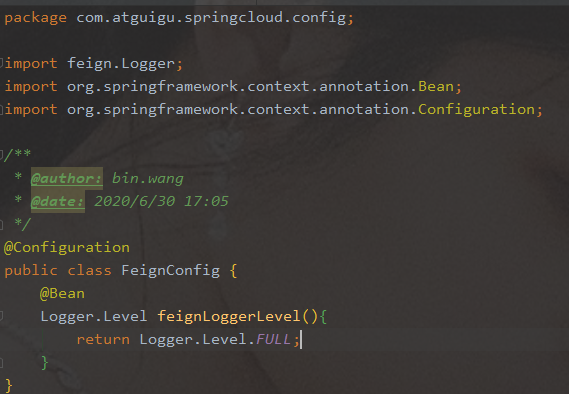
-
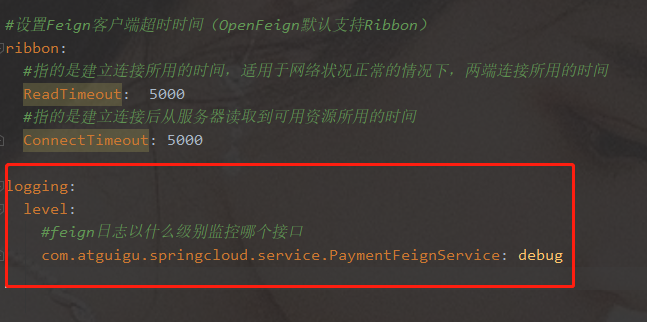
yml文件开启日志
服务降级
Hystrix断路器
概述
- 分布式系统面临的问题
- 复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免的失败
- 服务雪崩:多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”。
- 对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其它系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
- 所以,通常当你发现一个模块下的某个实例失败后,这时候这个模块依然还会接收流量,然后这个有问题的模块还需要调用其他模块,这样就会发生级联故障,或者叫做雪崩。
- 是什么
- Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整个服务失败,避免级联故障,以提高分布式系统的弹性
- “断路器”本身是一种开关装置,当某个服务单元发生故障后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要的占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
- 能干嘛
- 服务降级
- 服务熔断
- 接近实时的监控
- 。。。。。。(限流、隔离)
- Hystrix官宣,停更进维
Hystrix重要概念
- 服务降级--fallback(备选响应)
- 服务器忙,请稍后再试,不让客户端等待并立刻返回一个友好提示,fallback
- 哪些情况会触发降级:
- 程序运行异常
- 超时
- 服务熔断触发降级
- 线程池/信号量打满也会导致服务降级
- 服务熔断--break
- 类比保险丝达到最大服务访问后,直接拒绝访问,拉闸限电,然后调用服务降级的方法并返回友好提示
- 就是保险丝:服务的降级---进而熔断---恢复调用链路
- 服务限流--flowlimit
- 秒杀高并发等操作,严禁一窝蜂的过来拥挤,大家排队,一秒钟N个,有序进行
Hystrix案例
-
新建
cloud-provider-hystrix-payment8001 -
高并发测试 jemeter
- 开启Jmeter,来20000个并发压死8001,20000个请求都去访问paymentInfo_timeout服务
- 演示结果:出现卡顿,tomcat的默认工作线程数被打满了,没有多余的线程来分解压力和处理
-
压测结论
-
上面还是服务提供者8001自己测试,假如此时外部的消费者80也来访问,那消费者只能干等,最终导致消费端80不满意,服务端8001直接被拖死
-
看热闹不嫌事大,80新建加入
cloud-consumer-feign-hystrix-order80- 继续压测 8001自测以及80调用服务
-
故障现象和导致原因
- 8001同一层次的其他接口服务被困死,因为tomcat线程里面的工作线程已经被挤占完毕
- 80此时调用8001,客户端访问响应缓慢,转圈圈
-
结论:正因为有上述故障或不佳表现,才有我们的降级/容错/限流等技术诞生
-
如何解决?解决的要求
- 超时导致服务器变慢(转圈)----超时不再等待
- 出错(宕机或程序运行出错)----出错要有兜底
- 解决
- 对方服务(8001)超时了,调用者(80)不能一直卡死等待,必须有服务降级
- 对方服务(8001)宕机了,调用者(80)不能一直卡死等待,必须有服务降级
- 对方服务(8001)OK,调用者(80)自己出故障或有自我要求(自己的等待时间小于服务提供者)自己处理降级
-
服务降级
-
降级的配置
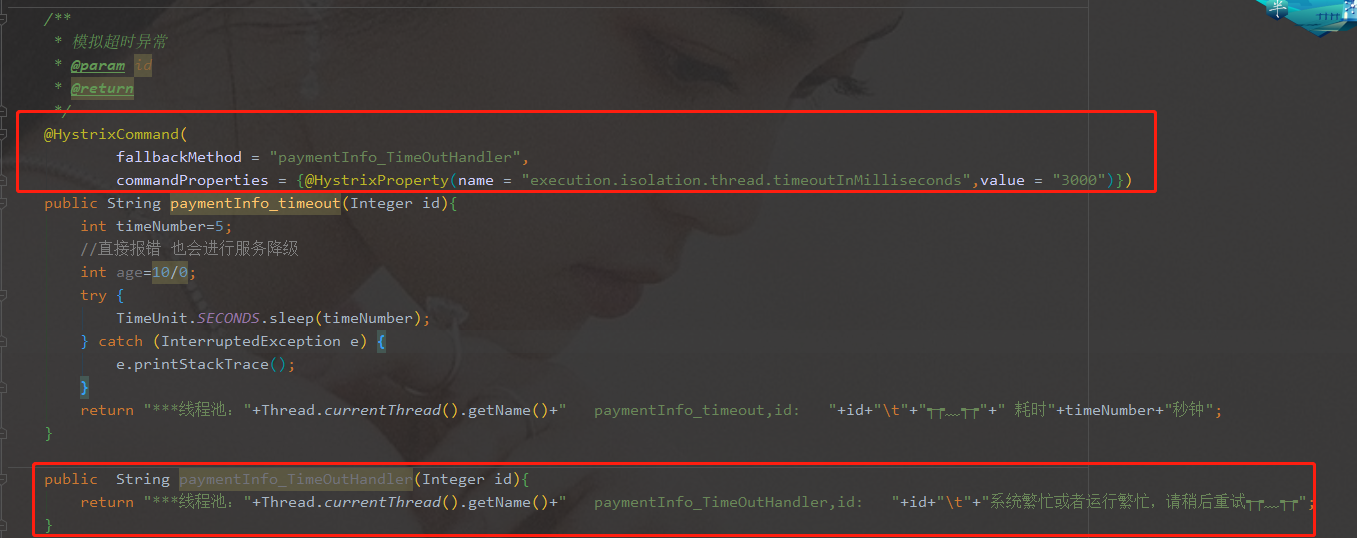
@HystrixCommand注解 -
8001先从自身找问题:设置自身调用的超时时间峰值,峰值内可以正常运行,超过l需要有兜底的方法处理,作服务降级
fallback -
8001
fallback- 业务类启用
- 主启动类激活 添加新注解
@EnableCircuitBreaker
-
80
fallback- 80订单微服务,也可以更好的保护自己,自己也依样画葫芦进行客户端降级保护
-
目前问题:
- 每个业务方法对应一个兜底的方法,代码膨胀、冗余
- 统一和自定义的分开
-
待解决问题
- 每个方法配置一个???代码冗余
- 注解
@DefaultProperties(defaultFallback = "通用处理方法名") - 除了特别重要的核心业务有专属,其他普通的可以通过
@DefaultProperties(defaultFallback ="")统一跳转到统一处理结果页面 - 通用的和独享的各自分开,避免了代码膨胀,合理减少了代码量
- 注解
- 和业务逻辑混合在一起???乱!
- 服务降级,客户端去调用服务端,碰上服务端宕机或关闭
- 本次案例服务降级处理是在客户端80实现的,与服务端8001没有关系,只需要为Feign客户端定义的接口添加一个服务降级处理的实现类即可实现解耦
- 未来我们要面对的异常:运行超时、宕机
- 根据
cloud-consumer-feign-hystrix-order80已经有的PaymentHystrixService接口,重新新建一个类(PaymentFallbackServiceImpl)实现该接口,统一为接口里面的方法进行异常处理
yml文件PaymentHystrixService接口,指定降级处理类。

- 客户端自己的提升:此时服务端provider已经down了,但是我们做了服务降级处理,让客户端在服务端不可用时也会获得提示信息而不会挂起耗死服务器
- 每个方法配置一个???代码冗余
-
-
服务熔断
-
断路器
-
熔断是什么
- 熔断机制概述:熔断机制是应对雪崩效应的一种微服务链路保护机制,当扇出链路的某个微服务出错不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路
- 在Spring Cloud框架里,熔断机制通过
Hystrix实现,Hystrix会监控微服务间的调用状况,当失败的调用到一定阈值,缺省是5秒内20次调用失败,就会启动熔断机制,熔断机制的注解是@HysrixCommand
-
实操
- 修改
cloud-provider-hystrix-payment8001 - service接口
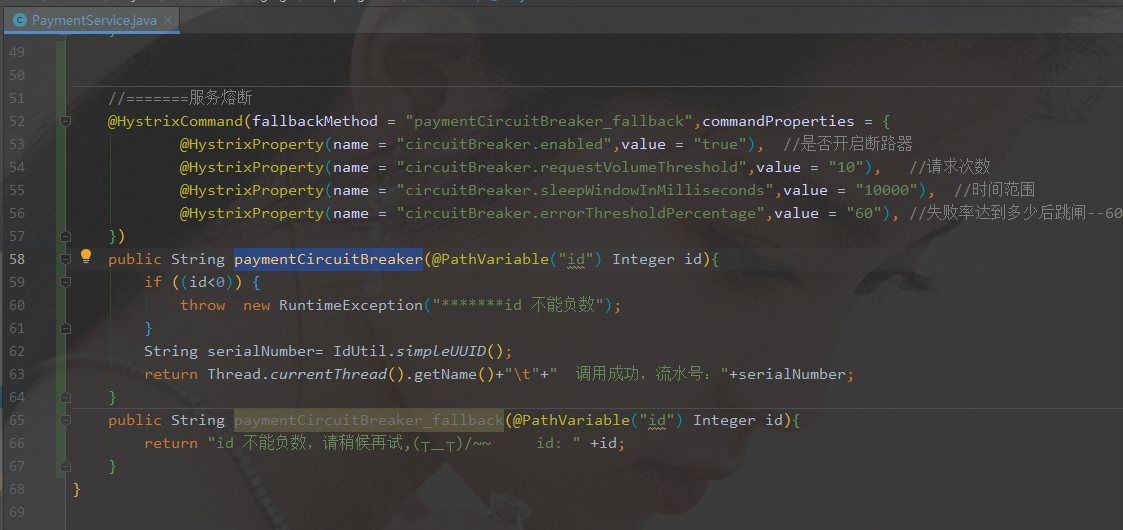
- 重点测试:多次错误,然后慢慢正确,发现刚开始不满足条件,就算是正确的访问地址也不能进行访问,需要慢慢的恢复链路
- 修改
-
原理(小总结)
-
大神理论:
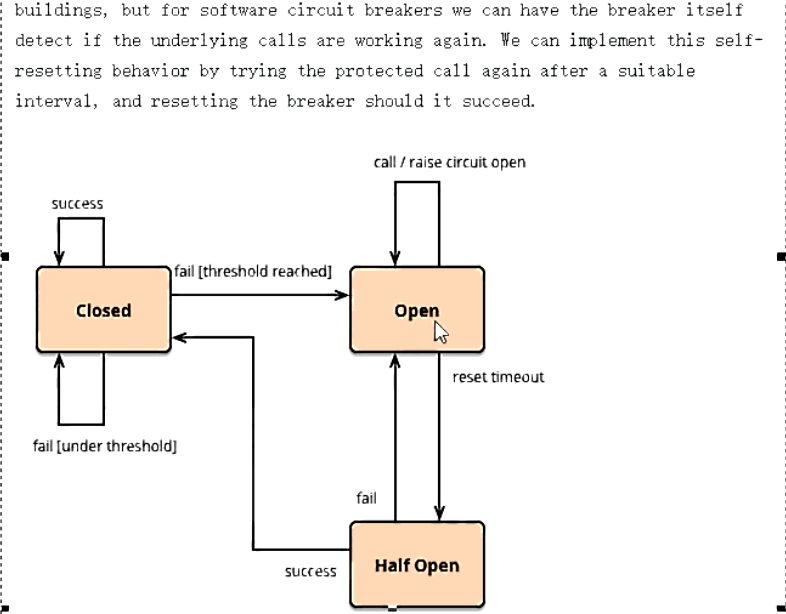
-
熔断类型:
- 熔断打开:请求不再进行调用当前服务,内部设置时钟一般为
MTTR(平均故障处理时间),当打开时长达到所设时钟则进入半熔断状态 - 熔断关闭:熔断关闭不会对服务进行熔断
- 熔断半开:部分请求根据规则调用当前服务,如果请求成功并且符合规则则认为当前服务恢复正常,关闭熔断
- 熔断打开:请求不再进行调用当前服务,内部设置时钟一般为
-
官网断路器流程
-
流程图
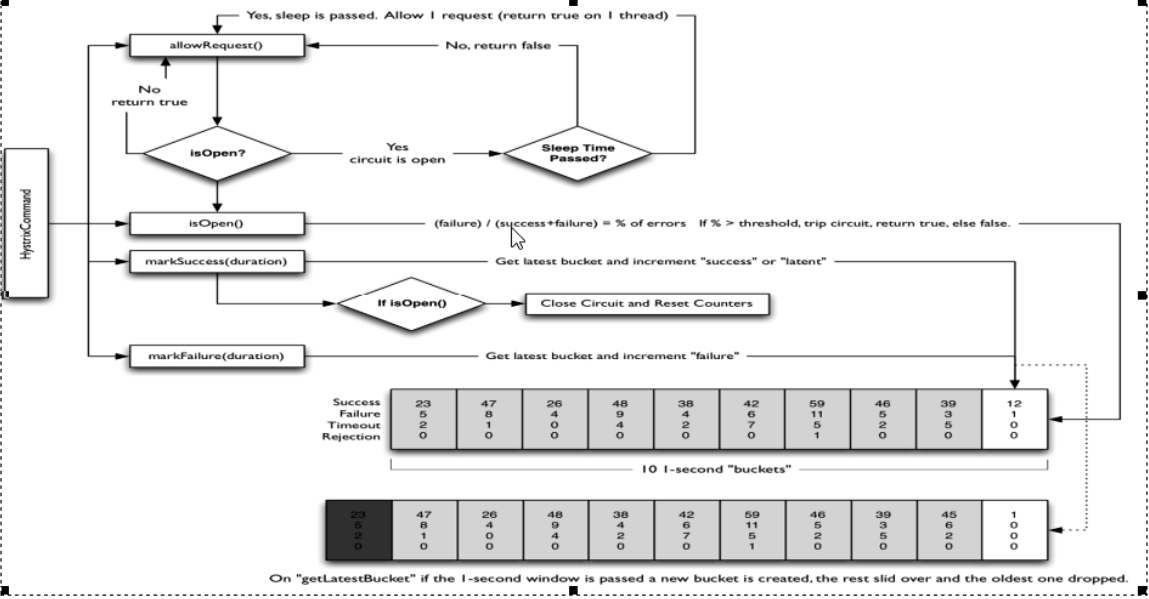
-
官网步骤


-
断路器在什么情况下开始起作用

-
断路器开启或者关闭的条件
- 当请求满足一定阈值的时候(默认10秒内超过20个请求次数)
- 并且失败率达到一定值的时候(默认10秒内超过50%的请求失败)
- 到达以上阈值,断路器将会开启
- 当开启的时候,所有请求都不会进行转发
- 一段时间之后(默认是5秒),这个时候断路器是半开状态,会让其中一个请求进行转发。如果成功,断路器会关闭,若失败,继续开启。重复4和5
-
断路器打开之后
- 打开之后,再有请求调用的时候,将不会调用主逻辑,而是直接调用降级fallback,通过断路器,实现了自动地发现错误并将降级逻辑切换为主逻辑,减少响应延迟的效果。
- 原来的主逻辑要如何恢复呢? -----对于这一问题,hystrix也为我们实现了自动恢复功能。当断路器打开,对主逻辑进行熔断之后,hystrix会启动一个休眠的时间窗,在这个时间窗内,降级逻辑是临时的成为主逻辑,当休眠时间窗到期,断路器将进入半开状态,释放一次请求到原来的主逻辑上,如果此次请求正常返回,那么断路器将继续闭合,主逻辑恢复,如果这次请求依然有问题,断路器继续进入打开状态,休眠时间窗重新计时。
-
ALL配置




-
-
-
-
服务限流
- 后面讲解alibaba的Sentinel说明
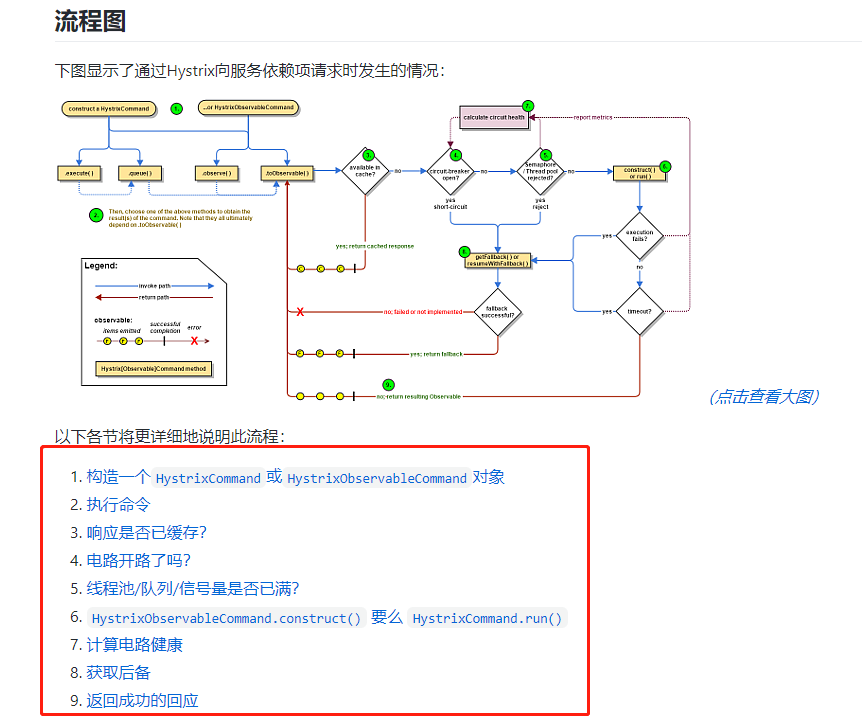
Hystrix工作流程
服务监控HystrixDashboard
- 概述
- 仪表盘9001
- 新建
cloud-consumer-hystrix-dashboard9001 - POM
- YML
HystrixDashboardMain9001+新注解@EnableHystrixDashboard- 所有Provider微服务提供类(8001/8002/8003)都需要监控依赖配置
- 启动
cloud-consumer-hystrix-dashboard9001该微服务后续将监控微服务8001
- 新建
- 断路器演示
- 修改
cloud-provider-hystrix-payment8001- 注意图形化展示:spring-boot-starter-actuator(必须有)
- 注意:新版本
Hystrix需要在主启动类MainAppHystrix8001中指定监控路径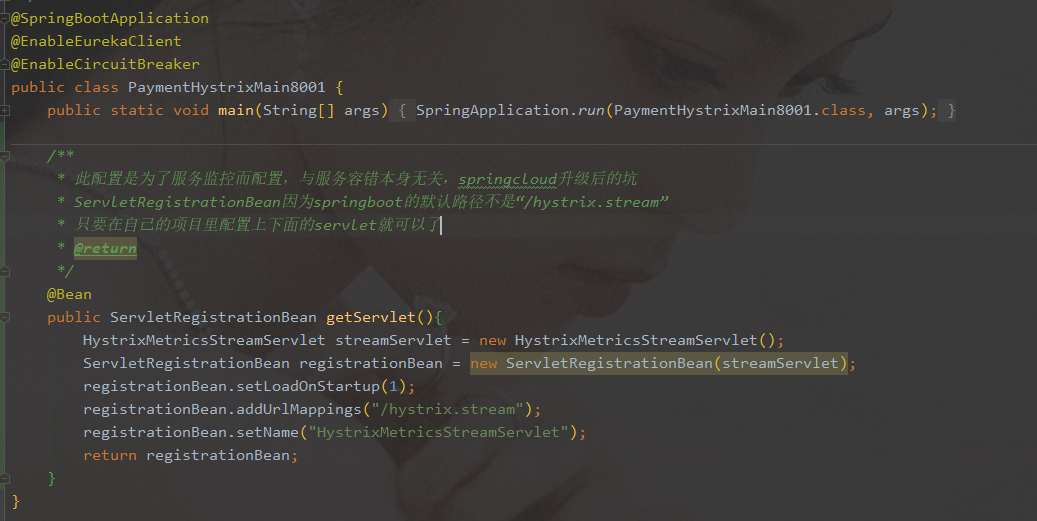
- 填写监控地址:http://localhost:8001/hystrix.stream
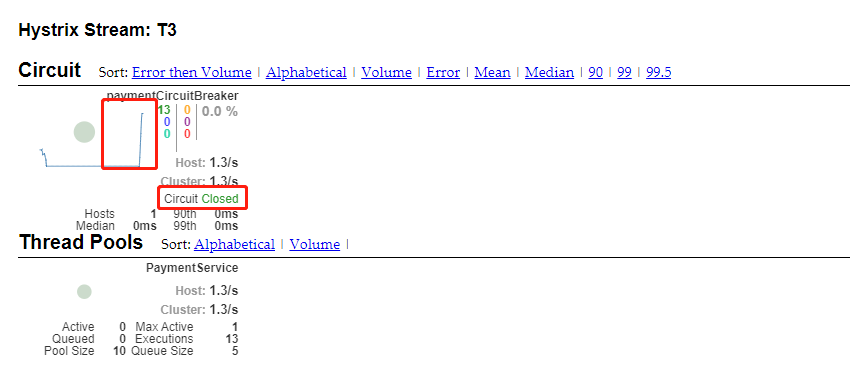
- 先访问正确地址,再访问错误地址,再正确地址,会发现图示断路器都是慢慢放开的(closed---->open 断路器打开 open--->close 断路器关闭)
- 修改
- 如何看监控界面:
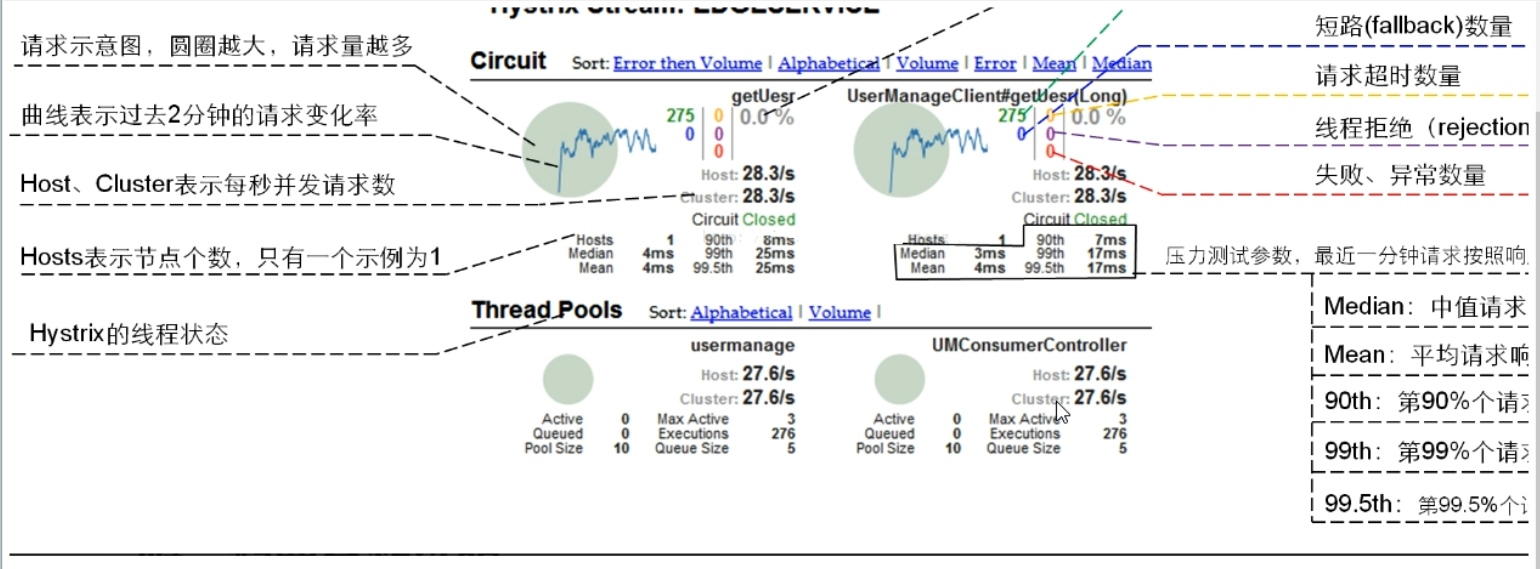
- 7色:每种颜色对应不同的故障
- 1圈:实心圈。共有两种含义,它通过颜色的变化代表了实例的健康程度,它的健康度从 绿色<黄色<橙色<红色递减。该实心圈除了颜色的变化之外,它的大小也会根据实例的请求流量发生变化,流量越大该实心圆就越大。所以通过该实心圆的展示,就可以在大量的实例中快速的发现故障实例和高压力实例
- 1线:曲线。用来记录2分钟内流量的相对变化,才可以通过它来观察到流量的上升和下降的趋势。
- 整个图的说明:
- 复杂的



服务网关
Gateway新一代网关
概述简介
-
官网:https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/html/
-
是什么
- 概述
SpringCloud Gateway是Spring Cloud的一个全新项目,它旨在为微服务架构提供一种简单有效的统一的API路由管理方式- 为了提高网关的性能,
SpringCloud Gateway是基于WebFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty SpringCloud Gateway的目标提供统一的路由方式且基于Filter链的方式提供了网关基本的功能,例如:安全,监控/指标和限流
- 一句话:Spring Cloud Gateway 使用的
Webflux中的reactor-netty响应式编程组件,底层使用了Netty通讯
- 概述
-
能干嘛
- 反向代理
- 鉴权
- 流量控制
- 熔断
- 日志监控
- ......
-
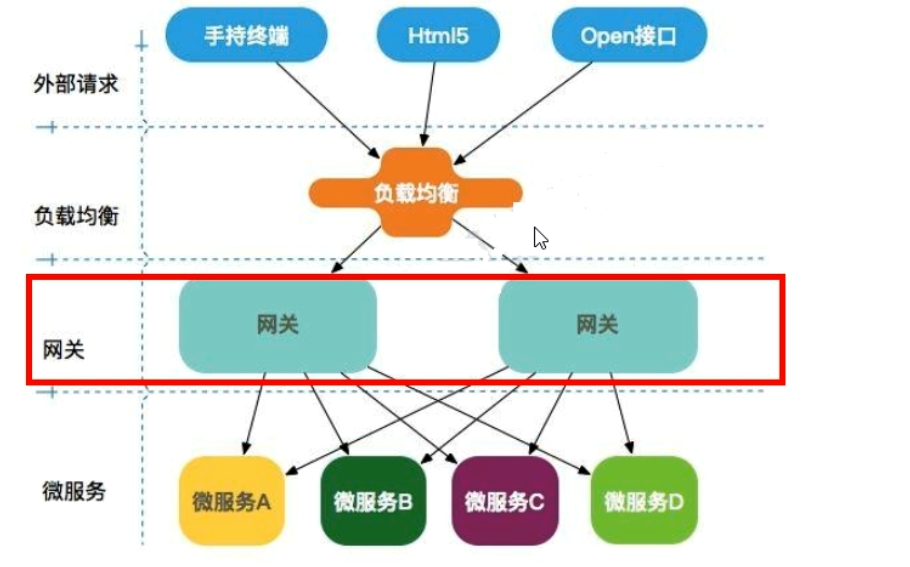
微服务架构中网关在哪里
-
为什么选择使用Gateway
- 1.neflix不太靠谱,zuul2.0一直跳票,迟迟不发布
- Spring Cloud Gateway 具有如下特性:
- 基于Spring Framework 5,Project Reactor和Spring Boot2.0进行构建
- 动态路由:能够匹配任何请求属性
- 可以对路由指定Predicate(断言)和Filter(过滤器)
- 集成Hystrix的断路器功能
- 集成Spring Cloud 服务发现功能
- 易于编写的Predicate(断言)和Filter(过滤器)
- 请求限流功能
- 支持路径重写
- Spring Cloud Gateway和Zuul的区别
- Zuul 1.x,,是一个基于阻塞I/O的API网关
- Zuul 2.x 理念更先进,想基于Netty非阻塞和支持长连接,但SpringCloud目前还没有整合。Zuul 2.x的性能比Zuul 1.x有较大的提升。在性能方面,根据官方提供的测试基准,Spring Cloud Gateway的RPS(每秒请求数)是Zuul的1.6倍
- Spring Cloud Gateway建立在Spring Framework5、Project Reator和Spring Boot 2之上,使用非阻塞API
- Spring Cloud Gateway还支持WebSocket,并且与Spring紧密集成拥有更好的开发体验
-
Zuul 1.x模型
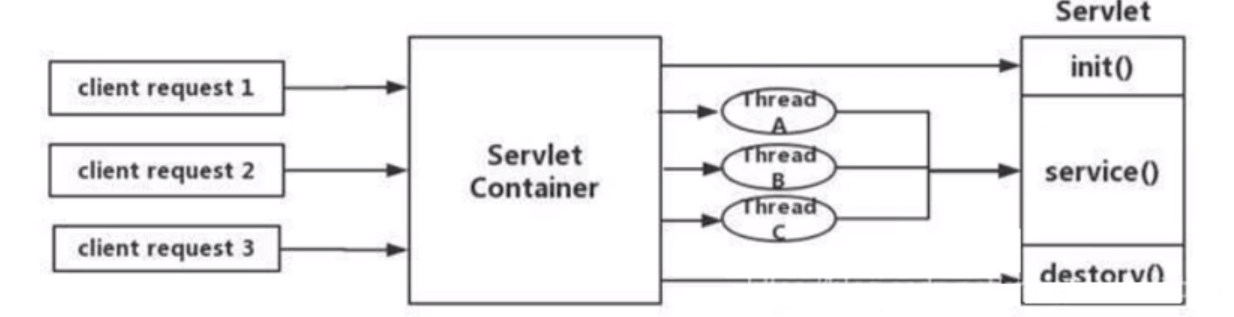
- 上述模型的缺点:servlet是一个简单的网络IO模型,当请求进入servlet container时,servlet container就会为其绑定一个线程,在并发不高的场景下,这种模型是适用的,但是一旦高并发(比如抽风用jemeter压测),线程数量就会上涨,而线程资源是昂贵的(上下文切换,内存消耗大)严重影响请求的处理时间。在一些简单业务场景下,不希望为每个request分配一个线程,只需要1个或几个线程就能应对极大并发的请求,这种业务场景下servlet模型没有优势,所以Zuul 1.x是基于servlet之上的一个阻塞式处理模型,即spring实现了处理所有请求的一个servlet(DispatcherServlet)并由该servlet阻塞式处理模型。
-
Gateway模型
-
webFlux:传统的Web框架,比如说:struts2、springmvc等都是基于Servlet API与Servlet容器基础之上运行的
但是在Servlet3.1之后有了异步非阻塞的支持。而WebFlux是一个典型非阻塞异步的框架,它的核心是基于Reactor的相关API实现的。相对于传统的微博框架来说,它可以运行在诸如Netty,Undertow以及支持Servlet3.1的容器上。非阻塞式+函数式编程(Spring5必须让你使用Java8)
Spring WebFlux是spring5.0引入的新的响应式框架,区别于Spring MVC,它不需要依赖Servlet API,它是完全异步非阻塞的且基于Reactor来实现响应式流规范
-
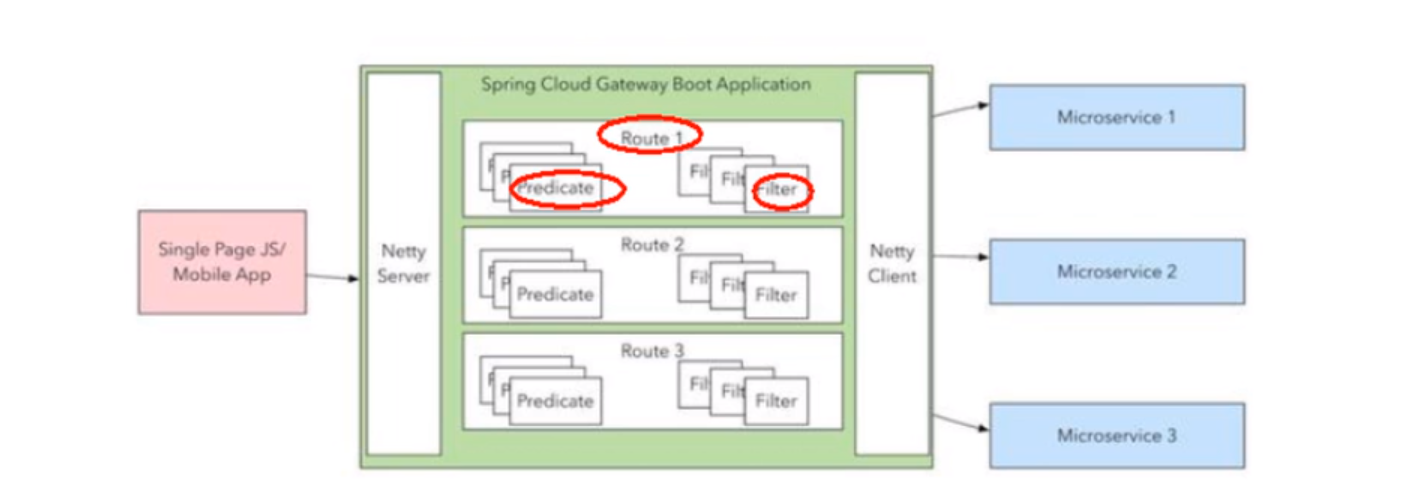
三大核心概念
-
Route(路由):路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组成,如果断言为true则匹配该路由
-
Predicate(断言):参考的是
Java8的java.util.function.Predicate.。开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数)如果请求与断言相匹配则进行路由 -
Filter(过滤器):指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由之前或者之后对请求镜像修改
-
总体
web请求,通过一些匹配条件,定位到真正的服务节点。并在这个转发过程的前后,进行一些精细化控制。perdicate就是我们的匹配条件。而Filter就可以理解为一个无所不能的拦截器,有了这两个元素,再加上目标uri,就可以实现一个具体的路由了。
Gateway工作流程
-
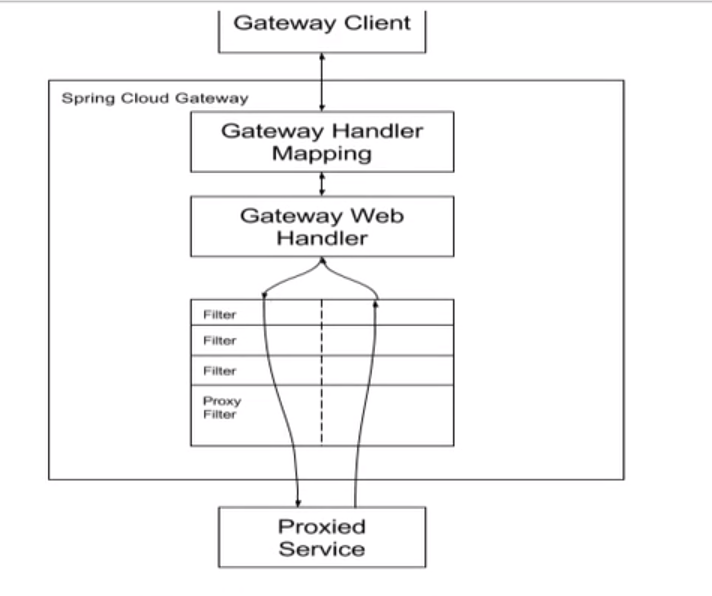
-
Gateway流程:客户端向Spring Cloud Gateway发出请求。然后在Gateway Handler Mapping 中找到与请求相匹配的路由,将其发送到Gateway Web Handler
Handler再通过指定的过滤器链来将请求发送到我们实际的服务执行业务逻辑,然后返回
过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前(“pre”)或之后(“post”)执行业务逻辑
Filter在“pre”类型的过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等,在“post”类型的过滤器中可以做响应内容、响应头的修改,日志的输出,流量监控等有非常重要的作用
入门配置
-
cloud-gateway-gateway9527
-
配置
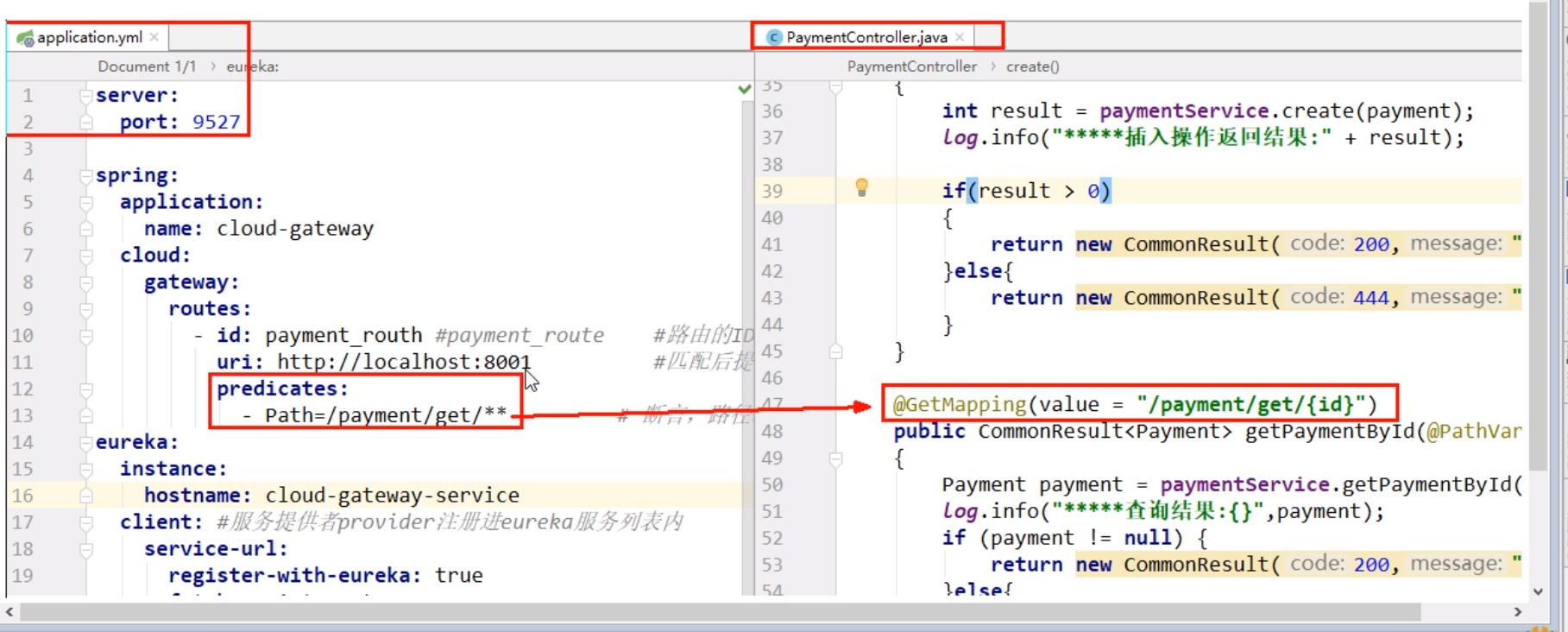
-
我们目前不想暴露8001端口,希望在8001外面套一层9527
-
测试
-
Gateway网关路由有两种配置方式
- 在配置文件yml中配置
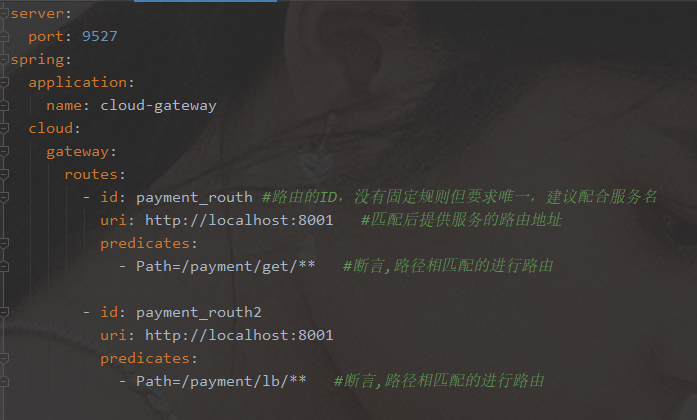
-
代码中注入RouteLocator的Bean
-
官网案例
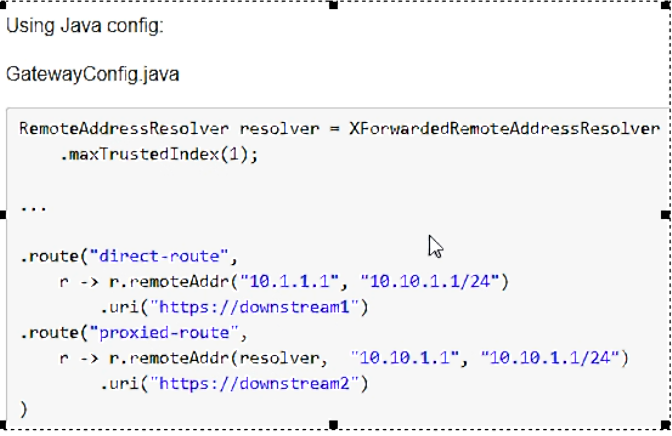
-
例子
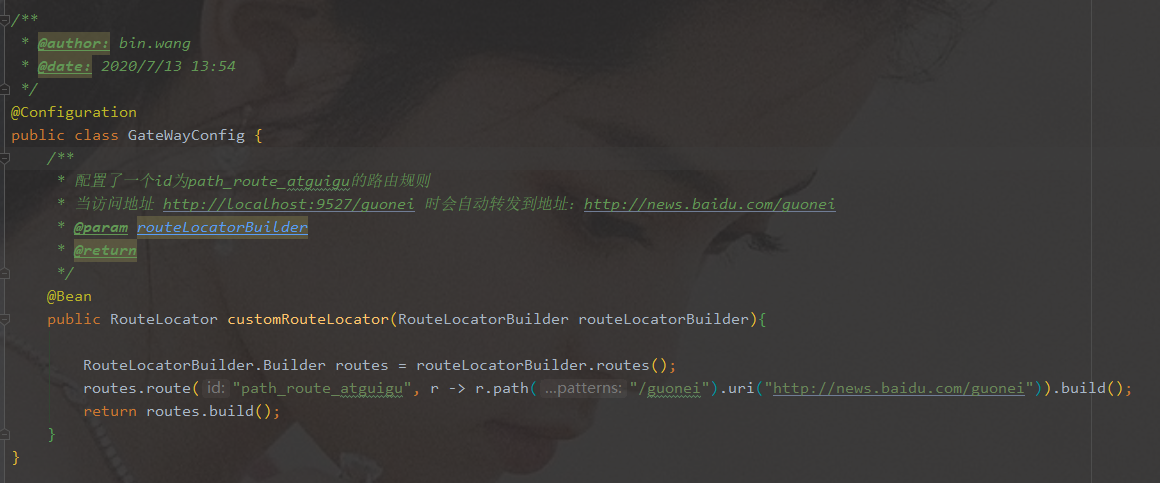
-
通过微服务名实现动态路由
-
对比未使用Gateway,提供了统一的对外端口9527
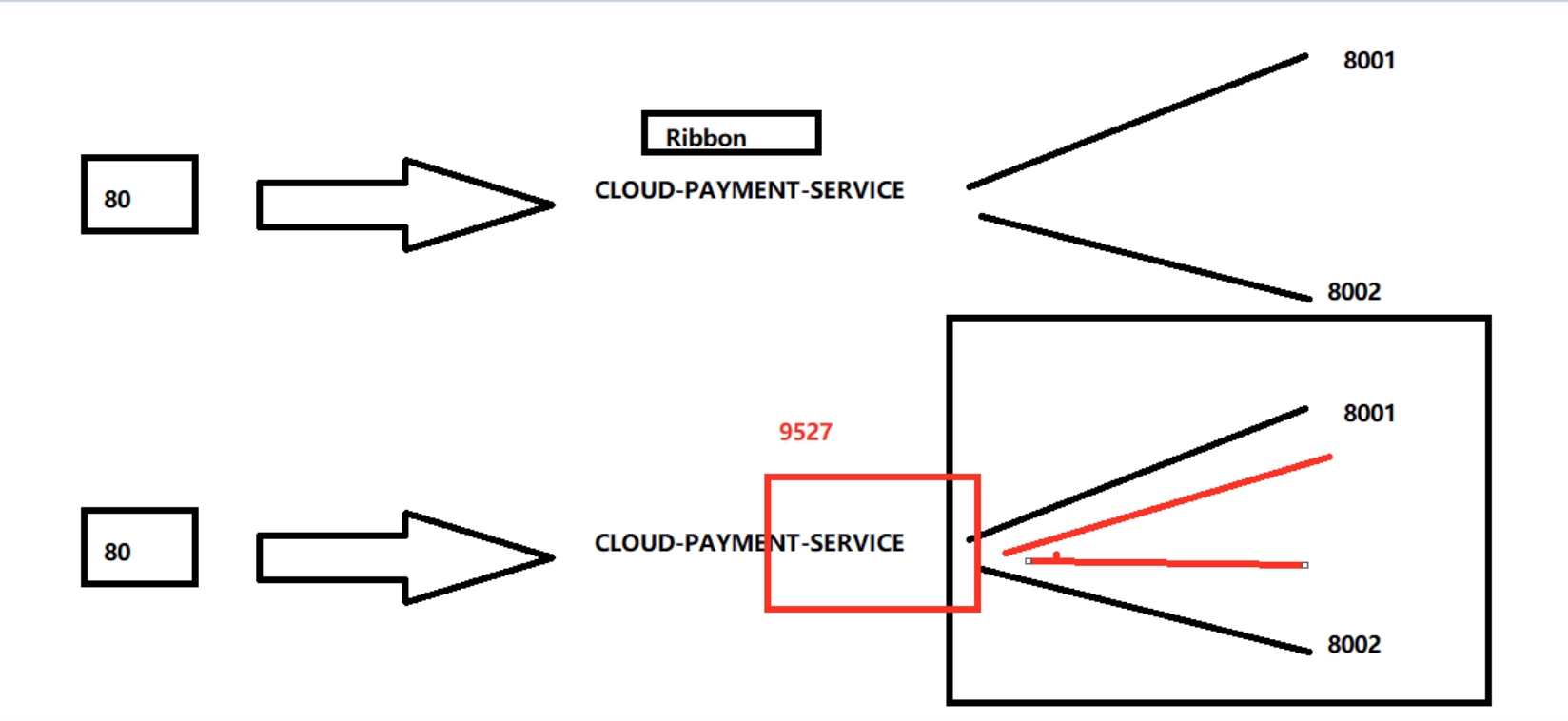
-
动态路由
- 默认情况下Gateway会根据注册中心注册的服务列表,以注册中心上微服务名为路径创建动态路由进行转发,从而实现动态路由
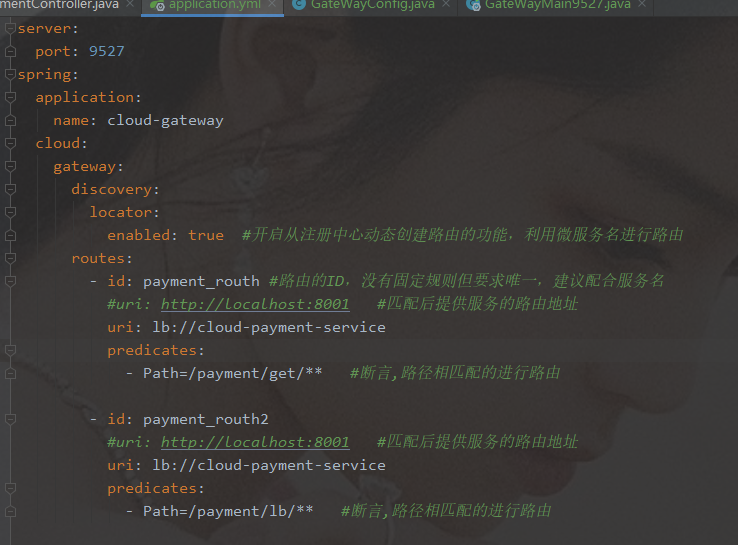
- 需要注意的是uri的协议为lb,表示启用Gateway的负载均衡功能。lb://serviceName是spring cloud gateway在微服务中自动为我们创建的负载均衡uri
- 测试:http://localhost:9527/payment/lb 看到8001/8002两个端口切换
Predicate的使用
-
是什么
-
启动9527项目 查看控制台
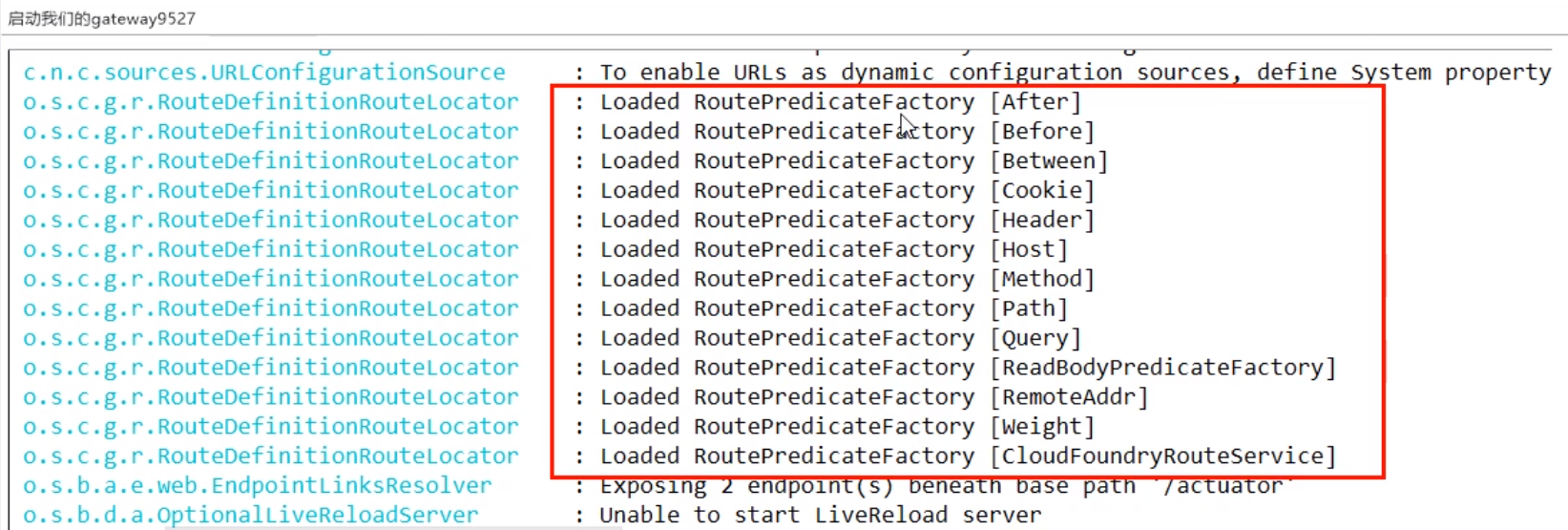
-
Route Predicate Factories这个是什么?
-
常用的Route Predicate
-
After

-
Before :同理After
-
Between:同路After
-
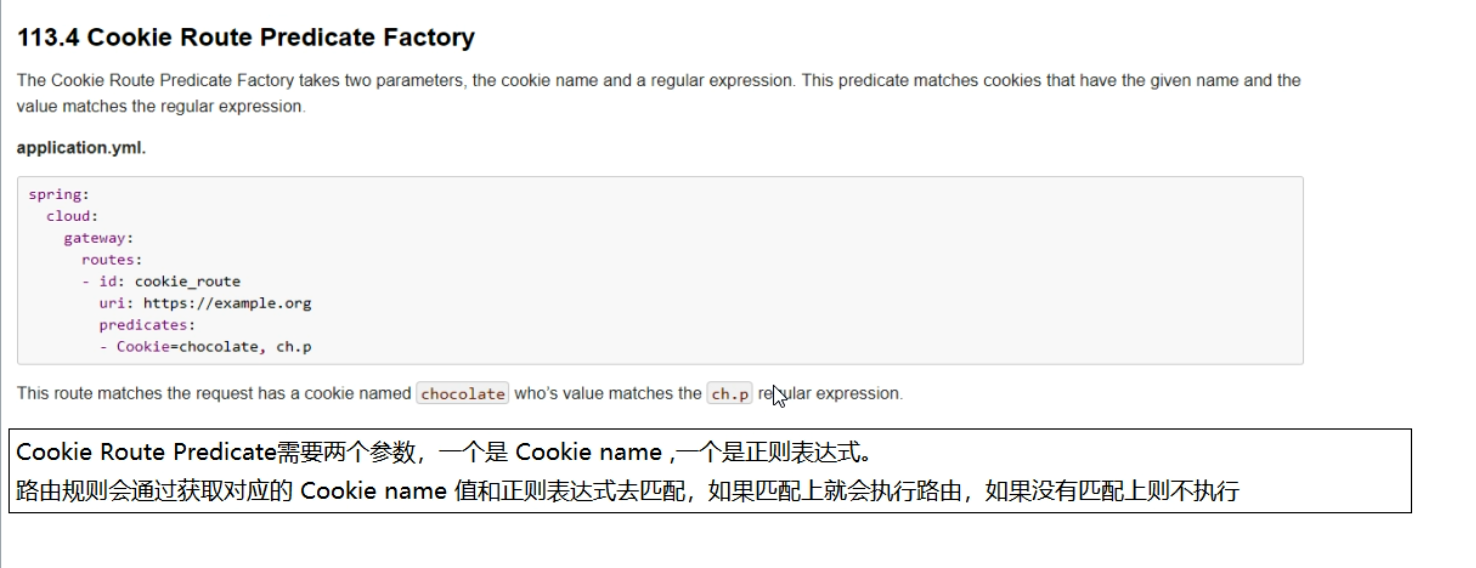
Cookie
-
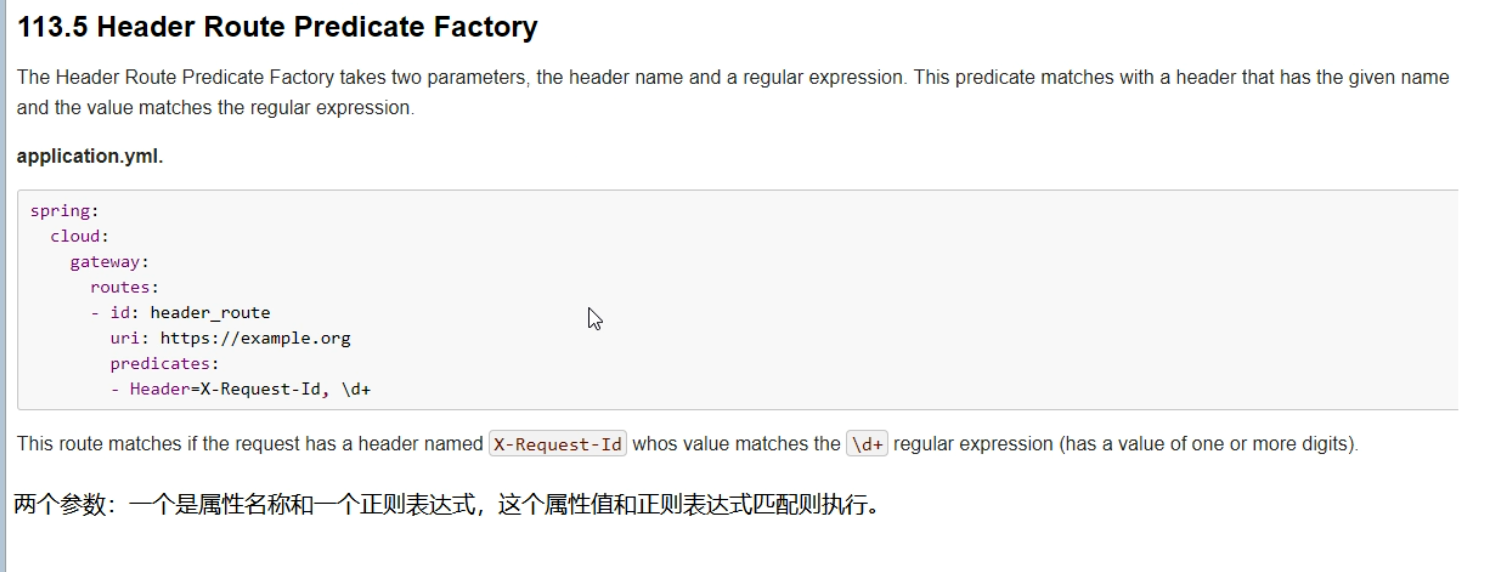
Header
-
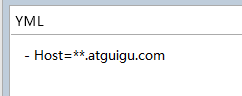
Host
-
Method
yml: -Method=GET
-
Path
-
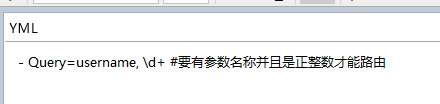
Query
-
说白了,Predicate就是为了实现一组匹配规则,让请求过来找到对应的Route进行处理
-
-

Filter的使用
-
是什么
-
Spring Cloud Gateway 的 Filter
- 生命周期 两种
- pre
- post
- 种类 两种
- Gateway Filter
- Global Filter
- 生命周期 两种
-
常用的Gateway Filter
-
自定义过滤器
- 自定义全局Global Filter
- 两个主要接口实现
implements GlobalFilter Ordered - 能干嘛
- 全局日志记录
- 统一网关鉴权
- 。。。
- 两个主要接口实现
- 自定义全局Global Filter
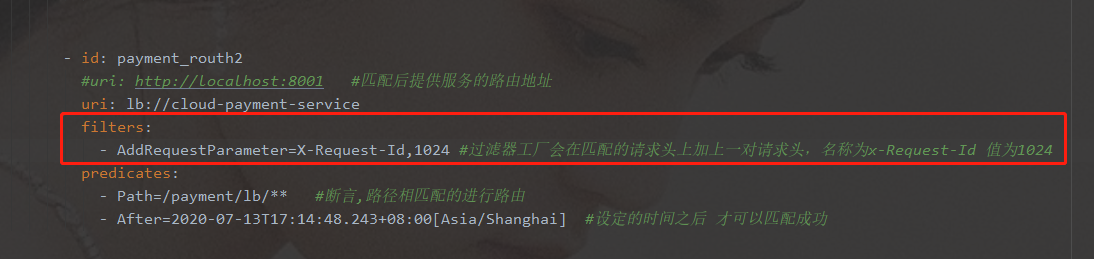
++++
服务配置
Spring Cloud config分布式配置中心
概述
-
分布式系统面临问题---配置问题
-
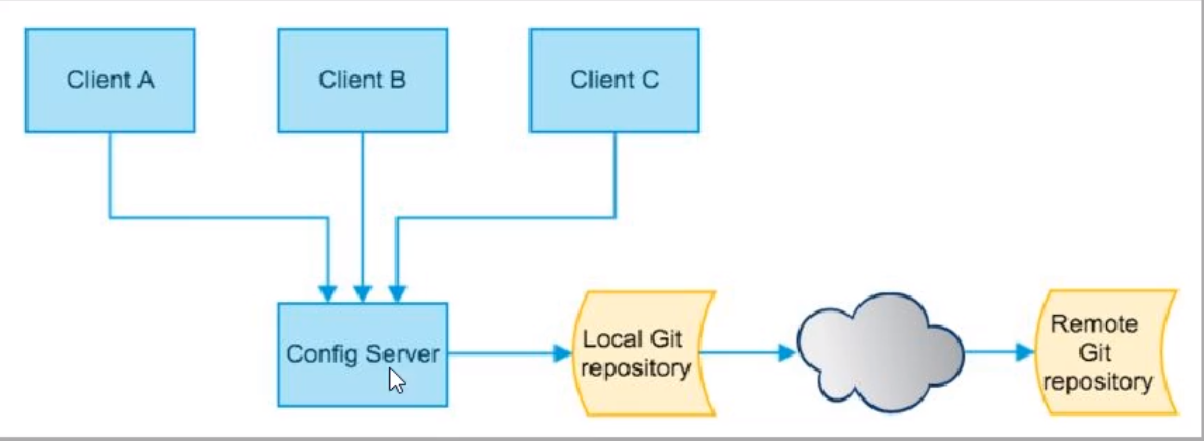
微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务。由于每个服务都需要必要的配置信息才能运行,所以一套集中式的、动态的配置管理设施是必不可少的
Spring Cloud提供了ConfigServer来解决这个问题,我们每一个微服务自己带着一个application.yml,上百个配置文件的管理
-
-
是什么
- SpringCloud Config为微服务架构中的微服务提供集中化的外部配置支持,配置服务器为各个不同微服务应用的所有环境提供了一个中心化的外部配置
-
怎么玩
- SpingCloud Config分为服务端和客户端两部分
- 服务端也称为分布式配置中心,它是一个独立的微服务应用,用来连接配置服务器并为客户端提供获取配置信息,加密/解密信息等访问接口
- 客户端则是通过指定的配置中心来管理应用资源,以及与业务相关的配置内容,并在启动的时候从配置中心获取加载配置信息,配置服务器默认采用git来存储配置信息,这样就有助于对环境配置进行版本管理,并且可以通过git客户端工具来方便的管理和访问配置内容
-
能干嘛
- 集中管理配置文件
- 不同环境不同配置,动态化的配置更新,分环境部署比如dev/test/prod/beta/release
- 运行期间动态调整配置,不再需要在每个服务不是的机器上编写配置文件,服务回向配置中心统一拉取配置自己的信息
- 当配置发生变动时,服务不需要重启即可感知到配置的变化并应用新的配置
- 将配置信息以REST接口的形式暴露
-
与GitHub整合配置
- 由于Spring Cloud Config默认使用Git来存储配置文件(也有其他方式,比如支持SVN和本地文件),但最推荐的还是Git,而且使用的是http/https访问的形式
-
官网
Config服务端配置与测试
-
新建Module模块
cloud-config-center-3344它既为Cloud的配置中心模块cloudConfig Center -
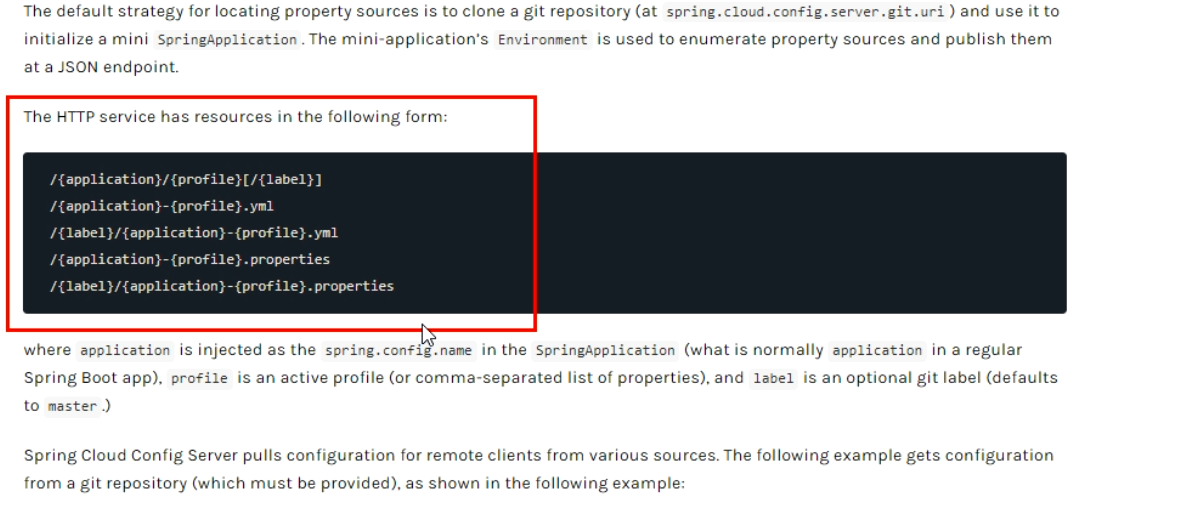
常用的配置读取规则
- /{label}/{application}-{profile}.yml ----->http://config-3344:3344/master/config-dev.yml
- /{application}-{profile}.yml ------>http://config-3344:3344/config-dev.yml
- /{application}/{profile}[/{label}]------>http://config-3344:3344/config/dev/master
Config客户端配置与测试
-
新建
cloud-config-client-3355 -
bootstrap.yml
-
是什么:

-

-
成功实现了客户端3355访问SpringCloud Config3344通过GitHub获取配置信息
-
问题随时而来,分布式配置的动态刷新
- Linux运维修改GitHub上的配置文件内容做调整
- 刷新3344,发现ConfigServer配置中心立刻响应
- 刷新3355,发现ConfigServer客户端没有任何响应
- 3355没有变化除非自己重启或者重新加载
- 难道每次运维修改配置文件,客户端都需要重启??噩梦
-
Config客户端之动态刷新(**)
-
避免每次更新配置都要重启客户端微服务3355
-
动态刷新
-
yml 暴露监控端口号
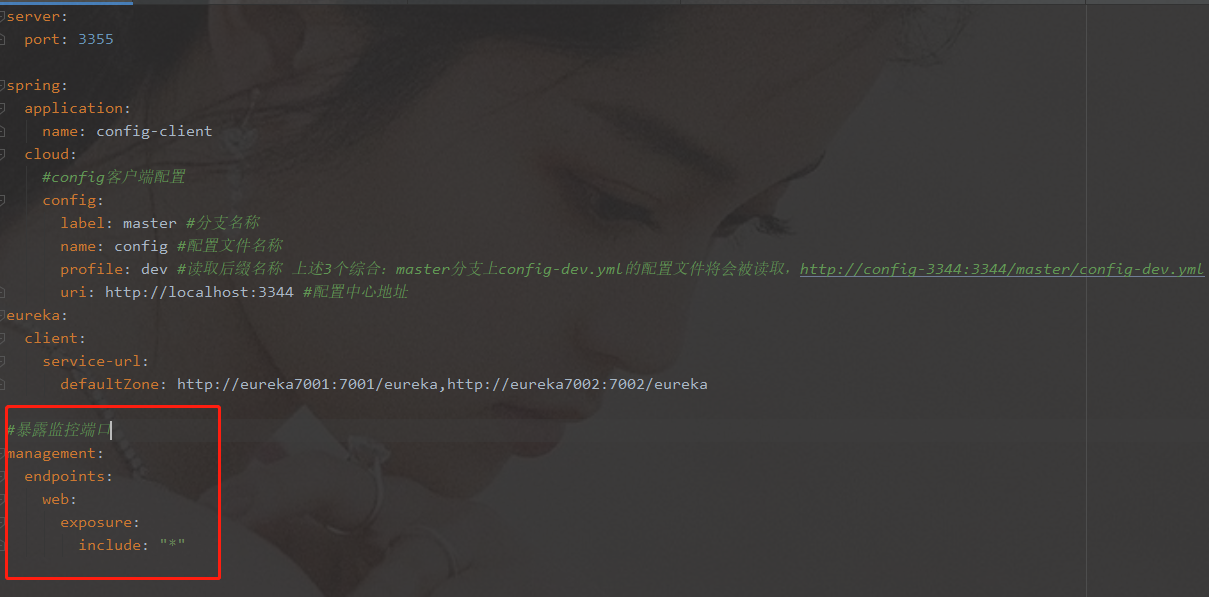
-
添加@RefreshScope 注解
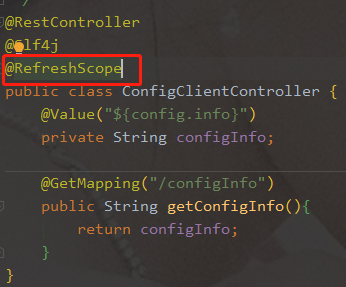
-
需要运维人员发送Post请求刷新3355--->curl -X POST "http://localhost:3355/actuator/refresh"
-
成功实现了客户端3355刷新到最新配置内容,避免了服务的重启
-
-
想想还有什么问题?---->引出了spring cloud bus消息总线
- 假如有多个微服务客户端3355/3366/3377。。。。
- 每个微服务都要执行一次post请求,手动刷新?
- 可否广播,一次通知,处处生效?
- 我们想大范围的自动刷新
++++
服务总线
Spring Cloud Bus消息总线
概述
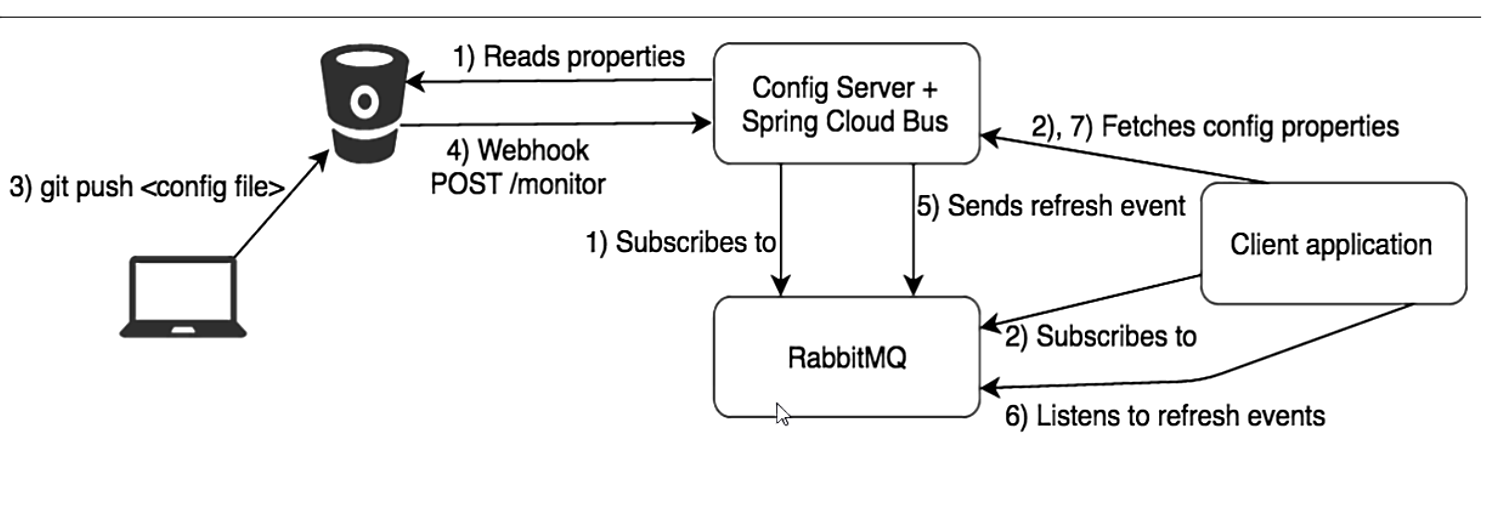
- 上一讲的加深和扩充,分布式自动刷新配置功能,SpringCloud Bus和SpringCloud Config使用可以实现配置的动态刷新
- 是什么
- Bus支持两种消息代理:RabbitMQ和Kafka
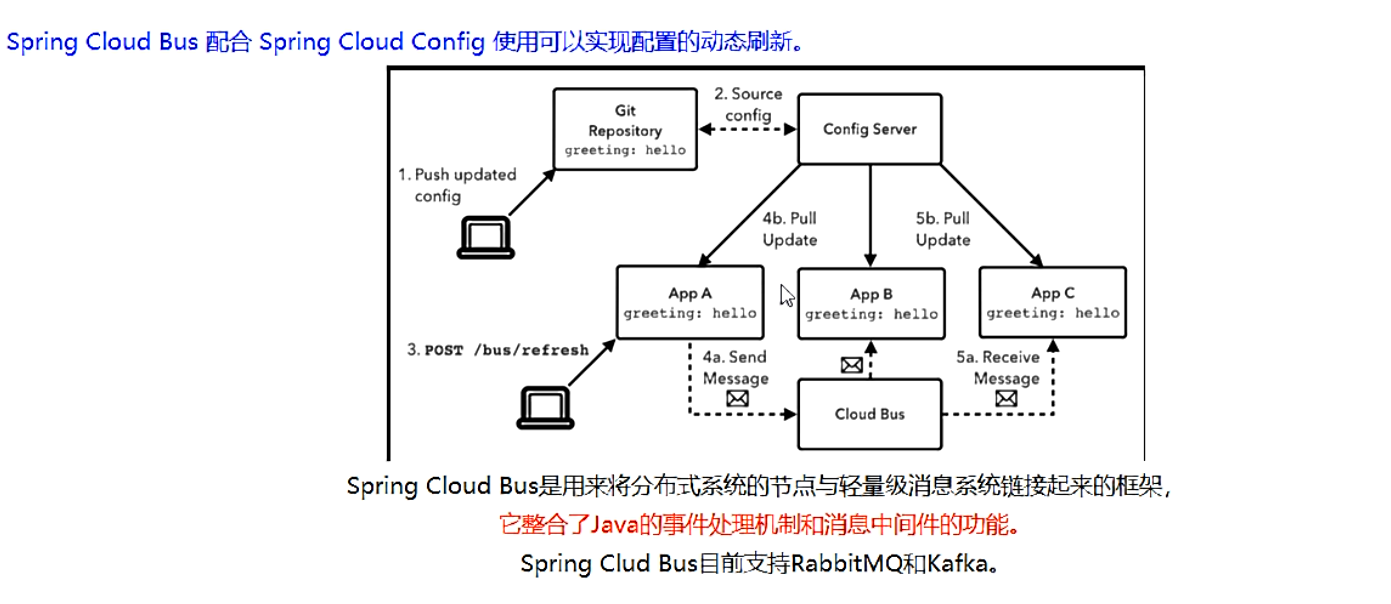
- 能干嘛
- 为何被称为总线
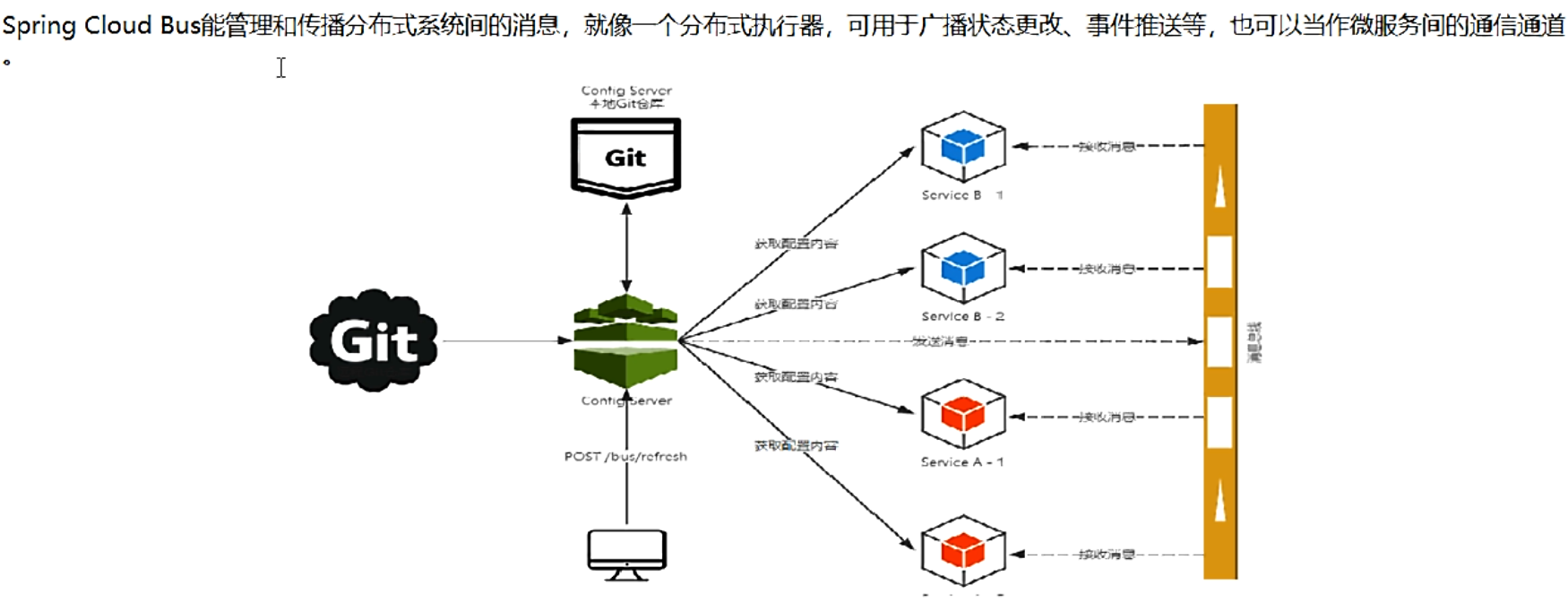
- 什么是总线:在微服务架构的系统中,通常会使用轻量级的消息代理来构建一个共用的消息主题,并让系统中的所有微服务实例都连接上来。由于该主题中产生的消息会被所有实例监听和消费,所以称它为消息总线。在总线上的各个实例,都可以方便的广播一些需要让其他连接在该主题上的实例都知道的消息。
- 基本原理:Config Client实例都监听MQ中同一个topic(默认是SpringCloud Bus).当一个服务刷新数据的时候,它会把这个信息放入到Topic中,这样其他监听同一Topic的服务就能得到通知,然后去更新自身的配置。
RabbitMQ环境配置(docker 启动)
SpringCloud Bus动态刷新全局广播
-
cloud-config-client-3366
-
设计思想:
- 利用消息总线触发一个客户端/bus/refresh,而刷新所有客户端的配置
- 利用消息总线触发一个服务端ConfigServer的/bus/refresh端点,而刷新所有客户端的配置(更加推荐)
- 利用消息总线触发一个客户端/bus/refresh,而刷新所有客户端的配置
-
第二种设计显然更加合适,第一种不适合的原因如下:
- 打破了微服务的职责单一性,因为微服务本身是业务模块,它本不应该承担配置刷新的职责
- 破坏了微服务各个节点的对等性
- 有一定的局限性,例如,微服务在迁移时,它的网络地址会常常发生变化,此时如果想要做到自动刷新,那就回增加更多的修改
-
示例
- 给cloud-config-center-3344配置中心服务端添加消息总线支持
- 给cloud-config-client-3355客户端添加消息总线支持
- 给cloud-config-client-3366客户端添加消息总线支持
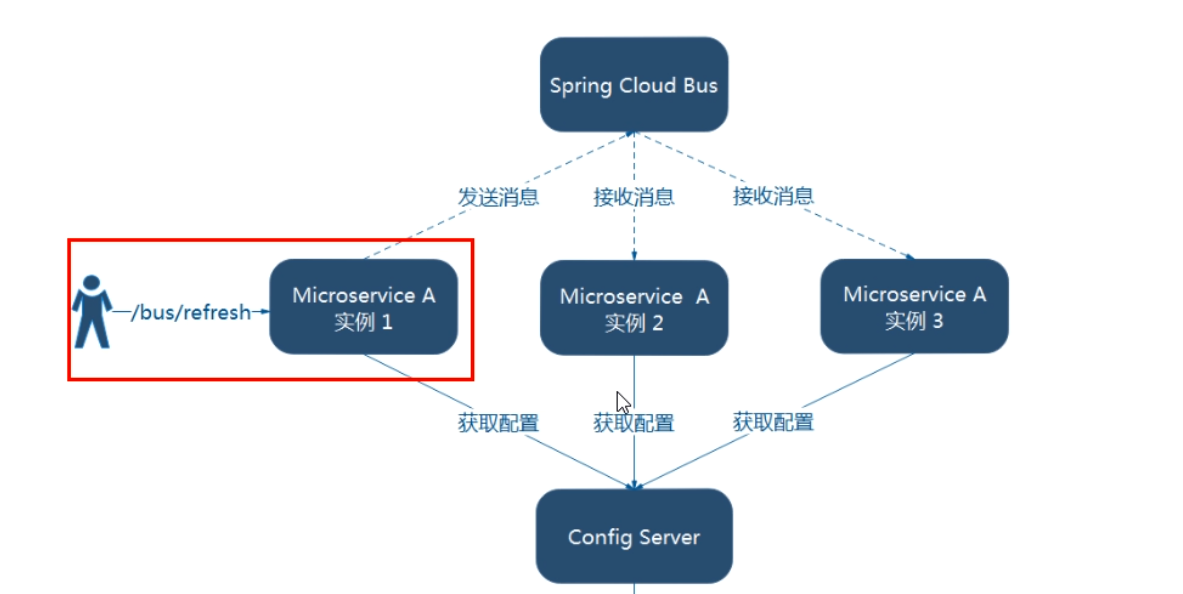
- 测试 curl -X POST "http://localhost:3344/actuator/bus-refresh"
- 一次发送,处处生效
-
一次修改,广播通知,处处生效
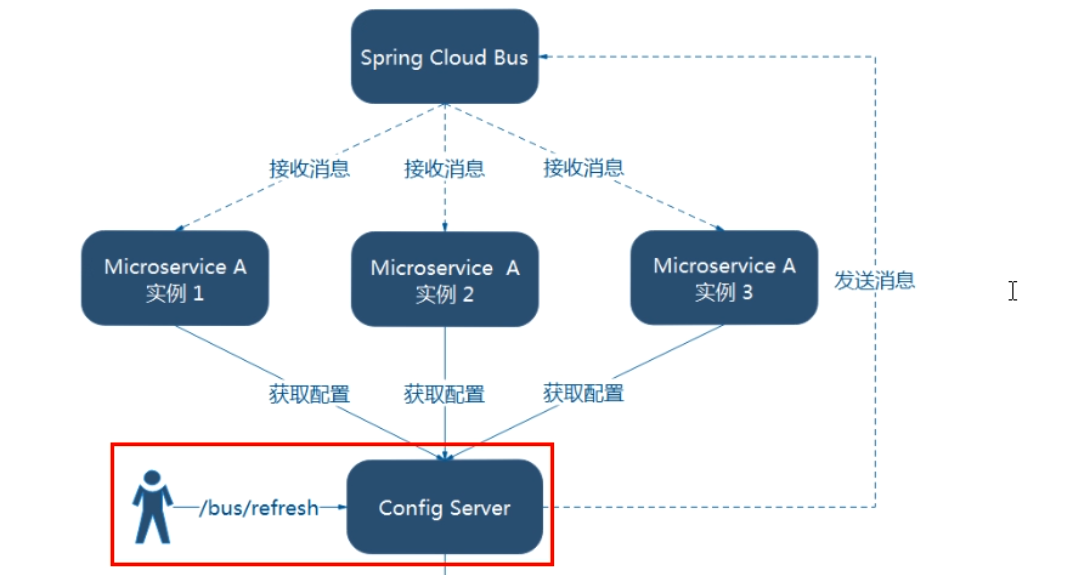
SpringCloud Bus动态刷新定点通知
-
不想全部通知,只想定点通知
-
一句话:指定具体某一个实例生效而不是全部
- 公式:http://localhost:配置中心的端口号/actuator/bus-refresh/{destination}
- /bus/refresh请求不再发送到具体的服务实例上,而是发给config server并通过destination参数类指定需要更新配置的服务或实例
-
案例:我们这里以刷新运行在3355端口上的config-client为例,只通知3355,不通知3366
-
curl -X POST "http://localhost:3344/actuator/bus-refresh/config-client:3355"
-
案例总结
SpringCloud Stream消息驱动
为什么要引入SpringCloud Stream
- 解决什么痛点
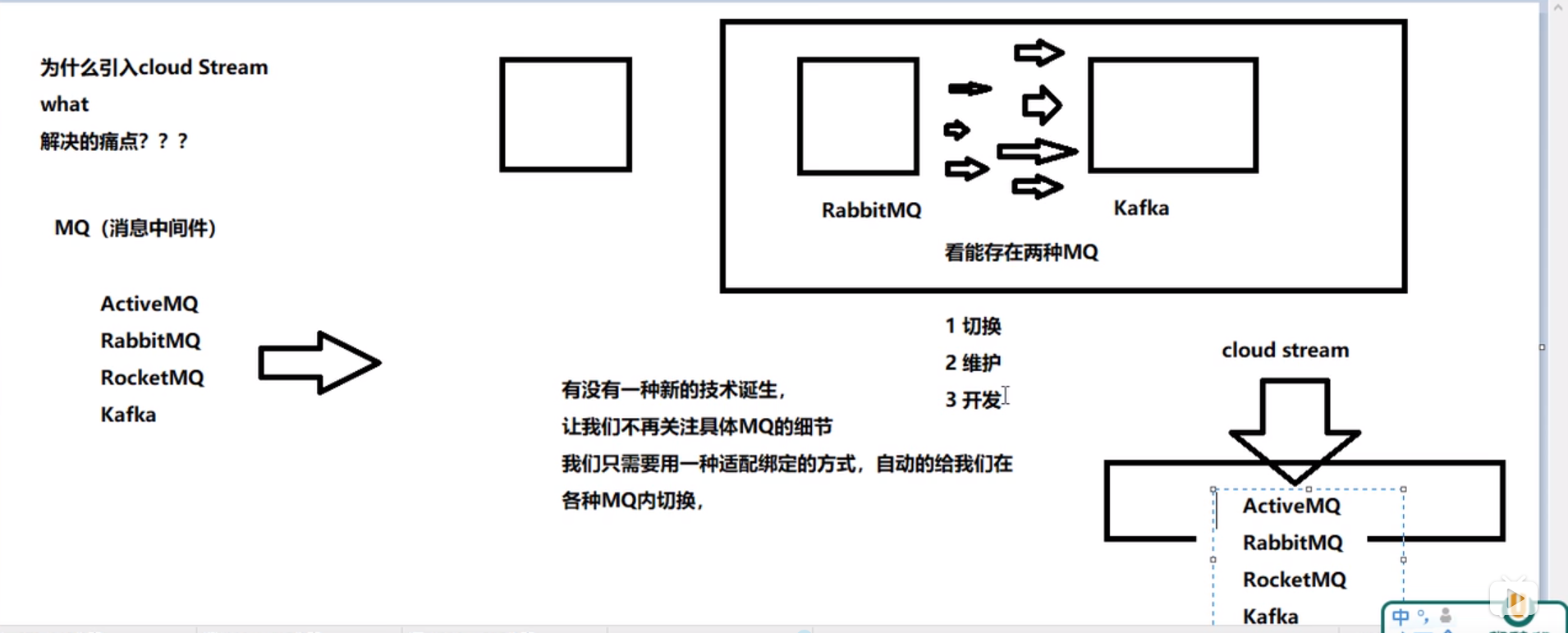
消息驱动概述
-
是什么
-
屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型
-
官网:https://spring.io/projects/spring-cloud-stream#overview
Spring Cloud Stream中文指导手册:https://m.wang1314.com/doc/webapp/topic/20971999.html
-

-
-
设计思想
- 标准MQ
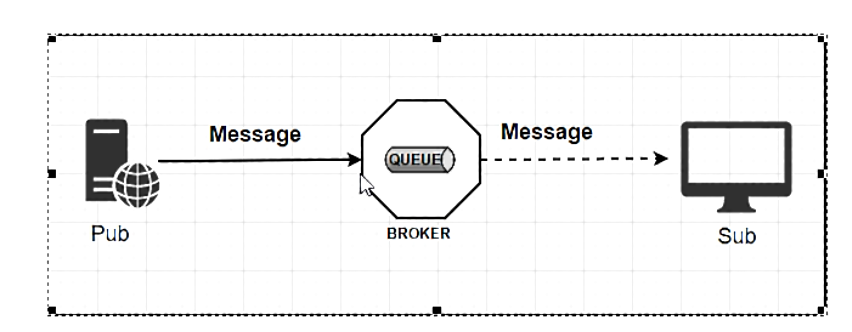
- Message:生产者/消费者之间靠消息媒介传递信息内容
- 消息通道MessageChannel:消息必须走特定的通道
- 消息通道MessageChannel的子接口SubscribableChannel,由MessageHandler消息处理器订阅:消息通道里的消息如何被消费呢,谁负责收发处理
- 为什么用Cloud Stream

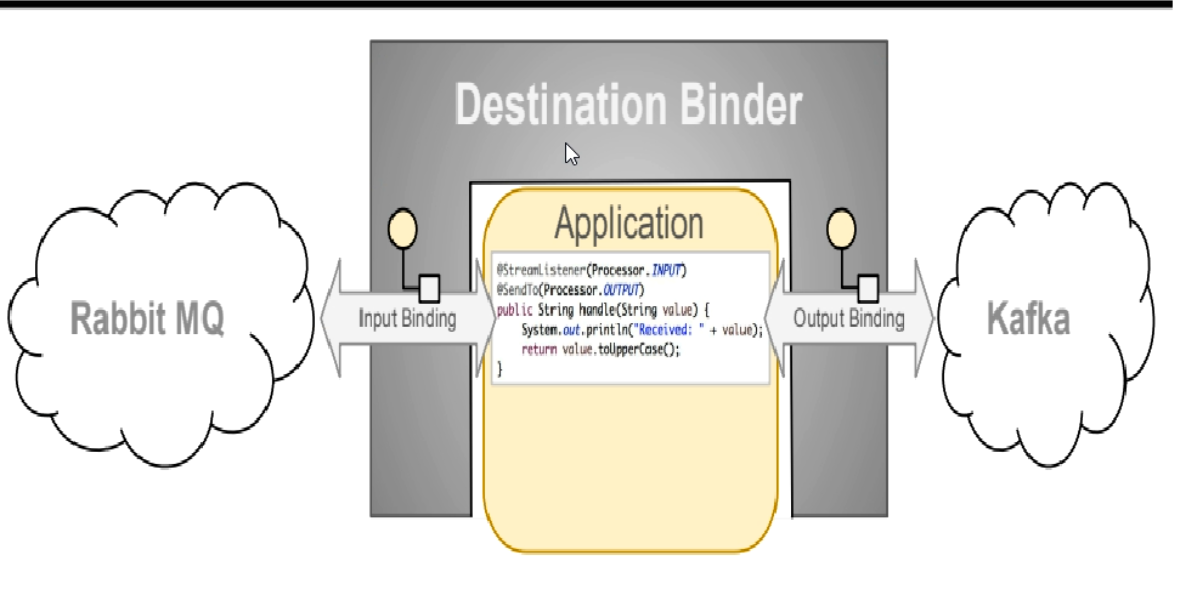
- Stream凭什么可以统一底层差异

- 通过定义绑定器Binder作为中间层,实现了应用程序与消息中间件细节之间的隔离
- Binder
- INPUT对应于消费者
- OUTPUT对应于生产者
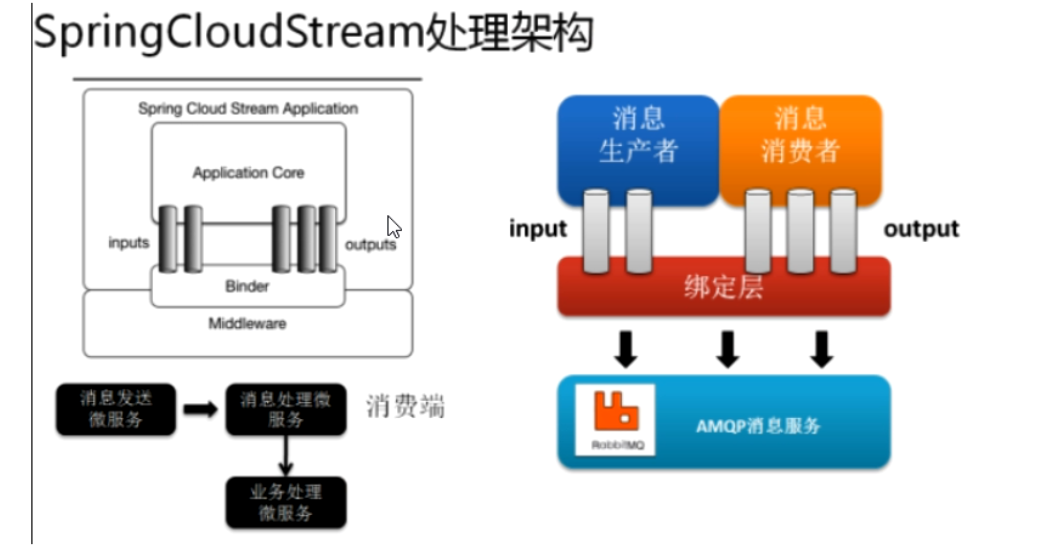
- Stream中的消息通信方式遵循了发布-订阅模式
- Topic主题进行广播
- 在RabbitMQ中就是Exchange
- 在Kakfa中就是Topic
- Topic主题进行广播
- 标准MQ
-
Spring Cloud Stream标准流程套路
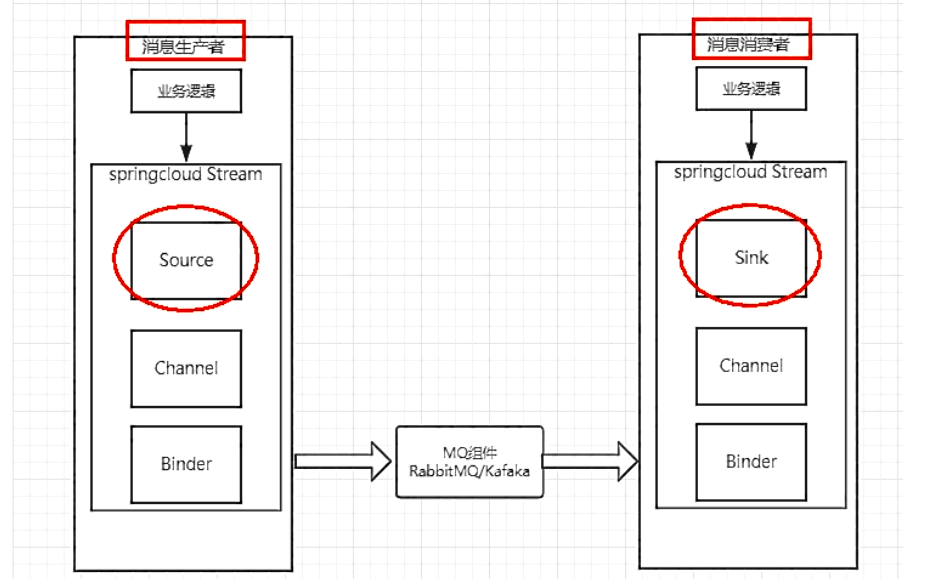
- Binder:很方便的连接中间件,屏蔽差异
- Channel:通道,是队列Queue的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过Channel对队列进行配置
- Source和Sink:简单的可理解为参照对象是Spring Cloud Stream自身,从Stream发布消息就是输出,接受消息就是输入
-
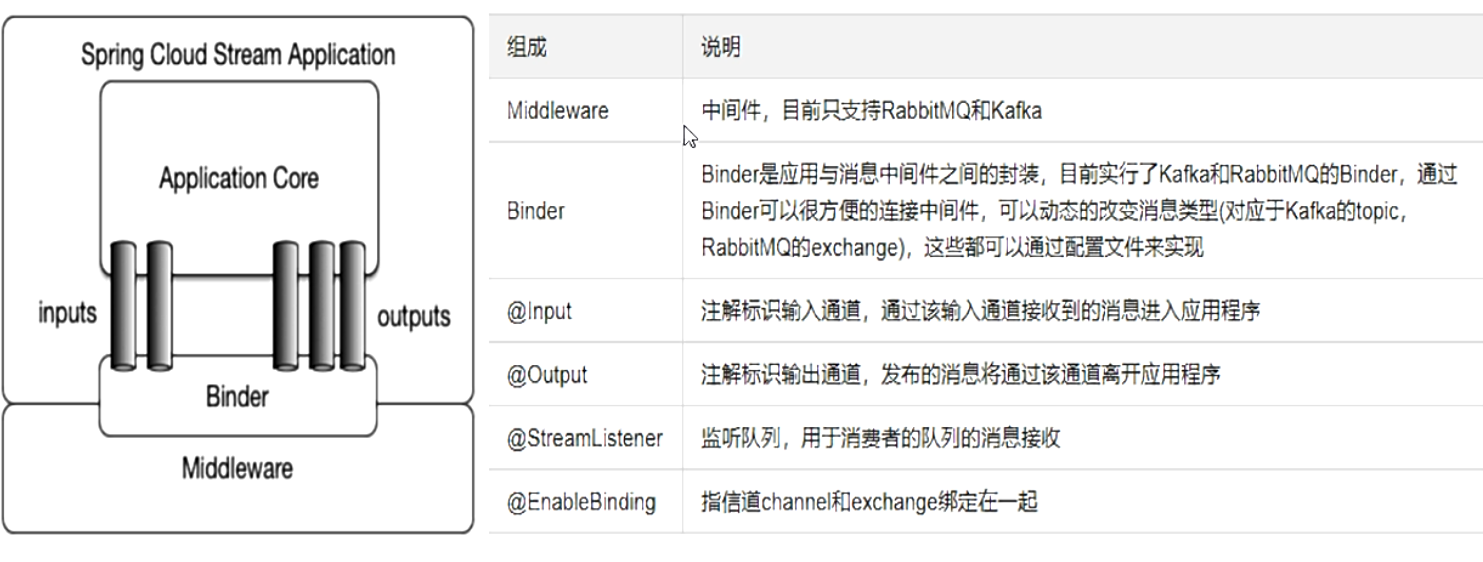
编码API和常用注解
案例说明
- RabbitMQ环境已经OK
- 三个子模块
- cloud-stream-rabbitmq-provider8801,作为生产者发送消息模块
- cloud-stream-rabbitmq-consumer8802,作为消息接收模块
- cloud-stream-rabbitmq-consumer8803 作为消息接收模块
消息驱动之生产者
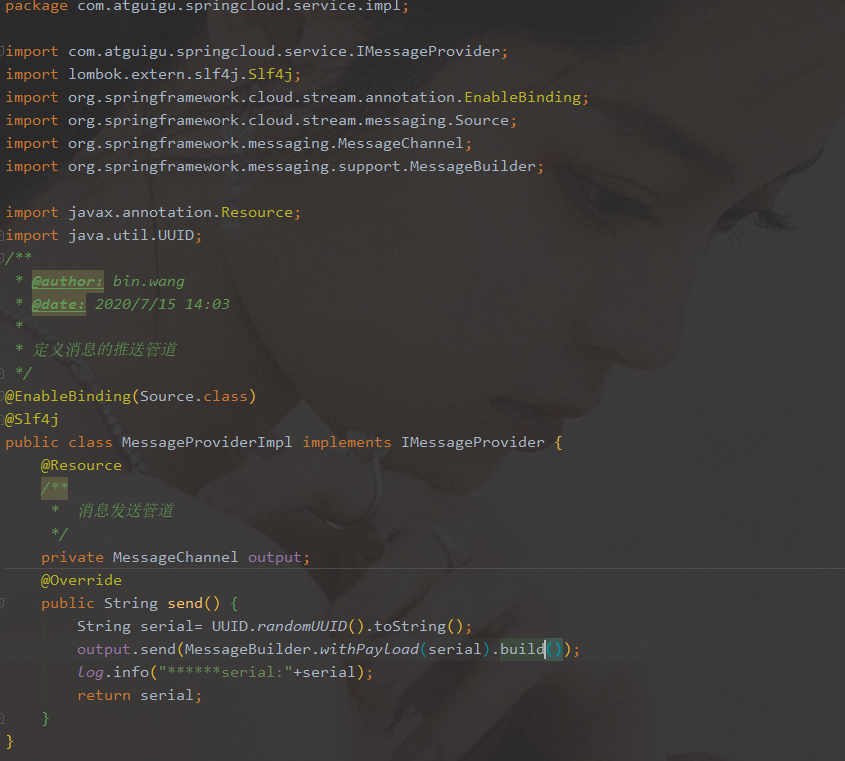
-
cloud-stream-rabbitmq-provider8801
-
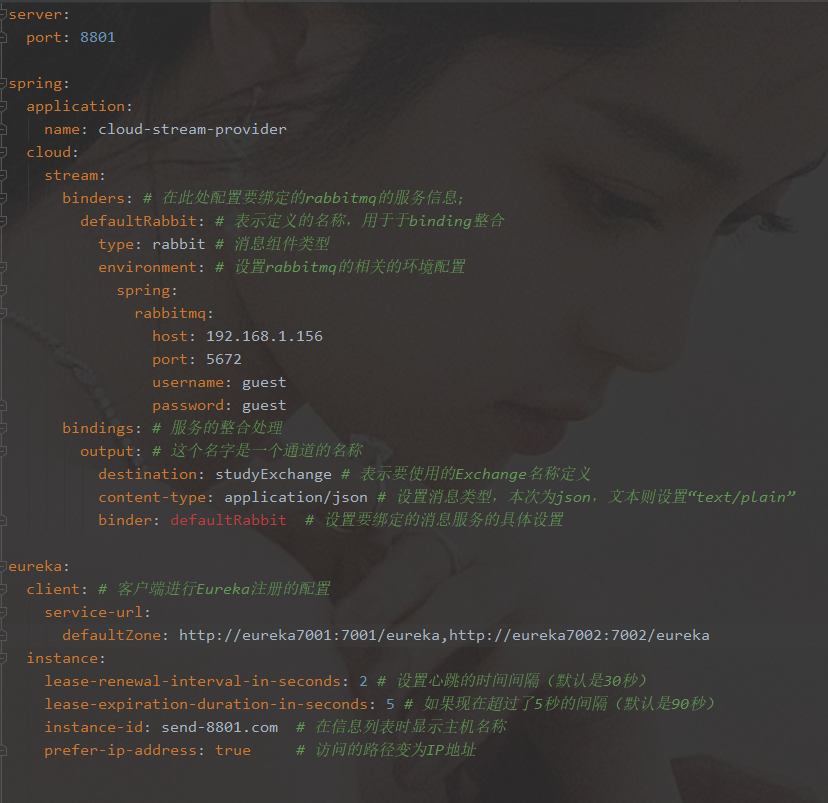
-
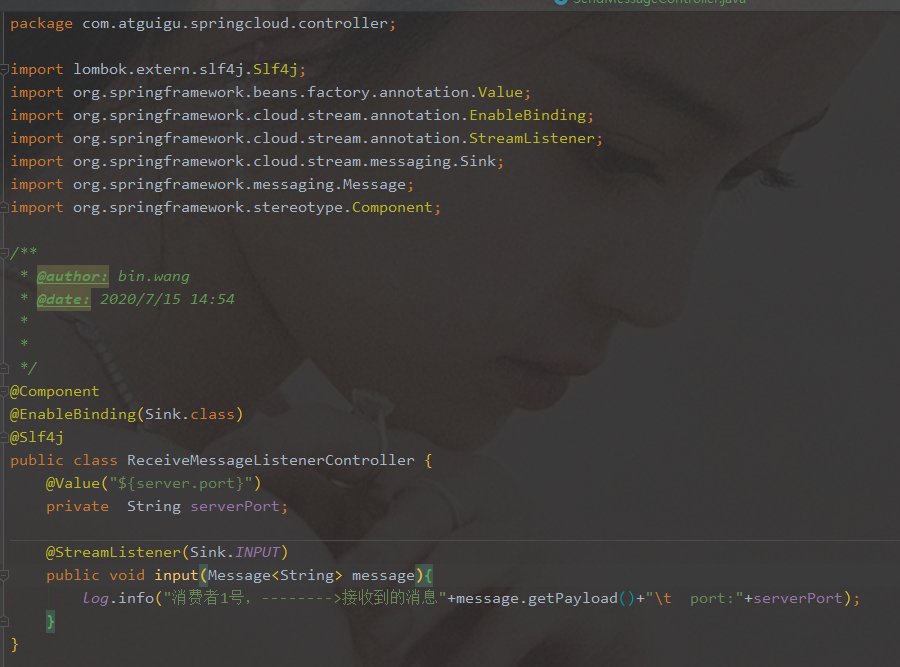
消息驱动之消费者
- cloud-stream-rabbitmq-consumer8802
分组消费(避免重复消费)与持久化
- 依照8802,clone一份8803,cloud-stream-rabbitmq-consumer8803
- 8001生产消息,8002和8003消费
- 存在两个问题:
- 重复消费

- 解决方案:分组和持久化属性group(**)
- 生产实际案例:
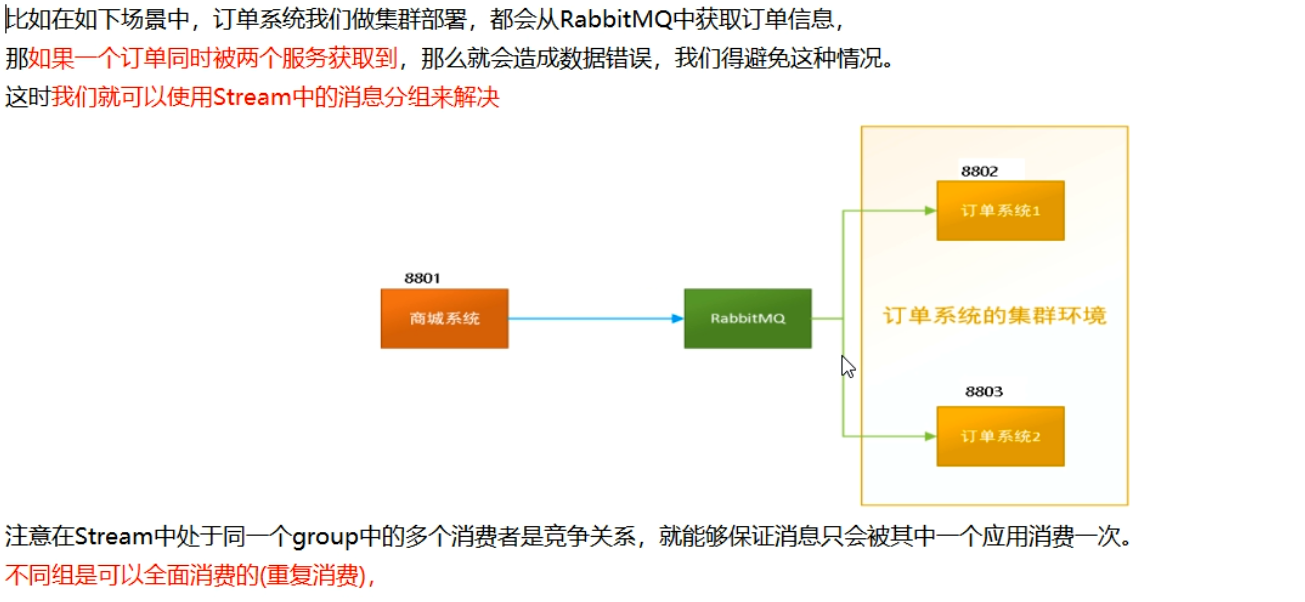
- 不同的组是可以全面消费的(重复消费);同一组内会发生竞争关系,只有其中一个可以消费
- 分组
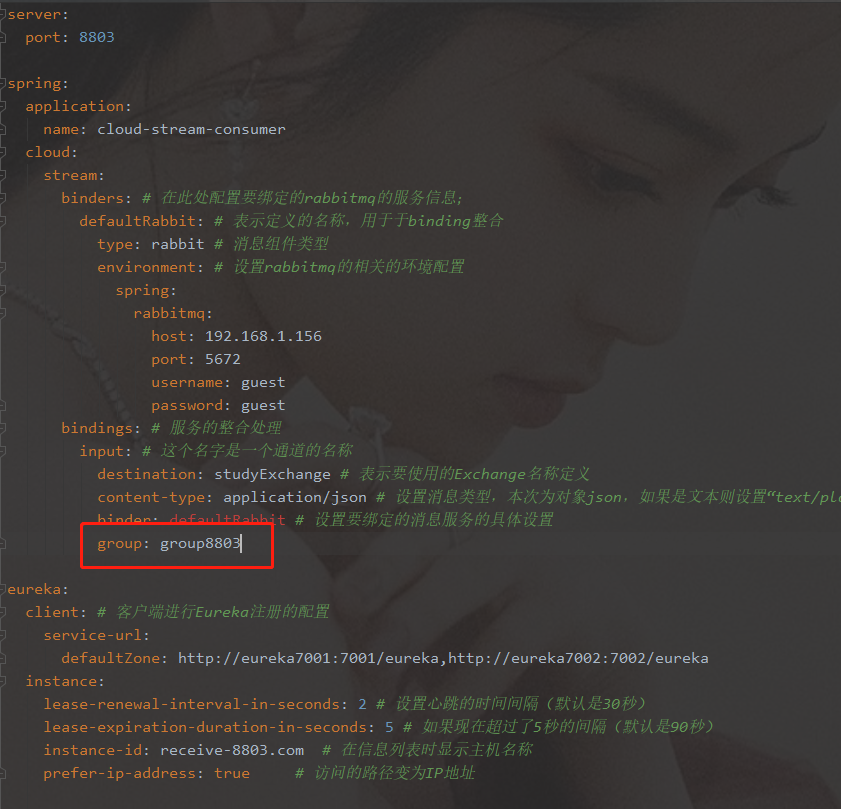
- 原理:微服务应用放置于同一个group中,就能保证消息只会被其中一个应用消费一次。不同的组是可以完全消费的,同一个组内会发生竞争关系,只有其中一个可以消费
- 默认生成流水号,处于不同组,导致重复消费
- 8802/8803实现了轮询分组,每次只有一个消费者 8801模块的发的消息只能被8802或8803其中一个接收到,这样避免了重复消费-
- 8802/8803都变成相同组,两个group相同,同一个组的多个微服务实例,每次只会被一个实例消费
- 消息持久化
- 加上group属性 默认持久化
- 去掉group属性,取消了持久化
- 重复消费
SpringCloud Sleuth 分布式请求链路跟踪
概述
- 为什么会出现这个技术?需要解决哪些问题?
- 是什么
- 官网:https://github.com/spring-cloud/spring-cloud-sleuth
- Spring Cloud Sleuth提供了一套完整的服务跟踪的解决方案,在分布式系统中提供追踪解决方案并且兼容支持了zipkin
链路监控(略)
下篇 SpringCloud Alibaba
SpringCloud Alibaba 入门简介
为什么会出现SpringCloud Alibaba
- Spring Cloud Netflix项目进入维护模式
- SpringCloud NetFlix Projects Entering Maintenance Mode
- 什么是维护模式


SpringCloud Alibaba带来了什么
- 是什么
- 能干嘛
- 服务限流降级:默认支持 WebServlet、WebFlux, OpenFeign、RestTemplate、Spring Cloud Gateway, Zuul, Dubbo 和 RocketMQ 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级 Metrics 监控
- 服务注册与发现:适配Spring Cloud服务注册与发现标准,默认集成了Ribbon的支持
- 分布式配置管理:支持分布式系统中的外部化配置,配置更改时自动刷新
- 消息驱动能力:基于Spring Cloud Stream为微服务应用构建消息驱动能力
- 分布式事务:使用 @GlobalTransactional 注解, 高效并且对业务零侵入地解决分布式事务问题
- 阿里云对象存储:阿里云提供的海量、安全、低成本、高可靠的云存储对象。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据
- 分布式任务调度:提供秒级、精准、高可靠、高可用的定时(基于Cron表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有Worker(schedulerx-client)上执行
- 阿里云短信服务:覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道
- 组件
- Sentinel:把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性
- Nacos:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台
- RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术、提供低延时的、高可靠的消息发布与订阅服务
- Dubbo:Apache Dubbo是一款高性能的Java RPC框架
- Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案
- Alibaba Cloud ACM:一款在分布式架构环境中对应用配置进行集中管理和推送的应用配置中心产品
- Alibaba Cloud OSS:阿里云对象存储服务(Object Storage Service,简称OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据
- Alibaba Cloud ScheduleX:阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准、高可靠、高可用的定时(基于Cron表达式)任务调度服务
- Alibaba Cloud SMS:覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道

SpringCloud alibaba学习资料获取
- 官网:https://spring.io/projects/spring-cloud-alibaba#overview
- 英文;https://github.com/alibaba/spring-cloud-alibaba和https://spring-cloud-alibaba-group.github.io/github-pages/greenwich/spring-cloud-alibaba.html
- 中文:https://github.com/alibaba/spring-cloud-alibaba/blob/master/README-zh.md
Spring Cloud Alibaba Nacos服务注册和配置中心
Nacos简介
-
为什么叫Nacos
- 前四个字母分别是Naming和Configuration的前两个字母,最后的s为Service
-
是什么
-
一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台
-
Nacos:Dynamic Naming and Configuration Service
-
Nacos就是注册中心+配置中心的组合--->Nacos=Eureka + Config + Bus
-
Nacos 致力于帮助您发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。
Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。 Nacos 是构建以“服务”为中心的现代应用架构 (例如微服务范式、云原生范式) 的服务基础设施。
-
-
能干嘛
- 替代Eureka做服务注册中心
- 替代Config做服务配置中心
-
去哪下
-
各种注册中心比较
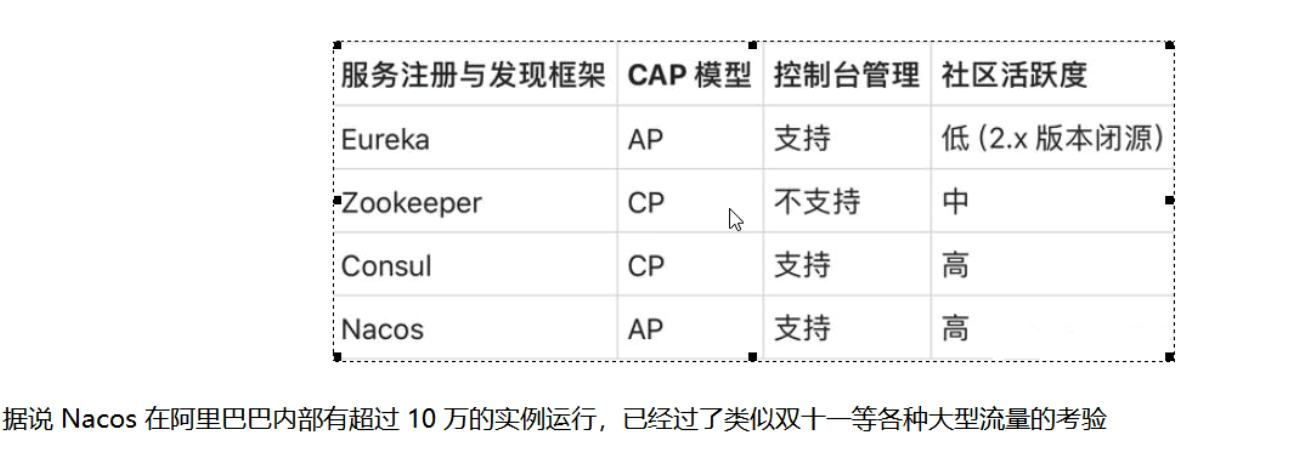
安装并运行Nacos(官网下载)
Nacos作为服务注册中心演示
-
cloudalibaba-provider-payment9001,cloudalibaba-provider-payment9002
-
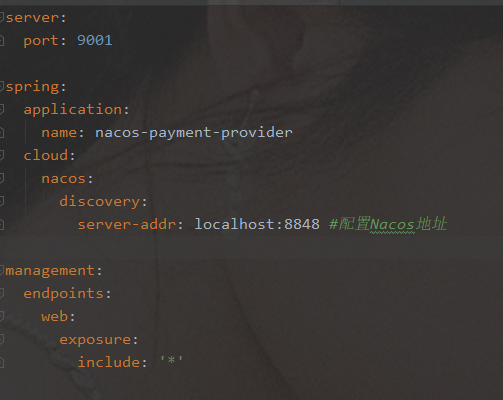
-
cloudalibaba-consumer-nacos-order83
-
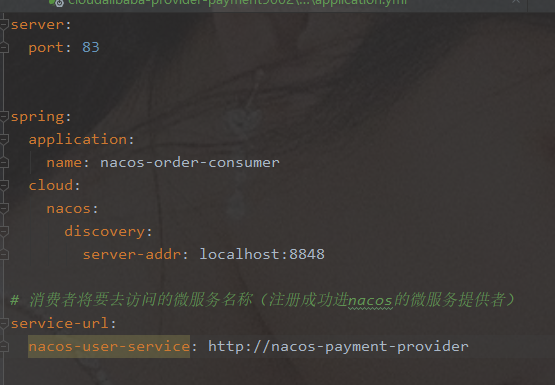
-
注册进了Nacos
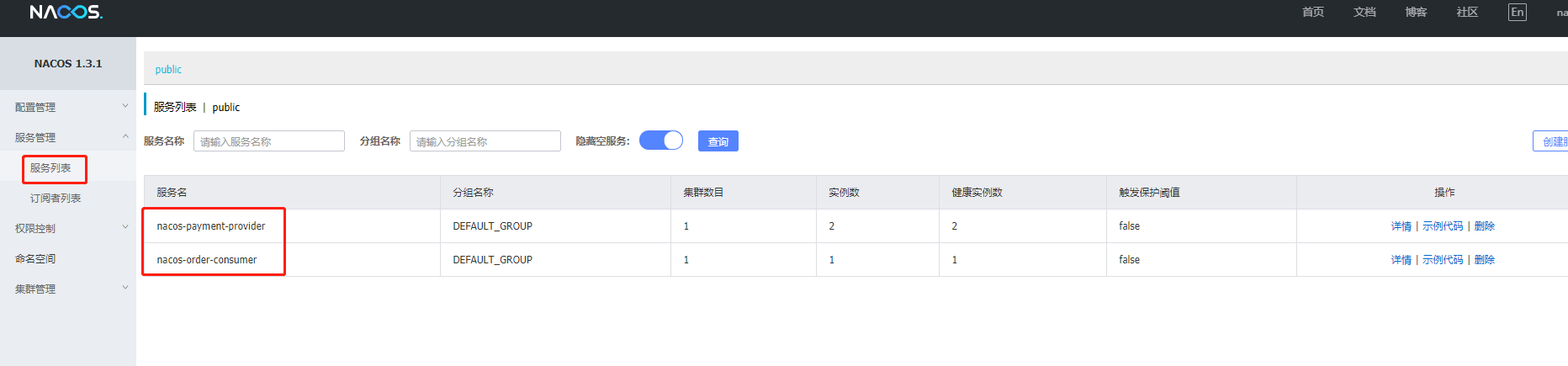
-
为什么nacos支持负载均衡:依赖中整合了ribbon
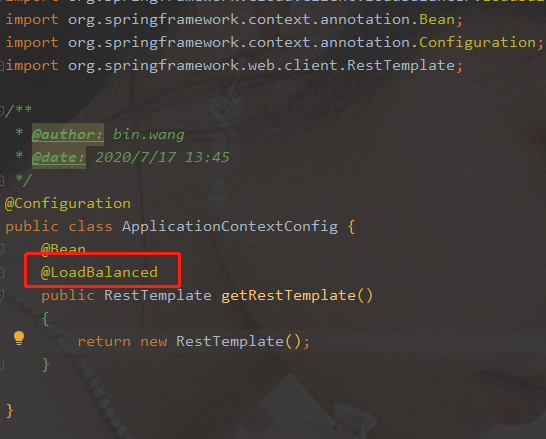
- 83访问9001/9002,轮询负载OK
各种注册中心比较
-
Nacos支持CAP中 AP和CP模式的切换
-
Nacos全景图所示

-
Nacos和CAP
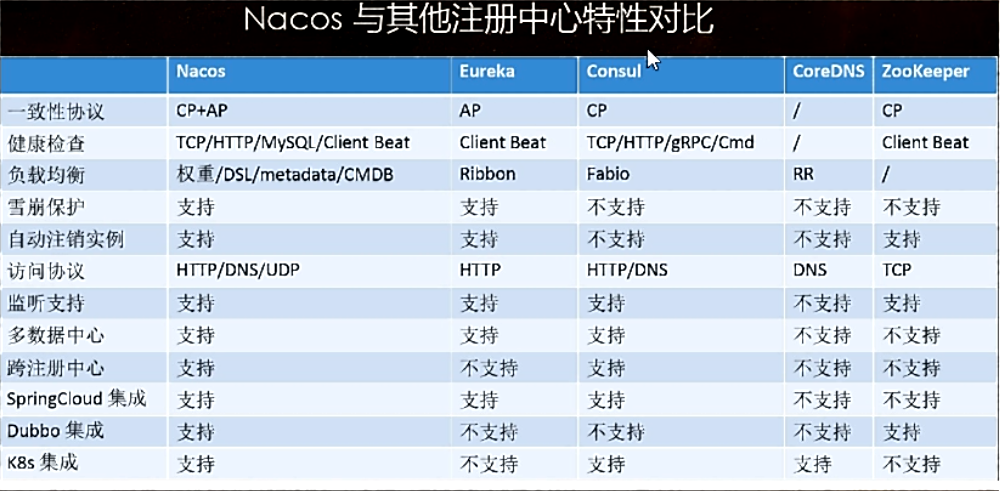
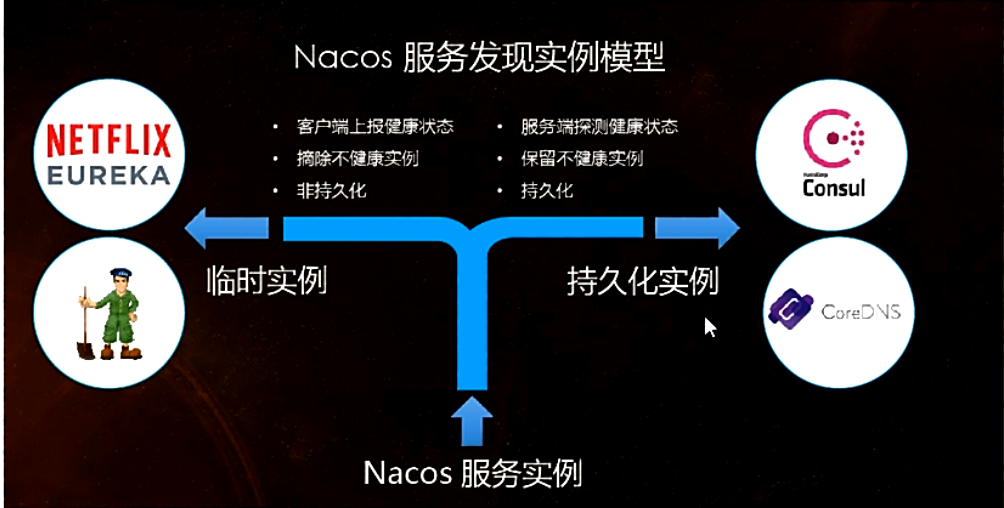
-
Nacos支持AP和CP模式的切换

Nacos作为服务配置中心演示
-
Nacos作为配置中心-基础配置
- cloudalibaba-config-nacos-client3377
- why配置两个
- application.yml
- bootstrap

- 在Nacos中添加配置信息
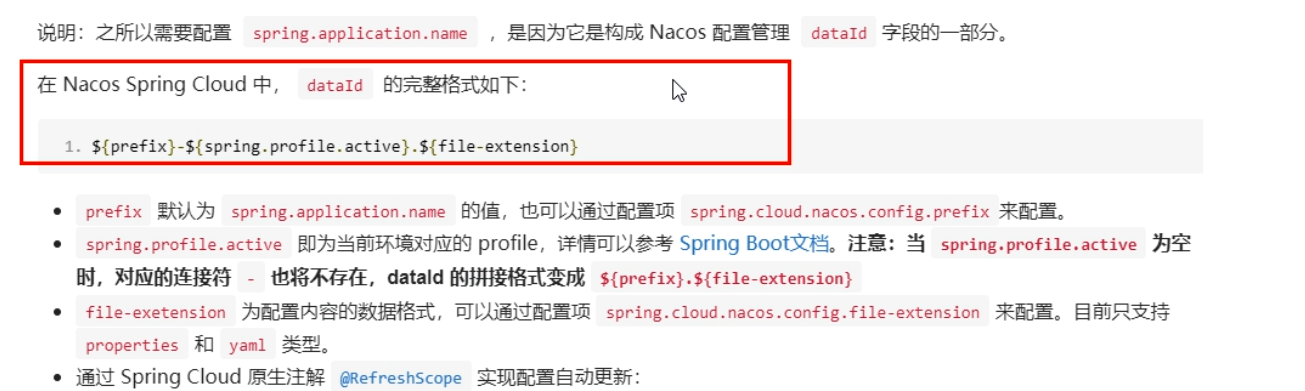
- 理论:Nacos中的dataid的组成格式与SpringBoot配置文件中的匹配规则
- 实操
- 配置新增
- Nacos界面配置对应


- 理论:Nacos中的dataid的组成格式与SpringBoot配置文件中的匹配规则

- 自带动态刷新:修改下Nacos中的yaml配置文件,再次调用查看配置的接口,就会发现配置已经刷新
-
Nacos作为配置中心-分类配置
-
问题:多环境多项目管理
-
Nacos的图形化管理界面
-
配置管理
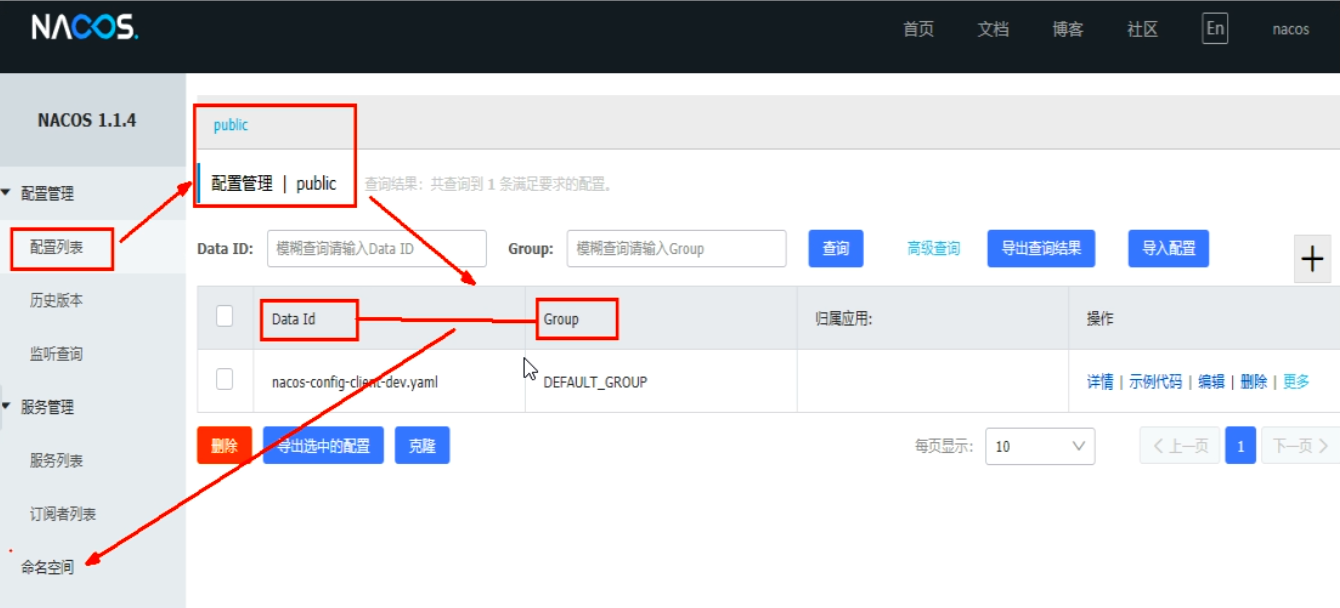
-
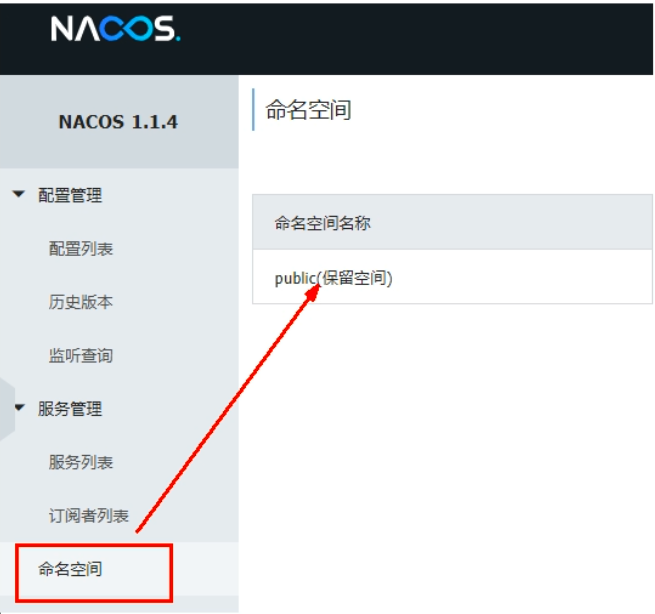
命名空间
-
-
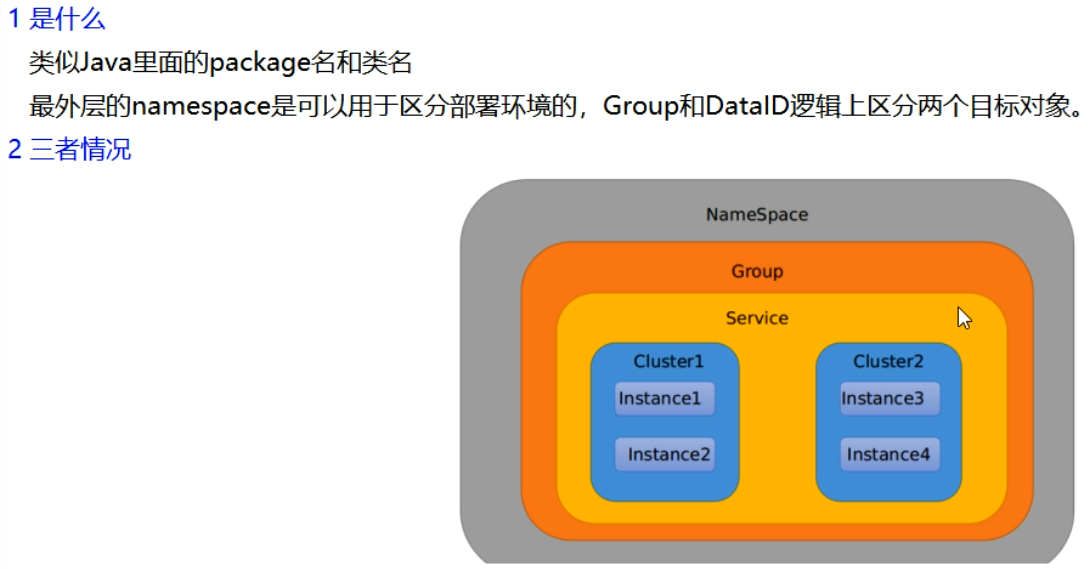
Namespace+Group+Data ID三者关系?为什么这么设计
-
Case
-
DataID方案
- 指定spring.profile.active和配置文件的DataID来使不同环境下读取不同的配置
- 默认空间+默认分组+新建dev和test两个DataID
- 新建dev配置DataID
- 新建test配置DataID
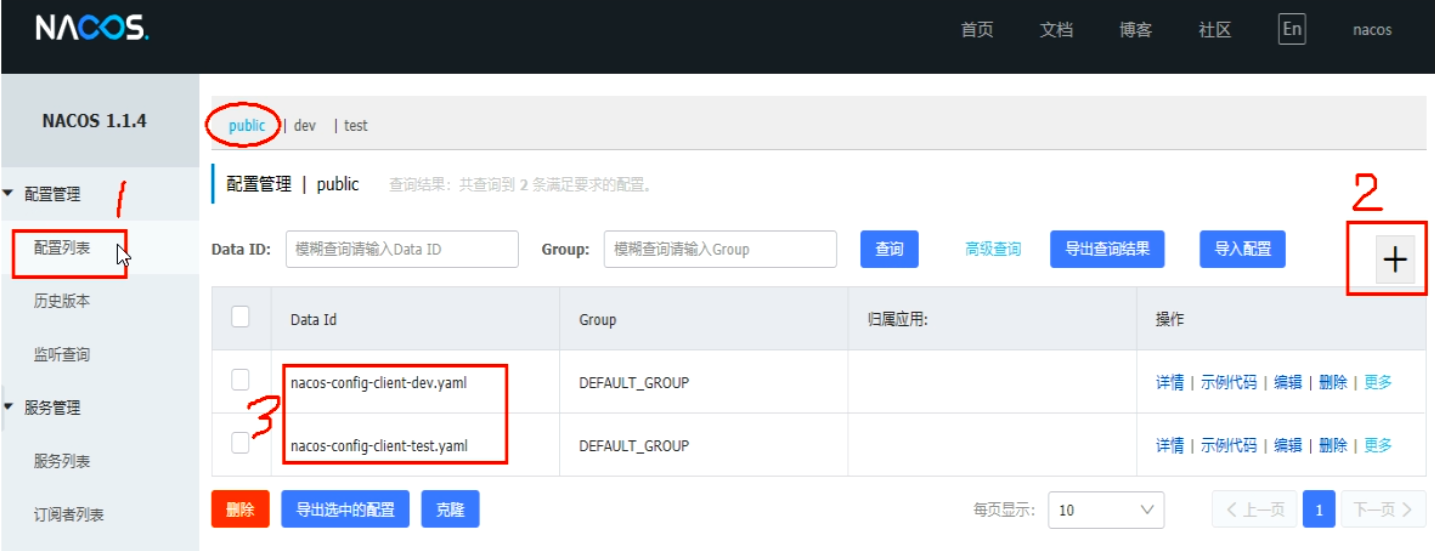
- 通过spring.profile.active属性就能进行多环境下配置文件的读取
-
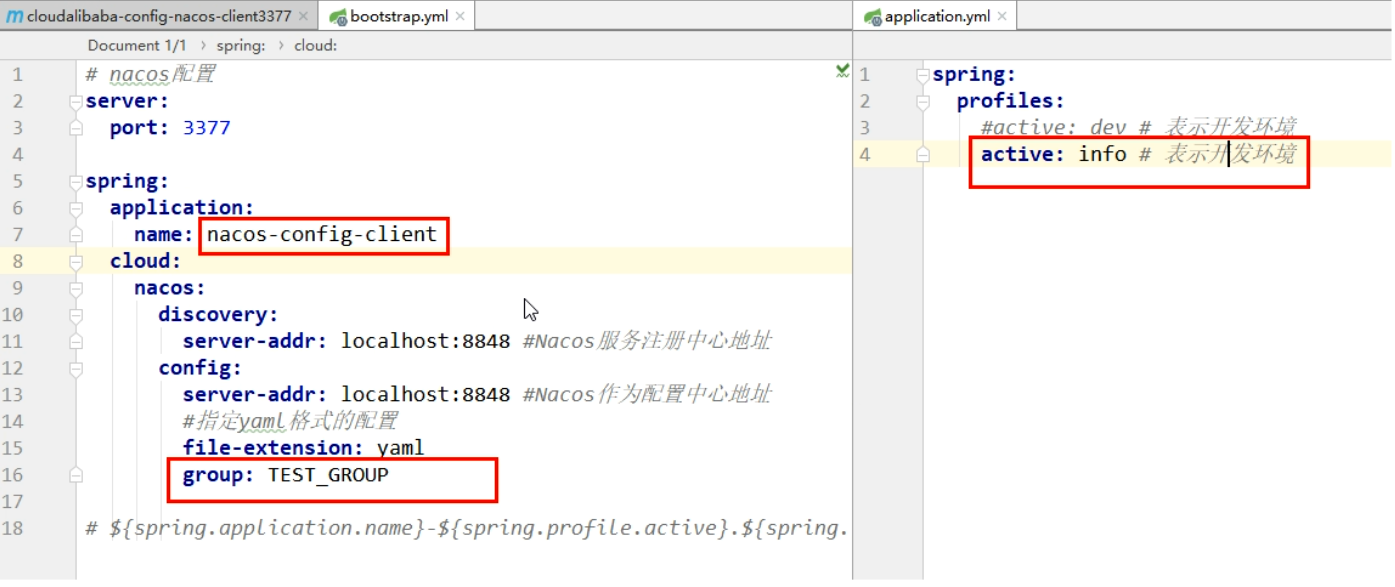
Group方案
-
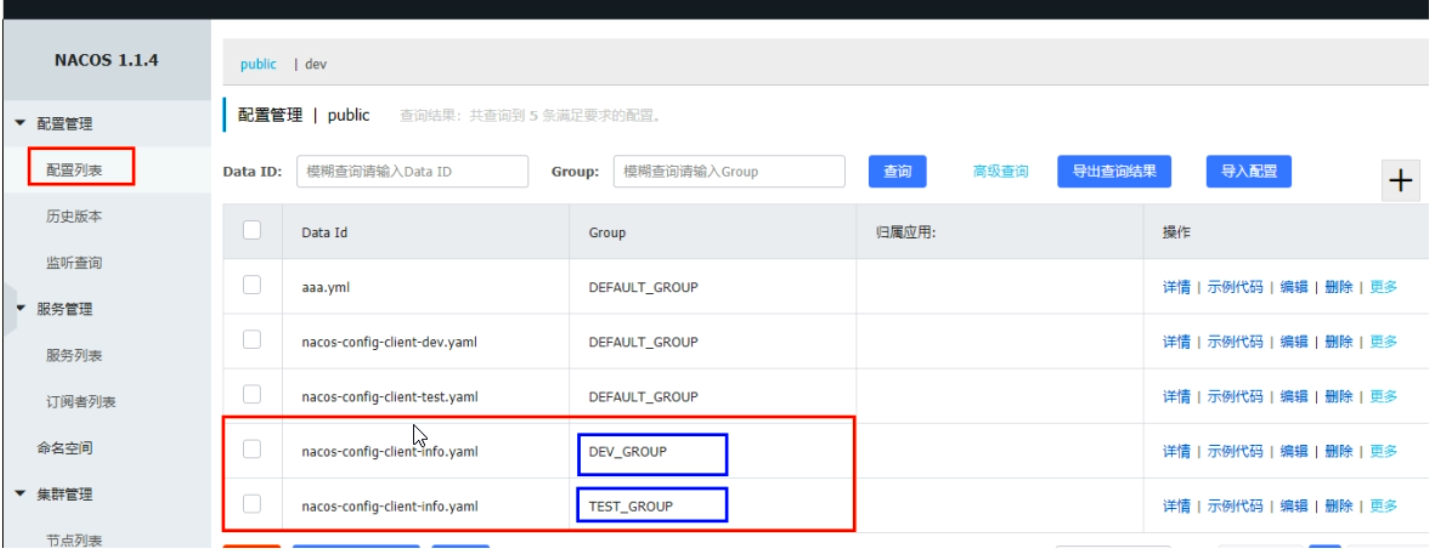
-
在config下增加一条group的配置即可。可配置为DEV_GROUP或TEST_GROUP
-
-
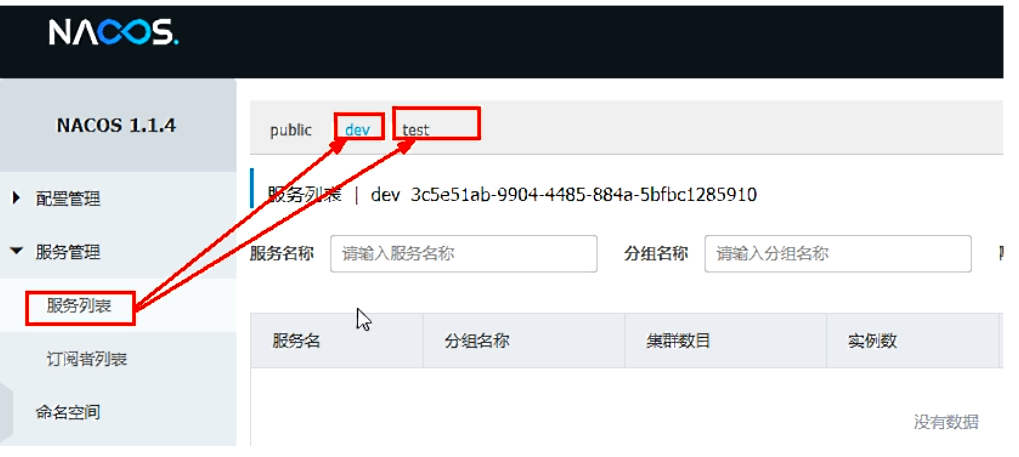
Namespace方案
- 新建dev/test的Namespace
- 回到服务管理-服务列表查看
- 按照域名配置填写
-
-


Nacos集群和持久化配置(**)
官方说明
-
官网:https://nacos.io/zh-cn/docs/cluster-mode-quick-start.html
-
官网架构图
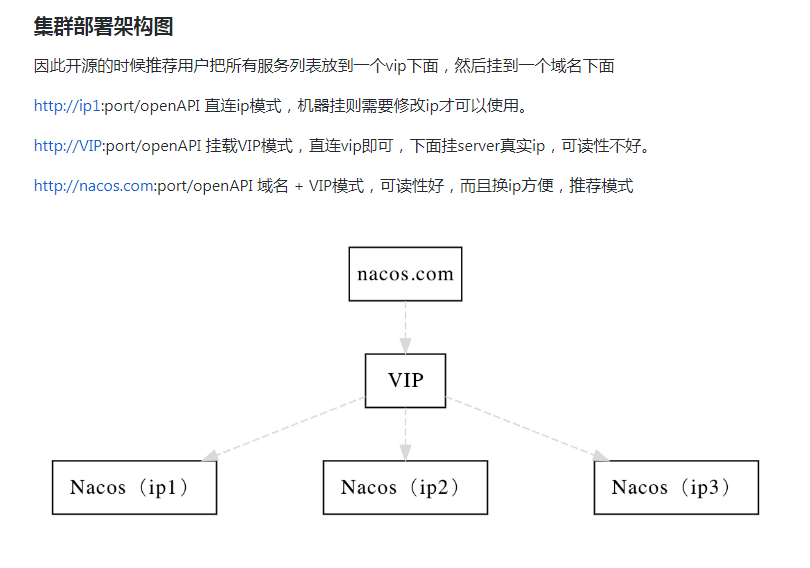
-
官网架构翻译,真是情况
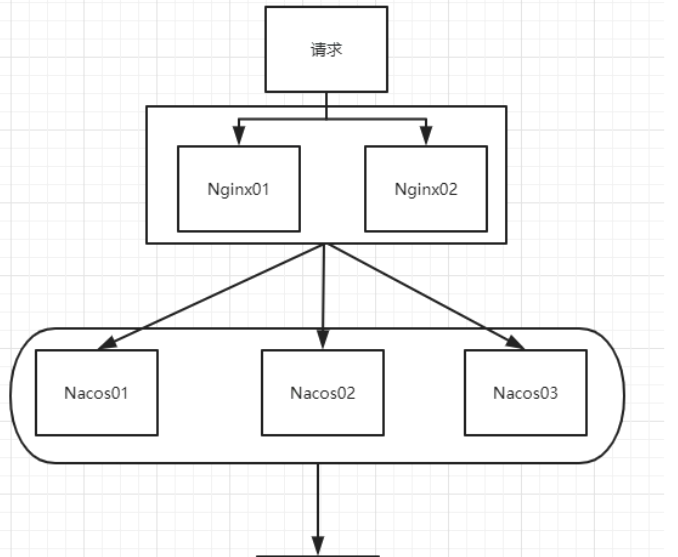
- 说明
- 需配置mysql数据,https://nacos.io/zh-cn/docs/deployment.html
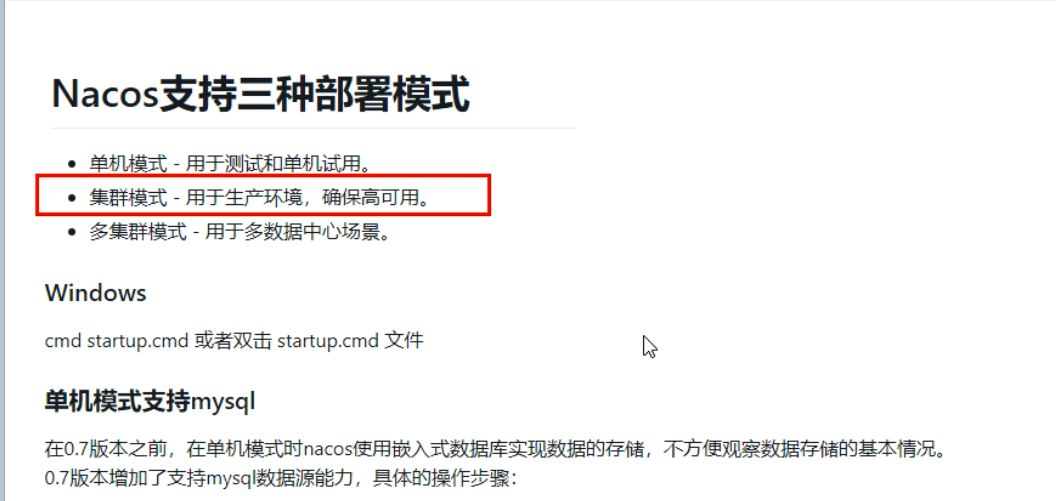
- 说明
Nacos持久化配置解释
-
Nacos默认自带的是嵌入式数据库derby,https://github.com/alibaba/nacos/blob/develop/config/pom.xml
-
derby到MySQL切换配置步骤
-
nacos-server-1.1.4\nacos\conf目录下找到sql脚本,执行脚本nacos-mysql.sql
-
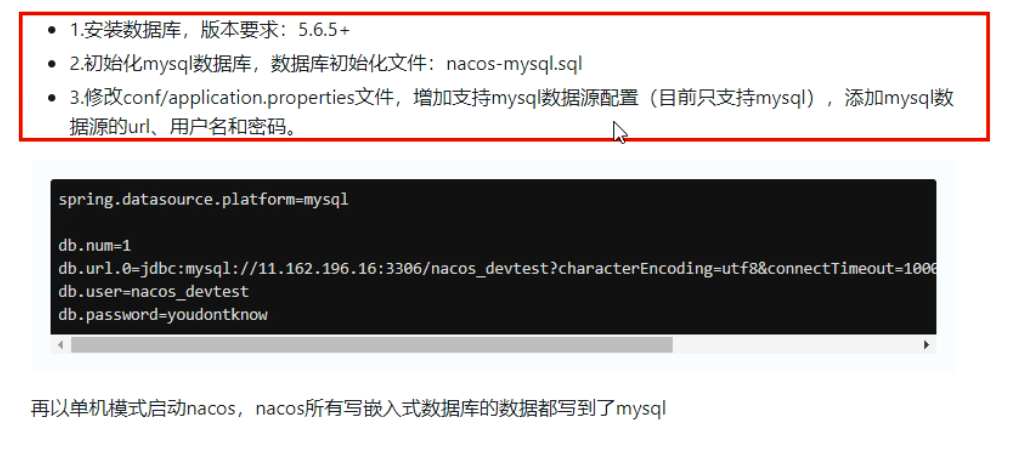
nacos-server-1.1.4\nacos\conf目录下找到application.properties
# db mysql spring.datasource.platform=mysql db.num=1 db.url.0=jdbc:mysql://127.0.0.1:3306/nacosconfig?serverTimezone=UTC&characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true db.user=root db.password=123456 -
启动nacos,可以看到是个全新的空记录界面,以前是记录进derby
-
Linux版Nacos+MySQL生产环境配置
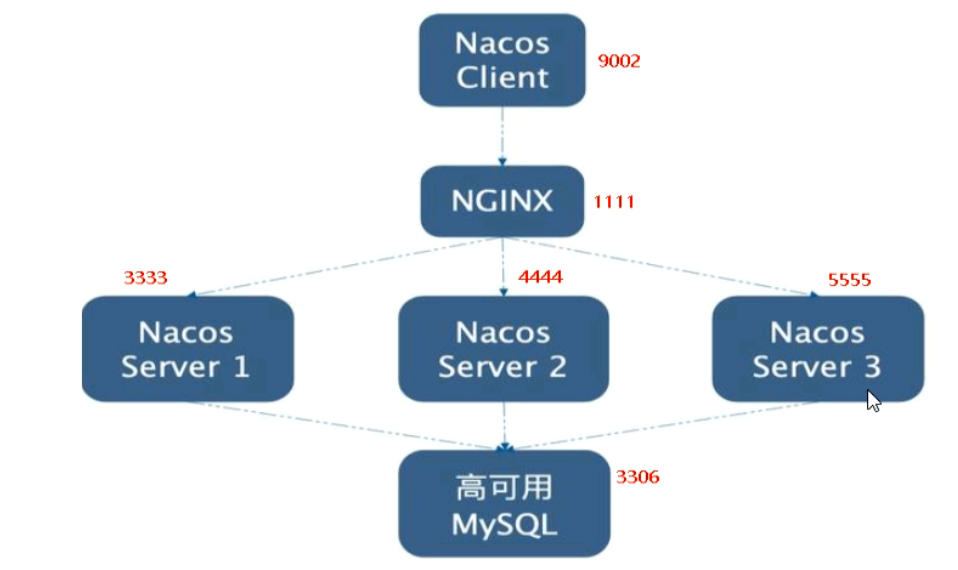
-
预计1个nginx+3个nacos注册中心+1个mysql
-
集群配置步骤(**)
-
测试
- 微服务cloudalibaba-provider-payment9002启动注册进nacos集群
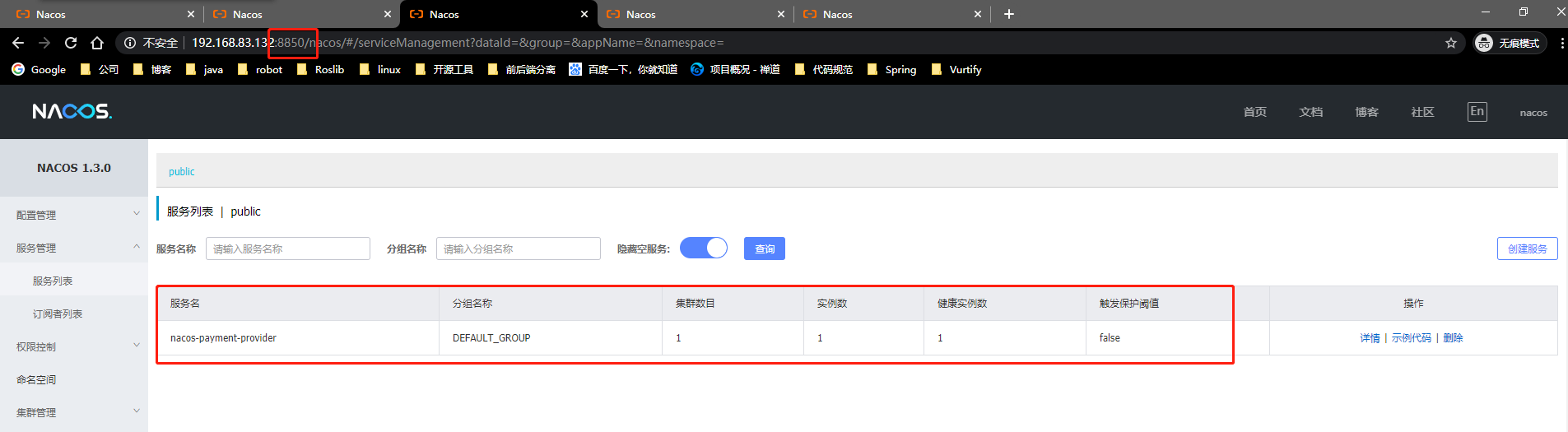
-
高可用小总结
SpringCloud Alibaba Sentinel实现熔断与限流
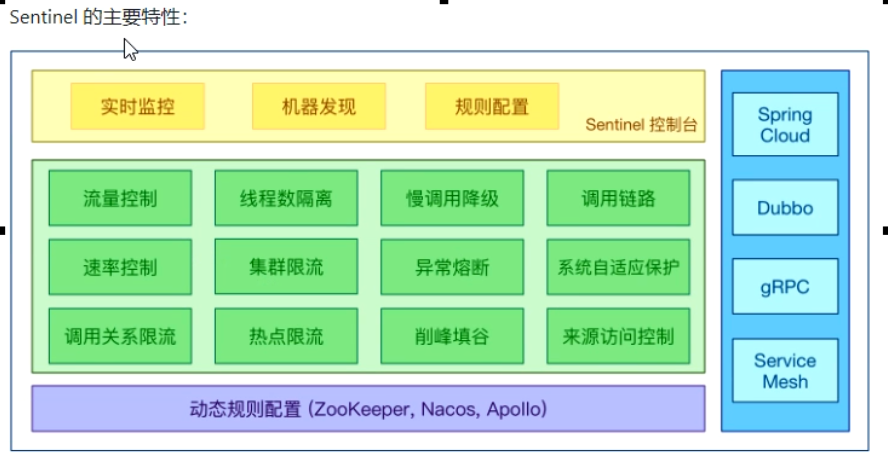
Sentinel简介
-
是什么
- Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等
- 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况
- 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel
- 完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等
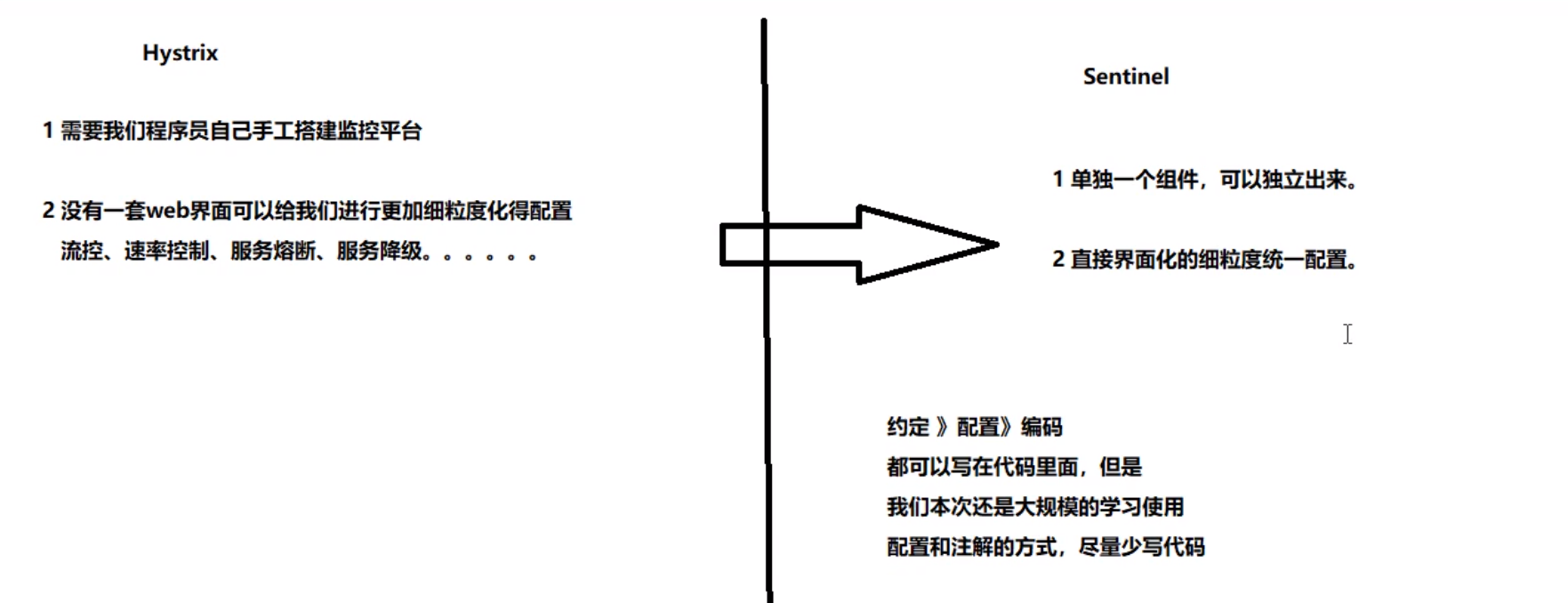
- Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性
-
能干嘛
-
怎么玩
- 服务使用中的各种问题
- 服务雪崩
- 服务降级
- 服务熔断
- 服务限流
- 服务使用中的各种问题
安装Sentinel控制台
- Sentinel组件由两部分构成
- 安装步骤
- 官网下载,sentinel-dashboard-x.x.jar
- 运行命令: java -jar sentinel-dashboard-x.x.jar
- 访问sentinel管理界面
- http://localhost:8080
- 登录账号密码均为sentinel

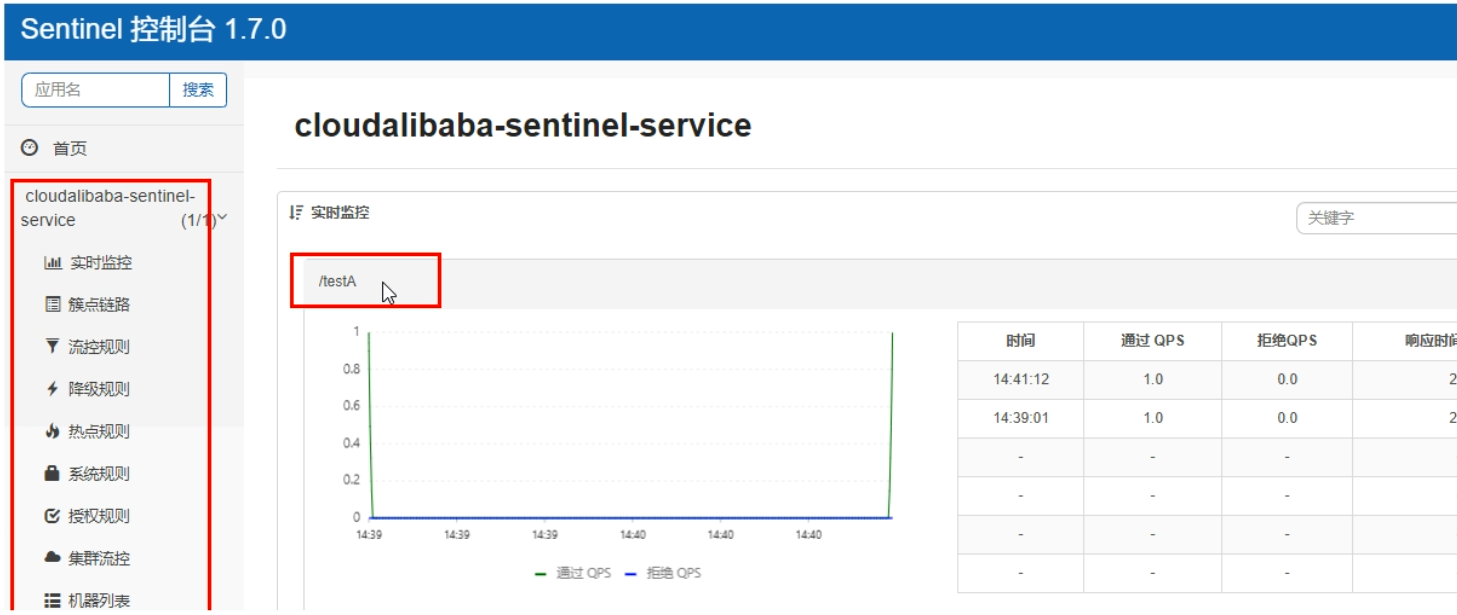
初始化演示工程
- cloudalibaba-sentinel-service8401
- 启动Nacos8848成功
- 启动Sentinel8080
- 启动8401微服务后查看sentienl控制台
- 第一次访问,空白页
- Sentinel采用的懒加载说明,执行一次访问即可
- 效果图:
流控规则
-
基本介绍
-
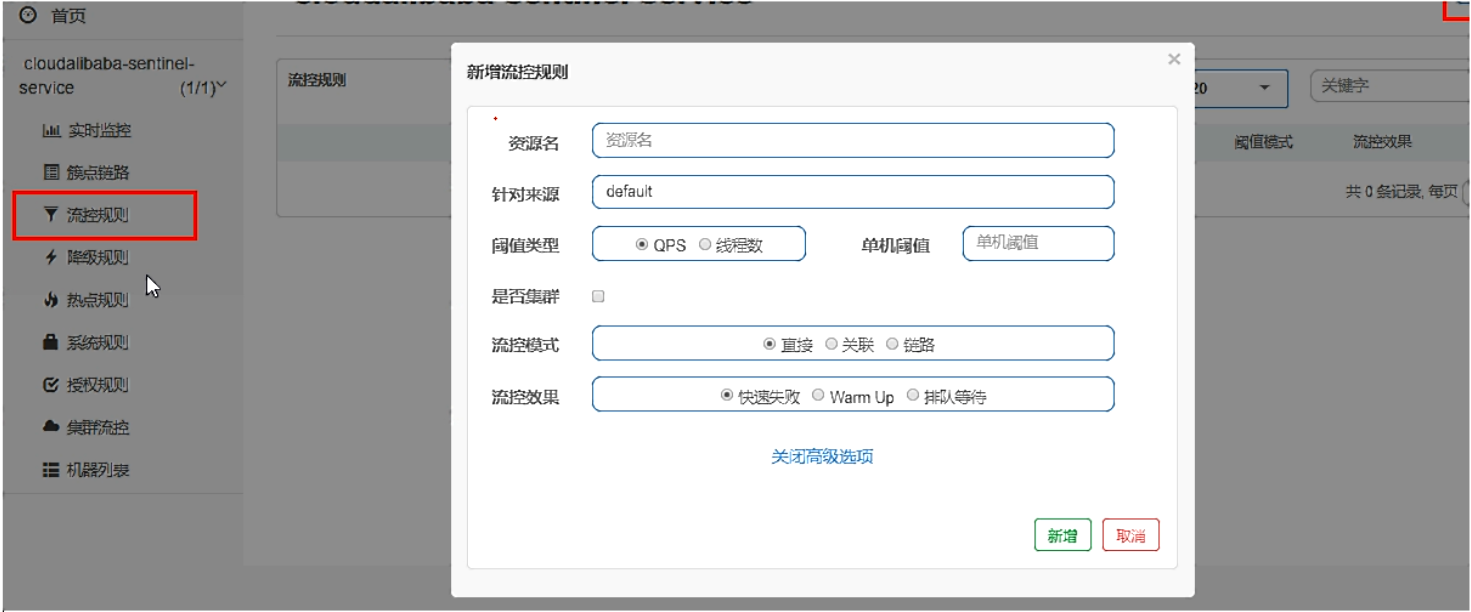
-
进一步介绍
-
-
-
流控模式
-
直接(默认)
-
系统默认,直接->快速失败
-
配置及说明
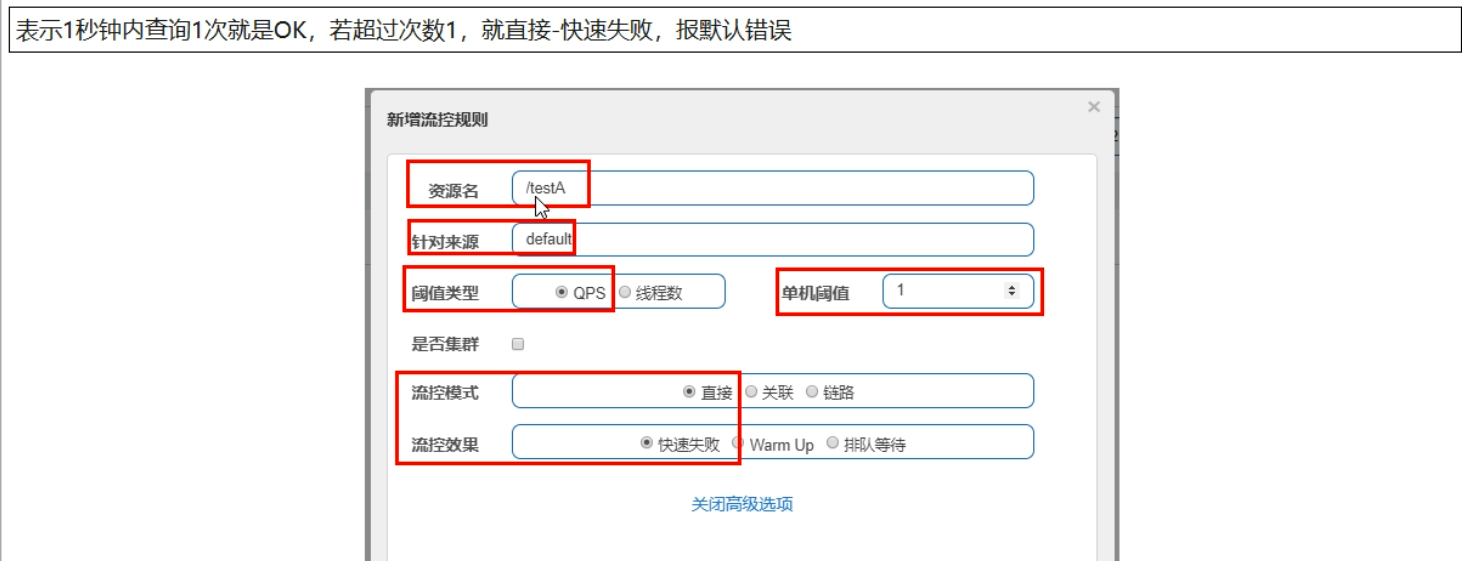
-
测试
- 快速点击访问http://localhost:8401/testA
- 结果;Blocked by Sentinel (flow limiting)
- 思考:是否应该加一个类似fallback的兜底方法?
-
-
关联
-
是什么
- 当关联的资源达到阈值时,就限流自己
- 当与A关联的资源B达到阈值后,就限流自己
- B惹事,A挂了
- 应用场景: 比如支付接口达到阈值,就要限流下订单的接口,防止一直有订单
-
postman模拟并发密集访问testB
-
配置规则
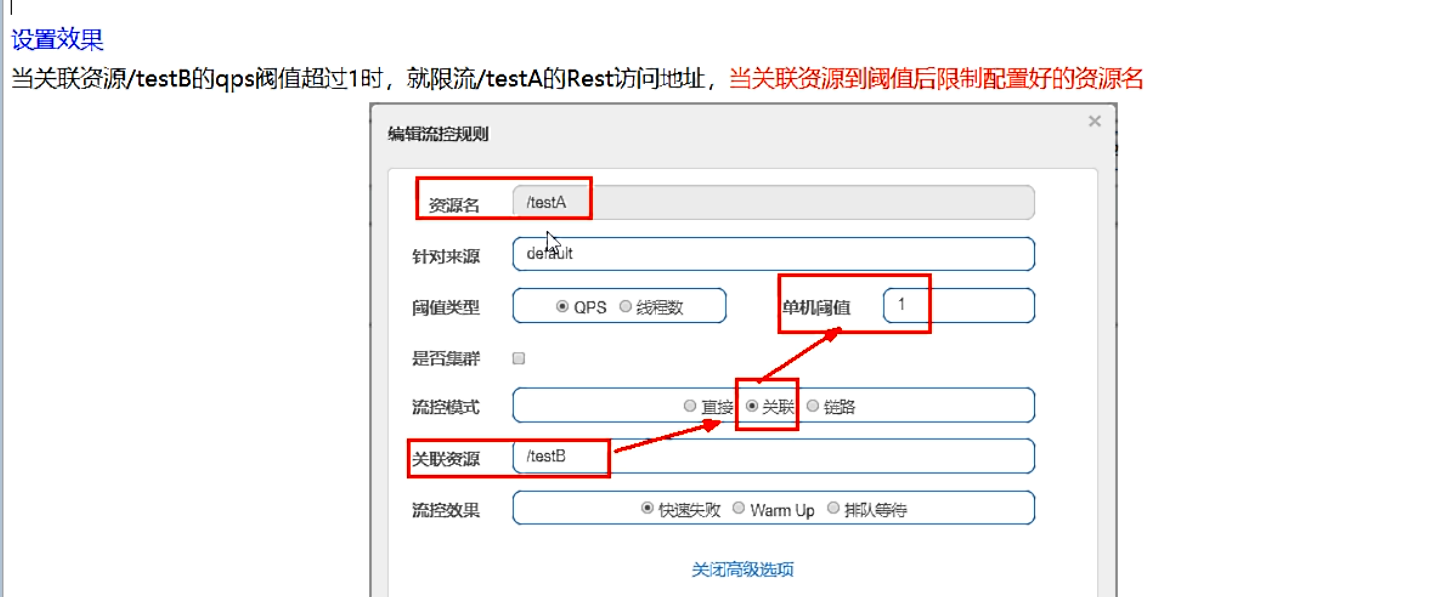
-
postman里新建多线程集合组
-
将访问地址添加进新线程组 -- save as 选择对应的collection
-
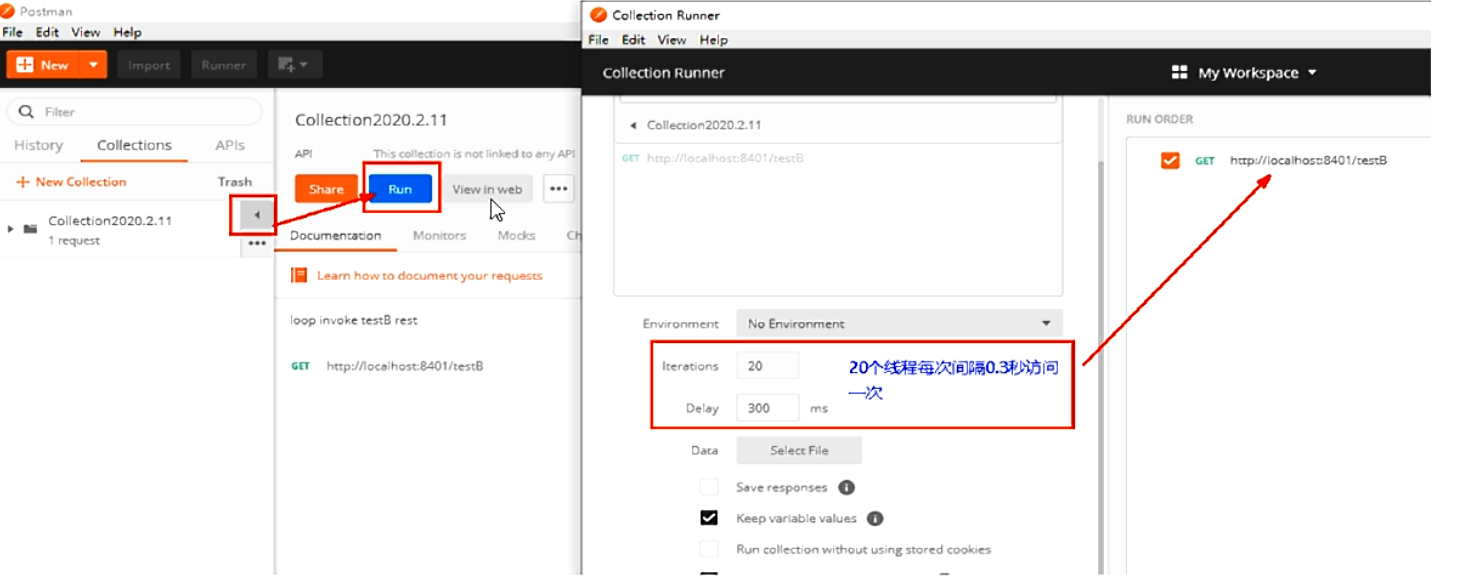
-
大批量线程高并发访问B,导致A失效了
-
-
-
链路
- 链路流控模式指的是,当从某个接口过来的资源达到限流条件时,开启限流;它的功能有点类似于针对 来源配置项,区别在于:针对来源是针对上级微服务,而链路流控是针对上级接口,也就是说它的粒度 更细
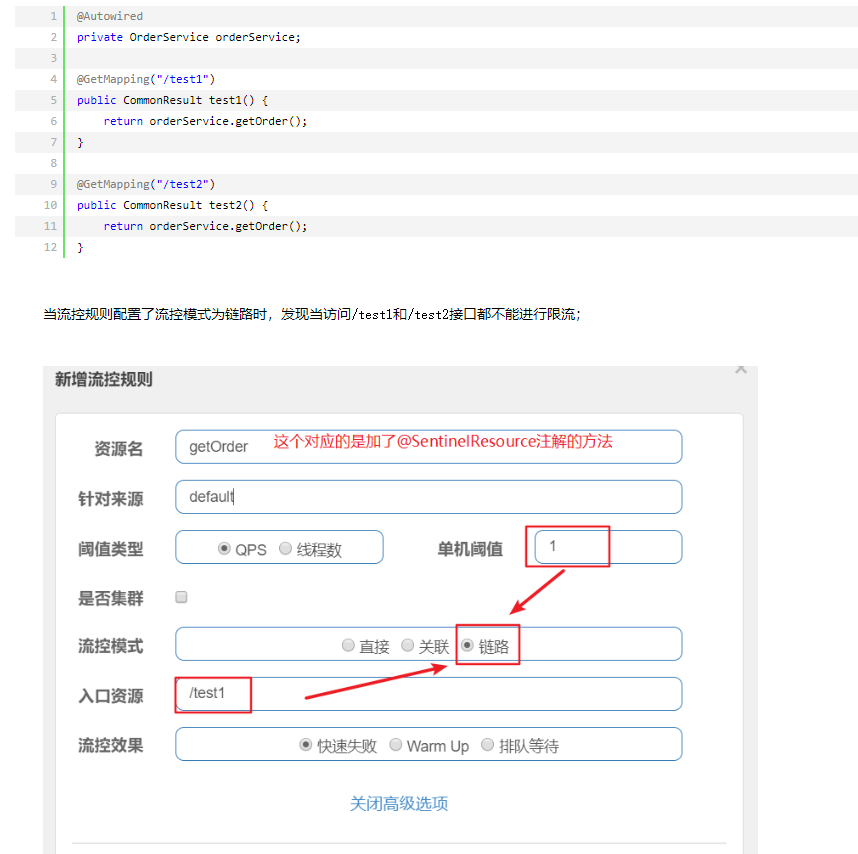
-
-
流控效果
-
直接--->快速失败(默认的流控处理),直接失败,抛出异常
-
预热
-
说明:公式:阈值除以coldFactor(默认值为3),经过预热时长后才会达到阈值
-
官网:

-
默认coldFactor为3,即请求QPS从threshold(阈值)/3开始,经预热时长逐渐升至设定的QPS阈值。
-
源码

-
配置
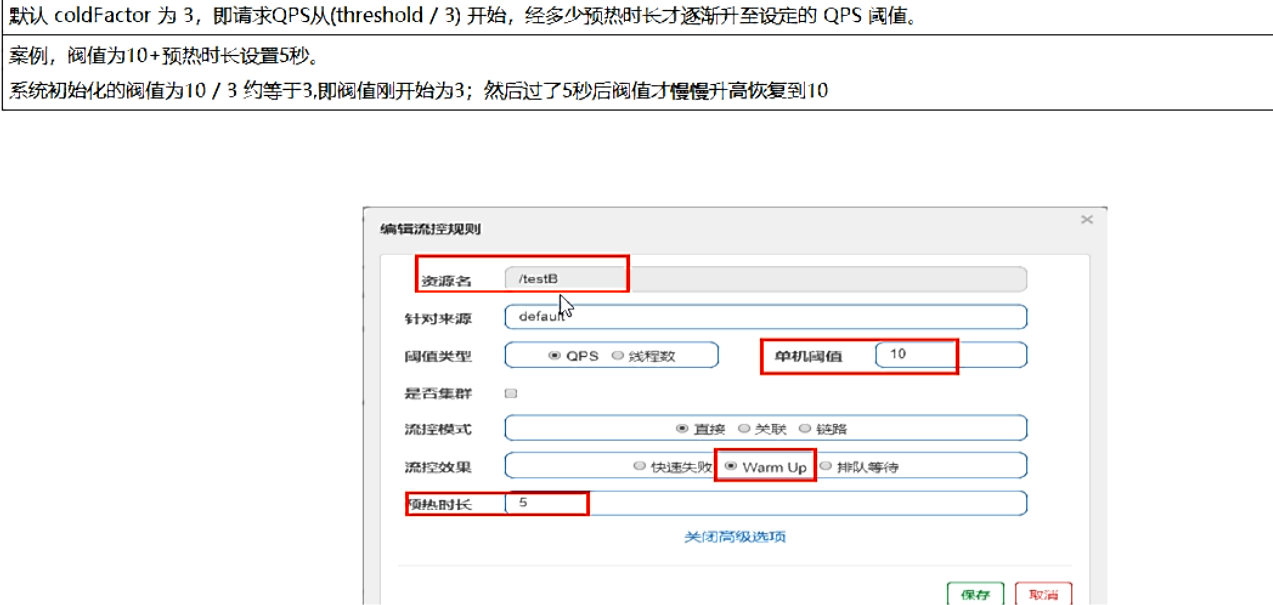
-
测试:多次点击http://localhost:8401/testB 结果:刚开始不行,后续慢慢OK
-
应用场景

-
-
排队等待
-
匀速排队,阈值必须设置为QPS
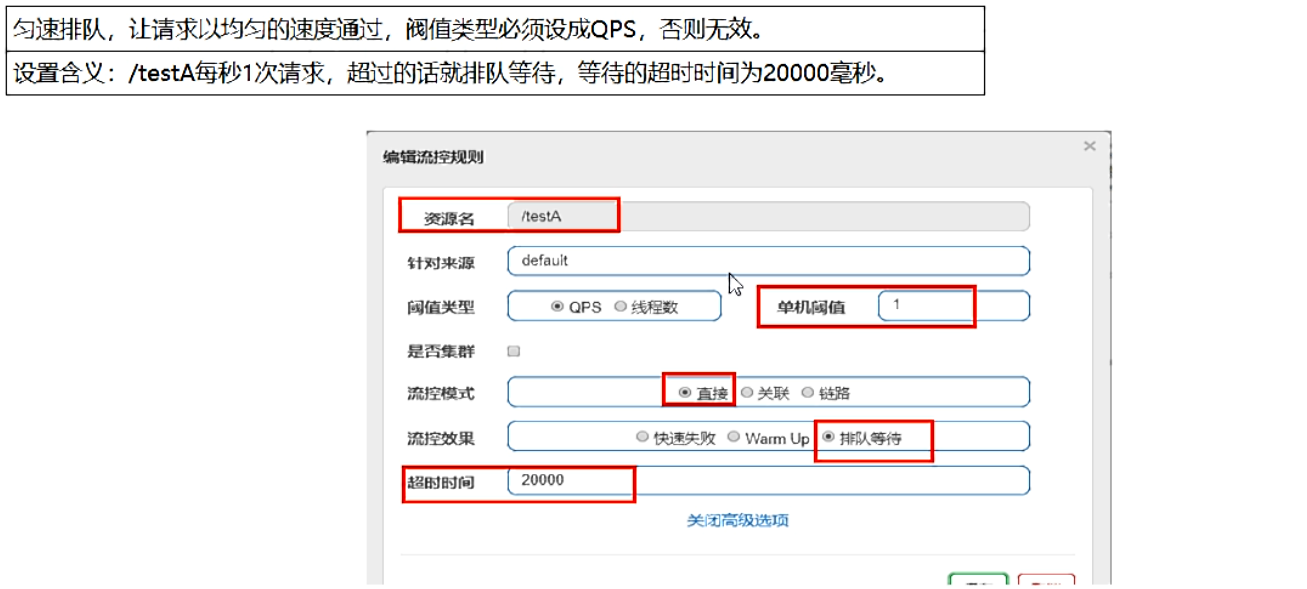
-
官网


-
-


降级规则
-
官网(https://github.com/alibaba/Sentinel/wiki/%E7%86%94%E6%96%AD%E9%99%8D%E7%BA%A7)

-
基本介绍
-
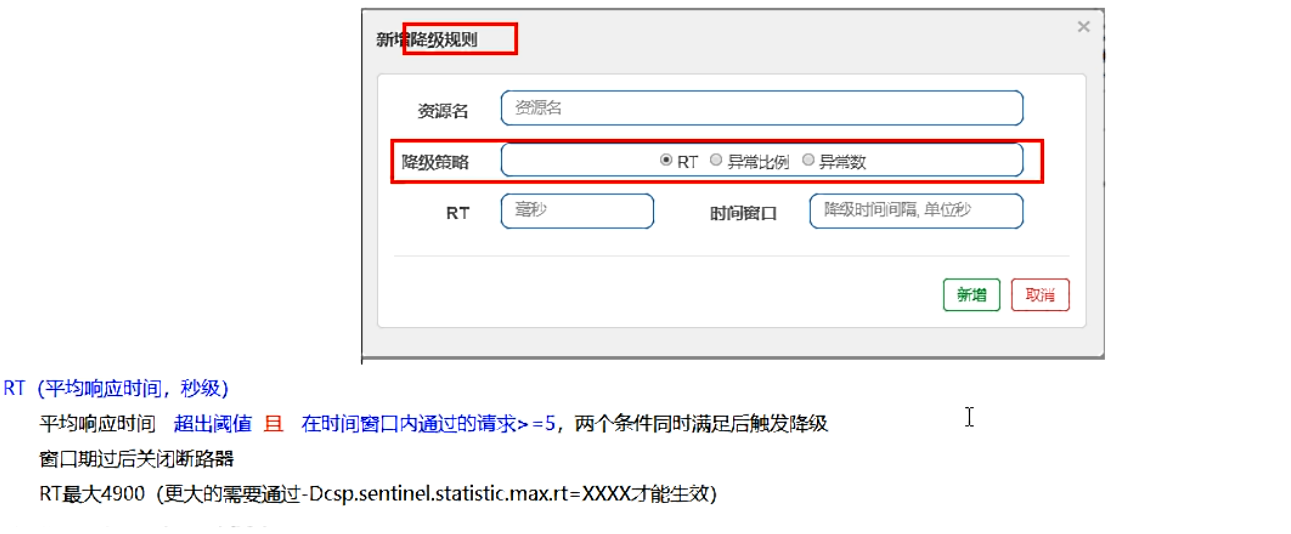

-
进一步说明

-
Sentinel的断路器是没有半开状态的
- 半开的状态系统自动去检测是否请求有异常,没有异常就关闭断路器恢复使用,有异常则继续打开断路器不可用。具体可以参考Hystrix
- hystrix
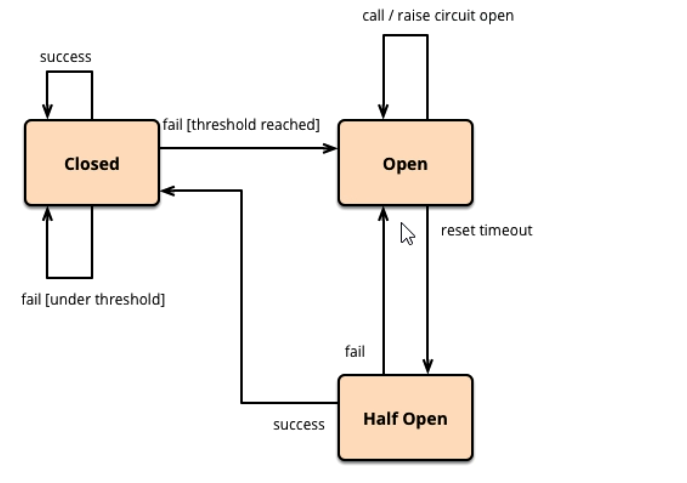
-
-
降级策略实战
-
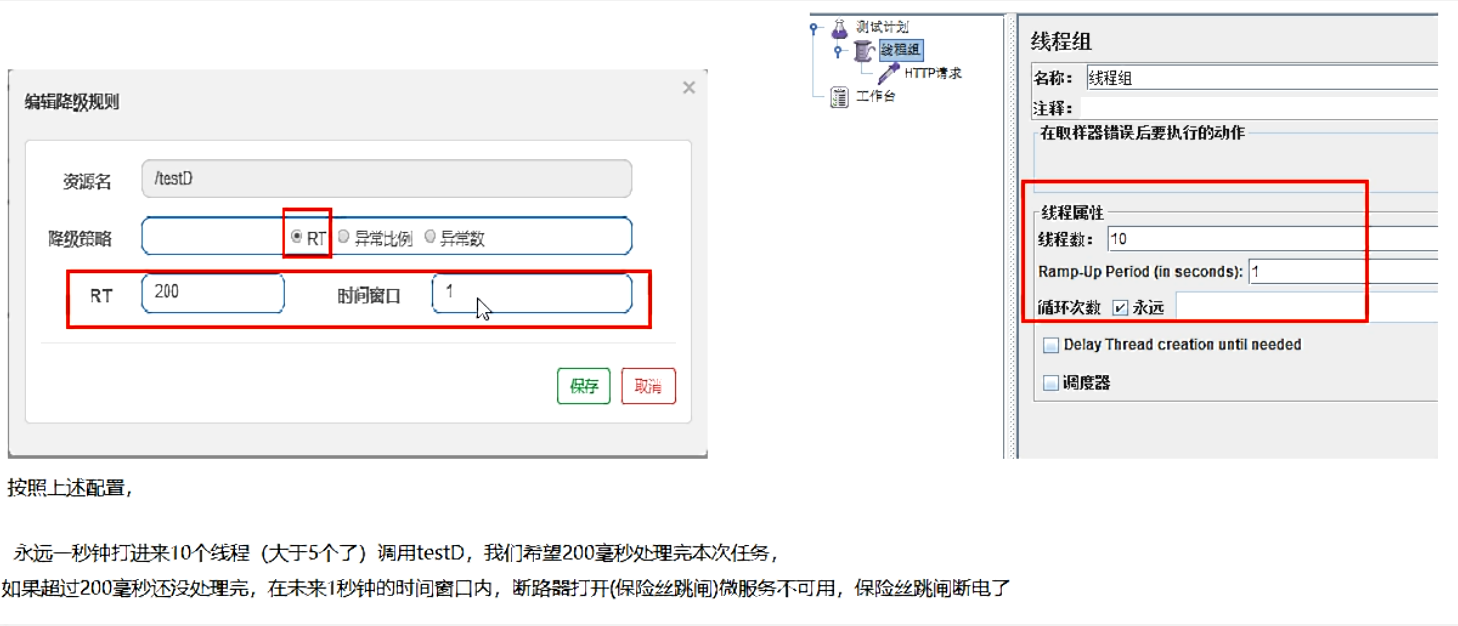
RT:平均响应时间
- 是什么

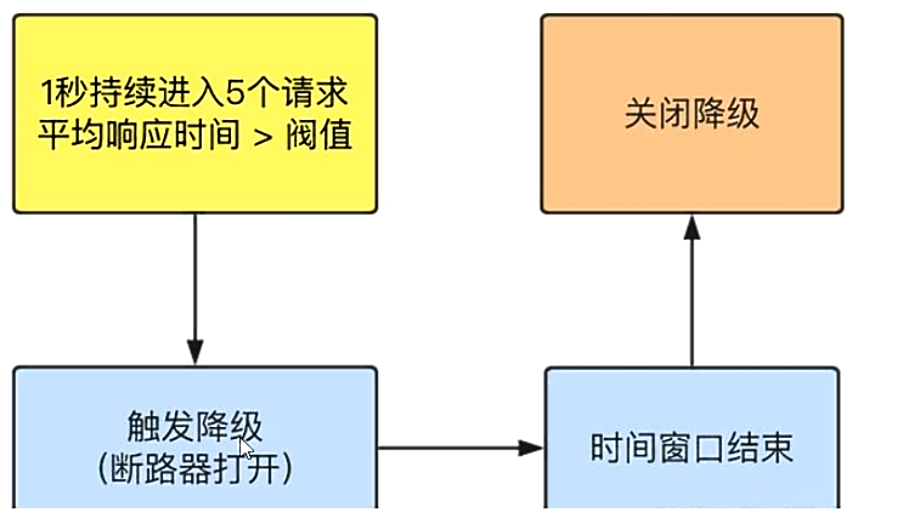
- jmeter压测--->1秒钟打入10个请求
- 结论
- 是什么
-
异常比例
-
是什么

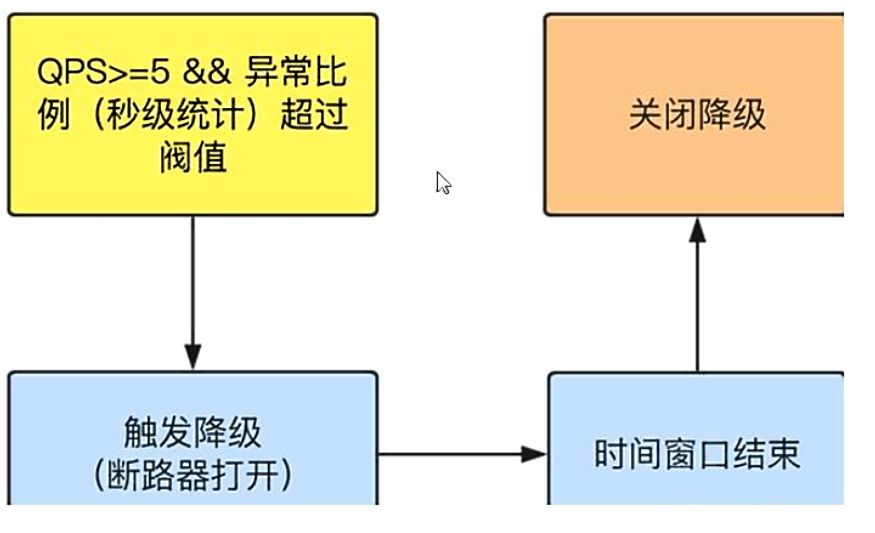
-
配置
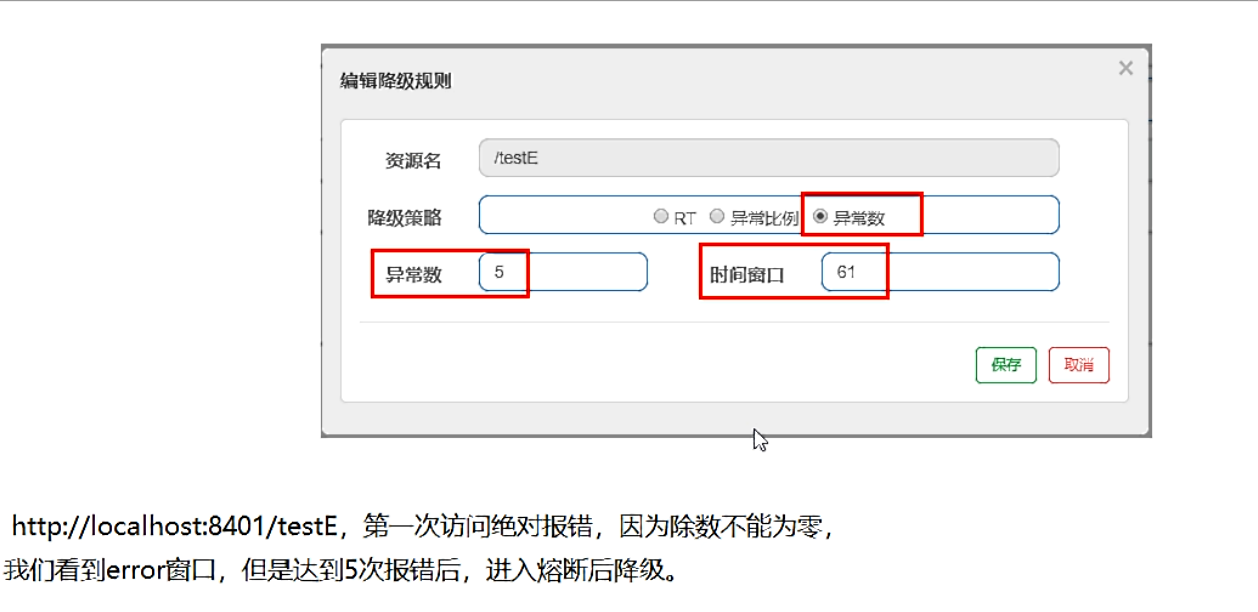
-
jmeter压测,结论

-
-
异常数
-
是什么

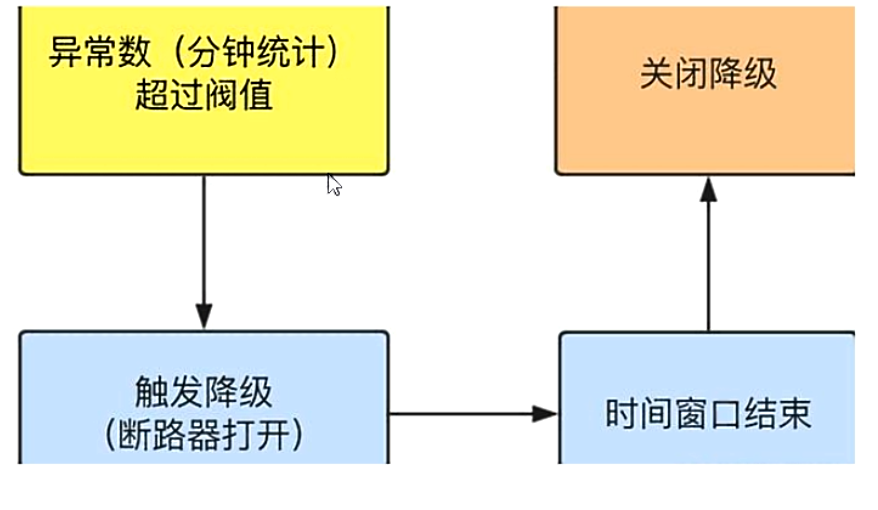
-
异常数是按照分钟统计的
-
配置+测试
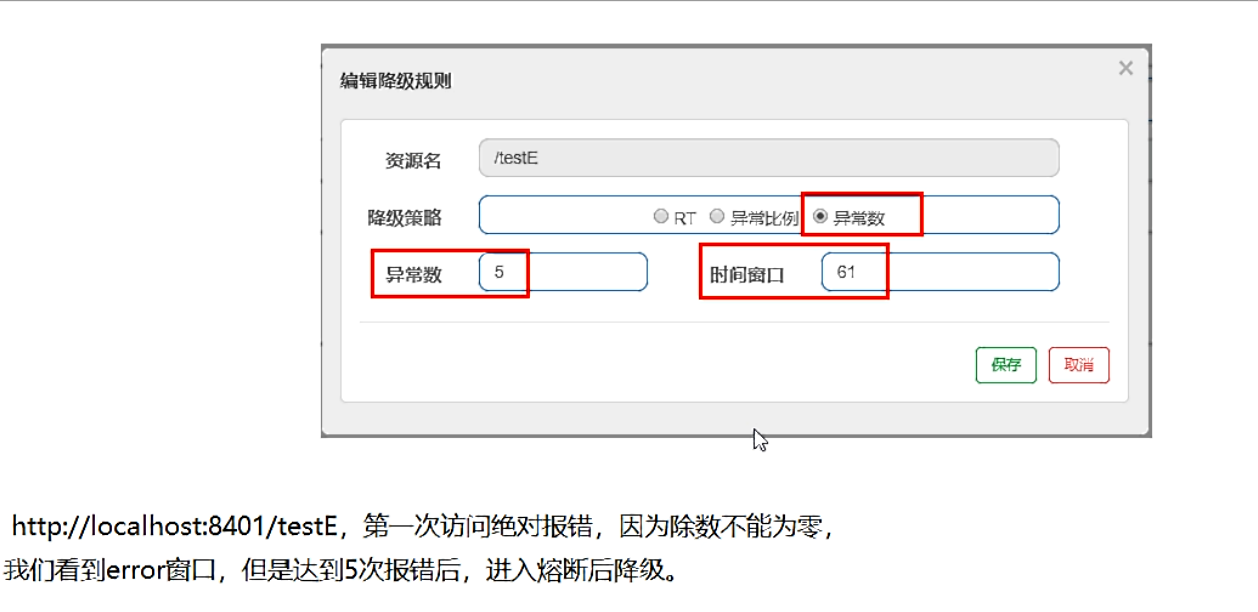
-
-
热点key限流(**)
-
基本介绍
-
官网:https://github.com/alibaba/Sentinel/wiki/热点参数限流
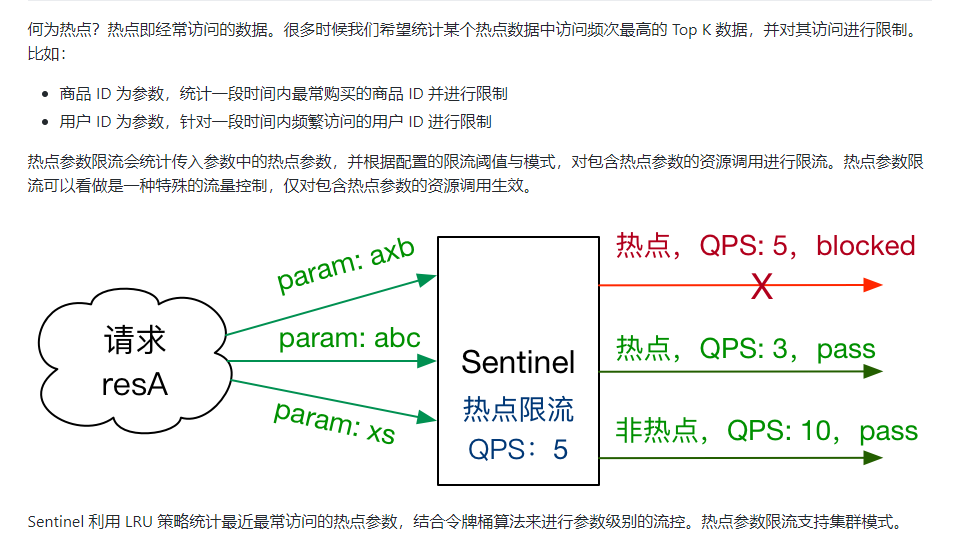
-
承上启下复习start

-
@SentinelResource等同于@HystrixCommand
-
源码:
com.alibaba.csp.sentinel.slots.block.BlockException -
配置
- @SentinelResource(value = "testHotKey",blockHandler = "deal_testHotKey")
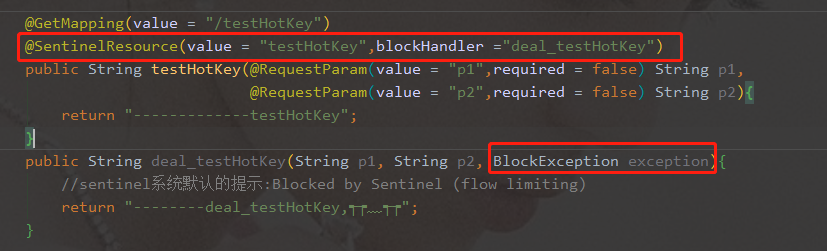
- 不添加blockHandler方法,会把异常打到前台页面,提示不友好
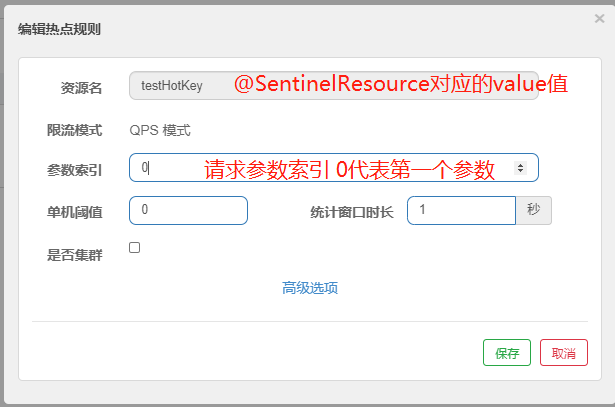
- 方法testHostKey里面第一个参数只要QPS超过每秒1次,马上降级处理,并且用了我们自己定义的降级提示
-
参数例外项
-
上述案例演示了第一个参数p1,当QPS超过1秒1次点击后马上被限流
-
特殊情况:
-
普通:超过1秒钟一个后,达到阈值1后马上被限流
-
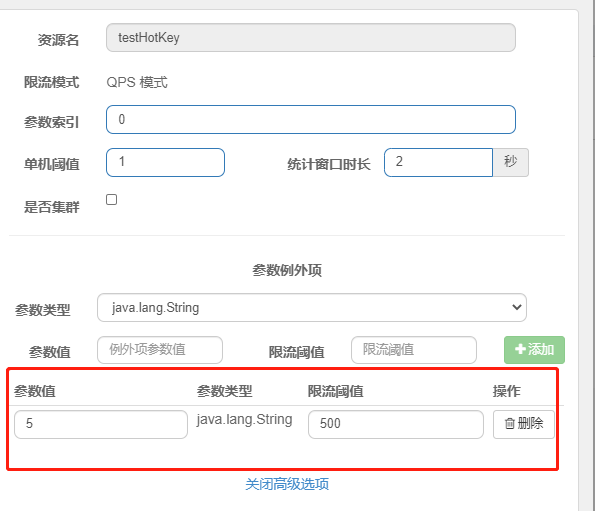
特例:我们期望p1参数当它是某个特殊值时,它的限流值和平时不一样.
例如当p1的值等于5时,它的阈值可以达到200
-
-
配置
-
-
测试结果:
- 当p1等于5的时候,阈值变为200
- 当p1不等于5的时候,阈值就是平常的1
-
前提:热点参数的注意点,参数必须是基本类型或者String
-
其他:存在异常

系统规则
- 是什么:https://github.com/alibaba/Sentinel/wiki/系统自适应限流
- 各项配置参数说明

- 配置全局QPS

@SentinelResource
-
按资源名称限流+后续处理
-
启动Nacos成功
-
启动Sentinel成功
-
修改cloudalibaba-sentinel-service8401
-
业务类RateLimitController
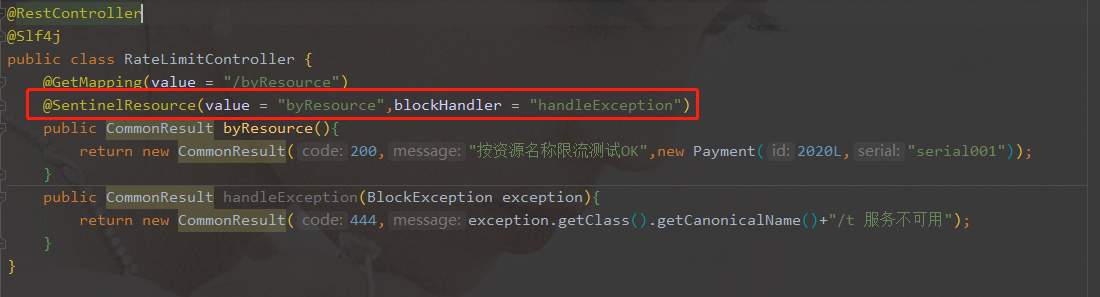
-
配置
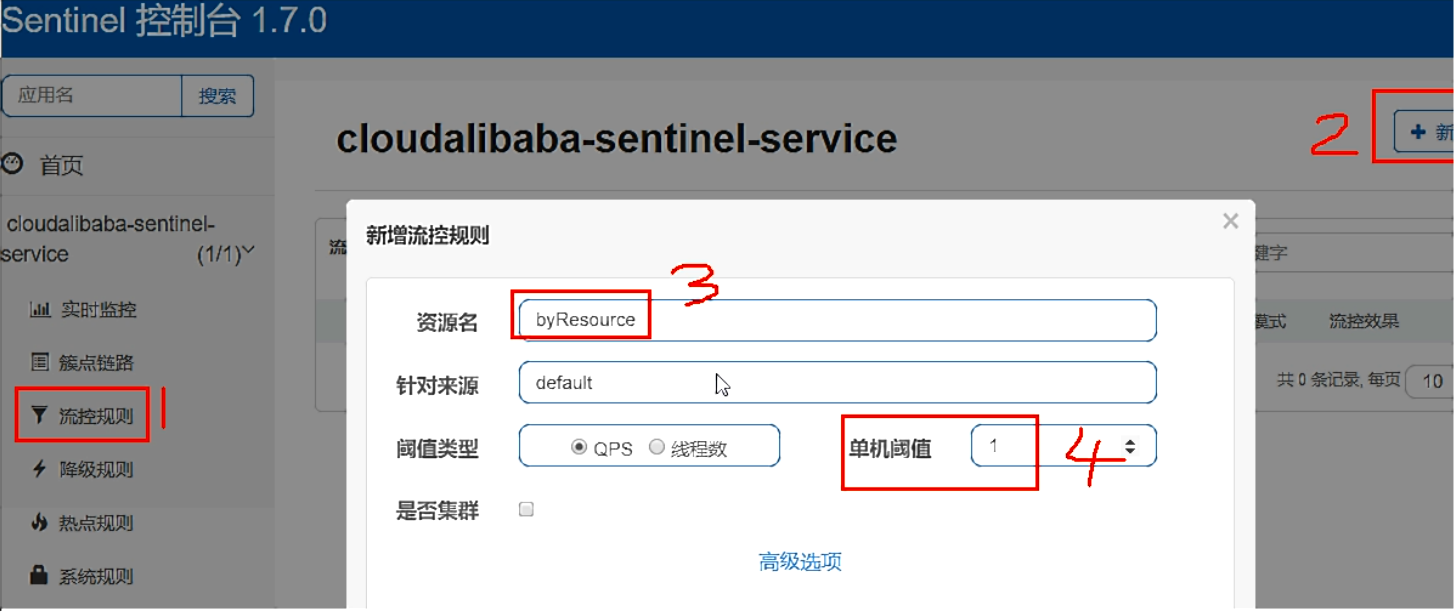
表示1秒钟内查询次数大于1,就跑到我们自定义的处流,限流
-
测试结果:1秒钟点击1下,OK
超过上述问题,疯狂点击,返回了自己定义的限流处理信息,限流发送--->进入blockHandler配置的方法
-
额外问题:此时关闭微服务8401看看,Sentinel控制台,流控规则消失了,临时/持久?
-
-
按照URL地址限流+后续处理
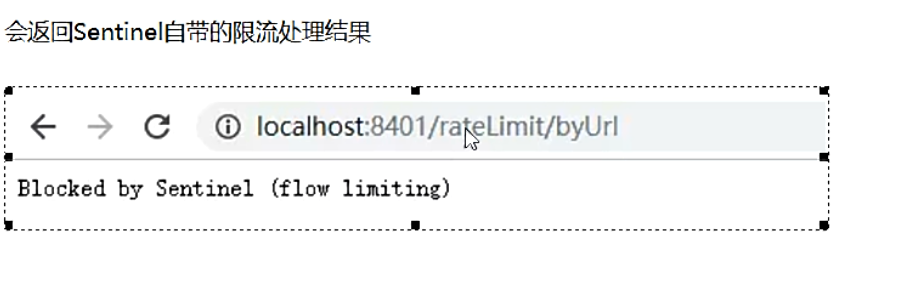
- 通过访问的URL来限流,会返回Sentinel自带默认的限流处理信息
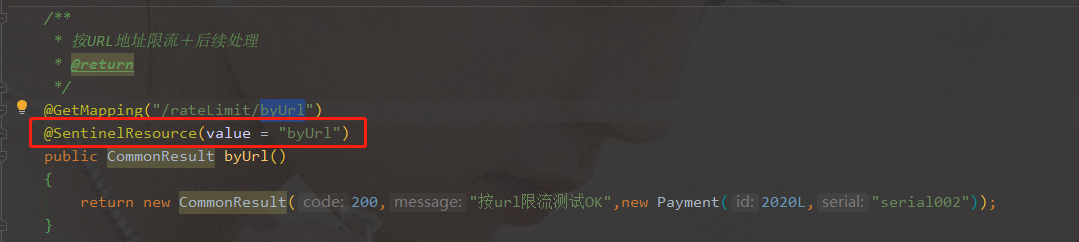
- 业务类RateLimitController
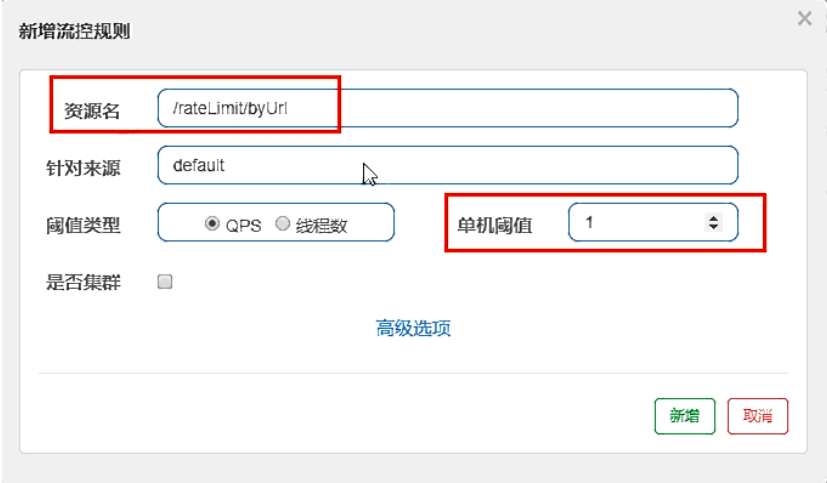
- 配置
- 测试结果
-
上面兜底方案面临的问题

-
客户自定义限流处理逻辑
- 创建customerBlockHandler类用于自定义限流处理逻辑
- 自定义限流处理类
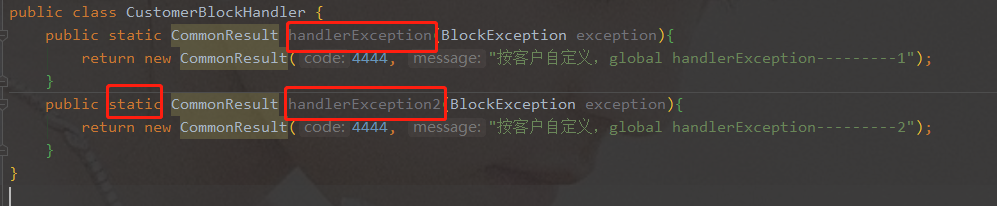
- 业务类指定处理方法
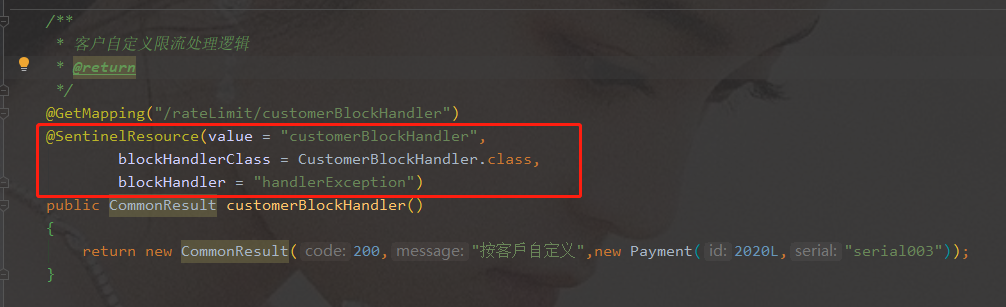
- 测试结果:业务与异常处理结构,
blockHandlerClass指定异常处理类和blockHandler指定该类中具体处理方法
-
更多注解属性说明
-


-
注意

-
Sentinel主要有三个核心API
- SphU定义资源
- Tracer定义统计
- ContextUtil定义了上下文
-
服务熔断功能
sentinel整合ribbon+openFeign+fallback(**)
Ribbon系列
-
启动nacos和sentinel
-
提供者9003/9004
-
消费者84
-
-
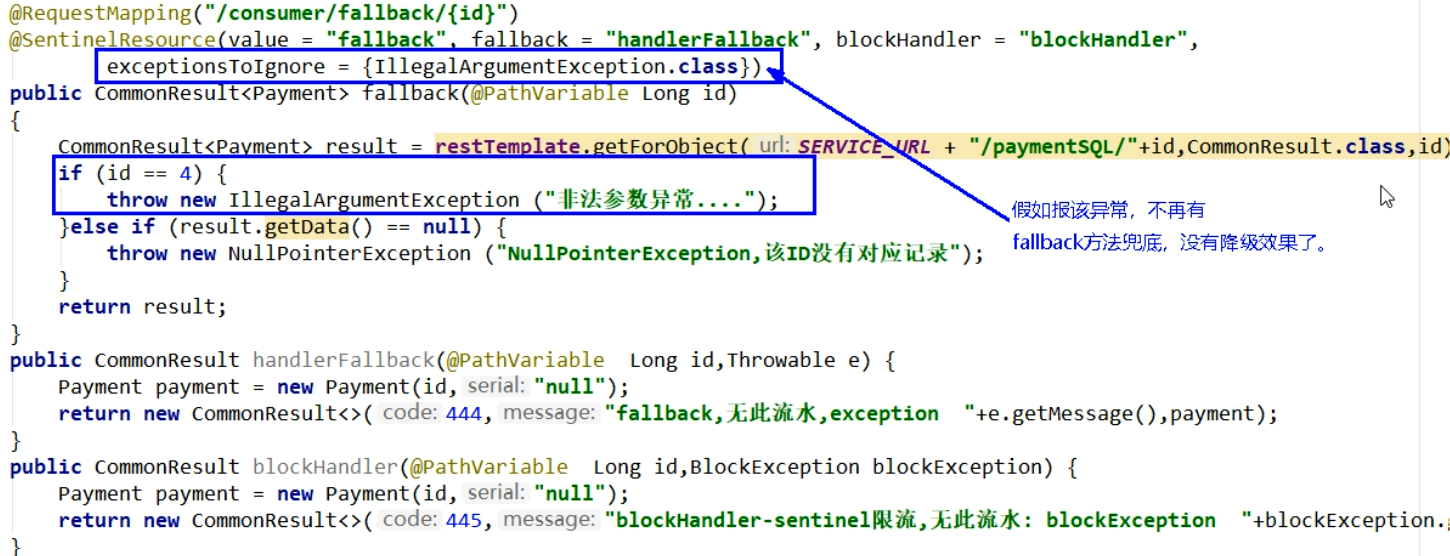
只配置fallback,处理运行时异常

-
只配置blockHandler,blockHandler只负责sentinel控制台配置违规

-
fallback和blockHandler都配置


-
忽略属性 exceptionToIgnore
Feign系列
* 修改84模块,Fegin组件一般是在消费侧
* yml 添加 feign配置
* 主启动添加@EnableFeignClients启动Feign的功能
* 业务类
* 测试84调用9003/9004,此时故意关闭9003和9004微服务提供者,**84消费自动降级**,不会被耗死
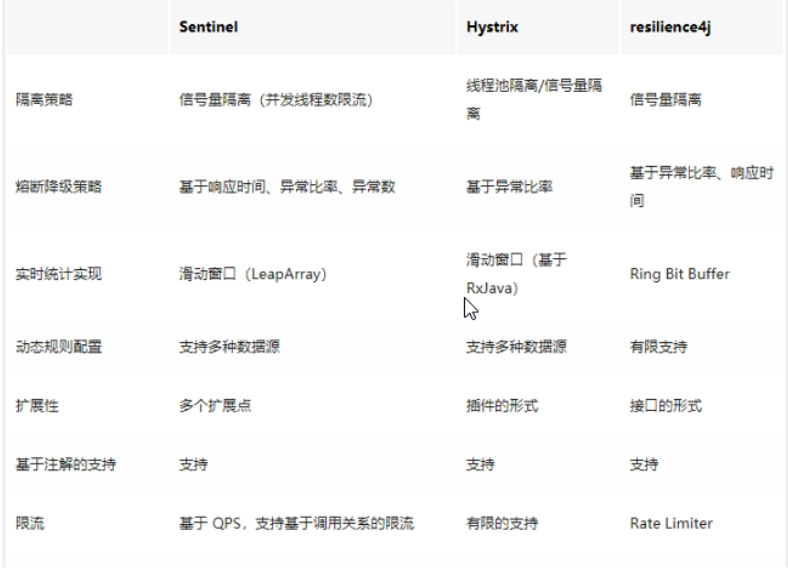
熔断框架比较

规则持久化
-
是什么:一旦我们重启应用,Sentinel规则将消失,生产环境需要将配置规则进行持久化
-
怎么玩:将限流配置规则持久化进Nacos保存,只要刷新8401某个rest地址,sentinel控制台的流控规则就能看到,只要Nacos里面的配置不删除,针对8401上Sentinel上的流控规则持续有效
-
步骤
-
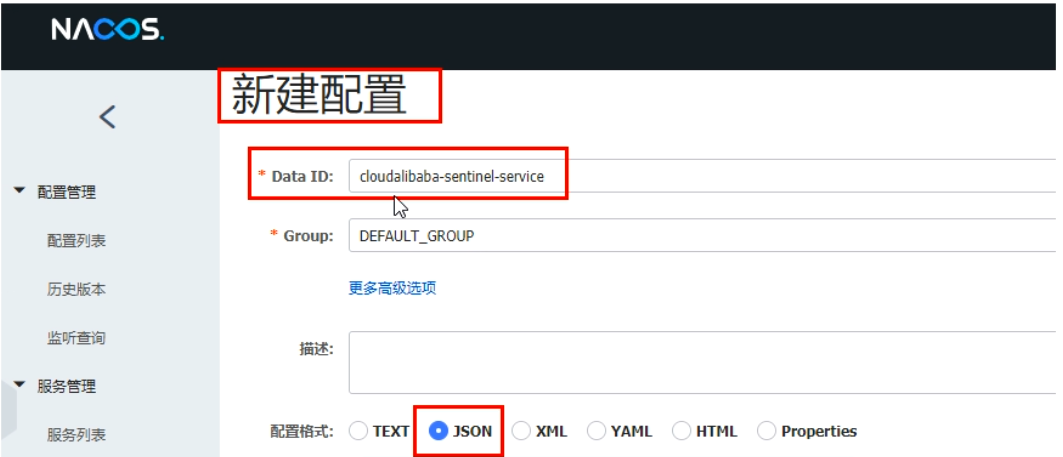
修改cloudalibaba-sentinel-service8401
-
yml :添加数据源配置
cloud: nacos: discovery: #Nacos服务注册中心地址 server-addr: localhost:8848 sentinel: transport: #配置Sentinel dashboard地址 dashboard: localhost:8080 port: 8719 #默认8719,假如被占用了会自动从8719开始依次+1扫描。直至找到未被占用的端口 datasource: ds1: nacos: server-addr: localhost:8848 dataId: cloudalibaba-sentinel-service groupId: DEFAULT_GROUP data-type: json rule-type: flow -
添加Nacos业务规则配置
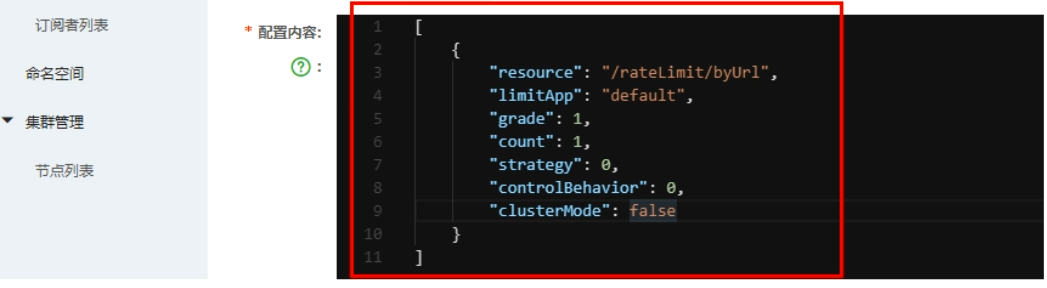
[ { "resource": "/rateLimit/byUrl", "limitApp": "default", "grade": 1, "count": 1, "strategy": 0, "controlBehavior": 0, "clusterMode": false } ]
-
启动8401后刷新sentinel发现业务规则有了
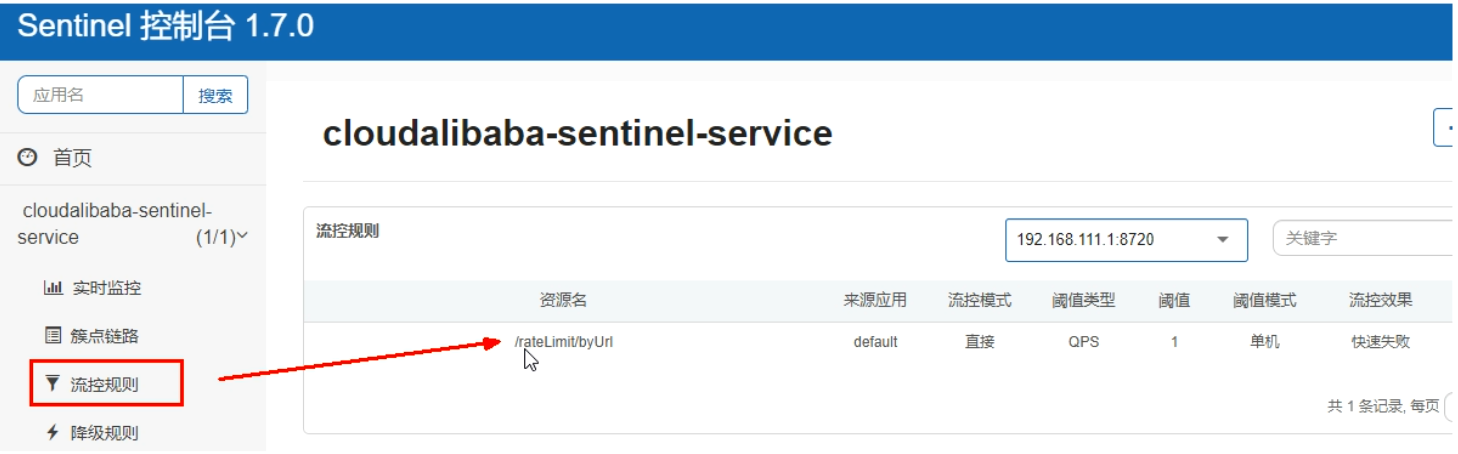
-
重新启动8401再看sentinel,多次调用,流控配置重新出现了,持久化验证通过
-
SpringCloud Alibaba Seata处理分布式事务
分布式事务问题
-
分布式前
- 单机单库没这个问题
- 从
1:1 -> 1:N -> N: N
-
分布式之后

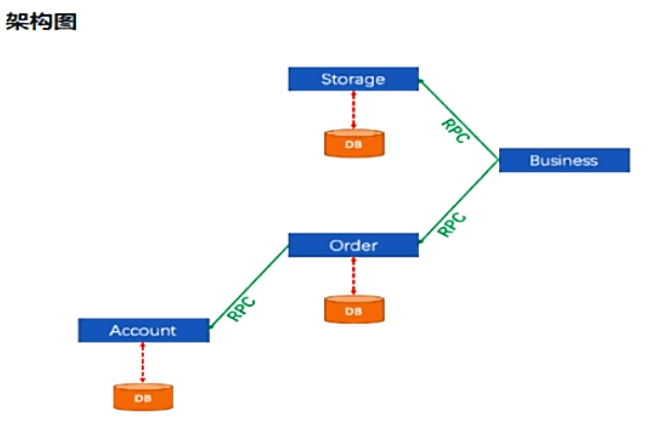
-
一句话:一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,就会产生分布式事务问题
Seata简介
-
是什么
- Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务
- 官网:http://seata.io/zh-cn/
-
能干嘛
-
一个典型的分布式事务过程:
-
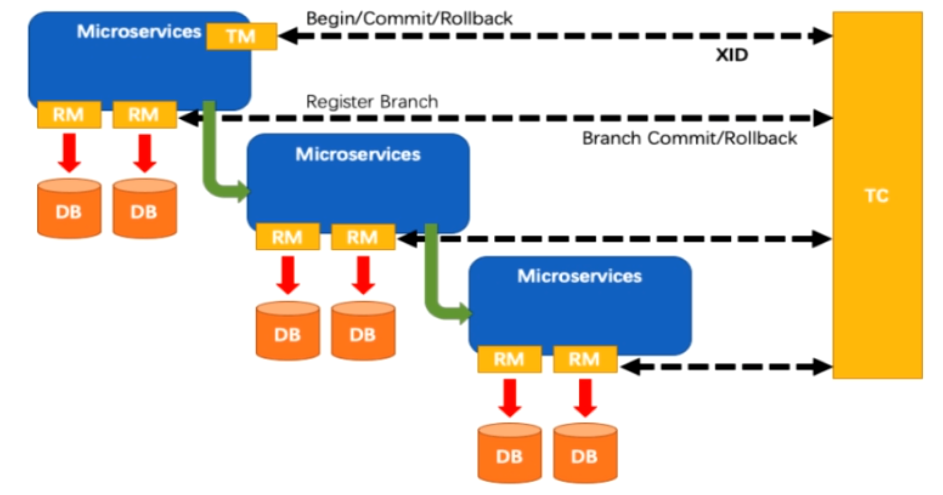
分布式事务处理过程一个ID+三组件模型
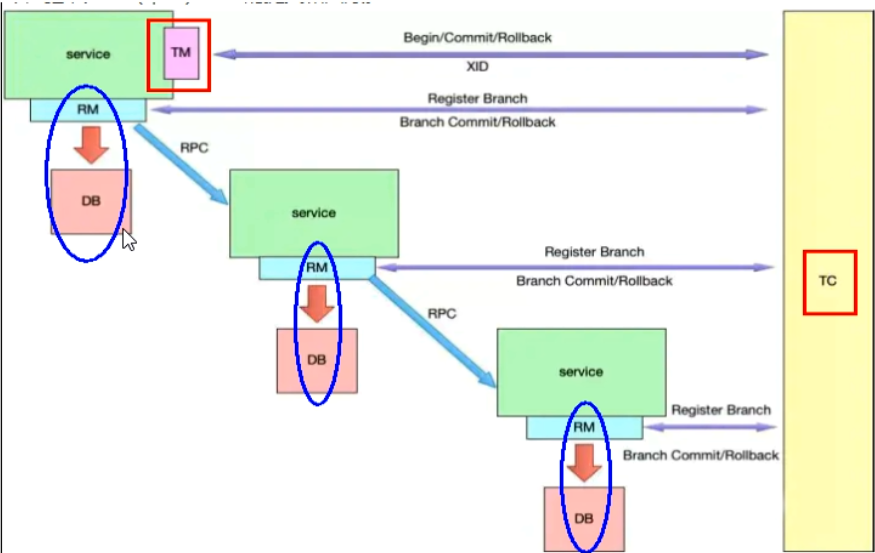
- Transaction ID XID 全局唯一的事务ID
- 三组件:
- Transaction Coordinator(TC):事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚;
- Transaction Manager(TM) :控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议;
- Resource Manager(RM) :控制分支事务,负责分支注册,状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚;
-
处理过程

-
-
-
怎么玩
- Spring 本地@Transactional
- 全局@GlobalTransactional
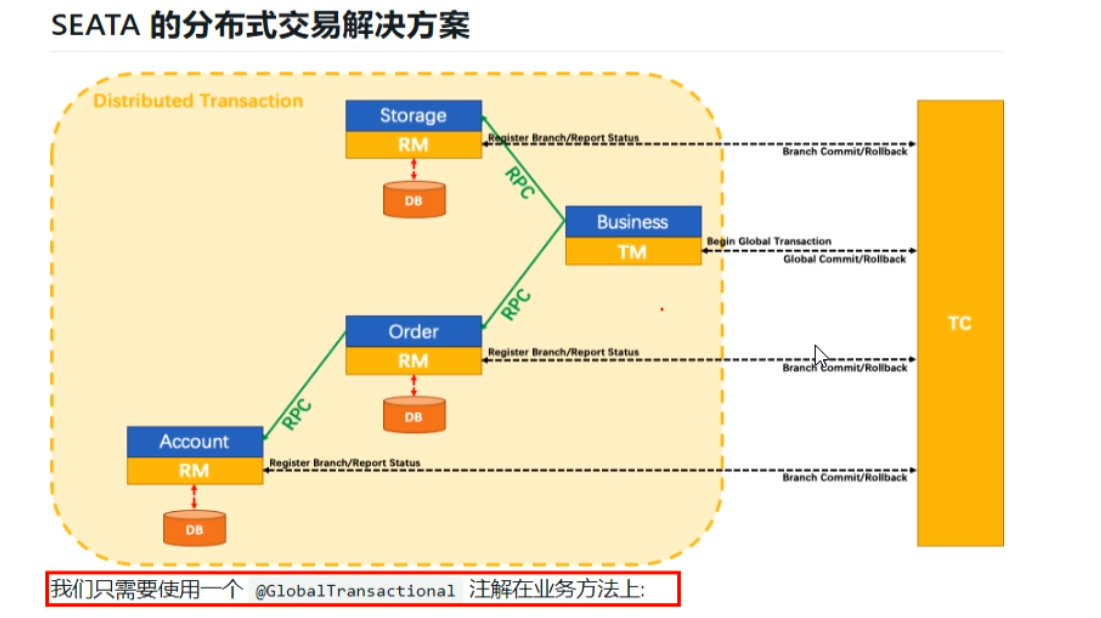
Seata-Server安装
- 官网下载稳定版本:https://github.com/seata/seata/releases
- 解压到指定目录并修改conf目录下的file.conf配置文件
- 先备份原始file.conf文件
- 主要修改:自定义事务组名称+事务日志存储模式为db+数据库连接信息
- file.conf,主要修改service模块和store模块两个模块
- 在seata库里建表
- 修改\conf目录下的registry.conf配置文件,将seata注册进nacos
- 先启动Nacos端口号8848
- 再启动seata-server
订单/库存/账户业务数据库准备
-
以下演示都需要先启动Nacos后启动Seata,保证两个都OK
-
分布式事务业务说明:三个服务 订单服务、库存服务、账户服务。当用户下单时,会在订单服务中创建一个订单,然后通过远程调用库存服务来扣减下单商品的库存,再通过远程调用账户服务来扣减用户账户里面的余额,最后在订单服务中修改订单状态为已完成
该操作跨越三个数据库,有两次远程调用,很明显会有分布式事务问题
下订单-->扣库存-->减账户(余额)
-
创建业务数据库
-- seata_order: 存储订单的数据库 CREATE DATABASE seata_order; -- seata_storage:存储库存的数据库 CREATE DATABASE seata_storage; -- sseata_account: 存储账户信息的数据库 CREATE DATABASE seata_account; -
按照上述3库分别建对应业务表
-
seata_order库下建t_order表
CREATE TABLE t_order( `id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, `user_id` BIGINT(11) DEFAULT NULL COMMENT '用户id', `product_id` BIGINT(11) DEFAULT NULL COMMENT '产品id', `count` INT(11) DEFAULT NULL COMMENT '数量', `money` DECIMAL(11,0) DEFAULT NULL COMMENT '金额', `status` INT(1) DEFAULT NULL COMMENT '订单状态:0:创建中; 1:已完结' ) ENGINE=INNODB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8; SELECT * FROM t_order; -
seata_storage库下建t_storage表
CREATE TABLE t_storage( `id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, `product_id` BIGINT(11) DEFAULT NULL COMMENT '产品id', `'total` INT(11) DEFAULT NULL COMMENT '总库存', `used` INT(11) DEFAULT NULL COMMENT '已用库存', `residue` INT(11) DEFAULT NULL COMMENT '剩余库存' ) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8; INSERT INTO seata_storage.t_storage(`id`,`product_id`,`total`,`used`,`residue`) VALUES('1','1','100','0','100'); SELECT * FROM t_storage; -
seata_account库下建t_account表
CREATE TABLE t_account( `id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT 'id', `user_id` BIGINT(11) DEFAULT NULL COMMENT '用户id', `total` DECIMAL(10,0) DEFAULT NULL COMMENT '总额度', `used` DECIMAL(10,0) DEFAULT NULL COMMENT '已用余额', `residue` DECIMAL(10,0) DEFAULT '0' COMMENT '剩余可用额度' ) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8; INSERT INTO seata_account.t_account(`id`,`user_id`,`total`,`used`,`residue`) VALUES('1','1','1000','0','1000') SELECT * FROM t_account; -
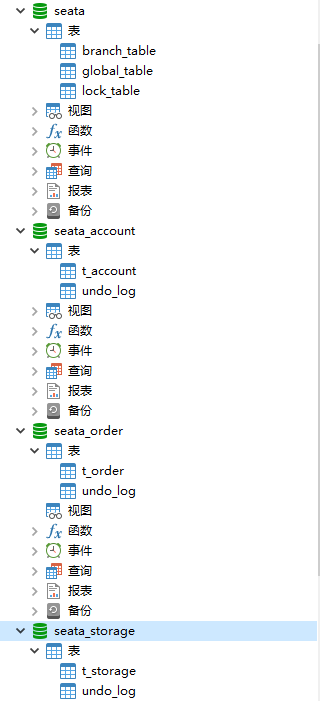
按照上述3库分别建对应的回滚日志表
-
订单-库存-账户3个库下都需要建各自的回滚日志表
-
drop table `undo_log`; CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) NOT NULL, `context` varchar(128) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; -
-
-
订单/库存/账户业务微服务准备
- 业务需求:下订单->减库存->扣余额->改(订单)状态
- 新建订单Order-Module:
cloudalibaba-seata-order-service2001 - 新建库存Storage-Module:
cloudalibaba-seata-storage-service2002 - 新建账户Account-Module:
cloudalibaba-seata-account-service2003 - 本地用的Seata1.2与视频中0.9配置差异较大。建议参考:https://blog.csdn.net/sinat_38670641/article/details/105857484
- 数据库文件及配置文件资源地址:https://github.com/seata/seata/tree/1.2.0/script/config-center
Test
- 下订单->减库存->扣余额->改(订单)状态
- 数据库初始情况
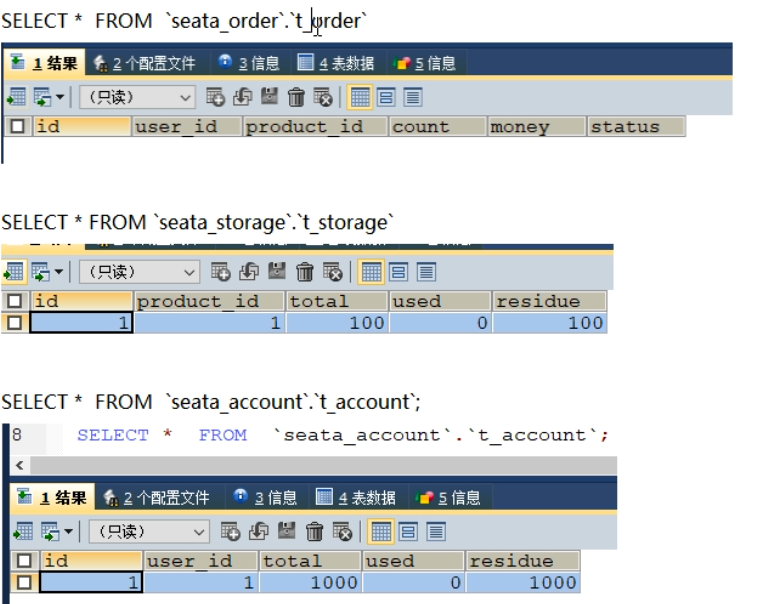
- 正常下单
- 超时异常,没加@GlobalTransactional
- AccountServiceImpl添加超时
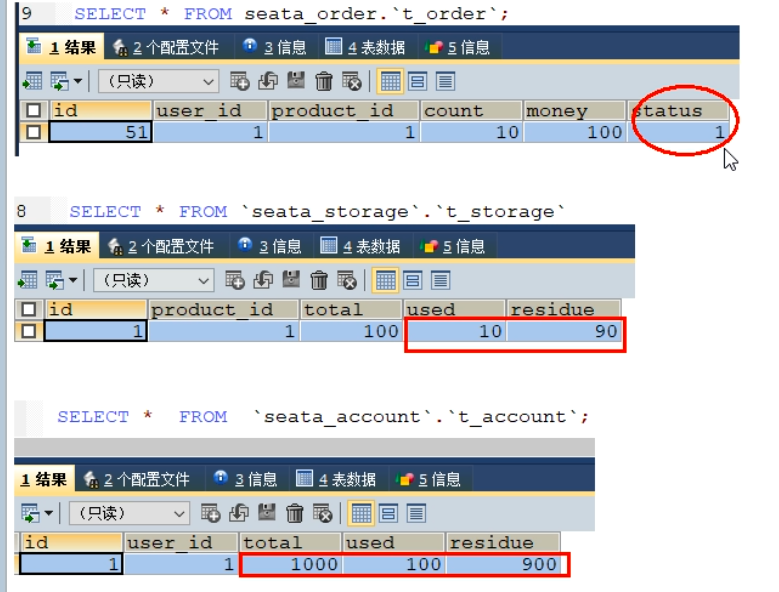
- 故障情况:当库存和账户余额扣减后,订单状态并没有设置为已经完成,没有从零改为1。而且由于feign的重试机制,账户余额还有可能被多次扣减
- 超时异常,添加@GlobalTransactional
- AccountServiceImpl添加超时
- OrderServiceImpl@GlobalTransactional
- 下单后数据库数据并没有任何改变,记录都添加不进来
Seata原理
-
再看TC/TM/RM三大组件
- 分布式事务执行流程(**)
- TM开启分布式事务(TM向TC注册全局事务记录)
- 换业务场景,编排数据库,服务等事务内资源(RM向TC汇报资源准备状态)
- TM结束分布式事务,事务一阶段结束(TM通知TC提交/回滚分布式事务)
- TC汇总事务信息,决定分布式事务是提交还是回滚
- TC通知所有RM提交/回滚资源,事务二阶段结束。
- 分布式事务执行流程(**)
-
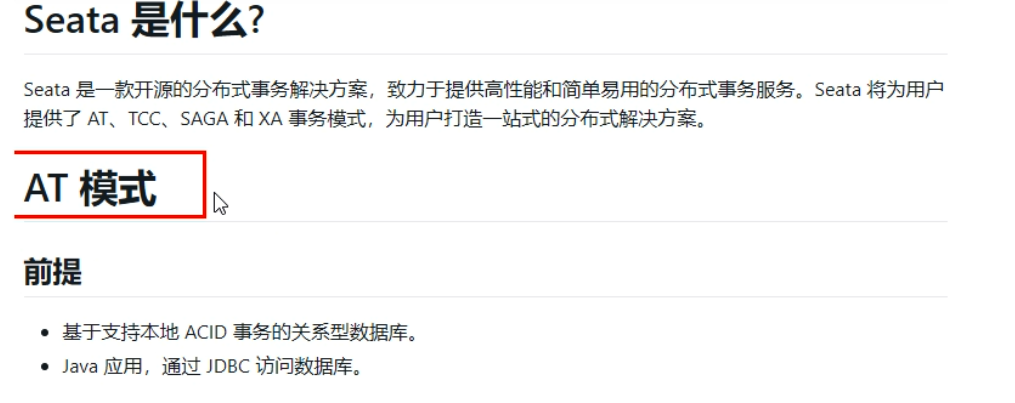
AT模式如何做到对业务的无侵入
-
是什么
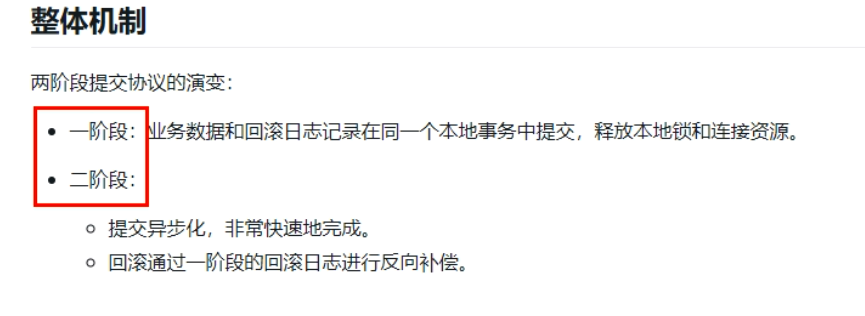
-
一阶段加载

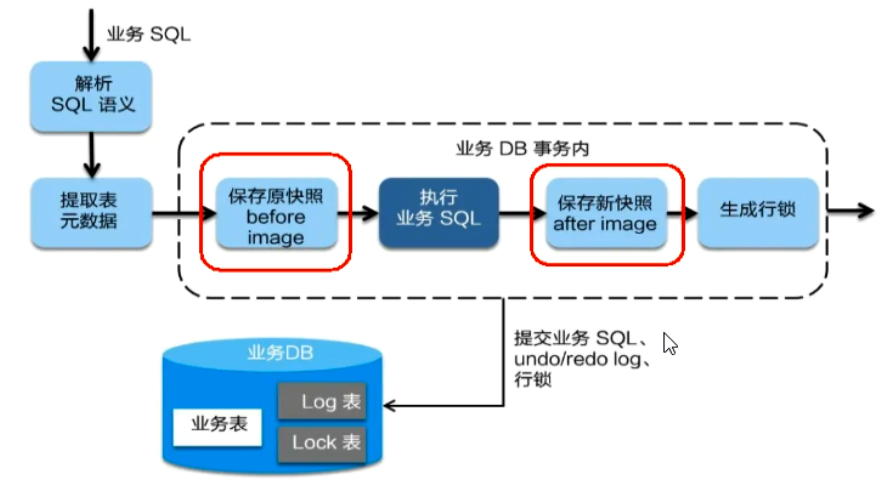
-
二阶段提交
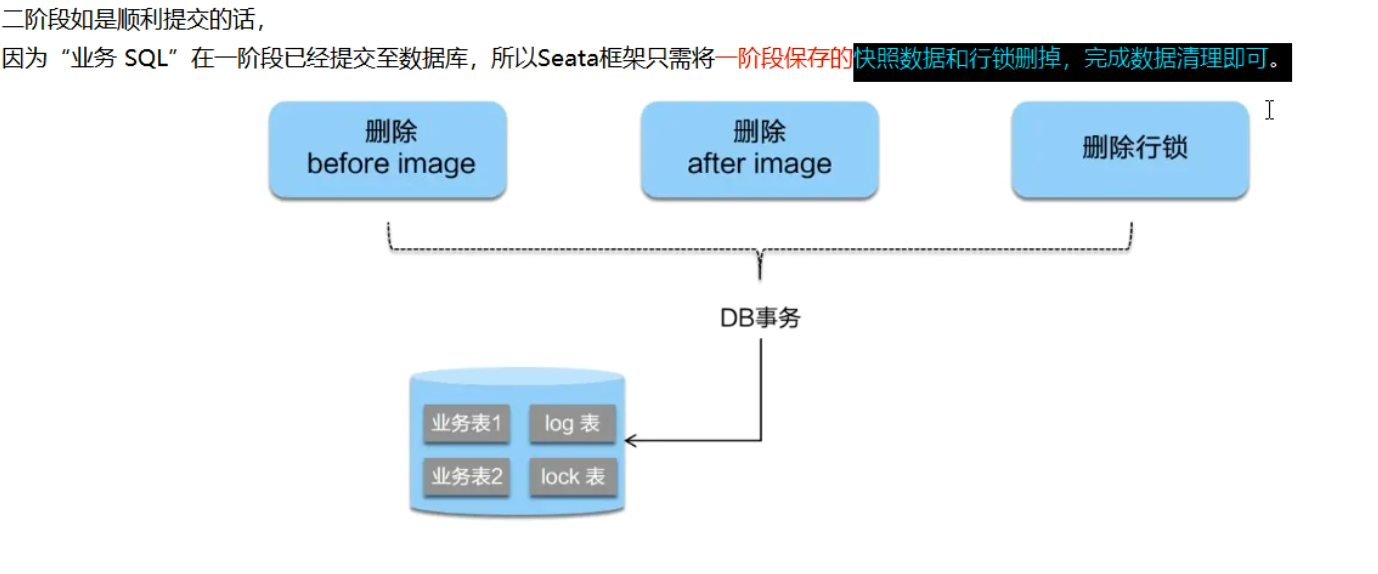
-
二阶段回滚

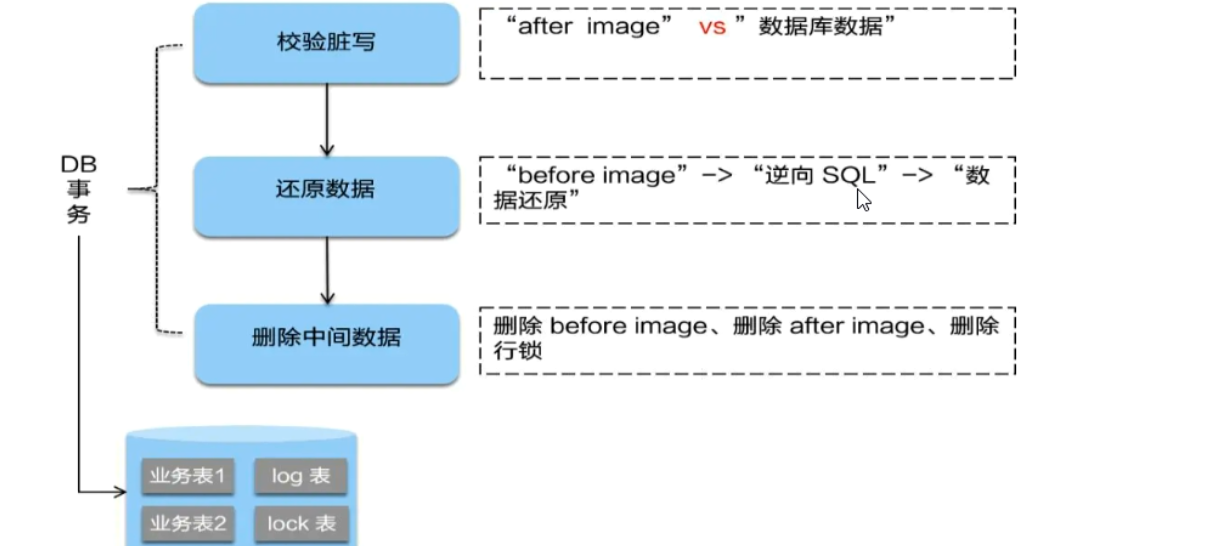
-
-
debug:观察数据库回滚细节
-
总结
