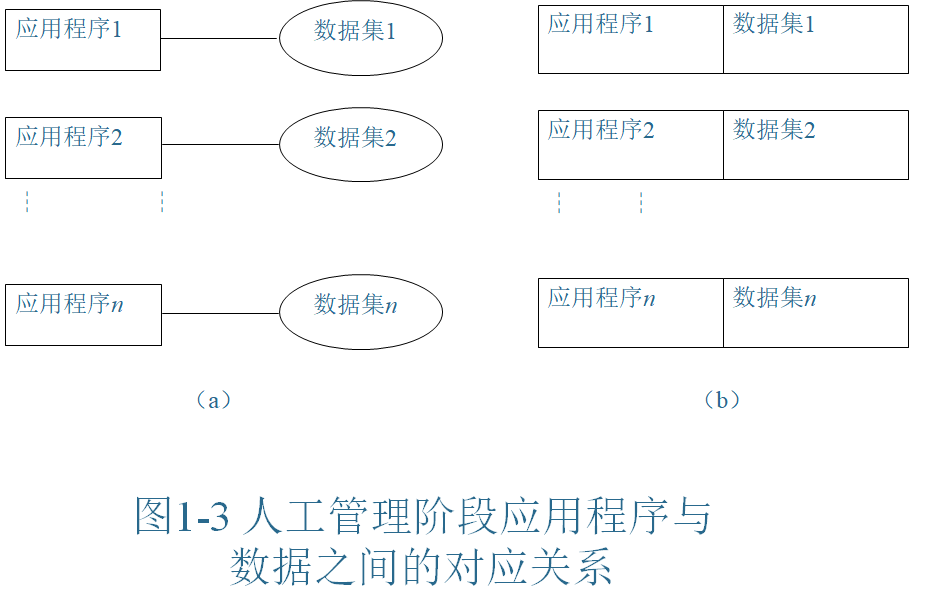
人工管理阶段
从应用上看,计算机的主要应用领域是科学计算。从硬件上看,这个时期计算机内存空间小,计算速度低,外存只有磁带、卡片和纸带,没有像磁盘这样快速的直接存取存储设备。从软件上看,计算机没有操作系统,更没有数据管理软件,数据处理是以批处理方式进行的
- 数据管理的特点
- 数据不保存:内存外存有限;主要用于科学计算,数据量较少
- 程序员管理数据:由于当时没有相应的软件系统负责数据的管理工作,应用程序中涉及的数据需要由程序员自己管理,即程序员在程序中不仅要编写数据逻辑结构的代码,而且还要编写数据物理结构的代码,包括数据存储结构、存取方法和输入方式的代码。
- 数据不能共享:由于数据是在程序中定义的,一组数据只能对应一个程序,易产生大量的冗余数据。
- 数据不具有独立性:由于数据的逻辑结构和物理结构均在程序代码中定义,如果因为某种原因,需要改变数据的逻辑结构或物理结构时,必须对应用程序代码作相应的修改,即数据与程序之间不具有独立性。这不仅加重了程序员的负担,且使用起来也很不方便、费时费力。
- 数据管理的缺点
- 数据管理中没有直接存取的存储设备存储数据,导致应用程序中的数据无法被其他程序利用。
- 由于人工管理阶段的数据是面向应用的,即使两个应用程序涉及某些相同的数据,也必须各自定义,所以程序与程序之间有大量重复数据,导致数据冗余。
- 由于没有专门的软件管理数据,程序员不仅要规定数据的逻辑结构,而且还要在程序中设计物理结构,使数据和程序之间不具有相对独立性,这样就会造成数据独立性、结构性差。
- 人工管理阶段的软硬件条件很差,在需要时将数据输入,用完就撤走,导致了数据不能长期保存。
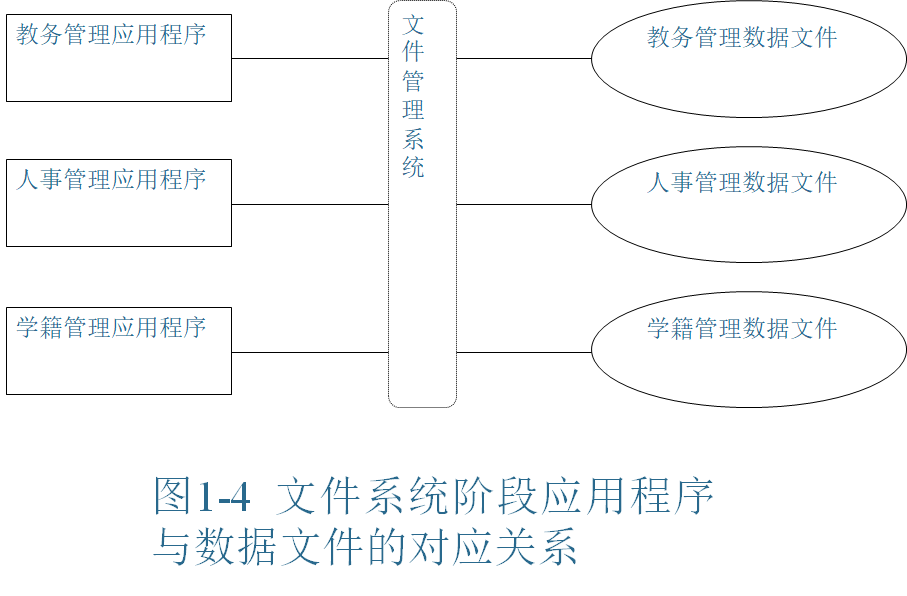
文件系统阶段
文件系统阶段是指从20世纪50年代后期到60年代中期。该时期的计算机应用范围逐渐扩大,计算机不仅用于科学计算,而且还大量用于信息管理。计算机硬件有了进一步的发展,出现了磁盘、磁鼓等能直接存取的外存储设备。在软件方面,高级语言和操作系统已经有了完善的产品,并且操作系统中有专门负责管理数据的文件系统功能。数据处理的方式有批处理,也有联机实时处理。
-
数据管理特点
- 数据可以长期保存:由于计算机大量用于数据处理,数据需要长期保存以便反复使用。把数据以文件的形式保存在磁盘等外存储器上,为数据的长期保存和反复使用提供了保证。
- 文件的多样化和结构化:由于有了直接存取设备,也就出现了顺序文件、索引文件、随机文件等多种文件组织形式。数据文件的存取基本上以记录为单位,而记录则是由一些字段按特定的结构组成的,每个记录的长度是相等的。因此文件是记录的集合,文件系统实现了记录内部的有结构、但在整体上数据仍然是无结构的。
- 文件系统管理数据:操作系统提供的文件管理系统是应用程序与数据文件的专门接口。程序和数据文件之间的存取操作由文件系统根据“按文件名访问,按记录进行存取”的管理技术自动完成。文件的逻辑结构到物理结构的转换由文件系统来自动完成,而不必由程序员设计考虑,从而使得程序和数据分开,数据与程序之间有了一定的独立性。
-
数据管理的缺点
- 数据冗余度大:在文件系统中,一个文件基本上对应于一个应用程序,即文件系统中文件仍由应用程序来定义。当不同的应用程序具有部分相同的数据时,也必须建立各自的数据文件,而不能共享相同的数据。由于相同的数据在不同的文件中重复存储、并由各自的程序管理,容易造成数据的不一致性,给数据的修改和维护带来困难。
- 数据独立性较差:由于文件的逻辑结构是在应用程序中定义的,文件系统中的文件是为某一特定应用服务的,因此一旦数据的逻辑结构改变,必须修改应用程序中关于文件结构的定义。反过来,应用程序的改变(例如,应用程序改用其他的高级语言编写)也将引起数据文件结构的改变。因此数据与程序之间独立性较差。
- 数据联系弱:数据联系是指不同文件中的数据之间的联系。在文件系统阶段,不同文件中的数据是相互独立的,数据联系弱。
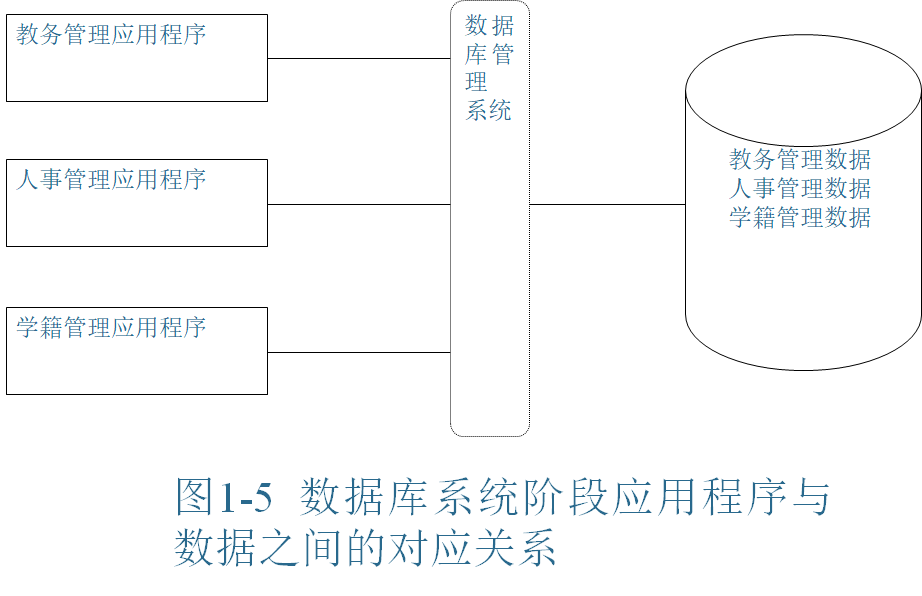
数据库系统阶段
数据库系统阶段是指从20世纪60年代后期至今。标志是20世纪60年代末期的三件大事:① 1968年美国IBM公司推出层次模型的IMS(Information Management System)系统。②1969年美国CODASYL(Conference On Data System Language)组织颁布了DBTG(Data Base Task Group,数据库任务组)报告。提出网状模型。③1970年美国IBM公司的E.F.Codd连续发表论文,提出关系模型,奠定了关系数据库的理论基础。
- 数据管理特点
- 采用特定的数据模型,使数据结构化 数据结构化是数据库和文件系统的本质区别。在文件系统中,相互独立的文件的记录内部是有结构的,通常采取的是等长或变长的记录格式,但记录之间没有联系,这种数据的独立性只对一个应用而言,仍有局限性,不适应多用户、多应用共享数据的需求。而数据库系统为用户提供一个数据的抽象视图,它能隐藏数据的存储结构和存取方法等细节,并通过数据模型作为实现数据抽象的主要工具,实现了整体数据的结构化,它要求在描述数据时不仅要描述数据本身,还要描述数据之间的联系。
- 数据的独立性高:数据库系统提供了三级数据抽象(视图级抽象、概念级抽象和物理级抽象)能力和三种数据库模式(外模式、模式和内模式),实现了数据的物理独立性和逻辑独立性。数据与程序的相互独立,使得可以把数据的定义和描述从应用程序中分离出去,而数据的存取由DBMS统一管理,用户在应用程序中不用考虑存取路径等细节,大大简化了应用程序的编制及应用程序对数据的维护和修改。
- 数据的共享性好,数据冗余度低:数据库系统允许多个用户或多个应用程序同时访问数据库中的相同数据,数据不再面向某个应用,而是面向整个系统,从而实现了数据的共享,节省了存储空间,大大减少了数据冗余,避免了数据之间的不相容性与不一致性。
- 为用户提供了方便的用户接口:用户可以使用查询语言(如SQL)或终端命令对数据库进行访问,也可以借助高级语言(如C、Java)采用程序方式对数据库进行操作。
- 统一的数据控制:数据库系统中的数据由DBMS统一管理,而且管理的是有结构的数据,因此可灵活地使用数据。一个数据库一般都要支持很多应用程序和用户。不同的应用程序和不同的用户对同一个数据库可能有不同的理解,对同一数据库的一种理解称为这个数据库的一个视图。一个视图可以是一个数据库子集合,也可以是多个数据库的子集按照某种方式构成的虚拟数据库。DBMS提供了定义、维护和操纵视图的机制,使得多个用户可以为他们的应用定义、维护和使用自己的视图。
- 为了适应数据共享环境,DBMS提供了数据控制功能
- 数据的安全性控制
- 数据的完整性控制
- 并发控制:并发控制是用来控制多个事务的并发运行,避免事务之间的相互干扰,保证每个事务都能产生正确的结果。
- 数据库恢复:数据库恢复是指在发生某种故障而使数据库当前状态已经不再正确时,能把数据库恢复到已知为正确的某种状态。