统计数据:pd.describe()
· 缺失值:df.isnull() #df就是加载进来的数据,DataFrame类型的
·异常值: 箱型图模型
画图
·分布:
核密度估计:sns.kdeplot()
直方图图:sns.distplot()
判断方法:df.info()
分类: 连续型(continuous)和标称型或分类变量(categorical)
1 f= r'movies_metadata.csv' 2 df =pd.read_csv(f) #加载数据 df是DataFrame类型 3 print(df.info()) #输出数据信息(数目、类型)
输出结果

分析统计数据:df.describe()
1 f= r'movies_metadata.csv' 2 df =pd.read_csv(f) #加载数据 df是DataFrame类型 3 print(df.describe()) #输出统计信息
输出结果

缺失值、异常值单变量绘图,这几项都写在一个类里面,对号入座
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import seaborn as sns 4 import warnings 5 warnings.filterwarnings('ignore') #忽略警告 6 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 7 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 8 9 class PreProcess: 10 def __init__(self,f): 11 self.data =pd.read_csv(f) 12 13 def missVal(self,col =None): 14 '''缺失值''' 15 raw,columns =self.data.shape #形状:(行数,列数) 16 if col: 17 num =self.data[col].isnull().sum().sort_values() #排序 18 else: 19 num =self.data.isnull().sum().sort_values() 20 #print(col, r"缺失数: ", num) 21 print(col,r"缺失值比例: ",num/raw) 22 23 def abnormalVal(self,col): 24 '''单连续变量异常值''' 25 #箱型图模型 26 colData =self.data[col] 27 dscr =colData.describe() #统计数据 28 iqr =dscr.loc['75%'] - dscr['25%'] #四分位间距 =上四分位数-下四分位数 29 upBoundry =dscr.loc['75%'] +1.5*iqr #上界 30 lowBoundry =dscr.loc['25%'] - 1.5*iqr #下界 31 num = (colData <lowBoundry).sum() +sum(colData >upBoundry) #超过边界的算异常值 32 print(col,"异常值数目:",num) 33 print(col,"异常值占比:",num/colData.shape[0]) 34 #self.data.boxplot(col);plt.show() #直接画箱型图 35 36 def sDraw(self,col): 37 '''单连续变量分布图''' 38 sns.kdeplot(self.data[col].values,shade=True) #核密度估计 KDE(Kernel Density Estimate) 39 plt.title(col) #设置标题 40 plt.show() 41 sns.distplot(self.data[col].values,bins=10,kde=True) #直方图 bins:直方图数目、kde:是否画kde曲线 42 plt.title(col) #设置标题 43 plt.show()
补充:两个图主要看分布
kedplot 的图
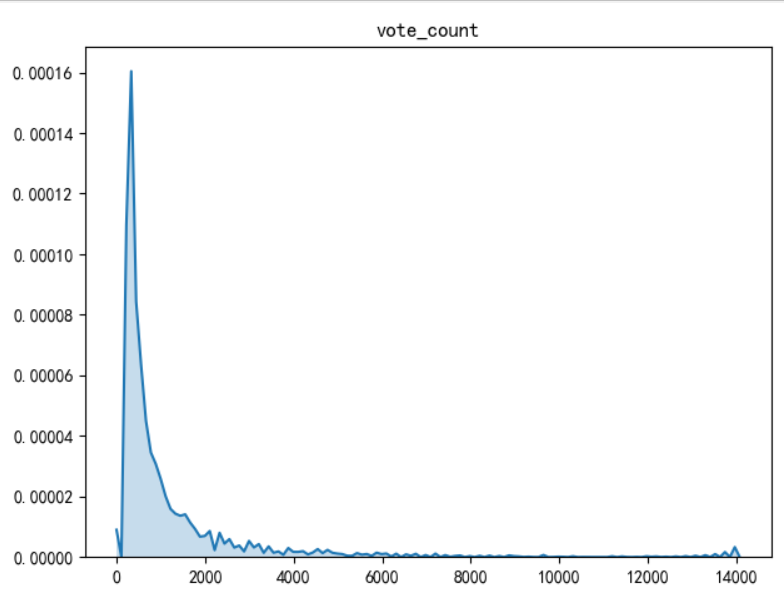
distplot()
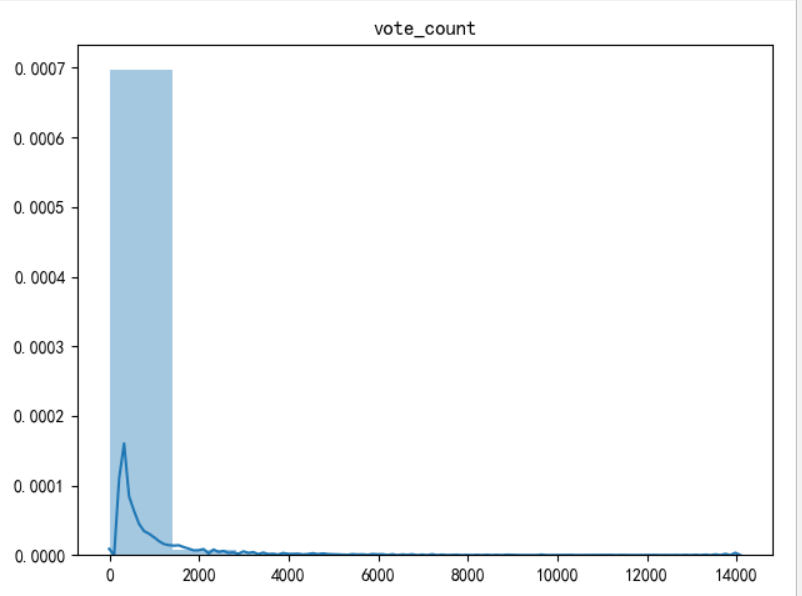
这个有一点重尾分布:评论数目较少的电影(样本/每一行的数据),占了70%左右