1.参数计算
卷积核大小*卷积核深度*输入该层数据的深度+卷积核深度
2.输出大小
(输入图像shape - 卷积核shape) / stride + 1
3.Dog-Vs-Cat实例
使用kaggle的Dog-Vs-Cat数据集,这个数据集包含25000条train数据,12500条test数据。这里仅使用train数据中的4000个数据作为全部数据。
数据集划分为2000条训练数据,1000条验证数据,1000条测试数据,猫和狗一半一半。
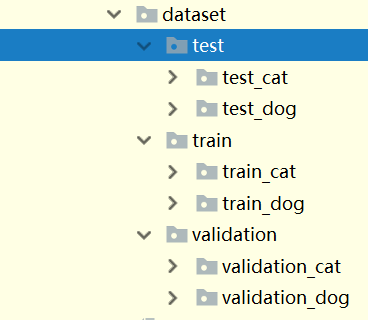
数据集创建好的文件结构是这样的
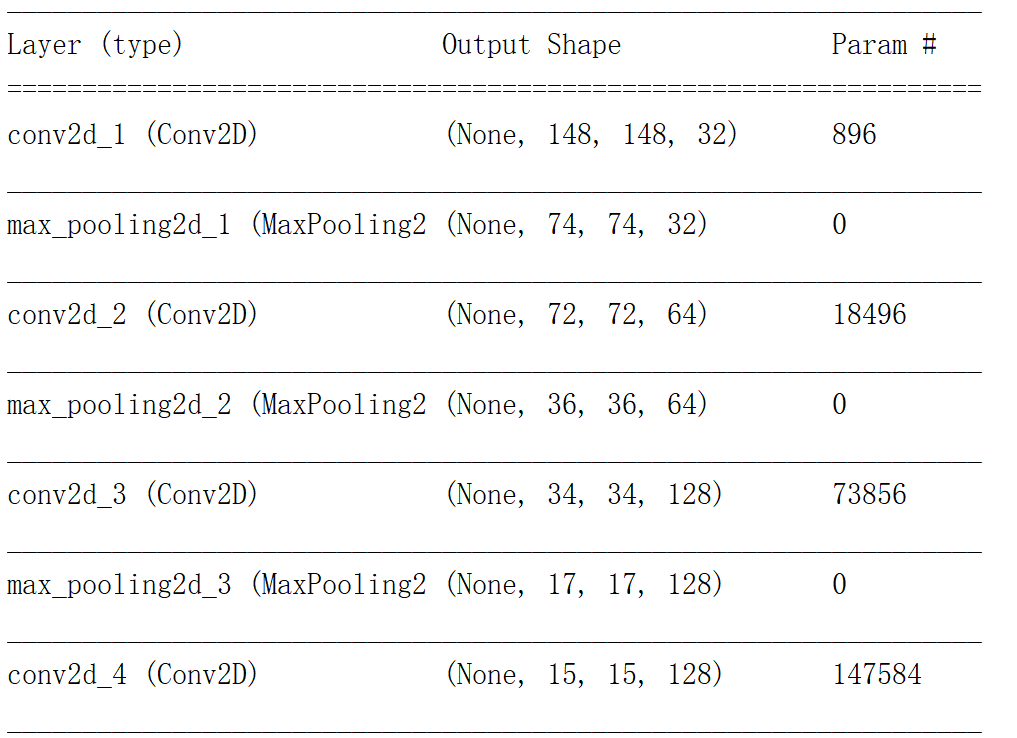
网络结构如下

from keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt from keras import models from keras import layers import matplotlib.pyplot as plt #数据增强 train_datagen = ImageDataGenerator( #rescale会为每个像素上乘以1.0/255,相当于将像素做了归一化 rescale=1.0/255, #像素随机旋转的范围 rotation_range=40, #水平、垂直平移范围,相对于高宽 width_shift_range=0.2, height_shift_range=0.2, #效果就是让所有点的x坐标(或者y坐标)保持不变, # 而对应的y坐标(或者x坐标)则按比例发生平移,且平移的大小和该点到x轴(或y轴)的垂直距离成正比 shear_range=0.2, #zoom_range参数可以让图片在长或宽的方向进行放大 #而参数大于0小于1时,执行的是放大操作,当参数大于1时,执行的是缩小操作 zoom_range=0.2, #随机水平翻转 horizontal_flip=True) test_datagen = ImageDataGenerator(rescale=1.0/255) train_generator = train_datagen.flow_from_directory( 'dataset/train', target_size=(150,150), batch_size=20, #binary是整数列表 class_mode='binary' ) validation_generator = test_datagen.flow_from_directory( 'dataset/validation', target_size=(150,150), batch_size=20, #binary是整数列表 class_mode='binary' ) network = models.Sequential() network.add(layers.Conv2D(32,(3,3),activation='relu',input_shape=(150,150,3))) #maxpooling窗口默认是(2,2),stride默认是窗口值 network.add(layers.MaxPooling2D((2,2))) network.add(layers.Conv2D(64,(3,3),activation='relu')) network.add(layers.MaxPooling2D((2,2))) network.add(layers.Conv2D(128,(3,3),activation='relu')) network.add(layers.MaxPooling2D((2,2))) network.add(layers.Conv2D(128,(3,3),activation='relu')) network.add(layers.MaxPooling2D((2,2))) #把网络展开为1维 network.add(layers.Flatten()) network.add(layers.Dropout(0.5)) network.add(layers.Dense(512,activation='relu')) network.add(layers.Dense(1,activation='sigmoid')) network.compile('rmsprop','binary_crossentropy',metrics=['acc']) network.summary() history = network.fit_generator( train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50) history_dict = history.history loss = history_dict['loss'] val_loss = history_dict['val_loss'] acc = history_dict['acc'] val_acc = history_dict['val_acc'] epochs = range(1,101) #loss的图 plt.subplot(121) plt.plot(epochs,loss,'g',label = 'Training loss') plt.plot(epochs,val_loss,'b',label = 'Validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') #显示图例 plt.legend() plt.subplot(122) plt.plot(epochs,acc,'g',label = 'Training accuracy') plt.plot(epochs,val_acc,'b',label = 'Validation accuracy') plt.xlabel('Epochs') plt.ylabel('accuracy') plt.legend() plt.show() network.save('cat_dog.h5')
由于使用的数据集较小,所以即使使用了数据增强,任然会在80%左右的精度发生过拟合,为了继续提高精度,可以使用预训练的神经网络,预训练的神经网络一般都是在大型数据集上训练的,他的前几层提取出了具有高通用性的特征(颜色、纹理、边缘等),因此前几层可以复用。
from keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt from keras import models from keras import layers from keras.applications import VGG16 import matplotlib.pyplot as plt #数据增强 train_datagen = ImageDataGenerator( #rescale会为每个像素上乘以1.0/255,相当于将像素做了归一化 rescale=1.0/255, #像素随机旋转的范围 rotation_range=40, #水平、垂直平移范围,相对于高宽 width_shift_range=0.2, height_shift_range=0.2, #效果就是让所有点的x坐标(或者y坐标)保持不变, # 而对应的y坐标(或者x坐标)则按比例发生平移,且平移的大小和该点到x轴(或y轴)的垂直距离成正比 shear_range=0.2, #zoom_range参数可以让图片在长或宽的方向进行放大 #而参数大于0小于1时,执行的是放大操作,当参数大于1时,执行的是缩小操作 zoom_range=0.2, #随机水平翻转 horizontal_flip=True) test_datagen = ImageDataGenerator(rescale=1.0/255) train_generator = train_datagen.flow_from_directory( 'dataset/train', target_size=(150,150), batch_size=20, #binary是整数列表 class_mode='binary' ) validation_generator = test_datagen.flow_from_directory( 'dataset/validation', target_size=(150,150), batch_size=20, #binary是整数列表 class_mode='binary' ) #weight='imagenet'模型初始化的权值 #include_top=False是否使用后边的全连接层 conv_base = VGG16(weights='imagenet',include_top=False,input_shape=(150,150,3)) network = models.Sequential() #不改变VGG16的权值 conv_base.trainable = False network.add(conv_base) network.add(layers.Flatten()) network.add(layers.Dense(256,activation='relu')) network.add(layers.Dense(1,activation='sigmoid')) network.compile('rmsprop','binary_crossentropy',metrics=['acc']) network.summary() history = network.fit_generator( train_generator, steps_per_epoch=100, epochs=30, validation_data=validation_generator, validation_steps=50) history_dict = history.history loss = history_dict['loss'] val_loss = history_dict['val_loss'] acc = history_dict['acc'] val_acc = history_dict['val_acc'] epochs = range(1,31) #loss的图 plt.subplot(121) plt.plot(epochs,loss,'g',label = 'Training loss') plt.plot(epochs,val_loss,'b',label = 'Validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') #显示图例 plt.legend() plt.subplot(122) plt.plot(epochs,acc,'g',label = 'Training accuracy') plt.plot(epochs,val_acc,'b',label = 'Validation accuracy') plt.xlabel('Epochs') plt.ylabel('accuracy') plt.legend() plt.show()
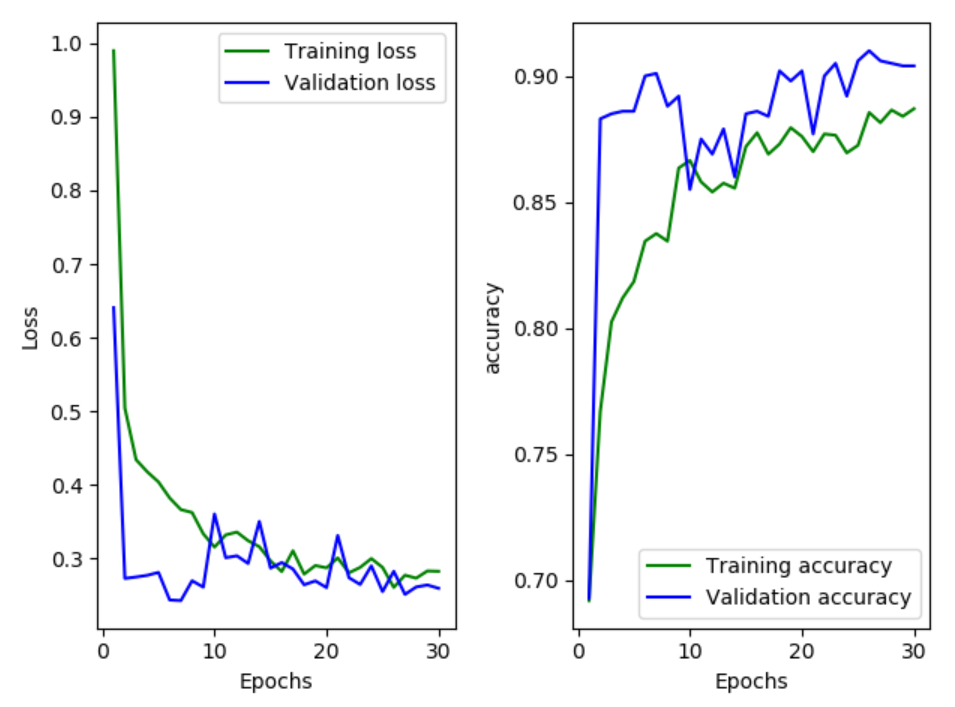
可以看到精度可以达到90%多
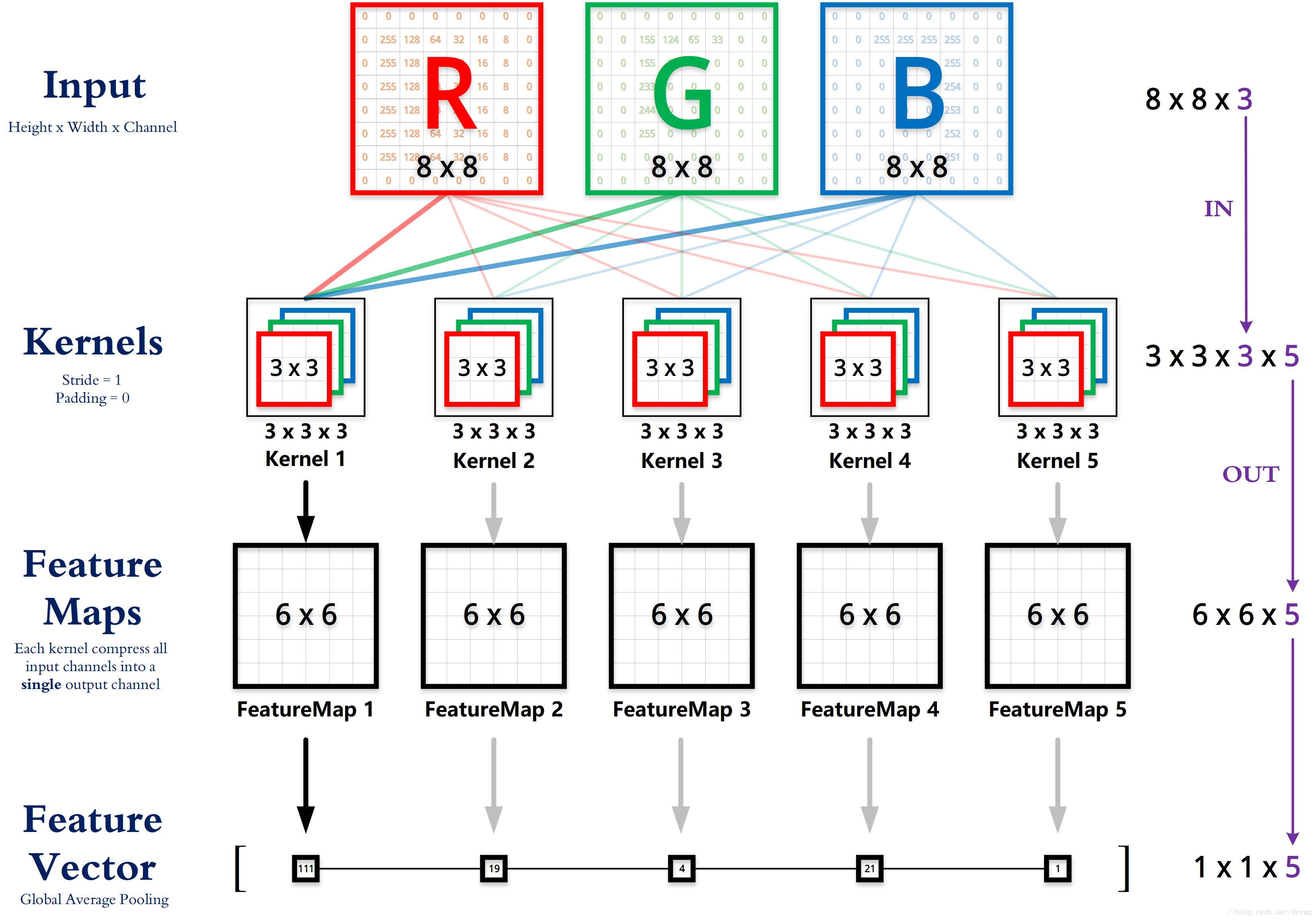
4.多特征图多个卷积核卷积
如下图所示,想要使用5个3*3的卷积核对8*8的图像进行卷积,要求输入图像的通道和卷积核的通道一致,然后每个卷积核会生成一个feature map,在卷积的时候,是每个卷积核的每个通道和输入图像的对应通道卷积,然后把各各通道的卷积结果加上bias作为feature map对应位置的值
5.权值共享
转载自:https://blog.csdn.net/chaipp0607/article/details/73650759
其实权值共享这个词说全了就是整张图片在使用同一个卷积核内的参数,比如一个3*3*1的卷积核,这个卷积核内9个的参数被整张图共享,而不会因为图像内位置的不同而改变卷积核内的权系数。说的再直白一些,就是用一个卷积核不改变其内权系数的情况下卷积处理整张图片(当然CNN中每一层不会只有一个卷积核的,这样说只是为了方便解释而已)。
是的,就是这样,很简单的一个操作而已,这样来说的话,其实图像处理中的类似边缘检测,滤波操作等等都是在做全局共享,那么为什么当时要把这个思路拿出来说明一下,然后又给它起了一个名字呢?
(以下部分是个人理解,如果有不对的地方,还望指正!!)
我们大部分人都是在后知后觉中发现这个问题很简单,但是只有大神才能做先驱者!LeNet首次把卷积的思想加入到神经网络模型中,这是一项开创性的工作,而在此之前,神经网络输入的都是提取到的特征而已,就比如想要做一个房价预测,我们选取了房屋面积,卧室个数等等数据作为特征。而将卷积核引入到了神经网络去处理图片后,自然而然就会出现一个问题,神经网络的输入是什么?如果还是一个个像素点上的像素值的话,那就意味着每一个像素值都会对应一个权系数,这样就带来了两个问题:
1.每一层都会有大量的参数
2.将像素值作为输入特征本质上和传统的神经网络没有区别,并没有利用到图像空间上的局部相关性。
而权值共享的卷积操作有效解决了这个问题,无论图像的尺寸是多大,都可以选择固定尺寸的卷积核,LeNet中最大的卷积核只有5*5*1,而在AlexNet中最大的卷积核也不过是11*11*3。而卷积操作保证了每一个像素都有一个权系数,只是这些系数是被整个图片共享的,着大大减少了卷积核中的参数量。此外卷积操作利用了图片空间上的局部相关性,这也就是CNN与传统神经网络或机器学习的一个最大的不同点,特征的自动提取。
这也就是为什么卷积层往往会有多个卷积核(甚至几十个,上百个),因为权值共享后意味着每一个卷积核只能提取到一种特征,为了增加CNN的表达能力,当然需要多个核,不幸的是,它是一个Hyper-Parameter。