3.1 如何检验
3.2 特征标准化
3.3 如何辨别好特征
3.4 激励函数
3.5 过拟合
3.6 加速神经网络训练过程
传统的w的更新方法:
momentum:引入一定的惯性
AdaGrad:在学习率上面修正,使得越弯曲,学习率越低
RMSProp
Adam
处理不均衡数据
batch normalization
L1/L2正则化
3.2 特征标准化
3.3 如何辨别好特征
3.4 激励函数
3.5 过拟合
3.6 加速神经网络训练过程
传统的w的更新方法:
momentum:引入一定的惯性
AdaGrad:在学习率上面修正,使得越弯曲,学习率越低
RMSProp
Adam
处理不均衡数据
batch normalization
L1/L2正则化
3.1 如何检验
训练数据集合,测试数据集合
评价标准:
误差
精确度曲线:R2 score、F1 Score(不均衡数据的准确度)
要考虑过拟合
3.2 特征标准化
实际中的数据具有不同的单位,取值范围,收集方法等等都不同
不同参数的变化值对于结果的影响大小不同
将取值跨度大的数据缩小,取值跨度小的数据扩大
两种方法:

效果:加速,同时使得也不会变的扭曲
3.3 如何辨别好特征
有区分度
避免重复性信息
3.4 激励函数
解决线性方程描述能力有限的问题,使得输出信息有非线性特征

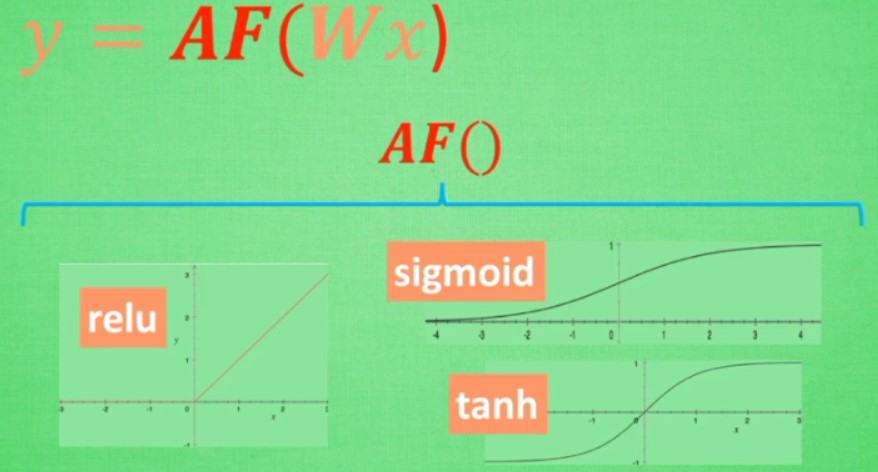
激励函数要可微分:这样才能在误差反向传播的时候才能将误差传播回去
默认首选的激励函数:
CNN:relu
RNN:relu或者tanh
3.5 过拟合
解决方法:
L1,L2正则式:防止变化太大,使得学习的曲线不会那么扭曲

dropout:专门用于神经网络
随机drop部分神经元,使得整个网络不会过于依赖某些结构的权值
3.6 加速神经网络训练过程
SGD:每次使用批量数据,加速NN的过程,不会丢失太多整体信息
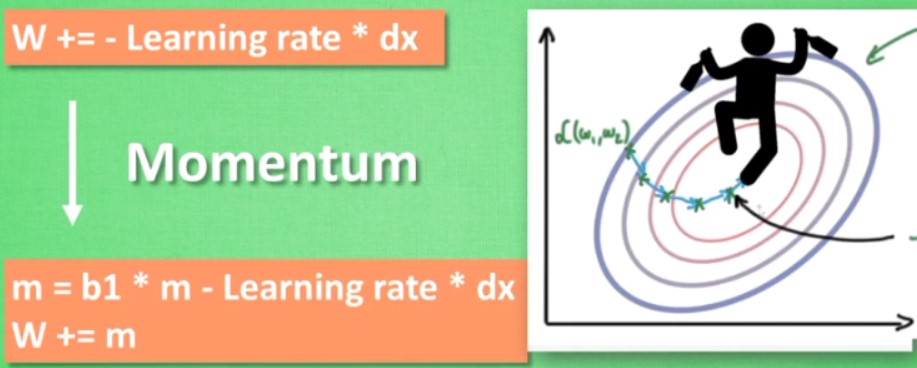
传统的w的更新方法:
![]() ,走的弯弯曲曲
,走的弯弯曲曲
momentum:引入一定的惯性
AdaGrad:在学习率上面修正,使得越弯曲,学习率越低

RMSProp
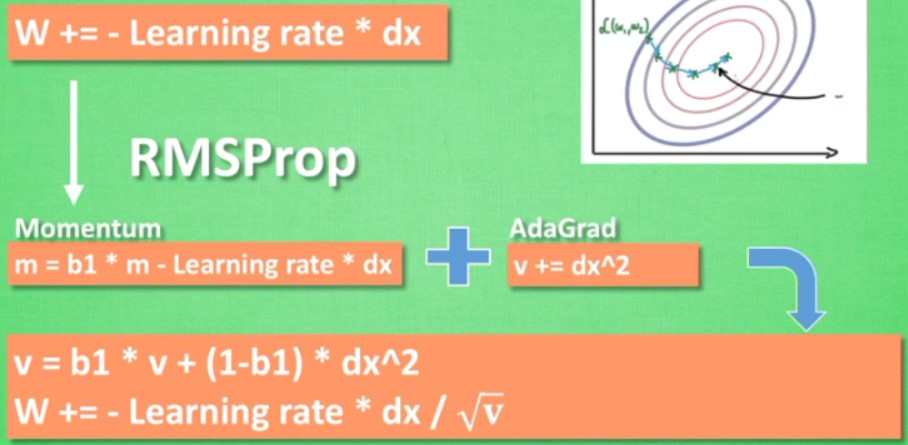
结合moment和ada
Adam
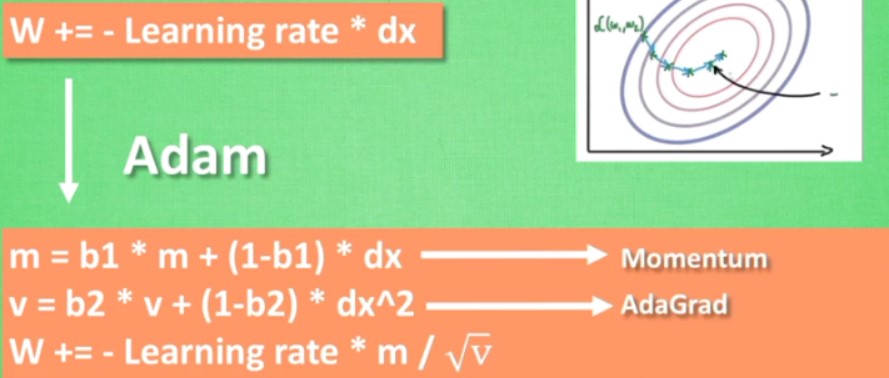
最常用的加速方法,效果好
处理不均衡数据
不均衡的数据处理起来,只要每次都预测多数派那么准确率都不会太差,但是没有什么意义
方法:
- 获得更多数据,使得数据变均衡
- 换个评判标准
原有的准确率和误差不好用

- 重组数据
人为调整数据的比例,比如可以砍掉部分多数派数据 - 换其他机器学习方法
神经网络会受到不均衡数据的影响,但是有些方法不受影响,比如决策树 - 修改算法
batch normalization
把数据分成很多小部分,
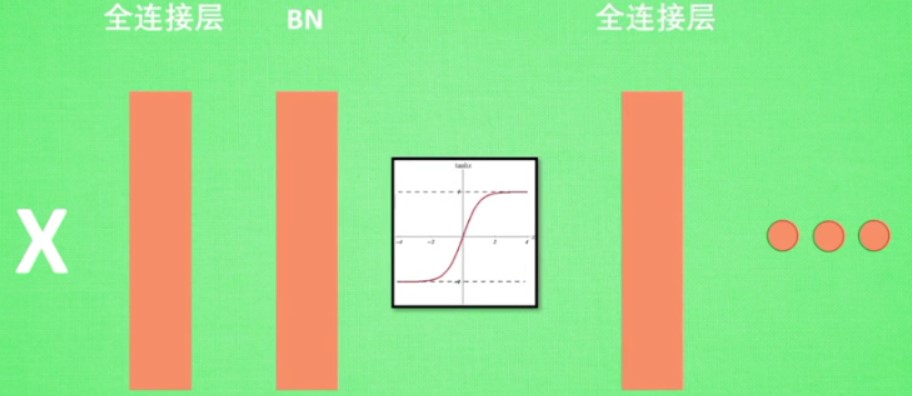
数据在输入激活函数之前的值是十分重要的

反标准化工序可以让网络自己学习β等参数,进行一定的纠正
L1/L2正则化
减缓过拟合问题
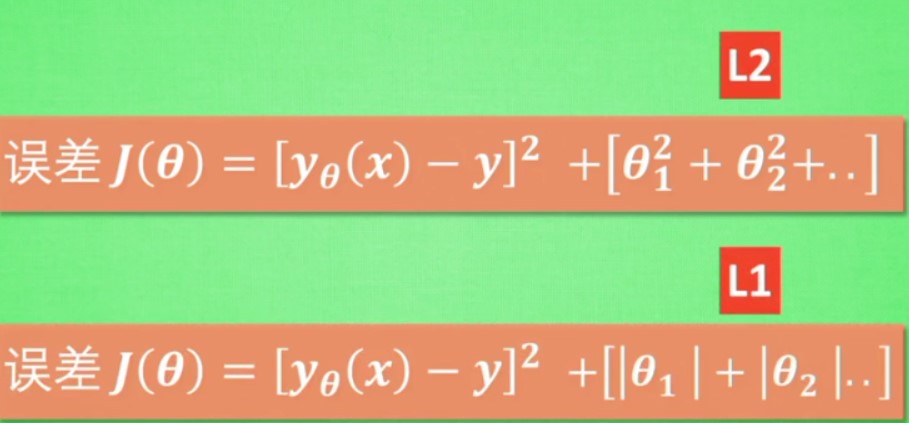

L1 的白点不太稳定,但是L2比较稳定
通常还会通过一定的权值来限制误差影响
而且还会通过交叉验证来进行一定的修正