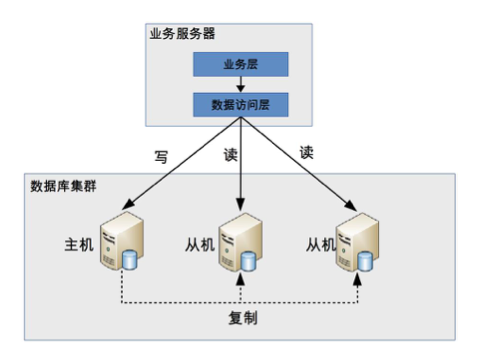
高性能数据库集群方案:读写分离。 其目的在于将访问压力分散到集群中的多个节点,减轻高并发现的访问压力,但是没有分散存储压力。
读写分离的基本架构图如下:

一主对从或者一主一从,主节点负责读写操作,从节点负责读操作。
主从分离的实现:
1、数据库搭建主从集群,一主多从或者一主一从
2、主机负责读写操作,从机负责读操作
3、主机通过复制将数据同步到从机,从而使每一个数据库都保证数据的一致性
主从同步的具体原理:
将主机的数据复制到多个从机(slaves)中,同步过程中,主机将数据库的操作写到二进制日志(binary log)中,从机打开一个io线程,打开和主机的连接,并将主机的更新日志写入从机的中继日志中,
从机开一个sql线程读取中继日志中的数据,进行更新,从而保证数据的主从数据的一致。
我们在这里为了数据库的高性能引入了主从分离,但是往往在做架构时,会因为提高系统的高性能,高可用等,引入一些操作,会增加系统的复杂度。 主从的实现不是难点,难点在于引入主从后复杂度随之而来的解决方案。
读写分离,增加了主从复制延迟 和分配机制两个负责度。
1、主从复制延迟
以 MySQL 为例,主从复制延迟可能达到 1 秒,如果有大量数据同步,延迟 1 分钟也是有可能的。主从复制延迟会带来一个问题:业务服务器将数据写入数据库主服务器立刻进行读取,但此时读操作的的访问时从机,主机还没有将数据复制到从机,所以此时查询会有问题。(比如用户刚进行注册,但是登录的时候却说无此用户)
有以下几种解决方案:
1、根据业务来区分,关键业务的读写全部指向主机,非关键业务采用读写分离
2、加入redis,将redis中数据的过期时间设置为主从延迟的时间,当进行访问时,redis中有数据,则说明主从同步未完成,若redis中无数据则说明主从同步已完成。
2、分配机制
读写分离,怎么实现读写分离呢?怎么知道读哪个数据库呢?一般有两种方式:程序代码封装和中间件封装。
1、程序代码的封装,在代码中抽象出来数据访问层,,实现读写操作分离和数据库服务器连接的管理