Background
第二次结对编程的任务是挑选一个用自然语言搜索相关代码片段的模型实现,并且可以提出自己的想法改进。这个任务很cool,前期做了不少调研。使用自然语言搜索相关代码片段现在是个很受关注的问题,比如Github如果能够加上这个搜索功能那么绝对是一个saving lives的黑科技。目前大家需要实现某个功能的代码时,往往选择在stackoverflow、segmentfault或者直接google找相关的内容。现在搜索引擎被污染的严重,各种垃圾回答坑害生命。(逃
目前学术界对于这个问题也挺关注的,今年出了一篇综述写的还不错,是关于codesearch相关的一个整理When Deep Learning Met Code Search。现在提出来的一些模型有code2vec, CODEnn, CodeNet, NCS以及改进版的UNIF等,github也发起了一个比赛CodeSearchNet。除了上课提到的一些method,一番调研下来发现这个问题确实很有意思。限于时间原因没有进一步尝试图神经网络的办法,不过目前关于CodeSearch Area确实没有GNN的身影(如果有相关paper欢迎留言!)
CODEnn Description
论文里给出了一个清晰的网络结构图,长成这个样子。思路其实非常的清晰,把(code, description)分别映射到向量空间里,让组成一个pair的余弦相关性更大。其中description的encoder论文里用的是RNN,而code部分的encoder的输入包含有三个部分:method name, api sequence和tokens。由于method name和api sequences都是上下文相关的,于是也都用RNN来做特征提取,而根据作者的说法,tokens是没有准确的order的,因此直接用MLP。
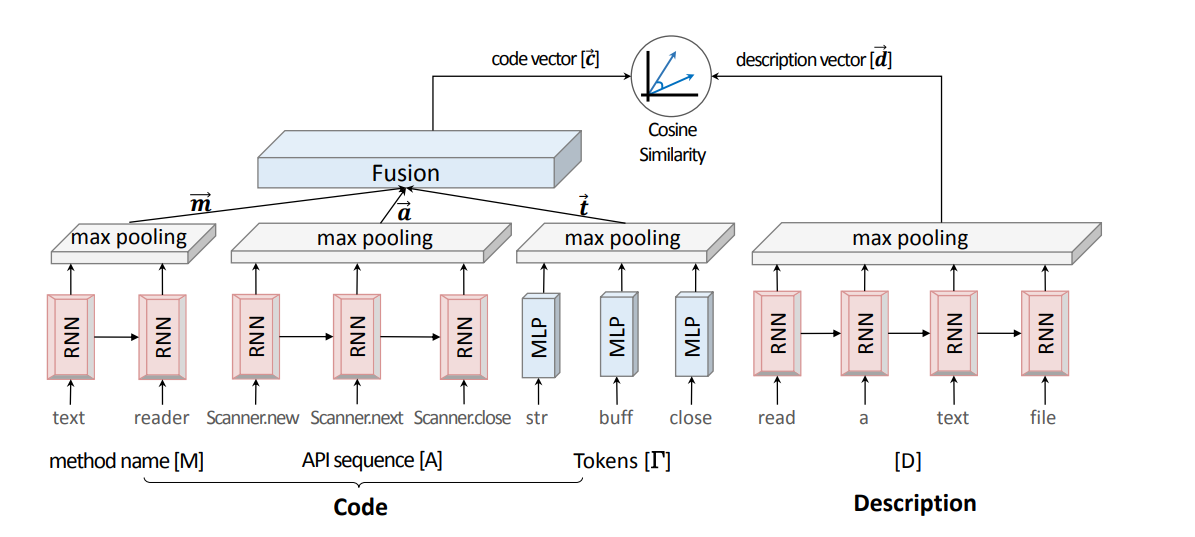
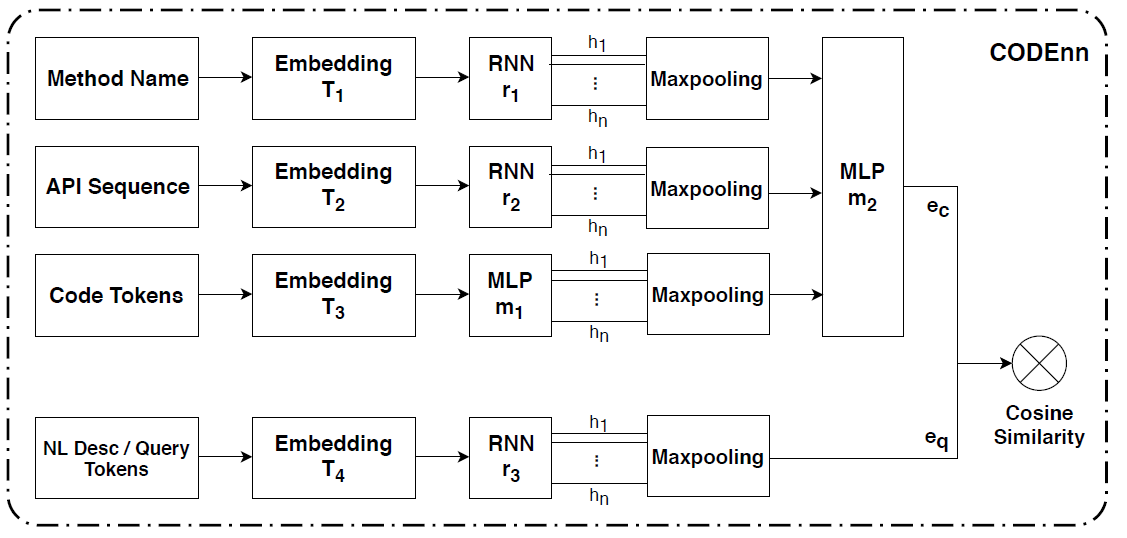
流程图也可以画成下面这个样子,可以看到决定模型最终效果的其实完全由codevec和descvec的训练出来的效果决定,首先通过wordembedding可以获得词向量,然后通过特征提取网络加pooling得到句子向量,这是现在NLP里的常规做法。
pros & cons
优点: 多方面的利用了code的属性来获取代码的特征,其中api的调用序列以及方法名称都是不错的attribute
缺点: 关于tokens和desc的encoder也许采用NLP里state-of-art的方法会更好,比如BERT当然模型就更难收敛了。
Reproduce
我和队友最后综合考虑决定复现CODEnn model,我们没有选择原始论文的数据集和代码来复现,因为手上没有足够的机器跑7位数的数据集。再加上老师希望我们实现python版本的codesearch模型,也是一个之后AI Coach的warm up,我和队友选择了Chao Li工程师提供的代码拿来复现。所幸之前实现的同学有一个最终结果可以拿来做参照。首先我和队友先研究了这份代码,数据集是预处理过了的大大降低了复现的难度。这里把原始论文中的RNN改成了GRU,maxpooling改成了meanpooling。训练过程中使用了tensorboard来观察loss和ACC、nDCG等指标。贴图出来可以看到,基本上已经收敛了

其中四个metric的变化过程如下:
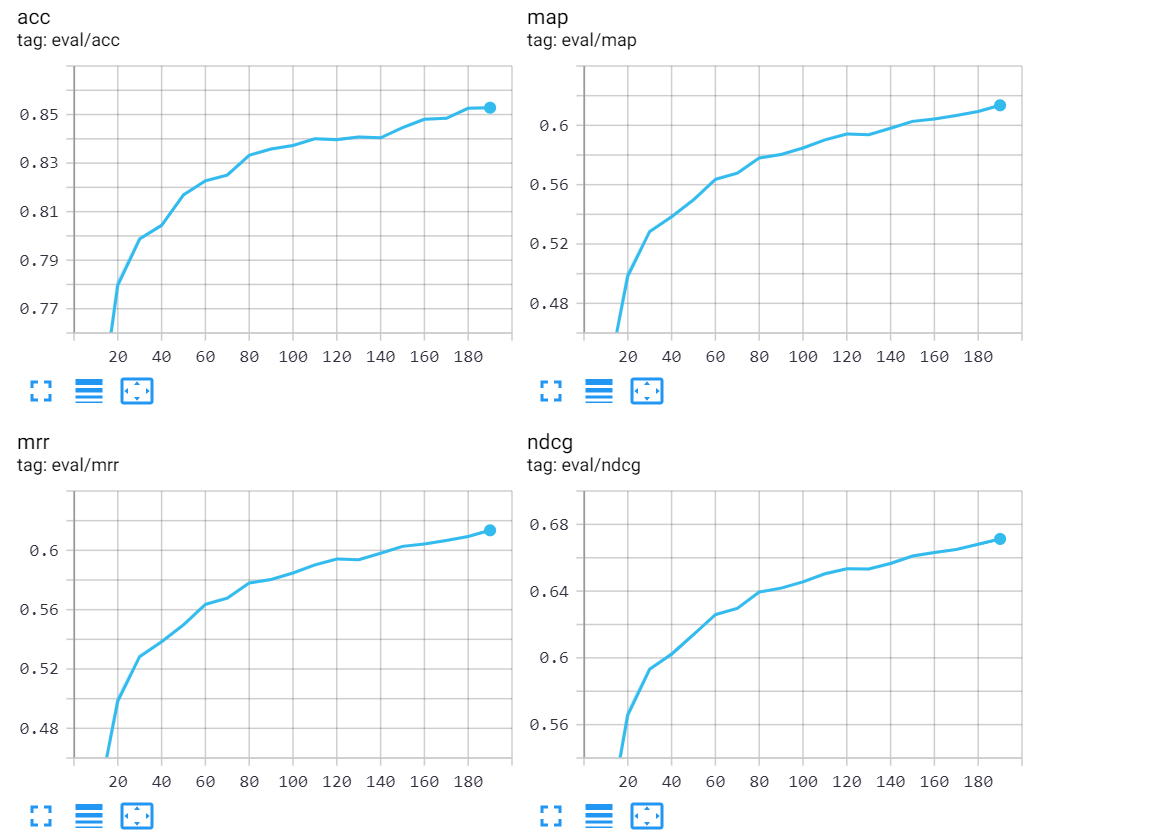
首先我们把batch_size改为64,在第一遍training的过程中发现lr不变的情况下在超过30个epoch之后loss就比较难降下去了,而且loss已经降到了1e-3的量级。所以第二遍train的时候把lr改成了分段的形式,在loss下降到了1e-3量级的时候调小了lr,在我们的训练过程里发现lr decay确实可以获得更好的效果。但是由于时间原因也没有跑到最佳的状态,目前的复现水平如下:
| datasets | acc@top5 | acc@top10 |
|---|---|---|
| validation set(pool=200) | 0.780680 | 0.860476 |
| validation set(pool=800) | 0.600521 | 0.704167 |
| test set(pool=200) | 0.783129 | 0.864014 |
| test set(pool=800) | 0.600486 | 0.704618 |
与Sunzi Ping复现的水平在validation set上有点差距,test set上基本保持一致的水平(有的高有的低)。不过考虑到测试的时候是240个epoch的版本,所以应该还有上升空间。按照目前曲线拟合的情况,应该是可以超过之前的浮现效果的。(模型还在跑,待更新最新数据)
| datasets | acc@top5 | acc@top10 |
|---|---|---|
| validation set(pool=200) | 0.806875 | 0.884375 |
| validation set(pool=800) | 0.621563 | 0.726250 |
| test set(pool=200) | 0.780667 | 0.860333 |
| test set(pool=800) | 0.596250 | 0.711250 |
Frontend Demostration
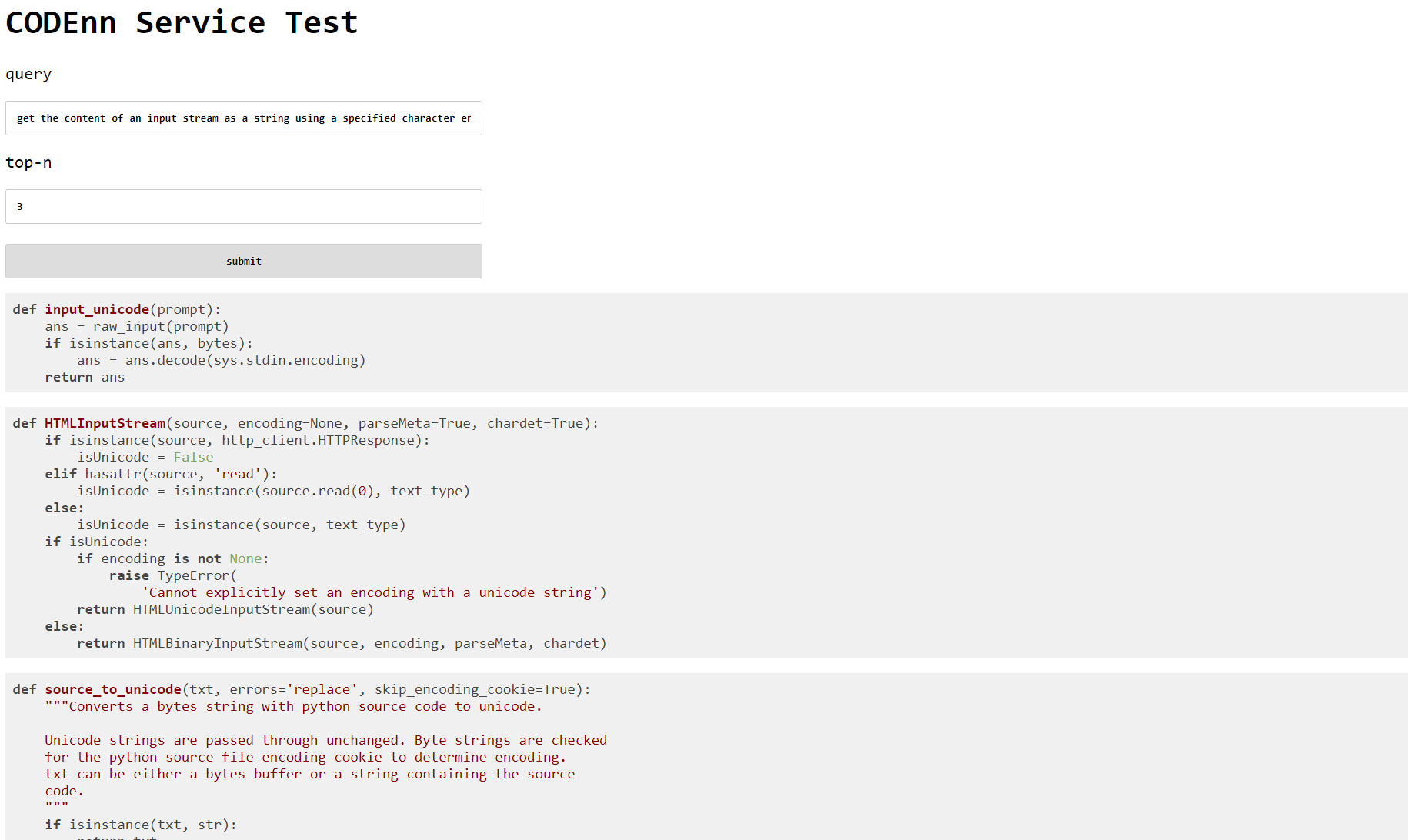
值得一提的是,我们写了点前端代码来方便演示模型的最终效果。我们拿一些例子跑了一下,有的时候返回的结果还是挺不错的,但是对于数据集里没有覆盖到的代码返回结果就很凌乱。比如论文中有一个例子,”get the content of an input stream as a string using a specified character encoding“,测试结果如下:
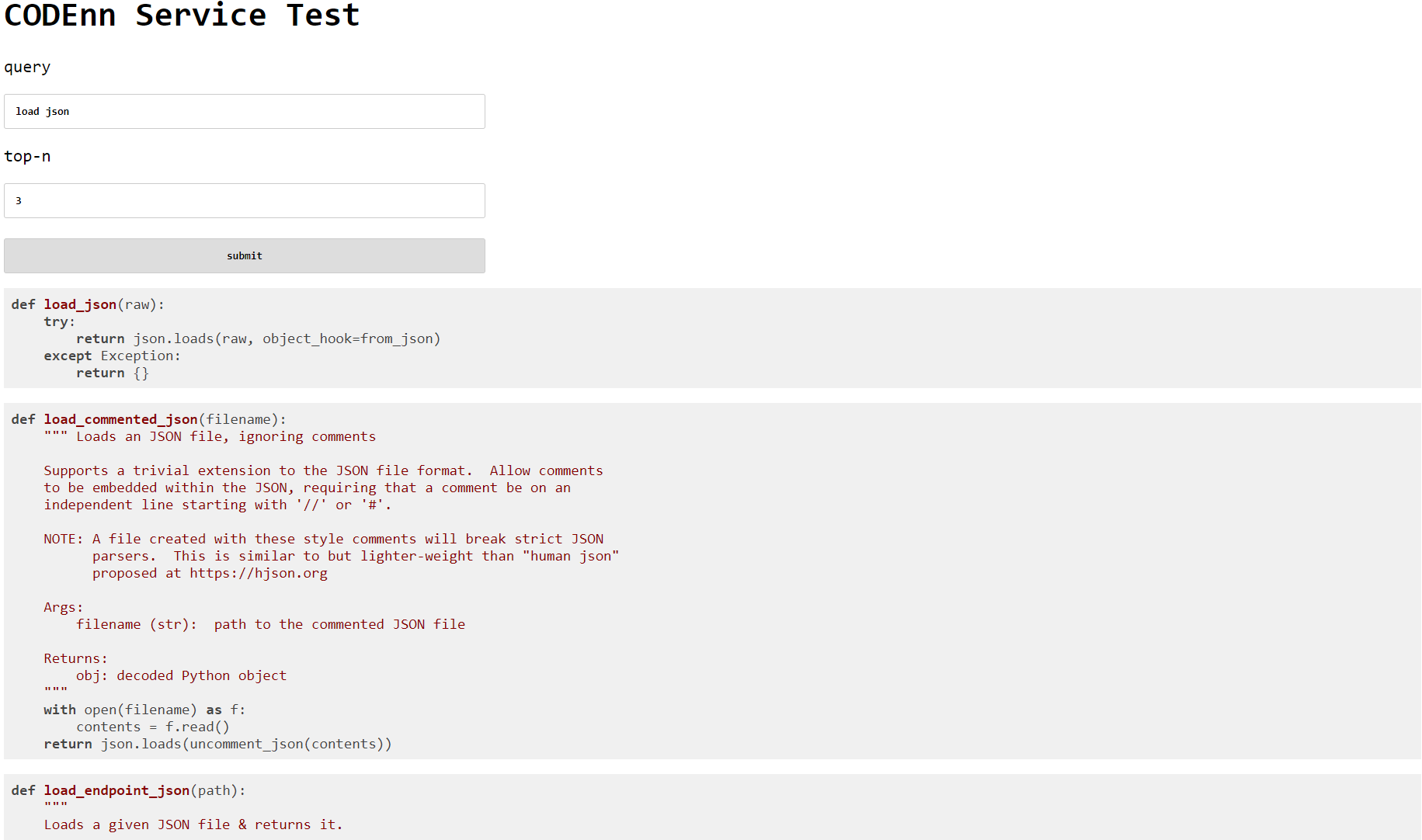
再比如可以测试一下简单需求”load json":
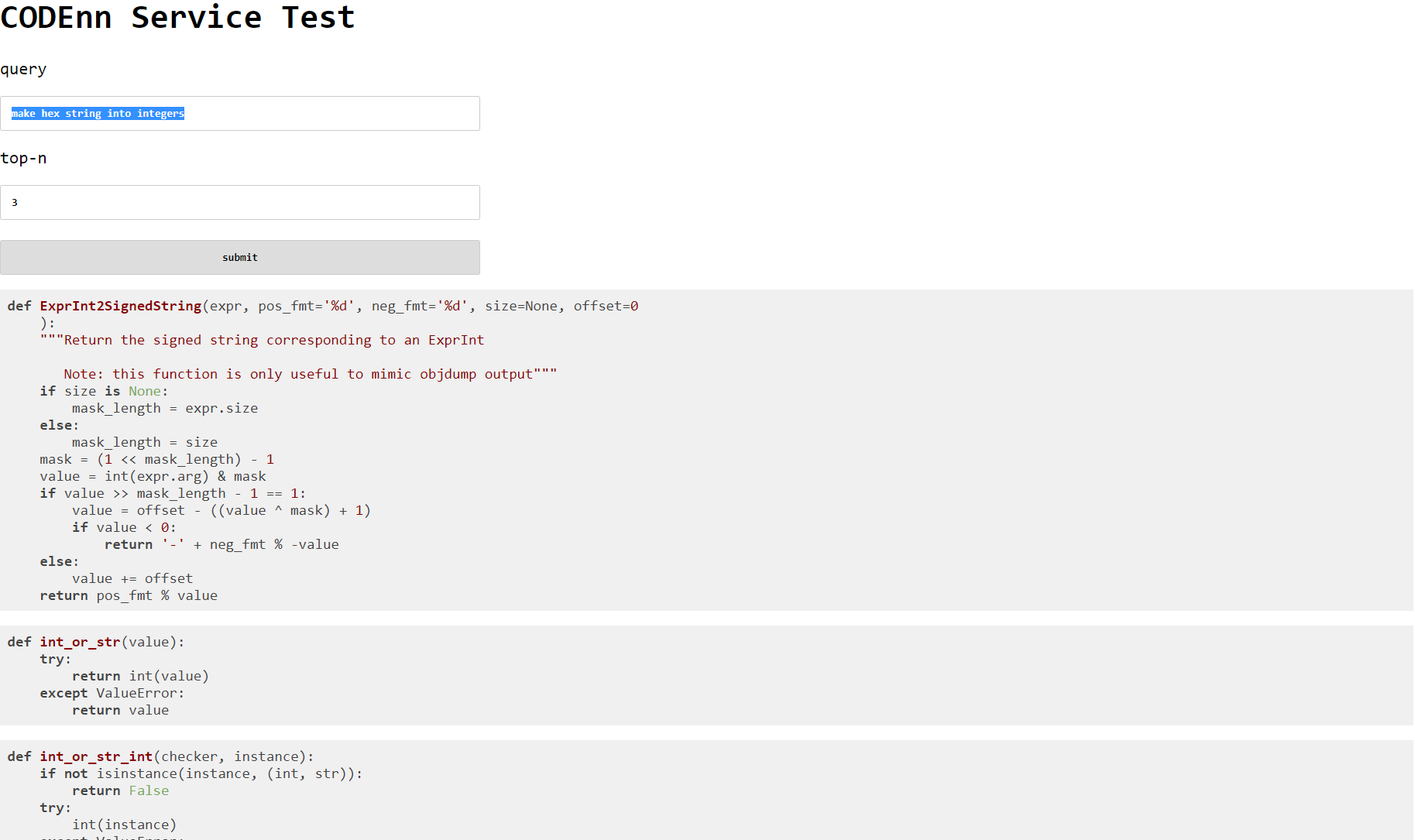
但是还是存在大量的搜索是不大ok的,比如“make hex string into integers"
Improvement
模型可以改进的地方有这么一些,不包括已经改变的RNN to GRU, maxpooling to meanpooling。可以把description部分的RNN用BERT代替,使用预训练的word2vec或者先预训练一个embedding,然后fine tune。code部分的改进办法可以简单的使用graph embeddding使用一些ast的信息。或者加上GCN来让事情变得有趣起来(大雾)。有一个比较大的问题时,经过我们的观察其实很多docstring并非一个准确的comment,比如一些作者信息、字符画也会存在。简而言之就是大家写代码(包括很多大型开源项目)都不喜欢写很清晰准确的注释,导致没有特别好的数据集。我和队友认为把当前的CODEnn配合干净、大量、高质量的数据集,应该已经可以获得thrilling的效果了。
Accessment
我的队友是易婧玮,她是一个非常positive的人,国庆假期经常找我商量结对编程的事情。我们做过很多讨论,并且她在NLP方面比我多很多经验,在读代码复现的过程中和她合作非常愉快,能够很快的定位问题解决问题。虽然我俩都很忙,还是比较认真的完成了这次结对编程的任务。遗憾的地方是没有来得及实现我们的idea,如果能抽出时间我们很愿意做这个工作。