作者:vivo 互联网服务器团队-Luo Mingbo
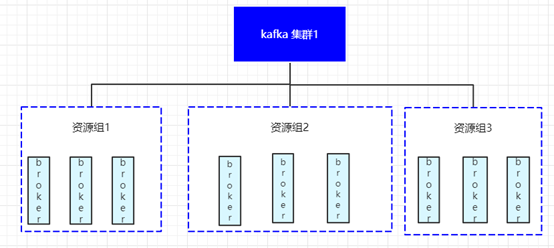
一、Kafka 集群部署架构
为了让读者能与小编在后续的问题分析中有更好的共鸣,小编先与各位读者朋友对齐一下我们 Kafka 集群的部署架构及服务接入 Kafka 集群的流程。
为了避免超大集群我们按照业务维度将整个每天负责十万亿级消息的 Kafka 集群拆分成了多个 Kafka 集群。拆分粒度太粗会导致单一集群过大,容易由于流量突变、资源隔离、限速等原因导致集群稳定性和可用性受到影响,拆分粒度太细又会因为集群太多不易维护,集群内资源较少应对突发情况的抗风险能力较弱。
由于 Kafka 数据存储和服务在同一节点上导致集群扩缩容周期较长,遇到突发流量时不能快速实现集群扩容扛住业务压力,因此我们按照业务维度和数据的重要程度及是否影响商业化等维度进行 Kafka 集群的拆分,同时在 Kafka 集群内添加一层逻辑概念“资源组”,资源组内的 Node 节点共享,资源组与资源组之间的节点资源相互隔离,确保故障发生时不会带来雪崩效应。
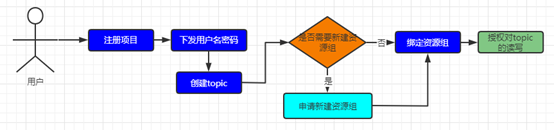
二、业务接入 Kafka 集群流程
-
在 Kafka 平台注册业务项目。
-
若项目的业务数据较为重要或直接影响商业化,用户需申请创建项目独立的资源组,若项目数据量较小且对数据的完整性要求不那么高可以直接使用集群提供的公共资源组无需申请资源组。
-
项目与逻辑概念资源组绑定。
-
创建 topic,创建 topic 时使用 Kafka 平台提供的接口进行创建,严格遵守 topic 的分区分布只能在项目绑定的资源组管理的 broker 节点上。
-
授权对 topic 的读写操作。
通过上述的架构部署介绍及接入流程接入介绍相信大家有很多相关知识点都与小编对齐了。
从部署架构图我们可以清晰的了解到我们这套集群部署在服务端最小的资源隔离单元为“资源组”即在同一个资源组下的多个broker节点之间会有影响,不同的资源组下的broker节点做了逻辑隔离。
上述的相关知识点对齐后我们将开启我们的故障排查之旅。
三、故障情况介绍
故障发生时,故障节点所在资源组的多个 topic 流量几乎全部掉零,生产环境我们对 Kafka 集群的磁盘指标READ、WRITE、IO.UTIL、AVG.WAIT、READ.REQ、WRITE.REQ做了告警监控,由于故障发生在凌晨,整个故障的处理过程持续实践较长,导致了业务方长时间的topic流量整体掉零对业务造成不小的影响。
四、监控指标介绍
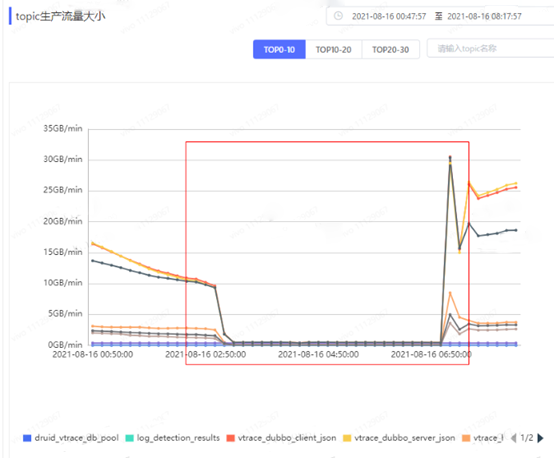
4.1 流量监控情况
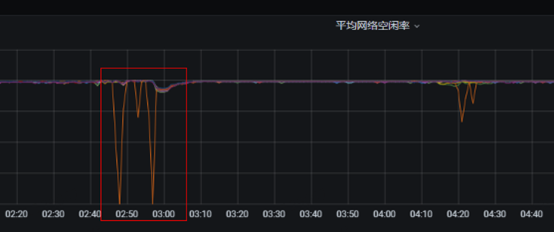
1、故障节点在故障发生时网络空闲率出现短暂的掉零情况,且与生产流量监控指标一致。一旦生产流量上升故障节点的网络空闲率就同步掉零。
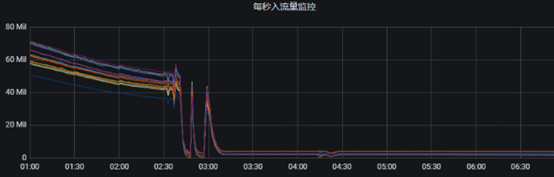
2、Grafana 监控指标中topic生产流量几乎全部掉零。
3、Kafka 平台项目监控中也体现了当前项目的多个topic生产流量指标掉零。
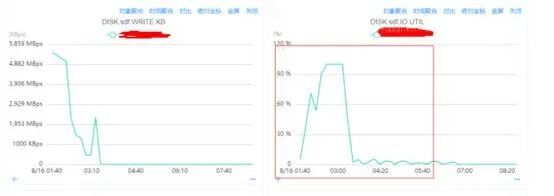
4.2 磁盘指标监控
SDF 盘的IO.UTIL指标达到100%, 80%左右我们认为是服务可稳定运行的指标阈值。
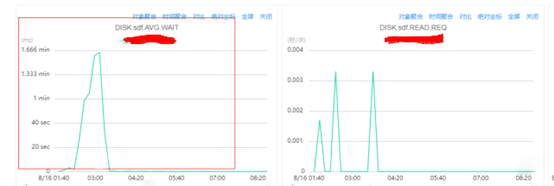
SDF 盘的AVG.WAIT指标达到分钟级等待,一般400ms左右的延迟我们认为是服务可稳定运行的阈值。
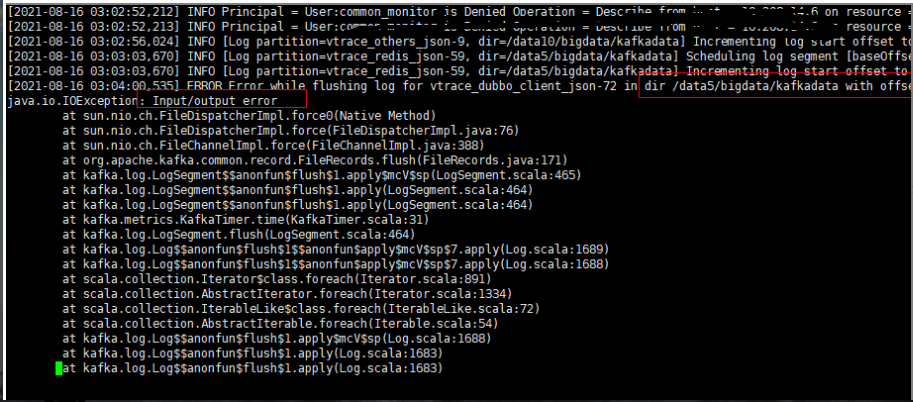
4.3 Kafka 服务端日志及系统日志情况
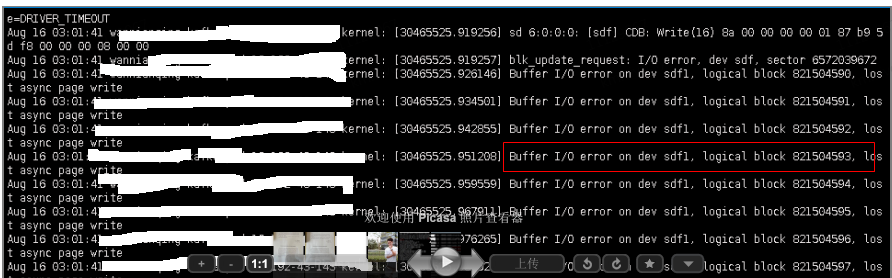
Kafka集群controller节点的日志中出现Input/Output error的错误日志。
Linux 系统日志中出现Buffer I/O error 的错误日志
五、故障猜想及分析
从上述的指标监控中很明显的可以得出结论,故障原因是由于 Kafka broker节点的sdf盘磁盘故障导致的,只需在对应的 Kafka broker 节点上将sdf盘踢掉重启即可恢复。那这样就结束了吗 ?of course not。
对 Kafka 有一定认识的小伙伴应该都知道,创建topic时topic的分区是均匀分布到集群内的不同broker节点上的,即使内部某一台broker节点故障,其他分区应该能正常进行生产消费,如果其他分区能进行正常的生产和消费就不应该出现整个topic的流量几乎全掉零的情况。
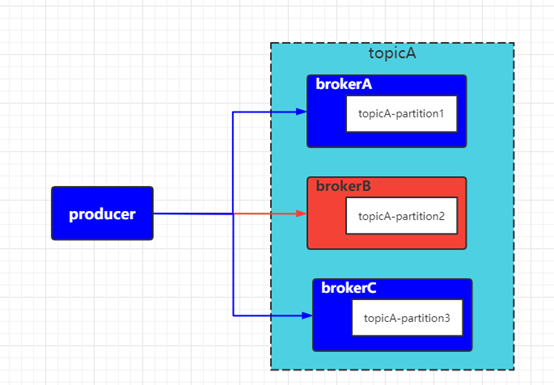
如上图所示,topicA 的三个分区分别分布在 brokerA、brokerB、brokerC三个物理主机节点上。
生产者producer向TopicA发送消息时会分别与brokerA、brokerB、brokerC三个物理主机节点建立长链接进行消息的发送,此时若 brokerB 节点发生故障无法向外部提供服务时按照我们的猜想应该不会影响到brokerA和brokerC两个节点继续向producer提供接收消息的服务。
但从监控指标的数据展示来分析当brokerB节点出现故障后topic整体流量掉零与我们的猜想大相径庭。
既然是出现类似了服务雪崩的效应导致了部分topic的整体流量几乎掉零那么我们在猜想问题发生的原因时就可以往资源隔离的方向去思考,看看在整个过程中还有哪些地方涉及到资源隔离的环节进行猜想。
Kafka 服务端我们按照资源组的方式做了 Kafka broker的逻辑隔离且从Grafana监控上可以看出有一些topic的流量并没有严重掉零的情况,那么我们暂时将分析问题的目光转移到 Kafka client端,去分析 Kafka producer的发送消息的过程是否存在有资源隔离地方没有做隔离导致了整体的雪崩效应。
六、Kafka 默认分区器的分区规则
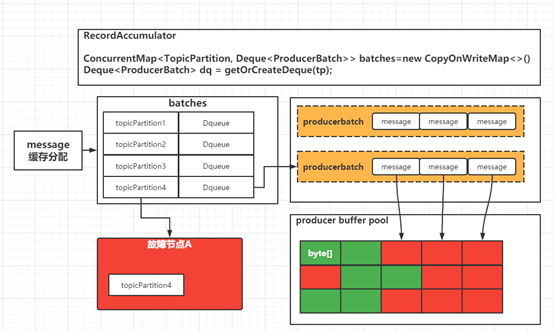
对 Kafka 生产流程流程有一定了解的同学肯定知道,Kafka 作为了大数据生态中海量数据的消息中间件,为了解决海量数据的并发问题 Kafka 在设计之初就采用了客户端缓冲消息,当消息达到一定批量时再进行批量消息的发送。
通过一次网络IO将批量的数据发送到 Kafka 服务端。关于Kafka producer客户端缓冲区的设计小编后续会单独一个篇幅进行深入的探索,鉴于篇幅问题不再此处进行详细分析。
基于此处的分析我们对一批消息发送到一个故障节点时的容错方案可以有以下猜想:
快速失败,记录故障节点信息。下次进行消息路由时只路由到健康的节点上。快速释放消息缓冲内存。
快速失败,记录故障节点信息,下次进行消息路由时当消息路由到故障节点上时直接报错,快速释放缓冲区内存。
等待超时,当次消息等待超时后,下次进行消息路由时依然会出现路由到故障节点上的情况,且每次等待超时时间后才释放占用的资源。
上述猜想中,如果是第一种情况,那么每次消息路由只路由到健康的节点上不会出现雪崩效应耗尽客户端缓冲区资源的情况;
第二种情况,当消息路由到故障节点上时,直接拒绝分配缓冲区资源也不会造成雪崩效应;
第三种情况,每次需要在一个或多个超时时间后才能将故障节点所占用的客户端缓冲区资源释放,在海量消息发送的场景下一个超时时间周期内故障节点上的消息足以将客户端缓冲区资源耗尽,导致其他可用分区无法分配客户端缓冲区资源导致出现雪崩效应。
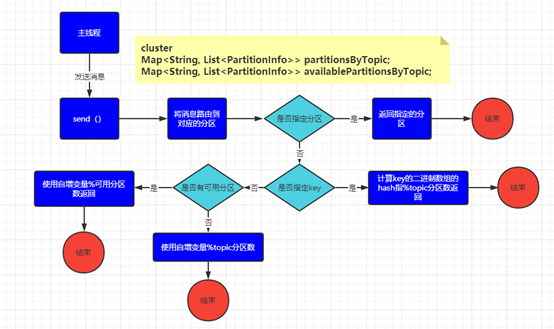
带着上述的猜想打开kafka client producer的源代码分析下defaultPartitioner的分区规则得到如下的分配逻辑:
发送消息时是否指定了分区,若指定了分区那消息就直接发往该分区无需重新路由分区。
消息是否指定了key,若消息指定了key,使用key的hash值与topic的分区数进行模运算,得出消息路由的分区号(对应第三种猜想)。
消息未指定分区也未指定key,使用自增变量与topic的可用分区进行模运算,得出消息路由的分区号(对应第一种猜想)。
七、总结
-
从源码中分析出若发送消息的时候指定了key,并使用的是 Kafka producer默认的分区分配器请款下会出现 Kafka producer 客户端缓冲区资源被耗尽而出现topic所有分区雪崩效应。
-
跟业务系统同学了解了他们的发送逻辑确实在消息发送指定了key并使用的是 Kafka producer的默认分区分配器。
-
问题得到论证。
八、建议
-
若非必要发送消息时不要指定key,否则可能会出现topic所有分区雪崩效应。
-
若确实需要发送消息指定key,建议不要使用Kafka producer默认的分区分配器,因为指定key的情况下使用 Kafka producer的默认分区分配器会出现雪崩效应。
九、扩展问题思考
-
为什么 Kafka producer提供的默认分区分配器要单独将指定key的情况采用topic所有分区进行模运算而在未指定key的采用是自增变量和可用分区进行模运算?
-
文章中分析的问题均为客户端缓冲区的粒度是producer实例级别的即一个producer共用一块内存缓冲区是否可以将缓冲区的粒度调整到分区级?
关于这系列的问题思考与分析,我们将在后续的文章中讲述,敬请关注。