作者:vivo互联网技术-Shuai Guangying
在《探究Presto SQL引擎(1)-巧用Antlr》中,我们介绍了Antlr的基本用法以及如何使用Antlr4实现解析SQL查询CSV数据,更加深入理解Presto查询引擎支持的SQL语法以及实现思路。
本次带来的是系列文章的第2篇,本文梳理了Join的原理,以及Join算法在Presto中的实现思路。通过理论和实践的结合,可以在理解原理的基础上,更加深入理解Join算法在OLAP场景下的工程落地技巧,比如火山模型,列式存储,批量处理等思想的应用。
一、背景
在业务开发中使用数据库,通常会有规范不允许过多表的Join。例如阿里巴巴开发手册中,有如下的规定:
【强制】超过三个表禁止Join。需要Join的字段,数据类型必须绝对一致;多表关联查询时,保证被关联的字段需要有索引。说明:即使双表Join也要注意表索引、SQL性能。
在大数据数仓的建设中,尽管我们有星型结构和雪花结构,但是最终交付业务使用的大多是宽表。
可以看出业务使用数据库中的一个矛盾点:我们需要Join来提供灵活的关联操作,但是又要尽量避免多表和大表Join带来的性能问题。这是为什么呢?
二、Join的基本原理
在数据库中Join提供的语义是非常丰富的。简单总结如下:
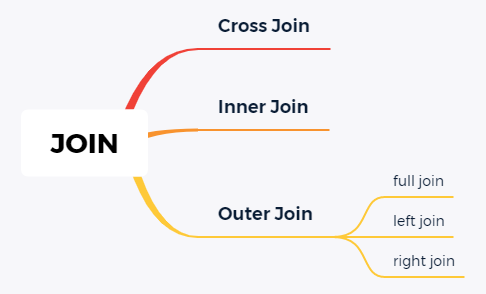
通常理解Join的实现原理,从Cross Join是最好的切入点,也就是所谓的笛卡尔积。对于集合进行笛卡尔积运算,理解非常简单,就是穷举两个集合中元素所有的组合情况。在数据库中,集合就对应到数据表中的所有行(tuples),集合中的元素就对应到单行(tuple)。所以实现Cross Join的算法也就呼之欲出了。
实现的代码样例如下:
List<Tuple> r = newArrayList(
new Tuple(newArrayList(1,"a")),
new Tuple(newArrayList(2,"b")));
List<Tuple> s = newArrayList(
new Tuple(newArrayList(3,"c")),
new Tuple(newArrayList(4,"d")));
int cnt =0;
for(Tuple ri:r){
for(Tuple si:s){
Tuple c = new Tuple().merge(ri).merge(si);
System.out.println(++cnt+": "+ c);
}
}
/**
* out:
1: [1, a, 3, c]
2: [1, a, 4, d]
3: [2, b, 3, c]
4: [2, b, 4, d]
*/
可以看出实现逻辑非常简单,就是两个For循环嵌套。
2.1 Nested Loop Join算法
在这个基础上,实现Inner Join的第一个算法就顺其自然了。非常直白的名称:Nested Loop,实现关键点如下:

(来源:Join Processing in Relational Databases)
其中,θ操作符可以是:=, !=, <, >, ≤, ≥。
相比笛卡尔积的实现思路,也就是添加了一层if条件的判断用于过滤满足条件的组合。
对于Nested Loop算法,最关键的点在于它的执行效率。假如参与Join的两张表一张量级为1万,一张量级为10w,那么进行比较的次数为1w*10w=10亿次。在大数据时代,通常一张表数据量都是以亿为单位,如果使用Nested Loop Join算法,那么Join操作的比较次数直接就是天文数字了。所以Nested Loop Join基本上是作为万不得已的保底方案。Nested Loop这个框架下,常见的优化措施如下:
-
小表驱动大表,即数据量较大的集作为于for循环的内部循环。
-
一次处理一个数据块,而不是一条记录。也就是所谓的Block Nested Loop Join,通过分块降低IO次数,提升缓存命中率。
值得一提的是Nested Loop Join的思想虽然非常朴素,但是天然的具备分布式、并行的能力。这也是为什么各类NoSQL数据库中依然保留Nested Loop Join实现的重要一点。虽然单机串行执行慢,但是可以并行化的话,那就是加机器能解决的问题了。
2.2 Sort Merge Join算法
通过前面的分析可以知道,Nested Loop Join算法的关键问题在于比较次数过多,算法的复杂度为O(m*n),那么突破口也得朝着这个点。如果集合中的元素是有序的,比较的次数会大幅度降低,避免很多无意义的比较运算。对于有序的所以Join的第二种实现方式如下所描述:

(来源:Join Processing in Relational Databases)s)
通过将JOIN操作拆分成Sort和Merge两个阶段实现Join操作的加速。对于Sort阶段,是可以提前准备好可以复用的。这样的思想对于MySQL这类关系型数据库是非常友好的,这也能解释阿里巴巴开发手册中要求关联的字段必须建立索引,因为索引保证了数据有序。该算法时间复杂度为排序开销O(m_log(m)+n_log(n))+合并开销O(m+n)。但是通常由于索引保证了数据有序,索引其时间复杂度为O(m+n)。
2.3 Hash Join算法
Sort Merge Join的思想在落地中有一定的限制。所谓成也萧何败萧何,对于基于Hadoop的数仓而言,保证数据存储的有序性这个点对于性能影响过大。在海量数据的背景下,维护索引成本是比较大的。而且索引还依赖于使用场景,不可能每个字段都建一个索引。在数据表关联的场景是大表关联小表时,比如:用户表(大表)--当日订单表(小表);事实表(大表)–维度表(小表),可以通过空间换时间。回想一下,在基础的数据结构中,tree结构和Hash结构可谓数据处理的两大法宝:一个保证数据有序方便实现区间搜索,一个通过hash函数实现精准命中点对点查询效率高。
在这样的背景下,通过将小表Hash化,实现Join的想法也就不足为奇了。

(来源:Join Processing in Relational Databases)
而且即使一张表在单机环境生成Hash内存消耗过大,还可以利用Hash将数据进行切分,实现分布式能力。所以,在Presto中Join算法通常会选择Hash Join,该算法的时间复杂度为O(m+n)。
通过相关资料的学习,可以发现Join算法的实现原理还是相当简单的,排序和Hash是数据结构最为基础的内容。了解了Join的基本思想,如何落地实践出来呢?毕竟talk is cheap。在项目中实现Join之前,需要一些铺垫知识。通常来说核心算法是皇冠上的明珠,但是仅有明珠是不够的还需要皇冠作为底座。
三、Join工程化前置条件
3.1 SQL处理架构-火山模型
在将Join算法落地前,需要先了解一下数据库处理数据的基本架构。在理解架构的基础上,才能将Join算法放置到合适的位置。在前面系列文章中探讨了基于antlr实现SQL语句的解析。可以发现SQL语法支持的操作类型非常丰富:查询表(TableScan),过滤数据(Filter),排序(Order),限制(Limit),字段进行运算(Project), 聚合(Group),关联(Join)等。为了实现上述的能力,需要一个具备并行化能力且可扩展的架构。
1994年Goetz Graefe在论文《Volcano-An Extensible and Parallel Query Evaluation System》提出了一个架构设计思想,这就是大名鼎鼎的火山模型,也称为迭代模型。火山模型其实包含了文件系统和查询处理两个部分,这里我们重点关注查询处理的设计思想。架构图如下:
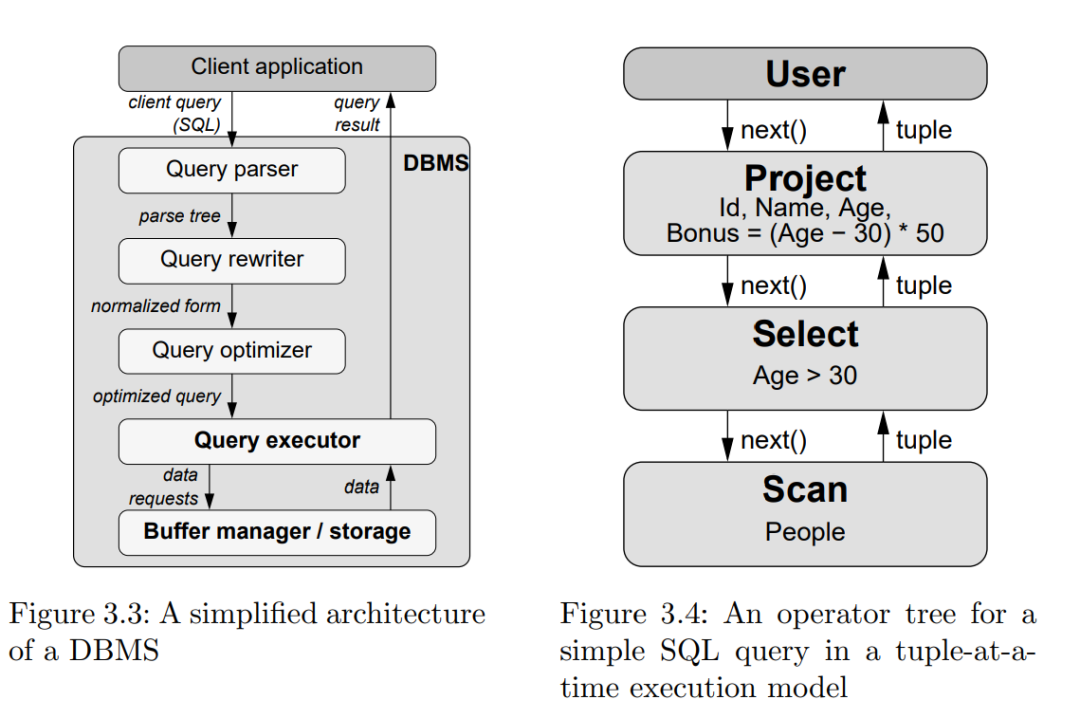
(来源:《Balancing vectorized execution with bandwidth-optimized storage》)
简单解读一下:
职责分离:将不同操作独立成一个的Operator,Operator采用open-next-close的迭代器模式。
例如对于SQL 。
SELECT Id, Name, Age, (Age - 30) * 50 AS Bonus
FROM People
WHERE Age > 30
对应到Scan, Select, Project三个Operator,数据交互通过next()函数实现。上述的理论在Presto中可以对应起来,例如Presto中几个常用的Operator, 基本上是见名知意:
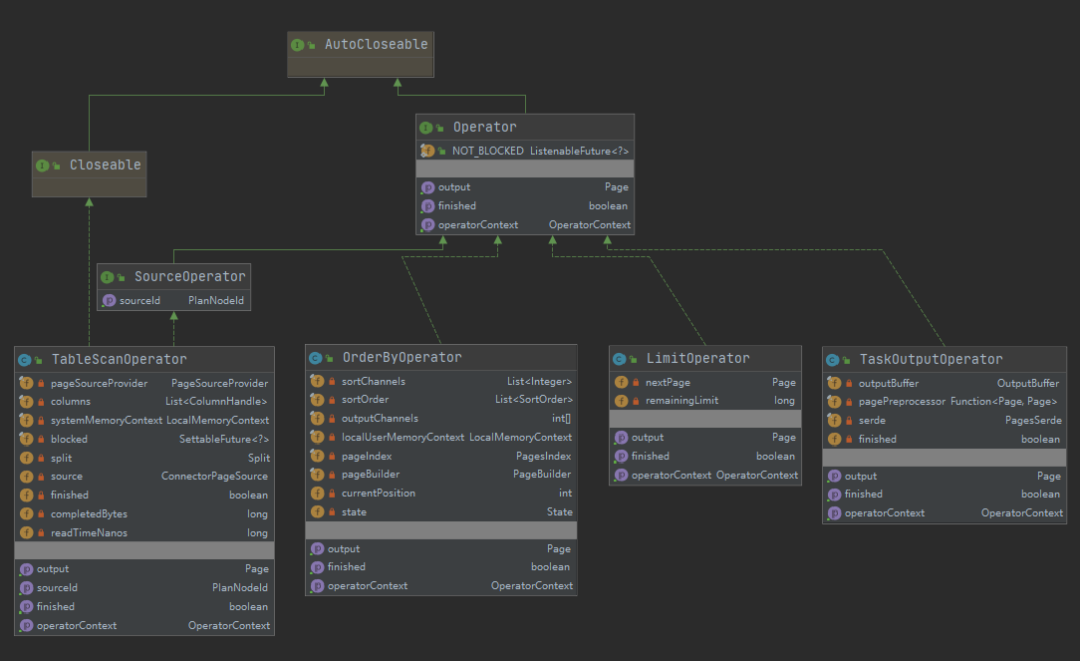
动态组装:Operator基于SQL语句的解析实现动态组装,多个Operator形成一个管道(pipeline)。
例如:print和predicate两个operator形成一个管道:
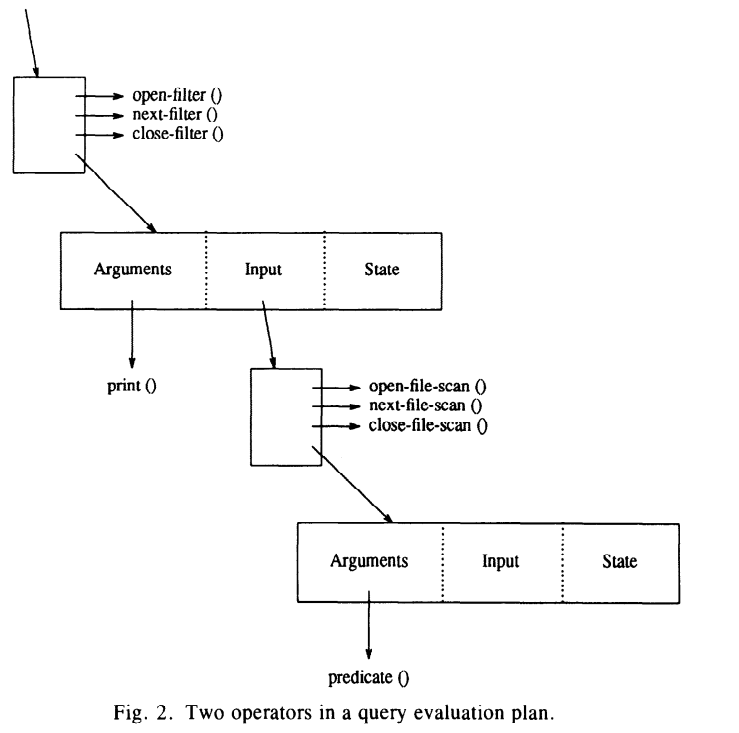
(来源: 《Volcano-An Extensible and Parallel Query Evaluation System》)
在火山模型的基础上,Presto吸收了数据库领域的其他思想,对基础的火山模型进行了优化改造,主要体现在如下几点:
-
Operator数据处理优化成一次一个Page,而不是一次行(也称为tuple)。
-
Page的存储采用列式结构。即相同的列封装到一个Block中。
批量处理结合列式存储奠定了向量化计算的基础。这也是数据库领域的优化方向。
3.2 批量处理和列式存储
在研读Presto源码时,几乎到处都可以看到Page/Block的身影。所以理解Page/Block背后的思想是理解Presto实现机制的基础。有相关书籍和文档讲解Page/Block的概念,但是由于这些概念是跟其他概念混在一起呈现,导致一时间不容易理解。
笔者认为Type-Block-Page三者放在一起,更容易理解。我们使用数据库,通常需要定义表,字段名称,字段类型。在传统的DBMS中,通常是按行存储数据,通常结构如下:

(来源:《数据库系统实现》)
但是通常OLAP场景不需要读取所有的字段,基于这样的场景,就衍生出来了列式存储。就是我们看到的如下结构:

(来源:《Presto技术内幕》)
即每个字段对应一个Block, 多个Block的切面才是一条记录,也就是所谓的行,在一些论文中称为tuple。通过对比可以清楚看出Presto中,Page就是典型了列式存储的实现。所以在Presto中,每个Type必然会关联到一种Block。例如:bigint类型就对应着LongArrayBlockBuilder,varchar类型对应着VariableWidthBlock。
理解了原理,操作Page/Block就变得非常简单了,简单的demo代码如下:
import com.facebook.presto.common.Page;
import com.facebook.presto.common.PageBuilder;
import com.facebook.presto.common.block.Block;
import com.facebook.presto.common.block.BlockBuilder;
import com.facebook.presto.common.type.BigintType;
import com.facebook.presto.common.type.Type;
import com.facebook.presto.common.type.VarcharType;
import com.google.common.collect.Lists;
import io.airlift.slice.Slice;
import java.util.List;
import static io.airlift.slice.Slices.utf8Slice;
/**
* PageBlockDemo
*
* @version 1.0
* @since 2021/6/22 19:26
*/
public class PageBlockDemo {
private static Page buildPage(List<Type> types,List<Object[]> dataSet){
PageBuilder pageBuilder = new PageBuilder(types);
// 封装成Page
for(Object[] row:dataSet){
// 完成一行
pageBuilder.declarePosition();
for (int column = 0; column < types.size(); column++) {
BlockBuilder out = pageBuilder.getBlockBuilder(column);
Object colVal = row[column];
if(colVal == null){
out.appendNull();
}else{
Type type = types.get(column);
Class<?> javaType = type.getJavaType();
if(javaType == long.class){
type.writeLong(out,(long)colVal);
}else if(javaType == Slice.class){
type.writeSlice(out, utf8Slice((String)colVal));
}else{
throw new UnsupportedOperationException("not implemented");
}
}
}
}
// 生成Page
Page page = pageBuilder.build();
pageBuilder.reset();
return page;
}
private static void readColumn(List<Type> types,Page page){
// 从Page中读取列
for(int column=0;column<types.size();column++){
Block block = page.getBlock(column);
Type type = types.get(column);
Class<?> javaType = type.getJavaType();
System.out.print("column["+type.getDisplayName()+"]>>");
List<Object> colList = Lists.newArrayList();
for(int pos=0;pos<block.getPositionCount();pos++){
if(javaType == long.class){
colList.add(block.getLong(pos));
}else if(javaType == Slice.class){
colList.add(block.getSlice(pos,0,block.getSliceLength(pos)).toStringUtf8());
}else{
throw new UnsupportedOperationException("not implemented");
}
}
System.out.println(colList);
}
}
public static void main(String[] args) {
/**
* 假设有两个字段,一个字段类型为int, 一个字段类型为varchar
*/
List<Type> types = Lists.newArrayList(BigintType.BIGINT, VarcharType.VARCHAR);
// 按行存储
List<Object[]> dataSet = Lists.newArrayList(
new Object[]{1L,"aa"},
new Object[]{2L,"ba"},
new Object[]{3L,"cc"},
new Object[]{4L,"dd"});
Page page = buildPage(types, dataSet);
readColumn(types,page);
}
}
// 运行结果:
//column[bigint]>>[1, 2, 3, 4]
//column[varchar]>>[aa, ba, cc, dd]
将数据封装成Page在各个Operator中流转,一方面避免了对象的序列化和反序列化成本,另一方面相比tuple的方式降低了函数调用的开销。这跟集装箱运货降低运输成本的思想是类似的。
四、Join算法的工程实践
理解了Join的核心算法和基础架构,结合前文中对antlr实现SQL表达式的解析以及实现where条件过滤,我们已经具备了实现Join的基础条件。接下来简单讲述一下Join算法的落地流程。首先在语法层面需要支持Join的语法,由于本文目的在于研究算法实现流程,而不在于实现完整的Join功能,因此我们暂且先考虑支持两张表单字段的等值Join语法。
首先在语法上需要支持Join, 基于antlr语法的定义关键点如下:
querySpecification
: SELECT selectItem (',' selectItem)*
(FROM relation (',' relation)*)?
(WHERE where=booleanExpression)?
;
selectItem
: expression #selectSingle
;
relation
: left=relation
(
joinType JOIN rightRelation=relation joinCriteria
) #joinRelation
| sampledRelation #relationDefault
;
joinType
: INNER?
;
joinCriteria
: ON booleanExpression
;
上述的语法定义将Join的关键要素拆解得非常清晰:Join的左表, Join的类型,Join关键词, Join的右表, Join的关联条件。例如,通常我们最简单的Join语句用例如下(借用presto的tpch数据源):
select t2.custkey, t2.phone, t1.orderkey from orders t1 inner join customer t2 on t1.custkey=t2.custkey limit 10;
对应着语法和SQL语句用例,可以看到在将Join算法落地,还需要考虑如下细节点:
-
检测SQL语句,确保SQL语句符合语法要求。
-
梳理表的别名和字段的对应关系,确保查询的字段和表能够对应起来,Join条件的字段类型能够匹配。
-
Join算法的选取,是HashJoin还是NestedLoopJoin还是SortMergeJoin?
-
哪个表是build表,哪个表是probe表?
-
Join条件的判断如何实现?
-
整个查询涉及到Operator如何组装,以实现最终结果的输出?
我们回顾一下SQL执行的关键流程:
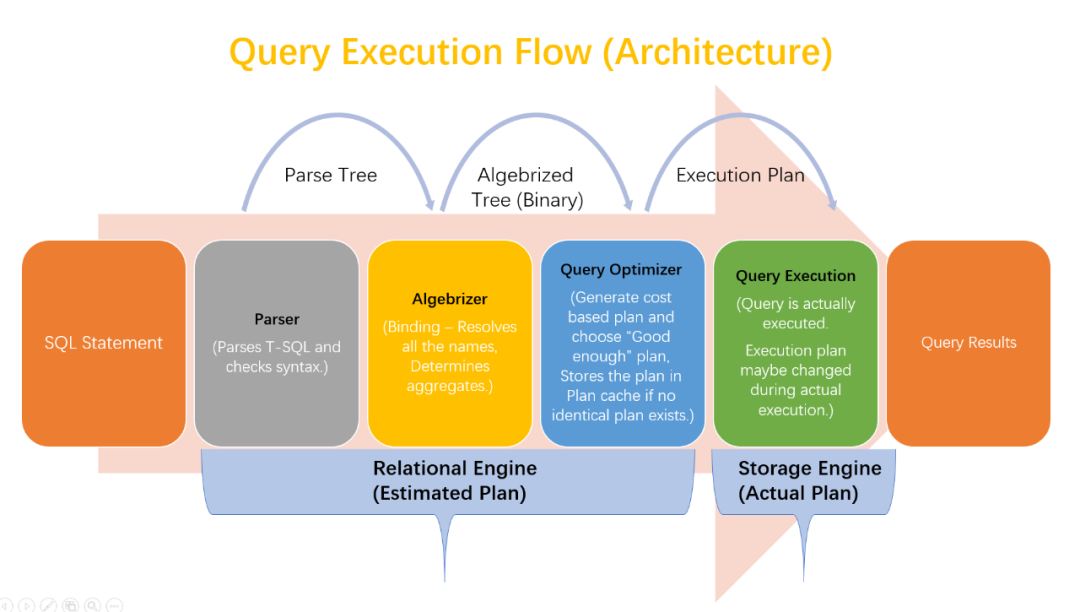
(来源: Query Execution Flow Architecture (SQL Server))
基于上面的流程,问题其实已经有了答案。
-
Parser:借助antlr的能力即可实现SQL语法的检测。
-
Binding:基于SQL语句生成AST,利用元数据检测字段和表的映射关系以及Join条件的字段类型。
-
Planner:基于AST生成查询计划。
-
Executor:基于查询计划生成对应的Operator并执行。
以NestedLoop Join算法为例,了解一下Presto的实现思路。对于NestedLoopJoin Join算法的落地,在Presto中其实是拆解为两个阶段:组合阶段和过滤阶段。在实现JoinOperator时,只需负责两个表数据的笛卡尔积组合即可。核心代码如下:
// NestedLoopPageBuilder中实现两个Page计算笛卡尔积的处理逻辑,这里RunLengthEncodedBlock用于一个元素复制,典型地笛卡尔积计算中需要将一列元素从1行复制成多行。
@Override
public Page next()
{
if (!hasNext()) {
throw new NoSuchElementException();
}
if (noColumnShortcutResult >= 0) {
rowIndex = maxRowIndex;
return new Page(noColumnShortcutResult);
}
rowIndex++;
// Create an array of blocks for all columns in both pages.
Block[] blocks = new Block[numberOfProbeColumns + numberOfBuildColumns];
// Make sure we always put the probe data on the left and build data on the right.
int indexForRleBlocks = buildPageLarger ? 0 : numberOfProbeColumns;
int indexForPageBlocks = buildPageLarger ? numberOfProbeColumns : 0;
// For the page with less rows, create RLE blocks and add them to the blocks array
for (int i = 0; i < smallPage.getChannelCount(); i++) {
Block block = smallPage.getBlock(i).getSingleValueBlock(rowIndex);
blocks[indexForRleBlocks] = new RunLengthEncodedBlock(block, largePage.getPositionCount());
indexForRleBlocks++;
}
// Put the page with more rows in the blocks array
for (int i = 0; i < largePage.getChannelCount(); i++) {
blocks[indexForPageBlocks + i] = largePage.getBlock(i);
}
return new Page(largePage.getPositionCount(), blocks);
}
五、小结
本文简单梳理了Join的基本算法以及在Presto中实现的基本框架,并以NestedLoop Join算法为例,演示了在Presto中的实现核心点。可以看出相比原始的算法描述,Presto的工程落地是截然不同: 不仅支持了所有的Join语义,而且实现了分布式能力。这其中有架构层面的思考,也有性能层面的思考,非常值得探索跟研究。就Join算法,可以探索的点还有很多,比如多表Join的顺序选取,大表跟小表Join的算法优化,Semi Join的算法优化,Join算法数据倾斜的问题等等,可谓路漫漫其修远兮,将在后续系列文章中继续分析探索。