全链路追踪技术的两个核心要素分别是 全链路信息获取 和 全链路信息存储展示。
Node.js 应用也不例外,这里将分成两篇文章进行介绍;第一篇介绍 Node.js 应用全链路信息获取, 第二篇介绍 Node.js 应用全链路信息存储展示。
一、Node.js 应用全链路追踪系统
目前行业内, 不考虑 Serverless 的情况下,主流的 Node.js 架构设计主要有以下两种方案:
-
通用架构:只做 ssr 和 bff,不做服务器和微服务;
-
全场景架构:包含 ssr、bff、服务器、微服务。
上述两种方案对应的架构说明图如下图所示:
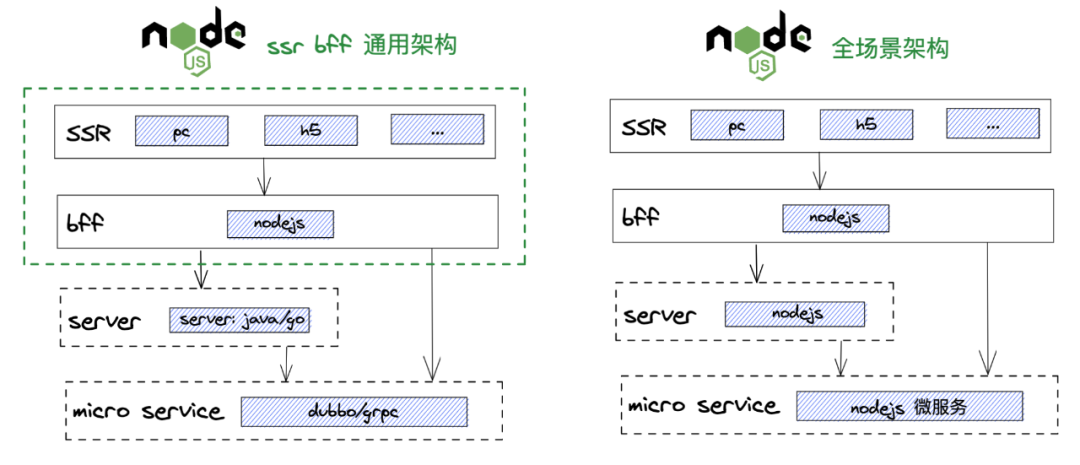
在上述两种通用架构中,nodejs 都会面临一个问题,那就是:
在请求链路越来越长,调用服务越来越多,其中还包含各种微服务调用的情况下,出现了以下诉求:
-
如何在请求发生异常时快速定义问题所在;
-
如何在请求响应慢的时候快速找出慢的原因;
-
如何通过日志文件快速定位问题的根本原因。
我们要解决上述诉求,就需要有一种技术,将每个请求的关键信息聚合起来,并且将所有请求链路串联起来。让我们可以知道一个请求中包含了几次服务、微服务请求的调用,某次服务、微服务调用在哪个请求的上下文。
这种技术,就是Node.js应用全链路追踪。它是 Node.js 在涉及到复杂服务端业务场景中,必不可少的技术保障。
综上,我们需要Node.js应用全链路追踪,说完为什么需要后,下面将介绍如何做Node.js应用的全链路信息获取。
二、全链路信息获取
全链路信息获取,是全链路追踪技术中最重要的一环。只有打通了全链路信息获取,才会有后续的存储展示流程。
对于多线程语言如 Java 、 Python 来说,做全链路信息获取有线程上下文如 ThreadLocal 这种利器相助。而对于Node.js来说,由于单线程和基于IO回调的方式来完成异步操作,所以在全链路信息获取上存在天然获取难度大的问题。那么如何解决这个问题呢?
三、业界方案
由于 Node.js 单线程,非阻塞 IO 的设计思想。在全链路信息获取上,到目前为止,主要有以下 4 种方案:
-
domain: node api;
-
zone.js: Angular 社区产物;
-
显式传递:手动传递、中间件挂载;
-
Async Hooks:node api;
而上述 4 个方案中, domain 由于存在严重的内存泄漏,已经被废弃了;zone.js 实现方式非常暴力、API比较晦涩、最关键的缺点是 monkey patch 只能 mock api ,不能 mock language;显式传递又过于繁琐和具有侵入性;综合比较下来,效果最好的方案就是第四种方案,这种方案有如下优点:
-
node 8.x 新加的一个核心模块,Node 官方维护者也在使用,不存在内存泄漏;
-
非常适合实现隐式的链路跟踪,入侵小,目前隐式跟踪的最优解;
-
提供了 API 来追踪 node 中异步资源的生命周期;
-
借助 async_hook 实现上下文的关联关系;
优点说完了,下面我们就来介绍如何通过 Async Hooks 来获取全链路信息。
四、Async Hooks【异步钩子】
4.1 Async Hooks 概念
Async Hooks 是 Node.js v8.x 版本新增加的一个核心模块,它提供了 API 用来追踪 Node.js 中异步资源的生命周期,可帮助我们正确追踪异步调用的处理逻辑及关系。在代码中,只需要写 import asyncHook from 'async_hooks' 即可引入 async_hooks 模块。
一句话概括:async_hooks 用来追踪 Node.js 中异步资源的生命周期。
目前 Node.js 的稳定版本是 v14.17.0 。我们通过一张图看下 Async Hooks 不同版本的 api 差异。如下图所示:

从图中可以看到该 api 变动较大。这是因为从 8 版本到 14 版本,async_hooks 依旧还是 Stability: 1 - Experimental
**Stability: 1 - Experimental **:该特性仍处于开发中,且未来改变时不做向后兼容,甚至可能被移除。不建议在生产环境中使用该特性。
但是没关系,要相信官方团队,这里我们的全链路信息获取方案是基于 Node v9.x 版本 api 实现的。对于 Async Hooks api 介绍和基本使用, 大家可以阅读官方文档,下文会阐述对核心知识的理解。
下面我们将系统介绍基于 Async Hooks 的全链路信息获取方案的设计和实现,下文统称为 zone-context 。
4.2 理解 async_hooks 核心知识
在介绍 zone-context 之前,要对 async_hooks 的核心知识有正确的理解,这里做了一个总结,有如下6点:
-
每一个函数(不论异步还是同步)都会提供一个上下文, 我们称之为 async scope ,这个认知对理解 async_hooks 非常重要;
-
每一个 async scope 中都有一个 asyncId ,它是当前 async scope 的标志,同一个的 async scope 中 asyncId 必然相同,每个异步资源在创建时, asyncId 自动递增,全局唯一;
-
每一个 async scope 中都有一个 triggerAsyncId ,用来表示当前函数是由哪个 async scope 触发生成的;
-
通过 asyncId 和 triggerAsyncId 我们可以追踪整个异步的调用关系及链路,这个是全链路追踪的核心;
-
通过 async_hooks.createHook 函数来注册关于每个异步资源在生命周期中发生的 init 等相关事件的监听函数;
-
同一个 async scope 可能会被调用及执行多次,不管执行多少次,其 asyncId 必然相同,通过监听函数,我们很方便追踪其执行的次数、时间以及上下文关系。
上述6点知识对于理解 async_hooks 是非常重要的。正是因为这些特性,才使得 async_hooks 能够优秀的完成Node.js 应用全链路信息获取。
到这里,下面就要介绍 zone-context 的设计和实现了,请和我一起往下看。
五、zone-context
5.1 架构设计
整体架构设计如下图所示:
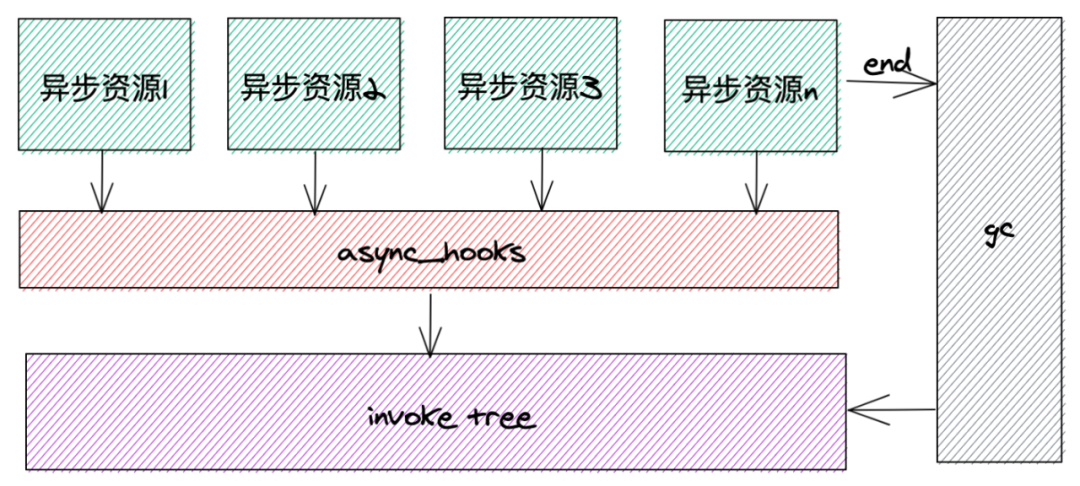
核心逻辑如下:异步资源(调用)创建后,会被 async_hooks 监听到。监听到后,对获取到的异步资源信息进行处理加工,整合成需要的数据结构,整合后,将数据存储到 invoke tree 中。在异步资源结束时,触发 gc 操作,对 invoke tree 中不再有用的数据进行删除回收。
从上述核心逻辑中,我们可以知道,此架构设计需要实现以下三个功能:
-
异步资源(调用)监听
-
invoke tree
-
gc
下面开始逐个介绍上述三个功能的实现。
5.2 异步资源(调用)监听
如何做到监听异步调用呢?
这里用到了 async_hooks (追踪 Node.js 异步资源的生命周期)代码实现如下:
asyncHook
.createHook({
init(asyncId, type, triggerAsyncId) {
// 异步资源创建(调用)时触发该事件
},
})
.enable()
是不是发现此功能实现非常简单,是的哦,就可以对所有异步操作进行追踪了。
在理解 async_hooks 核心知识中,我们提到了通过 asyncId 和 triggerAsyncId 可以追踪整个异步的调用关系及链路。现在大家看 init 中的参数,会发现, asyncId 和triggerAsyncId 都存在,而且是隐式传递,不需要手动传入。这样,我们在每次异步调用时,都能在 init 事件中,拿到这两个值。invoke tree 功能的实现,离不开这两个参数。
介绍完异步调用监听,下面将介绍 invoke tree 的实现。
5.3 invoke tree 设计和异步调用监听结合
5.3.1 设计
invoke tree 整体设计思路如下图所示:
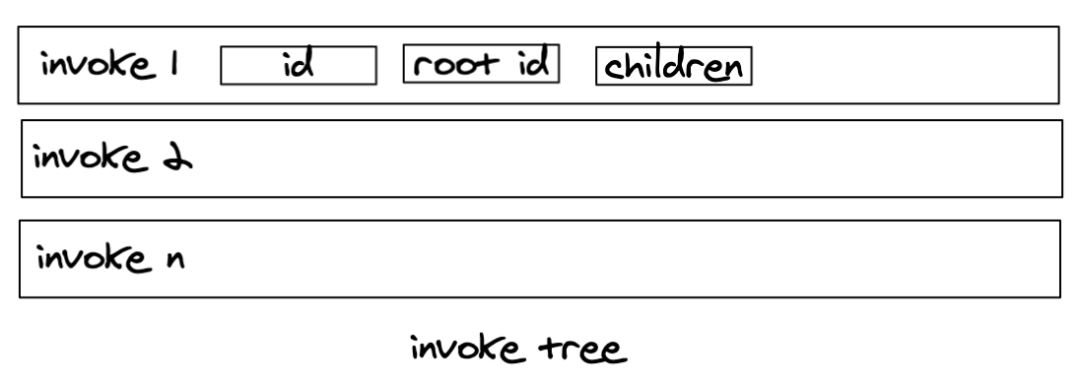
具体代码如下:
interface ITree { [key: string]: { // 调用链路上第一个异步资源asyncId rootId: number // 异步资源的triggerAsyncId pid: number // 异步资源中所包含的异步资源asyncId children: Array<number> }} const invokeTree: ITree = {}
创建一个大的对象 invokeTree, 每一个属性代表一个异步资源的完整调用链路。属性的key和value代表含义如下:
-
属性的 key 是代表这个异步资源的 asyncId。
-
属性的 value 是代表这个异步资源经过的所有链路信息聚合对象,该对象中的各属性含义请看上面代码中的注释进行理解。
通过这种设计,就能拿到任何一个异步资源在整个请求链路中的关键信息。收集根节点上下文。
5.3.2 和异步调用监听结合
虽然 invoke tree 设计好了。但是如何在 异步调用监听的 init 事件中,将 asyncId 、 triggerAsyncId 和 invokeTree 关联起来呢?
代码如下:
asyncHook
.createHook({
init(asyncId, type, triggerAsyncId) {
// 寻找父节点
const parent = invokeTree[triggerAsyncId]
if (parent) {
invokeTree[asyncId] = {
pid: triggerAsyncId,
rootId: parent.rootId,
children: [],
}
// 将当前节点asyncId值保存到父节点的children数组中
invokeTree[triggerAsyncId].children.push(asyncId)
}
}
})
.enable()
大家看上面代码,整个代码大致有以下几个步骤:
-
当监听到异步调用的时候,会先去 invokeTree 对象中查找是否含有 key 为 triggerAsyncId 的属性;
-
有的话,说明该异步调用在该追踪链路中,则进行存储操作,将 asyncId 当成 key , 属性值是一个对象,包含三个属性,分别是 pid、rootId、children , 具体含义上文已说过;
-
没有的话,说明该异步调用不在该追踪链路中。则不进行任何操作,如把数据存入 invokeTree 对象;
-
将当前异步调用 asyncId 存入到 invokeTree 中 key 为 triggerAsyncId 的 children 属性中。
至此,invoke tree 的设计、和异步调用监听如何结合,已经介绍完了。下面将介绍 gc 功能的设计和实现。
5.4 gc
5.4.1 目的
我们知道,异步调用次数是非常多的,如果不做 gc 操作,那么 invoke tree 会越来越大,node应用的内存会被这些数据慢慢占满,所以需要对 invoke tree 进行垃圾回收。
5.4.2 设计
gc 的设计思想主要如下:当异步资源结束的时候,触发垃圾回收,寻找此异步资源触发的所有异步资源,然后按照此逻辑递归查找,直到找出所有可回收的异步资源。
话不多说,直接上代码, gc 代码如下:
interface IRoot {
[key: string]: Object
}
// 收集根节点上下文
const root: IRoot = {}
function gc(rootId: number) {
if (!root[rootId]) {
return
}
// 递归收集所有节点id
const collectionAllNodeId = (rootId: number) => {
const {children} = invokeTree[rootId]
let allNodeId = [...children]
for (let id of children) {
// 去重
allNodeId = [...allNodeId, ...collectionAllNodeId(id)]
}
return allNodeId
}
const allNodes = collectionAllNodeId(rootId)
for (let id of allNodes) {
delete invokeTree[id]
}
delete invokeTree[rootId]
delete root[rootId]
}
gc 核心逻辑:用 collectionAllNodeId 递归查找所有可回收的异步资源( id )。然后再删除 invokeTree 中以这些 id 为 key 的属性。最后删除根节点。
大家看到了声明对象 root ,这个是什么呢?
root 其实是我们对某个异步调用进行监听时,设置的一个根节点对象,这个节点对象可以手动传入一些链路信息,这样可以为全链路追踪增加其他追踪信息,如错误信息、耗时时间等。
5.5 万事具备,只欠东风
我们的异步事件监听设计好了, invoke tree 设计好了,gc 也设计好了。那么如何将他们串联起来呢?比如我们要监听某一个异步资源,那么我们要怎样才能把 invoke tree 和异步资源结合起来呢?
这里需要三个函数来完成结合,分别是 **ZoneContext **、 setZoneContext 、 getZoneContext。下面来一一介绍下这三个函数:
5.5.1 ZoneContext
这是一个工厂函数,用来创建异步资源实例的,代码如下所示:
// 工厂函数
async function ZoneContext(fn: Function) {
// 初始化异步资源实例
const asyncResource = new asyncHook.AsyncResource('ZoneContext')
let rootId = -1
return asyncResource.runInAsyncScope(async () => {
try {
rootId = asyncHook.executionAsyncId()
// 保存 rootId 上下文
root[rootId] = {}
// 初始化 invokeTree
invokeTree[rootId] = {
pid: -1, // rootId 的 triggerAsyncId 默认是 -1
rootId,
children: [],
}
// 执行异步调用
await fn()
} finally {
gc(rootId)
}
})
}
大家会发现,在此函数中,有这样一行代码:
const asyncResource = new asyncHook.AsyncResource('ZoneContext')
这行代码是什么含义呢?
它是指我们创建了一个名为 ZoneContext 的异步资源实例,可以通过该实例的属性方法来更加精细的控制异步资源。
执行 asyncResource.runInAsyncScope 方法有什么用处呢?
调用该实例的 runInAsyncScope方法,在runInAsyncScope 方法中包裹要传入的异步调用。可以保证在这个资源( fn )的异步作用域下,所执行的代码都是可追踪到我们设置的 invokeTree 中,达到更加精细控制异步调用的目的。在执行完后,进行gc调用,完成内存回收。
5.5.2 setZoneContext
用来给异步调用设置额外的跟踪信息。代码如下:
function setZoneContext(obj: Object) {
const curId = asyncHook.executionAsyncId()
let root = findRootVal(curId)
Object.assign(root, obj)
}
通过 Object.assign(root, obj) 将传入的 obj 赋值给 root 对象中, key 为 curId 的属性。这样就可以给我们想跟踪的异步调用设置想要跟踪的信息。
5.5.3 getZoneContext
用来拿到异步调的 rootId 的属性值。代码如下:
function findRootVal(asyncId: number) {
const node = invokeTree[asyncId]
return node ? root[node.rootId] : null
}
function getZoneContext() {
const curId = asyncHook.executionAsyncId()
return findRootVal(curId)
}
通过给 findRootVal 函数传入 asyncId 来拿到 root 对象中 key 为 rootId 的属性值。这样就可以拿到当初我们设置的想要跟踪的信息了,完成一个闭环。
至此,我们将 Node.js应用全链路信息获取的核心设计和实现阐述完了。逻辑上有点抽象,需要多去思考和理解,才能对全链路追踪信息获取有一个更加深刻的掌握。
最后,我们使用本次全链路追踪的设计实现来展示一个追踪 demo 。
5.6 使用 zone-context
5.6.1 确定异步调用嵌套关系
为了更好的阐述异步调用嵌套关系,这里进行了简化,没有输出 invoke tree 。例子代码如下:
// 对异步调用A函数进行追踪
ZoneContext(async () => {
await A()
})
// 异步调用A函数中执行异步调用B函数
async function A() {
// 输出 A 函数的 asyncId
fs.writeSync(1, `A 函数的 asyncId -> ${asyncHook.executionAsyncId()}
`)
Promise.resolve().then(() => {
// 输出 A 函数中执行异步调用时的 asyncId
fs.writeSync(1, `A 执行异步 promiseC 时 asyncId 为 -> ${asyncHook.executionAsyncId()}
`)
B()
})
}
// 异步调用B函数中执行异步调用C函数
async function B() {
// 输出 B 函数的 asyncId
fs.writeSync(1, `B 函数的 asyncId -> ${asyncHook.executionAsyncId()}
`)
Promise.resolve().then(() => {
// 输出 B 函数中执行异步调用时的 asyncId
fs.writeSync(1, `B 执行异步 promiseC 时 asyncId 为 -> ${asyncHook.executionAsyncId()}
`)
C()
})
}
// 异步调用C函数
function C() {
const obj = getZoneContext()
// 输出 C 函数的 asyncId
fs.writeSync(1, `C 函数的 asyncId -> ${asyncHook.executionAsyncId()}
`)
Promise.resolve().then(() => {
// 输出 C 函数中执行异步调用时的 asyncId
fs.writeSync(1, `C 执行异步 promiseC 时 asyncId 为 -> ${asyncHook.executionAsyncId()}
`)
})
}
输出结果为:
A 函数的 asyncId -> 3
A 执行异步 promiseA 时 asyncId 为 -> 8
B 函数的 asyncId -> 8
B 执行异步 promiseB 时 asyncId 为 -> 13
C 函数的 asyncId -> 13
C 执行异步 promiseC 时 asyncId 为 -> 16
只看输出结果就可以推出以下信息:
-
A 函数执行异步调用后, asyncId 为 8 ,而 B 函数的 asyncId 是 8 ,这说明, B 函数是被 A 函数 调用;
-
B 函数执行异步调用后, asyncId 为 13 ,而 C 函数的 asyncId 是 13 ,这说明, C 函数是被 B 函数 调用;
-
C 函数执行异步调用后, asyncId 为 16 , 不再有其他函数的 asyncId 是 16 ,这说明, C 函数中没有调用其他函数;
-
综合上面三点,可以知道,此链路的异步调用嵌套关系为:A —> B -> C;
至此,我们可以清晰快速的知道谁被谁调用,谁又调用了谁。
5.6.2 额外设置追踪信息
在上面例子代码的基础下,增加以下代码:
ZoneContext(async () => {
const ctx = { msg: '全链路追踪信息', code: 1 }
setZoneContext(ctx)
await A()
})
function A() {
// 代码同上个demo
}
function B() {
// 代码同上个demo
D()
}
// 异步调用C函数
function C() {
const obj = getZoneContext()
Promise.resolve().then(() => {
fs.writeSync(1, `getZoneContext in C -> ${JSON.stringify(obj)}
`)
})
}
// 同步调用函数D
function D() {
const obj = getZoneContext()
fs.writeSync(1, `getZoneContext in D -> ${JSON.stringify(obj)}
`)
}
输出以下内容:呈现代码宏出错:参数
'com.atlassian.confluence.ext.code.render.InvalidValueException'的值无效。
getZoneContext in D -> {"msg":"全链路追踪信息","code":1}
getZoneContext in C-> {"msg":"全链路追踪信息","code":1}
可以发现, 执行 A 函数前设置的追踪信息后,调用 A 函数, A 函数中调用 B 函数, B 函数中调用 C 函数和 D 函数。在 C 函数和 D 函数中,都能访问到设置的追踪信息。
这说明,在定位分析嵌套的异步调用问题时,通过 getZoneContext 拿到顶层设置的关键追踪信息。可以很快回溯出,某个嵌套异步调用出现的异常,
是由顶层的某个异步调用异常所导致的。
5.6.3 追踪信息大而全的 invoke tree
例子代码如下:
ZoneContext(async () => {
await A()
})
async function A() {
Promise.resolve().then(() => {
fs.writeSync(1, `A 函数执行异步调用时的 invokeTree -> ${JSON.stringify(invokeTree)}
`)
B()
})
}
async function B() {
Promise.resolve().then(() => {
fs.writeSync(1, `B 函数执行时的 invokeTree -> ${JSON.stringify(invokeTree)}
`)
})
}
输出结果如下:
A 函数执行异步调用时的 invokeTree -> {"3":{"pid":-1,"rootId":3,"children":[5,6,7]},"5":{"pid":3,"rootId":3,"children":[10]},"6":{"pid":3,"rootId":3,"children":[9]},"7":{"pid":3,"rootId":3,"children":[8]},"8":{"pid":7,"rootId":3,"children":[]},"9":{"pid":6,"rootId":3,"children":[]},"10":{"pid":5,"rootId":3,"children":[]}}
B 函数执行异步调用时的 invokeTree -> {"3":{"pid":-1,"rootId":3,"children":[5,6,7]},"5":{"pid":3,"rootId":3,"children":[10]},"6":{"pid":3,"rootId":3,"children":[9]},"7":{"pid":3,"rootId":3,"children":[8]},"8":{"pid":7,"rootId":3,"children":[11,12]},"9":{"pid":6,"rootId":3,"children":[]},"10":{"pid":5,"rootId":3,"children":[]},"11":{"pid":8,"rootId":3,"children":[]},"12":{"pid":8,"rootId":3,"children":[13]},"13":{"pid":12,"rootId":3,"children":[]}}
根据输出结果可以推出以下信息:
1、此异步调用链路的 rootId (初始 asyncId ,也是顶层节点值) 是 3
2、函数执行异步调用时,其调用链路如下图所示:
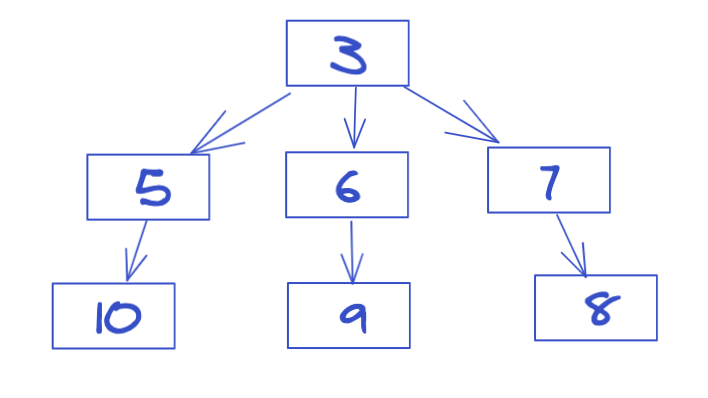
3、函数执行异步调用时,其调用链路如下图所示:
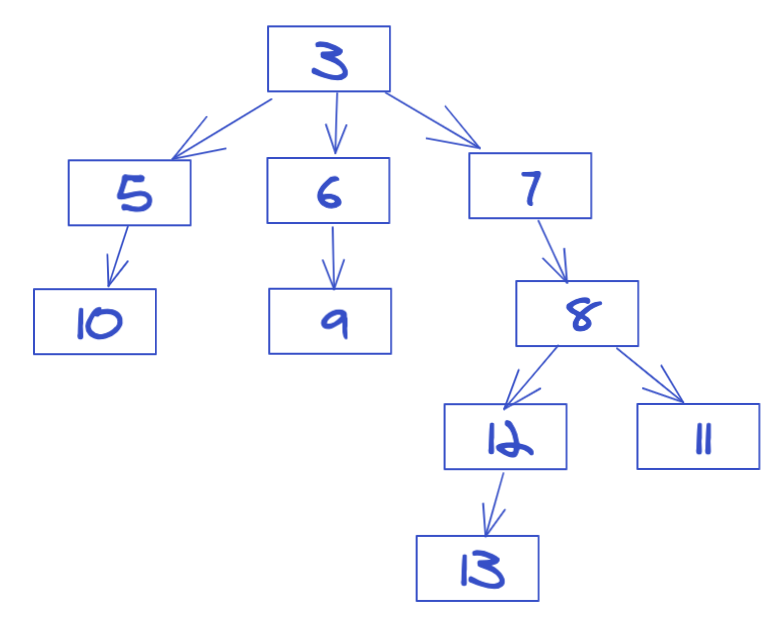
从调用链路图就可以清晰看出所有异步调用之间的相互关系和顺序。为异步调用的各种问题排查和性能分析提供了强有力的技术支持。
六、总结
到这,关于Node.js 应用全链路信息获取的设计、实现和案例演示就介绍完了。全链路信息获取是全链路追踪系统中最重要的一环,当信息获取搞定后,下一步就是全链路信息存储展示。
我将在下一篇文章中阐述如何基于 OpenTracing 开源协议来对获取的信息进行专业、友好的存储和展示。
作者:vivo互联网前端团队-Yang Kun